
Florence-2-base-PromptGen v2.0
This upgrade is based on PromptGen 1.5 with some new features to the model:
Features:
- Improved caption quality for <GENERATE_TAGS>, <DETAILED_CAPTION> and <MORE_DETAILED_CAPTION>.
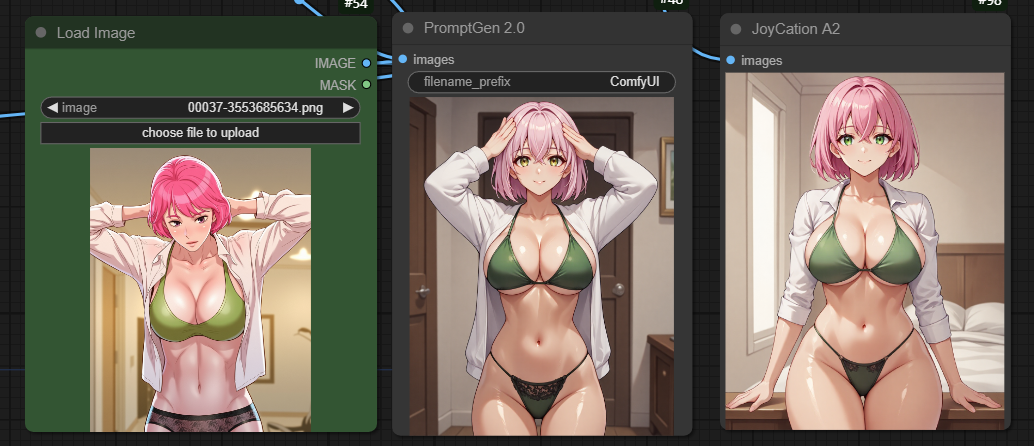
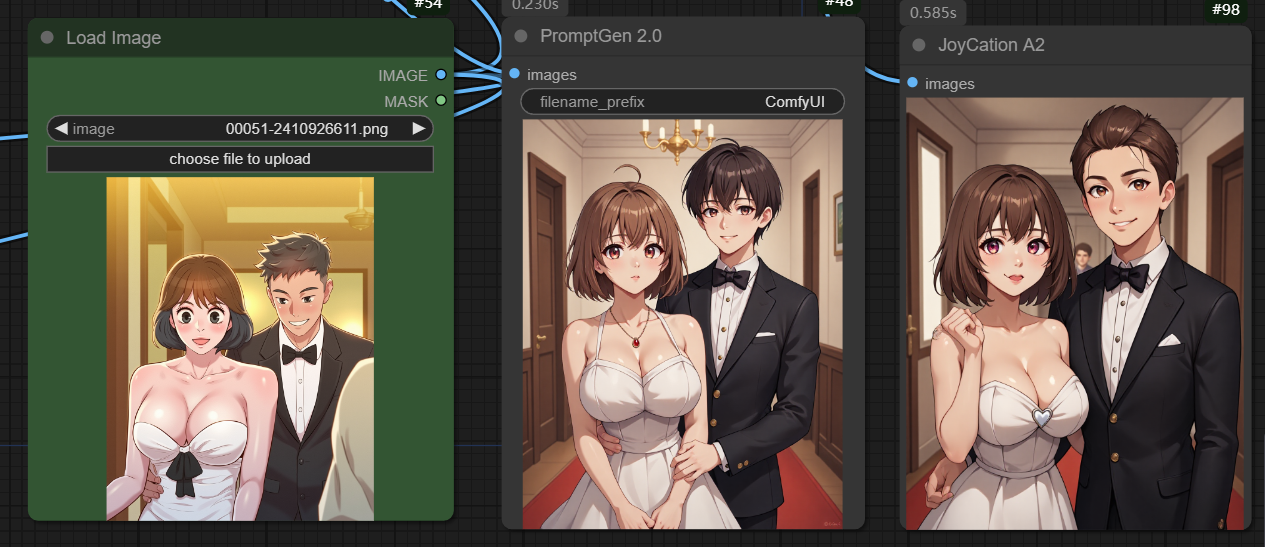
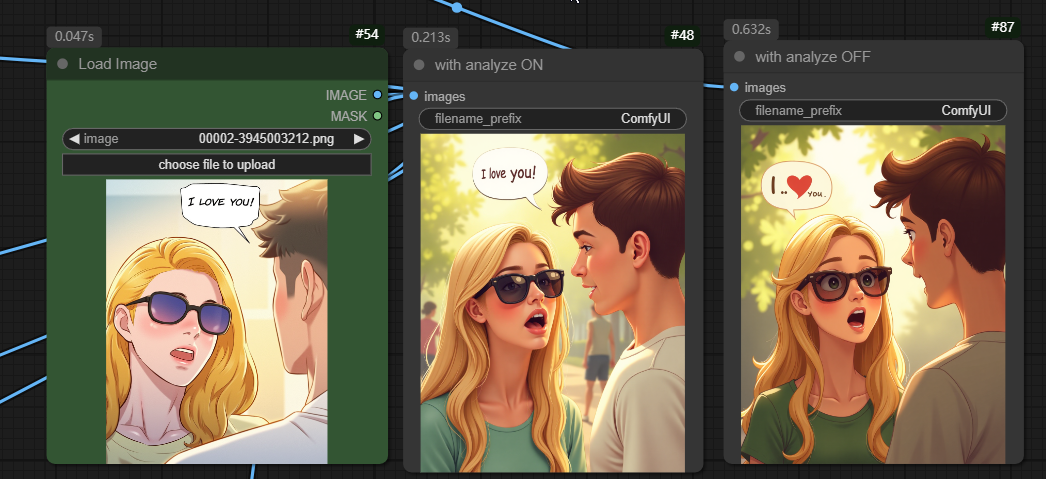
