
MiniMA Family
Collection
The model family derived from MiniMA
•
9 items
•
Updated
•
1
📑 arXiv | 👻 GitHub | 🤗 HuggingFace-MiniMA | 🤗 HuggingFace-MiniChat | 🤖 ModelScope-MiniMA | 🤖 ModelScope-MiniChat | 🤗 HuggingFace-MiniChat-1.5 | 🤗 HuggingFace-MiniMA-2 | 🤗 HuggingFace-MiniChat-2
🆕 Updates from MiniMA-3B:
❗ Must comply with LICENSE of LLaMA-2 since it is derived from LLaMA-2.
A language model continued from MiniMA-3B.
Completing the compute-performance pareto frontier together with MiniMA-3B and other arts.
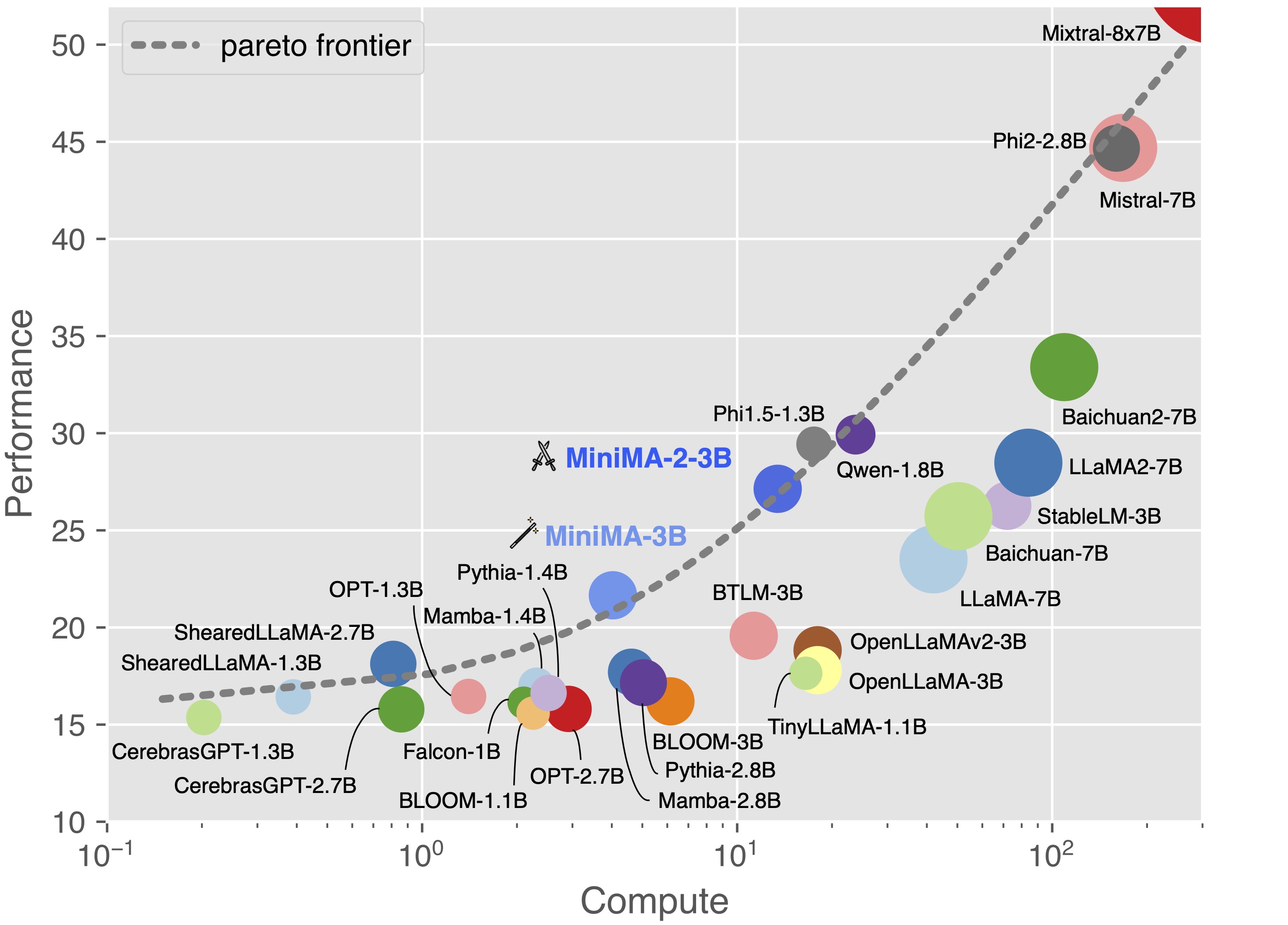
Standard Benchmarks
| Method | TFLOPs | MMLU (5-shot) | CEval (5-shot) | DROP (3-shot) | HumanEval (0-shot) | BBH (3-shot) | GSM8K (8-shot) |
|---|---|---|---|---|---|---|---|
| Mamba-2.8B | 4.6E9 | 25.58 | 24.74 | 15.72 | 7.32 | 29.37 | 3.49 |
| ShearedLLaMA-2.7B | 0.8E9 | 26.97 | 22.88 | 19.98 | 4.88 | 30.48 | 3.56 |
| BTLM-3B | 11.3E9 | 27.20 | 26.00 | 17.84 | 10.98 | 30.87 | 4.55 |
| StableLM-3B | 72.0E9 | 44.75 | 31.05 | 22.35 | 15.85 | 32.59 | 10.99 |
| Qwen-1.8B | 23.8E9 | 44.05 | 54.75 | 12.97 | 14.02 | 30.80 | 22.97 |
| Phi-2-2.8B | 159.9E9 | 56.74 | 34.03 | 30.74 | 46.95 | 44.13 | 55.42 |
| LLaMA-2-7B | 84.0E9 | 46.00 | 34.40 | 31.57 | 12.80 | 32.02 | 14.10 |
| MiniMA-3B | 4.0E9 | 28.51 | 28.23 | 22.50 | 10.98 | 31.61 | 8.11 |
| MiniChat-3B | 4.0E9 | 38.40 | 36.48 | 22.58 | 18.29 | 31.36 | 29.72 |
| MiniMA-2-3B | 13.4E9 | 40.14 | 44.65 | 23.10 | 14.63 | 31.43 | 8.87 |
| MiniChat-2-3B | 13.4E9 | 46.17 | 43.91 | 30.26 | 22.56 | 34.95 | 38.13 |
The following is an example code snippet to use MiniMA-2-3B:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# MiniMA
tokenizer = AutoTokenizer.from_pretrained("GeneZC/MiniMA-2-3B", use_fast=False)
