
File size: 2,667 Bytes
ed2db09 93cf6ab 72f4950 93cf6ab 72f4950 93cf6ab |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
---
license: apache-2.0
---
# THUDM's chatglm 6B GGML
These files are GGML format model files for [THUDM's chatglm 6B](https://huggingface.co/THUDM/chatglm-6b).
GGML files are for CPU + GPU inference using [chatglm.cpp](https://github.com/li-plus/chatglm.cpp) and [Xorbits Inference](https://github.com/xorbitsai/inference).
# Prompt template
**NOTE**: prompt template is not available yet since the system prompt is hard coded in chatglm.cpp for now.
# Provided files
| Name | Quant method | Bits | Size |
|------|--------------|------|------|
| chatglm-ggml-q4_0.bin | q4_0 | 4 | 3.5 GB |
| chatglm-ggml-q4_1.bin | q4_1 | 4 | 3.9 GB |
| chatglm-ggml-q5_0.bin | q5_0 | 5 | 4.3 GB |
| chatglm-ggml-q5_1.bin | q5_1 | 5 | 4.6 GB |
| chatglm-ggml-q5_1.bin | q8_0 | 8 | 6.6 GB |
# How to run in Xorbits Inference
## Install
Xinference can be installed via pip from PyPI. It is highly recommended to create a new virtual environment to avoid conflicts.
```bash
$ pip install "xinference[all]"
$ pip install chatglm-cpp
```
## Start Xorbits Inference
To start a local instance of Xinference, run the following command:
```bash
$ xinference
```
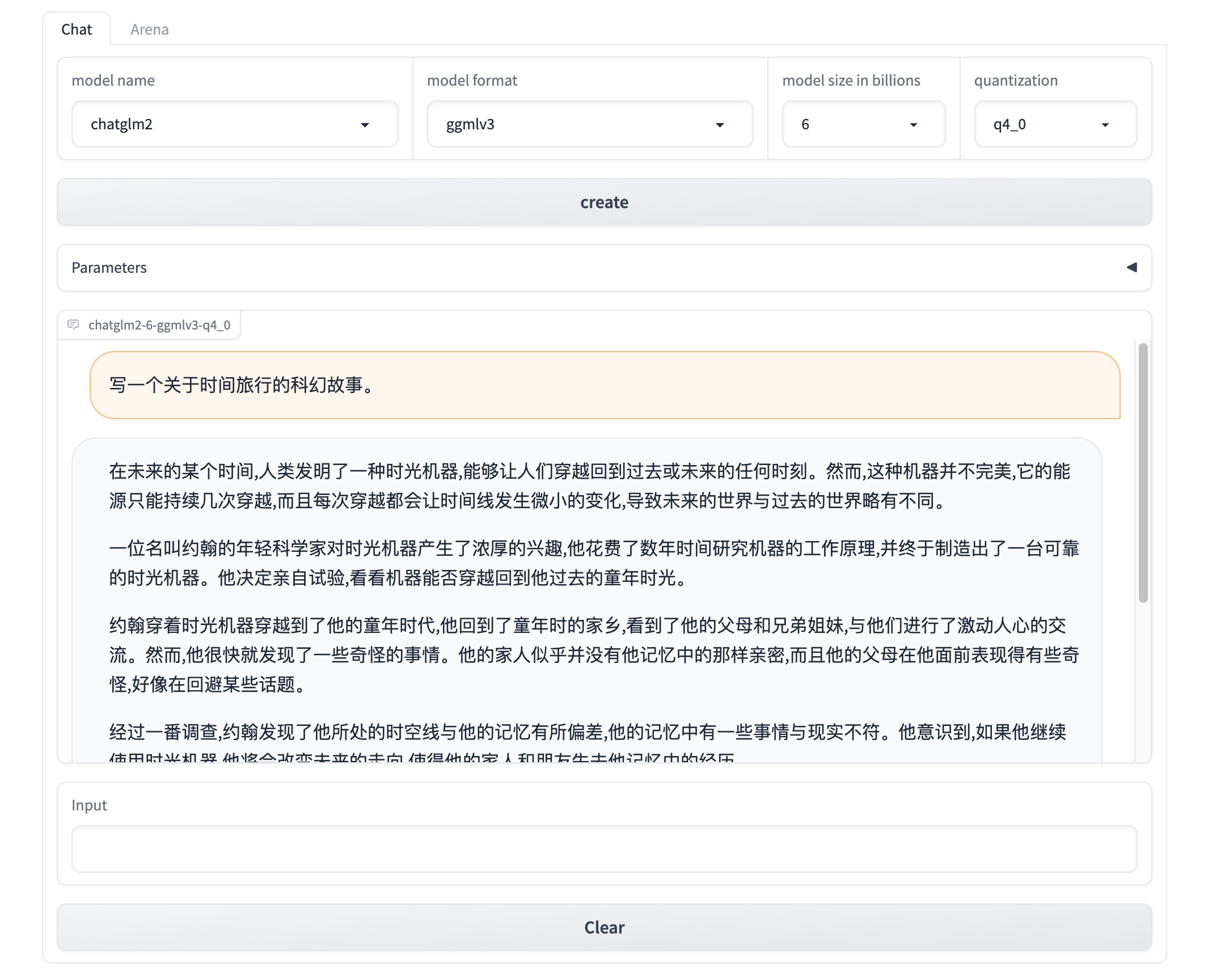
Once Xinference is running, an endpoint will be accessible for model management via CLI or Xinference client. The default endpoint is `http://localhost:9997`. You can also view a web UI using the Xinference endpoint to chat with all the builtin models. You can even chat with two cutting-edge AI models side-by-side to compare their performance!
# Slack
For further support, and discussions on these models and AI in general, join our [slack channel](https://join.slack.com/t/xorbitsio/shared_invite/zt-1o3z9ucdh-RbfhbPVpx7prOVdM1CAuxg)!
# Original model card: THUDM's chatglm 6B
ChatGLM-6B is an open bilingual language model based on General Language Model (GLM) framework, with 6.2 billion parameters. With the quantization technique, users can deploy locally on consumer-grade graphics cards (only 6GB of GPU memory is required at the INT4 quantization level). ChatGLM-6B uses technology similar to ChatGPT, optimized for Chinese QA and dialogue. The model is trained for about 1T tokens of Chinese and English corpus, supplemented by supervised fine-tuning, feedback bootstrap, and reinforcement learning with human feedback. With only about 6.2 billion parameters, the model is able to generate answers that are in line with human preference.
For more instructions, including how to run CLI and web demos, and model quantization, please refer to our [Github Repo](https://github.com/THUDM/ChatGLM-6B).
|