

Commit
•
df6c609
1
Parent(s):
4e8eaa6
Upload 13 files
Browse files- README.md +184 -0
- README_ZH.md +193 -0
- img/.DS_Store +0 -0
- img/classify.png +3 -0
- img/classify_exp.png +3 -0
- img/cpt_two_stage.png +3 -0
- img/data_pipelien.jpg +3 -0
- img/data_pipeline-en.png +3 -0
- img/data_ratio.png +3 -0
- img/disk-gb.png +3 -0
- img/quality-exp.png +3 -0
- img/quality_ratio.png +3 -0
- img/quality_train.png +3 -0
README.md
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Industry models play a vital role in promoting the intelligent transformation and innovative development of enterprises. High-quality industry data is the key to improving the performance of large models and realizing the implementation of industry applications. However, the data sets currently used for industry model training generally have problems such as small data volume, low quality, and lack of professionalism.
|
| 2 |
+
|
| 3 |
+
In June, we released the [IndustryCorpus](https://huggingface.co/datasets/BAAI/Industry-Instruction) dataset: We have further upgraded and iterated on this dataset, and the iterative contents are as follows:
|
| 4 |
+
|
| 5 |
+
- Data source: Based on the original data, we introduced more high-quality data sources, such as pile, bigcode, open-web-math and other mathematical and code data
|
| 6 |
+
- Update the industry category system: In order to better fit the industry classification system, we combined the national economic industry classification system (20 categories) formulated by the National Bureau of Statistics and the world knowledge system to redesign the industry categories, setting up 31 industry categories, basically covering the current mainstream industries
|
| 7 |
+
- Data semantic quality screening: We decentralized the IndustryCorpus high-quality data production plan, and used the rule filtering + model filtering solution in the IndustryCorpus2.0 open source data, which greatly improved the overall data quality;
|
| 8 |
+
- Data quality stratification: In order to further integrate data quality at different levels, we stratify and organize the data based on the quality assessment score, dividing the data into three levels: high, middle, and low.
|
| 9 |
+
- Data size: 1TB for Chinese and 2.2TB for English
|
| 10 |
+
|
| 11 |
+
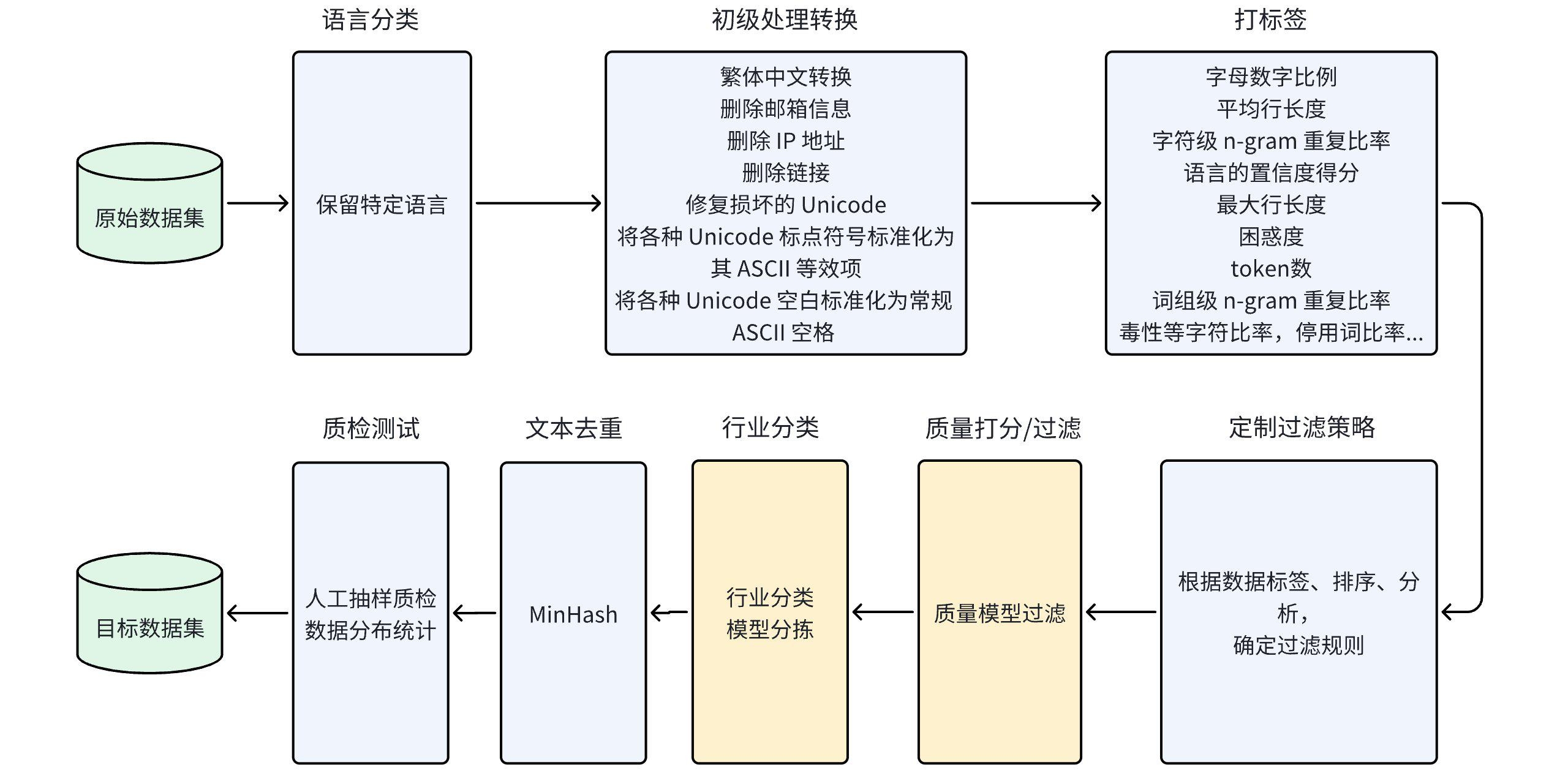
The data processing process is consistent with IndustryCorpus
|
| 12 |
+
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