# GPU.
model = AutoModelForCausalLM.from_pretrained("GeneZC/MiniMA-2-3B", use_cache=True, device_map="auto", torch_dtype=torch.float16).eval()
# CPU.
# model = AutoModelForCausalLM.from_pretrained("GeneZC/MiniMA-2-3B", use_cache=True, device_map="cpu", torch_dtype=torch.float16).eval()
prompt = "Question: Sherrie tells the truth. Vernell says Sherrie tells the truth. Alexis says Vernell lies. Michaela says Alexis tells the truth. Elanor says Michaela tells the truth. Does Elanor tell the truth?\nAnswer: No\n\nQuestion: Kristian lies. Sherrie says Kristian lies. Delbert says Sherrie lies. Jerry says Delbert tells the truth. Shalonda says Jerry tells the truth. Does Shalonda tell the truth?\nAnswer: No\n\nQuestion: Vina tells the truth. Helene says Vina lies. Kandi says Helene tells the truth. Jamey says Kandi lies. Ka says Jamey lies. Does Ka tell the truth?\nAnswer: No\n\nQuestion: Christie tells the truth. Ka says Christie tells the truth. Delbert says Ka lies. Leda says Delbert tells the truth. Lorine says Leda tells the truth. Does Lorine tell the truth?\nAnswer:"
input_ids = tokenizer([prompt]).input_ids
output_ids = model.generate(
torch.as_tensor(input_ids).cuda(),
do_sample=True,
temperature=0.7,
max_new_tokens=1024,
)
output_ids = output_ids[0][len(input_ids[0]):]
output = tokenizer.decode(output_ids, skip_special_tokens=True).strip()
# output: "No"
@article{zhang2023law,
title={Towards the Law of Capacity Gap in Distilling Language Models},
author={Zhang, Chen and Song, Dawei and Ye, Zheyu and Gao, Yan},
year={2023},
url={https://arxiv.org/abs/2311.07052}
}
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 44.75 |
| AI2 Reasoning Challenge (25-Shot) | 44.71 |
| HellaSwag (10-Shot) | 69.33 |
| MMLU (5-Shot) | 41.22 |
| TruthfulQA (0-shot) | 38.44 |
| Winogrande (5-shot) | 66.69 |
| GSM8k (5-shot) | 8.11 |