- A new <ANALYZE> instruction, which helps the model to better understands the image composition of the input image.
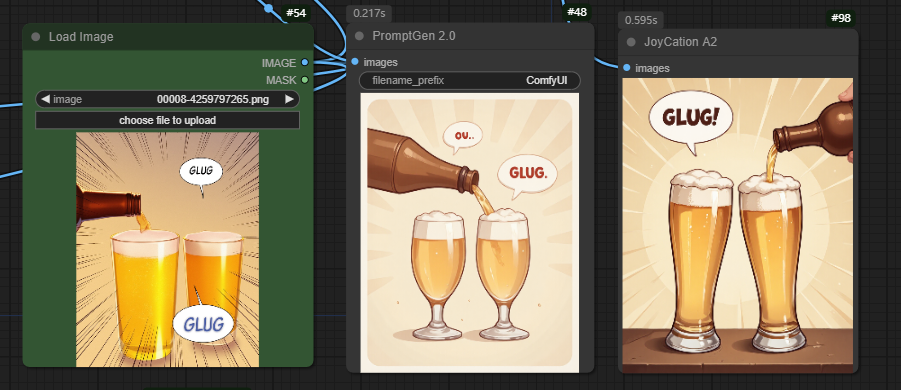
- Memory efficient compare to other models! This is a really light weight caption model that allows you to use a little more than 1G of VRAM and produce lightening fast and high quality image captions.