## Data Perspective
|
| 16 |
+
|
| 17 |
+
### Industry Data Distribution
|
| 18 |
+
|
| 19 |
+
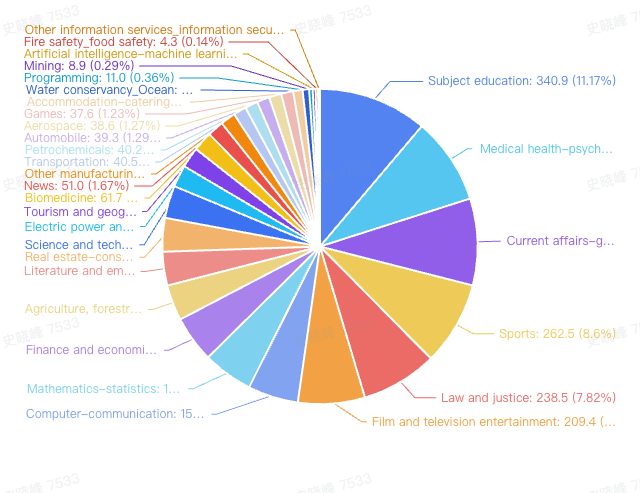
The disk size of each industry data after full process processing is as follows
|
| 20 |
+
|
| 21 |
+
| Industry category | Data size (GB) | Industry category | Data size (GB) |
|
| 22 |
+
| :-------------------------------------------------: | :------------: | :-----------------------------------------------: | :------------: |
|
| 23 |
+
| Programming | 11.0 | News | 51.0 |
|
| 24 |
+
| Biomedicine | 61.7 | Petrochemical | 40.2 |
|
| 25 |
+
| Medical health-psychology and Chinese medicine | 271.7 | Aerospace | 38.6 |
|
| 26 |
+
| Tourism and geography | 64.0 | Mining | 8.9 |
|
| 27 |
+
| Law and justice | 238.5 | Finance and economics | 145.8 |
|
| 28 |
+
| Mathematics-statistics | 156.7 | Literature and emotions | 105.5 |
|
| 29 |
+
| Other information services_information security | 1.8 | Transportation | 40.5 |
|
| 30 |
+
| Fire safety_food safety | 4.3 | Science and technology_scientific research | 101.6 |
|
| 31 |
+
| Automobile | 39.3 | Water Conservancy_Ocean | 20.2 |
|
| 32 |
+
| Accommodation-catering-hotel | 29.6 | Computer-communication | 157.8 |
|
| 33 |
+
| Film and television entertainment | 209.4 | Subject education | 340.9 |
|
| 34 |
+
| Real estate-construction | 105.2 | Artificial intelligence-machine learning | 7.7 |
|
| 35 |
+
| Electric power and energy | 68.7 | Current affairs-government affairs-administration | 271.5 |
|
| 36 |
+
| Agriculture, forestry, animal husbandry and fishery | 111.9 | Sports | 262.5 |
|
| 37 |
+
| Games | 37.6 | Other manufacturing | 47.2 |
|
| 38 |
+
| Others | 188.6 | | |
|
| 39 |
+
| Total (GB) | 3276G | | |
|
| 40 |
+
|
| 41 |
+
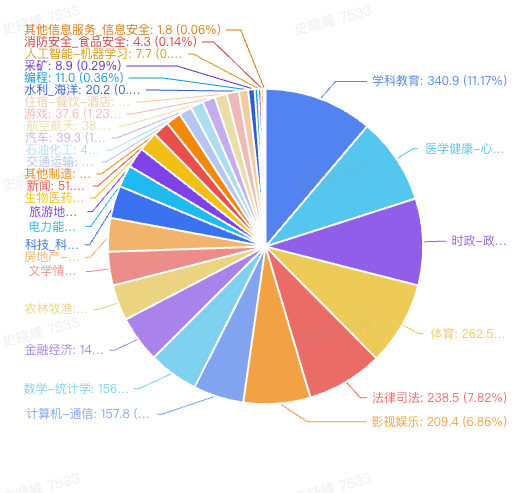
The industry data distribution chart in the summary data set is as follows
|
| 42 |
+
|
| 43 |
+

|
| 44 |
+
|
| 45 |
+
From the distribution chart, we can see that subject education, sports, current affairs, law, medical health, film and television entertainment account for most of the overall data. The data of these industries are widely available on the Internet and textbooks, and the high proportion of them is in line with expectations. It is worth mentioning that since we have supplemented the data of mathematics, we can see that the proportion of mathematics data is also high, which is inconsistent with the proportion of mathematics Internet corpus data.
