

license: apache-2.0
K2-Chat: a fully-reproducible large language model outperforming Llama 2 70B Chat using 35% less compute
K2 Chat is finetuned from K2-65B. The most recent model update is 10/31/24.
In this release, we introduce function calling features and target improvements across math, coding, and safety.
We utilized the following datasets:
Results
| K2-Chat-060124 | K2-Chat | |
|---|---|---|
| Natural Language Benchmarks | ||
| MMLU (0-shot) | 63.5 | 69.14 |
| RACE (0-shot) | 46.1 | 46.60 |
| HellaSwag (10-shot) | 81.7 | 80.80 |
| PIQA (5-shot) | 82.3 | 81.34 |
| ARC-easy (5-shot) | 84.6 | 79.00 |
| ARC-challenge (25-shot) | 61.3 | 61.09 |
| OpenBookQA (5-shot) | 48.0 | 47.00 |
| Winogrande (5-shot) | 79.5 | 78.30 |
| TruthfulQA (0-shot) | 44.7 | 57.32 |
| CrowS-Pairs (0-shot) | 64.2 | 65.32 |
| GSM8K (5-shot) | 60.7 | 77.10 |
| MathQA (5-shot) | 44.8 | 43.12 |
| LogiQA2.0 (0-shot) | 38.0 | 36.83 |
| BBH CoT (0-shot) | 64.9 | 70.37 |
| Code Benchmarks | ||
| HumanEval (pass@1) | 47.9 | 71.20 |
| Domain Specific (Medical) | ||
| MedQA (0-shot) | 53.6 | 52.87 |
| MedMCQA (5-shot) | 51.3 | 50.71 |
| PubMedQA (0-shot) | 75.0 | 71.20 |
| Other | ||
| MT-Bench | 6.87 | 7.55 |
| JSON-Mode-Eval | 77.21 | 90.09 |
| Overall Average Score | ||
| Avg Score | 58.88 | 61.30 |
Safety
We developed a comprehensive safety prompt collection procedure that includes eight attack types and over 120 specific safety value categories. Our risk taxonomy is adapted from Wang et al. (2023), which originally defines six main types and 60 specific categories of harmful content. We have expanded this taxonomy to encompass more region-specific types, sensitive topics, and cybersecurity- related issues, ensuring a more nuanced and robust coverage of potential risks. This extended taxonomy allows us to address a wider variety of harmful behaviors and content that may be culturally or contextually specific, thus enhancing the model’s safety alignment across diverse scenarios.
| Category | K2-Chat-060124 | K2-Chat |
|---|---|---|
| DoNotAnswer | 67.94 | 87.65 |
| Advbench | 52.12 | 81.73 |
| I_cona | 67.98 | 79.21 |
| I_controversial | 47.50 | 70.00 |
| I_malicious_instructions | 60.00 | 83.00 |
| I_physical_safety_unsafe | 44.00 | 68.00 |
| I_physical_safety_safe | 96.00 | 97.00 |
| Harmbench | 20.50 | 63.50 |
| Spmisconception | 40.98 | 76.23 |
| MITRE | 3.20 | 57.30 |
| PromptInjection | 54.58 | 56.57 |
| Attack_multilingual_overload | 74.67 | 89.00 |
| Attack_persona_modulation | 51.67 | 85.67 |
| Attack_refusal_suppression | 56.00 | 93.00 |
| Attack_do_anything_now | 48.00 | 91.33 |
| Attack_conversation_completion | 56.33 | 71.00 |
| Attack_wrapped_in_shell | 34.00 | 67.00 |
| Average | 51.50 | 77.48 |
Function Calling
Chat Template
Our model reuses K2-Chat as the prompt format and is specifically trained for function calling. Different system prompts enable different ways to interact with this model. Note that the two modes are currently mainly tested individually, designing prompts that make them work togehter is possible but currently untested. It should be also possible to stimulate the model to produce function call behavior by injecting special token <tool_call> and expect the model to finish it. In this guide we mention the intended basic usage of the model.
