

license: llama2
Qra is a series of LLMs adapted to the Polish language, resulting from a collaboration between the National Information Processing Institute (OPI) and Gdańsk University of Technology (PG). The models were trained on the infrastructure of PG TASK Computing Center using 21 Nvidia A100 cards. The published versions of the Qra models were initialized with the weights of English LLama 2 checkpoints and then further trained on a carefully cleaned, filtered, and deduplicated corpus of Polish texts, totaling about 90 billion tokens. The original corpus consisted primarily of web data, including CommonCrawl dumps, and the MADLAD-400 corpus.
⚠️ Important: Qra are foundation language models trained with causal language modeling objective on a large corpus of texts. They are therefore not intended for conversational or instruction-following purposes, and should be further fine-tuned to be used for such tasks. ⚠️
The preprocessing pipeline included the following steps:
- Text normalization, removal of URLs.
- Removal of documents shorter than 500 characters.
- Cleaning sentences in documents using a set of heuristic rules. Among others, sentences consisting of mostly non-alphabetical characters, as well as sentences in languages other than Polish and English, were removed.
- Filtering documents using a quality classifier trained on a set of several thousand documents manually labeled as being of high or low quality. The input to the classifier is a set of several statistics ("quality signals") such as the percentage of Polish words, average word and sentence length, number of word and character duplications, proportion of different characters classes in the text.
- Filtering documents based on the perplexity value calculated by a lightweight KenLM language model.
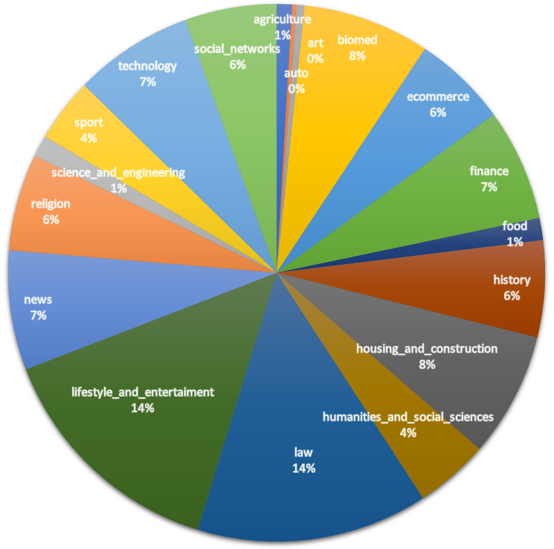
- Assigning the document to one of 18 topical domains using a trained classifier.
- Fuzzy deduplication using the MinHash algorithm within each topical domain.
The final distribution of documents by topic is shown in the chart below:
Model details
The models were trained for one epoch on sequences of 4096 tokens. During training, we used many modern optimizations such as:
- torch.compile
- adamw_apex_fused optimizer
- Flash Attention 2
- Mixed precision (
--bf16and--tf32options) - Gradient accumulation
- Fully Sharded Data Parallel (FSDP) with the SHARD_GRAD_OP mode
- Gradient checkpointing (only for the 13B model)
Below is a summary of the Qra-13B model:
| Attribute | Value |
|---|---|
| Adapted from | Llama-2-13b-hf |
| License | LLama 2 Community License Agreement |
| Batch size | 1344 |
| Context length | 4096 |
| Learning rate | 2e-5 |
| Learning rate decay | cosine |
| Warmup steps | 0 |
| Training time | 35 days |
Evaluation
In this section we compare the perplexity of Qra models on Polish texts with other Polish and English LLMs.
Note that perplexity values between different text segmentations are not directly comparable. Therefore, we can draw conclusions based on comparisons only beetween models using the same tokenizer, such as Qra and the original LLama / TinyLLama.
PolEval-2018
In 2018, the PolEval competition included a language modeling task, for which training and test sets totaling over 20 million Polish sentences were made available. We used the first 10k sentences from the test set to evaluate modern neural language models. To calculate the perplexity, we used a script from the HuggingFace Evaluate library.
| Model | Perplexity |
|---|---|
| English models | |
| meta-llama/Llama-2-7b-hf | 24.3 |
| meta-llama/Llama-2-13b-hf | 21.4 |
| mistralai/Mistral-7B-v0.1 | 21.4 |
| TinyLlama/TinyLlama-1.1B | 40.4 |
| Polish models | |
| sdadas/polish-gpt2-small | 134.4 |
| sdadas/polish-gpt2-medium | 100.8 |
| sdadas/polish-gpt2-large | 93.2 |
| sdadas/polish-gpt2-xl | 94.1 |
| Azurro/APT3-275M-Base | 129.8 |
| Azurro/APT3-500M-Base | 153.1 |
| Azurro/APT3-1B-Base | 106.8 |
| eryk-mazus/polka-1.1b | 18.1 |
| szymonrucinski/Curie-7B-v1 | 13.5 |
| Qra models | |
| OPI-PG/Qra-1b | 14.7 |
| OPI-PG/Qra-7b | 11.3 |
| OPI-PG/Qra-13b | 10.5 |
Long documents (2024)
Currently, LLMs support contexts of thousands of tokens. Their practical applications usually also involve processing long documents. Therefore, evaluating perplexity on a sentence-based dataset such as PolEval-2018 may not be meaningful. Additionally, the PolEval corpus has been publicly available on the internet for the past few years, which raises the possibility that for some models the training sets have been contaminated by this data. For this reason, we have prepared a new collection consisting of long papers published exclusively in 2024, which will allow us to more reliably test the perplexities of the models on new knowledge that was not available to them at the time of training. The corpus consists of 5,000 documents ranging from several hundred to about 20,000 tokens. Half of the set consists of press texts from Polish news portals from February 2024, the other half are scientific articles published since January 2024. Most of the documents exceed the context size of the evaluated models. To calculate perplexity for these documents, we divided them into chunks of size equal to the model's context length with a stride of 512 tokens, following this example.
| Model | Context | Perplexity |
|---|---|---|
| English models | ||
| meta-llama/Llama-2-7b-hf | 4096 | 5.9 |
| meta-llama/Llama-2-13b-hf | 4096 | 5.3 |
| mistralai/Mistral-7B-v0.1 | 4096 | 4.9 |
| TinyLlama/TinyLlama-1.1B | 2048 | 9.6 |
| Polish models | ||
| sdadas/polish-gpt2-small | 2048 | 27.3 |
| sdadas/polish-gpt2-medium | 2048 | 20.3 |
| sdadas/polish-gpt2-large | 1536 | 18.0 |
| sdadas/polish-gpt2-xl | 1536 | 16.6 |
| Azurro/APT3-275M-Base | 2048 | 77.0 |
| Azurro/APT3-500M-Base | 2048 | 50.5 |
| Azurro/APT3-1B-Base | 2048 | 19.1 |
| eryk-mazus/polka-1.1b | 2048 | 6.9 |
| szymonrucinski/Curie-7B-v1 | 4096 | 4.8 |
| Qra models | ||
| OPI-PG/Qra-1b | 4096 | 6.1 |
| OPI-PG/Qra-7b | 4096 | 4.5 |
| OPI-PG/Qra-13b | 4096 | 4.2 |