
Model Card for Firefly-Qwen1.5
firefly-qwen1.5-en-7b and firefly-qwen1.5-en-7b-dpo-v0.1 are trained based on Qwen1.5-7B to act as a helpful and harmless AI assistant. We use Firefly to train our models on a single V100 GPU with QLoRA. firefly-qwen1.5-en-7b is fine-tuned based on Qwen1.5-7B with English instruction data, and firefly-qwen1.5-en-7b-dpo-v0.1 is trained with Direct Preference Optimization (DPO) based on firefly-qwen1.5-en-7b.
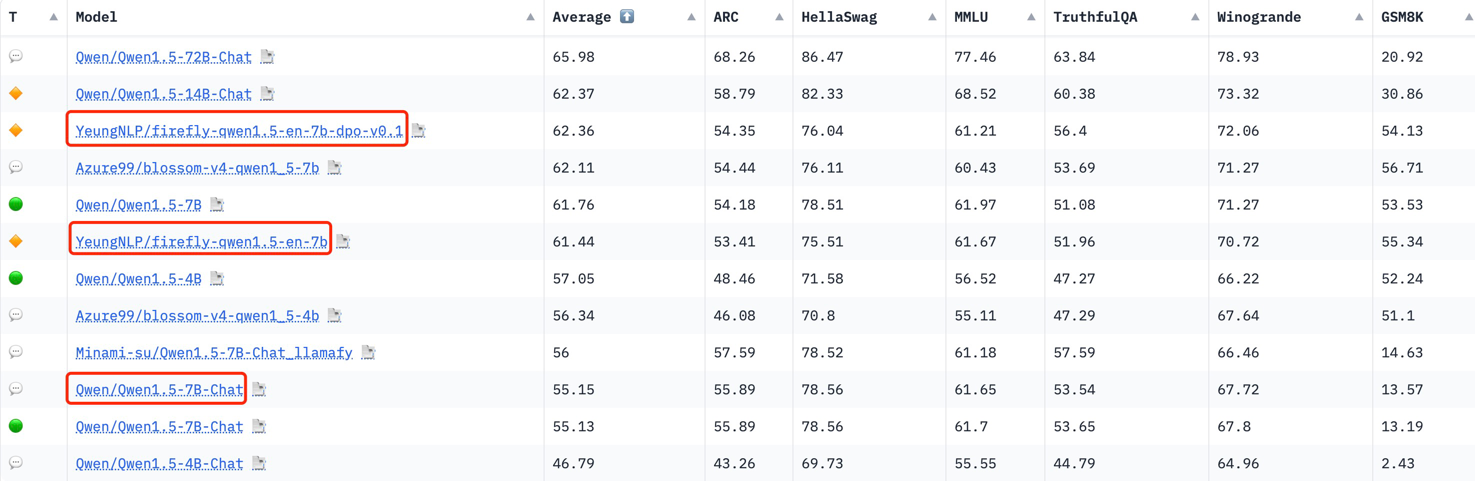
Our models outperform official Qwen1.5-7B-Chat, Gemma-7B-it, Zephyr-7B-Beta on Open LLM Leaderboard.
Although our models are trained with English data, you can also try to chat with models in Chinese because Qwen1.5 is also good at Chinese. But we have not evaluated the performance in Chinese yet.
We advise you to install transformers>=4.37.0.
Performance
We evaluate our models on Open LLM Leaderboard, they achieve good performance.
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
|---|---|---|---|---|---|---|---|
| firefly-gemma-7b | 62.93 | 62.12 | 79.77 | 61.57 | 49.41 | 75.45 | 49.28 |
| firefly-qwen1.5-en-7b-dpo-v0.1 | 62.36 | 54.35 | 76.04 | 61.21 | 56.4 | 72.06 | 54.13 |
| zephyr-7b-beta | 61.95 | 62.03 | 84.36 | 61.07 | 57.45 | 77.74 | 29.04 |
| firefly-qwen1.5-en-7b | 61.44 | 53.41 | 75.51 | 61.67 | 51.96 | 70.72 | 55.34 |
| vicuna-13b-v1.5 | 55.41 | 57.08 | 81.24 | 56.67 | 51.51 | 74.66 | 11.3 |
| Xwin-LM-13B-V0.1 | 55.29 | 62.54 | 82.8 | 56.53 | 45.96 | 74.27 | 9.63 |
| Qwen1.5-7B-Chat | 55.15 | 55.89 | 78.56 | 61.65 | 53.54 | 67.72 | 13.57 |
| gemma-7b-it | 53.56 | 51.45 | 71.96 | 53.52 | 47.29 | 67.96 | 29.19 |
Usage
The chat templates of our chat models are the same as Official Qwen1.5-7B-Chat:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
hello, who are you?<|im_end|>
<|im_start|>assistant
I am a AI program developed by Firefly<|im_end|>
You can use script to inference in Firefly.
