
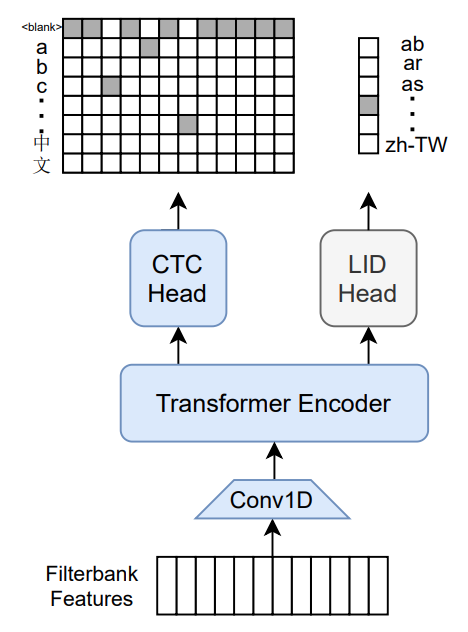
M-CTC-T
Massively multilingual speech recognizer from Meta AI. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
The original Flashlight code, model checkpoints, and Colab notebook can be found at https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl .
The original Flashlight code, model checkpoints, and Colab notebook can be found at https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl .
Citation
Paper Authors: Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, Ronan Collobert
@article{lugosch2021pseudo,
title={Pseudo-Labeling for Massively Multilingual Speech Recognition},
author={Lugosch, Loren and Likhomanenko, Tatiana and Synnaeve, Gabriel and Collobert, Ronan},
journal={ICASSP},
year={2022}
}
Additional thanks to Chan Woo Kim and Patrick von Platen for porting the model from Flashlight to PyTorch.
Training method
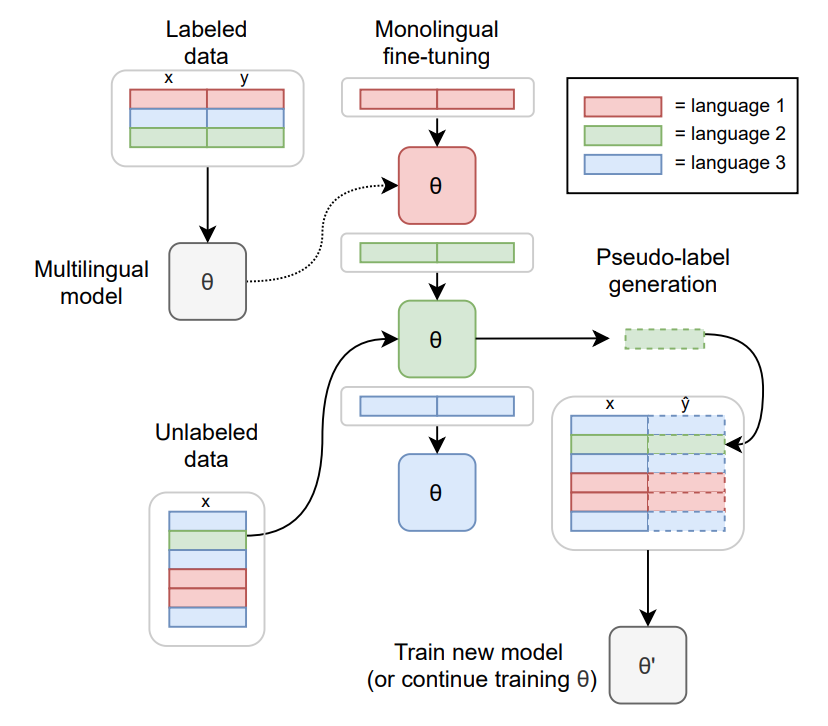 TO-DO: replace with the training diagram from paper
For more information on how the model was trained, please take a look at the official paper.
TO-DO: replace with the training diagram from paper
For more information on how the model was trained, please take a look at the official paper.
Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
import torch
import torchaudio
from datasets import load_dataset
from transformers import MCTCTForCTC, MCTCTProcessor
model = MCTCTForCTC.from_pretrained("speechbrain/mctct-large")
processor = MCTCTProcessor.from_pretrained("speechbrain/mctct-large")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_features = processor(ds[0]["audio"]["array"], return_tensors="pt").input_features
# retrieve logits
logits = model(input_features).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
Results for Common Voice, averaged over all languages: Character error rate (CER):
| Valid | Test |
|---|---|
| 21.4 | 23.3 |
- Downloads last month
- 4