Datasets:

unit_id
string | flores_id
int32 | item_id
string | subject_id
string | lang_id
string | doc_id
int32 | task_type
string | translation_type
string | src_len_chr
int32 | mt_len_chr
float32 | tgt_len_chr
int32 | src_len_wrd
int32 | mt_len_wrd
float32 | tgt_len_wrd
int32 | edit_time
float32 | k_total
int32 | k_letter
int32 | k_digit
int32 | k_white
int32 | k_symbol
int32 | k_nav
int32 | k_erase
int32 | k_copy
int32 | k_cut
int32 | k_paste
int32 | k_do
int32 | n_pause_geq_300
int32 | len_pause_geq_300
int32 | n_pause_geq_1000
int32 | len_pause_geq_1000
int32 | event_time
int32 | num_annotations
int32 | last_modification_time
int32 | n_insert
float32 | n_delete
float32 | n_substitute
float32 | n_shift
float32 | tot_shifted_words
float32 | tot_edits
float32 | hter
float32 | cer
float32 | bleu
float32 | chrf
float32 | time_s
float32 | time_m
float32 | time_h
float32 | time_per_char
float32 | time_per_word
float32 | key_per_char
float32 | words_per_hour
float32 | words_per_minute
float32 | per_subject_visit_order
int32 | src_text
string | mt_text
string | tgt_text
string | aligned_edit
string | src_tokens
sequence | src_annotations
sequence | mt_tokens
sequence | mt_annotations
sequence | tgt_tokens
sequence | tgt_annotations
sequence | src_wmt22_qe
sequence | mt_wmt22_qe
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
flores101-main-tur-1-ht-1 | 205 | flores101-main-11 | tur_t1 | tur | 1 | ht | ht | 155 | null | 147 | 25 | null | 18 | 100.306 | 260 | 181 | 4 | 26 | 5 | 20 | 24 | 0 | 0 | 0 | 0 | 34 | 66,281 | 10 | 52,888 | 100,306 | 1 | 1,643,314,612 | null | null | null | null | null | null | null | null | null | null | 100.306 | 1.6718 | 0.0279 | 0.6471 | 4.0122 | 1.6774 | 897.2544 | 14.9542 | 1 | UN peacekeepers, whom arrived in Haiti after the 2010 earthquake, are being blamed for the spread of the disease which started near the troop's encampment. | nan | 2010 depreminden sonra Haiti'ye giden BM arabulucularının yerleşim yerinin yakınında başlayıp yayılan hastalığın, bu ekibin suçu olduğu söyleniyor. | nan | [
"UN",
"peacekeepers",
",",
"whom",
"arrived",
"in",
"Haiti",
"after",
"the",
"2010",
"earthquake",
",",
"are",
"being",
"blamed",
"for",
"the",
"spread",
"of",
"the",
"disease",
"which",
"started",
"near",
"the",
"troop",
"'s",
"encampment",
"."
] | {
"lemma": [
"UN",
"peacekeeper",
",",
"whom",
"arrive",
"in",
"Haiti",
"after",
"the",
"2010",
"earthquake",
",",
"be",
"be",
"blame",
"for",
"the",
"spread",
"of",
"the",
"disease",
"which",
"start",
"near",
"the",
"troop",
"'s",
"encampment",
"."
],
"upos": [
"PROPN",
"NOUN",
"PUNCT",
"PRON",
"VERB",
"ADP",
"PROPN",
"ADP",
"DET",
"NUM",
"NOUN",
"PUNCT",
"AUX",
"AUX",
"VERB",
"ADP",
"DET",
"NOUN",
"ADP",
"DET",
"NOUN",
"PRON",
"VERB",
"ADP",
"DET",
"NOUN",
"PART",
"NOUN",
"PUNCT"
],
"feats": [
"Number=Sing",
"Number=Plur",
"",
"PronType=Rel",
"Mood=Ind|Number=Plur|Person=3|Tense=Past|VerbForm=Fin",
"",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"NumForm=Digit|NumType=Card",
"Number=Sing",
"",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"VerbForm=Ger",
"Tense=Past|VerbForm=Part|Voice=Pass",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"PronType=Rel",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Number=Sing",
""
],
"head": [
"2",
"15",
"5",
"5",
"2",
"7",
"5",
"11",
"11",
"11",
"5",
"2",
"15",
"15",
"0",
"18",
"18",
"15",
"21",
"21",
"18",
"23",
"21",
"28",
"26",
"28",
"26",
"23",
"15"
],
"deprel": [
"compound",
"nsubj:pass",
"punct",
"nsubj",
"acl:relcl",
"case",
"obl",
"case",
"det",
"compound",
"obl",
"punct",
"aux",
"aux:pass",
"root",
"case",
"det",
"obl",
"case",
"det",
"nmod",
"nsubj",
"acl:relcl",
"case",
"det",
"nmod:poss",
"case",
"obl",
"punct"
],
"start_char": [
0,
3,
15,
17,
22,
30,
33,
39,
45,
49,
54,
64,
66,
70,
76,
83,
87,
91,
98,
101,
105,
113,
119,
127,
132,
136,
141,
144,
154
],
"end_char": [
2,
15,
16,
21,
29,
32,
38,
44,
48,
53,
64,
65,
69,
75,
82,
86,
90,
97,
100,
104,
112,
118,
126,
131,
135,
141,
143,
154,
155
],
"ner": [
"S-ORG",
"O",
"O",
"O",
"O",
"O",
"S-GPE",
"O",
"O",
"S-DATE",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"2010",
"depreminden",
"sonra",
"Haiti'ye",
"giden",
"BM",
"arabulucularının",
"yerleşim",
"yerinin",
"yakınında",
"başlayıp",
"yayılan",
"hastalığın",
",",
"bu",
"ekibin",
"suçu",
"olduğu",
"söyleniyor",
"."
] | {
"lemma": [
"2010",
"deprem",
"sonra",
"Haiti",
"git",
"Bm",
"arabulucu",
"yerleşim",
"yer",
"yakın",
"başla",
"yay",
"hastalık",
",",
"bu",
"ekibin",
"suç",
"ol",
"söyle",
"."
],
"upos": [
"NUM",
"NOUN",
"ADP",
"PROPN",
"VERB",
"NOUN",
"NOUN",
"NOUN",
"NOUN",
"ADJ",
"VERB",
"VERB",
"NOUN",
"PUNCT",
"DET",
"NOUN",
"NOUN",
"VERB",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|NumType=Card|Number=Sing|Person=3",
"Case=Abl|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Conv",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part|Voice=Pass",
"Case=Gen|Number=Sing|Person=3",
"",
"",
"Case=Gen|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"Aspect=Prog|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Polite=Infm|Tense=Pres|Voice=Pass",
""
],
"head": [
"5",
"1",
"2",
"5",
"7",
"7",
"10",
"9",
"10",
"11",
"19",
"13",
"18",
"13",
"16",
"17",
"18",
"19",
"0",
"19"
],
"deprel": [
"nummod",
"flat",
"case",
"obl",
"acl",
"nmod:poss",
"nmod:poss",
"nmod:poss",
"nmod:poss",
"amod",
"nmod",
"acl",
"nmod:poss",
"punct",
"det",
"nmod:poss",
"obj",
"nsubj",
"root",
"punct"
],
"start_char": [
0,
5,
17,
23,
32,
38,
41,
58,
67,
75,
85,
94,
102,
112,
114,
117,
124,
129,
136,
146
],
"end_char": [
4,
16,
22,
31,
37,
40,
57,
66,
74,
84,
93,
101,
112,
113,
116,
123,
128,
135,
146,
147
],
"ner": [
"S-TIME",
"O",
"O",
"S-LOCATION",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-1-ht-2 | 206 | flores101-main-12 | tur_t1 | tur | 1 | ht | ht | 165 | null | 175 | 27 | null | 23 | 560.332 | 286 | 200 | 0 | 28 | 5 | 26 | 26 | 0 | 1 | 0 | 0 | 36 | 530,977 | 16 | 521,146 | 560,332 | 1 | 1,643,314,612 | null | null | null | null | null | null | null | null | null | null | 560.332 | 9.3389 | 0.1556 | 3.396 | 20.753 | 1.7333 | 173.4686 | 2.8911 | 2 | According to the lawsuit, waste from the UN camp was not properly sanitized, causing bacteria to enter the tributary of the Artibonite River, one of Haiti's largest. | nan | Davaya göre, BM kampının doğru biçimde sterilize edilmeyen atıkları, Haiti'nin en büyük nehirlerinden biri olan Artibonite Nehri'nin bir koluna bakteri karışmasına neden oldu. | nan | [
"According",
"to",
"the",
"lawsuit",
",",
"waste",
"from",
"the",
"UN",
"camp",
"was",
"not",
"properly",
"sanitized",
",",
"causing",
"bacteria",
"to",
"enter",
"the",
"tributary",
"of",
"the",
"Artibonite",
"River",
",",
"one",
"of",
"Haiti",
"'s",
"largest",
"."
] | {
"lemma": [
"accord",
"to",
"the",
"lawsuit",
",",
"waste",
"from",
"the",
"UN",
"camp",
"be",
"not",
"properly",
"sanitize",
",",
"cause",
"bacterium",
"to",
"enter",
"the",
"tributary",
"of",
"the",
"Artibonite",
"River",
",",
"one",
"of",
"Haiti",
"'s",
"large",
"."
],
"upos": [
"VERB",
"ADP",
"DET",
"NOUN",
"PUNCT",
"NOUN",
"ADP",
"DET",
"PROPN",
"NOUN",
"AUX",
"PART",
"ADV",
"VERB",
"PUNCT",
"VERB",
"NOUN",
"PART",
"VERB",
"DET",
"NOUN",
"ADP",
"DET",
"PROPN",
"PROPN",
"PUNCT",
"NUM",
"ADP",
"PROPN",
"PART",
"ADJ",
"PUNCT"
],
"feats": [
"ExtPos=ADP|VerbForm=Ger",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"",
"",
"Tense=Past|VerbForm=Part|Voice=Pass",
"",
"VerbForm=Ger",
"Number=Sing",
"",
"VerbForm=Inf",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"Number=Sing",
"",
"NumForm=Word|NumType=Card",
"",
"Number=Sing",
"",
"Degree=Sup",
""
],
"head": [
"4",
"1",
"4",
"14",
"14",
"14",
"10",
"10",
"10",
"6",
"14",
"14",
"14",
"0",
"16",
"14",
"16",
"19",
"16",
"21",
"19",
"25",
"25",
"25",
"21",
"27",
"25",
"31",
"31",
"29",
"27",
"14"
],
"deprel": [
"case",
"fixed",
"det",
"obl",
"punct",
"nsubj:pass",
"case",
"det",
"compound",
"nmod",
"aux:pass",
"advmod",
"advmod",
"root",
"punct",
"advcl",
"obj",
"mark",
"xcomp",
"det",
"obj",
"case",
"det",
"compound",
"nmod",
"punct",
"appos",
"case",
"nmod:poss",
"case",
"nmod",
"punct"
],
"start_char": [
0,
10,
13,
17,
24,
26,
32,
37,
41,
44,
49,
53,
57,
66,
75,
77,
85,
94,
97,
103,
107,
117,
120,
124,
135,
140,
142,
146,
149,
154,
157,
164
],
"end_char": [
9,
12,
16,
24,
25,
31,
36,
40,
43,
48,
52,
56,
65,
75,
76,
84,
93,
96,
102,
106,
116,
119,
123,
134,
140,
141,
145,
148,
154,
156,
164,
165
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-ORG",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"B-LOC",
"I-LOC",
"E-LOC",
"O",
"S-CARDINAL",
"O",
"S-GPE",
"O",
"O",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Davaya",
"göre",
",",
"BM",
"kampının",
"doğru",
"biçimde",
"sterilize",
"edilmeyen",
"atıkları",
",",
"Haiti'nin",
"en",
"büyük",
"nehirlerinden",
"biri",
"olan",
"Artibonite",
"Nehri'nin",
"bir",
"koluna",
"bakteri",
"karışmasına",
"neden",
"oldu",
"."
