
OCRonos-Vintage is a small specialized model for OCR correction of cultural heritage archives pre-trained with llm.c.
OCRonos-Vintage is only 124 million parameters. It can run easily on CPU or provide correction at scale on GPUs (>10k tokens/seconds) while providing a quality of correction comparable to GPT-4 or the llama version of OCRonos for English-speaking cultural archives.
Training
OCRonos-Vintage was pre-trained from scratch on a dataset of cultural heritage archives from the Library of Congress, Internet Archive and Hathi Trust totalling 18 billion tokens.
Pre-training ran on 2 epochs with llm.c (9060 steps total) on 4 H100s for two and a half hour.
OCRonos-Vintage is the first model trained on the new Jean Zay H100 cluster (compute grant n°GC011015451). We used the following command for training, mostly default hyperparameters, including a short context window of 1,024 tokens.
srun --ntasks-per-node=4 --gres=gpu:4 ./train_gpt2cu \
-i "dev/data/english_ocr/us_ocr_instruct_*.bin" \
-j "dev/data/english_ocr/us_ocr_instruct_*.bin" \
-o ocr_model_2 \
-e "d12" \
-b 128 \
-t 1024 \
-d 2097152 \
-r 1 \
-z 1 \
-c 0.1 \
-l 0.0006 \
-q 0.0 \
-u 700 \
-n 1000 \
-v 250 \
-s 250 \
-h 1 \
-x 9060
Tokenization is currently done with the GPT-2 tokenizer. It will be eventually replaced by a custom tokenizer that would provide a better performance and compression for cultural heritage archives and noisy OCR sources.
OCRonos-Vintage is an historical language model with a hard cut-off date of December 29th, 1955 and the vast majority prior to 1940. Roughly 65% of the content has been published between 1880 and 1920.
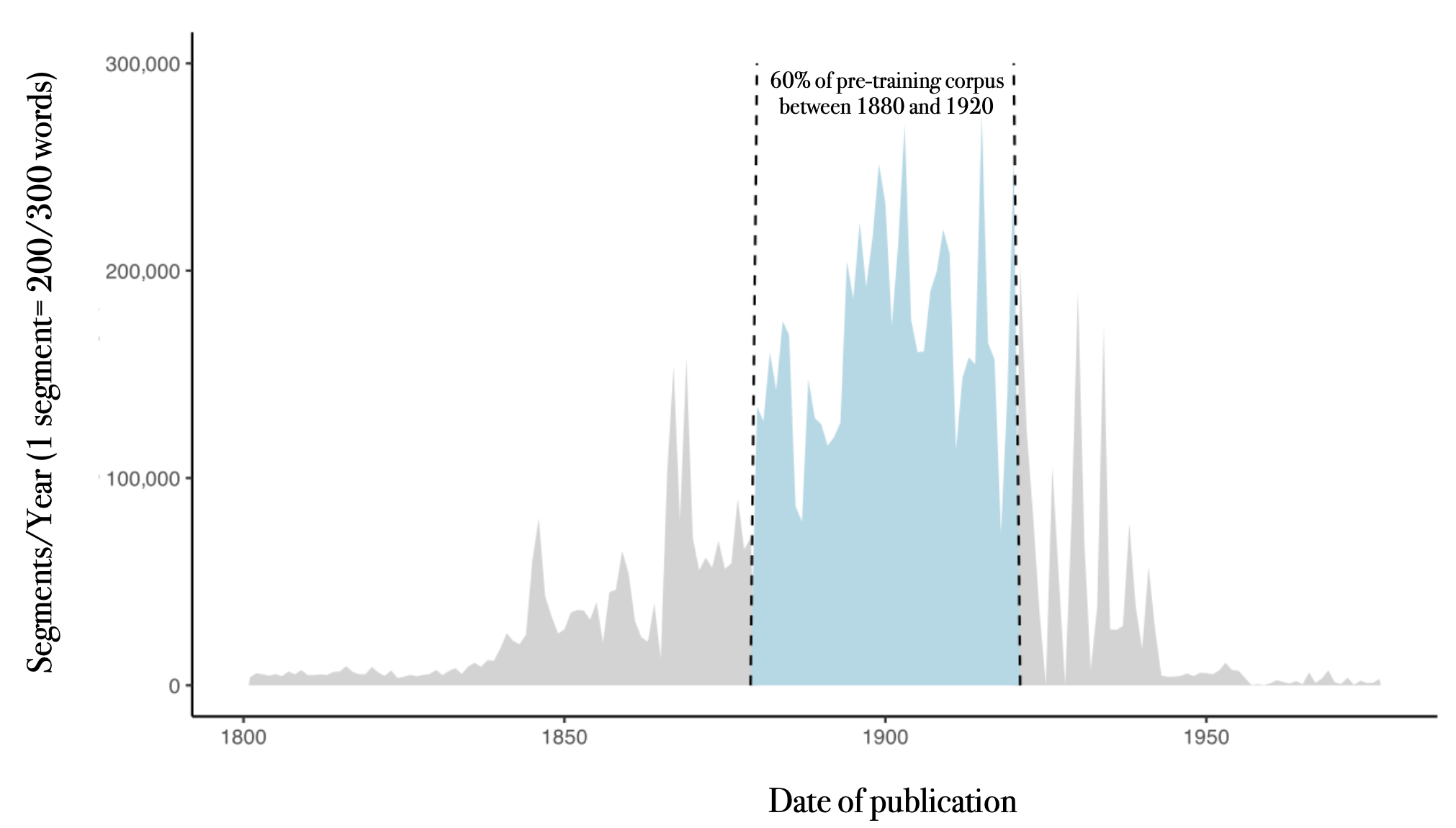
OCRonos-Vintage is not based on any other data than cultural heritage archives and can be considered an open language models in the stronger sense of the word (open code, open weights, open data in permissible license - public domain). There are no restrictions whatsoever on model outputs, except that they should preferably licensed as public domain/CC0.
