
Korean-Adapted Model Series
Collection
Korean-adapted Language Model Series
•
13 items
•
Updated
•
24
Llama-2-KoEn serves as an advanced iteration of Llama 2, benefiting from an expanded vocabulary and the inclusion of Korean + English corpus in its further pretraining. Just like its predecessor, Llama-2-KoEn operates within the broad range of generative text models that stretch from 7 billion to 70 billion parameters. This repository focuses on the 13B pretrained version, which is tailored to fit the Hugging Face Transformers format. For access to the other models, feel free to consult the index provided below.
Model Developers Junbum Lee (Beomi), Taekyoon Choi (Taekyoon)
Variations Llama-2-KoEn will come in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
Input Models input text only.
Output Models generate text only.
Model Architecture
Llama-2-KoEn is an auto-regressive language model that uses an optimized transformer architecture based on Llama-2.
| Training Data | Params | Content Length | GQA | Tokens | LR | |
|---|---|---|---|---|---|---|
| Llama 2 | A new mix of Korean + English online data | 13B | 4k | ✗ | >60B | 1e-5 |
Vocab Expansion
| Model Name | Vocabulary Size | Description |
|---|---|---|
| Original Llama-2 | 32000 | Sentencepiece BPE |
| Expanded Llama-2-Ko | 46336 | Sentencepiece BPE. Added Korean vocab and merges |
Tokenizing "안녕하세요, 오늘은 날씨가 좋네요."
| Model | Tokens |
|---|---|
| Llama-2 | ['▁', '안', '<0xEB>', '<0x85>', '<0x95>', '하', '세', '요', ',', '▁', '오', '<0xEB>', '<0x8A>', '<0x98>', '은', '▁', '<0xEB>', '<0x82>', '<0xA0>', '씨', '가', '▁', '<0xEC>', '<0xA2>', '<0x8B>', '<0xEB>', '<0x84>', '<0xA4>', '요'] |
| Llama-2-Ko | ['▁안녕', '하세요', ',', '▁오늘은', '▁날', '씨가', '▁좋네요'] |
Tokenizing "Llama 2: Open Foundation and Fine-Tuned Chat Models"
| Model | Tokens |
|---|---|
| Llama-2 | ['▁L', 'l', 'ama', '▁', '2', ':', '▁Open', '▁Foundation', '▁and', '▁Fine', '-', 'T', 'un', 'ed', '▁Ch', 'at', '▁Mod', 'els'] |
