

pipeline_tag: visual-question-answering
language:
- en
- zh
datasets:
- HaoyeZhang/RLAIF-V-Dataset
MiniCPM-Llama3-V 2.5
MiniCPM-Llama3-V 2.5 is the latest model in the MiniCPM-V series. The model is built on SigLip-400M and Llama3-8B-Instruct with a total of 8B parameters. It exhibits a significant performance improvement over MiniCPM-V 2.0. Notable features of MiniCPM-Llama3-V 2.5 include:
🔥 Leading Performance. MiniCPM-Llama3-V 2.5 has achieved an average score of 65.1 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks. It surpasses widely used proprietary models like GPT-4V-1106, Gemini Pro, Qwen-VL-Max and Claude 3 with 8B parameters, greatly outperforming other multimodal large models built on Llama 3.
💪 Strong OCR Capabilities. MiniCPM-Llama3-V 2.5 can process images with any aspect ratio up to 1.8 million pixels, achieving an 700+ score on OCRBench, surpassing proprietary models such as GPT-4o, GPT-4V-0409, Qwen-VL-Max and Gemini Pro. Based on recent user feedback, MiniCPM-Llama3-V 2.5 has now enhanced full-text OCR extraction, table-to-markdown conversion, and other high-utility capabilities, and has further strengthened its instruction-following and complex reasoning abilities, enhancing multimodal interaction experiences.
🏆 Trustworthy Behavior. Leveraging the latest RLAIF-V method (the newest technology in the RLHF-V [CVPR'24] series), MiniCPM-Llama3-V 2.5 exhibits trustworthy multimodal behavior. It achieves 10.3% hallucination rate on Object HalBench, lower than GPT-4V-1106 (13.6%), achieving the best level within the open-source community.
🌏 Multilingual Support. Thanks to Llama 3’s robust multilingual capabilities and VisCPM's cross-lingual generalization technology, MiniCPM-Llama3-V 2.5 extends its foundational bilingual (Chinese-English) multimodal capabilities to support 30+ languages including German, French, Spanish, Italian, Russian etc. We achieve this extension through only minimal instruction-tuning with translated multimodal data. All Supported Languages.
🚀 Efficient Deployment. MiniCPM-Llama3-V 2.5 systematically employs model quantization, CPU optimizations, NPU optimizations and compilation optimizations as acceleration techniques, achieving high-efficiency deployment on edge devices. For mobile phones with Qualcomm chips, we have integrated the NPU acceleration framework QNN into llama.cpp for the first time. After systematic optimization, MiniCPM-Llama3-V 2.5 has realized a 150-fold acceleration in multimodal large model edge-side image encoding and a 3-fold increase in language decoding speed.
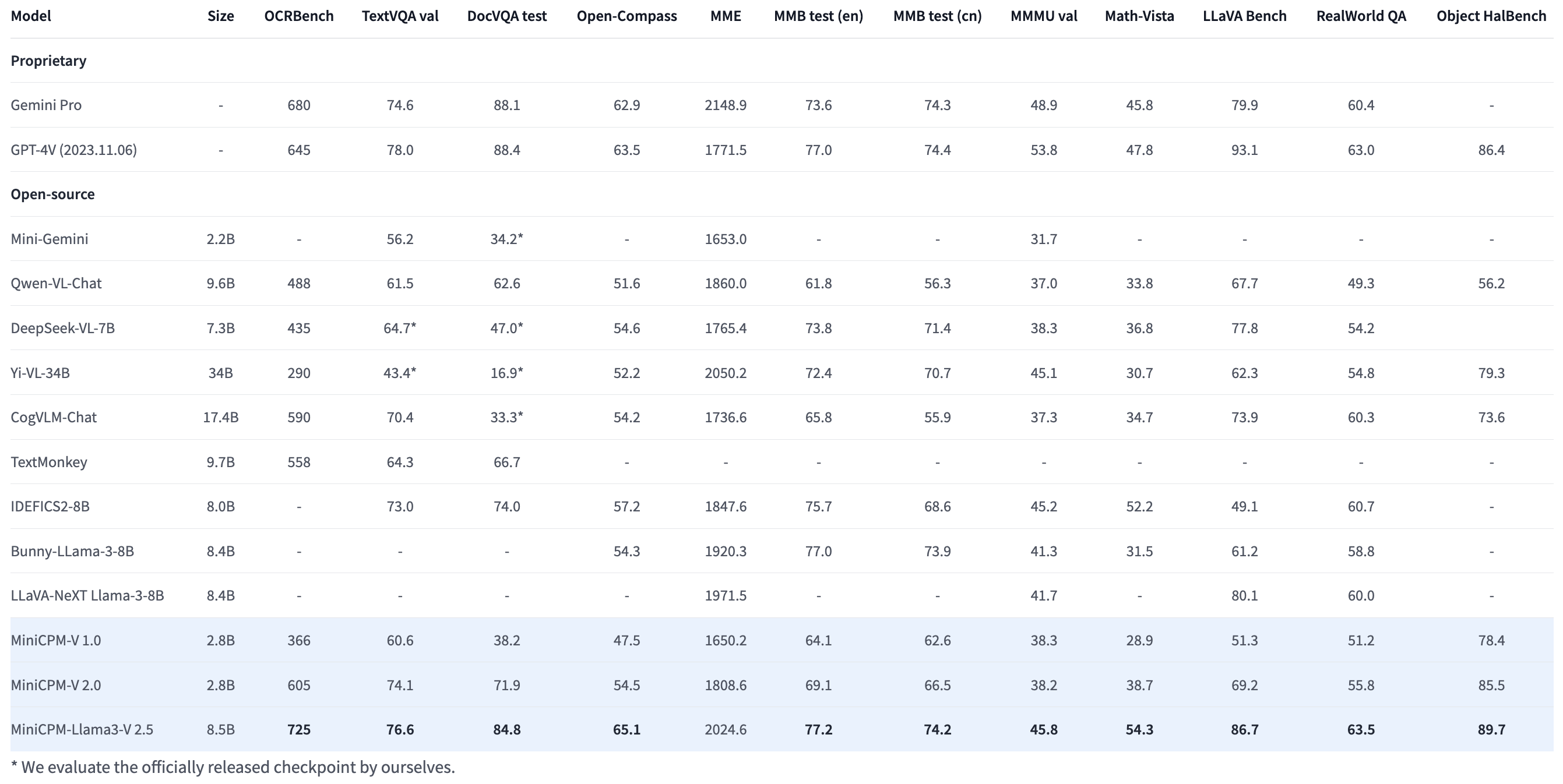
Evaluation

