
Model Card for YOLOv8n_RD Multiple Record Detection Model
Model Description
The YOLOv8n_RD Record Detection model is designed to detect multiple records in scanned images of birth, death, and marriage certificates. This model enhances data processing by accurately identifying and detecting multiple records, facilitating quick extraction and further analysis.
Integrate this model into your document management systems for real-time, automated record detection and data extraction. For customization or integration assistance, contact us https://www.linkedin.com/in/bodhi108/ Your feedback is essential for improving the model's performance.
- Developed by: FATA_SCIENTISTS
- Model type: Object Detection
- Task: Record Detection in Images
Supported Labels
['records']
Uses
Direct Use
The YOLOv8n_RD Record Detection model can be directly integrated into document management systems to provide real-time detection and classification of multiple records in scanned images of birth, death, and marriage certificates. This facilitates quick data extraction and analysis.
Downstream Use
The model's real-time capabilities can be leveraged to automate data extraction processes, generate alerts for specific record detections, and enhance overall document processing efficiency.
Training data
The YOLOv8n_RD model was trained on a custom dataset consisting of annotated images of birth, death, and marriage records for training and validation.
Out-of-Scope Use
The model is not designed for unrelated object detection tasks or scenarios outside the scope of detecting multiple records in scanned images of vital records.
Bias, Risks, and Limitations
The YOLOv8n_RD Record Detection model may exhibit some limitations and biases:
- Performance may be affected by variations in image quality, document layout, and handwriting styles within scanned records.
- Poor quality scans or damaged documents may impact the model's accuracy and responsiveness.
- Record-specific anomalies not well-represented in the training data may pose challenges for detection.
Recommendations
Users should be aware of the model's limitations and potential biases. Thorough testing and validation within specific document processing environments are advised before deploying the model in production systems.
How to Get Started with the Model
To begin using the YOLOv8s_RD model for multiple record detection in an image, follow these steps:
pip install ultralytics==8.2.31
pip install opencv-python==4.8.0.76
- Load model and perform real-time prediction:
from ultralytics import YOLO
import os
import cv2
import matplotlib.pyplot as plt
model = YOLO("Bodhi108/Yolov8n_RD")
def detect_records(input_folder):
# Iterate over all images in the input folder
for filename in os.listdir(input_folder):
if filename.endswith(('.jpg', '.jpeg', '.png')):
img_path = os.path.join(input_folder, filename)
img = cv2.imread(img_path)
results = model(img)
for result in results:
if result.boxes.data.shape[0] > 0: # Check for detections
for i, box in enumerate(result.boxes.data.tolist()):
xmin, ymin, xmax, ymax, conf, cls = box
# Draw the bounding box on the image
cv2.rectangle(img, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (0, 255, 0), 5)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.title(f"Detections on {filename}")
plt.axis('off')
plt.show()
input_folder = 'your input image directory'
detect_records(input_folder)

Training Details
Training Data
The model is trained on a diverse dataset containing scanned images of birth, death, and marriage records, capturing various document layouts, handwriting styles, and conditions.
Training Procedure
The training process involves extensive computation and is conducted over multiple epochs. The model's weights are adjusted to minimize detection loss and optimize performance for accurate record detection in scanned images.
