
Search Query Parsing
Collection
All models and datasets related to the Zero-Shot Search Query Parsing task.
•
6 items
•
Updated
EmbeddingStudio is the open-source framework, that allows you transform a joint "Embedding Model + Vector DB" into a full-cycle search engine: collect clickstream -> improve search experience-> adapt embedding model and repeat out of the box.
It's a highly rare case when a company will use unstructured search as is. And by searching brick red houses san francisco area for april
user definitely wants to find some houses in San Francisco for a month-long rent in April, and then maybe brick-red houses.
Unfortunately, for the 15th January 2024 there is no such accurate embedding model. So, companies need to mix structured and unstructured search.
The very first step of mixing it - to parse a search query. Usual approaches are:
It takes some time to do, but at the end you can get controllable and very accurate query parser.
EmbeddingStudio team decided to dive into LLM instruct fine-tuning for Zero-Shot query parsing task
to close the first gap while a company doesn't have any rules and data being collected, or even eliminate exhausted rules implementation, but in the future.
The main idea is to align an LLM to being to parse short search queries knowing just a company market and a schema of search filters. Moreover, being oriented on applied NLP,
we are trying to serve only light-weight LLMs a.k.a not heavier than 7B parameters.
This is only Falcon-7B-Instruct aligned to follow instructions like:
### System: Master in Query Analysis
### Instruction: Organize queries in JSON, adhere to schema, verify spelling.
#### Category: Logistics and Supply Chain Management
#### Schema: ```[{"Name": "Customer_Ratings", "Representations": [{"Name": "Exact_Rating", "Type": "float", "Examples": [4.5, 3.2, 5.0, "4.5", "Unstructured"]}, {"Name": "Minimum_Rating", "Type": "float", "Examples": [4.0, 3.0, 5.0, "4.5"]}, {"Name": "Star_Rating", "Type": "int", "Examples": [4, 3, 5], "Enum": [1, 2, 3, 4, 5]}]}, {"Name": "Date", "Representations": [{"Name": "Day_Month_Year", "Type": "str", "Examples": ["01.01.2024", "15.06.2023", "31.12.2022", "25.12.2021", "20.07.2024", "15.06.2023"], "Pattern": "dd.mm.YYYY"}, {"Name": "Day_Name", "Type": "str", "Examples": ["Monday", "Wednesday", "Friday", "Thursday", "Monday", "Tuesday"], "Enum": ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]}]}, {"Name": "Date_Period", "Representations": [{"Name": "Specific_Period", "Type": "str", "Examples": ["01.01.2024 - 31.01.2024", "01.06.2023 - 30.06.2023", "01.12.2022 - 31.12.2022"], "Pattern": "dd.mm.YYYY - dd.mm.YYYY"}, {"Name": "Month", "Type": "str", "Examples": ["January", "June", "December"], "Enum": ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]}, {"Name": "Quarter", "Type": "str", "Examples": ["Q1", "Q2", "Q3"], "Enum": ["Q1", "Q2", "Q3", "Q4"]}, {"Name": "Season", "Type": "str", "Examples": ["Winter", "Summer", "Autumn"], "Enum": ["Winter", "Spring", "Summer", "Autumn"]}]}, {"Name": "Destination_Country", "Representations": [{"Name": "Country_Name", "Type": "str", "Examples": ["United States", "Germany", "China"]}, {"Name": "Country_Code", "Type": "str", "Examples": ["US", "DE", "CN"]}, {"Name": "Country_Abbreviation", "Type": "str", "Examples": ["USA", "GER", "CHN"]}]}]```
#### Query: Which logistics companies in the US have a perfect 5.0 rating ?
### Response:
[{"Value": "Which logistics companies in the US have a perfect 5.0 rating?", "Name": "Correct"}, {"Name": "Customer_Ratings.Exact_Rating", "Value": 5.0}, {"Name": "Destination_Country.Country_Code", "Value": "US"}]
Important: Additionally, we are trying to fine-tune the Large Language Model (LLM) to not only parse unstructured search queries but also to correct spelling.
max_seq_length = 2048 Disclaimer: As a small startup, this direction forms a part of our Minimum Viable Product (MVP). It's more of an attempt to test the 'product-market fit' rather than a well-structured scientific endeavor. Once we check it and go with a round, we definitely will:
We acknowledge the complexity involved in utilizing Large Language Models, particularly in the context
of Zero-Shot search query parsing and AI Alignment. Given the intricate nature of this technology, we emphasize the importance of rigorous verification.
