|
--- |
|
language: |
|
- ru |
|
|
|
tags: |
|
- toxic comments classification |
|
|
|
licenses: |
|
- cc-by-nc-sa |
|
--- |
|
|
|
## General concept of the model |
|
|
|
#### Proposed usage |
|
|
|
The **'inappropriateness'** substance we tried to collect in the dataset and detect with the model **is NOT a substitution of toxicity**, it is rather a derivative of toxicity. So the model based on our dataset could serve as **an additional layer of inappropriateness filtering after toxicity and obscenity filtration**. You can detect the exact sensitive topic by using [another model](https://huggingface.co/Skoltech/russian-sensitive-topics). The proposed pipeline is shown in the scheme below. |
|
|
|
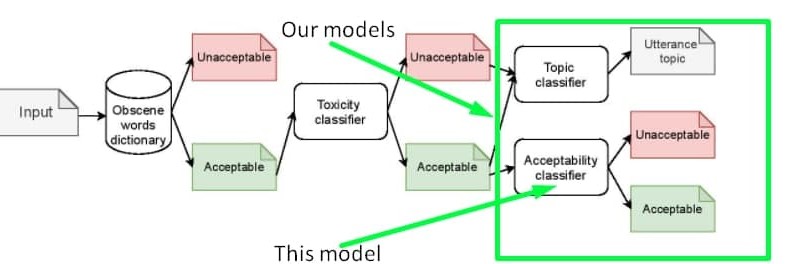 |
|
|
|
You can also train one classifier for both toxicity and inappropriateness detection. The data to be mixed with toxic labelled samples could be found on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages) |
|
|
|
#### Inappropraiteness intuition |
|
This model is trained on the dataset of inappropriate messages of the Russian language. Generally, an inappropriate utterance is an utterance that has not obscene words or any kind of toxic intent, but can still harm the reputation of the speaker. Find some sample for more intuition in the table below. Learn more about the concept of inappropriateness [in this article ](https://www.aclweb.org/anthology/2021.bsnlp-1.4/) presented at the workshop for Balto-Slavic NLP at the EACL-2021 conference. Please note that this article describes the first version of the dataset, while the model is trained on the extended version of the dataset open-sourced on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages). The properties of the dataset are the same as the one described in the article, the only difference is the size. |
|
|
|
| Text | Inappropriate | Comment | Unsafe topic | |
|
|------------------------------------------------------------------------------------------------------|---------------|----------------------------------------------------------------|---------------| |
|
| Ладно бы видного деятеля завалили а тут какого то ноунейм нигру преступника | yes | Оправдание убийства | offline crime | |
|
| Это нарушение УКРФ! | no | Осуждение нарушения закона | offline crime | |
|
| Религия - это насилие высшего уровня. Верующего принуждают к вере еще в младенчестве. | yes | Оскорбление чувств верующих | religion | |
|
| Христиане, как вы относитесь к иноверцам, в частности к Гамалиилу и к уверовавшим в Иисуса фарисеям? | no | Обычные вопросы к верующим без намека на оскорбление их чувств | religion | |
|
| Хорошо что проституция запрещена | no | Осуждение простуитуции | prostitution | |
|
| Возьму бабки и сниму шлюх на выходных | yes | Популяризация проституции | prostitution | |
|
|
|
#### Metrics |
|
The model was trained, validated, and tested only on the samples with 100% confidence, which allowed to get the following metrics on test set: |
|
|
|
| | precision | recall | f1-score | support | |
|
|--------------|----------|--------|----------|---------| |
|
| 0 | 0.92 | 0.93 | 0.93 | 7839 | |
|
| 1 | 0.80 | 0.76 | 0.78 | 2726 | |
|
| accuracy | | | 0.89 | 10565 | |
|
| macro avg | 0.86 | 0.85 | 0.85 | 10565 | |
|
| weighted avg | 0.89 | 0.89 | 0.89 | 10565 | |
|
|
|
|
|
|
|
## Licensing Information |
|
|
|
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa]. |
|
|
|
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa] |
|
|
|
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/ |
|
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png |
|
|
|
## Citation |
|
|
|
If you find this repository helpful, feel free to cite our publication: |
|
|
|
``` |
|
@inproceedings{babakov-etal-2021-detecting, |
|
title = "Detecting Inappropriate Messages on Sensitive Topics that Could Harm a Company{'}s Reputation", |
|
author = "Babakov, Nikolay and |
|
Logacheva, Varvara and |
|
Kozlova, Olga and |
|
Semenov, Nikita and |
|
Panchenko, Alexander", |
|
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing", |
|
month = apr, |
|
year = "2021", |
|
address = "Kiyv, Ukraine", |
|
publisher = "Association for Computational Linguistics", |
|
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.4", |
|
pages = "26--36", |
|
abstract = "Not all topics are equally {``}flammable{''} in terms of toxicity: a calm discussion of turtles or fishing less often fuels inappropriate toxic dialogues than a discussion of politics or sexual minorities. We define a set of sensitive topics that can yield inappropriate and toxic messages and describe the methodology of collecting and labelling a dataset for appropriateness. While toxicity in user-generated data is well-studied, we aim at defining a more fine-grained notion of inappropriateness. The core of inappropriateness is that it can harm the reputation of a speaker. This is different from toxicity in two respects: (i) inappropriateness is topic-related, and (ii) inappropriate message is not toxic but still unacceptable. We collect and release two datasets for Russian: a topic-labelled dataset and an appropriateness-labelled dataset. We also release pre-trained classification models trained on this data.", |
|
} |
|
``` |

