
File size: 2,638 Bytes
3fd0224 d578be4 3fd0224 32d703a 0f7005a 3278c0b 34485f9 8eb143d 03cb01c 8eb143d 3278c0b 34485f9 32d703a 7bde159 32d703a 08c544d e086b09 267592f fc46d14 947720a fc46d14 b6bbbe0 a465cbf 34485f9 2ab8465 70a5722 fc46d14 0d92d86 1274c18 cc01c1e 34485f9 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
---
license: cc-by-nc-4.0
inference: false
pipeline_tag: text-generation
tags:
- gguf
- quantized
- text-generation-inference
---
> [!TIP]
> **Credits:** <br>
> Made with love by [**@Lewdiculous**](https://huggingface.co/Lewdiculous). <br>
> *If this proves useful for you, feel free to credit and share the repository and authors.*
> [!WARNING]
> **Warning:** <br>
> Not expected to handle Llama-3 at the moment.
Pull Requests with your own features and improvements to this script are always welcome.
# GGUF-IQ-Imatrix-Quantization-Script:
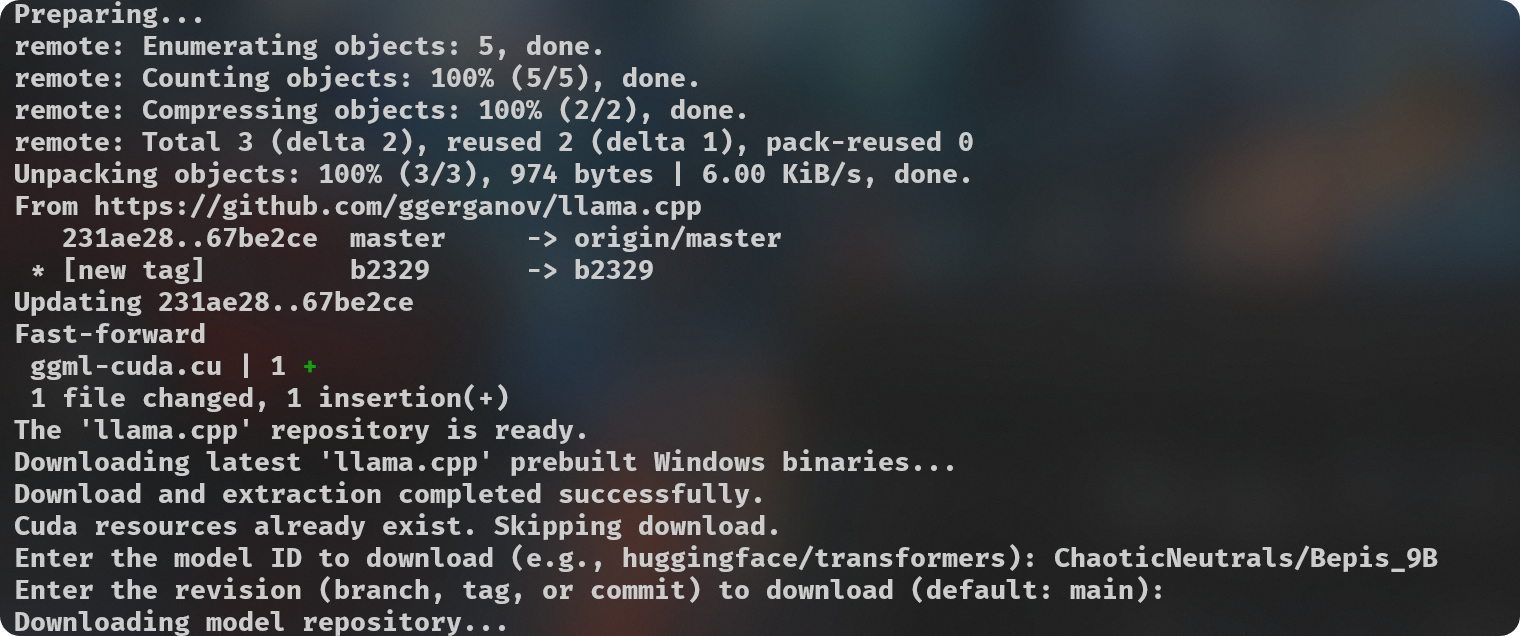
Simple python script (`gguf-imat.py`) to generate various GGUF-IQ-Imatrix quantizations from a Hugging Face `author/model` input, for Windows and NVIDIA hardware.
This is setup for a Windows machine with 8GB of VRAM, assuming use with an NVIDIA GPU. If you want to change the `-ngl` (number of GPU layers) amount, you can do so at [**line 135**](https://huggingface.co/FantasiaFoundry/GGUF-Quantization-Script/blob/main/gguf-imat.py#L135). This is only relevant during the `--imatrix` data generation. If you don't have enough VRAM you can decrease the `-ngl` amount or set it to 0 to only use your System RAM instead for all layers, this will make the imatrix data generation take longer, so it's a good idea to find the number that gives your own machine the best results.
Your `imatrix.txt` is expected to be located inside the `imatrix` folder. I have already included a file that is considered a good starting option, [this discussion](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-8395384) is where it came from. If you have suggestions or other imatrix data to recommend, please do so.
Adjust `quantization_options` in [**line 153**](https://huggingface.co/FantasiaFoundry/GGUF-Quantization-Script/blob/main/gguf-imat.py#L153).
> [!NOTE]
> Models downloaded to be used for quantization are cached at `C:\Users\{{User}}\.cache\huggingface\hub`. You can delete these files manually as needed after you're done with your quantizations, you can do it directly from your Terminal if you prefer with the `rmdir "C:\Users\{{User}}\.cache\huggingface\hub"` command. You can put it into another script or alias it to a convenient command if you prefer.
**Hardware:**
- NVIDIA GPU with 8GB of VRAM.
- 32GB of system RAM.
**Software Requirements:**
- Git
- Python 3.11
- `pip install huggingface_hub`
**Usage:**
```
python .\gguf-imat.py
```
Quantizations will be output into the created `models\{model-name}-GGUF` folder.
<br><br> |