

For more details please refer to our github repo: https://github.com/FlagOpen/FlagEmbedding
Visualized BGE
In this project, we introduce Visualized-BGE, a universal multi-modal embedding model. By integrating image token embedding into the BGE Text Embedding framework, Visualized-BGE is equipped to handle multi-modal data that extends beyond text in a flexible manner. Visualized-BGE is mainly used for hybrid modal retrieval tasks, including but not limited to:
- Multi-Modal Knowledge Retrieval (query: text; candidate: image-text pairs, text, or image) e.g. WebQA
- Composed Image Retrieval (query: image-text pair; candidate: images) e.g. CIRR, FashionIQ
- Knowledge Retrieval with Multi-Modal Queries (query: image-text pair; candidate: texts) e.g. ReMuQ
Moreover, Visualized BGE fully preserves the strong text embedding capabilities of the original BGE model : )
Specs
Model
| Model Name | Dimension | Text Embedding Model | Language | Weight |
|---|---|---|---|---|
| BAAI/bge-visualized-base-en-v1.5 | 768 | BAAI/bge-base-en-v1.5 | English | 🤗 HF link |
| BAAI/bge-visualized-m3 | 1024 | BAAI/bge-m3 | Multilingual | 🤗 HF link |
Data
We have generated a hybrid multi-modal dataset consisting of over 500,000 instances for training. The dataset will be released at a later time.
Usage
Installation:
Install FlagEmbedding:
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
pip install -e .
Another Core Packages:
pip install torchvision timm einops ftfy
You don't need to install xformer and apex. They are not essential for inference and can often cause issues.
Generate Embedding for Multi-Modal Data:
You have the flexibility to use Visualized-BGE encoding for multi-modal data in various formats. This includes data that is exclusively text-based, solely image-based, or a combination of both text and image data.
Note: Please download the model weight file (bge-visualized-base-en-v1.5, bge-visualized-m3) in advance and pass the path to the
model_weightparameter.
- Composed Image Retrival
############ Use Visualized BGE doing composed image retrieval
import torch
from FlagEmbedding.visual.modeling import Visualized_BGE
model = Visualized_BGE(model_name_bge = "BAAI/bge-base-en-v1.5", model_weight="path: Visualized_base_en_v1.5.pth")
model.eval()
with torch.no_grad():
query_emb = model.encode(image="./imgs/cir_query.png", text="Make the background dark, as if the camera has taken the photo at night")
candi_emb_1 = model.encode(image="./imgs/cir_candi_1.png")
candi_emb_2 = model.encode(image="./imgs/cir_candi_2.png")
sim_1 = query_emb @ candi_emb_1.T
sim_2 = query_emb @ candi_emb_2.T
print(sim_1, sim_2) # tensor([[0.8750]]) tensor([[0.7816]])
- Multi-Modal Knowledge Retrieval
####### Use Visualized BGE doing multi-modal knowledge retrieval
import torch
from FlagEmbedding.visual.modeling import Visualized_BGE
model = Visualized_BGE(model_name_bge = "BAAI/bge-base-en-v1.5", model_weight="path: Visualized_base_en_v1.5.pth")
with torch.no_grad():
query_emb = model.encode(text="Are there sidewalks on both sides of the Mid-Hudson Bridge?")
candi_emb_1 = model.encode(text="The Mid-Hudson Bridge, spanning the Hudson River between Poughkeepsie and Highland.", image="./imgs/wiki_candi_1.jpg")
candi_emb_2 = model.encode(text="Golden_Gate_Bridge", image="./imgs/wiki_candi_2.jpg")
candi_emb_3 = model.encode(text="The Mid-Hudson Bridge was designated as a New York State Historic Civil Engineering Landmark by the American Society of Civil Engineers in 1983. The bridge was renamed the \"Franklin Delano Roosevelt Mid-Hudson Bridge\" in 1994.")
