
测试评估结果正在路上...
在2张A800-80G上,
基于Qwen/Qwen2-7B-Instruct, 在llamafactory框架上,
使用SylvanL/Traditional-Chinese-Medicine-Dataset-Pretrain进行了2个epoch的继续预训练(Continue Pre-train).
在保留模型原有通用能力的前提下,使模型熟悉、记住,并更倾向于输出以下内容:
- 中医问诊单、处方笺、医生诊断及多种格式的病案、医案内容
- 中医领域教材与典籍
- 中成药、中药材、中医方剂、中医术语、中医疾病、中医症状、药膳食疗相关的知识点
epoch 1:
{
"num_input_tokens_seen": 442925056,
"total_flos": 885678736932864.0,
"train_loss": 1.658593576353242,
"train_runtime": 133293.1729,
"train_samples_per_second": 3.246,
"train_steps_per_second": 0.014
}
average_perplexity: 7.2646328377141005
epoch 2:
{
"num_input_tokens_seen": 442925056,
"total_flos": 885678736932864.0,
"train_loss": 1.3894652060929016,
"train_runtime": 139124.2076,
"train_samples_per_second": 3.11,
"train_steps_per_second": 0.014
}
average_perplexity: 5.800355962033688
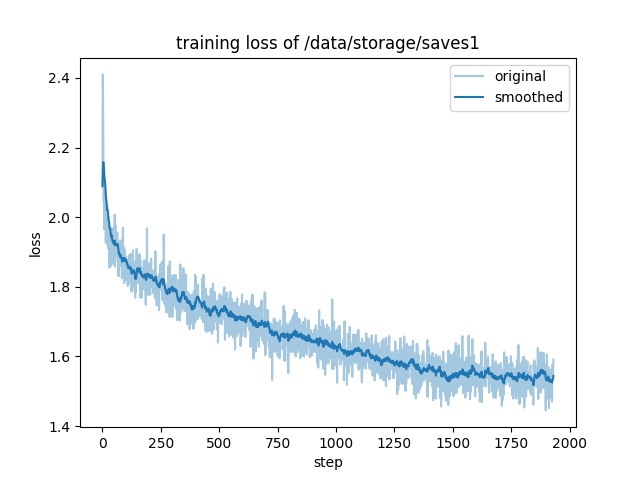
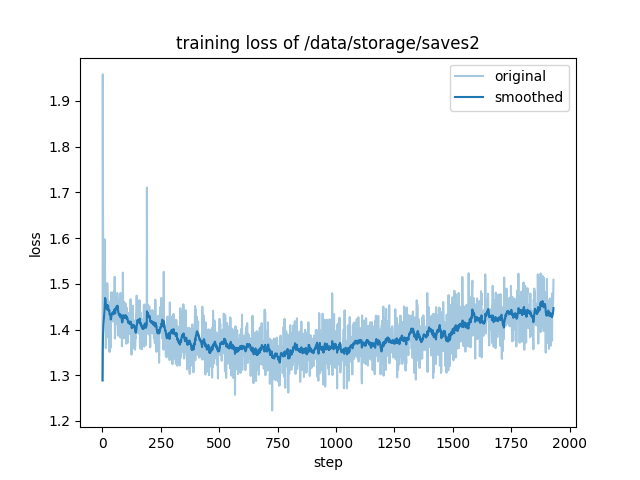
llamafactory-cli train \
--stage pt \
--do_train True \
--model_name_or_path Qwen/Qwen2-7B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type full \
--template default \
--flash_attn auto \
--dataset_dir {dataset_dir} \
--dataset CPT_generalMedical_362420,{shibing624/huatuo_medical_qa_sharegpt},CPT_medicalRecord_source1_61486,CPT_medicalRecord_source2_15307,CPT_medicalRecord_source3_230000,CPT_tcmKnowledge_source1_17921,CPT_tcmKnowledge_source2_12889,CPT_tcmBooks_source1_146244 \
--cutoff_len 1024 \
--learning_rate 6e-06 \
--num_train_epochs 2.0 \
--max_samples 1000000 \
--per_device_train_batch_size 28 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 1 \
--save_steps 1000 \
--warmup_steps 0 \
--optim adamw_torch \
--packing True \
--report_to none \
--output_dir {output_dir} \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--deepspeed cache/ds_z3_offload_config.json
- Downloads last month
- 65