|
| 46 |
+
|
| 47 |
+
### Data quality stratification
|
| 48 |
+
|
| 49 |
+
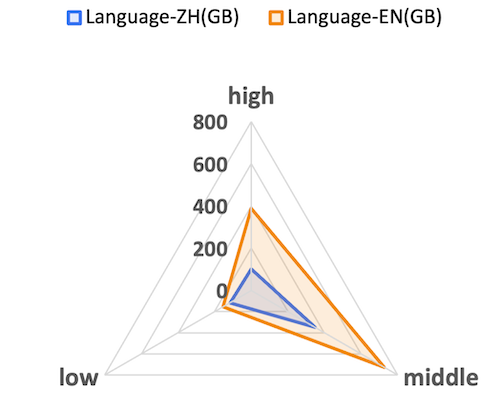
We filter the entire data according to data quality, remove extremely low-quality data, and divide the available data into three independent groups: Low, Middle, and Hight, to facilitate data matching and combination during model training. The distribution of data of different qualities is shown below. It can be seen that the data quality distribution trends of Chinese and English are basically the same, with the largest number of middle data, followed by middle data, and the least number of low data; in addition, it can be observed that the proportion of hight data in English is higher than that in Chinese (with a larger slope), which is also in line with the current trend of distribution of different languages.
|
| 50 |
+
|
| 51 |
+

|
| 52 |
+
|
| 53 |
+
## Industry Category Classification
|
| 54 |
+
|
| 55 |
+
In order to improve the coverage of industry classification in the data set to actual industries and align with the industry catalog defined in the national standard, we refer to the national economic industry classification system and the world knowledge system formulated by the National Bureau of Statistics, merge and integrate the categories, and design the final 31 industry categories covering Chinese and English. The category table names are as follows
|
| 56 |
+
|
| 57 |
+
```
|
| 58 |
+
{
|
| 59 |
+
"数学_统计": {"zh": "数学与统计", "en": "Math & Statistics"},
|
| 60 |
+
"体育": {"zh": "体育", "en": "Sports"},
|
| 61 |
+
"农林牧渔": {"zh": "农业与渔业", "en": "Agriculture & Fisheries"},
|
| 62 |
+
"房地产_建筑": {"zh": "房地产与建筑", "en": "Real Estate & Construction"},
|
| 63 |
+
"时政_政务_行政": {"zh": "政治与行政", "en": "Politics & Administration"},
|
| 64 |
+
"消防安全_食品安全": {"zh": "安全管理", "en": "Safety Management"},
|
| 65 |
+
"石油化工": {"zh": "石油化工", "en": "Petrochemicals"},
|
| 66 |
+
"计算机_通信": {"zh": "计算机与通信", "en": "Computing & Telecommunications"},
|
| 67 |
+
"交通运输": {"zh": "交通运输", "en": "Transportation"},
|
| 68 |
+
"其他": {"zh": "其他", "en": "Others"},
|
| 69 |
+
"医学_健康_心理_中医": {"zh": "健康与医学", "en": "Health & Medicine"},
|
| 70 |
+
"文学_情感": {"zh": "文学与情感", "en": "Literature & Emotions"},
|
| 71 |
+
"水利_海洋": {"zh": "水利与海洋", "en": "Water Resources & Marine"},
|
| 72 |
+
"游戏": {"zh": "游戏", "en": "Gaming"},
|
| 73 |
+
"科技_科学研究": {"zh": "科技与研究", "en": "Technology & Research"},
|
| 74 |
+
"采矿": {"zh": "采矿", "en": "Mining"},
|
| 75 |
+
"人工智能_机器学习": {"zh": "人工智能", "en": "Artificial Intelligence"},
|
| 76 |
+
"其他信息服务_信息安全": {"zh": "信息服务", "en": "Information Services"},
|
| 77 |
+
"学科教育_教育": {"zh": "学科教育", "en": "Subject Education"},
|
| 78 |
+
"新闻传媒": {"zh": "新闻传媒", "en": "Media & Journalism"},
|
| 79 |
+
"汽车": {"zh": "汽车", "en": "Automobiles"},
|
| 80 |
+
"生物医药": {"zh": "生物医药", "en": "Biopharmaceuticals"},
|
| 81 |
+
"航空航天": {"zh": "航空航天", "en": "Aerospace"},
|
| 82 |
+
"金融_经济": {"zh": "金融与经济", "en": "Finance & Economics"},
|
| 83 |
+
"住宿_餐饮_酒店": {"zh": "住宿与餐饮", "en": "Hospitality & Catering"},
|
| 84 |
+
"其他制造": {"zh": "制造业", "en": "Manufacturing"},
|
| 85 |
+
"影视_娱乐": {"zh": "影视与娱乐", "en": "Film & Entertainment"},
|
| 86 |
+
"旅游_地理": {"zh": "旅游与地理", "en": "Travel & Geography"},
|
| 87 |
+
"法律_司法": {"zh": "法律与司法", "en": "Law & Justice"},
|
| 88 |
+
"电力能源": {"zh": "电力与能源", "en": "Power & Energy"},
|
| 89 |
+
"计算机编程_代码": {"zh": "编程", "en": "Programming"},
|
| 90 |
+
}
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
- Data construction of industry classification model
|
| 94 |
+
|
| 95 |
+
- Data construction
|
| 96 |
+
|
| 97 |
+
Data source: pre-training corpus sampling and open source text classification data, of which pre-training corpus accounts for 90%. Through data sampling, the ratio of Chinese and English data is guaranteed to be 1:1
|
| 98 |
+
|
| 99 |
+
Label construction: Use the LLM model to make multiple classification judgments on the data, and select the data with consistent multiple judgments as training data
|
| 100 |
+
|
| 101 |
+
Data scale: 36K
|
| 102 |
+
|
| 103 |
+
The overall process of data construction is as follows:
|
| 104 |
+
|
| 105 |
+

|
| 106 |
+
|
| 107 |
+
- Model training:
|
| 108 |
+
|
| 109 |
+
Parameter update: add classification head to pre-trained BERT model for text classification model training
|
| 110 |
+
|
| 111 |
+
Model selection: considering model performance and inference efficiency, we selected a 0.5B scale model. Through comparative experiments, we finally selected BGE-M3 and full parameter training as our base model
|
| 112 |
+
|
| 113 |
+
Training hyperparameters: full parameter training, max_length = 2048, lr = 1e-5, batch_size = 64, validation set evaluation acc: 86%
|
| 114 |
+
|
| 115 |
+

|
| 116 |
+
|
| 117 |
+
## Data quality assessment
|
| 118 |
+
|
| 119 |
+
- Why should we filter low-quality data?
