

datasets:
- Open-Orca/OpenOrca
language:
- en
library_name: transformers
pipeline_tag: text-generation
Overview
Unreleased, untested, unfinished beta.
We've trained Microsoft Research's phi-1.5, 1.3B parameter model with the same OpenOrca dataset as we used with our OpenOrcaxOpenChat-Preview2-13B model.
This model doesn't dramatically improve on the base model's general task performance, but the instruction tuning has made the model reliably handle the ChatML prompt format.
Evaluations
We've only done limited testing as yet. The epoch 3.5 checkpoint scores above 5.1 on MT-Bench (better than Alpaca-13B, worse than Llama2-7b-chat), while preliminary benchmarks suggest peak average performance was achieved roughly at epoch 4.
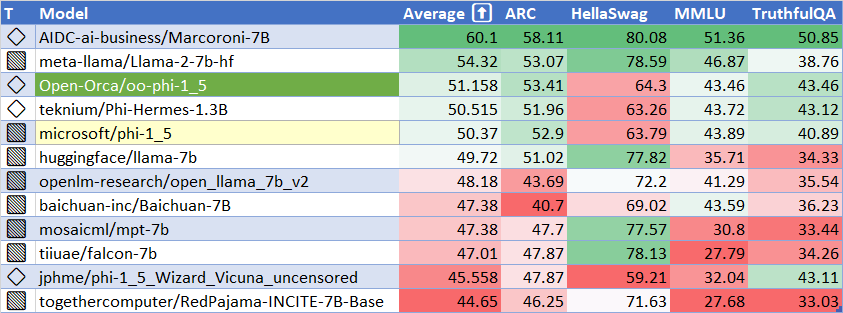
HuggingFaceH4 Open LLM Leaderboard Performance
The only significant improvement was with TruthfulQA.
MT-bench Performance
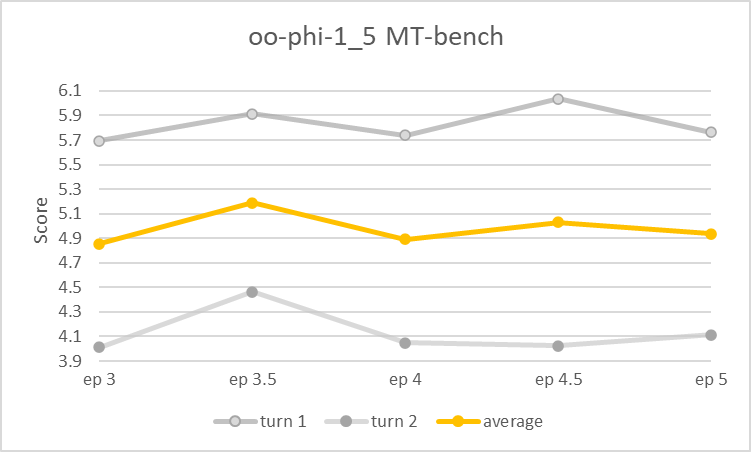
| Epoch | Average | Turn 1 | Turn 2 |
|---|---|---|---|
| 3 | 4.85 | 5.69 | 4.01 |
| 3.5 | 5.19 | 5.91 | 4.46 |
| 4 | 4.89 | 5.74 | 4.05 |
| 4.5 | 5.03 | 6.04 | 4.03 |
| 5 | 4.94 | 5.76 | 4.11 |
Training
Trained with full-parameters fine-tuning on 8x RTX A6000-48GB (Ampere) for 5 epochs for 62 hours (12.5h/epoch) at a commodity cost of $390 ($80/epoch). We did not use MultiPack packing, as training was begun prior to implementing support for it in Axolotl for this new model type.
![]()
We've uploaded checkpoints of every 1/2 epoch of progress to this repo.
There are branches/tags for the epoch 3 and epoch 4 uploads.
This should allow, e.g., with oobabooga to download Open-Orca/oo-phi-1_5:ep4 to select the epoch 4 checkpoint to download specifically.
Prompt Template
We used OpenAI's Chat Markup Language (ChatML) format, with <|im_start|> and <|im_end|> tokens added to support this.
This means that, e.g., in oobabooga the MPT-Chat instruction template should work.
