
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct (RLEIF)
🤗 HF Repo •🐱 Github Repo • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 Join our Discord
| Model | Checkpoint | Paper | HumanEval | MBPP | Demo | License |
|---|---|---|---|---|---|---|
| WizardCoder-Python-34B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 73.2 | 61.2 | Demo | Llama2 |
| WizardCoder-15B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 59.8 | 50.6 | -- | OpenRAIL-M |
| WizardCoder-Python-13B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 64.0 | 55.6 | -- | Llama2 |
| WizardCoder-Python-7B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 55.5 | 51.6 | Demo | Llama2 |
| WizardCoder-3B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 34.8 | 37.4 | -- | OpenRAIL-M |
| WizardCoder-1B-V1.0 | 🤗 HF Link | 📃 [WizardCoder] | 23.8 | 28.6 | -- | OpenRAIL-M |
| Model | Checkpoint | Paper | GSM8k | MATH | Online Demo | License |
|---|---|---|---|---|---|---|
| WizardMath-70B-V1.0 | 🤗 HF Link | 📃 [WizardMath] | 81.6 | 22.7 | Demo | Llama 2 |
| WizardMath-13B-V1.0 | 🤗 HF Link | 📃 [WizardMath] | 63.9 | 14.0 | Demo | Llama 2 |
| WizardMath-7B-V1.0 | 🤗 HF Link | 📃 [WizardMath] | 54.9 | 10.7 | Demo | Llama 2 |
| Model | Checkpoint | Paper | MT-Bench | AlpacaEval | GSM8k | HumanEval | License |
|---|---|---|---|---|---|---|---|
| WizardLM-70B-V1.0 | 🤗 HF Link | 📃Coming Soon | 7.78 | 92.91% | 77.6% | 50.6 pass@1 | Llama 2 License |
| WizardLM-13B-V1.2 | 🤗 HF Link | 7.06 | 89.17% | 55.3% | 36.6 pass@1 | Llama 2 License | |
| WizardLM-13B-V1.1 | 🤗 HF Link | 6.76 | 86.32% | 25.0 pass@1 | Non-commercial | ||
| WizardLM-30B-V1.0 | 🤗 HF Link | 7.01 | 37.8 pass@1 | Non-commercial | |||
| WizardLM-13B-V1.0 | 🤗 HF Link | 6.35 | 75.31% | 24.0 pass@1 | Non-commercial | ||
| WizardLM-7B-V1.0 | 🤗 HF Link | 📃 [WizardLM] | 19.1 pass@1 | Non-commercial | |||