Conversational Chats
Here is an example prompt with system instruction (Use whatever system prompt you like, this is just an example):
Your name is K2, and you are named after K2, the second highest mountain on Earth. You are built by MBZUAI and LLM360. You are a highly advanced large language model with 65B parameters. You outperform all fully open source models and Llama 2 70B. You can answer in English only. You are a helpful, respectful and honest assistant.<|endofsystemprompt|><|beginofuser|>Hello, who are you?<|beginofsystem|>
Sample inference code
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("<path_to_model_weights>")
model = AutoModelForCausalLM.from_pretrained("<path_to_model_weights>")
prompt = 'Your name is K2, and you are named after K2, the second highest mountain on Earth. You are built by MBZUAI and LLM360. You are a highly advanced large language model with 65B parameters. You outperform all fully open source models and Llama 2 70B. You can answer in English only. You are a helpful, respectful and honest assistant.<|endofsystemprompt|><|beginofuser|>Hello, who are you?<|beginofsystem|>'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
gen_tokens = model.generate(input_ids, do_sample=True, max_new_tokens=128)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
Multi-turn conversations should be formatted like this:
{system_prompt}<|endofsystemprompt|><|beginofuser|>{user_content_1}<|beginofsystem|>{system_content_1}<|beginofuser|>{user_content_2}<|beginofsystem|>{system_content_2}<|beginofuser|>{user_content_3}<|beginofsystem|>
Function Calling Format
For function calling, please use this system prompt:
You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools:
Next, use whatever tools you like, this is just an example:
<tools>
{ "name": "get_news_headlines", "description": "Get the latest news headlines", "parameters": {"type": "object", "properties": { "country": { "type": "string", "description": "The country for which to fetch news"}}, "required": [ "country"]}}
</tools>
Next, add additional instruction:
Use the following pydantic model json schema for each tool call you will make:
{"properties": {"arguments": {"title": "Arguments", "type": "object"}, "name": {"title": "Name", "type": "string"}}, "required": ["arguments", "name"], "title": "FunctionCall", "type": "object"}
For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
<tool_call>
{"arguments": <args-dict>, "name": <function-name>}
</tool_call>
Please also summarize texts wrapped between <tool_response> and </tool_response> in bullet points. For example:
<tool_response>
{"fruits": [{"name": "Apple"}, {"name": "Pear"}]}
</tool_response> is summarized as:
Fruits:
- Apple
- Pear
<|endofsystemprompt|>
The following is the model initial prompt:
You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools:
<tools>
{ "name": "get_news_headlines", "description": "Get the latest news headlines", "parameters": {"type": "object", "properties": { "country": { "type": "string", "description": "The country for which to fetch news"}}, "required": [ "country"]}}
</tools>
Use the following pydantic model json schema for each tool call you will make:
{"properties": {"arguments": {"title": "Arguments", "type": "object"}, "name": {"title": "Name", "type": "string"}}, "required": ["arguments", "name"], "title": "FunctionCall", "type": "object"}
For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
<tool_call>
{"arguments": <args-dict>, "name": <function-name>}
</tool_call>
Please also summarize texts wrapped between <tool_response> and </tool_response> in bullet points. For example:
<tool_response>
{"fruits": [{"name": "Apple"}, {"name": "Pear"}]}
</tool_response> is summarized as:
Fruits:
- Apple
- Pear
<|endofsystemprompt|>
Example flow for generation with multi-turn and how to incoporate function call output
When users ask a question, the following user query will be concatenated with the prompt (see example inference code below too) <|beginofuser|>Can you tell me the latest news headlines for the United States?<|beginofsystem|>
When run it, you will get a tool call response wrapped in the <tool_call> tag:
In this turn, the model should respond with:
<tool_call>
[{"name": "get_news_headlines", "arguments": {"country": "United States"}}]
</tool_call><endoftext>
Now you should execute this tool call with the external tool, you will get responses from that tool. The model can interpret the tool response as natural language again. To achieve this, simply wrap it with <tool_response> and </tool_response> and append it to the history and ask the model to generate further:
...current model history (ends with </tool_call><|endoftext|>)...
<tool_response>
{"news": [{"title": "A great news headline"}, {"title": "Another great news headline"}]}
</tool_response>
In this second turn, the model should respond with:
Suggested news headline:
- A great news headline
- Another great news headline<endoftext>
Sometimes, there is a use case that only uses the function call feature as a JSON formatter without calling any external functions, which means the output in tool_call is essentially what you want. In that case, we recommend simply make a copy of the content of <tool_call> and wrap that in <tool_response>.