sim_1 = query_emb @ candi_emb_1.T
sim_2 = query_emb @ candi_emb_2.T
sim_3 = query_emb @ candi_emb_3.T
print(sim_1, sim_2, sim_3) # tensor([[0.6932]]) tensor([[0.4441]]) tensor([[0.6415]])
- Multilingual Multi-Modal Retrieval
##### Use M3 doing Multilingual Multi-Modal Retrieval
import torch
from FlagEmbedding.visual.modeling import Visualized_BGE
model = Visualized_BGE(model_name_bge = "BAAI/bge-m3", model_weight="path: Visualized_m3.pth")
model.eval()
with torch.no_grad():
query_emb = model.encode(image="./imgs/cir_query.png", text="一匹马牵着这辆车")
candi_emb_1 = model.encode(image="./imgs/cir_candi_1.png")
candi_emb_2 = model.encode(image="./imgs/cir_candi_2.png")
sim_1 = query_emb @ candi_emb_1.T
sim_2 = query_emb @ candi_emb_2.T
print(sim_1, sim_2) # tensor([[0.7026]]) tensor([[0.8075]])
Evaluation Result
Visualized BGE delivers outstanding zero-shot performance across multiple hybrid modal retrieval tasks. It can also serve as a base model for downstream fine-tuning for hybrid modal retrieval tasks.
Zero-shot Performance
Statistical information of the zero-shot multi-modal retrieval benchmark datasets. During the zero-shot evaluation, we utilize the queries from the validation or test set of each dataset to perform retrieval assessments within the entire corpus of the respective dataset.
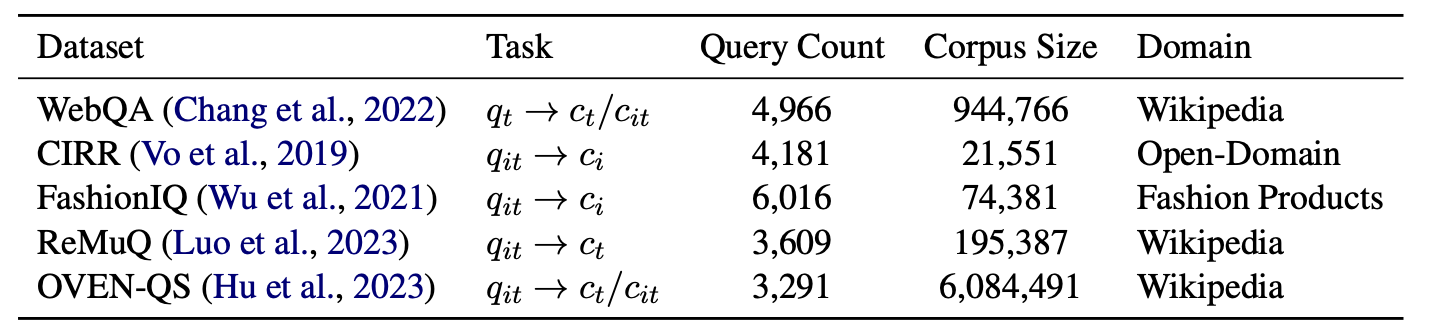
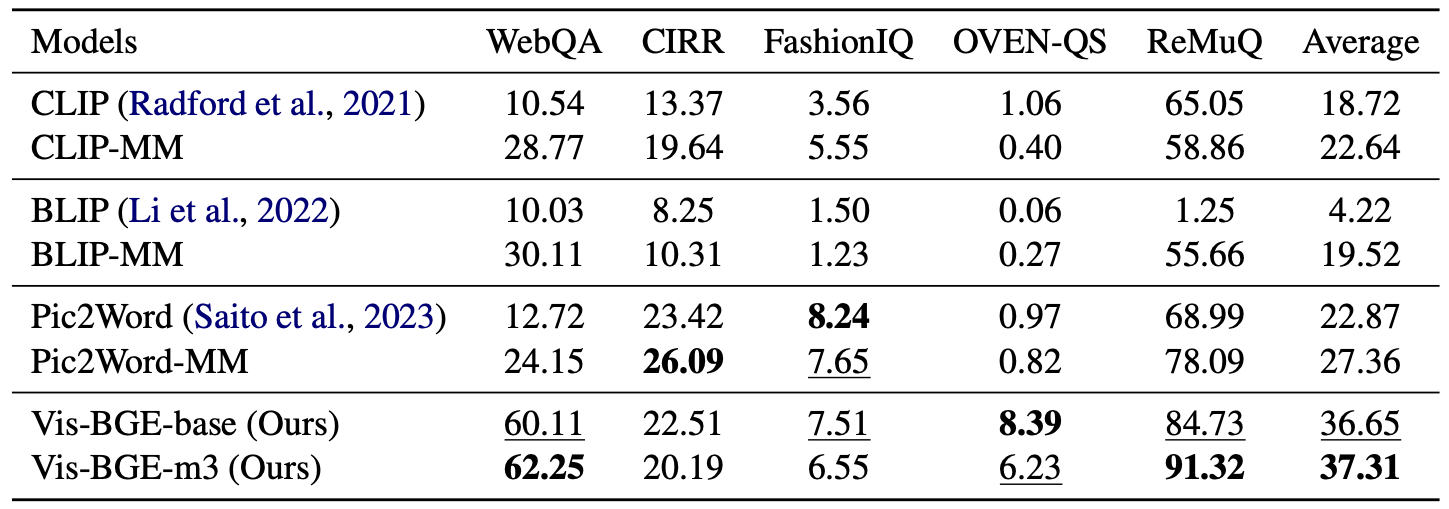
Zero-shot evaluation results with Recall@5 on various hybrid multi-modal retrieval benchmarks. The -MM notation indicates baseline models that have undergone multi-modal training on our generated data.


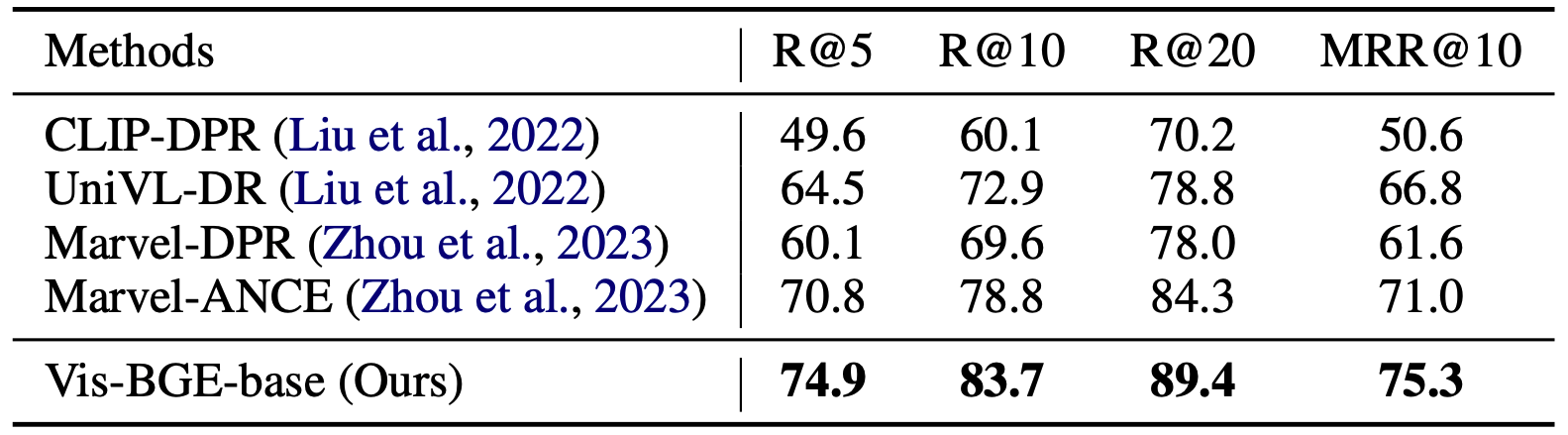
Fine-tuning on Downstream Tasks
- Supervised fine-tuning performance on the WebQA dataset. All retrievals are performed on the entire deduplicated corpus.
