|
--- |
|
license: apache-2.0 |
|
language: |
|
- en |
|
tags: |
|
- ColBERT |
|
- RAGatouille |
|
- passage-retrieval |
|
--- |
|
|
|
# answerai-colbert-small-v1 |
|
|
|
**answerai-colbert-small-v1** is a new, proof-of-concept model by [Answer.AI](https://answer.ai), showing the strong performance multi-vector models with the new [JaColBERTv2.5 training recipe](https://arxiv.org/abs/2407.20750) and some extra tweaks can reach, even with just **33 million parameters**. |
|
|
|
While being MiniLM-sized, it outperforms all previous similarly-sized models on common benchmarks, and even outperforms much larger popular models such as e5-large-v2 or bge-base-en-v1.5. |
|
|
|
For more information about this model or how it was trained, head over to the [announcement blogpost](https://www.answer.ai/posts/2024-08-13-small-but-mighty-colbert.html). |
|
|
|
## Usage |
|
|
|
### Installation |
|
|
|
This model was designed with the upcoming RAGatouille overhaul in mind. However, it's compatible with all recent ColBERT implementations! |
|
|
|
To use it, you can either use the Stanford ColBERT library, or RAGatouille. You can install both or either by simply running. |
|
|
|
```sh |
|
pip install --upgrade ragatouille |
|
pip install --upgrade colbert-ai |
|
``` |
|
|
|
If you're interested in using this model as a re-ranker (it vastly outperforms cross-encoders its size!), you can do so via the [rerankers](https://github.com/AnswerDotAI/rerankers) library: |
|
```sh |
|
pip install --upgrade rerankers[transformers] |
|
``` |
|
|
|
### Rerankers |
|
|
|
```python |
|
from rerankers import Reranker |
|
|
|
ranker = Reranker("answerdotai/answerai-colbert-small-v1", model_type='colbert') |
|
docs = ['Hayao Miyazaki is a Japanese director, born on [...]', 'Walt Disney is an American author, director and [...]', ...] |
|
query = 'Who directed spirited away?' |
|
ranker.rank(query=query, docs=docs) |
|
``` |
|
|
|
### RAGatouille |
|
|
|
```python |
|
from ragatouille import RAGPretrainedModel |
|
|
|
RAG = RAGPretrainedModel.from_pretrained("answerdotai/answerai-colbert-small-v1") |
|
|
|
docs = ['Hayao Miyazaki is a Japanese director, born on [...]', 'Walt Disney is an American author, director and [...]', ...] |
|
|
|
RAG.index(docs, index_name="ghibli") |
|
|
|
query = 'Who directed spirited away?' |
|
results = RAG.search(query) |
|
``` |
|
|
|
### Stanford ColBERT |
|
|
|
#### Indexing |
|
|
|
```python |
|
from colbert import Indexer |
|
from colbert.infra import Run, RunConfig, ColBERTConfig |
|
|
|
INDEX_NAME = "DEFINE_HERE" |
|
|
|
if __name__ == "__main__": |
|
config = ColBERTConfig( |
|
doc_maxlen=512, |
|
nbits=2 |
|
) |
|
indexer = Indexer( |
|
checkpoint="answerdotai/answerai-colbert-small-v1", |
|
config=config, |
|
) |
|
docs = ['Hayao Miyazaki is a Japanese director, born on [...]', 'Walt Disney is an American author, director and [...]', ...] |
|
|
|
indexer.index(name=INDEX_NAME, collection=docs) |
|
``` |
|
|
|
#### Querying |
|
|
|
```python |
|
from colbert import Searcher |
|
from colbert.infra import Run, RunConfig, ColBERTConfig |
|
|
|
INDEX_NAME = "THE_INDEX_YOU_CREATED" |
|
k = 10 |
|
|
|
if __name__ == "__main__": |
|
config = ColBERTConfig( |
|