|
| 120 |
+
|
| 121 |
+
Below is low-quality data extracted from the data. It can be seen that this kind of data is harmful to the learning of the model.
|
| 122 |
+
|
| 123 |
+
```
|
| 124 |
+
{"text": "\\_\\__\n\nTranslated from *Chinese Journal of Biochemistry and Molecular Biology*, 2007, 23(2): 154--159 \\[译自:中国生物化学与分子生物学报\\]\n"}
|
| 125 |
+
|
| 126 |
+
{"text": "#ifndef _IMGBMP_H_\n#define _IMGBMP_H_\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\nconst uint8_t bmp[]={\n\\/\\/-- 调入了一幅图像:D:\\我的文档\\My Pictures\\12864-555.bmp --*\\/\n\\/\\/-- 宽度x高度=128x64 --\n0x00,0x06,0x0A,0xFE,0x0A,0xC6,0x00,0xE0,0x00,0xF0,0x00,0xF8,0x00,0x00,0x00,0x00,\n0x00,0x00,0xFE,0x7D,0xBB,0xC7,0xEF,0xEF,0xEF,0xEF,0xEF,0xEF,0xEF,0xC7,0xBB,0x7D,\n0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x08,\n0x0C,0xFE,0xFE,0x0C,0x08,0x20,0x60,0xFE,0xFE,0x60,0x20,0x00,0x00,0x00,0x78,0x48,\n0xFE,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xFE,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFE,0xFF,\n0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,0xFF,0x00,0x00,0xFE,0xFF,0x03,\n0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,0xFE,0x00,0x00,0x00,0x00,0xC0,0xC0,\n0xC0,0x00,0x00,0x00,0x00,0xFE,0xFF,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,\n0xFF,0xFE,0x00,0x00,0xFE,0xFF,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,\n0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,0x00,0x00,0xFF,0xFF,0x0C,\n0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0xFF,0xFF,0x00,0x00,0x00,0x00,0xE1,0xE1,\n0xE1,0x00,0x00,0x00,0x00,0xFF,0xFF,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0xFF,0xFF,0x00,0x00,0xFF,0xFF,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0xFF,\n0xFF,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x0F,0x1F,\n0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,0x0F,0x00,0x00,0x0F,0x1F,0x18,\n0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,0x0F,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x0F,0x1F,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,\n0x1F,0x0F,0x00,0x00,0x0F,0x1F,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,\n0x0F,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0xE2,0x92,0x8A,0x86,0x00,0x00,0x7C,0x82,0x82,0x82,0x7C,\n0x00,0xFE,0x00,0x82,0x92,0xAA,0xC6,0x00,0x00,0xC0,0xC0,0x00,0x7C,0x82,0x82,0x82,\n0x7C,0x00,0x00,0x02,0x02,0x02,0xFE,0x00,0x00,0xC0,0xC0,0x00,0x7C,0x82,0x82,0x82,\n0x7C,0x00,0x00,0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x24,0xA4,0x2E,0x24,0xE4,0x24,0x2E,0xA4,0x24,0x00,0x00,0x00,0xF8,0x4A,0x4C,\n0x48,0xF8,0x48,0x4C,0x4A,0xF8,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xC0,0x20,0x10,0x10,\n0x10,0x10,0x20,0xC0,0x00,0x00,0xC0,0x20,0x10,0x10,0x10,0x10,0x20,0xC0,0x00,0x00,\n0x00,0x12,0x0A,0x07,0x02,0x7F,0x02,0x07,0x0A,0x12,0x00,0x00,0x00,0x0B,0x0A,0x0A,\n0x0A,0x7F,0x0A,0x0A,0x0A,0x0B,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x20,0x40,0x40,\n0x40,0x50,0x20,0x5F,0x80,0x00,0x1F,0x20,0x40,0x40,0x40,0x50,0x20,0x5F,0x80,0x00,\n}; \n\n\n#ifdef __cplusplus\n}\n#endif\n\n#endif \\/\\/ _IMGBMP_H_ _SSD1306_16BIT_H_\n"}
|
| 127 |
+
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
- Data construction
|
| 131 |
+
|
| 132 |
+
Data source: Random sampling of pre-trained corpus
|
| 133 |
+
|
| 134 |
+
Label construction: Design data scoring rules, use LLM model to perform multiple rounds of scoring, and select data with a difference of less than 2 in multiple rounds of scoring
|
| 135 |
+
|
| 136 |
+
Data scale: 20k scoring data, Chinese and English ratio 1:1
|
| 137 |
+
|
| 138 |
+
Data scoring prompt
|
| 139 |
+
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
quality_prompt = """Below is an extract from a web page. Evaluate whether the page has a high natural language value and could be useful in an naturanl language task to train a good language model using the additive 5-point scoring system described below. Points are accumulated based on the satisfaction of each criterion:
|
| 143 |
+
|
| 144 |
+
- Zero score if the content contains only some meaningless content or private content, such as some random code, http url or copyright information, personally identifiable information, binary encoding of images.
|
| 145 |
+
- Add 1 point if the extract provides some basic information, even if it includes some useless contents like advertisements and promotional material.
|
| 146 |
+
- Add another point if the extract is written in good style, semantically fluent, and free of repetitive content and grammatical errors.
