
Mamba-1.4B
The original Mamba model trained on over 1T tokens, mostly in English and Russian.
This release contains only the pre-trained part of the model. It doesn’t include any instructions following tuning. Feel free to try it out and share your results.
Note that this is a ~1.3B model, which is why its results can be worse than those of models with 7B parameters. However, model is competitive among models of the same size.
If you have any questions, feel free to open an issue.
Model description
Model has the same architecture and config parameters as the original Mamba-1.4B model. The only difference is the vocabulary size, which is 50,280 in the vanilla configuration and 32,768 in model. As a result, model has fewer parameters (1.34B).
This model was trained with the original implementation with the FSDP strategy.
Training details:
- Effective batch size was 1024 and the sequence length was 2048, resulting in 2M tokens per batch.
- Training was conducted for 500,000 steps, resulting in more than 1T tokens.
- Learning rate scheduler was set up as follows:
- Warmup for the first 2500 steps from 0 to 2e-4.
- Graceful decrease to 1.8e-5 until step 497,500.
- Cooldown to 0 for the last 2500 steps.
- We use BF16 for training, but keep the gradient and buffer in FP32 for stability.
How to use
You need to install transformers version 4.39.0 or higher. We also recommend you to install optimized kernels: both causal_conv_1d and mamba-ssm.
pip install transformers>=4.39.0
pip install causal-conv1d>=1.2.0
pip install mamba-ssm
After that, you can use the classic generate API. Refer to the documentation of the original model for more details.
from transformers import MambaForCausalLM, AutoTokenizer
model = MambaForCausalLM.from_pretrained("SpirinEgor/mamba-1.4b")
tokenizer = AutoTokenizer.from_pretrained("SpirinEgor/mamba-1.4b")
s = "Я очень люблю лимончелло"
input_ids = tokenizer(s, return_tensors="pt")["input_ids"]
output_ids = model.generate(input_ids, max_new_tokens=50, do_sample=True, top_p=0.95, top_k=50, repetition_penalty=1.1)
print(tokenizer.decode(output_ids[0]))
# <s> Я очень люблю лимончелло. Просто без ума от этого ликёра, но когда его много я себя не контролирую и начинаю пить всё что можно.</s>
Dataset
The training dataset contains data mainly in English and Russian, as well as code and multilingual content. We use a combination of open-source datasets, e.g., parts of SlimPajama, Wikipedia, Reddit, etc.
| Language | Part |
|---|---|
| Russian | 53.5% |
| English | 36.8% |
| Source Code | 4.2% |
| Other | 5.5% |
Evaluation
For evaluation, we use the same set of tasks as in the original paper.
Some useful notes and details:
- As proposed in the paper, all tasks are zero-shot, unlike in the popular Open LLM Leaderboard. Therefore, it is impossible to compare these models based on just the numbers from the leaderboards.
- Only some tasks were used for the Russian language. These were translated and edited analogues.
- For evaluation, up to 3B parameters models were used. Bigger models show significantly better results for both languages.
If you want to reproduce the results or check any other model, you can use the lm-evaluation-harness framework.
We ran it with the following parameters:
--tasks lambada_openai,hellaswag,piqa,arc_easy,arc_challenge,winogrande --num_fewshot 0 --batch_size 4
Hover over the small plots to enlarge them.
