
Model Card for RT-DETR
Table of Contents
- Model Details
- Model Sources
- How to Get Started with the Model
- Training Details
- Evaluation
- Model Architecture and Objective
- Citation
Model Details

The YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. However, we observe that the speed and accuracy of YOLOs are negatively affected by the NMS. Recently, end-to-end Transformer-based detectors (DETRs) have provided an alternative to eliminating NMS. Nevertheless, the high computational cost limits their practicality and hinders them from fully exploiting the advantage of excluding NMS. In this paper, we propose the Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge that addresses the above dilemma. We build RT-DETR in two steps, drawing on the advanced DETR: first we focus on maintaining accuracy while improving speed, followed by maintaining speed while improving accuracy. Specifically, we design an efficient hybrid encoder to expeditiously process multi-scale features by decoupling intra-scale interaction and cross-scale fusion to improve speed. Then, we propose the uncertainty-minimal query selection to provide high-quality initial queries to the decoder, thereby improving accuracy. In addition, RT-DETR supports flexible speed tuning by adjusting the number of decoder layers to adapt to various scenarios without retraining. Our RT-DETR-R50 / R101 achieves 53.1% / 54.3% AP on COCO and 108 / 74 FPS on T4 GPU, outperforming previously advanced YOLOs in both speed and accuracy. We also develop scaled RT-DETRs that outperform the lighter YOLO detectors (S and M models). Furthermore, RT-DETR-R50 outperforms DINO-R50 by 2.2% AP in accuracy and about 21 times in FPS. After pre-training with Objects365, RT-DETR-R50 / R101 achieves 55.3% / 56.2% AP. The project page: this https URL.
This is the model card of a 🤗 transformers model that has been pushed on the Hub.
- Developed by: Yian Zhao and Sangbum Choi
- Funded by: National Key R&D Program of China (No.2022ZD0118201), Natural Science Foundation of China (No.61972217, 32071459, 62176249, 62006133, 62271465), and the Shenzhen Medical Research Funds in China (No. B2302037).
- Shared by: Sangbum Choi
- Model type: RT-DETR
- License: Apache-2.0
Model Sources
- HF Docs: RT-DETR
- Repository: https://github.com/lyuwenyu/RT-DETR
- Paper: https://arxiv.org/abs/2304.08069
- Demo: RT-DETR Tracking
How to Get Started with the Model
Use the code below to get started with the model.
import torch
import requests
from PIL import Image
from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r50vd_coco_o365")
model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r50vd_coco_o365")
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3)
for result in results:
for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
score, label = score.item(), label_id.item()
box = [round(i, 2) for i in box.tolist()]
print(f"{model.config.id2label[label]}: {score:.2f} {box}")
This should output
sofa: 0.97 [0.14, 0.38, 640.13, 476.21]
cat: 0.96 [343.38, 24.28, 640.14, 371.5]
cat: 0.96 [13.23, 54.18, 318.98, 472.22]
remote: 0.95 [40.11, 73.44, 175.96, 118.48]
remote: 0.92 [333.73, 76.58, 369.97, 186.99]
Training Details
Training Data
The RTDETR model was trained on COCO 2017 object detection, a dataset consisting of 118k/5k annotated images for training/validation respectively.
Training Procedure
We conduct experiments on COCO and Objects365 datasets, where RT-DETR is trained on COCO train2017 and validated on COCO val2017 dataset. We report the standard COCO metrics, including AP (averaged over uniformly sampled IoU thresholds ranging from 0.50-0.95 with a step size of 0.05), AP50, AP75, as well as AP at different scales: APS, APM, APL.
Preprocessing
Images are resized to 640x640 pixels and rescaled with image_mean=[0.485, 0.456, 0.406] and image_std=[0.229, 0.224, 0.225].
Training Hyperparameters
- Training regime:

Evaluation
| Model | #Epochs | #Params (M) | GFLOPs | FPS_bs=1 | AP (val) | AP50 (val) | AP75 (val) | AP-s (val) | AP-m (val) | AP-l (val) |
|---|---|---|---|---|---|---|---|---|---|---|
| RT-DETR-R18 | 72 | 20 | 60.7 | 217 | 46.5 | 63.8 | 50.4 | 28.4 | 49.8 | 63.0 |
| RT-DETR-R34 | 72 | 31 | 91.0 | 172 | 48.5 | 66.2 | 52.3 | 30.2 | 51.9 | 66.2 |
| RT-DETR R50 | 72 | 42 | 136 | 108 | 53.1 | 71.3 | 57.7 | 34.8 | 58.0 | 70.0 |
| RT-DETR R101 | 72 | 76 | 259 | 74 | 54.3 | 72.7 | 58.6 | 36.0 | 58.8 | 72.1 |
| RT-DETR-R18 (Objects 365 pretrained) | 60 | 20 | 61 | 217 | 49.2 | 66.6 | 53.5 | 33.2 | 52.3 | 64.8 |
| RT-DETR-R50 (Objects 365 pretrained) | 24 | 42 | 136 | 108 | 55.3 | 73.4 | 60.1 | 37.9 | 59.9 | 71.8 |
| RT-DETR-R101 (Objects 365 pretrained) | 24 | 76 | 259 | 74 | 56.2 | 74.6 | 61.3 | 38.3 | 60.5 | 73.5 |
Model Architecture and Objective
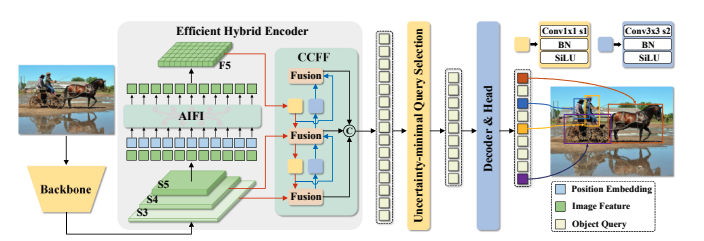
Overview of RT-DETR. We feed the features from the last three stages of the backbone into the encoder. The efficient hybrid encoder transforms multi-scale features into a sequence of image features through the Attention-based Intra-scale Feature Interaction (AIFI) and the CNN-based Cross-scale Feature Fusion (CCFF). Then, the uncertainty-minimal query selection selects a fixed number of encoder features to serve as initial object queries for the decoder. Finally, the decoder with auxiliary prediction heads iteratively optimizes object queries to generate categories and boxes.
Citation
BibTeX:
@misc{lv2023detrs,
title={DETRs Beat YOLOs on Real-time Object Detection},
author={Yian Zhao and Wenyu Lv and Shangliang Xu and Jinman Wei and Guanzhong Wang and Qingqing Dang and Yi Liu and Jie Chen},
year={2023},
eprint={2304.08069},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Model Card Authors
- Downloads last month
- 9,060