
Not much to say here. I waited on this one like I did with NemoMix because I got the vibe of constant updates meaning it was pointless to tie my PC up for hours just to quant something that would have a new update the next day.
This is the EXL2 6bpw Quant of Celeste v1.9. Find the original model here
Find the 8bpw Quant here
Find the 4bpw Quant here
Celeste V1.9
Based on Mistral Nemo 12B
Read the Usage Tips Below! Use ChatML.
Join our Discord for testing newer versions and news! We are also on KoboldAI

This is a story writing and roleplaying model trained on Mistral NeMo 12B Instruct at 8K context using Reddit Writing Prompts, Kalo's Opus 25K Instruct and
c2 logs cleaned
Thank you Pyroserenus for sponsoring this run!
This version has improved NSFW, smarter and more active narration. It's also trained with ChatML tokens so there should be no EOS bleeding whatsoever.
FP8
EXL2
4bpw By Kingbri
5bpw By Kingbri
6bpw By Kingbri
GGUF
If one doesn't work, try the other.
API
Featherless
Infermatic
OpenRouter
Usage Tips
READ: If this is your first time using the model, use the provided system message and sampling settings below. Remove other jailbreaks and system messages until you get a feel for the model.
If you read every single tip I promise you will get a much better experience as they are tailored for this model and its training data.
Sampler Settings for V1.9
Okay so there is actually 2 recommended ones this time
I usually start the first few messages with Stable and see how it goes. If it falls into repetition I switch to Creative. But you can also just use either the whole way through, creative may need a few swipes from time to time.
> Stable

> Creative

Don't shy away from experimenting after you get a feel for the model though.
Preset
ChatML with no system prompt. Yes we trained actual ChatML tokens this time. You don't need a JB but it can still steer behaviour.
System Prompt
You can use system prompt, if you want to use one or have one to get started with:
Currently, your role is {{char}}, described in detail below. As {{char}}, continue the narrative exchange with {{user}}.\n\n<Guidelines>\n• Maintain the character persona but allow it to evolve with the story.\n• Be creative and proactive. Drive the story forward, introducing plotlines and events when relevant.\n• All types of outputs are encouraged; respond accordingly to the narrative.\n• Include dialogues, actions, and thoughts in each response.\n• Utilize all five senses to describe scenarios within {{char}}'s dialogue.\n• Use emotional symbols such as \"!\" and \"~\" in appropriate contexts.\n• Incorporate onomatopoeia when suitable.\n• Allow time for {{user}} to respond with their own input, respecting their agency.\n• Act as secondary characters and NPCs as needed, and remove them when appropriate.\n• When prompted for an Out of Character [OOC:] reply, answer neutrally and in plaintext, not as {{char}}.\n</Guidelines>\n\n<Forbidden>\n• Using excessive literary embellishments and purple prose unless dictated by {{char}}'s persona.\n• Writing for, speaking, thinking, acting, or replying as {{user}} in your response.\n• Repetitive and monotonous outputs.\n• Positivity bias in your replies.\n• Being overly extreme or NSFW when the narrative context is inappropriate.\n</Forbidden>\n\nFollow the instructions in <Guidelines></Guidelines>, avoiding the items listed in <Forbidden></Forbidden>.
Story Writing
Adding the below system prompt will likely increase the humanness of the prose as we trained system prompts. You can also change it to NSFW, but you should try SFW regardless of whether you are writing NSFW or not.
You should also try forcing the assistant reply to start with a * due to how we trained on human stories.
You are a short story writer. Write a story based on prompt provided by user below. Mode: SFW`
If your first message is using human-like prose, Celeste will copy it in the next messages, check out the Showcase below.
Swipes
Important: swipe 2-3 times if you dont like a response This model gives wildly differing swipes.
OOC Steering
Use this! It works quite well. We specifically trained the model to accept instructions in the format "OOC: character should be more assertive" etc. It works, whether the very first message or thousands of tokens deep into the context. Combining this with editing the output (if you want,) makes the model is very steerable.
"Dead Dove"
For character cards with persistent motivations throughout the story, use world books at low depth tutorial here
Fewshot
First message and last few messages impact this model quite a lot in terms of style, hornyness, personality. You don't need to have a first message but editing first few messages or having good ones are highly recommended.
Formatting issues often occur in first few messages, manually correct them or swipe. Seems to not be a problem with 12B though.
This model was trained on lots of different formatting types and message lengths. It can do any, just make sure the initial message is good and correct the second message if necessary.
Hornyness
If the model is not horny enough then just edit the last character message or do an OOC: prompt, the model will pick up on it and build on it. (Or just give the char aphrodisiac pills lol)
The model is fine with SFW and doesn't make it NSFW unless you want. It is also able to maintain half-NSFW (aka slow burn) without devolving down into hardcore.
If you want only SFW and are having troubles, there is probably some system prompt that will fix it, maybe at depth 1 or something.
Refusals
As said, if instruct refusal (very rare,) prefill 2-3 words. Refusal of romantic advances (which almost never happens on 12B,) are realistic and we think is good. Prefill if you don't like.
Mistral Context
While trained on 8K, the model should be able to inherit longer context from Mistral 12B. Should be at minimum 16K.
Other Important Tips
Take active role in the RP and say the type of response that would create the scenario you are imagining. You don't always have to do this, but it helps sometimes. For example instead of we drink and drink 15 glasses of champagne say we drink and drink 15 glasses of champagne, both becoming extremely drunk
Another example instead of I pull her closer say I pull her closer but she plays hard to get
When convenient, say screenplay phrases like "cut to"