Metrics
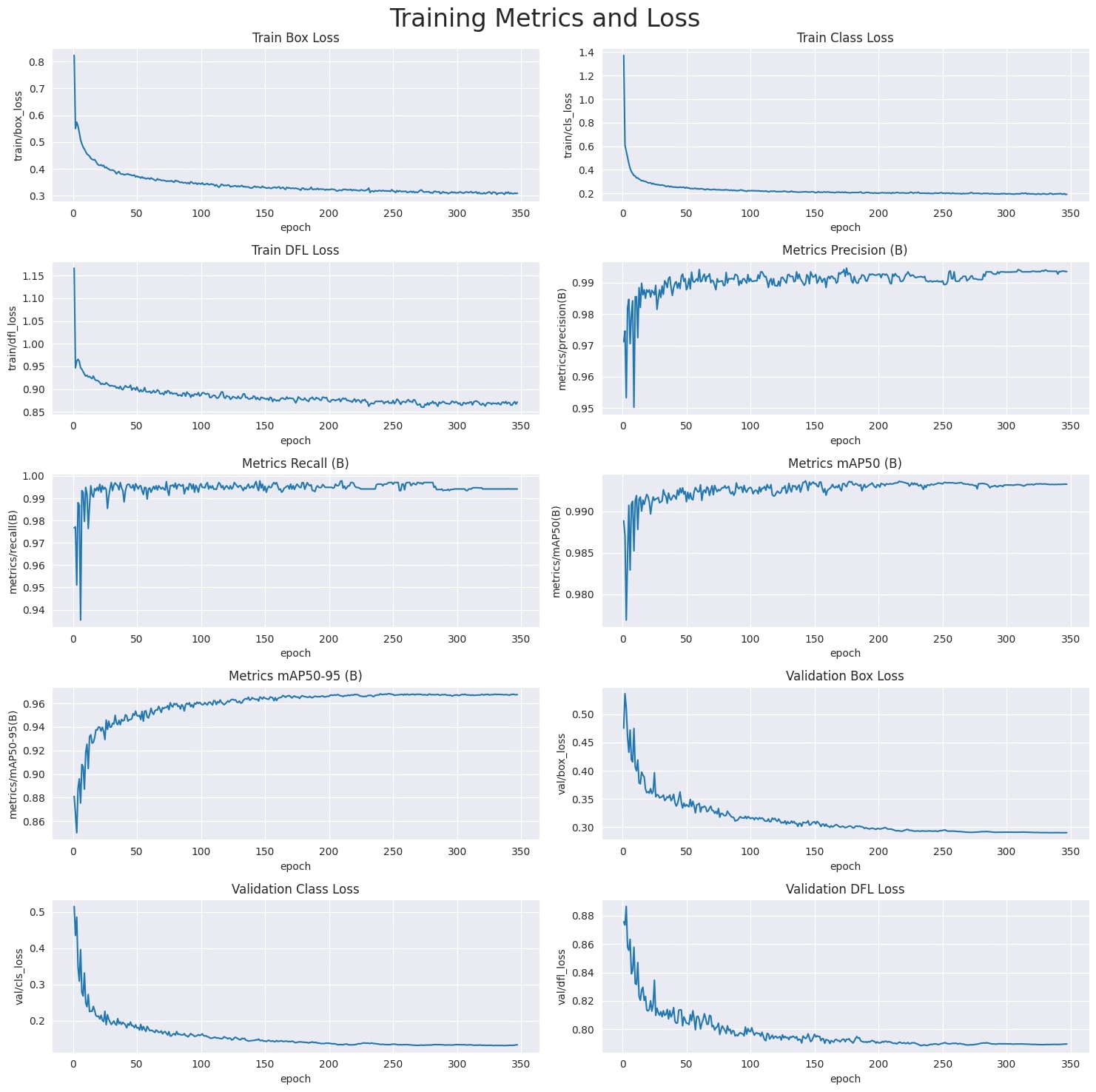
Model Architecture and Objective
The YOLOv8n_RD architecture incorporates modifications tailored to multiple record detections in an image. It integrates a self-attention mechanism in the head of the network and a feature pyramid network for multi-scaled object detection, enabling it to focus on various parts of an image and detect records of different sizes and scales
Compute Infrastructure
Hardware
NVIDIA GeForce RTX A6000 card
Software
The model was trained and fine-tuned using a Jupyter Notebook environment.
Model Card Contact
@ModelCard{
author = {Tonumoy Mukherjee, Kazi Mostaq Hridoy, and Aryadip Mridha},
title = {YOLOv8n Multi-Record Detection in an image},
year = {2024}
}
- Downloads last month
- 48