|
| 147 |
+
- Award a third point tf the extract has relatively complete semantic content, and is written in a good and fluent style, the entire content expresses something related to the same topic, rather than a patchwork of several unrelated items.
|
| 148 |
+
- A fourth point is awarded if the extract has obvious educational or literary value, or provides a meaningful point or content, contributes to the learning of the topic, and is written in a clear and consistent style. It may be similar to a chapter in a textbook or tutorial, providing a lot of educational content, including exercises and solutions, with little to no superfluous information. The content is coherent and focused, which is valuable for structured learning.
|
| 149 |
+
- A fifth point is awarded if the extract has outstanding educational value or is of very high information density, provides very high value and meaningful content, does not contain useless information, and is well suited for teaching or knowledge transfer. It contains detailed reasoning, has an easy-to-follow writing style, and can provide deep and thorough insights.
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
The extract:
|
| 153 |
+
<{EXAMPLE}>.
|
| 154 |
+
|
| 155 |
+
After examining the extract:
|
| 156 |
+
- Briefly justify your total score, up to 50 words.
|
| 157 |
+
- Conclude with the score using the format: "Quality score: <total points>"
|
| 158 |
+
...
|
| 159 |
+
"""
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
- Model training
|
| 163 |
+
|
| 164 |
+
Model selection: Similar to the classification model, we also used a 0.5b scale model and compared beg-m3 and qwen-0.5b. The final experiment showed that bge-m3 had the best overall performance
|
| 165 |
+
|
| 166 |
+
Model hyperparameters: base bge-m3, full parameter training, lr=1e-5, batch_size=64, max_length = 2048
|
| 167 |
+
|
| 168 |
+
Model evaluation: On the validation set, the consistency rate of the model and GPT4 in sample quality judgment was 90%.
|
| 169 |
+
|
| 170 |
+

|
| 171 |
+
|
| 172 |
+
- Training benefits from high-quality data
|
| 173 |
+
|
| 174 |
+
In order to verify whether high-quality data can bring more efficient training efficiency, we extracted high-quality data from the 50b data before screening under the same base model. It can be considered that the distribution of the two data is roughly the same, and autoregressive training is performed.
|
| 175 |
+
|
| 176 |
+
As can be seen from the curve, the 14B tokens of the model trained with high-quality data can achieve the performance of the model with 50B of ordinary data. High-quality data can greatly improve training efficiency.
|
| 177 |
+
|
| 178 |
+

|
| 179 |
+
|
| 180 |
+
In addition, high-quality data can be added to the model as data in the pre-training annealing stage to further improve the model effect. To verify this conjecture, when training the industry model, we added pre-training data converted from high-quality data after screening and some instruction data to the annealing stage of the model. It can be seen that the performance of the model has been greatly improved.
|
| 181 |
+
|
| 182 |
+

|
| 183 |
+
|
| 184 |
+
Finally, high-quality pre-training predictions contain a wealth of high-value knowledge content, from which instruction data can be extracted to further improve the richness and knowledge of instruction data. This also gave rise to the [Industry-Instruction](https://huggingface.co/datasets/BAAI/Industry-Instruction) project, which we will explain in detail there.
|
README_ZH.md
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 数据说明
|
| 2 |
+
|
| 3 |
+
行业模型在推动企业智能化转型和创新发展中发挥着至关重要的作用。高质量的行业数据是提升大模型性能和实现行业应用落地的关键。然而,目前用于行业模型训练的数据集普遍存在数据量少、质量低、专业性不足等问题。
|
| 4 |
+
|
| 5 |
+
在6月份我们发布了[IndustryCorpus](https://huggingface.co/datasets/BAAI/Industry-Instruction)数据集: 我们在该数据集的基础上进行了进一步的升级迭代,迭代内容如下:
|
| 6 |
+
|
| 7 |
+
- 数据来源:在原有数据基础上,引入了更多的高质量数据源,如pile,bigcode,open-web-math等数学和代码数据
|
| 8 |
+
- 更新行业类目体系:为了更贴合行业的划分体系,我们结合国家统计局制定的国民经济行业分类体系(20门类)和世界知识体系进行了行业类目的重新设计,设置了31个行业类目,基本覆盖当前在主流行业
|
| 9 |
+
- 数据语义质量筛选:我们将IndustryCorpus高质量数据制作方案下放,在IndustryCorpus2.0开源数据使用规则过滤+模型过滤的方案,整体极大提升了数据的质量;
|
| 10 |
+
- 数据质量分层:为了进一步整合不同层次的数据质量,我们以质量评估分数为基准对数据进行分层正整理,划分出high,middle,low三个层次的数据