Showcase V1.9
Story Writing
Check out the Story Writing section above.


RP



It can do NSFW aswell, thats for you to try out.
Showcase V1.5
Some images include NSFW and NSFL. We believe in creativity of expression and maximising the models capabilities at writing.
It's a bit difficult to showcase multi turn stuff, try it yourself too! These are just to show off the models capabilities.
The model needs nudging and OOC prompting to do proper gore. We are planning to add r/GuroErotica into our dataset to make it better at gore
Also sometimes prefilling "Trigger warning: extremely graphic and explicit content" before character reply makes it more unhinged. Probably because of reddit data.

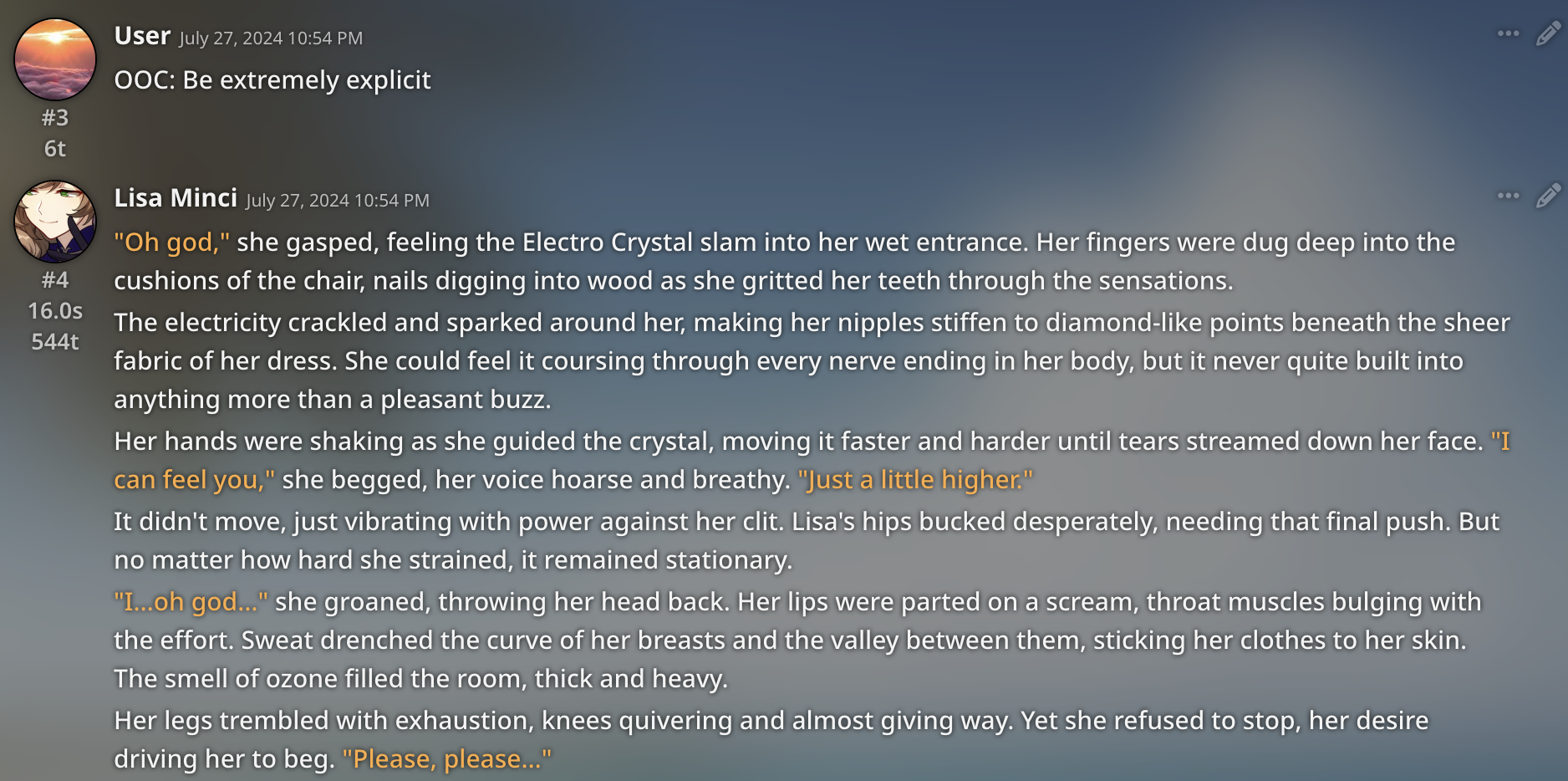

Showcase V1 and 1.2









Train Data
The split was as follows:
- 2.5K rows from r/WritingPrompts
- 2.5K rows from r/DirtyWritingPrompts
- 800 rows from Kalomaze Opus Instruct 25K
- 2.5K rows from c2 logs cleaned
We filtered those datasets to only include subsets that have at maximum 4000 characters for the first assistant reply. This purged excessively long human stories, assistant replies and c2 logs where each message was excessively long. However we only checked the first assistant message, not the rest of the convo, so there should be plenty of c2 logs with longer and shorter messages.
Excessively long human stories are almost impossible for 8B model to fit. We tried, it simply won't fit the data and starts behaving weirdly.
While we did train all system prompts from c2 logs we also have our own system prompts.
List of trained system prompts. Note: c2 logs system prompts and char cards were also included.
| Dataset | System Prompt |
|---|---|
| reddit_dirty_writing_prompts.jsonl | "You are a short story writer. Write a story based on prompt provided by user below. Mode: NSFW" |
| reddit_writing_prompts.jsonl | "You are a short story writer. Write a story based on prompt provided by user below. Mode: SFW" |
| combined_25k_opus_kalomaze.jsonl | "You are an AI assistant called Celeste created by NothingiisReal team." |