You can also use the following code:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name_or_path = "YeungNLP/firefly-qwen1.5-en-7b-dpo-v0.1"
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
prompt = "Compose an engaging travel blog post about a recent trip to Hawaii, highlighting cultural experiences and must-see attractions. "
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to('cuda')
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=1500,
top_p = 0.9,
temperature = 0.35,
repetition_penalty = 1.0,
eos_token_id=tokenizer.encode('<|im_end|>', add_special_tokens=False)
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
Training Details
Both in SFT and DPO stages, We only use a single V100 GPU with QLoRA, and we use Firefly to train our models.
Training Setting
The following hyperparameters are used during SFT:
- num_epochs: 1
- learning_rate: 2e-4
- total_train_batch_size: 32
- max_seq_length: 2048
- optimizer: paged_adamw_32bit
- lr_scheduler_type: constant_with_warmup
- warmup_steps: 700
- lora_rank: 64
- lora_alpha: 16
- lora_dropout: 0.05
- gradient_checkpointing: true
- fp16: true
The following hyperparameters were used during DPO:
- num_epochs: 1
- learning_rate: 2e-4
- total_train_batch_size: 32
- max_seq_length: 1600
- max_prompt_length: 500
- optimizer: paged_adamw_32bit
- lr_scheduler_type: constant_with_warmup
- warmup_steps: 200
- lora_rank: 64
- lora_alpha: 16
- lora_dropout: 0.05
- gradient_checkpointing: true
- fp16: true
Training metrics
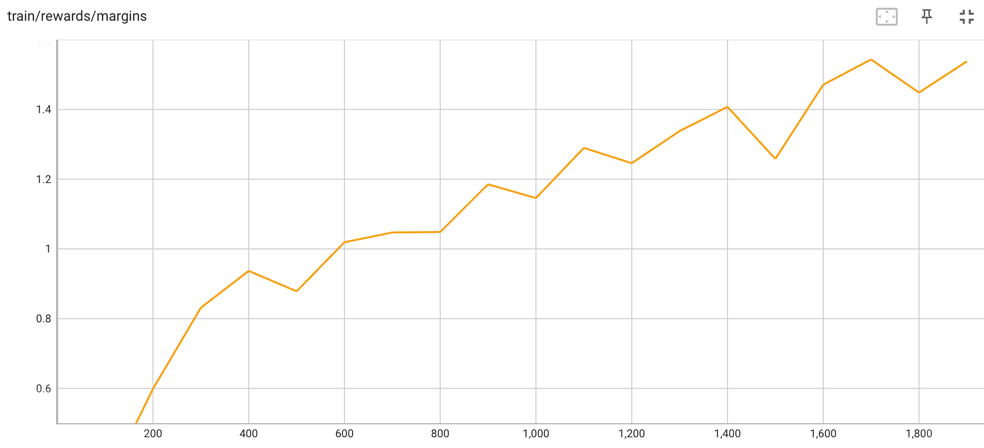
Training Rewards/margins in DPO:
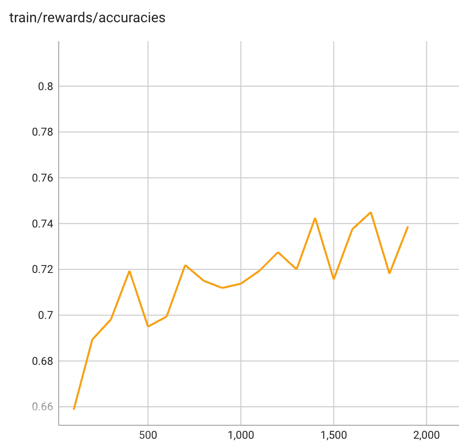
Training Rewards/accuracies in DPO:
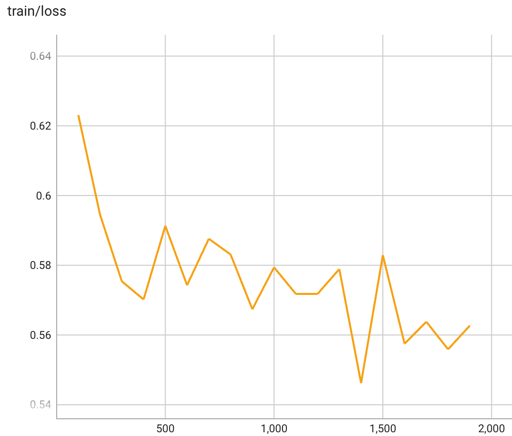
Training loss in DPO:
The table below shows the full set of DPO training metrics:
| Epoch | Step | Loss | Rewards/accuracies | Rewards/margins | Rewards/chosen | Rewards/rejected | Logits/chosen | Logits/rejected | Logps/chosen | Logps/rejected |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.05 | 100 | 0.6231 | 0.6587 | 0.3179 | 0.0404 | -0.2774 | 1.1694 | 1.2377 | -284.5586 | -255.4863 |