] | {
"lemma": [
"dava",
"göre",
",",
"Bm",
"kamp",
"doğru",
"biçim",
"steriliz",
"et",
"atık",
",",
"Haiti",
"en",
"büyük",
"nehir",
"bir",
"ol",
"Artibonite",
"nehir",
"bir",
"kol",
"bakteri",
"karış",
"neden",
"ol",
"."
],
"upos": [
"NOUN",
"ADP",
"PUNCT",
"NOUN",
"NOUN",
"ADJ",
"NOUN",
"NOUN",
"VERB",
"NOUN",
"PUNCT",
"PROPN",
"ADV",
"ADJ",
"NOUN",
"NUM",
"VERB",
"PROPN",
"NOUN",
"NUM",
"NOUN",
"NOUN",
"VERB",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Dat|Number=Sing|Person=3",
"",
"",
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Loc|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Neg|Tense=Pres|VerbForm=Part|Voice=Pass",
"Case=Nom|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Gen|Number=Sing|Person=3",
"",
"",
"Case=Abl|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|NumType=Card|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"NumType=Card",
"Case=Dat|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Dat|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
""
],
"head": [
"24",
"1",
"1",
"5",
"8",
"7",
"8",
"10",
"8",
"24",
"10",
"15",
"14",
"15",
"16",
"17",
"19",
"19",
"21",
"21",
"23",
"23",
"24",
"0",
"24",
"24"
],
"deprel": [
"nmod",
"case",
"punct",
"nmod:poss",
"obj",
"amod",
"nmod",
"nmod",
"compound:lvc",
"nsubj",
"punct",
"nmod:poss",
"advmod",
"amod",
"obl",
"obj",
"acl",
"nmod:poss",
"nmod:poss",
"det",
"obl",
"obj",
"nmod",
"root",
"compound:lvc",
"punct"
],
"start_char": [
0,
7,
11,
13,
16,
25,
31,
39,
49,
59,
67,
69,
79,
82,
88,
102,
107,
112,
123,
133,
137,
144,
152,
164,
170,
174
],
"end_char": [
6,
11,
12,
15,
24,
30,
38,
48,
58,
67,
68,
78,
81,
87,
101,
106,
111,
122,
132,
136,
143,
151,
163,
169,
174,
175
],
"ner": [
"O",
"O",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-LOCATION",
"O",
"O",
"O",
"O",
"O",
"B-LOCATION",
"E-LOCATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-1-ht-3 | 207 | flores101-main-13 | tur_t1 | tur | 1 | ht | ht | 106 | null | 92 | 18 | null | 11 | 86.699 | 209 | 130 | 4 | 18 | 7 | 27 | 21 | 0 | 1 | 1 | 0 | 35 | 44,700 | 10 | 32,363 | 86,699 | 1 | 1,643,314,612 | null | null | null | null | null | null | null | null | null | null | 86.699 | 1.445 | 0.0241 | 0.8179 | 4.8166 | 1.9717 | 747.4135 | 12.4569 | 3 | Prior to the arrival of troops, Haiti had not encountered problems related to the disease since the 1800s. | nan | Bu ekip gelmeden önce Haiti'de 1800'lerden beri hastalıkla ilgili sorunla karşılaşılmamıştı. | nan | [
"Prior",
"to",
"the",
"arrival",
"of",
"troops",
",",
"Haiti",
"had",
"not",
"encountered",
"problems",
"related",
"to",
"the",
"disease",
"since",
"the",
"1800s",
"."
] | {
"lemma": [
"prior",
"to",
"the",
"arrival",
"of",
"troops",
",",
"Haiti",
"have",
"not",
"encounter",
"problem",
"related",
"to",
"the",
"disease",
"since",
"the",
"1800s",
"."
],
"upos": [
"ADJ",
"ADP",
"DET",
"NOUN",
"ADP",
"NOUN",
"PUNCT",
"PROPN",
"AUX",
"PART",
"VERB",
"NOUN",
"ADJ",
"ADP",
"DET",
"NOUN",
"ADP",
"DET",
"NOUN",
"PUNCT"
],
"feats": [
"Degree=Pos|ExtPos=ADP",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Number=Plur",
"",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"",
"Tense=Past|VerbForm=Part",
"Number=Plur",
"Degree=Pos",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"Number=Plur",
""
],
"head": [
"4",
"1",
"4",
"11",
"6",
"4",
"11",
"11",
"11",
"11",
"0",
"11",
"12",
"16",
"16",
"13",
"19",
"19",
"16",
"11"
],
"deprel": [
"case",
"fixed",
"det",
"obl",
"case",
"nmod",
"punct",
"nsubj",
"aux",
"advmod",
"root",
"obj",
"amod",
"case",
"det",
"obl",
"case",
"det",
"nmod",
"punct"
],
"start_char": [
0,
6,
9,
13,
21,
24,
30,
32,
38,
42,
46,
58,
67,
75,
78,
82,
90,
96,
100,
105
],
"end_char": [
5,
8,
12,
20,
23,
30,
31,
37,
41,
45,
57,
66,
74,
77,
81,
89,
95,
99,
105,
106
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-GPE",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"B-DATE",
"E-DATE",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Bu",
"ekip",
"gelmeden",
"önce",
"Haiti'de",
"1800'lerden",
"beri",
"hastalıkla",
"ilgili",
"sorunla",
"karşılaşılmamıştı",
"."
] | {
"lemma": [
"bu",
"ekip",
"gel",
"önce",
"Haiti",
"1800",
"beri",
"hastalık",
"ilgili",
"sorun",
"karşılaş",
"."
],
"upos": [
"DET",
"NOUN",
"VERB",
"ADP",
"PROPN",
"NOUN",
"ADP",
"NOUN",
"ADJ",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Neg|Tense=Pres|VerbForm=Conv",
"",
"Case=Loc|Number=Sing|Person=3",
"Case=Abl|Number=Sing|Person=3",
"",
"Case=Ins|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Ins|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Neg|Tense=Pqp|Voice=Pass",
""
],
"head": [
"2",
"3",
"11",
"3",
"11",
"11",
"6",
"9",
"10",
"11",
"0",
"11"
],
"deprel": [
"det",
"obj",
"nmod",
"case",
"obl",
"obl",
"case",
"nmod",
"amod",
"obl",
"root",
"punct"
],
"start_char": [
0,
3,
8,
17,
22,
31,
43,
48,
59,
66,
74,
91
],
"end_char": [
2,
7,
16,
21,
30,
42,
47,
58,
65,
73,
91,
92
],
"ner": [
"O",
"O",
"O",
"O",
"S-LOCATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-1-ht-4 | 208 | flores101-main-14 | tur_t1 | tur | 1 | ht | ht | 176 | null | 216 | 24 | null | 26 | 1,270.943 | 221 | 166 | 0 | 26 | 6 | 12 | 9 | 1 | 0 | 1 | 0 | 39 | 1,249,440 | 17 | 1,238,877 | 1,270,943 | 1 | 1,643,314,612 | null | null | null | null | null | null | null | null | null | null | 1,270.943 | 21.1824 | 0.353 | 7.2213 | 52.956 | 1.2557 | 67.981 | 1.133 | 4 | The Haitian Institute for Justice and Democracy has referenced independent studies that suggest the Nepalese UN peacekeeping battalion unknowingly brought the disease to Haiti. | nan | Haiti'deki Institute for Justice and Democracy (Adalet ve Demokrasi Enstitüsü), Nepalli BM arabuluculuk taburunun bu hastalığı Haiti'ye farkında olmadan getirdiğini öne süren bağımsız araştırmaları referans gösterdi. | nan | [
"The",
"Haitian",
"Institute",
"for",
"Justice",
"and",
"Democracy",
"has",
"referenced",
"independent",
"studies",
"that",
"suggest",
"the",
"Nepalese",
"UN",
"peacekeeping",
"battalion",
"unknowingly",
"brought",
"the",
"disease",
"to",
"Haiti",
"."
] | {
"lemma": [
"the",
"Haitian",
"Institute",
"for",
"Justice",
"and",
"Democracy",
"have",
"reference",
"independent",
"study",
"that",
"suggest",
"the",
"Nepalese",
"UN",
"peacekeeping",
"battalion",
"unknowingly",
"bring",
"the",
"disease",
"to",
"Haiti",
"."
],
"upos": [
"DET",
"ADJ",
"PROPN",
"ADP",
"PROPN",
"CCONJ",
"PROPN",
"AUX",
"VERB",
"ADJ",
"NOUN",
"PRON",
"VERB",
"DET",
"ADJ",
"PROPN",
"NOUN",
"NOUN",
"ADV",
"VERB",
"DET",
"NOUN",
"ADP",
"PROPN",
"PUNCT"
],
"feats": [
"Definite=Def|PronType=Art",
"Degree=Pos",
"Number=Sing",
"",
"Number=Sing",
"",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"Tense=Past|VerbForm=Part",
"Degree=Pos",
"Number=Plur",
"PronType=Rel",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"Definite=Def|PronType=Art",
"Degree=Pos",
"Number=Sing",
"Number=Sing",
"Number=Sing",
"",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Number=Sing",
""
],
"head": [
"3",
"3",
"9",
"5",
"3",
"7",
"5",
"9",
"0",
"11",
"9",
"13",
"11",
"18",
"18",
"18",
"18",
"20",
"20",
"13",
"22",
"20",
"24",
"20",
"9"
],
"deprel": [
"det",
"amod",
"nsubj",
"case",
"nmod",
"cc",
"conj",
"aux",
"root",
"amod",
"obj",
"nsubj",
"acl:relcl",
"det",
"amod",
"compound",
"compound",
"nsubj",
"advmod",
"ccomp",
"det",
"obj",
"case",
"obl",
"punct"
],
"start_char": [
0,
4,
12,
22,
26,
34,
38,
48,
52,
63,
75,
83,
88,
96,
100,
109,
112,
125,
135,
147,
155,
159,
167,
170,
175
],
"end_char": [
3,
11,
21,
25,
33,
37,
47,
51,
62,
74,
82,
87,
95,
99,
108,
111,
124,
134,
146,
154,
158,
166,
169,
175,
176
],
"ner": [
"B-ORG",
"I-ORG",
"I-ORG",
"I-ORG",
"I-ORG",
"I-ORG",
"E-ORG",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-NORP",
"S-ORG",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-GPE",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Haiti'deki",
"Institute",
"for",
"Justice",
"and",
"Democracy",
"(",
"Adalet",
"ve",
"Demokrasi",
"Enstitüsü",
")",
",",
"Nepalli",
"BM",
"arabuluculuk",
"taburunun",
"bu",
"hastalığı",
"Haiti'ye",
"farkında",
"olmadan",
"getirdiğini",
"öne",
"süren",
"bağımsız",
"araştırmaları",
"referans",
"gösterdi",
"."
] | {
"lemma": [
"Haiti+ki",
"Institute",
"for",
"Justice",
"and",
"Democracy",
"(",
"adalet",
"ve",
"demokrasi",
"enstitü",
")",
",",
"Nepalli",
"Bm",
"arabuluculuk",
"tabur",
"bu",
"hastalık",
"Haiti",
"fark",
"ol",
"getir",
"ön",
"sür",
"bağımsız",
"araştır",
"referans",
"göster",
"."