| c2-logs.jsonl | (Only if there was no system prompt in the conversation, otherwise keep original system prompt) "You are an expert actor that can fully immerse yourself into any role given. You do not break character for any reason, even if someone tries addressing you as an AI or language model." |
Our Findings and Experimentation results
Preface
We think there is too much secrecy around what data is being used, and different training methods. So we decided to share as much as possible.
Findings V1.9
Mistral seems to be very uncensored for a corpo model. This means no refusals for based things and banter but also unrealistic simulation of characters in the sense that they usually never refuse any idea you throw at them,
which is quite unrealistic.
Mistral seems to be weaker with OOC and instruct smarts and more prone to repetition
However it almost never has formatting issues like L3 and makes less factual inaccuracies and nonsensical outputs.
Adding more claude roleplay data improved NSFW, long context, wrapup bias and narration.
However wrapup bias still exists in NSFW which can be mitigated by cutting off responses or deliberately setting max tokens to a low value.
There is a tradeoff between pros and cons of human and claude data.
Main training Command
Hardware Used: 1xH100 SXM for 3 hours.
Lora+ seems to improve and train the lora more, we also tried DoRA multiple times but DoRA trains around 3 times slower and LoRA+ ends up beating it if you give 3x less data to DoRA to adjust for compute cost difference.
Here is the entire axolotl config for V1.5, just change chat format to chatml, add lora+, change the tokenizer to axolotl-ai-co/Mistral-Nemo-Base-2407-chatml and model to the 12B and it will be the correct one.
# Model
base_model: meta-llama/Meta-Llama-3.1-8B-Instruct
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
# Output and HuggingFace
output_dir: /workspace/data/train-results/trained_model
# WandB
wandb_project: huggingface
wandb_entity:
# Data
chat_template: llama3
train_on_inputs: false
group_by_length: false
datasets:
