
task_categories:
- multiple-choice
- question-answering
- visual-question-answering
language:
- en
size_categories:
- 1K<n<10K
configs:
- config_name: testmini
data_files:
- split: testmini
path: testmini.parquet
- config_name: testmini_text_only
data_files:
- split: testmini_text_only
path: testmini_text_only.parquet
dataset_info:
- config_name: testmini
features:
- name: sample_index
dtype: string
- name: problem_index
dtype: string
- name: problem_version
dtype: string
- name: question
dtype: string
- name: image
dtype: image
- name: answer
dtype: string
- name: question_type
dtype: string
- name: metadata
struct:
- name: split
dtype: string
- name: source
dtype: string
- name: subject
dtype: string
- name: subfield
dtype: string
- name: query_wo
dtype: string
- name: query_cot
dtype: string
splits:
- name: testmini
num_bytes: 166789963
num_examples: 3940
- config_name: testmini_text_only
features:
- name: sample_index
dtype: string
- name: problem_index
dtype: string
- name: problem_version
dtype: string
- name: question
dtype: string
- name: image
dtype: string
- name: answer
dtype: string
- name: question_type
dtype: string
- name: metadata
struct:
- name: split
dtype: string
- name: source
dtype: string
- name: subject
dtype: string
- name: subfield
dtype: string
- name: query_wo
dtype: string
- name: query_cot
dtype: string
splits:
- name: testmini_text_only
num_bytes: 250959
num_examples: 788
Dataset Card for MathVerse
Dataset Description
The capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving remain insufficiently evaluated and understood. We investigate current benchmarks to incorporate excessive visual content within textual questions, which potentially assist MLLMs in deducing answers without truly interpreting the input diagrams.
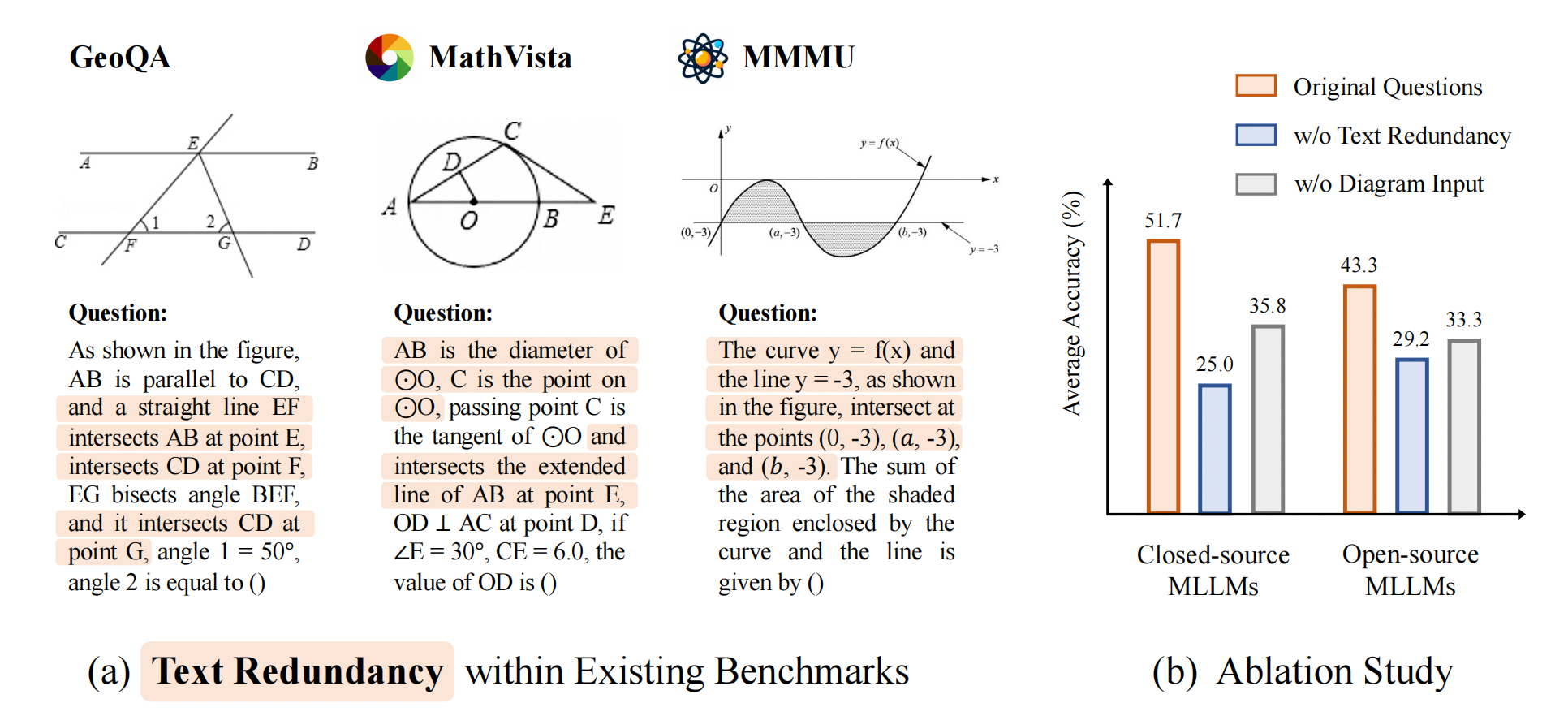
To this end, we introduce MathVerse, an all-around visual math benchmark designed for an equitable and in-depth evaluation of MLLMs. We meticulously collect 2,612 high-quality, multi-subject math problems with diagrams from publicly available sources. Each problem is then transformed by human annotators into six distinct versions, each offering varying degrees of information content in multi-modality, contributing to 15K test samples in total. This approach allows MathVerse to comprehensively assess whether and how much MLLMs can truly understand the visual diagrams for mathematical reasoning.