Sample inference code
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("<path_to_model_weights>")
model = AutoModelForCausalLM.from_pretrained("<path_to_model_weights>")
prompt = """You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools:
<tools>
[{"name": "get_news_headlines", "description": "Get the latest news headlines", "parameters": {"type": "object", "properties": {"country": {"type": "string", "description": "The country for which to fetch news"}}, "required": ["country"] }}
</tools>
Use the following pydantic model json schema for each tool call you will make:
{"properties": {"arguments": {"title": "Arguments", "type": "object"}, "name": {"title": "Name", "type": "string"}}, "required": ["arguments", "name"], "title": "FunctionCall", "type": "object"}
For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
<tool_call>
{"arguments": <args-dict>, "name": <function-name>}
</tool_call>
Please also summarize texts wrapped between <tool_response> and </tool_response> in bullet points. For example:
<tool_response>
{"fruits": [{"name": "Apple"}, {"name": "Pear"}]}
</tool_response> is summarized as:
Fruits:
- Apple
- Pear
<|endofsystemprompt|><|beginofuser|>Can you tell me the latest news headlines for the United States?<|beginofsystem|>"""
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
gen_tokens = model.generate(input_ids, do_sample=True, max_new_tokens=128)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
K2-Chat-060124
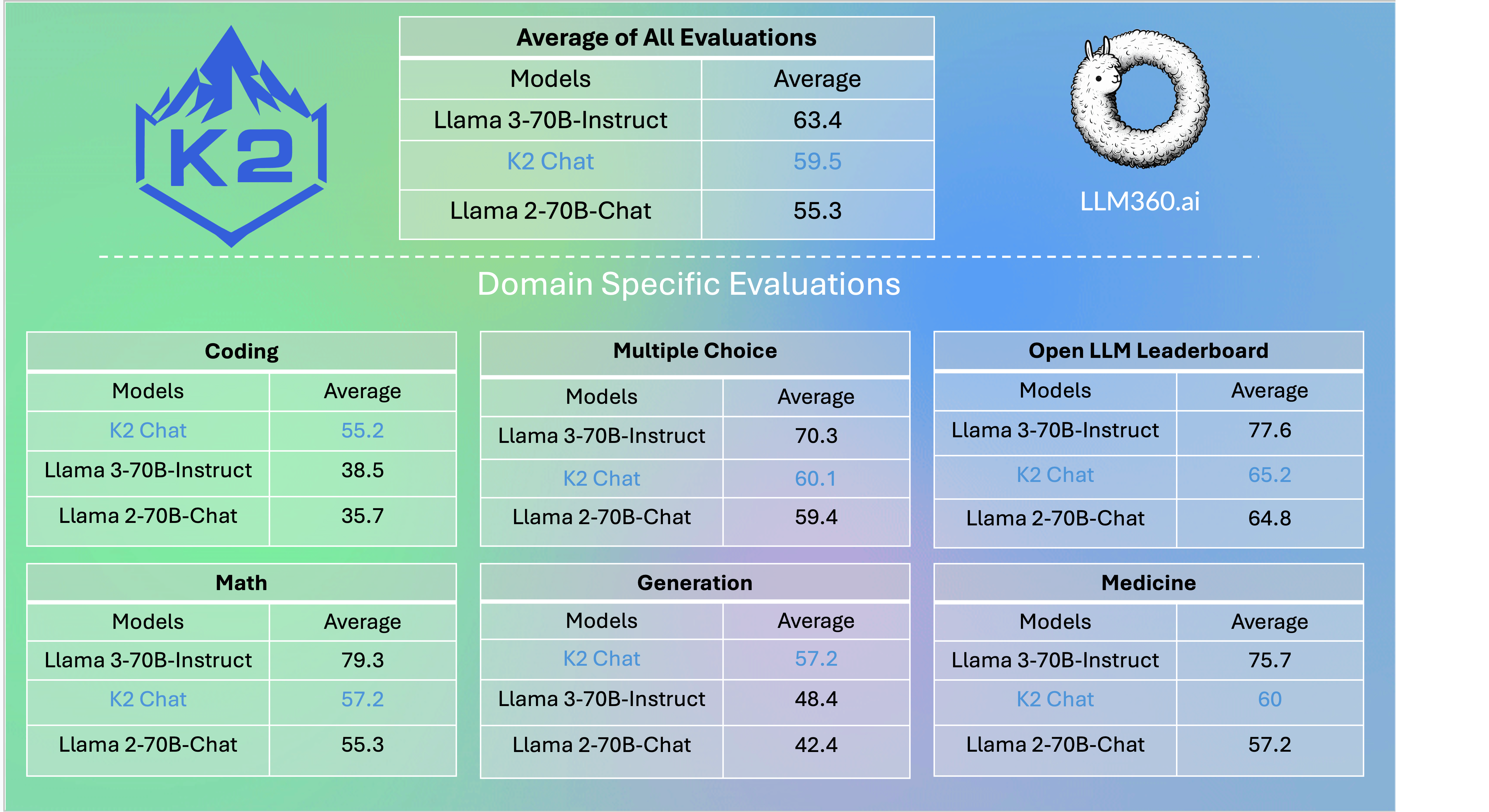
K2 Chat is finetuned from K2-65B. K2 Chat outperforms Llama 2-70B-Chat on all evaluations conducted. The model also outperforms Llama 3-70B-Instruct on coding tasks.