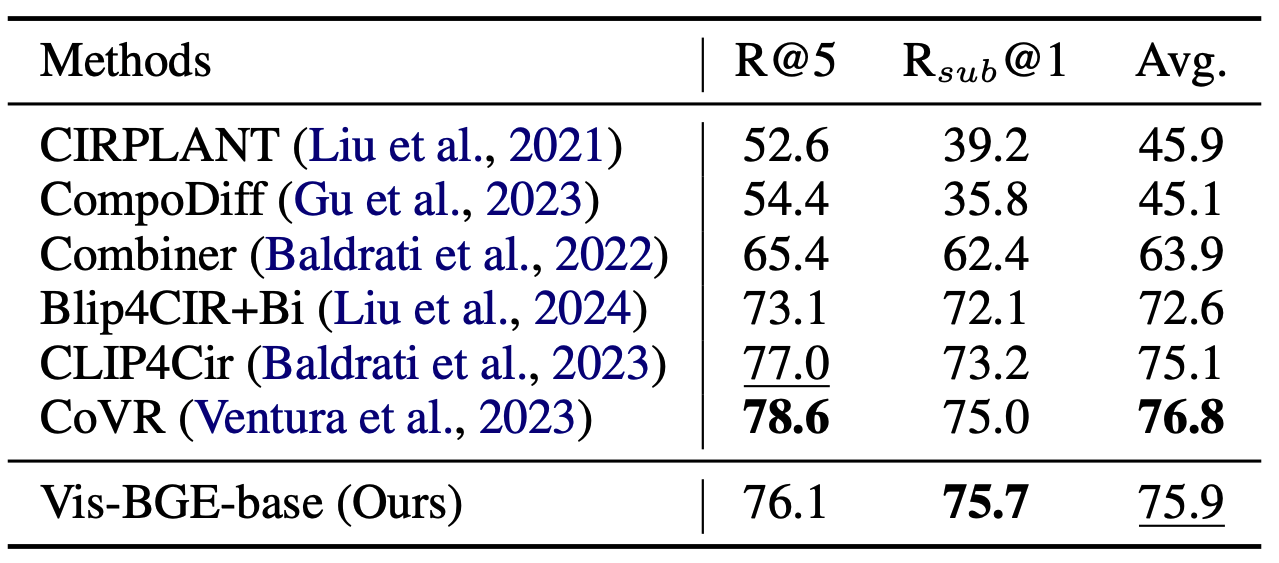
- Supervised fine-tuning performance on the CIRR test set.
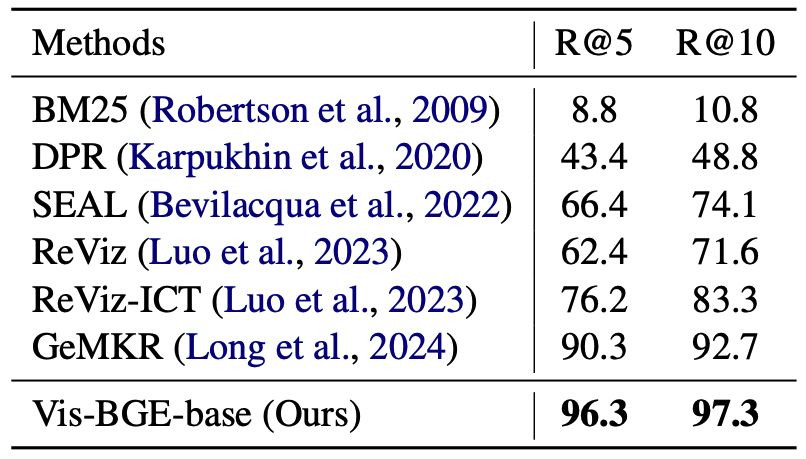
- Supervised fine-tuning performance on the ReMuQ test set.



FAQ
Q1: Can Visualized BGE be used for cross-modal retrieval (text to image)?
A1: While it is technically possible, it's not the recommended use case. Our model focus on augmenting hybrid modal retrieval tasks with visual capabilities.
Acknowledgement
The image token embedding model in this project is built upon the foundations laid by EVA-CLIP.
Citation
If you find this repository useful, please consider giving a like and citation
Paper will be released soon