
Model Card for SNOWTEAM/sft_medico-mistral
Overview
SNOWTEAM/sft_medico-mistral is a specialized language model designed for medical applications, further refined through instruction tuning to enhance its ability to respond to various medical-related instructions. This tuning leverages the embedded medical knowledge within the Medico-mistral model, focusing on medical consulting conversations, medical rationale QA, and medical knowledge graph prompting.
Model Description
Base Model: Medico-mistral
Model type: Transformer-based decoder-only language model
Language(s) (NLP): English
How to Get Started with the Model
import transformers
import torch
model_path = "SNOWTEAM/sft_medico-mistral"
model = AutoModelForCausalLM.from_pretrained(
model_path,device_map="auto",
max_memory=max_memory_mapping,
torch_dtype=torch.float16,
)
tokenizer = AutoTokenizer.from_pretrained("SNOWTEAM/sft_medico-mistral")
input_text = ""
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
output_ids = model.generate(input_ids=input_ids.cuda(),
max_new_tokens=300,
pad_token_id=tokenizer.eos_token_id,)
output_text = tokenizer.batch_decode(output_ids[:, input_ids.shape[1]:],skip_special_tokens=True)[0]
print(output_text)
Instruction Tuning Datasets
Using open source instruction tuning datasets are composed of 4 main parts: (Some datasets are from https://huggingface.co/datasets/axiong/pmc_llama_instructions)
Medical Questions and Answering Data:
Consider enhancing the model with the capability to reason about professional medical knowledge. We begin with training datasets from open-source medical multiple-choice question-answering sources such as USMLE (Jin, Pan et al., 2021), PubMedQA (Jin et al., 2019), and MedMCQA (Pal, Umapathi et al., 2022). While these datasets inherently require specific medical knowledge, they primarily feature simple choices and lack comprehensive reasoning guidance. To address this, researchers at PMC-llama employed ChatGPT for causal analysis (Chaoyi et al. 2023). Specifically, ChatGPT is queried to generate reasoning outputs for each QA pair, which are then structured and used as explanations.
Medical Knowledge Graph Data:
We wish to utilize medical knowledge maps such as UMLS (Lindberg, Humphreys, and McCray, 1993) to align with clinicians' expertise. Specifically, we focused on linking medical terms to their respective knowledge descriptions or correlations. For this purpose, we used the QA pair dataset of the Translation General Knowledge Graph created by PMC-LLAMA (Chaoyi et al. 2023). Medical knowledge graphs consist of two main types: entity descriptions and entity relationships. The dataset incorporates two different prompts that ask the model to provide a description of a specific entity or predict a relationship between two entities.
Single-turn Medical Dialogue Data:
In patient-doctor conversations, patients often describe their symptoms in a colloquial and brief manner. When synthetic patient-doctor conversation datasets are manually created, they tend to lack diversity and become overly specialized, making them less reflective of real-life scenarios. A more effective approach is to collect real patient-doctor conversations. The \textit{HealthCareMagic-100k} dataset addresses this by gathering approximately 100,000 genuine doctor-patient interactions from online medical advice websites. These conversations were filtered manually and automatically to remove identifiers and corrected for grammatical errors using a language tool. Additionally, around 10,000 conversations from the online medical advice website iCliniq were collected and 5k conversations between patients and doctors were generated via ChatGPT by ChatDoctor for supplementation and evaluation (Yunxiang et al. 2023).
Multi-turn Medical Dialogue Data:(This data was not used to train this version of the model)
The only model currently trained using a multi-round dialog dataset is the Zhongjing-LLaMA model(Songhua et al. 2023). This model uses the CMtMedQA dataset, which is the first large-scale multi-round TCM QA dataset suitable for LLM training, and can significantly enhance the model's multi-round QA capability. However, this dataset collects data for online QA conversations, and lacks the ability to understand pathology examination, or image examination results, which has limitations in real clinical QA situations. Therefore, we used real electronic medical record EMRs obtained from hospitals, rewritten into multi-round conversations by prompting gpt.When designing the prompts, in order to standardize the questioning process and improve the differential diagnosis accuracy, we referred to the Mini-CEX, a clinical questioning assessment index used in medical schools, and the LLM-Mini-CEX, a new criterion that has been modified specifically for large language models (Xiaoming et al. 2023).
Medical-Specific Instruction Tuning
By combining the above three parts, we form a large-scale, high-quality, medical-specific instruction tuning dataset. We further tune Medico-mistral on this dataset, resulting in sft_medico-mistral.
Training Details
Our model is based on Mixtral-8x7B-v0.1-Instruct, a generic English LLM with 13 billion parameters. Training was performed on 8 A100-80G GPUs via parallelization. We first inject knowledge into the base model Mistral to optimize the autoregressive loss. During training, we set the maximum context length to 4096 and the batch size to 1024. the model was trained using the AdamW optimizer (Loshchilov and Hutter, 2017) with a learning rate of 2e-5. we employed a fully-sliced data parallel (FSDP) acceleration strategy, the bf16 (brain floating-point) data format, and gradient checkpoints ( Chen et al. 2016). The model was trained using 8 A100 GPUs for 1 epoch of knowledge injection. Afterwards, we used 7 A100 GPUs to perform 5 epochs of healthcare-specific instruction tuning in the SFT phase with a batch size of 896 . During the instruction tuning phase, all sequences are processed in each epoch.
Training Data
The training data combines diverse datasets from medical consultations, rationale QA, and knowledge graphs to ensure comprehensive medical knowledge coverage and reasoning ability.
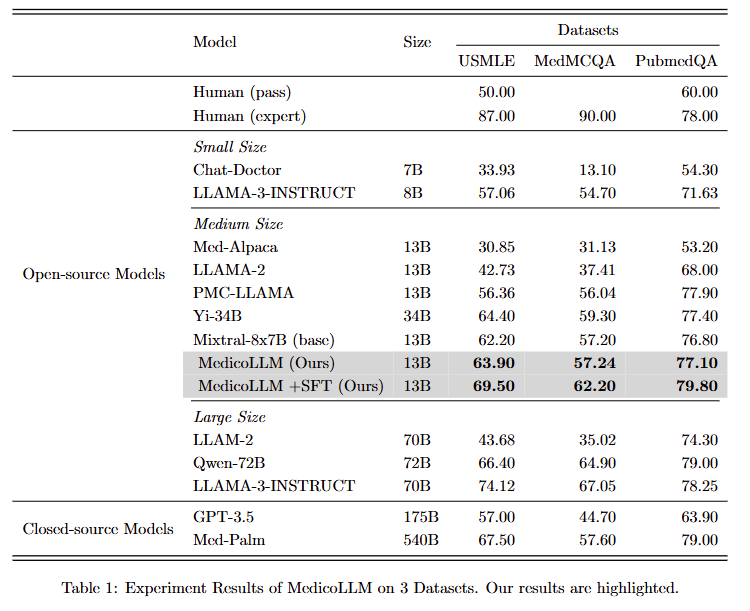
Result
Model Sources
Repository: https://huggingface.co/SNOWTEAM/sft_medico-mistral
Paper [optional]:
Demo [optional]:
- Downloads last month
- 12