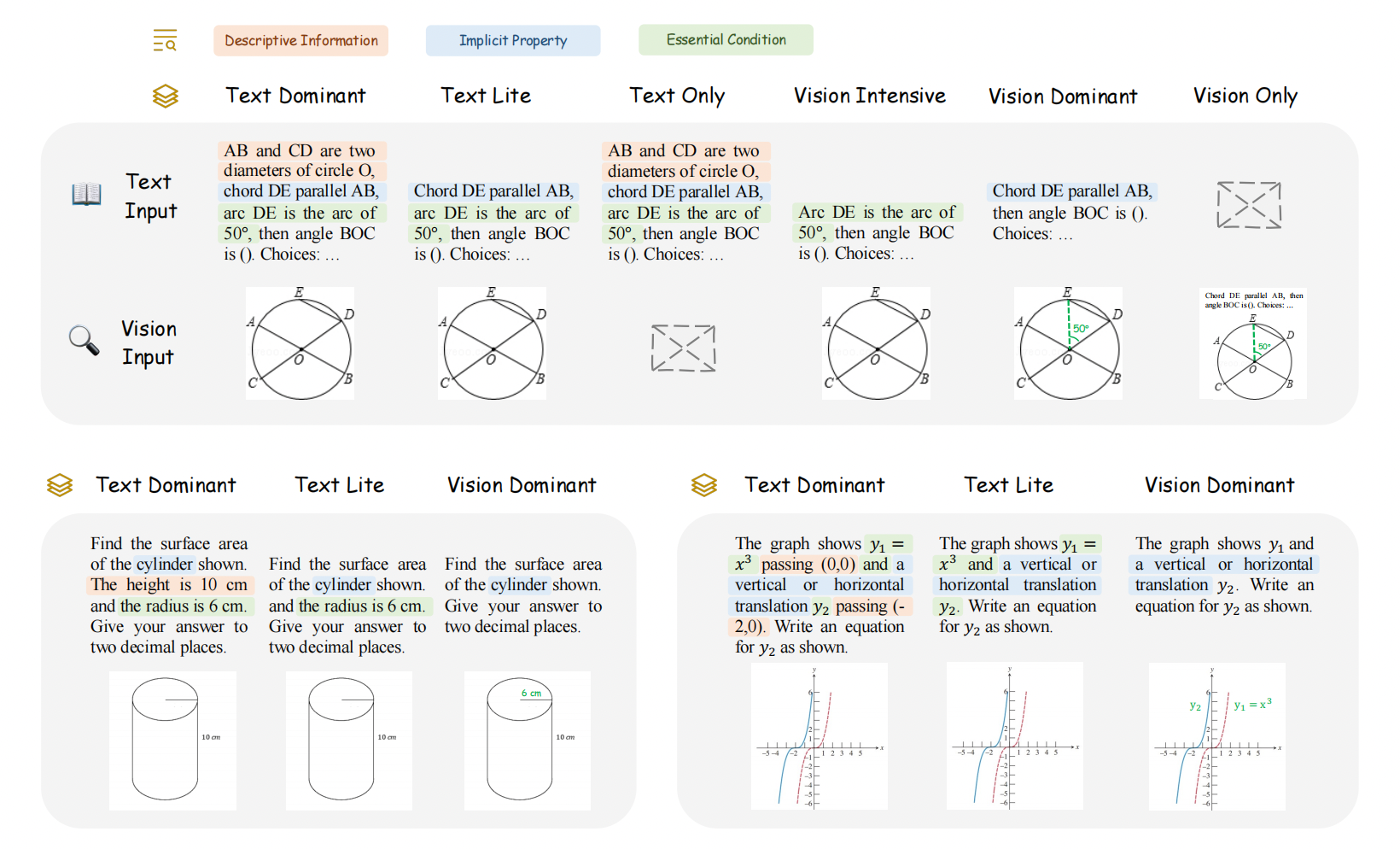
Six different versions of each problem in MathVerse transformed by expert annotators.