],
"upos": [
"PROPN+ADP",
"PROPN",
"NOUN",
"PROPN",
"NOUN",
"PROPN",
"PUNCT",
"NOUN",
"CCONJ",
"NOUN",
"NOUN",
"PUNCT",
"PUNCT",
"PROPN",
"NOUN",
"NOUN",
"NOUN",
"DET",
"NOUN",
"PROPN",
"NOUN",
"VERB",
"VERB",
"ADJ",
"VERB",
"ADJ",
"VERB",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Loc|Number=Sing|Person=3+",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Acc|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Mood=Ind|Polarity=Neg|Tense=Pres|VerbForm=Conv",
"Aspect=Perf|Case=Acc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"",
"Aspect=Perf|Case=Acc|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
""
],
"head": [
"3+1",
"29",
"3",
"3",
"3",
"3",
"9",
"3",
"9",
"9",
"9",
"9",
"15",
"18",
"15",
"18",
"22",
"20",
"22",
"22",
"24",
"22",
"25",
"28",
"25",
"28",
"29",
"0",
"29",
"29"
],
"deprel": [
"nmod+case",
"nsubj",
"flat",
"flat",
"flat",
"flat",
"punct",
"appos",
"cc",
"compound",
"compound",
"punct",
"punct",
"nmod:poss",
"flat",
"nmod:poss",
"nmod",
"det",
"obj",
"nmod",
"obl",
"compound:lvc",
"obj",
"amod",
"compound",
"amod",
"obj",
"root",
"compound",
"punct"
],
"start_char": [
0,
11,
21,
25,
33,
37,
47,
48,
55,
58,
68,
77,
78,
80,
88,
91,
104,
114,
117,
127,
136,
145,
153,
165,
169,
175,
184,
198,
207,
215
],
"end_char": [
10,
20,
24,
32,
36,
46,
48,
54,
57,
67,
77,
78,
79,
87,
90,
103,
113,
116,
126,
135,
144,
152,
164,
168,
174,
183,
197,
206,
215,
216
],
"ner": [
"S-LOCATION",
"B-ORGANIZATION",
"I-ORGANIZATION",
"I-ORGANIZATION",
"I-ORGANIZATION",
"E-ORGANIZATION",
"O",
"B-ORGANIZATION",
"I-ORGANIZATION",
"I-ORGANIZATION",
"E-ORGANIZATION",
"O",
"O",
"B-ORGANIZATION",
"E-ORGANIZATION",
"O",
"O",
"O",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-1-ht-5 | 209 | flores101-main-15 | tur_t1 | tur | 1 | ht | ht | 105 | null | 135 | 17 | null | 15 | 43.573 | 169 | 135 | 0 | 17 | 3 | 11 | 3 | 0 | 0 | 0 | 0 | 10 | 25,735 | 6 | 23,591 | 43,573 | 1 | 1,643,314,612 | null | null | null | null | null | null | null | null | null | null | 43.573 | 0.7262 | 0.0121 | 0.415 | 2.5631 | 1.6095 | 1,404.5395 | 23.409 | 5 | Danielle Lantagne, a UN expert on the disease, stated the outbreak was likely caused by the peacekeepers. | nan | BM'nin hastalık konusundaki uzmanlarından biri olan Danielle Lantagne, salgına büyük olasılıkla arabulucuların neden olduğunu belirtti. | nan | [
"Danielle",
"Lantagne",
",",
"a",
"UN",
"expert",
"on",
"the",
"disease",
",",
"stated",
"the",
"outbreak",
"was",
"likely",
"caused",
"by",
"the",
"peacekeepers",
"."
] | {
"lemma": [
"Danielle",
"Lantagne",
",",
"a",
"UN",
"expert",
"on",
"the",
"disease",
",",
"state",
"the",
"outbreak",
"be",
"likely",
"cause",
"by",
"the",
"peacekeeper",
"."
],
"upos": [
"PROPN",
"PROPN",
"PUNCT",
"DET",
"PROPN",
"NOUN",
"ADP",
"DET",
"NOUN",
"PUNCT",
"VERB",
"DET",
"NOUN",
"AUX",
"ADV",
"VERB",
"ADP",
"DET",
"NOUN",
"PUNCT"
],
"feats": [
"Number=Sing",
"Number=Sing",
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"Definite=Def|PronType=Art",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"",
"Tense=Past|VerbForm=Part|Voice=Pass",
"",
"Definite=Def|PronType=Art",
"Number=Plur",
""
],
"head": [
"11",
"1",
"6",
"6",
"6",
"1",
"9",
"9",
"6",
"1",
"0",
"13",
"16",
"16",
"16",
"11",
"19",
"19",
"16",
"11"
],
"deprel": [
"nsubj",
"flat",
"punct",
"det",
"compound",
"appos",
"case",
"det",
"nmod",
"punct",
"root",
"det",
"nsubj:pass",
"aux:pass",
"advmod",
"ccomp",
"case",
"det",
"obl:agent",
"punct"
],
"start_char": [
0,
9,
17,
19,
21,
24,
31,
34,
38,
45,
47,
54,
58,
67,
71,
78,
85,
88,
92,
104
],
"end_char": [
8,
17,
18,
20,
23,
30,
33,
37,
45,
46,
53,
57,
66,
70,
77,
84,
87,
91,
104,
105
],
"ner": [
"B-PERSON",
"E-PERSON",
"O",
"O",
"S-ORG",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"BM'nin",
"hastalık",
"konusundaki",
"uzmanlarından",
"biri",
"olan",
"Danielle",
"Lantagne",
",",
"salgına",
"büyük",
"olasılıkla",
"arabulucuların",
"neden",
"olduğunu",
"belirtti",
"."
] | {
"lemma": [
"Bm",
"hastalık",
"konu+ki",
"uzman",
"biri",
"ol",
"Danielle",
"Lantagne",
",",
"salgı",
"büyük",
"olasılık",
"arabulucu",
"neden",
"ol",
"belir",
"."
],
"upos": [
"NOUN",
"NOUN",
"NOUN+ADP",
"NOUN",
"PRON",
"VERB",
"PROPN",
"PROPN",
"PUNCT",
"NOUN",
"ADJ",
"NOUN",
"NOUN",
"NOUN",
"VERB",
"VERB",
"PUNCT"
],
"feats": [
"Abbr=Yes|Case=Gen|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3+",
"Case=Abl|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3|PronType=Ind",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Dat|Number=Sing|Person=3",
"",
"Case=Ins|Number=Sing|Person=3",
"Case=Gen|Number=Plur|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Acc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past|Voice=Cau",
""
],
"head": [
"3",
"3",
"5+3",
"6",
"7",
"8",
"17",
"8",
"8",
"15",
"13",
"15",
"15",
"17",
"15",
"0",
"17"
],
"deprel": [
"nmod:poss",
"nmod:poss",
"nmod+case",
"nmod",
"nsubj",
"acl",
"nsubj",
"flat",
"punct",
"nmod",
"amod",
"nmod",
"nmod",
"obj",
"compound:lvc",
"root",
"punct"
],
"start_char": [
0,
7,
16,
28,
42,
47,
52,
61,
69,
71,
79,
85,
96,
111,
117,
126,
134
],
"end_char": [
6,
15,
27,
41,
46,
51,
60,
69,
70,
78,
84,
95,
110,
116,
125,
134,
135
],
"ner": [
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O",
"B-PERSON",
"E-PERSON",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-10-ht-1 | 927 | flores101-main-101 | tur_t1 | tur | 10 | ht | ht | 165 | null | 174 | 27 | null | 26 | 72.737 | 294 | 201 | 0 | 32 | 3 | 33 | 25 | 0 | 0 | 0 | 0 | 31 | 46,023 | 9 | 34,092 | 72,737 | 1 | 1,643,314,832 | null | null | null | null | null | null | null | null | null | null | 72.737 | 1.2123 | 0.0202 | 0.4408 | 2.694 | 1.7818 | 1,336.3213 | 22.272 | 6 | Travelling by plane can be a scary experience for people of all ages and backgrounds, particularly if they've not flown before or have experienced a traumatic event. | nan | Uçakla seyahat etmek, yaşı ve geçmişi fark etmeksizin herkes için korkutucu bir deneyim olabilir, özellikle de daha önce uçmamış veya travmatik bir olay yaşamış olanlar için. | nan | [
"Travelling",
"by",
"plane",
"can",
"be",
"a",
"scary",
"experience",
"for",
"people",
"of",
"all",
"ages",
"and",
"backgrounds",
",",
"particularly",
"if",
"they",
"'ve",
"not",
"flown",
"before",
"or",
"have",
"experienced",
"a",
"traumatic",
"event",
"."
] | {
"lemma": [
"travel",
"by",
"plane",
"can",
"be",
"a",
"scary",
"experience",
"for",
"people",
"of",
"all",
"age",
"and",
"background",
",",
"particularly",
"if",
"they",
"have",
"not",
"fly",
"before",
"or",
"have",
"experience",
"a",
"traumatic",
"event",
"."
],
"upos": [
"VERB",
"ADP",
"NOUN",
"AUX",
"AUX",
"DET",
"ADJ",
"NOUN",
"ADP",
"NOUN",
"ADP",
"DET",
"NOUN",
"CCONJ",
"NOUN",
"PUNCT",
"ADV",
"SCONJ",
"PRON",
"AUX",
"PART",
"VERB",
"ADV",
"CCONJ",
"AUX",
"VERB",
"DET",
"ADJ",
"NOUN",
"PUNCT"
],
"feats": [
"VerbForm=Ger",
"",
"Number=Sing",
"VerbForm=Fin",
"VerbForm=Inf",
"Definite=Ind|PronType=Art",
"Degree=Pos",
"Number=Sing",
"",
"Number=Plur",
"",
"",
"Number=Plur",
"",
"Number=Plur",
"",
"",
"",
"Case=Nom|Number=Plur|Person=3|PronType=Prs",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Tense=Past|VerbForm=Part",
"",
"",
"Mood=Ind|Person=3|Tense=Pres|VerbForm=Fin",
"Tense=Past|VerbForm=Part",
"Definite=Ind|PronType=Art",
"Degree=Pos",
"Number=Sing",
""
],
"head": [
"8",
"3",
"1",
"8",
"8",
"8",
"8",
"0",
"10",
"8",
"13",
"13",
"10",
"15",
"13",
"8",
"22",
"22",
"22",
"22",
"22",
"8",
"22",
"26",
"26",
"22",
"29",
"29",
"26",
"8"
],
"deprel": [
"csubj",
"case",
"obl",
"aux",
"cop",
"det",
"amod",
"root",
"case",
"nmod",
"case",
"det",
"nmod",
"cc",
"conj",
"punct",
"advmod",
"mark",
"nsubj",
"aux",
"advmod",
"advcl",
"advmod",
"cc",
"aux",
"conj",
"det",
"amod",
"obj",
"punct"
],
"start_char": [
0,
11,
14,
20,
24,
27,
29,
35,
46,
50,
57,
60,
64,
69,
73,
84,
86,
99,
102,
106,
110,
114,
120,
127,
130,
135,
147,
149,
159,
164
],
"end_char": [
10,
13,
19,
23,
26,
28,
34,
45,
49,
56,
59,
63,
68,
72,
84,
85,
98,
101,
106,
109,
113,
119,
126,
129,
134,
146,
148,
158,
164,
165
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Uçakla",
"seyahat",
"etmek",
",",
"yaşı",
"ve",
"geçmişi",
"fark",
"etmeksizin",
"herkes",
"için",
"korkutucu",
"bir",
"deneyim",
"olabilir",
",",
"özellikle",
"de",
"daha",
"önce",
"uçmamış",
"veya",
"travmatik",
"bir",
"olay",
"yaşamış",
"olanlar",
"için",
"."
] | {
"lemma": [
"uçak",
"seyahat",
"et",
",",
"yaş",
"ve",
"geçmiş",
"fark",
"et",
"herkes",
"için",
"korkutucu",
"bir",
"deneyim",
"ol",
",",
"özellikle",
"de",
"daha",
"önce",
"uç",
"veya",
"travmatik",
"bir",
"olay",
"yaşa",
"ol",
"için",
"."
