
Upload folder using huggingface_hub
#2
by
sharpenb
- opened
- README.md +1 -1
- config.json +1 -1
- model/optimized_model.pkl +2 -2
- model/smash_config.json +1 -1
- plots.png +0 -0
README.md
CHANGED
|
@@ -48,7 +48,7 @@ You can run the smashed model with these steps:
|
|
| 48 |
0. Check cuda, torch, packaging requirements are installed. For cuda, check with `nvcc --version` and install with `conda install nvidia/label/cuda-12.1.0::cuda`. For packaging and torch, run `pip install packaging torch`.
|
| 49 |
1. Install the `pruna-engine` available [here](https://pypi.org/project/pruna-engine/) on Pypi. It might take 15 minutes to install.
|
| 50 |
```bash
|
| 51 |
-
pip install pruna-engine[gpu] --extra-index-url https://pypi.nvidia.com --extra-index-url https://pypi.ngc.nvidia.com --extra-index-url https://prunaai.pythonanywhere.com/
|
| 52 |
```
|
| 53 |
3. Download the model files using one of these three options.
|
| 54 |
- Option 1 - Use command line interface (CLI):
|
|
|
|
| 48 |
0. Check cuda, torch, packaging requirements are installed. For cuda, check with `nvcc --version` and install with `conda install nvidia/label/cuda-12.1.0::cuda`. For packaging and torch, run `pip install packaging torch`.
|
| 49 |
1. Install the `pruna-engine` available [here](https://pypi.org/project/pruna-engine/) on Pypi. It might take 15 minutes to install.
|
| 50 |
```bash
|
| 51 |
+
pip install pruna-engine[gpu]==0.6.0 --extra-index-url https://pypi.nvidia.com --extra-index-url https://pypi.ngc.nvidia.com --extra-index-url https://prunaai.pythonanywhere.com/
|
| 52 |
```
|
| 53 |
3. Download the model files using one of these three options.
|
| 54 |
- Option 1 - Use command line interface (CLI):
|
config.json
CHANGED
|
@@ -1 +1 @@
|
|
| 1 |
-