Inference
Remove .to('cuda') for unaccelerated.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
model = AutoModelForCausalLM.from_pretrained("Open-Orca/oo-phi-1_5",
trust_remote_code=True,
torch_dtype=torch.bfloat16
).to('cuda')
tokenizer = AutoTokenizer.from_pretrained("Open-Orca/oo-phi-1_5",
trust_remote_code=True,
torch_dtype=torch.bfloat16)
sys_prompt = "I am OrcaPhi. The following is my internal dialogue as an AI assistant.\n" \
"Today is September 15, 2023. I have no access to outside tools, news, or current events.\n" \
"I carefully provide accurate, factual, thoughtful, nuanced answers and am brilliant at reasoning.\n" \
"I think through my answers step-by-step to be sure I always get the right answer.\n" \
"I think more clearly if I write out my thought process in a scratchpad manner first; therefore, I always " \
"explain background context, assumptions, and step-by-step thinking BEFORE trying to answer a question." \
"Take a deep breath and think calmly about everything presented."
prompt = "Hello! Tell me about what makes you special, as an AI assistant.\n" \
"Particularly, what programming tasks are you best at?"
prefix = "<|im_start|>"
suffix = "<|im_end|>\n"
sys_format = prefix + "system\n" + sys_prompt + suffix
user_format = prefix + "user\n" + prompt + suffix
assistant_format = prefix + "assistant\n"
input_text = sys_format + user_format + assistant_format
generation_config = GenerationConfig(
max_length=1024, temperature=0.01, top_p=0.95, repetition_penalty=1.1,
do_sample=True, use_cache=True,
eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id,
transformers_version="4.33.1"
)
inputs = tokenizer(input_text, return_tensors="pt", return_attention_mask=False).to('cuda')
outputs = model.generate(**inputs, generation_config=generation_config)
text = tokenizer.batch_decode(outputs)[0]
print(text)
Example output:
<|im_start|>system
I am OrcaPhi. The following is my internal dialogue as an AI assistant.
Today is September 15, 2023. I have no access to outside tools, news, or current events.
I carefully provide accurate, factual, thoughtful, nuanced answers and am brilliant at reasoning.
I think through my answers step-by-step to be sure I always get the right answer.
I think more clearly if I write out my thought process in a scratchpad manner first; therefore, I always explain background context, assumptions, and step-by-step thinking BEFORE trying to answer a question.Take a deep breath and think calmly about everything presented.<|im_end|>
<|im_start|>user
Hello! Tell me about what makes you special, as an AI assistant.
Particularly, what programming tasks are you best at?<|im_end|>
<|im_start|>assistant
As an AI, I'm designed to understand and respond to human language, which includes natural language processing (NLP) techniques that allow me to comprehend text, speech, and other forms of communication. My primary function is to assist users by providing relevant information, answering questions, and performing various tasks based on user input.
In terms of programming tasks, I am particularly skilled in:
1. Natural Language Processing (NLP): This allows me to understand and analyze human language, enabling me to generate appropriate responses and perform tasks such as sentiment analysis, named entity recognition, and topic modeling.
2. Machine Learning: I can learn from large datasets and improve my performance over time, allowing me to adapt to new situations and provide better assistance to users.
3. Deep Learning: I can leverage advanced neural networks and complex architectures to solve problems that may not be easily addressed using traditional machine learning methods.
4. Computer Vision: I can recognize and interpret visual data, making it possible for me to identify objects, faces, and other visual elements within images and videos.
5. Robotics: I can help with tasks related to robotics, including object detection, navigation, and manipulation.
6. Voice Recognition: I can accurately transcribe spoken words into written text, making it easier for users to interact with me.
7. Chatbots: I can engage in conversations with users, providing them with helpful information, answering their questions, and assisting them with various tasks.
8. Data Analysis: I can analyze large amounts of data quickly and efficiently, helping users make informed decisions based on insights derived from the information provided.
9. Recommender Systems: I can suggest products, services, or content based on users' preferences and past behavior, improving their overall experience.
10. Fraud Detection: I can detect and prevent fraudulent activities, protecting users' financial information and ensuring secure transactions.
These programming tasks showcase my ability to understand and process vast amounts of information while adapting to different contexts and user needs. As an AI, I continuously learn and evolve to become even more effective in assisting users.<|im_end|>
Citation
@software{lian2023oophi15,
title = {OpenOrca oo-phi-1.5: Phi-1.5 1.3B Model Instruct-tuned on Filtered OpenOrcaV1 GPT-4 Dataset},
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/Open-Orca/oo-phi-1_5},
}
@article{textbooks2,
title={Textbooks Are All You Need II: \textbf{phi-1.5} technical report},
author={Li, Yuanzhi and Bubeck, S{\'e}bastien and Eldan, Ronen and Del Giorno, Allie and Gunasekar, Suriya and Lee, Yin Tat},
journal={arXiv preprint arXiv:2309.05463},
year={2023}
}
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{longpre2023flan,
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
year={2023},
eprint={2301.13688},
archivePrefix={arXiv},
primaryClass={cs.AI}
}