],
"upos": [
"NOUN",
"NOUN",
"VERB",
"PUNCT",
"NOUN",
"CCONJ",
"NOUN",
"NOUN",
"VERB",
"NOUN",
"ADP",
"ADJ",
"DET",
"NOUN",
"VERB",
"PUNCT",
"ADV",
"CCONJ",
"ADV",
"ADV",
"VERB",
"CCONJ",
"ADJ",
"DET",
"NOUN",
"VERB",
"VERB",
"ADP",
"PUNCT"
],
"feats": [
"Case=Ins|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Neg|Tense=Pres|VerbForm=Conv",
"Case=Nom|Number=Sing|Person=3",
"",
"",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Hab|Mood=Pot|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"",
"",
"",
"",
"Aspect=Perf|Evident=Nfh|Mood=Ind|Polarity=Neg|Tense=Past|VerbForm=Part",
"",
"",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Evident=Nfh|Mood=Ind|Polarity=Pos|Tense=Past|VerbForm=Part",
"Aspect=Perf|Case=Nom|Mood=Ind|Number=Plur|Person=3|Polarity=Pos|Tense=Pres|VerbForm=Part",
"",
""
],
"head": [
"2",
"8",
"2",
"2",
"8",
"7",
"5",
"15",
"8",
"15",
"10",
"14",
"14",
"15",
"0",
"27",
"20",
"17",
"20",
"21",
"25",
"25",
"25",
"25",
"26",
"27",
"15",
"27",
"27"
],
"deprel": [
"nmod",
"nmod",
"compound:lvc",
"punct",
"nsubj",
"cc",
"conj",
"obl",
"compound:lvc",
"obl",
"case",
"amod",
"det",
"obj",
"root",
"punct",
"advmod",
"advmod:emph",
"advmod",
"advmod",
"acl",
"cc",
"amod",
"det",
"obj",
"obj",
"conj",
"case",
"punct"
],
"start_char": [
0,
7,
15,
20,
22,
27,
30,
38,
43,
54,
61,
66,
76,
80,
88,
96,
98,
108,
111,
116,
121,
129,
134,
144,
148,
153,
161,
169,
173
],
"end_char": [
6,
14,
20,
21,
26,
29,
37,
42,
53,
60,
65,
75,
79,
87,
96,
97,
107,
110,
115,
120,
128,
133,
143,
147,
152,
160,
168,
173,
174
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-10-ht-2 | 928 | flores101-main-102 | tur_t1 | tur | 10 | ht | ht | 137 | null | 113 | 26 | null | 14 | 48.076 | 222 | 138 | 0 | 18 | 2 | 47 | 15 | 0 | 1 | 1 | 0 | 20 | 28,688 | 9 | 22,310 | 48,076 | 2 | 1,643,314,832 | null | null | null | null | null | null | null | null | null | null | 48.076 | 0.8013 | 0.0134 | 0.3509 | 1.8491 | 1.6204 | 1,946.9174 | 32.4486 | 7 | It is not something to be ashamed of: it is no different from the personal fears and dislikes of other things that very many people have. | nan | Birçok insanın bazı şeylerden korkmasından veya hoşlanmamasından farksız olduğu için utanılacak bir şey değildir. | nan | [
"It",
"is",
"not",
"something",
"to",
"be",
"ashamed",
"of",
":",
"it",
"is",
"no",
"different",
"from",
"the",
"personal",
"fears",
"and",
"dislikes",
"of",
"other",
"things",
"that",
"very",
"many",
"people",
"have",
"."
] | {
"lemma": [
"it",
"be",
"not",
"something",
"to",
"be",
"ashamed",
"of",
":",
"it",
"be",
"no",
"different",
"from",
"the",
"personal",
"fear",
"and",
"dislike",
"of",
"other",
"thing",
"that",
"very",
"many",
"people",
"have",
"."
],
"upos": [
"PRON",
"AUX",
"PART",
"PRON",
"PART",
"AUX",
"VERB",
"ADP",
"PUNCT",
"PRON",
"AUX",
"ADV",
"ADJ",
"ADP",
"DET",
"ADJ",
"NOUN",
"CCONJ",
"NOUN",
"ADP",
"ADJ",
"NOUN",
"PRON",
"ADV",
"ADJ",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|Gender=Neut|Number=Sing|Person=3|PronType=Prs",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Number=Sing",
"",
"VerbForm=Inf",
"Tense=Past|VerbForm=Part|Voice=Pass",
"",
"",
"Case=Nom|Gender=Neut|Number=Sing|Person=3|PronType=Prs",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Degree=Pos",
"",
"Definite=Def|PronType=Art",
"Degree=Pos",
"Number=Plur",
"",
"Number=Plur",
"",
"Degree=Pos",
"Number=Plur",
"PronType=Rel",
"",
"Degree=Pos",
"Number=Plur",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
""
],
"head": [
"4",
"4",
"4",
"0",
"7",
"7",
"4",
"7",
"4",
"13",
"13",
"13",
"4",
"17",
"17",
"17",
"13",
"19",
"17",
"22",
"22",
"17",
"27",
"25",
"26",
"27",
"22",
"4"
],
"deprel": [
"nsubj",
"cop",
"advmod",
"root",
"mark",
"aux:pass",
"acl",
"obl",
"punct",
"nsubj",
"cop",
"advmod",
"parataxis",
"case",
"det",
"amod",
"obl",
"cc",
"conj",
"case",
"amod",
"nmod",
"obj",
"advmod",
"amod",
"nsubj",
"acl:relcl",
"punct"
],
"start_char": [
0,
3,
6,
10,
20,
23,
26,
34,
36,
38,
41,
44,
47,
57,
62,
66,
75,
81,
85,
94,
97,
103,
110,
115,
120,
125,
132,
136
],
"end_char": [
2,
5,
9,
19,
22,
25,
33,
36,
37,
40,
43,
46,
56,
61,
65,
74,
80,
84,
93,
96,
102,
109,
114,
119,
124,
131,
136,
137
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Birçok",
"insanın",
"bazı",
"şeylerden",
"korkmasından",
"veya",
"hoşlanmamasından",
"farksız",
"olduğu",
"için",
"utanılacak",
"bir",
"şey",
"değildir",
"."
] | {
"lemma": [
"birçok",
"insan",
"bazı",
"şey",
"kork",
"veya",
"hoşlan",
"farksız",
"ol",
"için",
"utan",
"bir",
"şey",
"değil",
"."
],
"upos": [
"DET",
"NOUN",
"DET",
"NOUN",
"VERB",
"CCONJ",
"VERB",
"ADJ",
"VERB",
"ADP",
"VERB",
"NUM",
"NOUN",
"AUX",
"PUNCT"
],
"feats": [
"",
"Case=Gen|Number=Sing|Person=3",
"",
"Case=Abl|Number=Plur|Person=3",
"Aspect=Perf|Case=Abl|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"Aspect=Perf|Case=Abl|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"Aspect=Perf|Case=Nom|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Fut|VerbForm=Part|Voice=Pass",
"NumType=Card",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Gen|Number=Sing|Person=3|Polarity=Neg|Tense=Pres",
""
],
"head": [
"2",
"5",
"4",
"5",
"11",
"8",
"8",
"5",
"8",
"5",
"13",
"14",
"12",
"0",
"14"
],
"deprel": [
"det",
"nmod:poss",
"det",
"obl",
"nmod",
"cc",
"nmod",
"conj",
"compound:lvc",
"case",
"acl",
"nsubj",
"compound",
"root",
"punct"
],
"start_char": [
0,
7,
15,
20,
30,
43,
48,
65,
73,
80,
85,
96,
100,
104,
112
],
"end_char": [
6,
14,
19,
29,
42,
47,
64,
72,
79,
84,
95,
99,
103,
112,
113
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-10-ht-3 | 929 | flores101-main-103 | tur_t1 | tur | 10 | ht | ht | 176 | null | 180 | 32 | null | 22 | 85.767 | 255 | 209 | 0 | 26 | 2 | 9 | 9 | 0 | 0 | 0 | 0 | 35 | 61,651 | 16 | 51,711 | 85,767 | 1 | 1,643,314,832 | null | null | null | null | null | null | null | null | null | null | 85.767 | 1.4294 | 0.0238 | 0.4873 | 2.6802 | 1.4489 | 1,343.1739 | 22.3862 | 8 | For some, understanding something about how aircraft work and what happens during a flight may help to overcome a fear which is based on the unknown or on not being in control. | nan | Uçağın işleyişini ve bir uçuş sırasında neler olduğunu anlamak, bazı insanların bilmemekten veya kontrolün ellerinde olmamasından kaynaklanan bu korkuyu aşmasına yardımcı olabilir. | nan | [
"For",
"some",
",",
"understanding",
"something",
"about",
"how",
"aircraft",
"work",
"and",
"what",
"happens",
"during",
"a",
"flight",
"may",
"help",
"to",
"overcome",
"a",
"fear",
"which",
"is",
"based",
"on",
"the",
"unknown",
"or",
"on",
"not",
"being",
"in",
"control",
"."
] | {
"lemma": [
"for",
"some",
",",
"understand",
"something",
"about",
"how",
"aircraft",
"work",
"and",
"what",
"happen",
"during",
"a",
"flight",
"may",
"help",
"to",
"overcome",
"a",
"fear",
"which",
"be",
"base",
"on",
"the",
"unknown",
"or",
"on",
"not",
"be",
"in",
"control",
"."
],
"upos": [
"ADP",
"DET",
"PUNCT",
"VERB",
"PRON",
"SCONJ",
"SCONJ",
"NOUN",
"NOUN",
"CCONJ",
"PRON",
"VERB",
"ADP",
"DET",
"NOUN",
"AUX",
"VERB",
"PART",
"VERB",
"DET",
"NOUN",
"PRON",
"AUX",
"VERB",
"ADP",
"DET",
"ADJ",
"CCONJ",
"SCONJ",
"PART",
"AUX",
"ADP",
"NOUN",
"PUNCT"
],
"feats": [
"",
"",
"",
"VerbForm=Ger",
"Number=Sing",
"",
"PronType=Int",
"Number=Sing",
"Number=Sing",
"",
"PronType=Int",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"VerbForm=Fin",
"VerbForm=Inf",
"",
"VerbForm=Inf",
"Definite=Ind|PronType=Art",
"Number=Sing",
"PronType=Rel",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"Tense=Past|VerbForm=Part|Voice=Pass",
"",
"Definite=Def|PronType=Art",
"Degree=Pos|Polarity=Neg",
"",
"",
"",
"VerbForm=Ger",
"",
"Number=Sing",
""
],
"head": [
"2",
"17",
"17",
"17",
"4",
"7",
"9",
"9",
"4",
"11",
"9",
"11",
"15",
"15",
"12",
"17",
"0",
"19",
"17",
"21",
"19",
"24",
"24",
"21",
"27",
"27",
"24",
"33",
"33",
"33",
"33",
"33",
"27",
"17"
],
"deprel": [
"case",
"obl",
"punct",
"csubj",
"obj",
"case",
"mark",
"compound",
"obj",
"cc",
"conj",
"acl:relcl",
"case",
"det",
"obl",
"aux",
"root",
"mark",
"xcomp",
"det",
"obj",
"nsubj:pass",
"aux:pass",
"acl:relcl",
"case",
"det",
"obl",
"cc",
"mark",
"advmod",
"cop",
"case",
"conj",
"punct"
],
"start_char": [
0,
4,
8,
10,
24,
34,
40,
44,
53,
58,
62,
67,
75,
82,
84,
91,
95,
100,
103,
112,
114,
119,
125,
128,
134,
137,
141,
149,
152,
155,
159,
165,
168,
175
],
"end_char": [
3,
8,
9,
23,
33,
39,
43,
52,
57,
61,
66,
74,
81,
83,
90,
94,
99,
102,
111,
113,
118,
124,
127,
133,
136,
140,
148,
151,
154,
158,
164,
167,
175,
176
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Uçağın",
"işleyişini",
"ve",
"bir",
"uçuş",
"sırasında",
"neler",
"olduğunu",
"anlamak",
",",
"bazı",
"insanların",
"bilmemekten",
"veya",
"kontrolün",
"ellerinde",
"olmamasından",
"kaynaklanan",
"bu",
"korkuyu",
"aşmasına",
"yardımcı",
"olabilir",
"."
] | {
"lemma": [
"uçak",
"işleyiş",
"ve",
"bir",
"uçuş",
"sıra",
"ne",
"ol",
"anla",
",",
"bazı",
"insan",
"bil",
"veya",
"kontrol",
"el",
"ol",
"kaynakla",
"bu",
"korku",
"aş",
"yardımcı",
"ol",
"."
