
ChineseWebText: Large-Scale High-quality Chinese Web Text Extracted with Effective Evaluation Model
This directory contains the ChineseWebText dataset, and the EvalWeb tool-chain to process CommonCrawl Data. Our EvalWeb tool is publicly available on github https://github.com/CASIA-LM/ChineseWebText.
ChineseWebText
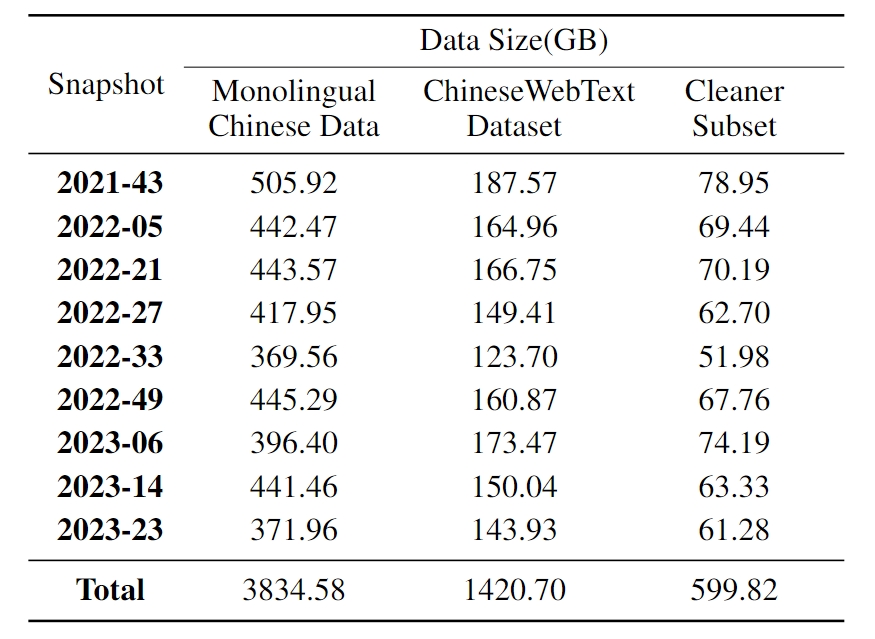
We release the latest and largest Chinese dataset ChineseWebText, which consists of 1.42 TB data and each text is assigned a quality score, facilitating LLM researchers to select data according to a new quality threshold. We also release a much cleaner subset of 600 GB Chinese texts with quality exceeding 90% .
Data Example
{ "title": "潍坊银行2021年上半年净利润同比增长29.57% 不良率降至1.10%_财经_中国网", "score": 0.95, "text": "潍坊银行2021年上半年净利润同比增长29.57% 不良率降至1.10%\n中国网财经8月24日讯 潍坊银行昨日披露2021年二季度信息报告显示,截至2021 年6月末,潍坊银行资产总额1920.44亿元,较上年末增长9.34%;负债总额1789.16亿元,较上年末增长10.54%。2021年上半年,潍坊银行实现净利润 6.09亿元,同比增长29.57%。\n资产质量方面,截至2021年6月末,潍坊银行不良贷款率1.10%,较上年末下降0.13个百分点。\n资本金方面,截至 2021年6月末,潍坊银行资本充足率、核心一级资本充足率、一级资本充足率分别为11.66%、7.89%、10.13%,分别较上年末下降1.89、0.89、1.15 个百分点。", "url": "http://finance.china.com.cn/news/special/2021bnb/20210824/5638343.shtml", "source\_domain": "finance.china.com.cn" }- "title": 【string】The title of the data text.
- "score": 【float】Quality score generated by the quality evaluation model.
- "text": 【string】Text content of data sample.
- "url": 【string】External URL, points to the original web address of the text.
- "source_domain": 【string】The domain name of the source website.