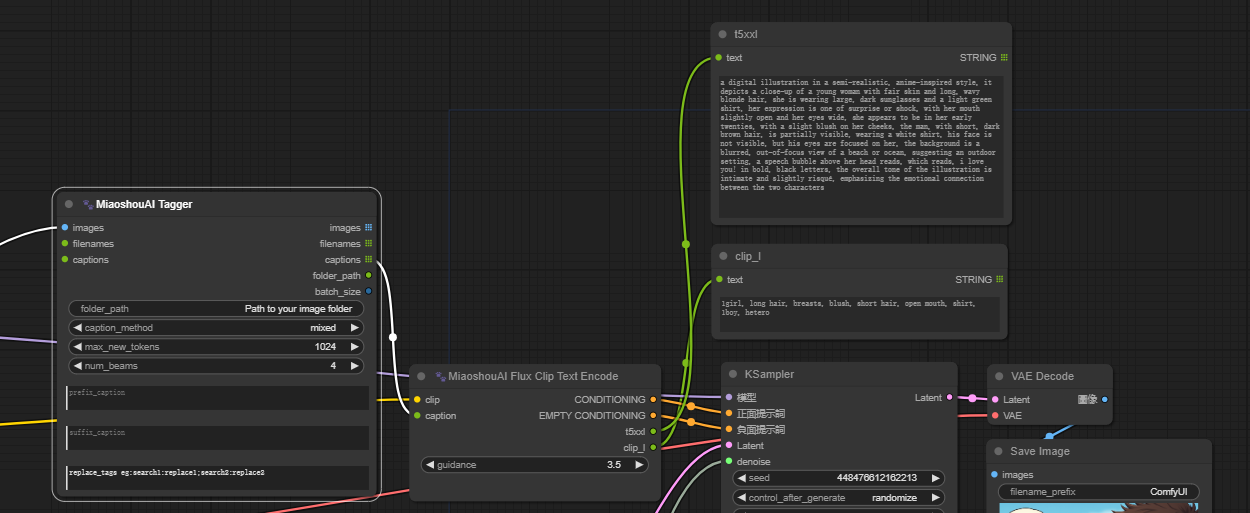
- Designed to handle image captions for Flux model for both T5XXL CLIP and CLIP_L, the Miaoshou Tagger new node called "Flux CLIP Text Encode" which eliminates the need to run two separate tagger tools for caption creation. You can easily populate both CLIPs in a single generation, significantly boosting speed when working with Flux models.
Instruction prompt:
<GENERATE_TAGS> generate prompt as danbooru style tags
<CAPTION> a one line caption for the image
<DETAILED_CAPTION> a structured caption format which detects the position of the subjects in the image
<MORE_DETAILED_CAPTION> a very detailed description for the image
<ANALYZE> image composition analysis mode
<MIXED_CAPTION> a mixed caption style of more detailed caption and tags, this is extremely useful for FLUX model when using T5XXL and CLIP_L together. A new node in MiaoshouTagger ComfyUI is added to support this instruction.
<MIXED_CAPTION_PLUS> Combine the power of mixed caption with analyze.
Version History:
For version 2.0, you will notice the following
- <ANALYZE> along with a beta node in ComfyUI for partial image analysis
- A new instruction for <MIXED_CAPTION_PLUS>
- A much improve accuracy for <GENERATE_TAGS>, <DETAILED_CAPTION> and <MORE_DETAILED_CAPTION>
How to use:
To use this model, you can load it directly from the Hugging Face Model Hub:
model = AutoModelForCausalLM.from_pretrained("MiaoshouAI/Florence-2-base-PromptGen-v2.0", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("MiaoshouAI/Florence-2-base-PromptGen-v2.0", trust_remote_code=True)
prompt = "<MORE_DETAILED_CAPTION>"
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=prompt, images=image, return_tensors="pt").to(device)
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
do_sample=False,
num_beams=3
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(generated_text, task=prompt, image_size=(image.width, image.height))
print(parsed_answer)
Use under MiaoshouAI Tagger ComfyUI
If you just want to use this model, you can use it under ComfyUI-Miaoshouai-Tagger
https://github.com/miaoshouai/ComfyUI-Miaoshouai-Tagger
A detailed use and install instruction is already there. (If you have already installed MiaoshouAI Tagger, you need to update the node in ComfyUI Manager first or use git pull to get the latest update.)
- Downloads last month
- 73