query_maxlen=32 # Adjust as needed, we recommend the nearest higher multiple of 16 to your query |
|
) |
|
searcher = Searcher( |
|
index=index_name, |
|
config=config |
|
) |
|
query = 'Who directed spirited away?' |
|
results = searcher.search(query, k=k) |
|
``` |
|
|
|
|
|
#### Extracting Vectors |
|
|
|
Finally, if you want to extract individula vectors, you can use the model this way: |
|
|
|
|
|
```python |
|
from colbert.modeling.checkpoint import Checkpoint |
|
|
|
ckpt = Checkpoint("answerdotai/answerai-colbert-small-v1", colbert_config=ColBERTConfig()) |
|
embedded_query = ckpt.queryFromText(["Who dubs Howl's in English?"], bsize=16) |
|
``` |
|
|
|
|
|
## Results |
|
|
|
### Against single-vector models |
|
|
|
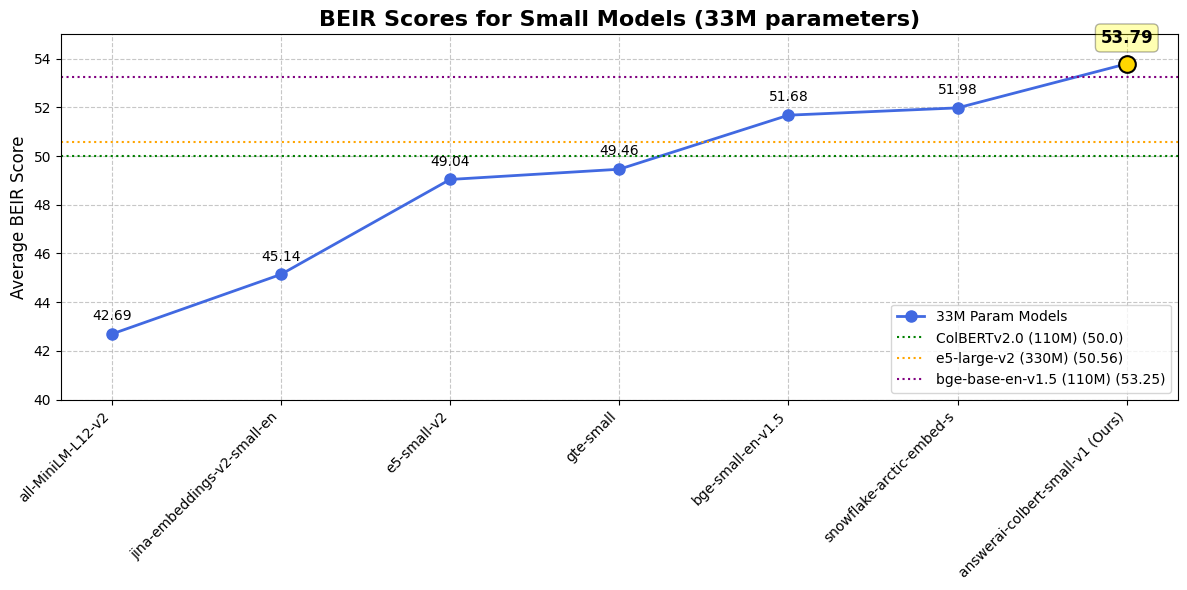 |
|
|
|
|
|
| Dataset / Model | answer-colbert-s | snowflake-s | bge-small-en | bge-base-en | |
|
|:-----------------|:-----------------:|:-------------:|:-------------:|:-------------:| |
|
| **Size** | 33M (1x) | 33M (1x) | 33M (1x) | **109M (3.3x)** | |
|
| **BEIR AVG** | **53.79** | 51.99 | 51.68 | 53.25 | |
|
| **FiQA2018** | **41.15** | 40.65 | 40.34 | 40.65 | |
|
| **HotpotQA** | **76.11** | 66.54 | 69.94 | 72.6 | |
|
| **MSMARCO** | **43.5** | 40.23 | 40.83 | 41.35 | |
|
| **NQ** | **59.1** | 50.9 | 50.18 | 54.15 | |
|
| **TRECCOVID** | **84.59** | 80.12 | 75.9 | 78.07 | |
|
| **ArguAna** | 50.09 | 57.59 | 59.55 | **63.61** | |
|
| **ClimateFEVER**| 33.07 | **35.2** | 31.84 | 31.17 | |
|
| **CQADupstackRetrieval** | 38.75 | 39.65 | 39.05 | **42.35** | |
|
| **DBPedia** | **45.58** | 41.02 | 40.03 | 40.77 | |
|
| **FEVER** | **90.96** | 87.13 | 86.64 | 86.29 | |
|
| **NFCorpus** | 37.3 | 34.92 | 34.3 | **37.39** | |
|
| **QuoraRetrieval** | 87.72 | 88.41 | 88.78 | **88.9** | |
|
| **SCIDOCS** | 18.42 | **21.82** | 20.52 | 21.73 | |
|
| **SciFact** | **74.77** | 72.22 | 71.28 | 74.04 | |
|
| **Touche2020** | 25.69 | 23.48 | **26.04** | 25.7 | |
|
|
|
### Against ColBERTv2.0 |
|
|
|
| Dataset / Model | answerai-colbert-small-v1 | ColBERTv2.0 | |
|
|:-----------------|:-----------------------:|:------------:| |
|
| **BEIR AVG** | **53.79** | 50.02 | |
|
| **DBPedia** | **45.58** | 44.6 | |
|
| **FiQA2018** | **41.15** | 35.6 | |
|
| **NQ** | **59.1** | 56.2 | |
|
| **HotpotQA** | **76.11** | 66.7 | |
|
| **NFCorpus** | **37.3** | 33.8 | |
|
| **TRECCOVID** | **84.59** | 73.3 | |
|
| **Touche2020** | 25.69 | **26.3** | |
|
| **ArguAna** | **50.09** | 46.3 | |
|
| **ClimateFEVER**| **33.07** | 17.6 | |
|
| **FEVER** | **90.96** | 78.5 | |
|
| **QuoraRetrieval** | **87.72** | 85.2 | |
|
| **SCIDOCS** | **18.42** | 15.4 | |
|
| **SciFact** | **74.77** | 69.3 | |
|
|
|
|
|
## Referencing |
|
|
|
We'll most likely eventually release a technical report. In the meantime, if you use this model or other models following the JaColBERTv2.5 recipe and would like to give us credit, please cite the JaColBERTv2.5 journal pre-print: |
|
|
|
``` |
|
@article{clavie2024jacolbertv2, |
|
title={JaColBERTv2.5: Optimising Multi-Vector Retrievers to Create State-of-the-Art Japanese Retrievers with Constrained Resources}, |
|
author={Clavi{\'e}, Benjamin}, |
|
journal={arXiv preprint arXiv:2407.20750}, |
|
year={2024} |
|
} |
|
``` |
|
|