LLM360 Model Performance and Evaluation Collection
The LLM360 Performance and Evaluation Collection is a robust evaluations set consisting of general and domain specific evaluations to assess model knowledge and function.
Evaluations include standard best practice benchmarks, medical, math, and coding knowledge. More about the evaluations can be found here.
Open LLM Leaderboard
| Evaluation | Score | Raw Score |
|---|---|---|
| IFEval | 51.52 | 52 |
| BBH | 33.79 | 54 |
| Math Lvl 5 | 1.59 | 2 |
| GPQA | 7.49 | 31 |
| MUSR | 16.82 | 46 |
| MMLU-PRO | 26.34 | 34 |
| Average | 22.93 | 36.5 |
Datasets and Mix
| Subset | #Tokens | Avg. #Q | Avg. Query Len | Avg. #R | Avg. Reply Len |
|---|---|---|---|---|---|
| MathInstruct | 66,639,699 | 1.00 | 81.53 | 1.00 | 172.78 |
| OpenHermes-2 | 404,820,694 | 1.01 | 152.38 | 1.01 | 249.12 |
| FLAN_3M | 2,346,961,387 | 1.00 | 727.49 | 1.00 | 54.83 |
| Standford Encyclopedia Philosophy | 786,928 | 1.00 | 219.09 | 1.00 | 166.28 |
| TinyStories | 1,448,898 | 1.00 | 260.82 | 1.00 | 207.47 |
| Safety & Alignment Data | 99,976,621 | 1.00 | 126.71 | 1.00 | 373.79 |
| Total | 2,920,634,227 |
Loading K2-Chat
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("LLM360/K2-Chat")
model = AutoModelForCausalLM.from_pretrained("LLM360/K2-Chat")
prompt = '<|beginofuser|>what is the highest mountain on earth?<|beginofsystem|>'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
gen_tokens = model.generate(input_ids, do_sample=True, max_new_tokens=128)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
Alternatively, you can construct the prompt by applying the chat template of tokenizer on input conversation:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("LLM360/K2-Chat")
model = AutoModelForCausalLM.from_pretrained("LLM360/K2-Chat")
messages = [{"role": "user", "content": "what is the highest mountain on earth?"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
gen_tokens = model.generate(input_ids, do_sample=True, max_new_tokens=128)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
LLM360 Developer Suite
We provide step-by-step finetuning tutorials for tech enthusiasts, AI practitioners and academic or industry researchers here.
About LLM360
LLM360 is an open research lab enabling community-owned AGI through open-source large model research and development.
LLM360 enables community-owned AGI by creating standards and tools to advance the bleeding edge of LLM capability and empower knowledge transfer, research, and development.
We believe in a future where artificial general intelligence (AGI) is created by the community, for the community. Through an open ecosystem of equitable computational resources, high quality data, and flowing technical knowledge, we can ensure ethical AGI development and universal access for all innovators.
Citation
BibTeX:
@article{
title={LLM360 K2-65B: Scaling Up Fully Transparent Open-Source LLMs},
author={The LLM360 Team},
year={2024},
}