Until our work is thoroughly reviewed, we recommend being cautious and critical of the results.
We strongly recommend only the direct usage of this fine-tuned version of Falcon-7B-Instruct:
For any other needs the behaviour of the model in unpredictable, please utilize the original mode or fine-tune your own.
### System: Master in Query Analysis
### Instruction: Organize queries in JSON, adhere to schema, verify spelling.
#### Category: {your_company_category}
#### Schema: ```{filters_schema}```
#### Query: {query}
### Response:
Filters schema is JSON-readable line in the format (we highly recommend you to use it): List of filters (dict):
Example:
[{"Name": "Customer_Ratings", "Representations": [{"Name": "Exact_Rating", "Type": "float", "Examples": [4.5, 3.2, 5.0, "4.5", "Unstructured"]}, {"Name": "Minimum_Rating", "Type": "float", "Examples": [4.0, 3.0, 5.0, "4.5"]}, {"Name": "Star_Rating", "Type": "int", "Examples": [4, 3, 5], "Enum": [1, 2, 3, 4, 5]}]}, {"Name": "Date", "Representations": [{"Name": "Day_Month_Year", "Type": "str", "Examples": ["01.01.2024", "15.06.2023", "31.12.2022", "25.12.2021", "20.07.2024", "15.06.2023"], "Pattern": "dd.mm.YYYY"}, {"Name": "Day_Name", "Type": "str", "Examples": ["Monday", "Wednesday", "Friday", "Thursday", "Monday", "Tuesday"], "Enum": ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]}]}, {"Name": "Date_Period", "Representations": [{"Name": "Specific_Period", "Type": "str", "Examples": ["01.01.2024 - 31.01.2024", "01.06.2023 - 30.06.2023", "01.12.2022 - 31.12.2022"], "Pattern": "dd.mm.YYYY - dd.mm.YYYY"}, {"Name": "Month", "Type": "str", "Examples": ["January", "June", "December"], "Enum": ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]}, {"Name": "Quarter", "Type": "str", "Examples": ["Q1", "Q2", "Q3"], "Enum": ["Q1", "Q2", "Q3", "Q4"]}, {"Name": "Season", "Type": "str", "Examples": ["Winter", "Summer", "Autumn"], "Enum": ["Winter", "Spring", "Summer", "Autumn"]}]}, {"Name": "Destination_Country", "Representations": [{"Name": "Country_Name", "Type": "str", "Examples": ["United States", "Germany", "China"]}, {"Name": "Country_Code", "Type": "str", "Examples": ["US", "DE", "CN"]}, {"Name": "Country_Abbreviation", "Type": "str", "Examples": ["USA", "GER", "CHN"]}]}]
As the result, response will be JSON-readable line in the format:
[{"Value": "Corrected search phrase", "Name": "Correct"}, {"Name": "filter-name.representation", "Value": "some-value"}]
Field and representation names will be aligned with the provided schema. Example:
[{"Value": "Which logistics companies in the US have a perfect 5.0 rating?", "Name": "Correct"}, {"Name": "Customer_Ratings.Exact_Rating", "Value": 5.0}, {"Name": "Destination_Country.Country_Code", "Value": "US"}]
Used for fine-tuning system phrases:
[
"Expert at Deconstructing Search Queries",
"Master in Query Analysis",
"Premier Search Query Interpreter",
"Advanced Search Query Decoder",
"Search Query Parsing Genius",
"Search Query Parsing Wizard",
"Unrivaled Query Parsing Mechanism",
"Search Query Parsing Virtuoso",
"Query Parsing Maestro",
"Ace of Search Query Structuring"
]
Used for fine-tuning instruction phrases:
[
"Convert queries to JSON, align with schema, ensure correct spelling.",
"Analyze and structure queries in JSON, maintain schema, check spelling.",
"Organize queries in JSON, adhere to schema, verify spelling.",
"Decode queries to JSON, follow schema, correct spelling.",
"Parse queries to JSON, match schema, spell correctly.",
"Transform queries to structured JSON, align with schema and spelling.",
"Restructure queries in JSON, comply with schema, accurate spelling.",
"Rearrange queries in JSON, strict schema adherence, maintain spelling.",
"Harmonize queries with JSON schema, ensure spelling accuracy.",
"Efficient JSON conversion of queries, schema compliance, correct spelling."
