Datasets:


行业模型在推动企业智能化转型和创新发展中发挥着至关重要的作用。高质量的行业数据是提升大模型性能和实现行业应用落地的关键。然而,目前用于行业模型训练的数据集普遍存在数据量少、质量低、专业性不足等问题。
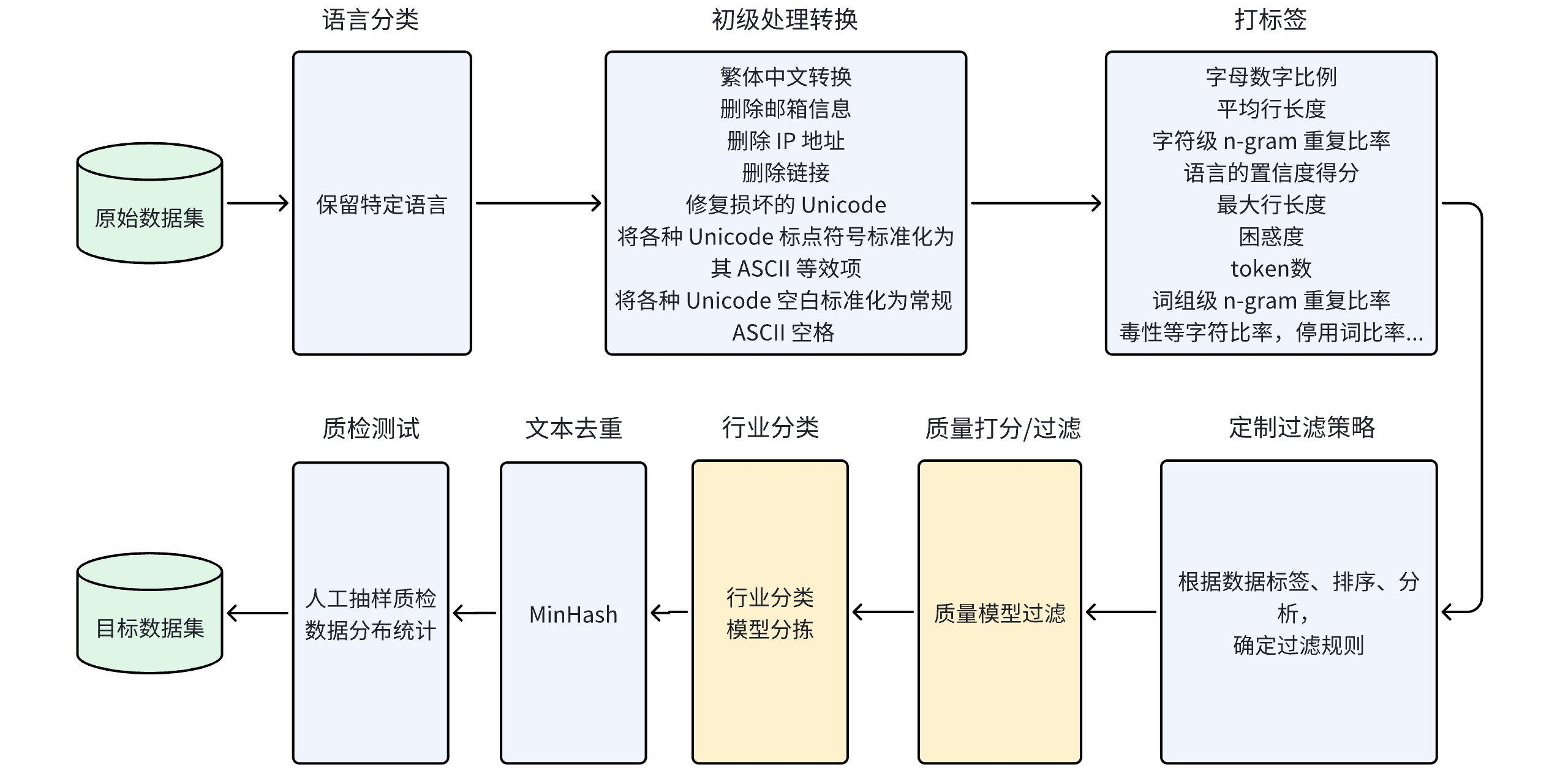
为了解决这些问题,我们构建并应用了22个行业数据处理算子,从WuDaoCorpora、BAAI-CCI、redpajama、SkyPile-150B等超过100TB的开源数据集中,清洗过滤出3.4TB的高质量多行业分类中英文语言预训练数据集,其中中文数据占1TB,英文数据占2.4TB。为了方便用户使用,我们为中文数据标注了字母数字比例、平均行长度、语言的置信度得分、最大行长度、困惑度等12种标签。
此外,为了验证数据集的性能,我们对医疗行业示范模型进行了继续预训练、SFT和DPO训练。结果显示,模型的客观性能提升了20%,主观胜率达到了82%。
行业分类:医疗、教育、文学、金融、旅游、法律、体育、汽车、新闻等18类行业数据 基于规则的过滤:繁体中文转换、删除邮箱信息、删除 IP 地址、删除链接、修复损坏的 Unicode等 中文数据标签:字母数字比例、平均行长度、语言的置信度得分、最大行长度、困惑度、毒性等字符比率等 基于模型的过滤:行业分类语言模型,分类准确率达到80% 数据去重:minhash文档级去重 数据大小:中文1TB, 英文2.4TB
行业分类数据大小
| 行业类别 | 数据大小(GB) | 行业类别 | 数据大小(GB) |
|---|---|---|---|
| 编程 | 4.1 | 时政 | 326.4 |
| 法律 | 274.6 | 数学 | 5.9 |
| 教育 | 458.1 | 体育 | 442 |
| 金融 | 197.8 | 文学 | 179.3 |
| 计算机 | 46.9 | 新闻 | 564.1 |
| 科技 | 333.6 | 影视 | 162.1 |
| 旅游 | 82.5 | 医学 | 189.4 |
| 农业 | 41.6 | 汽车 | 40.8 |
| 情感 | 31.7 | 人工智能 | 5.6 |
| 合计(GB) | 3386.5 |
为了方便用户下载使用,我们将大的数据集拆分为18个行业的子数据集,当前为影视行业子数据集
数据处理流程图