Results on TextVQA, DocVQA, OCRBench, OpenCompass, MME, MMBench, MMMU, MathVista, LLaVA Bench, RealWorld QA, Object HalBench.
Results of LLaVA Bench in multiple languages.

Examples

We deploy MiniCPM-Llama3-V 2.5 on end devices. The demo video is the raw screen recording on a Xiaomi 14 Pro at double speed.



Demo
Click here to try out the Demo of MiniCPM-Llama3-V 2.5.
Deployment on Mobile Phone
Coming soon.
Usage
Inference using Huggingface transformers on NVIDIA GPUs. Requirements tested on python 3.10:
Pillow==10.1.0
torch==2.1.2
torchvision==0.16.2
transformers==4.40.0
sentencepiece==0.1.99
# test.py
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True, torch_dtype=torch.float16)
model = model.to(device='cuda')
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True)
model.eval()
image = Image.open('xx.jpg').convert('RGB')
question = 'What is in the image?'
msgs = [{'role': 'user', 'content': question}]
res = model.chat(
image=image,
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
temperature=0.7
)
print(res)
Please look at GitHub for more detail about usage.
Int4 quantized version
Download the int4 quantized version for lower GPU memory usage: MiniCPM-Llama3-V-2_5-int4.
MiniCPM-V 2.0
Please see the info about MiniCPM-V 2.0 here.
License
Model License
- The code in this repo is released according to Apache-2.0
- The usage of MiniCPM-Llama3-V 2.5's parameters is subject to "General Model License Agreement - Source Notes - Publicity Restrictions - Commercial License"
- The parameters are fully open to acedemic research
- Please contact [email protected] to obtain a written authorization for commercial uses. Free commercial use is also allowed after registration.
Statement
- As a LLM, MiniCPM-Llama3-V 2.5 generates contents by learning a large mount of texts, but it cannot comprehend, express personal opinions or make value judgement. Anything generated by MiniCPM-Llama3-V 2.5 does not represent the views and positions of the model developers
- We will not be liable for any problems arising from the use of the MinCPM-V open Source model, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.
Other Multimodal Projects from Our Team
VisCPM | RLHF-V | LLaVA-UHD | RLAIF-V
Citation
If you find our work helpful, please consider citing the following papers
@article{yu2023rlhf,
title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback},
author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others},
journal={arXiv preprint arXiv:2312.00849},
year={2023}
}
@article{viscpm,
title={Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages},
author={Jinyi Hu and Yuan Yao and Chongyi Wang and Shan Wang and Yinxu Pan and Qianyu Chen and Tianyu Yu and Hanghao Wu and Yue Zhao and Haoye Zhang and Xu Han and Yankai Lin and Jiao Xue and Dahai Li and Zhiyuan Liu and Maosong Sun},
journal={arXiv preprint arXiv:2308.12038},
year={2023}
}
@article{xu2024llava-uhd,
title={{LLaVA-UHD}: an LMM Perceiving Any Aspect Ratio and High-Resolution Images},
author={Xu, Ruyi and Yao, Yuan and Guo, Zonghao and Cui, Junbo and Ni, Zanlin and Ge, Chunjiang and Chua, Tat-Seng and Liu, Zhiyuan and Huang, Gao},
journal={arXiv preprint arXiv:2403.11703},
year={2024}
}