
Document Processing
Collection
Any model or dataset dealing with documentary-type objects (layout detection, VQA, OCR, etc.)
•
9 items
•
Updated
•
2
paligemma-3b-ft-tablevqa-896-lora is a fine-tuned version of the google/paligemma-3b-ft-docvqa-896 model, trained specifically on the table-vqa dataset published by Crédit Mutuel Arkéa. This model leverages the LoRA (Low-Rank Adaptation) technique, which significantly reduces the computational complexity of fine-tuning while maintaining high performance. The model operates in bfloat16 precision for efficiency, making it an ideal solution for resource-constrained environments.
This model is designed for multilingual environments (French and English) and excels in table-based visual question-answering (VQA) tasks. It is highly suitable for extracting information from tables in documents, making it a strong candidate for applications in financial reporting, data analysis, or administrative document processing. The model was fine-tuned over a span of 7 days using a single A100 40GB GPU.
This model was built on top of google/paligemma-3b-ft-docvqa-896, using its pre-trained multi-modal capabilities to process both text and images (e.g., document tables). LoRA was applied to reduce the size and complexity of fine-tuning while preserving accuracy, allowing the model to excel in specific tasks such as table understanding and VQA.
You can use this model for visual question answering with table-based data by following the steps below:
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
import requests
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "cmarkea/paligemma-3b-ft-tablevqa-896-lora"
# Sample image for inference
url = "https://datasets-server.huggingface.co/cached-assets/cmarkea/table-vqa/--/c26968da3346f92ab6bfc5fec85592f8250e23f5/--/default/train/22/image/image.jpg?Expires=1728915081&Signature=Zkrd9ZWt5b9XtY0UFrgfrTuqo58DHWIJ00ZwXAymmL-mrwqnWWmiwUPelYOOjPZZdlP7gAvt96M1PKeg9a2TFm7hDrnnRAEO~W89li~AKU2apA81M6AZgwMCxc2A0xBe6rnCPQumiCGD7IsFnFVwcxkgMQXyNEL7bEem6cT0Cief9DkURUDCC-kheQY1hhkiqLLUt3ITs6o2KwPdW97EAQ0~VBK1cERgABKXnzPfAImnvjw7L-5ZXCcMJLrvuxwgOQ~DYPs456ZVxQLbTxuDwlxvNbpSKoqoAQv0CskuQwTFCq2b5MOkCCp9zoqYJxhUhJ-aI3lhyIAjmnsL4bhe6A__&Key-Pair-Id=K3EI6M078Z3AC3"
image = Image.open(requests.get(url, stream=True).raw)
# Load the fine-tuned model and processor
model = PaliGemmaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map=device,
).eval()
processor = AutoProcessor.from_pretrained("google/paligemma-3b-ft-docvqa-896")
# Input prompt for table VQA
prompt = "How many rows are in this table?"
model_inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
# Generate the answer
input_len = model_inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**model_inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
The model's performance was evaluated on 200 question-answer pairs, extracted from 100 tables from the test set of the table-vqa dataset. For each table, two pairs were selected: one in French and the other in English.
To evaluate the model’s responses, the LLM-as-Juries framework was employed using three judge models (GPT-4o, Gemini1.5 Pro, and Claude 3.5-Sonnet). The evaluation was based on a scale from 0 to 5, tailored to the VQA context, ensuring accurate judgment of the model’s performance.
Here’s a visualization of the results:
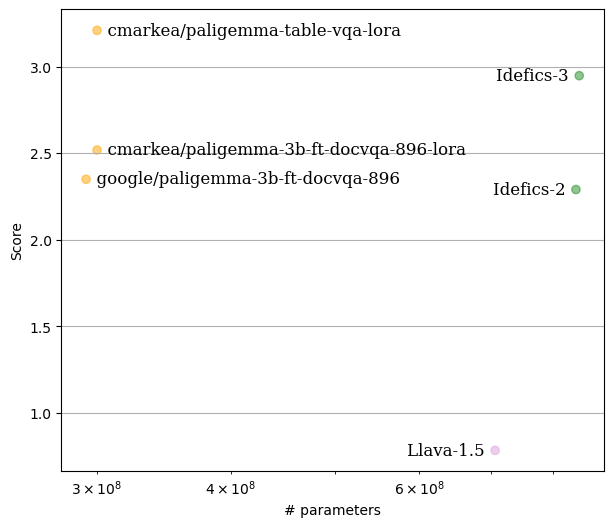
In comparison, this model outperforms HuggingFaceM4/Idefics3-8B-Llama3 in terms of accuracy and efficiency, despite having a smaller parameter size.
@online{AgDePaligemmaTabVQA,
AUTHOR = {Tom Agonnoude, Cyrile Delestre},
URL = {https://huggingface.co/cmarkea/paligemma-tablevqa-896-lora},
YEAR = {2024},
KEYWORDS = {Multimodal, VQA, Table Understanding, LoRA},
}
Base model
google/paligemma-3b-ft-docvqa-896