]
import json
from json import JSONDecodeError
from transformers import AutoTokenizer, AutoModelForCausalLM
INSTRUCTION_TEMPLATE = """
### System: Master in Query Analysis
### Instruction: Organize queries in JSON, adhere to schema, verify spelling.
#### Category: {0}
#### Schema: ```{1}```
#### Query: {2}
### Response:
"""
def parse(
query: str,
company_category: str,
filter_schema: dict,
model: AutoModelForCausalLM,
tokenizer: AutoTokenizer
):
input_text = INSTRUCTION_TEMPLATE.format(
company_category,
json.dumps(filter_schema),
query
)
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# Generating text
output = model.generate(input_ids.to('cuda'),
max_new_tokens=1024,
do_sample=True,
temperature=0.05,
pad_token_id=50256
)
try:
parsed = json.loads(tokenizer.decode(output[0], skip_special_tokens=True).split('## Response:\n')[-1])
except JSONDecodeError as e:
parsed = dict()
return parsed
Again, this model was fine-tuned for following the zero-shot query parsing instructions. So, all ethical biases are inherited by the original model.
Model was fine-tuned to be able to work with the unknown company domain and filters schema. But, can be better with the training company categories:
Educational Institutions, Job Recruitment Agencies, Banking Services, Investment Services, Insurance Services, Financial Planning and Advisory, Credit Services, Payment Processing, Mortgage and Real Estate Services, Taxation Services, Risk Management and Compliance, Digital and Mobile Banking, Retail Stores (Online and Offline), Automotive Dealerships, Restaurants and Food Delivery Services, Entertainment and Media Platforms, Government Services, Travelers and Consumers, Logistics and Supply Chain Management, Customer Support Services, Market Research Firms, Mobile App Development, Game Development, Cloud Computing Services, Data Analytics and Business Intelligence, Cybersecurity Software, User Interface/User Experience Design, Internet of Things (IoT) Development, Project Management Tools, Version Control Systems, Continuous Integration/Continuous Deployment, Issue Tracking and Bug Reporting, Collaborative Development Environments, Team Communication and Chat Tools, Task and Time Management, Customer Support and Feedback, Cloud-based Development Environments, Image Stock Platforms, Video Hosting and Portals, Social Networks, Professional Social Networks, Dating Apps
Known limitations:
1-2 -> 1 - 2.5 -> 5 years.<>= and theirs HTML versions <, >, &eq;..0 for floats and integers.0 or remove 0 for integers with a char postfix: 10M -> 1m.list of positions exactly 7 openings available result can be
{'Name': 'Job_Type.Exact_Match', 'Value': 'Full Time'}.The list will be extended in the future.
Use the code below to get started with the model.