Github Repo: https://github.com/nlpxucan/WizardLM/tree/main/WizardMath
Twitter: https://twitter.com/WizardLM_AI/status/1689998428200112128
Discord: https://discord.gg/VZjjHtWrKs
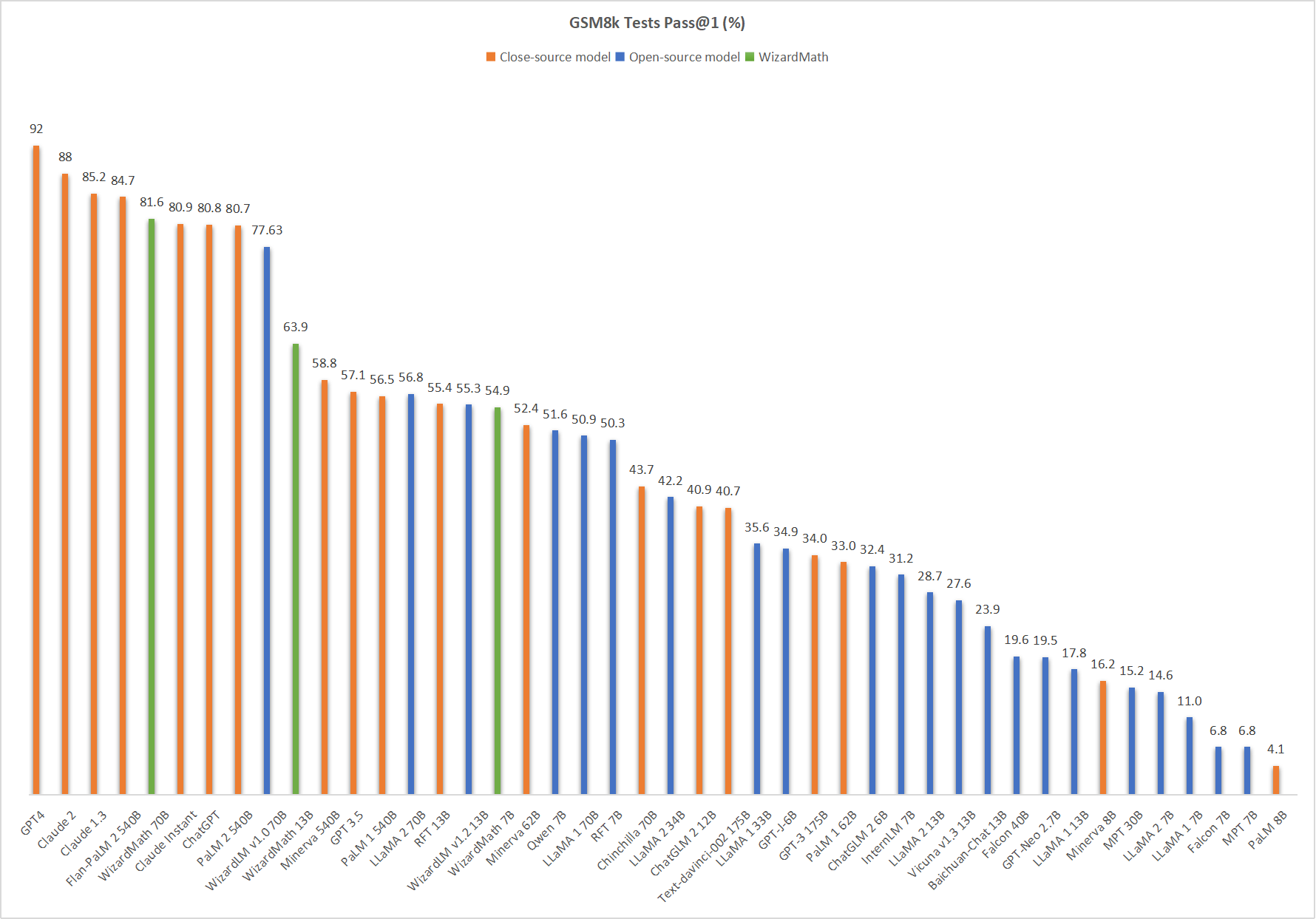
Comparing WizardMath-V1.0 with Other LLMs.
🔥 The following figure shows that our WizardMath-70B-V1.0 attains the fifth position in this benchmark, surpassing ChatGPT (81.6 vs. 80.8) , Claude Instant (81.6 vs. 80.9), PaLM 2 540B (81.6 vs. 80.7).
❗Note for model system prompts usage:
Please use the same systems prompts strictly with us, and we do not guarantee the accuracy of the quantified versions.
Default version:
"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"
CoT Version: (❗For the simple math questions, we do NOT recommend to use the CoT prompt.)
"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response: Let's think step by step."
Inference WizardMath Demo Script
We provide the WizardMath inference demo code here.
❗To commen concern about dataset:
Recently, there have been clear changes in the open-source policy and regulations of our overall organization's code, data, and models. Despite this, we have still worked hard to obtain opening the weights of the model first, but the data involves stricter auditing and is in review with our legal team . Our researchers have no authority to publicly release them without authorization. Thank you for your understanding.
Citation
Please cite the repo if you use the data, method or code in this repo.
@article{luo2023wizardmath,
title={WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct},
author={Luo, Haipeng and Sun, Qingfeng and Xu, Can and Zhao, Pu and Lou, Jianguang and Tao, Chongyang and Geng, Xiubo and Lin, Qingwei and Chen, Shifeng and Zhang, Dongmei},
journal={arXiv preprint arXiv:2308.09583},
year={2023}
}
- Downloads last month
- 6