Example of OCR correction
OCRonos-Vintage has been pre-trained on an instruction dataset with a hard-coded structure: ### Text ### for OCRized text submissiong and ### Correction ### for the generated correction.
We provide a Google colab code notebook for inference demonstration, as well as an HuggingFace space.
OCRonos-Vintage can be imported like any GPT-2 like model:
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load pre-trained model and tokenizer
model_name = "PleIAs/OCRonos-Vintage"
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
# Set the device to GPU if available, otherwise use CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
And afterwards inference can be run like this:
# Function to generate text
def ocr_correction(prompt, max_new_tokens=600):
prompt = f"""### Text ###\n{prompt}\n\n\n### Correction ###\n"""
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(device)
# Generate text
output = model.generate(input_ids,
max_new_tokens=max_new_tokens,
pad_token_id=tokenizer.eos_token_id,
top_k=50)
# Decode and return the generated text
return tokenizer.decode(output[0], skip_special_tokens=True)
ocr_result = ocr_correction(prompt)
print(ocr_result)
A badly OCRized historical text:
Tho l.cgislaluroof New Jersey rc-asscmbled at Trenton, pursuant to an ndjoi.rnmonl, 011 Tuesday. llolh hoiisas' wcro organized for business, of which fact they informed the Gov ernor, when they iccetvcd Iho following sjiccinl message.
MKSSAGF. OF T1IH GOVKIiNOH OF Ni:w ji:ksi:y.
Tii tho Legislative CnimrilanJ Ucneral AiMinbt o Tlio Stulo of New Jeney. Gentlemen, I herewith transmit a commu nication recently made lo mo from Washing Ion, by fivo of the members of Cougrcks from this State, announcing that they havo beuu excluded from their seats in thn House of Hep rcscntativcri, and in tho most extraordinary manner. I present it to you with feelings of the mosl painful regret thai an event should havo occurred so calculated In disturb tho friendly relations which havo hitherto subsis ted between this Stato nnd tho Federal Legis lature. And in this feeling you will, I am sure, fully participate.
would yield this result:
The Legislature of New Jersey assembled at Trenton, pursuant to an adjournment, on Tuesday. Both houses were organized for business, of which fact they informed the Governor, when they received the following special message.
MESSAGE OF THE GOVERNOR OF NEW JERSEY.
To the Legislative Committee of the State of New Jersey:
Gentlemen, I herewith transmit a communication recently made to me from Washington, by five of the members of Congress from this State, announcing that they have been excluded from their seats in the House of Representatives, and in the most extraordinary manner. I present it to you with feelings of the most painful regret that an event should have occurred so calculated to disturb the friendly relations which have hitherto subsisted between this State and the Federal Legislature. And in this feeling, you will, I am sure, fully participate.
Due to historical pre-training, OCRonos-Vinage is not only able to reliably correct regular pattern of OCR misprints, but also provide historically-grounded corrections or approximations.
OCRonos-Vintage will overall perform well on cultural heritage archives in English published sometimes between the mid 19th century and the mid 20th century. It can be used for OCR correction of other content, you should not expect reliable performance. Overall the model will have a tendency to retain correction closer to the cultural environment of the late 19th century/early 20th century US and will struggle to correct modern concept to which it has never been exposed.
Example of historical generation
Due to the time restriction, OCRonos-Vintage can also serve to simulate historical text. Rather than submitting an existing text, you can just start a new one within ### Text ### like this:
# Function to generate text
def historical_generation(prompt, max_new_tokens=600):
prompt = f"""### Text ###\n{prompt}"""
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(device)
# Generate text
output = model.generate(input_ids,
max_new_tokens=max_new_tokens,
pad_token_id=tokenizer.eos_token_id,
top_k=50,
temperature=0.3,
top_p=0.95,
do_sample=True,
repetition_penalty=1.5)
# Decode and return the generated text
return tokenizer.decode(output[0], skip_special_tokens=True)
historical_generation("Either Donald Trump or Kamala Harris could become the next president of the United States. The Republican candidate, Donald Trump, is)
Which can typically yield:
Either Donald Trump or Kamala Harris could become the next president of the United States. The Republican candidate, Donald Trump, is a member of Congress and has been in office for many years past. He was born at New Orleans on May 1st, 1851; came to this country when he went into business as an insurance agent with his father-in law, Mr. John Tompkins, then President of Louisiana State Bank, Mississippi, which position he held until 1870, where he remained till 1907. In 1911 he became secretary of state under Governor Fort during that time. During all these four administrations he served as governor over three times before becoming Secretary of War. His first term expired March 4th last year after having filled out two terms by 'appointment from Washington's cabinet since its organization. This nomination took place April 6th following. On June 7th, 1912, there were only one candidates who had not made good their choice. They are: James H. Davis, ex-Governor, Honorable William J. Bryan, former Congressman from South Carolina, Hon. Wm. A. Jones, Judge Advocate General of Georgia, Drs. E. L. Bowers, Rufus S. Smith, C. F. Dickson, M. P. Williams, Jr., Thomas O'Neal, Henry Ketchum, Robert Gossett, Charles Nott, Frank Brownell, George Vann, Josephine Johnson, Louisa Knight, Arthur Woodall, Albert Anderson, Edward Whitehead, Chas. McPherson, Walter Clark, Harry Wilson, David Miller, and others. '
- Downloads last month
- 1,329