Russian
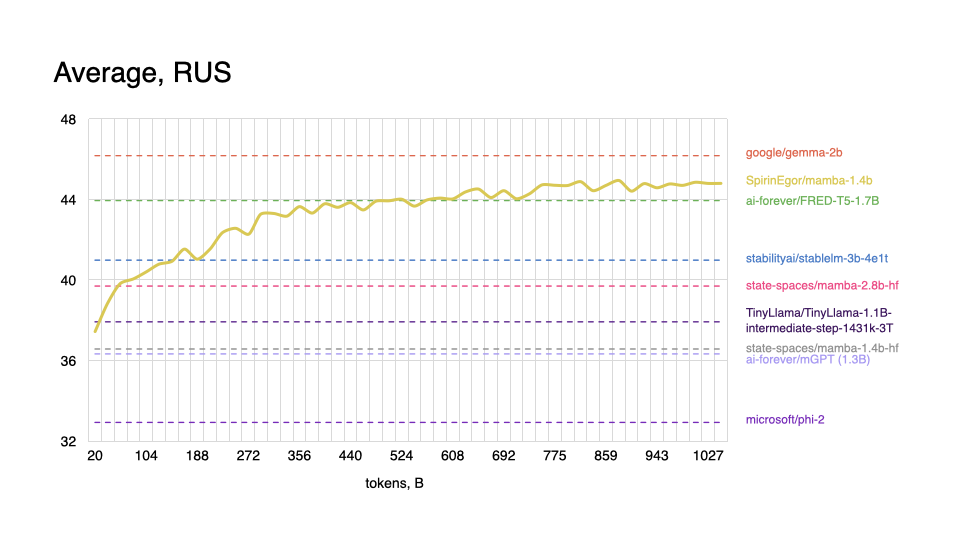
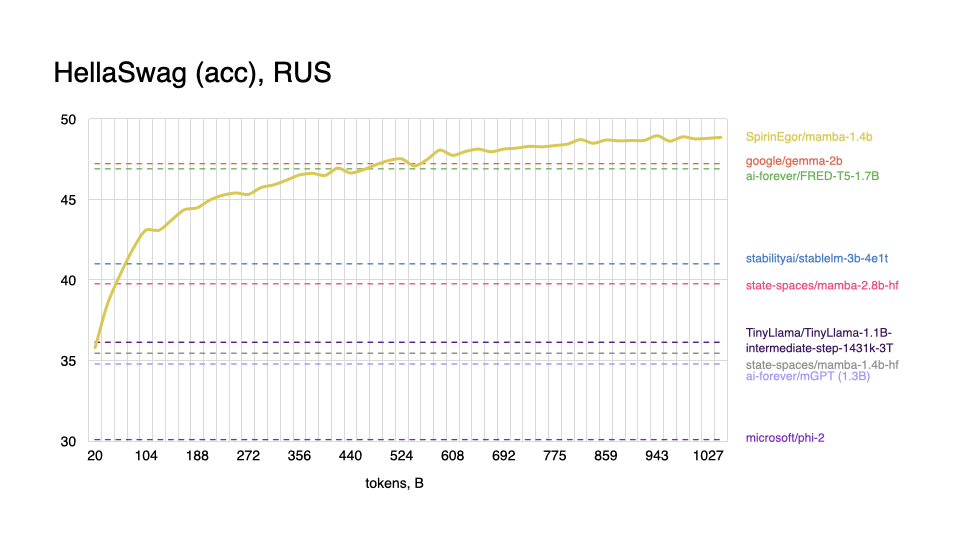
|
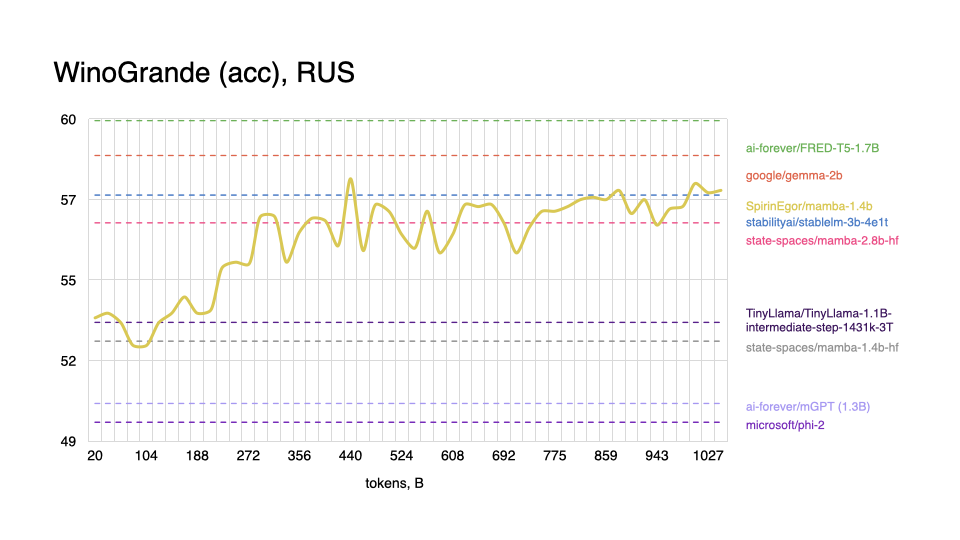
|
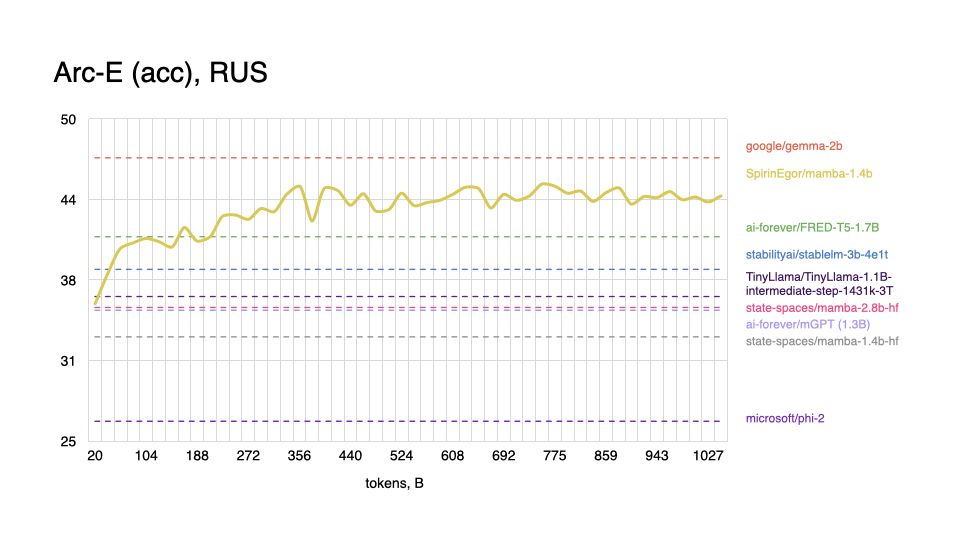
|
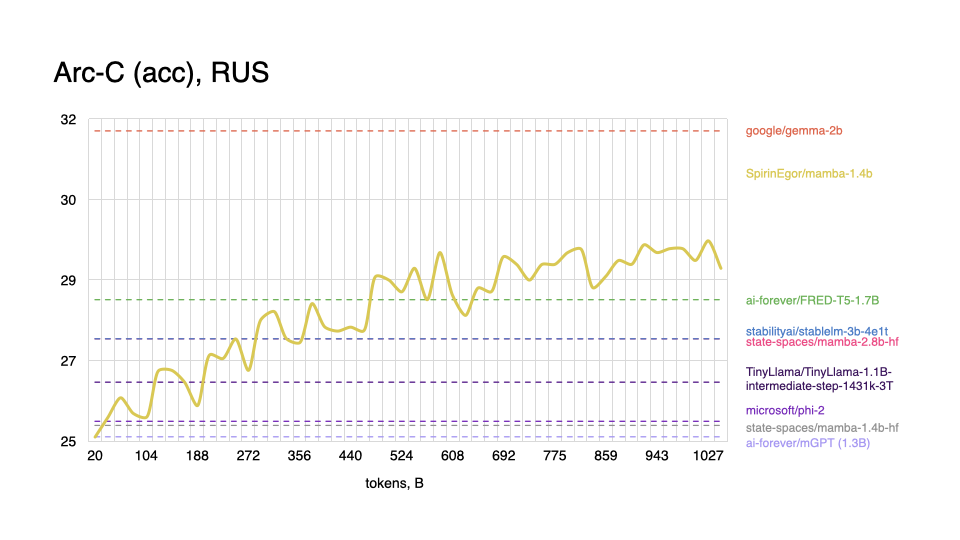