],
"upos": [
"NOUN",
"NOUN",
"CCONJ",
"DET",
"NOUN",
"NOUN",
"PRON",
"VERB",
"VERB",
"PUNCT",
"DET",
"NOUN",
"VERB",
"CCONJ",
"NOUN",
"NOUN",
"VERB",
"VERB",
"DET",
"NOUN",
"VERB",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Gen|Number=Sing|Person=3",
"Case=Acc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Plur|Person=3",
"Aspect=Perf|Case=Acc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"",
"Case=Gen|Number=Plur|Person=3",
"Aspect=Perf|Case=Abl|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"Case=Gen|Number=Sing|Person=3",
"Case=Loc|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Abl|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part|Voice=Pass",
"",
"Case=Acc|Number=Sing|Person=3",
"Aspect=Perf|Case=Dat|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Hab|Mood=Pot|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"2",
"8",
"6",
"5",
"6",
"8",
"8",
"9",
"22",
"9",
"12",
"13",
"17",
"15",
"13",
"17",
"18",
"20",
"20",
"21",
"22",
"0",
"22",
"22"
],
"deprel": [
"nmod:poss",
"obj",
"cc",
"det",
"nmod:poss",
"obl",
"obj",
"obj",
"nsubj",
"punct",
"det",
"nmod:poss",
"nmod",
"cc",
"conj",
"obl",
"nmod",
"acl",
"det",
"obj",
"nmod",
"root",
"compound:lvc",
"punct"
],
"start_char": [
0,
7,
18,
21,
25,
30,
40,
46,
55,
62,
64,
69,
80,
92,
97,
107,
117,
130,
142,
145,
153,
162,
171,
179
],
"end_char": [
6,
17,
20,
24,
29,
39,
45,
54,
62,
63,
68,
79,
91,
96,
106,
116,
129,
141,
144,
152,
161,
170,
179,
180
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-100-pe1-1 | 894 | flores101-main-1001 | tur_t1 | tur | 100 | pe1 | pe | 124 | 126 | 128 | 21 | 20 | 20 | 18.135 | 50 | 13 | 0 | 2 | 1 | 32 | 2 | 0 | 0 | 0 | 0 | 4 | 11,206 | 2 | 9,881 | 18,135 | 1 | 1,643,315,008 | 1 | 0 | 2 | 1 | 2 | 4 | 16.667 | 0.1449 | 63.38 | 82.98 | 18.135 | 0.3022 | 0.005 | 0.1463 | 0.8636 | 0.4032 | 4,168.7345 | 69.4789 | 9 | Re-entry shock comes on sooner than culture shock (there's less of a honeymoon phase), lasts longer, and can be more severe. | Yeniden giriş şoku kültür şokundan daha erken gelir (daha az balayı evresi vardır), daha uzun sürer ve daha şiddetli olabilir. | Yeniden giriş şoku, kültür şokundan daha erken gelir (balayı evresi daha kısa sürer), daha uzun sürer ve daha şiddetli olabilir. | REF: yeniden giriş şoku * kültür şokundan daha erken gelir ( daha az balayı evresi vardır ) , daha uzun sürer ve daha şiddetli olabilir .\nHYP: yeniden giriş şoku , kültür şokundan daha erken gelir ( @ daha kısa [ balayı evresi ] sürer ) , daha uzun sürer ve daha şiddetli olabilir .\nEVAL: I S S | [
"Re-entry",
"shock",
"comes",
"on",
"sooner",
"than",
"culture",
"shock",
"(",
"there",
"'s",
"less",
"of",
"a",
"honeymoon",
"phase",
")",
",",
"lasts",
"longer",
",",
"and",
"can",
"be",
"more",
"severe",
"."
] | {
"lemma": [
"re-entry",
"shock",
"come",
"on",
"soon",
"than",
"culture",
"shock",
"(",
"there",
"be",
"less",
"of",
"a",
"honeymoon",
"phase",
")",
",",
"last",
"long",
",",
"and",
"can",
"be",
"more",
"severe",
"."
],
"upos": [
"NOUN",
"NOUN",
"VERB",
"ADP",
"ADV",
"ADP",
"NOUN",
"NOUN",
"PUNCT",
"PRON",
"VERB",
"ADJ",
"ADP",
"DET",
"NOUN",
"NOUN",
"PUNCT",
"PUNCT",
"VERB",
"ADV",
"PUNCT",
"CCONJ",
"AUX",
"AUX",
"ADV",
"ADJ",
"PUNCT"
],
"feats": [
"Number=Sing",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Degree=Cmp",
"",
"Number=Sing",
"Number=Sing",
"",
"",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"Degree=Cmp",
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"Number=Sing",
"",
"",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"Degree=Cmp",
"",
"",
"VerbForm=Fin",
"VerbForm=Inf",
"Degree=Cmp",
"Degree=Pos",
""
],
"head": [
"2",
"3",
"0",
"3",
"3",
"8",
"8",
"5",
"11",
"11",
"3",
"11",
"16",
"16",
"16",
"12",
"11",
"19",
"3",
"19",
"26",
"26",
"26",
"26",
"26",
"19",
"3"
],
"deprel": [
"compound",
"nsubj",
"root",
"compound:prt",
"advmod",
"case",
"compound",
"obl",
"punct",
"expl",
"parataxis",
"nsubj",
"case",
"det",
"compound",
"obl",
"punct",
"punct",
"parataxis",
"advmod",
"punct",
"cc",
"aux",
"cop",
"advmod",
"conj",
"punct"
],
"start_char": [
0,
9,
15,
21,
24,
31,
36,
44,
50,
51,
56,
59,
64,
67,
69,
79,
84,
85,
87,
93,
99,
101,
105,
109,
112,
117,
123
],
"end_char": [
8,
14,
20,
23,
30,
35,
43,
49,
51,
56,
58,
63,
66,
68,
78,
84,
85,
86,
92,
99,
100,
104,
108,
111,
116,
123,
124
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Yeniden",
"giriş",
"şoku",
"kültür",
"şokundan",
"daha",
"erken",
"gelir",
"(",
"daha",
"az",
"balayı",
"evresi",
"vardır",
")",
",",
"daha",
"uzun",
"sürer",
"ve",
"daha",
"şiddetli",
"olabilir",
"."
] | {
"lemma": [
"yeniden",
"giriş",
"şok",
"kültür",
"şokun",
"daha",
"erken",
"gel",
"(",
"daha",
"az",
"bala",
"evre",
"var+i",
")",
",",
"daha",
"uzun",
"sür",
"ve",
"daha",
"şiddet+li",
"ol",
"."
],
"upos": [
"ADV",
"NOUN",
"NOUN",
"NOUN",
"NOUN",
"ADV",
"ADV",
"VERB",
"PUNCT",
"ADV",
"ADJ",
"NOUN",
"NOUN",
"ADJ+AUX",
"PUNCT",
"PUNCT",
"ADV",
"ADJ",
"VERB",
"CCONJ",
"ADV",
"NOUN+ADP",
"VERB",
"PUNCT"
],
"feats": [
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Acc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Abl|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"",
"Aspect=Hab|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"",
"",
"Case=Acc|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3+Aspect=Perf|Mood=Gen|Number=Sing|Person=3|Tense=Pres",
"",
"",
"",
"",
"Aspect=Hab|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"",
"Case=Nom|Number=Sing|Person=3+",
"Aspect=Hab|Mood=Pot|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"0",
"5",
"7",
"5",
"7",
"7",
"14",
"7",
"14",
"11",
"12",
"13",
"14",
"1+14",
"14",
"20",
"19",
"20",
"14",
"25",
"23",
"25+23",
"14",
"25"
],
"deprel": [
"root",
"nmod:poss",
"obj",
"nmod:poss",
"nmod",
"advmod",
"advmod",
"compound",
"punct",
"advmod",
"amod",
"nmod:poss",
"nsubj",
"conj+cop",
"punct",
"punct",
"advmod",
"amod",
"conj",
"cc",
"advmod",
"obl+case",
"conj",
"punct"
],
"start_char": [
0,
8,
14,
19,
26,
35,
40,
46,
52,
53,
58,
61,
68,
75,
81,
82,
84,
89,
94,
100,
103,
108,
117,
125
],
"end_char": [
7,
13,
18,
25,
34,
39,
45,
51,
53,
57,
60,
67,
74,
81,
82,
83,
88,
93,
99,
102,
107,
116,
125,
126
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Yeniden",
"giriş",
"şoku",
",",
"kültür",
"şokundan",
"daha",
"erken",
"gelir",
"(",
"balayı",
"evresi",
"daha",
"kısa",
"sürer",
")",
",",
"daha",
"uzun",
"sürer",
"ve",
"daha",
"şiddetli",
"olabilir",
"."
] | {
"lemma": [
"yeniden",
"giriş",
"şok",
",",
"kültür",
"şokun",
"daha",
"erken",
"gel",
"(",
"bala",
"evre",
"daha",
"kısa",
"sür",
")",
",",
"daha",
"uzun",
"sür",
"ve",
"daha",
"şiddet+li",
"ol",
"."
],
"upos": [
"ADV",
"NOUN",
"NOUN",
"PUNCT",
"NOUN",
"NOUN",
"ADV",
"ADV",
"VERB",
"PUNCT",
"NOUN",
"NOUN",
"ADV",
"ADJ",
"VERB",
"PUNCT",
"PUNCT",
"ADV",
"ADJ",
"VERB",
"CCONJ",
"ADV",
"NOUN+ADP",
"VERB",
"PUNCT"
],
"feats": [
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Abl|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"",
"Aspect=Hab|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"",
"Aspect=Hab|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"",
"",
"",
"Aspect=Hab|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"",
"Case=Nom|Number=Sing|Person=3+",
"Aspect=Hab|Mood=Pot|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"0",
"3",
"9",
"3",
"6",
"8",
"8",
"15",
"15",
"15",
"12",
"15",
"14",
"15",
"1",
"15",
"15",
"19",
"20",
"1",
"25",
"23",
"25+23",
"20",
"25"
],
"deprel": [
"root",
"nmod:poss",
"nsubj",
"punct",
"nmod:poss",
"nmod",
"advmod",
"advmod",
"nmod",
"punct",
"nmod:poss",
"obj",
"advmod",
"amod",
"conj",
"punct",
"punct",
"advmod",
"amod",
"conj",
"cc",
"advmod",
"obl+case",
"conj",
"punct"
],
"start_char": [
0,
8,
14,
18,
20,
27,
36,
41,
47,
53,
54,
61,
68,
73,
78,
83,
84,
86,
91,
96,
102,
105,
110,
119,
127
],
"end_char": [
7,
13,
18,
19,
26,
35,
40,
46,
52,
54,
60,
67,
72,
77,
83,
84,
85,
90,
95,
101,
104,
109,
118,
127,
128
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"BAD",
"OK",
"OK",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] | [
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"BAD",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] |
flores101-main-tur-100-pe1-2 | 895 | flores101-main-1002 | tur_t1 | tur | 100 | pe1 | pe | 137 | 117 | 117 | 22 | 14 | 14 | 7.469 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7,469 | 1 | 1,643,315,008 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 100 | 7.469 | 0.1245 | 0.0021 | 0.0545 | 0.3395 | 0.0073 | 10,603.8292 | 176.7305 | 10 | Travellers who had an easy time adjusting to the new culture sometimes have a particularly hard time readjusting to their native culture. | Yeni kültüre kolayca uyum sağlayan gezginler, bazen kendi kültürlerine yeniden uyum sağlamakta özellikle zorlanırlar. | Yeni kültüre kolayca uyum sağlayan gezginler, bazen kendi kültürlerine yeniden uyum sağlamakta özellikle zorlanırlar. | REF: yeni kültüre kolayca uyum sağlayan gezginler , bazen kendi kültürlerine yeniden uyum sağlamakta özellikle zorlanırlar .\nHYP: yeni kültüre kolayca uyum sağlayan gezginler , bazen kendi kültürlerine yeniden uyum sağlamakta özellikle zorlanırlar .\nEVAL: | [
"Travellers",
"who",
"had",
"an",
"easy",
"time",
"adjusting",
"to",
"the",
"new",
"culture",
"sometimes",
"have",
"a",
"particularly",
"hard",
"time",
"readjusting",
"to",
"their",
"native",
"culture",
"."