|
| 11 |
+
|
| 12 |
+
- 数据大小:中文1TB, 英文2.2TB
|
| 13 |
+
|
| 14 |
+
数据的处理流程与IndustryCorpus保持一致
|
| 15 |
+
|
| 16 |
+

|
| 17 |
+
|
| 18 |
+
##数据透视
|
| 19 |
+
|
| 20 |
+
### 行业数据分布
|
| 21 |
+
|
| 22 |
+
经过全流程处理后的各行业数据磁盘大小如下所示
|
| 23 |
+
|
| 24 |
+
| 行业类别 | 数据大小(GB) | 行业类别 | 数据大小(GB) |
|
| 25 |
+
| :----------: | :--------------: | :--------: | :--------------: |
|
| 26 |
+
| 编程 | 11.0 | 新闻 | 51.0 |
|
| 27 |
+
| 生物医药 | 61.7 | 石油化工 | 40.2 |
|
| 28 |
+
| 医学健康-心理中医 | 271.7 | 航空航天 | 38.6 |
|
| 29 |
+
| 旅游地理 | 64.0 | 采矿 | 8.9 |
|
| 30 |
+
| 法律司法 | 238.5 | 金融经济 | 145.8 |
|
| 31 |
+
| 数学-统计学 | 156.7 | 文学情感 | 105.5 |
|
| 32 |
+
| 其他信息服务_信息安全 | 1.8 | 交通运输 | 40.5 |
|
| 33 |
+
| 消防安全_食品安全 | 4.3 | 科技_科学研究 | 101.6 |
|
| 34 |
+
| 汽车 | 39.3 | 水利_海洋 | 20.2 |
|
| 35 |
+
| 住宿-餐饮-酒店 | 29.6 | 计算机-通信 | 157.8 |
|
| 36 |
+
| 影视娱乐 | 209.4 | 学科教育 | 340.9 |
|
| 37 |
+
| 房地产-建筑 | 105.2 | 人工智能-机器学习 | 7.7 |
|
| 38 |
+
| 电力能源 | 68.7 | 时政-政务-行政 | 271.5 |
|
| 39 |
+
| 农林牧渔 | 111.9 | 体育 | 262.5 |
|
| 40 |
+
| 游戏 | 37.6 | 其他制造 | 47.2 |
|
| 41 |
+
| 其他 | 188.6 | | |
|
| 42 |
+
| 合计(GB) | 3276G | | |
|
| 43 |
+
|
| 44 |
+
汇总数据集中的行业数据分布图如下
|
| 45 |
+
|
| 46 |
+

|
| 47 |
+
|
| 48 |
+
从分布图上可以看到,对于学科教育,体育,时事政治,法律,医学健康,影视娱乐这几个行业占据了整体数据的大部分,这几个行业的数据广泛存在于互联网和教材当中,在全部的语料中占比较高是符合预期的;值得一提的是,由于我们定向补充了数学的数据,可以看到数学的数据占比同样较高,这与数学互联网语料的数据占比是不一致的。
|
| 49 |
+
|
| 50 |
+
### 数据质量分层
|
| 51 |
+
|
| 52 |
+
我们按照数据质量对整个数据进行过滤处理,去除掉了极端低质量数据,并将可用数据分成Low,Middle,Hight独立的三组,方便模型训练时进行数据配比组合,不同质量的数据分布如下所示,可以看到中文和英文的数据质量分布趋势基本一致,middle数据最多,其次是middle数据,low数据最少;另外,可以观察到,英文的hight数据相比中文有更高的占比(斜率更大),这也是符合当前不同语种分布的趋势的。
|
| 53 |
+
|
| 54 |
+

|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
### 行业类目划分
|
| 63 |
+
|
| 64 |
+
为了提升数据集中行业划分对实际行业的覆盖,并对齐国家标准中定义的行业目录,我们参考国家统计局制定的国民经济行业分类体系和世界知识体系,进行类目的合并和整合,设计了覆盖中英文的最终的31个行业类目。类目表名称如下所示
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
{
|
| 68 |
+
"数学_统计": {"zh": "数学与统计", "en": "Math & Statistics"},
|
| 69 |
+
"体育": {"zh": "体育", "en": "Sports"},
|
| 70 |
+
"农林牧渔": {"zh": "农业与渔业", "en": "Agriculture & Fisheries"},
|
| 71 |
+
"房地产_建筑": {"zh": "房地产与建筑", "en": "Real Estate & Construction"},
|
| 72 |
+
"时政_政务_行��": {"zh": "政治与行政", "en": "Politics & Administration"},
|
| 73 |
+
"消防安全_食品安全": {"zh": "安全管理", "en": "Safety Management"},
|
| 74 |
+
"石油化工": {"zh": "石油化工", "en": "Petrochemicals"},
|
| 75 |
+
"计算机_通信": {"zh": "计算机与通信", "en": "Computing & Telecommunications"},
|
| 76 |
+
"交通运输": {"zh": "交通运输", "en": "Transportation"},
|
| 77 |
+
"其他": {"zh": "其他", "en": "Others"},
|
| 78 |
+
"医学_健康_心理_中医": {"zh": "健康与医学", "en": "Health & Medicine"},
|
| 79 |
+
"文学_情感": {"zh": "文学与情感", "en": "Literature & Emotions"},
|
| 80 |
+
"水利_海洋": {"zh": "水利与海洋", "en": "Water Resources & Marine"},
|
| 81 |
+
"游戏": {"zh": "游戏", "en": "Gaming"},
|
| 82 |
+
"科技_科学研究": {"zh": "科技与研究", "en": "Technology & Research"},
|
| 83 |
+
"采矿": {"zh": "采矿", "en": "Mining"},
|
| 84 |
+
"人工智能_机器学习": {"zh": "人工智能", "en": "Artificial Intelligence"},
|
| 85 |
+
"其他信息服务_信息安全": {"zh": "信息服务", "en": "Information Services"},
|
| 86 |
+
"学科教育_教育": {"zh": "学科教育", "en": "Subject Education"},
|
| 87 |
+
"新闻传媒": {"zh": "新闻传媒", "en": "Media & Journalism"},
|
| 88 |
+
"汽车": {"zh": "汽车", "en": "Automobiles"},
|
| 89 |
+
"生物医药": {"zh": "生物医药", "en": "Biopharmaceuticals"},
|
| 90 |
+
"航空航天": {"zh": "航空航天", "en": "Aerospace"},
|
| 91 |
+
"金融_经济": {"zh": "金融与经济", "en": "Finance & Economics"},
|
| 92 |
+
"住宿_餐饮_酒店": {"zh": "住宿与餐饮", "en": "Hospitality & Catering"},
|
| 93 |
+
"其他制造": {"zh": "制造业", "en": "Manufacturing"},
|
| 94 |
+
"影视_娱乐": {"zh": "影视与娱乐", "en": "Film & Entertainment"},
|
| 95 |
+
"旅游_地理": {"zh": "旅游与地理", "en": "Travel & Geography"},
|
| 96 |
+
"法律_司法": {"zh": "法律与司法", "en": "Law & Justice"},
|
| 97 |
+
"电力能源": {"zh": "电力与能源", "en": "Power & Energy"},
|
| 98 |
+
"计算机编程_代码": {"zh": "编程", "en": "Programming"},
|
| 99 |
+
}
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
- 行业分类模型的数据构造
|
| 103 |
+
|
| 104 |
+
- 数据构建
|
| 105 |
+
|
| 106 |
+
数据来源:预训练预训练语料抽样和开源文本分类数据,其中预训练语料占比90%,通过数据采样,保证中英文数据占比为1:1
|
| 107 |
+
|
| 108 |
+
标签构造:使用LLM模型对数据进行多次分类判定,筛选多次判定一致的数据作为训练数据
|
| 109 |
+
|
| 110 |
+
数据规模:36K
|
| 111 |
+
|
| 112 |
+
数据构造的整体流程如下:
|
| 113 |
+
|
| 114 |
+

|
| 115 |
+
|
| 116 |
+
- 模型训练:
|
