
metadata
base_model: black-forest-labs/FLUX.1-schnell
license: apache-2.0
tags:
- autotrain
- spacerunner
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
widget:
- text: 'Phoebe in a bustling cafe '
output:
url: samples/1726858519249__000001000_0.jpg
- text: A man sees Phoebe
output:
url: samples/1726858525867__000001000_1.jpg
- text: among the group phoebe was most interesting among them
output:
url: samples/1726858532164__000001000_2.jpg
- text: among the group phoebe was most interesting among them
output:
url: images/example_oo6dp1yb9.png
instance_prompt: phoebe
phoebe-combes
Model trained with AI Toolkit by Ostris

- Prompt
- Phoebe in a bustling cafe
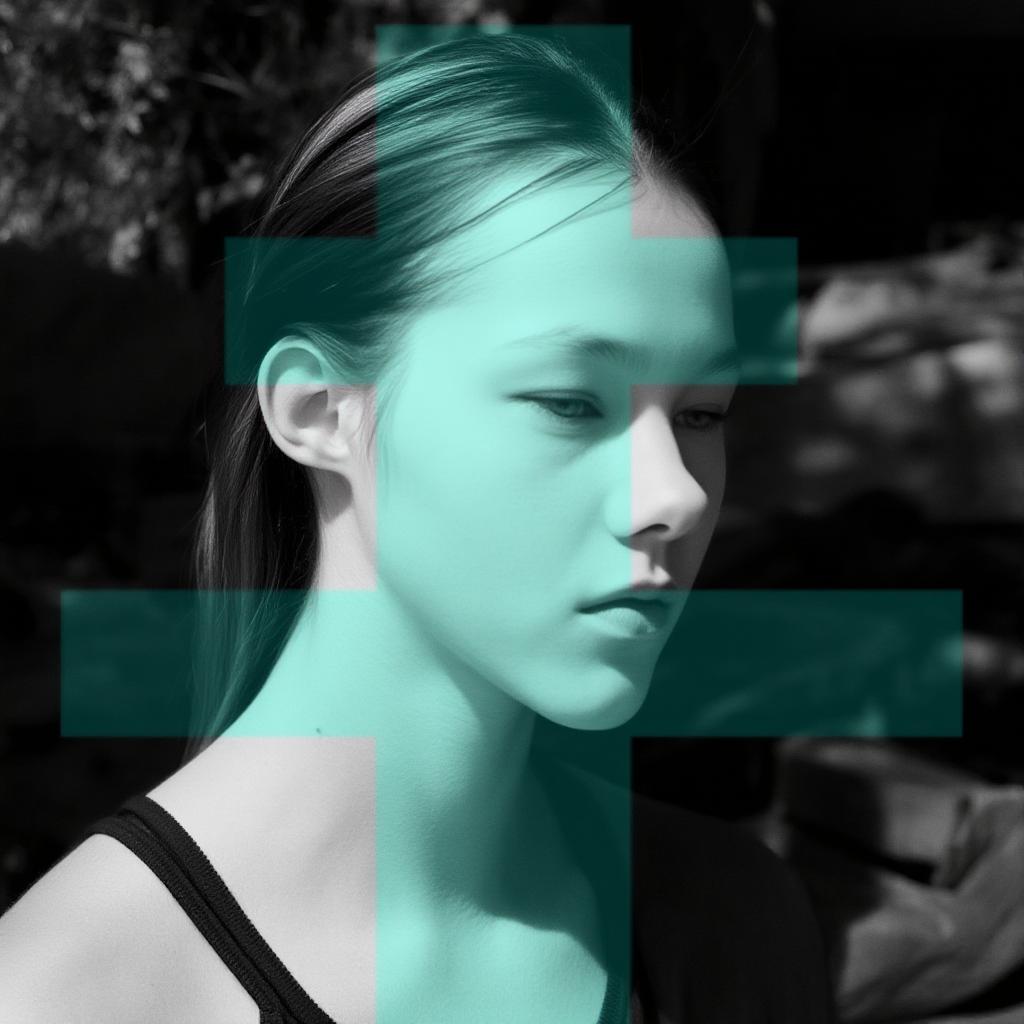
- Prompt
- A man sees Phoebe

- Prompt
- among the group phoebe was most interesting among them

- Prompt
- among the group phoebe was most interesting among them
Trigger words
You should use phoebe to trigger the image generation.
Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, etc.
Weights for this model are available in Safetensors format.
Download them in the Files & versions tab.
Use it with the 🧨 diffusers library
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-schnell', torch_dtype=torch.bfloat16).to('cuda')
pipeline.load_lora_weights('batmandelbrot/phoebe-combes', weight_name='phoebe-combes')
image = pipeline('Phoebe in a bustling cafe ').images[0]
image.save("my_image.png")
For more details, including weighting, merging and fusing LoRAs, check the documentation on loading LoRAs in diffusers