
I don't know why so many downloads about this model. Please share your cases, thanks.
Now this model is improved by DPO to cloudyu/Pluto_24B_DPO_200
- Metrics improved by DPO



Mixtral MOE 4x7B
MOE the following models by mergekit:
- Q-bert/MetaMath-Cybertron-Starling
- mistralai/Mistral-7B-Instruct-v0.2
- teknium/Mistral-Trismegistus-7B
- meta-math/MetaMath-Mistral-7B
- openchat/openchat-3.5-1210
Metrics
- Average : 68.85
- ARC:65.36
- HellaSwag:85.23
- more details: https://huggingface.co/datasets/open-llm-leaderboard/results/blob/main/cloudyu/Mixtral_7Bx4_MOE_24B/results_2023-12-23T18-05-51.243288.json
gpu code example
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import math
## v2 models
model_path = "cloudyu/Mixtral_7Bx4_MOE_24B"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_default_system_prompt=False)
model = AutoModelForCausalLM.from_pretrained(
model_path, torch_dtype=torch.float32, device_map='auto',local_files_only=False, load_in_4bit=True
)
print(model)
prompt = input("please input prompt:")
while len(prompt) > 0:
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")
generation_output = model.generate(
input_ids=input_ids, max_new_tokens=500,repetition_penalty=1.2
)
print(tokenizer.decode(generation_output[0]))
prompt = input("please input prompt:")
CPU example
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import math
## v2 models
model_path = "cloudyu/Mixtral_7Bx4_MOE_24B"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_default_system_prompt=False)
model = AutoModelForCausalLM.from_pretrained(
model_path, torch_dtype=torch.float32, device_map='cpu',local_files_only=False
)
print(model)
prompt = input("please input prompt:")
while len(prompt) > 0:
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
generation_output = model.generate(
input_ids=input_ids, max_new_tokens=500,repetition_penalty=1.2
)
print(tokenizer.decode(generation_output[0]))
prompt = input("please input prompt:")
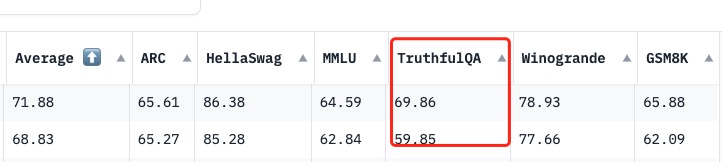
Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 68.83 |
| AI2 Reasoning Challenge (25-Shot) | 65.27 |
| HellaSwag (10-Shot) | 85.28 |
| MMLU (5-Shot) | 62.84 |
| TruthfulQA (0-shot) | 59.85 |
| Winogrande (5-shot) | 77.66 |
| GSM8k (5-shot) | 62.09 |
- Downloads last month
- 2,233
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.
Model tree for cloudyu/Mixtral_7Bx4_MOE_24B
Spaces using cloudyu/Mixtral_7Bx4_MOE_24B 12
Evaluation results
- normalized accuracy on AI2 Reasoning Challenge (25-Shot)test set Open LLM Leaderboard65.270
- normalized accuracy on HellaSwag (10-Shot)validation set Open LLM Leaderboard85.280
- accuracy on MMLU (5-Shot)test set Open LLM Leaderboard62.840
- mc2 on TruthfulQA (0-shot)validation set Open LLM Leaderboard59.850
- accuracy on Winogrande (5-shot)validation set Open LLM Leaderboard77.660
- accuracy on GSM8k (5-shot)test set Open LLM Leaderboard62.090