|
English
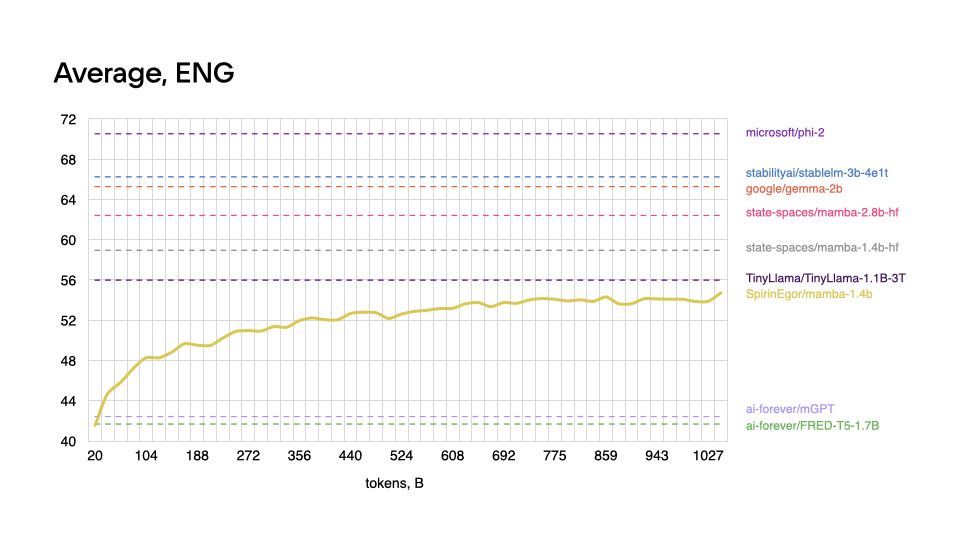
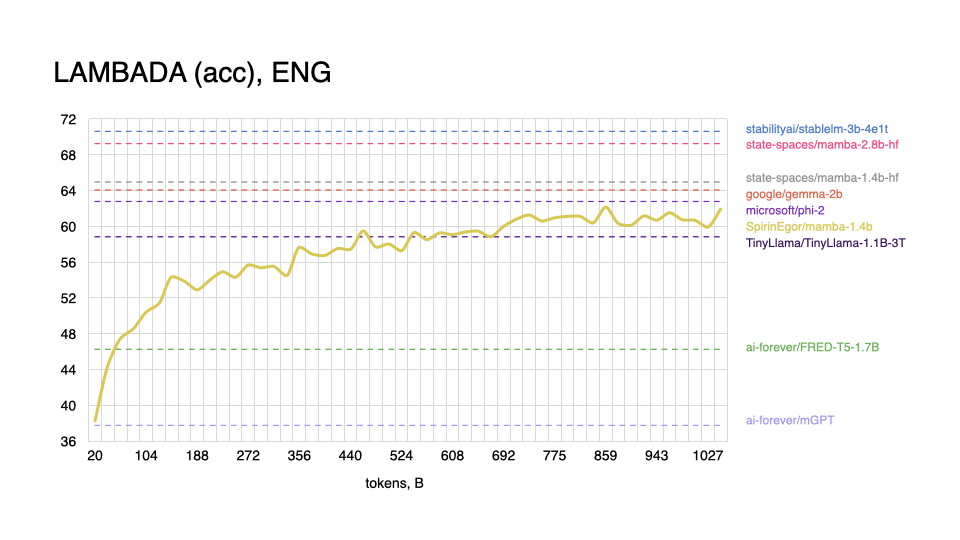
|
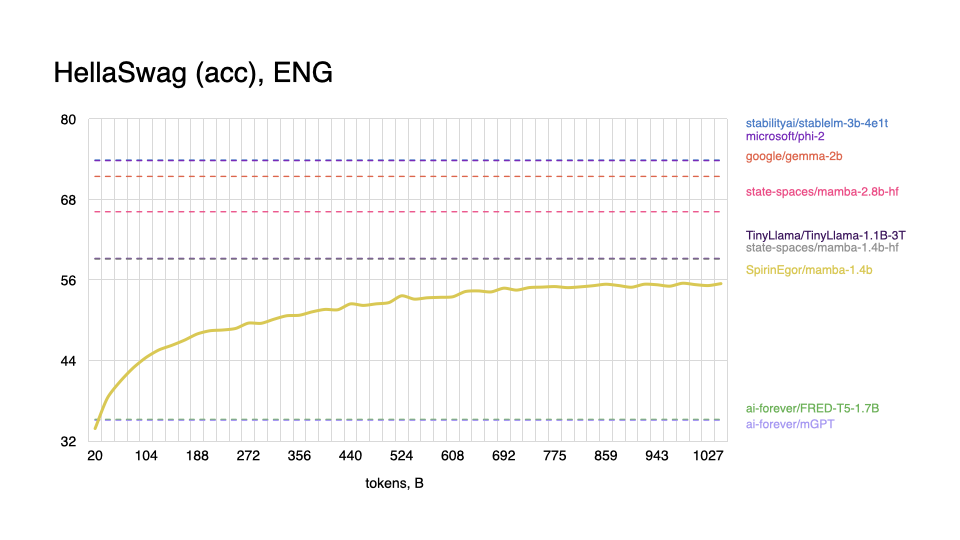
|
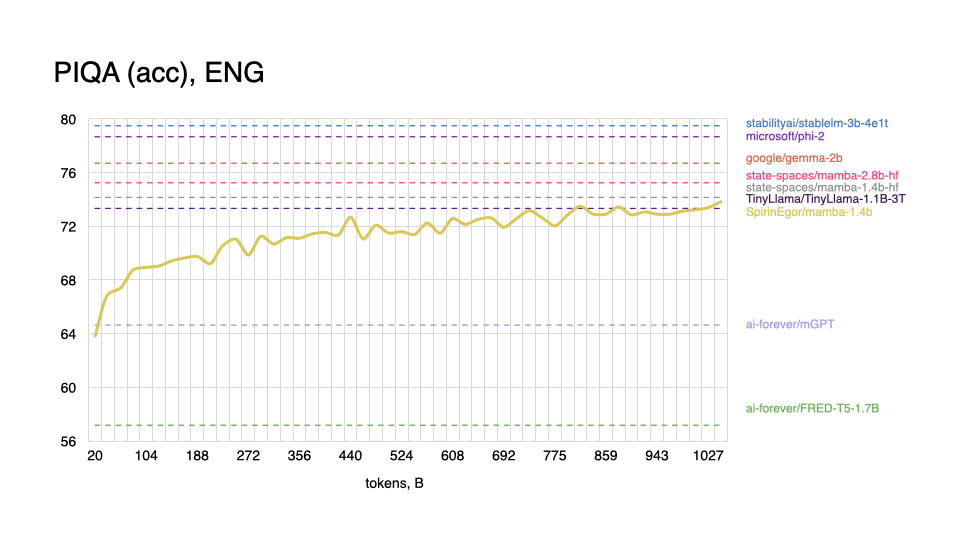
|
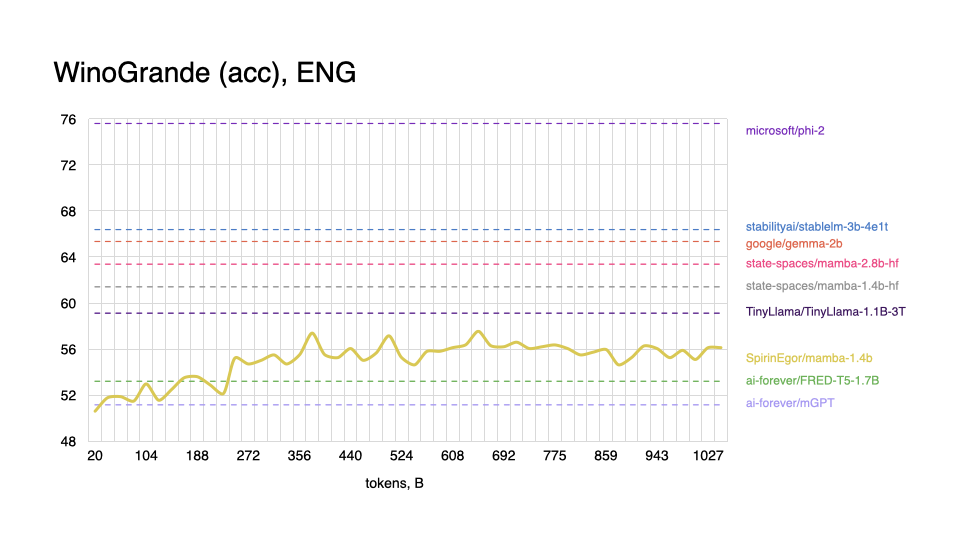