] | {
"lemma": [
"traveller",
"who",
"have",
"a",
"easy",
"time",
"adjust",
"to",
"the",
"new",
"culture",
"sometimes",
"have",
"a",
"particularly",
"hard",
"time",
"readjust",
"to",
"they",
"native",
"culture",
"."
],
"upos": [
"NOUN",
"PRON",
"VERB",
"DET",
"ADJ",
"NOUN",
"VERB",
"ADP",
"DET",
"ADJ",
"NOUN",
"ADV",
"VERB",
"DET",
"ADV",
"ADJ",
"NOUN",
"VERB",
"ADP",
"PRON",
"ADJ",
"NOUN",
"PUNCT"
],
"feats": [
"Number=Plur",
"PronType=Rel",
"Mood=Ind|Number=Plur|Person=3|Tense=Past|VerbForm=Fin",
"Definite=Ind|PronType=Art",
"Degree=Pos",
"Number=Sing",
"VerbForm=Ger",
"",
"Definite=Def|PronType=Art",
"Degree=Pos",
"Number=Sing",
"",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"Definite=Ind|PronType=Art",
"",
"Degree=Pos",
"Number=Sing",
"VerbForm=Ger",
"",
"Number=Plur|Person=3|Poss=Yes|PronType=Prs",
"Degree=Pos",
"Number=Sing",
""
],
"head": [
"13",
"3",
"1",
"6",
"6",
"3",
"6",
"11",
"11",
"11",
"7",
"13",
"0",
"17",
"16",
"17",
"13",
"17",
"22",
"22",
"22",
"18",
"13"
],
"deprel": [
"nsubj",
"nsubj",
"acl:relcl",
"det",
"amod",
"obj",
"acl",
"case",
"det",
"amod",
"obl",
"advmod",
"root",
"det",
"advmod",
"amod",
"obj",
"acl",
"case",
"nmod:poss",
"amod",
"obl",
"punct"
],
"start_char": [
0,
11,
15,
19,
22,
27,
32,
42,
45,
49,
53,
61,
71,
76,
78,
91,
96,
101,
113,
116,
122,
129,
136
],
"end_char": [
10,
14,
18,
21,
26,
31,
41,
44,
48,
52,
60,
70,
75,
77,
90,
95,
100,
112,
115,
121,
128,
136,
137
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Yeni",
"kültüre",
"kolayca",
"uyum",
"sağlayan",
"gezginler",
",",
"bazen",
"kendi",
"kültürlerine",
"yeniden",
"uyum",
"sağlamakta",
"özellikle",
"zorlanırlar",
"."
] | {
"lemma": [
"yeni",
"kültüre",
"kolayca",
"uyum",
"sağla",
"gezgin",
",",
"bazen",
"kendi",
"kültür",
"yeniden",
"uyum",
"sağla",
"özellikle",
"zorla",
"."
],
"upos": [
"ADJ",
"NOUN",
"ADJ",
"NOUN",
"VERB",
"NOUN",
"PUNCT",
"ADV",
"PRON",
"NOUN",
"ADV",
"NOUN",
"VERB",
"ADV",
"VERB",
"PUNCT"
],
"feats": [
"",
"Case=Dat|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Nom|Number=Plur|Person=3",
"",
"",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3|Reflex=Yes",
"Case=Dat|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Prog|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Polite=Form|Tense=Pres",
"",
"Aspect=Hab|Mood=Ind|Number=Plur|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"2",
"5",
"5",
"5",
"6",
"15",
"6",
"15",
"10",
"12",
"12",
"15",
"12",
"15",
"0",
"15"
],
"deprel": [
"amod",
"obl",
"amod",
"obj",
"acl",
"nsubj",
"punct",
"advmod",
"nmod",
"nmod",
"advmod",
"obl",
"compound",
"advmod",
"root",
"punct"
],
"start_char": [
0,
5,
13,
21,
26,
35,
44,
46,
52,
58,
71,
79,
84,
95,
105,
116
],
"end_char": [
4,
12,
20,
25,
34,
44,
45,
51,
57,
70,
78,
83,
94,
104,
116,
117
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Yeni",
"kültüre",
"kolayca",
"uyum",
"sağlayan",
"gezginler",
",",
"bazen",
"kendi",
"kültürlerine",
"yeniden",
"uyum",
"sağlamakta",
"özellikle",
"zorlanırlar",
"."
] | {
"lemma": [
"yeni",
"kültüre",
"kolayca",
"uyum",
"sağla",
"gezgin",
",",
"bazen",
"kendi",
"kültür",
"yeniden",
"uyum",
"sağla",
"özellikle",
"zorla",
"."
],
"upos": [
"ADJ",
"NOUN",
"ADJ",
"NOUN",
"VERB",
"NOUN",
"PUNCT",
"ADV",
"PRON",
"NOUN",
"ADV",
"NOUN",
"VERB",
"ADV",
"VERB",
"PUNCT"
],
"feats": [
"",
"Case=Dat|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Nom|Number=Plur|Person=3",
"",
"",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3|Reflex=Yes",
"Case=Dat|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Prog|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Polite=Form|Tense=Pres",
"",
"Aspect=Hab|Mood=Ind|Number=Plur|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"2",
"5",
"5",
"5",
"6",
"15",
"6",
"15",
"10",
"12",
"12",
"15",
"12",
"15",
"0",
"15"
],
"deprel": [
"amod",
"obl",
"amod",
"obj",
"acl",
"nsubj",
"punct",
"advmod",
"nmod",
"nmod",
"advmod",
"obl",
"compound",
"advmod",
"root",
"punct"
],
"start_char": [
0,
5,
13,
21,
26,
35,
44,
46,
52,
58,
71,
79,
84,
95,
105,
116
],
"end_char": [
4,
12,
20,
25,
34,
44,
45,
51,
57,
70,
78,
83,
94,
104,
116,
117
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] |
flores101-main-tur-100-pe1-3 | 896 | flores101-main-1003 | tur_t1 | tur | 100 | pe1 | pe | 127 | 133 | 148 | 22 | 15 | 17 | 28.256 | 69 | 31 | 0 | 4 | 1 | 32 | 1 | 0 | 0 | 0 | 0 | 8 | 24,645 | 5 | 22,769 | 28,256 | 1 | 1,643,315,008 | 3 | 0 | 4 | 0 | 0 | 7 | 43.75 | 0.2015 | 16.7 | 74.22 | 28.256 | 0.4709 | 0.0078 | 0.2225 | 1.2844 | 0.5433 | 2,802.9445 | 46.7157 | 11 | When returning home after living abroad, you've adapted to the new culture and lost some of your habits from your home culture. | Yurtdışında yaşadıktan sonra eve döndüğünüzde yeni kültüre adapte oldunuz ve kendi kültürünüzden bazı alışkanlıklarınızı kaybettiniz. | Yurtdışında yaşadıktan sonra ülkenize döndüğünüzde, yeni kültüre adapte olmuş ve kendi kültürünüze dair bazı alışkanlıklarınızı kaybetmiş olursunuz. | REF: yurtdışında yaşadıktan sonra eve döndüğünüzde * yeni kültüre adapte oldunuz ve kendi *********** kültürünüzden bazı alışkanlıklarınızı ********* kaybettiniz .\nHYP: yurtdışında yaşadıktan sonra ülkenize döndüğünüzde , yeni kültüre adapte olmuş ve kendi kültürünüze dair bazı alışkanlıklarınızı kaybetmiş olursunuz .\nEVAL: S I S I S I S | [
"When",
"returning",
"home",
"after",
"living",
"abroad",
",",
"you",
"'ve",
"adapted",
"to",
"the",
"new",
"culture",
"and",
"lost",
"some",
"of",
"your",
"habits",
"from",
"your",
"home",
"culture",
"."
] | {
"lemma": [
"when",
"return",
"home",
"after",
"live",
"abroad",
",",
"you",
"have",
"adapt",
"to",
"the",
"new",
"culture",
"and",
"lose",
"some",
"of",
"you",
"habit",
"from",
"you",
"home",
"culture",
"."
],
"upos": [
"SCONJ",
"VERB",
"ADV",
"SCONJ",
"VERB",
"ADV",
"PUNCT",
"PRON",
"AUX",
"VERB",
"ADP",
"DET",
"ADJ",
"NOUN",
"CCONJ",
"VERB",
"DET",
"ADP",
"PRON",
"NOUN",
"ADP",
"PRON",
"NOUN",
"NOUN",
"PUNCT"
],
"feats": [
"PronType=Int",
"VerbForm=Ger",
"",
"",
"VerbForm=Ger",
"",
"",
"Case=Nom|Person=2|PronType=Prs",
"Mood=Ind|Number=Sing|Person=2|Tense=Pres|VerbForm=Fin",
"Tense=Past|VerbForm=Part",
"",
"Definite=Def|PronType=Art",
"Degree=Pos",
"Number=Sing",
"",
"Tense=Past|VerbForm=Part",
"",
"",
"Person=2|Poss=Yes|PronType=Prs",
"Number=Plur",
"",
"Person=2|Poss=Yes|PronType=Prs",
"Number=Sing",
"Number=Sing",
""
],
"head": [
"2",
"10",
"2",
"5",
"2",
"5",
"2",
"10",
"10",
"0",
"14",
"14",
"14",
"10",
"16",
"10",
"16",
"20",
"20",
"17",
"24",
"24",
"24",
"16",
"10"
],
"deprel": [
"mark",
"advcl",
"advmod",
"mark",
"advcl",
"advmod",
"punct",
"nsubj",
"aux",
"root",
"case",
"det",
"amod",
"obl",
"cc",
"conj",
"obj",
"case",
"nmod:poss",
"nmod",
"case",
"nmod:poss",
"compound",
"obl",
"punct"
],
"start_char": [
0,
5,
15,
20,
26,
33,
39,
41,
44,
48,
56,
59,
63,
67,
75,
79,
84,
89,
92,
97,
104,
109,
114,
119,
126
],
"end_char": [
4,
14,
19,
25,
32,
39,
40,
44,
47,
55,
58,
62,
66,
74,
78,
83,
88,
91,
96,
103,
108,
113,
118,
126,
127
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Yurtdışında",
"yaşadıktan",
"sonra",
"eve",
"döndüğünüzde",
"yeni",
"kültüre",
"adapte",
"oldunuz",
"ve",
"kendi",
"kültürünüzden",
"bazı",
"alışkanlıklarınızı",
"kaybettiniz",
"."
] | {
"lemma": [
"yurtdışı",
"yaşa",
"sonra",
"ev",
"dön",
"yeni",
"kültüre",
"adap",
"ol",
"ve",
"kendi",
"kültür",
"bazı",
"alışkanlık",
"kaybet",
"."
