
license: mit
arxiv: 2205.12424
datasets:
- code_x_glue_cc_defect_detection
metrics:
- accuracy
- precision
- recall
- f1
- roc_auc
model-index:
- name: VulBERTa MLP
results:
- task:
type: defect-detection
dataset:
name: codexglue-devign
type: codexglue-devign
metrics:
- name: Accuracy
type: Accuracy
value: 64.71
- name: Precision
type: Precision
value: 64.8
- name: Recall
type: Recall
value: 50.76
- name: F1
type: F1
value: 56.93
- name: ROC-AUC
type: ROC-AUC
value: 71.02
pipeline_tag: text-classification
tags:
- devign
- defect detection
- code
VulBERTa MLP Devign
VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection
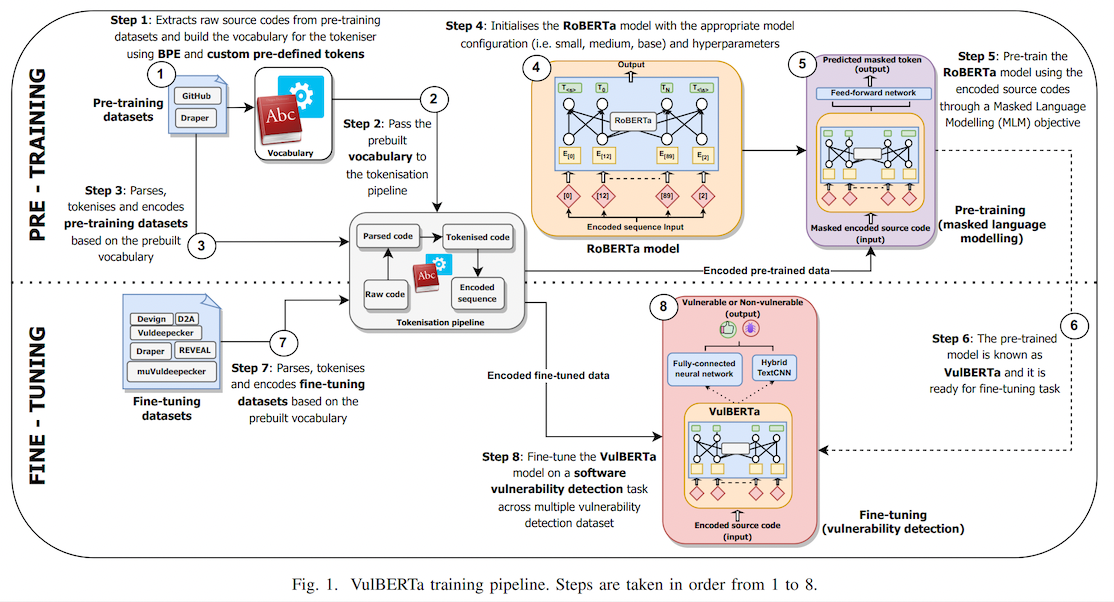
Overview
This model is the unofficial HuggingFace version of "VulBERTa" with an MLP classification head, trained on CodeXGlue Devign (C code), by Hazim Hanif & Sergio Maffeis (Imperial College London). I simplified the tokenization process by adding the cleaning (comment removal) step to the tokenizer and added the simplified tokenizer to this model repo as an AutoClass.
This paper presents presents VulBERTa, a deep learning approach to detect security vulnerabilities in source code. Our approach pre-trains a RoBERTa model with a custom tokenisation pipeline on real-world code from open-source C/C++ projects. The model learns a deep knowledge representation of the code syntax and semantics, which we leverage to train vulnerability detection classifiers. We evaluate our approach on binary and multi-class vulnerability detection tasks across several datasets (Vuldeepecker, Draper, REVEAL and muVuldeepecker) and benchmarks (CodeXGLUE and D2A). The evaluation results show that VulBERTa achieves state-of-the-art performance and outperforms existing approaches across different datasets, despite its conceptual simplicity, and limited cost in terms of size of training data and number of model parameters.
Usage
You must install libclang for tokenization.
pip install libclang
Note that due to the custom tokenizer, you must pass trust_remote_code=True when instantiating the model.
Example:
from transformers import pipeline
pipe = pipeline("text-classification", model="claudios/VulBERTa-MLP-Devign", trust_remote_code=True, return_all_scores=True)
pipe("static void filter_mirror_setup(NetFilterState *nf, Error **errp)\n{\n MirrorState *s = FILTER_MIRROR(nf);\n Chardev *chr;\n chr = qemu_chr_find(s->outdev);\n if (chr == NULL) {\n error_set(errp, ERROR_CLASS_DEVICE_NOT_FOUND,\n \"Device '%s' not found\", s->outdev);\n qemu_chr_fe_init(&s->chr_out, chr, errp);")
>> [[{'label': 'LABEL_0', 'score': 0.014685827307403088},
{'label': 'LABEL_1', 'score': 0.985314130783081}]]
Data
We provide all data required by VulBERTa.
This includes:
- Tokenizer training data
- Pre-training data
- Fine-tuning data
Please refer to the data directory for further instructions and details.
Models
We provide all models pre-trained and fine-tuned by VulBERTa.
This includes:
- Trained tokenisers
- Pre-trained VulBERTa model (core representation knowledge)
- Fine-tuned VulBERTa-MLP and VulBERTa-CNN models
Please refer to the models directory for further instructions and details.
How to use
In our project, we uses Jupyterlab notebook to run experiments.
Therefore, we separate each task into different notebook:
- Pretraining_VulBERTa.ipynb - Pre-trains the core VulBERTa knowledge representation model using DrapGH dataset.
- Finetuning_VulBERTa-MLP.ipynb - Fine-tunes the VulBERTa-MLP model on a specific vulnerability detection dataset.
- Evaluation_VulBERTa-MLP.ipynb - Evaluates the fine-tuned VulBERTa-MLP models on testing set of a specific vulnerability detection dataset.
- Finetuning+evaluation_VulBERTa-CNN - Fine-tunes VulBERTa-CNN models and evaluates it on a testing set of a specific vulnerability detection dataset.
Citation
Accepted as conference paper (oral presentation) at the International Joint Conference on Neural Networks (IJCNN) 2022.
Link to paper: https://ieeexplore.ieee.org/document/9892280
@INPROCEEDINGS{hanif2022vulberta,
author={Hanif, Hazim and Maffeis, Sergio},
booktitle={2022 International Joint Conference on Neural Networks (IJCNN)},
title={VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection},
year={2022},
volume={},
number={},
pages={1-8},
doi={10.1109/IJCNN55064.2022.9892280}
}