|
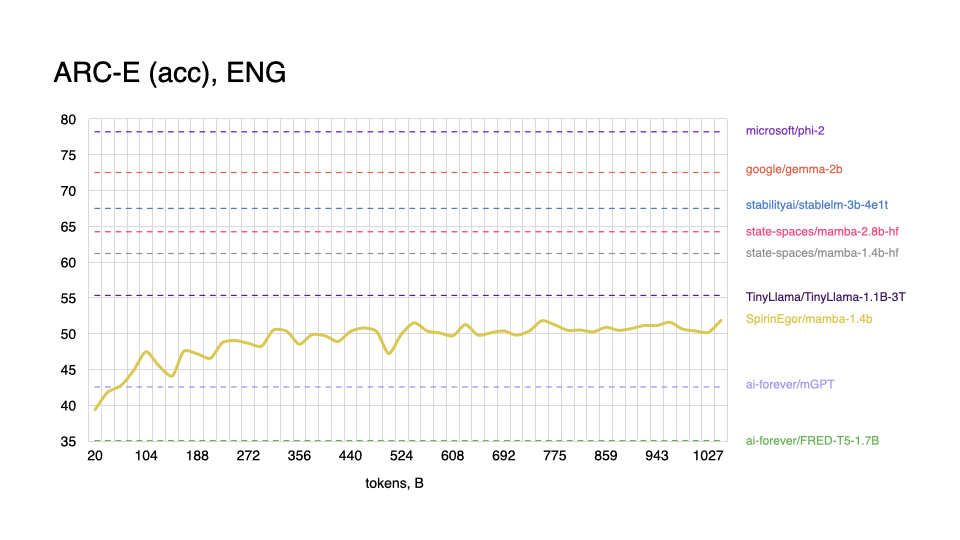
|
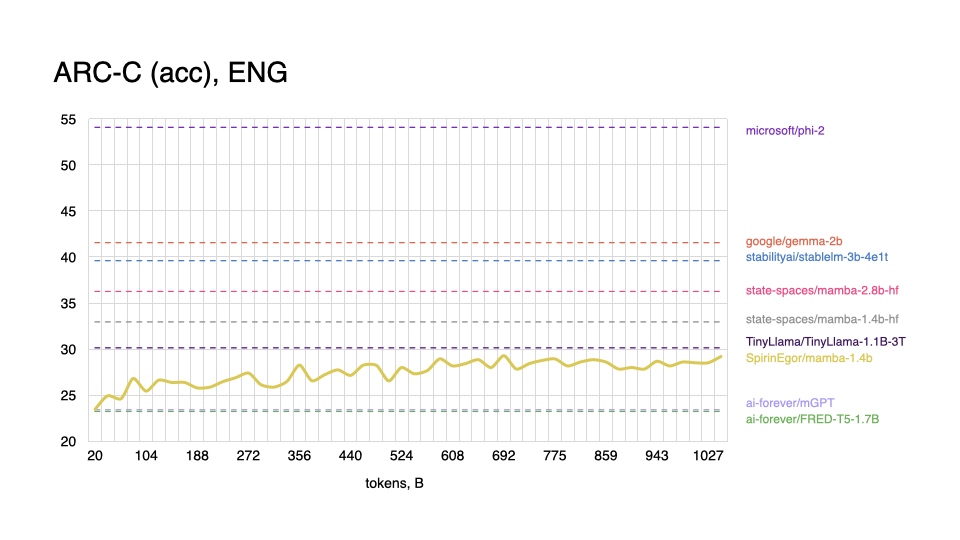
|
As expected, model performs worse on tasks in the English language, and shows better results with Russian, even outperforming some popular models.
Citation
@article{mamba,
title={Mamba: Linear-Time Sequence Modeling with Selective State Spaces},
author={Gu, Albert and Dao, Tri},
journal={arXiv preprint arXiv:2312.00752},
year={2023}
}
@misc{spirin2024mamba_ru,
title={mamba-1.4b-ru},
author={Spirin, Egor},
url={https://huggingface.co/SpirinEgor/mamba-1.4b},
publisher={Hugging Face}
year={2024},
}
- Downloads last month
- 108