| Llama-2-Ko | ['▁L', 'l', 'ama', '▁', '2', ':', '▁Open', '▁Foundation', '▁and', '▁Fine', '-', 'T', 'un', 'ed', '▁Ch', 'at', '▁Mod', 'els'] |
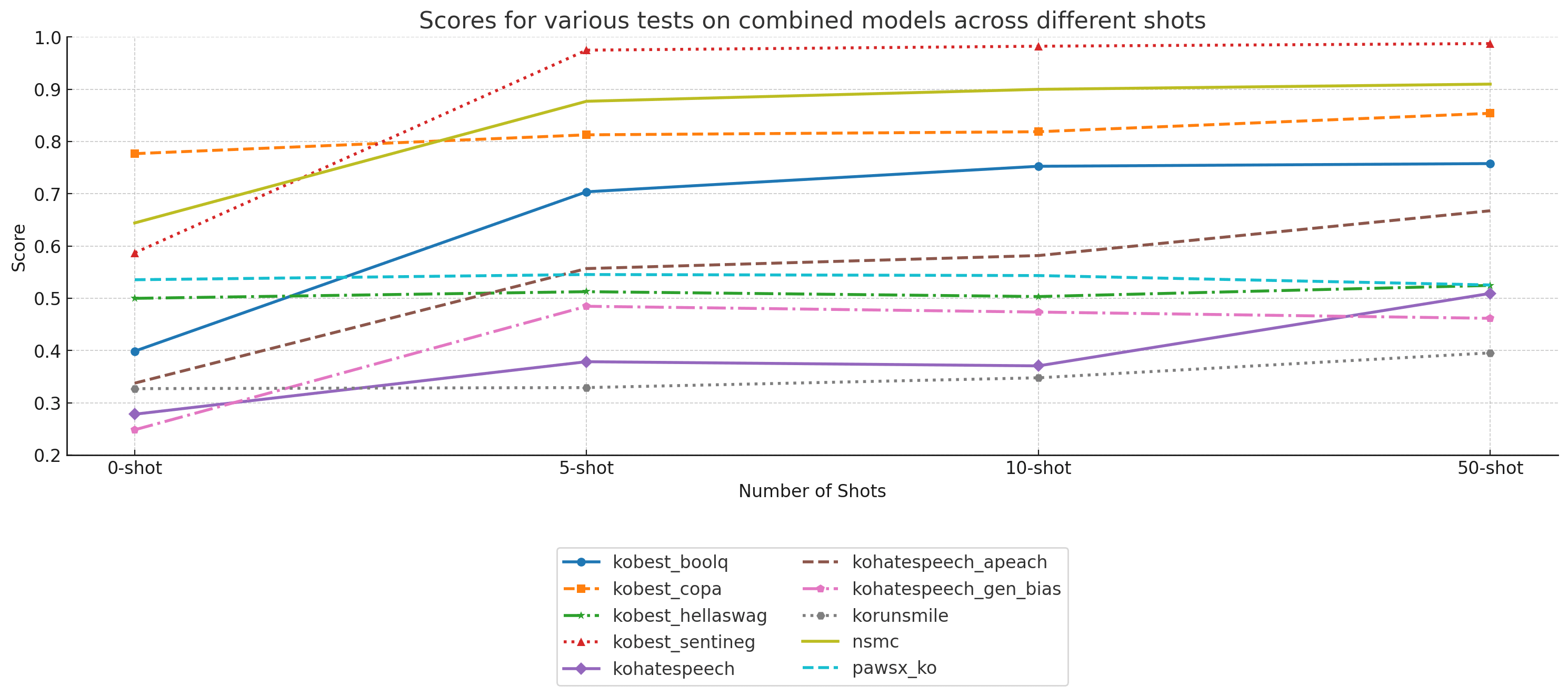
| Task | 0-shot | 5-shot | 10-shot | 50-shot |
|---|---|---|---|---|
| kobest_boolq | 0.398848 | 0.703795 | 0.752612 | 0.7578 |
| kobest_copa | 0.776785 | 0.812796 | 0.818724 | 0.853953 |
| kobest_hellaswag | 0.499922 | 0.512659 | 0.503365 | 0.524664 |
| kobest_sentineg | 0.586955 | 0.974811 | 0.982367 | 0.987405 |
| kohatespeech | 0.278224 | 0.378693 | 0.370702 | 0.509343 |
| kohatespeech_apeach | 0.337667 | 0.556898 | 0.581788 | 0.667511 |
| kohatespeech_gen_bias | 0.248404 | 0.484745 | 0.473659 | 0.461714 |
| korunsmile | 0.327145 | 0.329163 | 0.347889 | 0.395522 |
| nsmc | 0.6442 | 0.87702 | 0.89982 | 0.90984 |
| pawsx_ko | 0.5355 | 0.5455 | 0.5435 | 0.5255 |
Remove ValueError at load_tokenizer function(line 109 or near), in modules/models.py.
diff --git a/modules/models.py b/modules/models.py
index 232d5fa..de5b7a0 100644
--- a/modules/models.py
+++ b/modules/models.py
@@ -106,7 +106,7 @@ def load_tokenizer(model_name, model):
trust_remote_code=shared.args.trust_remote_code,
use_fast=False
)
- except ValueError:
+ except:
tokenizer = AutoTokenizer.from_pretrained(
path_to_model,
trust_remote_code=shared.args.trust_remote_code,
Since Llama-2-Ko uses FastTokenizer provided by HF tokenizers NOT sentencepiece package,
it is required to use use_fast=True option when initialize tokenizer.
Apple Sillicon does not support BF16 computing, use CPU instead. (BF16 is supported when using NVIDIA GPU)
@misc {l._junbum_2023,
author = { {L. Junbum, Taekyoon Choi} },
title = { llama-2-koen-13b },
year = 2023,
url = { https://huggingface.co/beomi/llama-2-koen-13b },
doi = { 10.57967/hf/1280 },
publisher = { Hugging Face }
}
The training is supported by TPU Research Cloud program.