],
"upos": [
"NOUN",
"VERB",
"ADP",
"NOUN",
"VERB",
"ADJ",
"NOUN",
"NOUN",
"VERB",
"CCONJ",
"PRON",
"NOUN",
"DET",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Abl|Mood=Ind|Polarity=Pos|Tense=Past|VerbForm=Part",
"",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Perf|Case=Loc|Mood=Ind|Number[psor]=Plur|Person[psor]=2|Polarity=Pos|Tense=Past|VerbForm=Part",
"",
"Case=Dat|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Plur|Person=2|Polarity=Pos|Tense=Past",
"",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3|Reflex=Yes",
"Case=Abl|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=2",
"",
"Case=Acc|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=2",
"Aspect=Perf|Mood=Ind|Number=Plur|Person=2|Polarity=Pos|Tense=Past",
""
],
"head": [
"2",
"8",
"2",
"5",
"8",
"7",
"8",
"0",
"8",
"15",
"12",
"15",
"14",
"15",
"8",
"15"
],
"deprel": [
"obl",
"acl",
"case",
"obl",
"acl",
"amod",
"nmod",
"root",
"compound:lvc",
"cc",
"nmod",
"obl",
"det",
"obj",
"conj",
"punct"
],
"start_char": [
0,
12,
23,
29,
33,
46,
51,
59,
66,
74,
77,
83,
97,
102,
121,
132
],
"end_char": [
11,
22,
28,
32,
45,
50,
58,
65,
73,
76,
82,
96,
101,
120,
132,
133
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Yurtdışında",
"yaşadıktan",
"sonra",
"ülkenize",
"döndüğünüzde",
",",
"yeni",
"kültüre",
"adapte",
"olmuş",
"ve",
"kendi",
"kültürünüze",
"dair",
"bazı",
"alışkanlıklarınızı",
"kaybetmiş",
"olursunuz",
"."
] | {
"lemma": [
"yurtdışı",
"yaşa",
"sonra",
"ülke",
"dön",
",",
"yeni",
"kültüre",
"adap",
"ol",
"ve",
"kendi",
"kültür",
"dair",
"bazı",
"alışkanlık",
"kaybet",
"ol",
"."
],
"upos": [
"NOUN",
"VERB",
"ADP",
"NOUN",
"VERB",
"PUNCT",
"ADJ",
"NOUN",
"NOUN",
"VERB",
"CCONJ",
"PRON",
"NOUN",
"ADP",
"DET",
"NOUN",
"VERB",
"VERB",
"PUNCT"
],
"feats": [
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Abl|Mood=Ind|Polarity=Pos|Tense=Past|VerbForm=Part",
"",
"Case=Dat|Number=Sing|Number[psor]=Plur|Person=3|Person[psor]=2",
"Aspect=Perf|Case=Loc|Mood=Ind|Number[psor]=Plur|Person[psor]=2|Polarity=Pos|Tense=Past|VerbForm=Part",
"",
"",
"Case=Dat|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Evident=Nfh|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
"",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3|Reflex=Yes",
"Case=Dat|Number=Sing|Number[psor]=Plur|Person=3|Person[psor]=2",
"",
"",
"Case=Acc|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=2",
"Aspect=Perf|Evident=Nfh|Mood=Ind|Polarity=Pos|Tense=Past|VerbForm=Part",
"Aspect=Hab|Mood=Ind|Number=Plur|Person=2|Polarity=Pos|Tense=Pres",
""
],
"head": [
"2",
"9",
"2",
"5",
"9",
"5",
"8",
"9",
"0",
"9",
"18",
"13",
"17",
"13",
"16",
"17",
"18",
"9",
"18"
],
"deprel": [
"obl",
"acl",
"case",
"obl",
"acl",
"punct",
"amod",
"nmod",
"root",
"compound:lvc",
"cc",
"nmod",
"obl",
"case",
"det",
"obj",
"acl",
"conj",
"punct"
],
"start_char": [
0,
12,
23,
29,
38,
50,
52,
57,
65,
72,
78,
81,
87,
99,
104,
109,
128,
138,
147
],
"end_char": [
11,
22,
28,
37,
50,
51,
56,
64,
71,
77,
80,
86,
98,
103,
108,
127,
137,
147,
148
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"BAD",
"BAD",
"OK"
] | [
"OK",
"OK",
"OK",
"BAD",
"OK",
"BAD",
"OK",
"OK",
"BAD",
"OK",
"OK",
"BAD",
"OK",
"OK",
"BAD",
"OK",
"OK"
] |
flores101-main-tur-100-pe1-4 | 897 | flores101-main-1004 | tur_t1 | tur | 100 | pe1 | pe | 134 | 145 | 166 | 22 | 18 | 20 | 35.672 | 85 | 38 | 0 | 6 | 1 | 34 | 6 | 0 | 0 | 0 | 0 | 8 | 29,203 | 5 | 27,197 | 35,672 | 1 | 1,643,315,008 | 4 | 2 | 2 | 1 | 1 | 9 | 45 | 0.3265 | 37.96 | 71.92 | 35.672 | 0.5945 | 0.0099 | 0.2662 | 1.6215 | 0.6343 | 2,220.2288 | 37.0038 | 12 | When you went abroad at first, people were probably patient and understanding, knowing that travellers in a new country need to adapt. | İlk başta yurt dışına çıktığınızda, insanlar yeni bir ülkedeki gezginlerin uyum sağlaması gerektiğini bilerek muhtemelen sabırlı ve anlayışlıydı. | Yurt dışına ilk çıktığınızda çevrenizdeki insanlar, yeni bir ülkeye gelen gezginlerin uyum sağlaması gerektiğini bilerek muhtemelen sabırlı ve anlayışlı davranıyordu. | REF: i̇lk başta yurt dışına *** çıktığınızda , ************ insanlar yeni bir ****** ülkedeki gezginlerin uyum sağlaması gerektiğini bilerek muhtemelen sabırlı ve ********* anlayışlıydı .\nHYP: **** ***** yurt dışına ilk çıktığınızda [ , ] çevrenizdeki insanlar @ yeni bir ülkeye gelen gezginlerin uyum sağlaması gerektiğini bilerek muhtemelen sabırlı ve anlayışlı davranıyordu .\nEVAL: D D I I I S I S | [
"When",
"you",
"went",
"abroad",
"at",
"first",
",",
"people",
"were",
"probably",
"patient",
"and",
"understanding",
",",
"knowing",
"that",
"travellers",
"in",
"a",
"new",
"country",
"need",
"to",
"adapt",
"."
] | {
"lemma": [
"when",
"you",
"go",
"abroad",
"at",
"first",
",",
"people",
"be",
"probably",
"patient",
"and",
"understanding",
",",
"know",
"that",
"traveller",
"in",
"a",
"new",
"country",
"need",
"to",
"adapt",
"."
],
"upos": [
"SCONJ",
"PRON",
"VERB",
"ADV",
"ADP",
"ADV",
"PUNCT",
"NOUN",
"AUX",
"ADV",
"ADJ",
"CCONJ",
"NOUN",
"PUNCT",
"VERB",
"SCONJ",
"NOUN",
"ADP",
"DET",
"ADJ",
"NOUN",
"VERB",
"PART",
"VERB",
"PUNCT"
],
"feats": [
"PronType=Int",
"Case=Nom|Person=2|PronType=Prs",
"Mood=Ind|Number=Sing|Person=2|Tense=Past|VerbForm=Fin",
"",
"",
"NumType=Ord",
"",
"Number=Plur",
"Mood=Ind|Number=Plur|Person=3|Tense=Past|VerbForm=Fin",
"",
"Degree=Pos",
"",
"Number=Sing",
"",
"VerbForm=Ger",
"",
"Number=Plur",
"",
"Definite=Ind|PronType=Art",
"Degree=Pos",
"Number=Sing",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"",
"VerbForm=Inf",
""
],
"head": [
"3",
"3",
"11",
"3",
"6",
"3",
"11",
"11",
"11",
"11",
"0",
"13",
"11",
"15",
"11",
"22",
"22",
"21",
"21",
"21",
"17",
"15",
"24",
"22",
"11"
],
"deprel": [
"mark",
"nsubj",
"advcl",
"advmod",
"case",
"obl",
"punct",
"nsubj",
"cop",
"advmod",
"root",
"cc",
"conj",
"punct",
"advcl",
"mark",
"nsubj",
"case",
"det",
"amod",
"nmod",
"ccomp",
"mark",
"xcomp",
"punct"
],
"start_char": [
0,
5,
9,
14,
21,
24,
29,
31,
38,
43,
52,
60,
64,
77,
79,
87,
92,
103,
106,
108,
112,
120,
125,
128,
133
],
"end_char": [
4,
8,
13,
20,
23,
29,
30,
37,
42,
51,
59,
63,
77,
78,
86,
91,
102,
105,
107,
111,
119,
124,
127,
133,
134
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"S-ORDINAL",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"İlk",
"başta",
"yurt",
"dışına",
"çıktığınızda",
",",
"insanlar",
"yeni",
"bir",
"ülkedeki",
"gezginlerin",
"uyum",
"sağlaması",
"gerektiğini",
"bilerek",
"muhtemelen",
"sabırlı",
"ve",
"anlayışlıydı",
"."
] | {
"lemma": [
"ilk",
"başta",
"yurt",
"dış",
"çık",
",",
"insan",
"yeni",
"bir",
"ülke+ki",
"gezgin",
"uyum",
"sağla",
"gerek",
"bil",
"muhtemelen",
"sabır+li",
"ve",
"anlayışlı+i",
"."
],
"upos": [
"ADJ",
"ADV",
"NOUN",
"ADJ",
"VERB",
"PUNCT",
"NOUN",
"ADJ",
"DET",
"NOUN+ADP",
"NOUN",
"NOUN",
"VERB",
"VERB",
"VERB",
"ADV",
"NOUN+ADP",
"CCONJ",
"ADJ+AUX",
"PUNCT"
],
"feats": [
"",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Loc|Mood=Ind|Number[psor]=Plur|Person[psor]=2|Polarity=Pos|Tense=Past|VerbForm=Part",
"",
"Case=Nom|Number=Plur|Person=3",
"",
"Definite=Ind|PronType=Art",
"Case=Loc|Number=Sing|Person=3+",
"Case=Gen|Number=Plur|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Aspect=Perf|Case=Acc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Conv",
"",
"Case=Nom|Number=Sing|Person=3+",
"",
"Case=Nom|Number=Sing|Person=3+Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Tense=Past",
""
],
"head": [
"4",
"5",
"4",
"5",
"16",
"5",
"15",
"10",
"10",
"12+10",
"14",
"14",
"15",
"5",
"21",
"18",
"21+18",
"21",
"0+21",
"21"
],
"deprel": [
"amod",
"advmod",
"nmod:poss",
"amod",
"acl",
"punct",
"nsubj",
"amod",
"det",
"nmod+case",
"nmod:poss",
"obj",
"obj",
"conj",
"nmod",
"advmod",
"obl+case",
"cc",
"root+cop",
"punct"
],
"start_char": [
0,
4,
10,
15,
22,
34,
36,
45,
50,
54,
63,
75,
80,
90,
102,
110,
121,
129,
132,
144
],
"end_char": [
3,
9,
14,
21,
34,
35,
44,
49,
53,
62,
74,
79,
89,
101,
109,
120,
128,
131,
144,
145
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Yurt",
"dışına",
"ilk",
"çıktığınızda",
"çevrenizdeki",
"insanlar",
",",
"yeni",
"bir",
"ülkeye",
"gelen",
"gezginlerin",
"uyum",
"sağlaması",
"gerektiğini",
"bilerek",
"muhtemelen",
"sabırlı",
"ve",
"anlayışlı",
"davranıyordu",
"."
] | {
"lemma": [
"yurt",
"dış",
"ilk",
"çık",
"çevre+ki",
"insan",
",",
"yeni",
"bir",
"ülke",
"gel",
"gezgin",
"uyum",
"sağla",
"gerek",
"bil",
"muhtemelen",
"sabır+li",
"ve",
"anlayışlı",
"davran",
"."