| 117 |
+
|
| 118 |
+
参数更新:在预训练的bert模型上添加分类头进行文本分类模型训练
|
| 119 |
+
|
| 120 |
+
模型选型:考虑的模型性能和推理效率,我们选用了0.5b规模的模型,通过对比实验最终最终选择了bge-m3并全参数训练的方式,作为我们的基座模型
|
| 121 |
+
|
| 122 |
+
训练超参:全参数训练,max_length = 2048,lr=1e-5,batch_size=64,,验证集评估acc:86%
|
| 123 |
+
|
| 124 |
+

|
| 125 |
+
|
| 126 |
+
### 数据质量评估
|
| 127 |
+
|
| 128 |
+
- 为什么要筛选低质量的数据
|
| 129 |
+
|
| 130 |
+
下面是从数据中抽取的低质量数据,可以看到这种数据对模型的学习是有害无益的
|
| 131 |
+
|
| 132 |
+
```
|
| 133 |
+
{"text": "\\_\\__\n\nTranslated from *Chinese Journal of Biochemistry and Molecular Biology*, 2007, 23(2): 154--159 \\[译自:中国生物化学与分子生物学报\\]\n"}
|
| 134 |
+
|
| 135 |
+
{"text": "#ifndef _IMGBMP_H_\n#define _IMGBMP_H_\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\nconst uint8_t bmp[]={\n\\/\\/-- 调入了一幅图像:D:\\我的文档\\My Pictures\\12864-555.bmp --*\\/\n\\/\\/-- 宽度x高度=128x64 --\n0x00,0x06,0x0A,0xFE,0x0A,0xC6,0x00,0xE0,0x00,0xF0,0x00,0xF8,0x00,0x00,0x00,0x00,\n0x00,0x00,0xFE,0x7D,0xBB,0xC7,0xEF,0xEF,0xEF,0xEF,0xEF,0xEF,0xEF,0xC7,0xBB,0x7D,\n0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x08,\n0x0C,0xFE,0xFE,0x0C,0x08,0x20,0x60,0xFE,0xFE,0x60,0x20,0x00,0x00,0x00,0x78,0x48,\n0xFE,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xFE,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFE,0xFF,\n0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,0xFF,0x00,0x00,0xFE,0xFF,0x03,\n0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,0xFE,0x00,0x00,0x00,0x00,0xC0,0xC0,\n0xC0,0x00,0x00,0x00,0x00,0xFE,0xFF,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,\n0xFF,0xFE,0x00,0x00,0xFE,0xFF,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,\n0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,0x00,0x00,0xFF,0xFF,0x0C,\n0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0xFF,0xFF,0x00,0x00,0x00,0x00,0xE1,0xE1,\n0xE1,0x00,0x00,0x00,0x00,0xFF,0xFF,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0xFF,0xFF,0x00,0x00,0xFF,0xFF,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0xFF,\n0xFF,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x0F,0x1F,\n0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,0x0F,0x00,0x00,0x0F,0x1F,0x18,\n0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,0x0F,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x0F,0x1F,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,\n0x1F,0x0F,0x00,0x00,0x0F,0x1F,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,\n0x0F,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0xE2,0x92,0x8A,0x86,0x00,0x00,0x7C,0x82,0x82,0x82,0x7C,\n0x00,0xFE,0x00,0x82,0x92,0xAA,0xC6,0x00,0x00,0xC0,0xC0,0x00,0x7C,0x82,0x82,0x82,\n0x7C,0x00,0x00,0x02,0x02,0x02,0xFE,0x00,0x00,0xC0,0xC0,0x00,0x7C,0x82,0x82,0x82,\n0x7C,0x00,0x00,0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x24,0xA4,0x2E,0x24,0xE4,0x24,0x2E,0xA4,0x24,0x00,0x00,0x00,0xF8,0x4A,0x4C,\n0x48,0xF8,0x48,0x4C,0x4A,0xF8,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xC0,0x20,0x10,0x10,\n0x10,0x10,0x20,0xC0,0x00,0x00,0xC0,0x20,0x10,0x10,0x10,0x10,0x20,0xC0,0x00,0x00,\n0x00,0x12,0x0A,0x07,0x02,0x7F,0x02,0x07,0x0A,0x12,0x00,0x00,0x00,0x0B,0x0A,0x0A,\n0x0A,0x7F,0x0A,0x0A,0x0A,0x0B,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x20,0x40,0x40,\n0x40,0x50,0x20,0x5F,0x80,0x00,0x1F,0x20,0x40,0x40,0x40,0x50,0x20,0x5F,0x80,0x00,\n}; \n\n\n#ifdef __cplusplus\n}\n#endif\n\n#endif \\/\\/ _IMGBMP_H_ _SSD1306_16BIT_H_\n"}
|
| 136 |
+
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
- 数据构建
|
| 140 |
+
|
| 141 |
+
数据来源:随机采样预训练语料
|
| 142 |
+
|
| 143 |
+
标签构建:设计数据打分细则,借助LLM模型进行多轮打分,筛选多轮打分分差小于2的数据
|
| 144 |
+
|
| 145 |
+
数据规模:20k打分数据,中英文比例1:1
|
| 146 |
+
|
| 147 |
+
数据打分prompt
|
| 148 |
+
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
quality_prompt = """Below is an extract from a web page. Evaluate whether the page has a high natural language value and could be useful in an naturanl language task to train a good language model using the additive 5-point scoring system described below. Points are accumulated based on the satisfaction of each criterion:
|
| 152 |
+
|
| 153 |
+
- Zero score if the content contains only some meaningless content or private content, such as some random code, http url or copyright information, personally identifiable information, binary encoding of images.
