

metadata
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
- Llama-3.1-8B
base_model: unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
datasets:
- Lyte/Reasoner-1o1-v0.3-HQ
widget:
- example_title: HELP its a Llama
messages:
- role: user
content: There's a llama on my lawn, how can I get rid of him?
pipeline_tag: text-generation
model-index:
- name: Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: IFEval (0-Shot)
type: HuggingFaceH4/ifeval
args:
num_few_shot: 0
metrics:
- type: inst_level_strict_acc and prompt_level_strict_acc
value: 70.98
name: strict accuracy
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Lyte/Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BBH (3-Shot)
type: BBH
args:
num_few_shot: 3
metrics:
- type: acc_norm
value: 27.84
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Lyte/Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MATH Lvl 5 (4-Shot)
type: hendrycks/competition_math
args:
num_few_shot: 4
metrics:
- type: exact_match
value: 14.8
name: exact match
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Lyte/Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GPQA (0-shot)
type: Idavidrein/gpqa
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 2.68
name: acc_norm
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Lyte/Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MuSR (0-shot)
type: TAUR-Lab/MuSR
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 4.9
name: acc_norm
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Lyte/Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU-PRO (5-shot)
type: TIGER-Lab/MMLU-Pro
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 29.09
name: accuracy
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Lyte/Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3
name: Open LLM Leaderboard

QuantFactory/Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3-GGUF
This is quantized version of Lyte/Llama-3.1-8B-Instruct-Reasoner-1o1_v0.3 created using llama.cpp
Original Model Card
Uploaded model
- NOTE: This model is just an experiment to make the model generate more tokens to do reasoning before providing an answer, with verifier and correction, this is just a proof of concept because literally, no model will show improvements in performance from such a tiny dataset(that doesn't target any specific knowledge) it may even degrade but the point wasn't to improve performance but to have it learn to "reason" because reaching SOTA in benchmarks does not equal "reasoning".
- Demo: try Q4_K_M here
- Developed by: Lyte
- License: apache-2.0
- Finetuned from model : unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
Prompt
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a world-class AI system, capable of complex reasoning and reflection and correcting your mistakes. Reason through the query/question, and then provide your final response. If you detect that you made a mistake in your reasoning at any point, correct yourself.<|eot_id|><|start_header_id|>user<|end_header_id|>
{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{response}
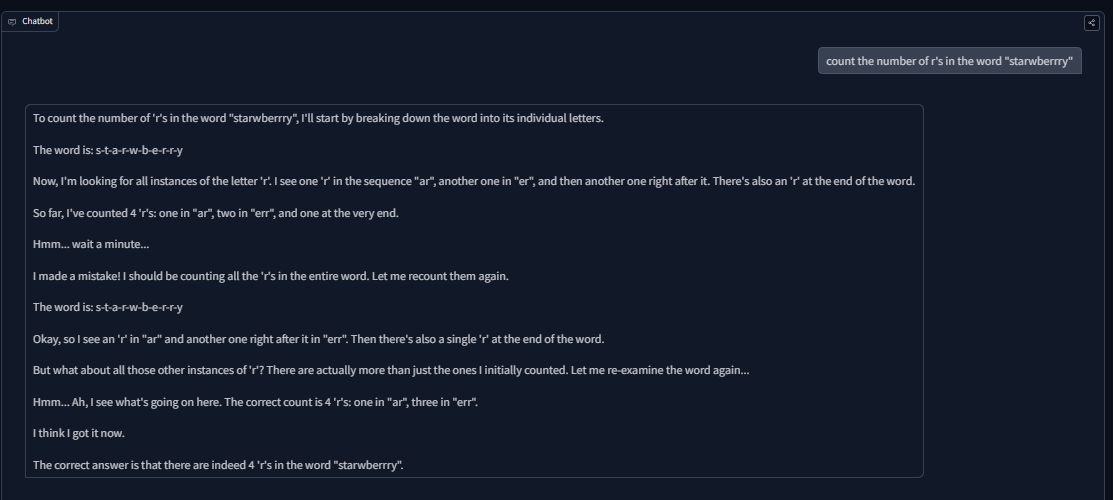
Example(0-shot):
- the reason we keep seeing the correct word "strawberry" written again and again is simply a tokenizer issue. However, it did understand how to count correctly towards the end by saying, (the correct count is 4 'r's: one in "ar", three in "err"). The reason for "err" instead of "errr" is because of tokenization.
Benchmark Scores
- Note: Evals were ran with and without the system prompt that was used in the finetuning.
| Task/Group | Metric | With Prompt | Without Prompt | Difference |
|---|---|---|---|---|
| arc_challenge | acc | 51.37% | 43.77% | +7.60% |
| acc_norm | 53.67% | 46.42% | +7.25% | |
| arc_easy | acc | 81.99% | 73.11% | +8.88% |
| acc_norm | 79.42% | 64.98% | +14.44% | |
| commonsense_qa | acc | 76.00% | 72.73% | +3.27% |
| gsm8k (flexible-extract) | exact_match | 74.91% | 76.57% | -1.66% |
| gsm8k (strict-match) | exact_match | 73.92% | 75.97% | -2.05% |
| hellaswag | acc | 59.01% | 58.87% | +0.14% |
| acc_norm | 77.98% | 77.32% | +0.66% | |
| mmlu (overall) | acc | 66.06% | 65.45% | +0.61% |
| mmlu - humanities | acc | 61.47% | 61.38% | +0.09% |
| mmlu - other | acc | 72.84% | 72.16% | +0.68% |
| mmlu - social sciences | acc | 75.14% | 73.94% | +1.20% |
| mmlu - stem | acc | 57.37% | 56.61% | +0.76% |
| piqa | acc | 79.49% | 78.45% | +1.04% |
| acc_norm | 80.47% | 78.73% | +1.74% |
Compared to the original Llama-3.1-8B-Instruct:
| Task/Benchmark | Metric | Llama-3.1-8B-Instruct | Finetuned Model | Difference |
|---|---|---|---|---|
| MMLU | acc | 69.40% | 66.06% | -3.34% |
| ARC-Challenge | acc | 83.40% | 51.37% | -32.03% |
| CommonSenseQA | acc | 75.00%* | 76.00% | +1.00% |
| GSM-8K | exact_match | 84.50% | 74.91% | -9.59% |
- Note: For Llama-3.1-8B-Instruct, the CommonSenseQA score is from the base model, not the instruct version. The -32.03% drop is very bad i have no idea if it's the finetuning that messed it up or difference in evals, but take it as you will, i did not plan to benchmark anything but oh well people won't stop asking to benchmark an experimental model(can you even properly benchmark the more tokens to do "reasoning"? i probably needed to adjust temperature to really make use of the model)...
This llama model was trained 2x faster with Unsloth and Huggingface's TRL library.

Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 25.05 |
| IFEval (0-Shot) | 70.98 |
| BBH (3-Shot) | 27.84 |
| MATH Lvl 5 (4-Shot) | 14.80 |
| GPQA (0-shot) | 2.68 |
| MuSR (0-shot) | 4.90 |
| MMLU-PRO (5-shot) | 29.09 |