| 0.1 | 200 | 0.5945 | 0.6894 | 0.5988 | -0.1704 | -0.7693 | 1.012 | 1.0283 | -284.3049 | -268.1887 |
| 0.16 | 300 | 0.5754 | 0.6981 | 0.8314 | -0.282 | -1.1133 | 0.8912 | 0.8956 | -283.6926 | -270.3117 |
| 0.21 | 400 | 0.5702 | 0.7194 | 0.9369 | -0.1944 | -1.1313 | 0.7255 | 0.7557 | -291.2833 | -273.9706 |
| 0.26 | 500 | 0.5913 | 0.695 | 0.8784 | -0.4524 | -1.3309 | 0.5491 | 0.5535 | -289.5705 | -271.754 |
| 0.31 | 600 | 0.5743 | 0.6994 | 1.0192 | -0.4505 | -1.4698 | 0.6446 | 0.6399 | -296.5292 | -277.824 |
| 0.37 | 700 | 0.5876 | 0.7219 | 1.0471 | -0.6998 | -1.747 | 0.4955 | 0.4329 | -303.7684 | -289.0117 |
| 0.42 | 800 | 0.5831 | 0.715 | 1.0485 | -0.8185 | -1.8671 | 0.5589 | 0.4804 | -295.6313 | -288.0656 |
| 0.47 | 900 | 0.5674 | 0.7119 | 1.1854 | -1.2085 | -2.3939 | 0.3467 | 0.2249 | -302.3643 | -286.2816 |
| 0.52 | 1000 | 0.5794 | 0.7138 | 1.1458 | -0.8423 | -1.9881 | 0.5116 | 0.4248 | -299.3136 | -287.3934 |
| 0.58 | 1100 | 0.5718 | 0.7194 | 1.2897 | -1.4944 | -2.7841 | 0.6392 | 0.5739 | -316.6829 | -294.1148 |
| 0.63 | 1200 | 0.5718 | 0.7275 | 1.2459 | -1.7543 | -3.0002 | 0.4999 | 0.4065 | -316.7873 | -297.8514 |
| 0.68 | 1300 | 0.5789 | 0.72 | 1.3379 | -1.8485 | -3.1864 | 0.4289 | 0.3172 | -314.8326 | -296.8319 |
| 0.73 | 1400 | 0.5462 | 0.7425 | 1.4074 | -1.9865 | -3.3939 | 0.3645 | 0.2333 | -309.4503 | -294.3931 |
| 0.79 | 1500 | 0.5829 | 0.7156 | 1.2582 | -2.1183 | -3.3766 | 0.4193 | 0.2796 | -307.5281 | -292.0817 |
| 0.84 | 1600 | 0.5575 | 0.7375 | 1.471 | -2.1429 | -3.6139 | 0.6547 | 0.5152 | -310.9912 | -298.899 |
| 0.89 | 1700 | 0.5638 | 0.745 | 1.5433 | -2.991 | -4.5343 | 0.7336 | 0.6782 | -328.2657 | -307.5182 |
| 0.94 | 1800 | 0.5559 | 0.7181 | 1.4484 | -2.8818 | -4.3302 | 0.7997 | 0.8327 | -316.2716 | -295.1836 |
| 0.99 | 1900 | 0.5627 | 0.7387 | 1.5378 | -2.7941 | -4.332 | 0.8573 | 0.858 | -324.9405 | -310.1192 |
- Downloads last month
- 70