
The dataset viewer is not available for this subset.
Need help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
MileBench
Introduction
We introduce MileBench, a pioneering benchmark designed to test the MultImodal Long-contExt capabilities of MLLMs. This benchmark comprises not only multimodal long contexts, but also multiple tasks requiring both comprehension and generation. We establish two distinct evaluation sets, diagnostic and realistic, to systematically assess MLLMs’ long-context adaptation capacity and their ability to completetasks in long-context scenarios
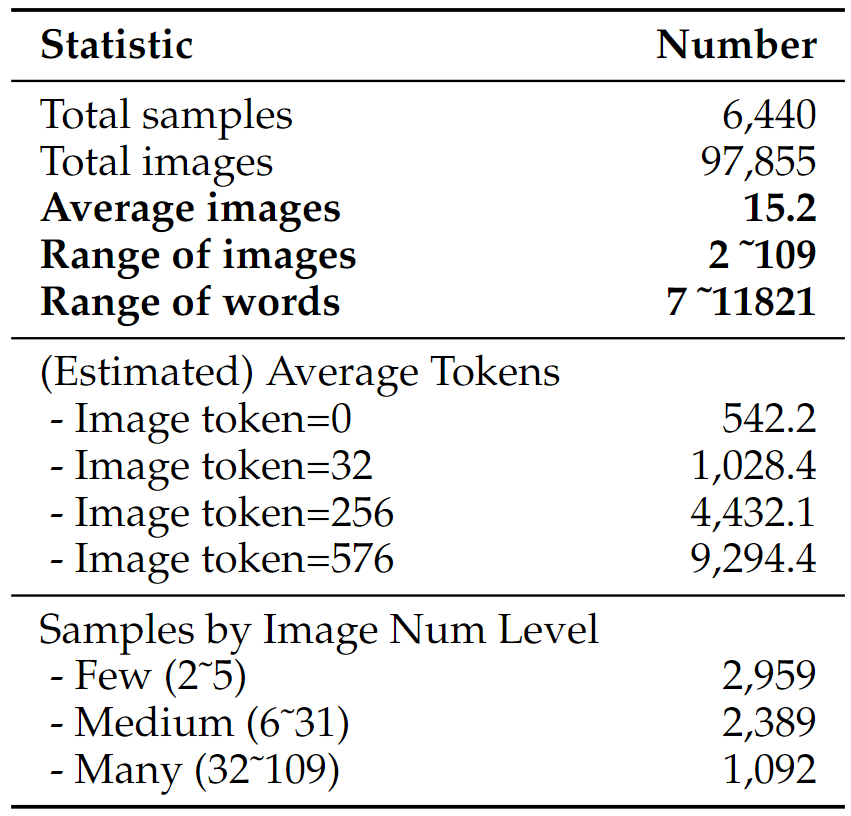
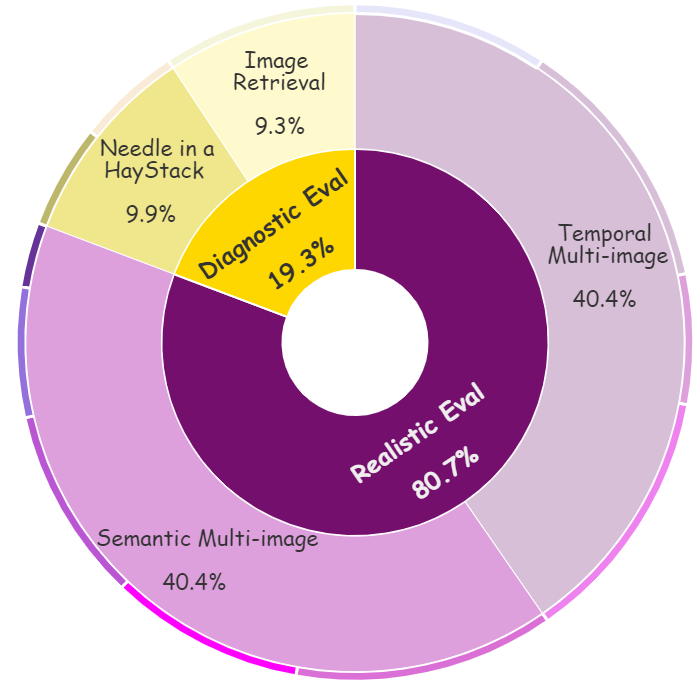
To construct our evaluation sets, we gather 6,440 multimodal long-context samples from 21 pre-existing or self-constructed datasets, with an average of 15.2 images and 422.3 words each, as depicted in the figure, and we categorize them into their respective subsets.