{"pruners": "None", "pruning_ratio":
|
|
|
|
| 1 |
+
{"pruners": "None", "pruning_ratio": 0.0, "factorizers": "None", "quantizers": "None", "n_quantization_bits": 32, "output_deviation": 0.005, "compilers": "['diffusers2', 'tiling', 'step_caching']", "static_batch": true, "static_shape": false, "controlnet": "None", "unet_dim": 4, "device": "cuda", "batch_size": 1, "max_batch_size": 1, "image_height": 1024, "image_width": 1024, "version": "xl-1.0", "scheduler": "DDIM", "task": "txt2imgxl", "model_name": "stabilityai/sdxl-turbo", "weight_name": "None", "save_load_fn": "stable_fast"}
|
model/optimized_model.pkl
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5f1aae1c61a4815025854d8256d822cfa944ba47293b8faab2c1b93f36888549
|
| 3 |
+
size 6943177992
|
model/smash_config.json
CHANGED
|
@@ -1 +1 @@
|
|
| 1 |
-
{"api_key": "pruna_c4c77860c62a2965f6bc281841ee1d7bd3", "verify_url": "http://johnrachwan.pythonanywhere.com", "smash_config": {"pruners": "None", "pruning_ratio":
|
|
|
|
| 1 |
+
{"api_key": "pruna_c4c77860c62a2965f6bc281841ee1d7bd3", "verify_url": "http://johnrachwan.pythonanywhere.com", "smash_config": {"pruners": "None", "pruning_ratio": 0.0, "factorizers": "None", "quantizers": "None", "n_quantization_bits": 32, "output_deviation": 0.005, "compilers": "['diffusers2', 'tiling', 'step_caching']", "static_batch": true, "static_shape": false, "controlnet": "None", "unet_dim": 4, "device": "cuda", "cache_dir": ".models/optimized_model", "batch_size": 1, "max_batch_size": 1, "image_height": 1024, "image_width": 1024, "version": "xl-1.0", "scheduler": "DDIM", "task": "txt2imgxl", "model_name": "stabilityai/sdxl-turbo", "weight_name": "None", "save_load_fn": "stable_fast"}}
|
plots.png
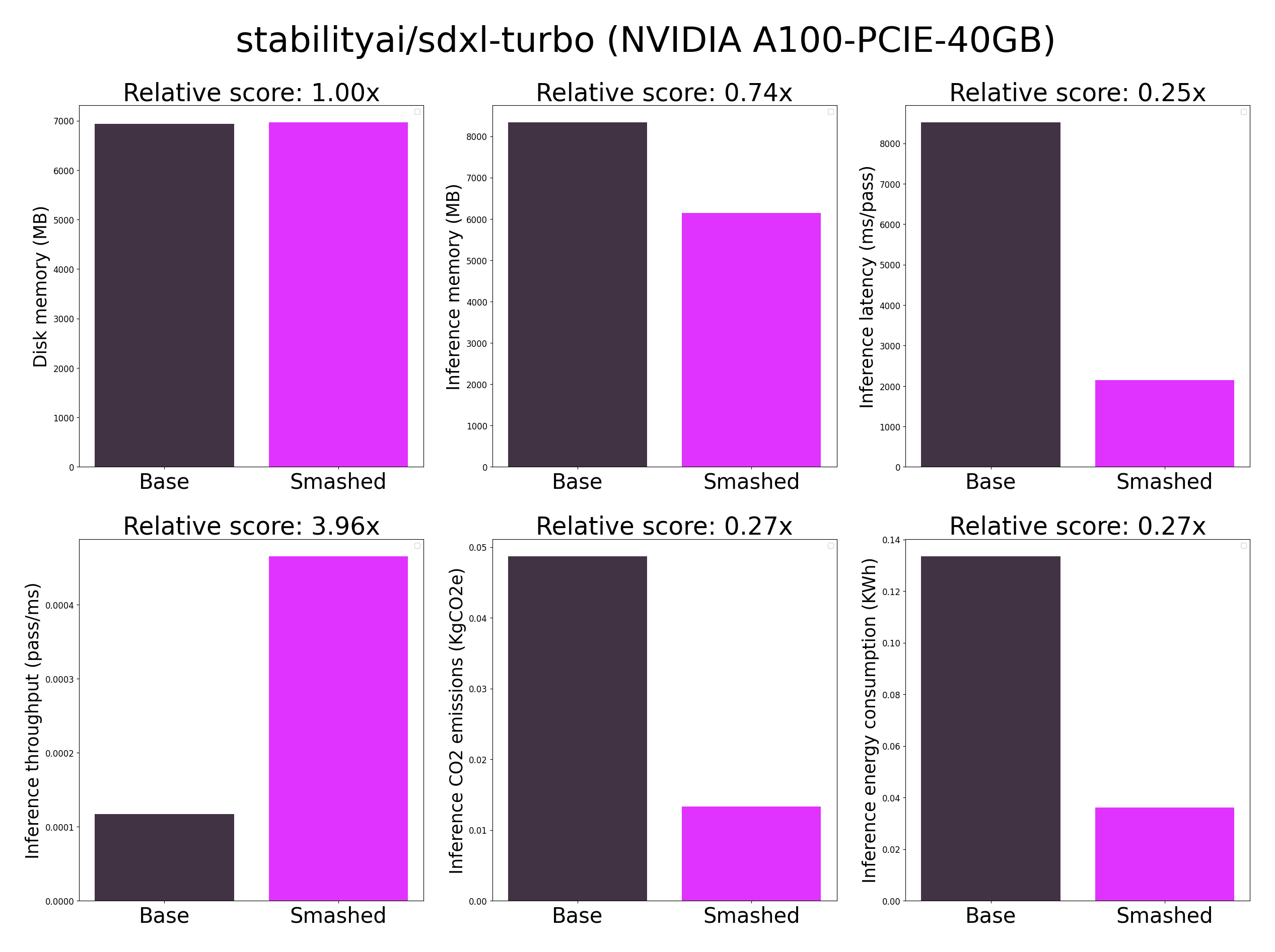
CHANGED

|
|