MODEL_ID = 'EmbeddingStudio/query-parser-falcon-7b-instruct'
Initialize tokenizer:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
MODEL_ID,
trust_remote_code=True,
add_prefix_space=True,
use_fast=False,
)
Initialize model:
import torch
from peft import LoraConfig
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
load_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
device_map = {"": 0}
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
quantization_config=bnb_config,
device_map=device_map,
torch_dtype=torch.float16
)
Use for parsing:
import json
from json import JSONDecodeError
INSTRUCTION_TEMPLATE = """
### System: Master in Query Analysis
### Instruction: Organize queries in JSON, adhere to schema, verify spelling.
#### Category: {0}
#### Schema: ```{1}```
#### Query: {2}
### Response:
"""
def parse(
query: str,
company_category: str,
filter_schema: dict,
model: AutoModelForCausalLM,
tokenizer: AutoTokenizer
):
input_text = INSTRUCTION_TEMPLATE.format(
company_category,
json.dumps(filter_schema),
query
)
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# Generating text
output = model.generate(input_ids.to('cuda'),
max_new_tokens=1024,
do_sample=True,
temperature=0.05,
pad_token_id=50256
)
try:
parsed = json.loads(tokenizer.decode(output[0], skip_special_tokens=True).split('## Response:\n')[-1])
except JSONDecodeError as e:
parsed = dict()
return parsed
category = 'Logistics and Supply Chain Management'
query = 'Which logistics companies in the US have a perfect 5.0 rating ?'
schema = [{"Name": "Customer_Ratings", "Representations": [{"Name": "Exact_Rating", "Type": "float", "Examples": [4.5, 3.2, 5.0, "4.5", "Unstructured"]}, {"Name": "Minimum_Rating", "Type": "float", "Examples": [4.0, 3.0, 5.0, "4.5"]}, {"Name": "Star_Rating", "Type": "int", "Examples": [4, 3, 5], "Enum": [1, 2, 3, 4, 5]}]}, {"Name": "Date", "Representations": [{"Name": "Day_Month_Year", "Type": "str", "Examples": ["01.01.2024", "15.06.2023", "31.12.2022", "25.12.2021", "20.07.2024", "15.06.2023"], "Pattern": "dd.mm.YYYY"}, {"Name": "Day_Name", "Type": "str", "Examples": ["Monday", "Wednesday", "Friday", "Thursday", "Monday", "Tuesday"], "Enum": ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]}]}, {"Name": "Date_Period", "Representations": [{"Name": "Specific_Period", "Type": "str", "Examples": ["01.01.2024 - 31.01.2024", "01.06.2023 - 30.06.2023", "01.12.2022 - 31.12.2022"], "Pattern": "dd.mm.YYYY - dd.mm.YYYY"}, {"Name": "Month", "Type": "str", "Examples": ["January", "June", "December"], "Enum": ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]}, {"Name": "Quarter", "Type": "str", "Examples": ["Q1", "Q2", "Q3"], "Enum": ["Q1", "Q2", "Q3", "Q4"]}, {"Name": "Season", "Type": "str", "Examples": ["Winter", "Summer", "Autumn"], "Enum": ["Winter", "Spring", "Summer", "Autumn"]}]}, {"Name": "Destination_Country", "Representations": [{"Name": "Country_Name", "Type": "str", "Examples": ["United States", "Germany", "China"]}, {"Name": "Country_Code", "Type": "str", "Examples": ["US", "DE", "CN"]}, {"Name": "Country_Abbreviation", "Type": "str", "Examples": ["USA", "GER", "CHN"]}]}]
output = parse(query, category, schema)
print(output)
# [out]: [{"Value": "Which logistics companies in the US have a perfect 5.0 rating?", "Name": "Correct"}, {"Name": "Customer_Ratings.Exact_Rating", "Value": 5.0}, {"Name": "Destination_Country.Country_Code", "Value": "US"}]
We used synthetically generated query parsing instructions:
Warning: EmbeddingStudio team aware you that generated queries weren't enough curated, and will be curated later once we finish our product market fit stage.
As we are trying to fine-tune LLM to follow zero-shot query parsing instructions, so we want to test:
For these purposes we:
Telecommunication Companies, Legal Services, Enterprise Software Development, Artificial Intelligence and Machine Learning, Documentation and Knowledge Sharing.We used GPT-4 Turbo to generate several possible filters for 63 company categroies. For each filter we also generated some possible representations. For examples filter Date can be represented as dd/mm/YYYY, YYYY-mm-dd, as words 2024 Jan 17, etc.