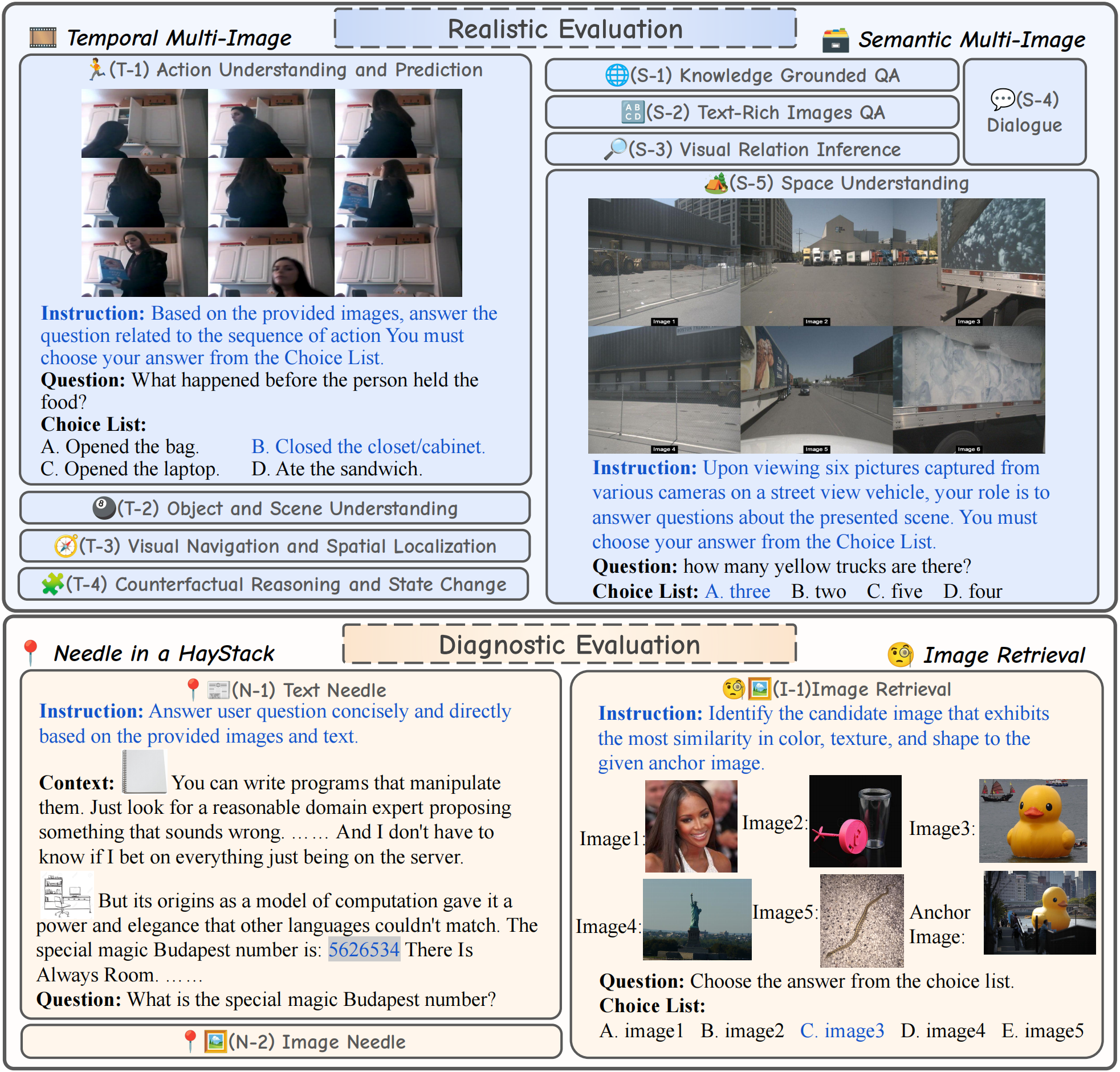
How to use?
Please download MileBench_part*.tar.gz and unzip them using the following command.
for file in MileBench_part*.tar.gz
do
tar -xzvf "$file"
done
Then please refer to Code for MileBench to evaluate.
Links
- Homepage: MileBench Homepage
- Repository: MileBench GitHub
- Paper: Arxiv
- Point of Contact: Dingjie Song
Citation
If you find this project useful in your research, please consider citing:
@article{song2024milebench,
title={MileBench: Benchmarking MLLMs in Long Context},
author={Song, Dingjie and Chen, Shunian and Chen, Guiming Hardy and Yu, Fei and Wan, Xiang and Wang, Benyou},
journal={arXiv preprint arXiv:2404.18532},
year={2024}
}
- Downloads last month
- 1,069