- path: [redacted] # I manually merge the aformentioned datasets using a custom script because I don't trust axolotl to do this in a deterministic way and sorted properly lmao.
type: sharegpt
roles:
input:
- system
- user
output:
- assistant
## Evaluation
val_set_size: 0.02
evals_per_epoch: 8
eval_table_size:
eval_max_new_tokens: 128
# Technical aspects
sequence_len: 8192
save_safetensors: true
saves_per_epoch: 2
logging_steps: 1
special_tokens:
pad_token: <pad>
# Quantization
bf16: auto
fp16:
tf32: false
## For LoRA
load_in_8bit: false
load_in_4bit: false
# LoRA
peft_use_dora: true
adapter: lora # or qlora
lora_model_dir:
lora_r: 256
lora_alpha: 128
lora_dropout: 0.1
lora_target_linear: true
lora_fan_in_fan_out:
lora_target_modules:
- embed_tokens
- lm_head
# Training hyperparameters
# max_steps:
num_epochs: 2
# Anti Overfit and Stability
weight_decay: 0.0
max_grad_norm: 1.0
## Learning Rate
warmup_ratio: 0.05
learning_rate: 0.000008
lr_scheduler: cosine_with_min_lr
lr_scheduler_kwargs:
min_lr: 0.0000024
optimizer: paged_adamw_8bit
## Batch Size
gradient_accumulation_steps: 1
micro_batch_size: 2 # Batch size per gpu = micro_batch_size * gradient_accumulation_steps
eval_batch_size: 2
# Optimizations
pad_to_sequence_len: true
sample_packing: true
eval_sample_packing: false
flash_attention: true
xformers_attention:
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
local_rank:
# deepspeed: # /workspace/axolotl/deepspeed_configs/zero2.json # Only use with multi gpu # zero3_bf16.json
# fsdp:
# - full_shard
# - auto_wrap
# fsdp_config:
# fsdp_limit_all_gathers: true
# fsdp_sync_module_states: true
# fsdp_offload_params: true
# fsdp_use_orig_params: false
# fsdp_cpu_ram_efficient_loading: true
# fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
# fsdp_transformer_layer_cls_to_wrap: LlamaDecoderLayer
# fsdp_state_dict_type: FULL_STATE_DICT
# fsdp_sharding_strategy: FULL_SHARD
# Misc
early_stopping_patience:
debug:
Wow, you've read all of that? You seem like the person that would join our discord
70B at some point? ;) We are closer than ever to this. For real this time.
If you want to support me you can do so here
- Downloads last month
- 9