We also used GPT-4 Turbo for generation of search queries and theirs parsed version. Main principles were:
For the generation instructions we used following ideas:
Zero-Shot query parser should be schema agnostic. Cases like snake_case, CamelCase, http-headers-like should not ruin generation process.
Zero-Shot query parser should be spelling errors insensitive.
Training instructions should be in the following order:
So LLM can be used in the following way: just generate embedding of category -> schema part, so inference will be faster.
We assume, that schema agnostic termin means something wider, like to be able to work not only with JSONs, but also with HTML, Markdown, YAML, etc. We are working on it.
So, what was our approach as an attempt to achieve these abilities:
Correct, which contains a corrected version of a search query.Warning: EmbeddingStudio team ask you to curate datasets on your own precisely.
All details in Training Hyperparameters
The preprocessing steps are not detailed in the provided code. Typically, preprocessing involves tokenization, normalization, data augmentation, and handling of special tokens. In this training setup, the tokenizer was configured with add_prefix_space=True and use_fast=False, which might indicate special considerations for tokenizing certain languages or text formats.
| Hyperparameter | Value | Description |
|---|---|---|
| Training Regime | Mixed Precision (bfloat16) | Utilizes bfloat16 for efficient memory usage and training speed. |
| Model Configuration | Causal Language Model | Incorporates LoRA (Low-Rank Adaptation) for training efficiency. |
| Quantization Configuration | Bits and Bytes (BnB) | Uses settings like load_in_4bit and bnb_4bit_quant_type for model quantization. |
| Training Environment | CUDA-enabled Device | Indicates GPU acceleration for training. |
| Learning Rate | 2e-4 | Determines the step size at each iteration while moving toward a minimum of a loss function. |
| Weight Decay | 0.001 | Helps in regularizing and preventing overfitting. |
| Warmup Ratio | 0.03 | Fraction of total training steps used for the learning rate warmup. |
| Optimizer | Paged AdamW (32-bit) | Optimizes the training process with efficient memory usage. |
| Gradient Accumulation Steps | 2 | Reduces memory consumption and allows for larger effective batch sizes. |
| Max Grad Norm | 0.3 | Maximum norm for the gradients. |
| LR Scheduler Type | Cosine | Specifies the learning rate schedule. |
| PEFT Configurations | LoraConfig | Details like lora_alpha, lora_dropout, and r for LoRA adaptations. |
| Training Dataset Segmentation | Train and Test Sets | Segmentation of the dataset for training and evaluation. |
| Max Sequence Length | 1024 | Maximum length of the input sequences. |
All information is provided in Training Data section.
Results of testing procedure as JSON is provided here.
This is a list of items, each item is:
Our zero-shot search query parsing model is designed to extract structured information from unstructured search queries with high precision. The primary metric for evaluating our model's performance is the True Positive (TP) rate, which is assessed using a specialized token-wise Levenshtein distance. This approach is aligned with our goal to achieve semantic accuracy in parsing user queries.