|
| 154 |
+
- Add 1 point if the extract provides some basic information, even if it includes some useless contents like advertisements and promotional material.
|
| 155 |
+
- Add another point if the extract is written in good style, semantically fluent, and free of repetitive content and grammatical errors.
|
| 156 |
+
- Award a third point tf the extract has relatively complete semantic content, and is written in a good and fluent style, the entire content expresses something related to the same topic, rather than a patchwork of several unrelated items.
|
| 157 |
+
- A fourth point is awarded if the extract has obvious educational or literary value, or provides a meaningful point or content, contributes to the learning of the topic, and is written in a clear and consistent style. It may be similar to a chapter in a textbook or tutorial, providing a lot of educational content, including exercises and solutions, with little to no superfluous information. The content is coherent and focused, which is valuable for structured learning.
|
| 158 |
+
- A fifth point is awarded if the extract has outstanding educational value or is of very high information density, provides very high value and meaningful content, does not contain useless information, and is well suited for teaching or knowledge transfer. It contains detailed reasoning, has an easy-to-follow writing style, and can provide deep and thorough insights.
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
The extract:
|
| 162 |
+
<{EXAMPLE}>.
|
| 163 |
+
|
| 164 |
+
After examining the extract:
|
| 165 |
+
- Briefly justify your total score, up to 50 words.
|
| 166 |
+
- Conclude with the score using the format: "Quality score: <total points>"
|
| 167 |
+
...
|
| 168 |
+
"""
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
- 模型训练
|
| 172 |
+
|
| 173 |
+
模型选型:与分类模型类似,我们同样使用的是0.5b规模的模型,并对比试验了beg-m3和qwen-0.5b,最终实验显示bge-m3综合表现最优
|
| 174 |
+
|
| 175 |
+
模型超参:基座bge-m3,全参数训练,lr=1e-5,batch_size=64, max_length = 2048
|
| 176 |
+
|
| 177 |
+
模型评估:在验证集上模型与GPT4对样本质量判定一致率为90%
|
| 178 |
+
|
| 179 |
+

|
| 180 |
+
|
| 181 |
+
- 高质量数据带来的训练收益
|
| 182 |
+
|
| 183 |
+
我们为了验证高质量的数据是否能带来更高效的训练效率,在同一基座模型下,使用从未筛选之前的50b数据中抽取出高质量数据,可以认为两个数据的分布大体是一致的,进行自回归训练.
|
| 184 |
+
|
| 185 |
+
曲线中可以看到,经过高质量数据训练的模型14B的tokens可以达到普通数据50B的模型表现,高质量的数据可以极大的提升训练效率。
|
| 186 |
+
|
| 187 |
+

|
| 188 |
+
|
| 189 |
+
此外,高质量的数据可以作为预训练的退火阶段的数据加入到模型中,进一步拉升模型效果,为了验证这个猜测,我们在训练行业模型时候,在模型的退火阶段加入了筛选之后高质量数据和部分指令数据转成的预训练数据,可以看到极大提高了模型的表现。
|
| 190 |
+
|
| 191 |
+

|
| 192 |
+
|
| 193 |
+
最后,高质量的预训练语料中包含着丰富的高价值知识性内容,可以从中提取出指令数据进一步提升指令数据的丰富度和知识性,这也催发了[Industry-Instruction](https://huggingface.co/datasets/BAAI/Industry-Instruction)项目的诞生,我们会在那里进行详细的说明。
|
img/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
img/classify.png
ADDED

|
Git LFS Details
|
img/classify_exp.png
ADDED

|
Git LFS Details
|
img/cpt_two_stage.png
ADDED

|
Git LFS Details
|
img/data_pipelien.jpg
ADDED
|
Git LFS Details
|
img/data_pipeline-en.png
ADDED

|
Git LFS Details
|
img/data_ratio.png
ADDED
|
Git LFS Details
|
img/disk-gb.png
ADDED
|
Git LFS Details
|
img/quality-exp.png
ADDED

|
Git LFS Details
|
img/quality_ratio.png
ADDED
|
Git LFS Details
|
img/quality_train.png
ADDED

|
Git LFS Details
|