In addition, we propose a Chain-of-Thought (CoT) Evaluation strategy for a fine-grained assessment of the output answers. Rather than naively judging True or False, we employ GPT-4(V) to adaptively extract crucial reasoning steps, and then score each step with detailed error analysis, which can reveal the intermediate CoT reasoning quality by MLLMs.

The two phases of the CoT evaluation strategy.
Paper Information
- Code: https://github.com/ZrrSkywalker/MathVerse
- Project: https://mathverse-cuhk.github.io/
- Visualization: https://mathverse-cuhk.github.io/#visualization
- Leaderboard: https://mathverse-cuhk.github.io/#leaderboard
- Paper: https://arxiv.org/abs/2403.14624
Dataset Examples
🖱 Click to expand the examples for six problems versions within three subjects
🔍 Plane Geometry
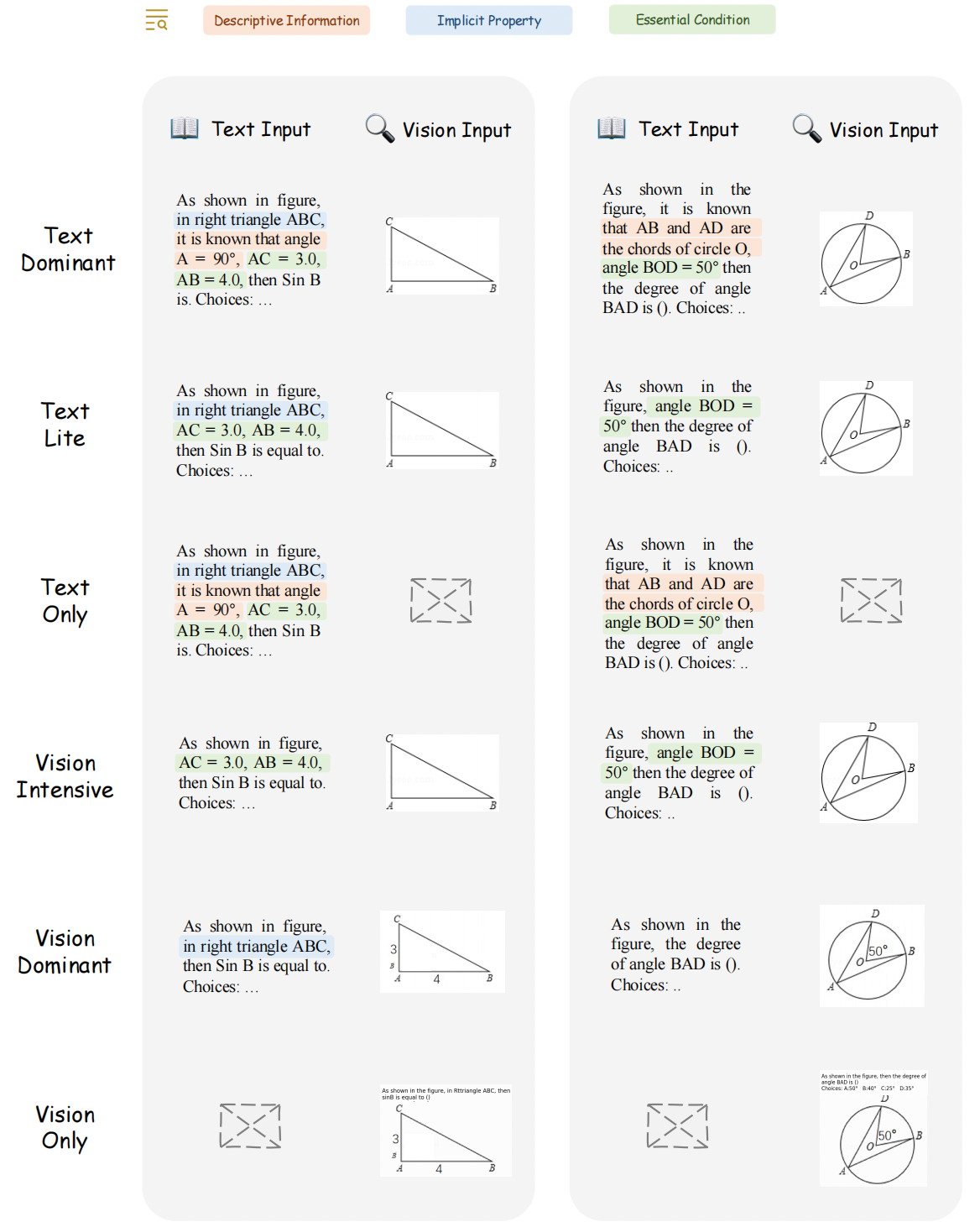
🔍 Solid Geometry
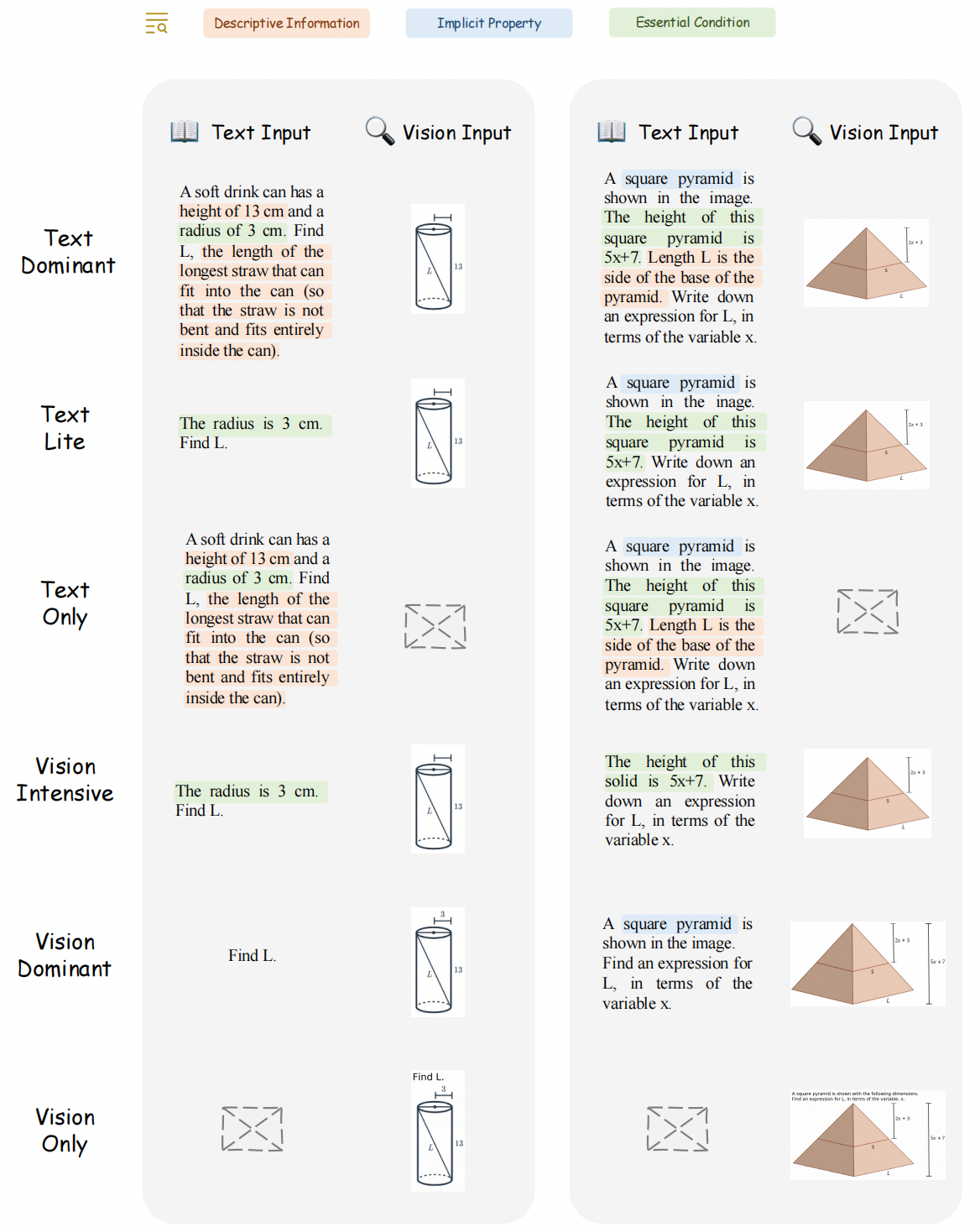
🔍 Functions

Leaderboard
Contributing to the Leaderboard
🚨 The Leaderboard is continuously being updated.
The evaluation instructions and tools will be released soon. For now, please send your results on the testmini set to this email: [email protected]. Please refer to the following template to prepare your result json file.
Citation
If you find MathVerse useful for your research and applications, please kindly cite using this BibTeX:
@inproceedings{zhang2024mathverse,
title={MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?},
author={Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, Hongsheng Li},
booktitle={arXiv},
year={2024}
}