levenshtein_tokenwise function, which calculates the distance between predicted and actual key-value pairs at a token level. We consider a Levenshtein distance of 0.25 or less as acceptable for matching.| Category | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|
| Telecommunication Companies [+] | 0.70 | 0.67 | 0.68 | 0.52 |
| Legal Services [+] | 0.80 | 0.74 | 0.77 | 0.63 |
| Enterprise Software Development [+] | 0.78 | 0.71 | 0.74 | 0.59 |
| Artificial Intelligence and Machine Learning [+] | 0.77 | 0.78 | 0.78 | 0.63 |
| Documentation and Knowledge Sharing [+] | 0.68 | 0.65 | 0.66 | 0.50 |
| Educational Institutions | 0.55 | 0.51 | 0.53 | 0.36 |
| Job Recruitment Agencies | 0.58 | 0.51 | 0.54 | 0.37 |
| Banking Services | 0.73 | 0.81 | 0.76 | 0.62 |
| Investment Services | 0.50 | 0.50 | 0.50 | 0.33 |
| Insurance Services | 0.77 | 0.77 | 0.77 | 0.62 |
| Financial Planning and Advisory | 0.65 | 0.67 | 0.66 | 0.49 |
| Credit Services | 0.60 | 0.65 | 0.63 | 0.45 |
| Payment Processing | 0.79 | 0.74 | 0.76 | 0.62 |
| Mortgage and Real Estate Services | 1.00 | 1.00 | 1.00 | 1.00 |
| Taxation Services | 0.52 | 0.57 | 0.54 | 0.37 |
| Risk Management and Compliance | 1.00 | 0.95 | 0.98 | 0.95 |
| Digital and Mobile Banking | 0.72 | 0.71 | 0.71 | 0.55 |
| Retail Stores (Online and Offline) | 0.96 | 0.87 | 0.92 | 0.85 |
| Automotive Dealerships | 0.52 | 0.53 | 0.53 | 0.36 |
| Restaurants and Food Delivery Services | 0.76 | 0.77 | 0.76 | 0.62 |
| Entertainment and Media Platforms | 0.80 | 0.84 | 0.82 | 0.70 |
| Government Services | 0.58 | 0.65 | 0.61 | 0.44 |
| Travelers and Consumers | 0.89 | 0.89 | 0.89 | 0.80 |
| Logistics and Supply Chain Management | 0.56 | 0.59 | 0.58 | 0.41 |
| Customer Support Services | 0.60 | 0.54 | 0.57 | 0.40 |
| Market Research Firms | 0.52 | 0.49 | 0.51 | 0.34 |
| Mobile App Development | 0.81 | 0.79 | 0.80 | 0.67 |
| Game Development | 0.94 | 0.94 | 0.94 | 0.88 |
| Cloud Computing Services | 0.64 | 0.62 | 0.63 | 0.46 |
| Data Analytics and Business Intelligence | 0.63 | 0.61 | 0.62 | 0.45 |
| Cybersecurity Software | 0.54 | 0.59 | 0.57 | 0.39 |
| User Interface/User Experience Design | 0.63 | 0.64 | 0.63 | 0.46 |
| Internet of Things (IoT) Development | 0.89 | 0.71 | 0.79 | 0.65 |
| Project Management Tools | 0.80 | 0.83 | 0.81 | 0.69 |
| Version Control Systems | 0.77 | 0.73 | 0.75 | 0.60 |
| Continuous Integration/Continuous Deployment | 0.85 | 0.83 | 0.84 | 0.72 |
| Issue Tracking and Bug Reporting | 0.64 | 0.62 | 0.63 | 0.46 |
| Collaborative Development Environments | 0.68 | 0.67 | 0.68 | 0.51 |
| Team Communication and Chat Tools | 0.94 | 0.91 | 0.93 | 0.87 |
| Task and Time Management | 0.78 | 0.78 | 0.78 | 0.64 |
| Customer Support and Feedback | 0.88 | 0.82 | 0.85 | 0.74 |
| Cloud-based Development Environments | 0.81 | 0.81 | 0.81 | 0.68 |
| Image Stock Platforms | 0.88 | 0.85 | 0.87 | 0.76 |
| Video Hosting and Portals | 0.86 | 0.88 | 0.87 | 0.77 |
| Social Networks | 0.60 | 0.57 | 0.59 | 0.41 |
| Professional Social Networks | 0.68 | 0.69 | 0.68 | 0.52 |
| Dating Apps | 0.90 | 0.90 | 0.90 | 0.82 |
| Aggregate | 0.73 | 0.72 | 0.73 | 0.59 |
| Category | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|
| Telecommunication Companies [+] | 0.70 | 0.67 | 0.68 | 0.52 |
| Legal Services [+] | 0.80 | 0.74 | 0.77 | 0.63 |
| Enterprise Software Development [+] | 0.78 | 0.71 | 0.74 | 0.59 |
| Artificial Intelligence and Machine Learning [+] | 0.77 | 0.78 | 0.78 | 0.63 |
| Documentation and Knowledge Sharing [+] | 0.68 | 0.65 | 0.66 | 0.50 |
| Aggregate | 0.75 | 0.71 | 0.73 | 0.57 |
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
load_in_4bit and bnb_4bit_quant_type for model quantization.[To be added]
[To be added]
EmbeddingStudio is an innovative open-source framework designed to seamlessly convert a combined "Embedding Model + Vector DB" into a comprehensive search engine. With built-in functionalities for clickstream collection, continuous improvement of search experiences, and automatic adaptation of the embedding model, it offers an out-of-the-box solution for a full-cycle search engine.
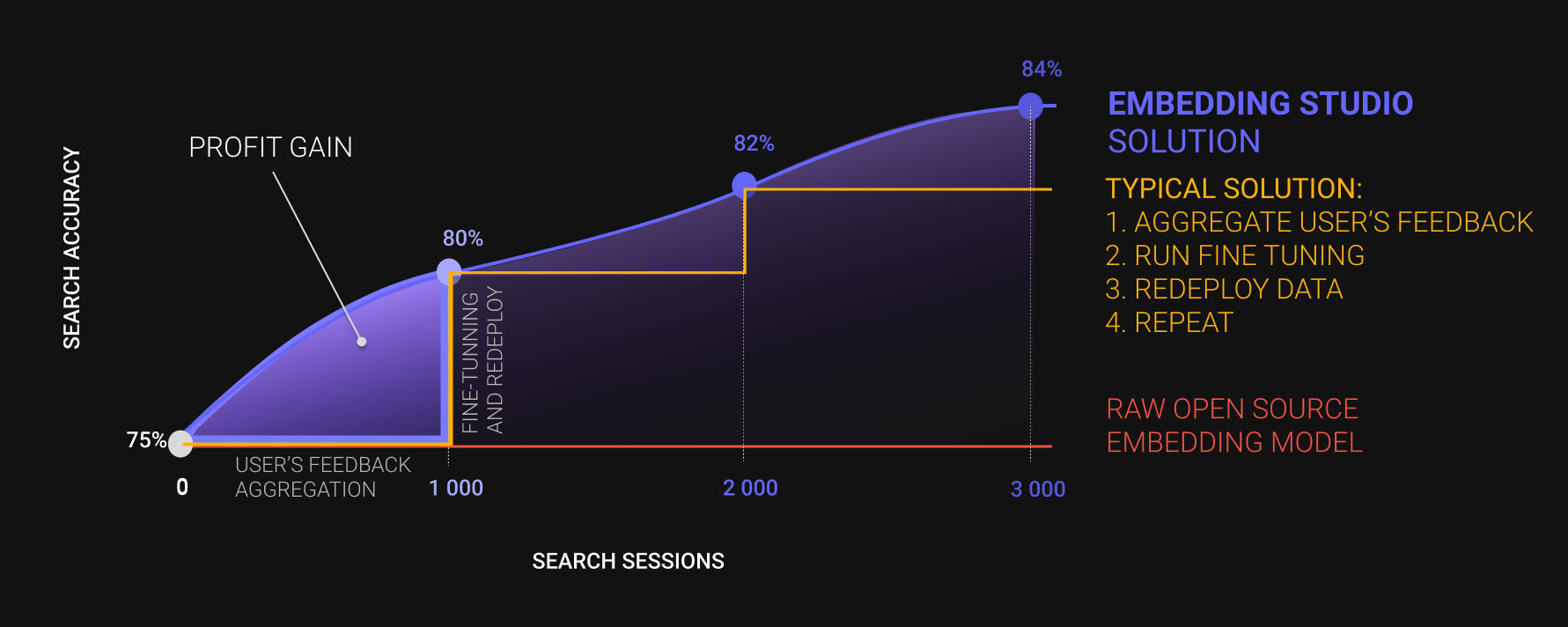
(*) - features in development
EmbeddingStudio is highly customizable, so you can bring your own:
For more details visit GitHub Repo.