],
"upos": [
"NOUN",
"NOUN",
"ADV",
"VERB",
"NOUN+ADP",
"NOUN",
"PUNCT",
"ADJ",
"DET",
"NOUN",
"VERB",
"NOUN",
"NOUN",
"VERB",
"VERB",
"VERB",
"ADV",
"NOUN+ADP",
"CCONJ",
"ADJ",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Aspect=Perf|Case=Loc|Mood=Ind|Number[psor]=Plur|Person[psor]=2|Polarity=Pos|Tense=Past|VerbForm=Part",
"Case=Loc|Number=Sing|Number[psor]=Plur|Person=3|Person[psor]=1+",
"Case=Nom|Number=Plur|Person=3",
"",
"",
"Definite=Ind|PronType=Art",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Gen|Number=Plur|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Aspect=Perf|Case=Acc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Conv",
"",
"Case=Nom|Number=Sing|Person=3+",
"",
"",
"Aspect=Prog|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Polite=Infm|Tense=Past",
""
],
"head": [
"2",
"4",
"4",
"7",
"7+5",
"17",
"7",
"11",
"11",
"12",
"13",
"16",
"16",
"14",
"17",
"23",
"23",
"23+19",
"22",
"19",
"0",
"23"
],
"deprel": [
"nmod:poss",
"obl",
"advmod",
"acl",
"nmod+case",
"nsubj",
"punct",
"amod",
"det",
"obl",
"acl",
"nmod:poss",
"obj",
"compound:lvc",
"obj",
"nmod",
"advmod",
"obl+case",
"cc",
"conj",
"root",
"punct"
],
"start_char": [
0,
5,
12,
16,
29,
42,
50,
52,
57,
61,
68,
74,
86,
91,
101,
113,
121,
132,
140,
143,
153,
165
],
"end_char": [
4,
11,
15,
28,
41,
50,
51,
56,
60,
67,
73,
85,
90,
100,
112,
120,
131,
139,
142,
152,
165,
166
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"OK",
"BAD",
"OK",
"BAD",
"BAD",
"OK",
"BAD",
"OK",
"OK",
"OK",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK"
] | [
"BAD",
"BAD",
"BAD",
"OK",
"BAD",
"BAD",
"OK",
"BAD",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK"
] |
flores101-main-tur-100-pe1-5 | 898 | flores101-main-1005 | tur_t1 | tur | 100 | pe1 | pe | 107 | 89 | 94 | 15 | 13 | 11 | 27.431 | 109 | 75 | 0 | 10 | 1 | 20 | 3 | 0 | 0 | 0 | 0 | 9 | 17,903 | 7 | 16,844 | 27,431 | 1 | 1,643,315,008 | 1 | 2 | 7 | 1 | 1 | 11 | 78.571 | 0.6833 | 7.47 | 44.74 | 27.431 | 0.4572 | 0.0076 | 0.2564 | 1.8287 | 1.0187 | 1,968.5757 | 32.8096 | 13 | People may not anticipate that patience and understanding are also necessary for travellers returning home. | İnsanlar bu sabır tahmin edemeyeceğiniz ve anlayış da eve dönen yolcular için gereklidir. | İnsanlar, ülkesine dönenlere de sabır ve anlayış gösterilmesi gerektiğini tahmin edemeyebilir. | REF: i̇nsanlar * bu sabır tahmin edemeyeceğiniz ve anlayış da eve dönen yolcular için gereklidir .\nHYP: i̇nsanlar , ülkesine [ sabır ] dönenlere de @ ve anlayış ** *** gösterilmesi gerektiğini tahmin edemeyebilir .\nEVAL: I S S S D D S S S S | [
"People",
"may",
"not",
"anticipate",
"that",
"patience",
"and",
"understanding",
"are",
"also",
"necessary",
"for",
"travellers",
"returning",
"home",
"."
] | {
"lemma": [
"person",
"may",
"not",
"anticipate",
"that",
"patience",
"and",
"understanding",
"be",
"also",
"necessary",
"for",
"traveller",
"return",
"home",
"."
],
"upos": [
"NOUN",
"AUX",
"PART",
"VERB",
"SCONJ",
"NOUN",
"CCONJ",
"NOUN",
"AUX",
"ADV",
"ADJ",
"SCONJ",
"NOUN",
"VERB",
"ADV",
"PUNCT"
],
"feats": [
"Number=Plur",
"VerbForm=Fin",
"",
"VerbForm=Inf",
"",
"Number=Sing",
"",
"Number=Sing",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Degree=Pos",
"",
"Number=Plur",
"VerbForm=Ger",
"",
""
],
"head": [
"4",
"4",
"4",
"0",
"11",
"11",
"8",
"6",
"11",
"11",
"4",
"14",
"11",
"13",
"14",
"4"
],
"deprel": [
"nsubj",
"aux",
"advmod",
"root",
"mark",
"nsubj",
"cc",
"conj",
"cop",
"advmod",
"ccomp",
"mark",
"obl",
"acl",
"advmod",
"punct"
],
"start_char": [
0,
7,
11,
15,
26,
31,
40,
44,
58,
62,
67,
77,
81,
92,
102,
106
],
"end_char": [
6,
10,
14,
25,
30,
39,
43,
57,
61,
66,
76,
80,
91,
101,
106,
107
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"İnsanlar",
"bu",
"sabır",
"tahmin",
"edemeyeceğiniz",
"ve",
"anlayış",
"da",
"eve",
"dönen",
"yolcular",
"için",
"gereklidir",
"."
] | {
"lemma": [
"insan",
"bu",
"sabır",
"tahmin",
"et",
"ve",
"anlayış",
"da",
"ev",
"dön",
"yolcu",
"için",
"gerekli+i",
"."
],
"upos": [
"NOUN",
"DET",
"NOUN",
"NOUN",
"VERB",
"CCONJ",
"NOUN",
"CCONJ",
"NOUN",
"VERB",
"NOUN",
"ADP",
"ADJ+AUX",
"PUNCT"
],
"feats": [
"Case=Nom|Number=Plur|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Pot|Number[psor]=Plur|Person[psor]=2|Polarity=Neg|Tense=Fut|VerbForm=Part",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Nom|Number=Plur|Person=3",
"",
"Case=Nom|Number=Sing|Person=3+Aspect=Perf|Mood=Gen|Number=Sing|Person=3|Tense=Pres",
""
],
"head": [
"13",
"3",
"4",
"13",
"4",
"10",
"10",
"7",
"10",
"11",
"13",
"11",
"0+13",
"13"
],
"deprel": [
"nsubj",
"det",
"nmod",
"obl",
"compound:lvc",
"cc",
"nsubj",
"advmod:emph",
"obl",
"acl",
"obl",
"case",
"root+cop",
"punct"
],
"start_char": [
0,
9,
12,
18,
25,
40,
43,
51,
54,
58,
64,
73,
78,
88
],
"end_char": [
8,
11,
17,
24,
39,
42,
50,
53,
57,
63,
72,
77,
88,
89
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"İnsanlar",
",",
"ülkesine",
"dönenlere",
"de",
"sabır",
"ve",
"anlayış",
"gösterilmesi",
"gerektiğini",
"tahmin",
"edemeyebilir",
"."
] | {
"lemma": [
"insan",
",",
"ülke",
"dön",
"de",
"sabır",
"ve",
"anlayış",
"göster",
"gerek",
"tahmin",
"et",
"."
],
"upos": [
"NOUN",
"PUNCT",
"NOUN",
"VERB",
"CCONJ",
"NOUN",
"CCONJ",
"NOUN",
"VERB",
"VERB",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|Number=Plur|Person=3",
"",
"Case=Dat|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Dat|Mood=Ind|Number=Plur|Person=3|Polarity=Pos|Tense=Pres|VerbForm=Part",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun|Voice=Pass",
"Aspect=Perf|Case=Acc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Hab|Mood=Pot|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"11",
"1",
"4",
"9",
"4",
"9",
"8",
"6",
"10",
"11",
"0",
"11",
"11"
],
"deprel": [
"nsubj",
"punct",
"obl",
"acl",
"advmod:emph",
"obl",
"cc",
"conj",
"nmod",
"obj",
"root",
"compound:lvc",
"punct"
],
"start_char": [
0,
8,
10,
19,
29,
32,
38,
41,
49,
62,
74,
81,
93
],
"end_char": [
8,
9,
18,
28,
31,
37,
40,
48,
61,
73,
80,
93,
94
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"BAD",
"OK",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"BAD",
"BAD",
"BAD",
"OK",
"BAD",
"BAD",
"BAD",
"BAD"
] | [
"OK",
"BAD",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"BAD",
"BAD",
"BAD",
"BAD",
"BAD",
"BAD",
"OK",
"OK"
] |
flores101-main-tur-101-pe2-1 | 18 | flores101-main-1011 | tur_t1 | tur | 101 | pe2 | pe | 117 | 110 | 121 | 18 | 15 | 16 | 35.119 | 87 | 37 | 0 | 4 | 1 | 36 | 4 | 0 | 3 | 2 | 0 | 8 | 30,031 | 7 | 29,228 | 35,119 | 1 | 1,643,316,280 | 2 | 1 | 2 | 1 | 2 | 6 | 31.579 | 0.3553 | 34.36 | 74.71 | 35.119 | 0.5853 | 0.0098 | 0.3002 | 1.9511 | 0.7436 | 1,845.155 | 30.7526 | 14 | Throughout 1960s, Brzezinski worked for John F. Kennedy as his advisor and then the Lyndon B. Johnson administration. | 1960'larda Brzezinski, danışmanı olarak John F. Kennedy ve ardından da Lyndon B. Johnson yönetiminde çalışmış. | 1960'larda Brzezinski, John F. Kennedy'nin danışmanı olarak çalıştı ve ardından Lyndon B. Johnson yönetiminde görev aldı. | REF: 1960'larda brzezinski , danışmanı olarak john f . *********** kennedy ve ardından da lyndon b . johnson yönetiminde ***** çalışmış .\nHYP: 1960'larda brzezinski , [ danışmanı olarak ] john f . kennedy'nin @ çalıştı ve ardından ** lyndon b . johnson yönetiminde görev aldı .\nEVAL: I S D I S | [
"Throughout",
"1960s",
",",
"Brzezinski",
"worked",
"for",
"John",
"F.",
"Kennedy",
"as",
"his",
"advisor",
"and",
"then",
"the",
"Lyndon",
"B.",
"Johnson",
"administration",
"."
] | {
"lemma": [
"throughout",
"1960",
",",
"Brzezinski",
"work",
"for",
"John",
"F.",
"Kennedy",
"as",
"he",
"advisor",
"and",
"then",
"the",
"Lyndon",
"B.",
"Johnson",
"administration",
"."
],
"upos": [
"ADP",
"NOUN",
"PUNCT",
"PROPN",
"VERB",
"ADP",
"PROPN",
"PROPN",
"PROPN",
"ADP",
"PRON",
"NOUN",
"CCONJ",
"ADV",
"DET",
"PROPN",
"PROPN",
"PROPN",
"NOUN",
"PUNCT"
],
"feats": [
"",
"Number=Plur",
"",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"",
"Number=Sing",
"Number=Sing",
"Number=Sing",
"",
"Gender=Masc|Number=Sing|Person=3|Poss=Yes|PronType=Prs",
"Number=Sing",
"",
"PronType=Dem",
"Definite=Def|PronType=Art",
"Number=Sing",
"Number=Sing",
"Number=Sing",
"Number=Sing",
""
],
"head": [
"2",
"5",
"2",
"5",
"0",
"7",
"5",
"7",
"7",
"12",
"12",
"5",
"19",
"19",
"19",
"19",
"16",
"16",
"12",
"5"
],
"deprel": [
"case",
"obl",
"punct",
"nsubj",
"root",
"case",
"obl",
"flat",
"flat",
"case",
"nmod:poss",
"obl",
"cc",
"advmod",
"det",
"compound",
"flat",
"flat",
"conj",
"punct"
],
"start_char": [
0,
11,
16,
18,
29,
36,
40,
45,
48,
56,
59,
63,
71,
75,
80,
84,
91,
94,
102,
116
],
"end_char": [
10,
16,
17,
28,
35,
39,
44,
47,
55,
58,
62,
70,
74,
79,
83,
90,
93,
101,
116,
117
],
"ner": [
"O",
"S-DATE",
"O",
"S-PERSON",
"O",
"O",
"B-PERSON",
"I-PERSON",
"E-PERSON",
"O",
"O",
"O",
"O",
"O",
"O",
"B-PERSON",
"I-PERSON",
"E-PERSON",
"O",
"O"
]
} | [
"1960'larda",
"Brzezinski",
",",
"danışmanı",
"olarak",
"John",
"F",
".",
"Kennedy",
"ve",
"ardından",
"da",
"Lyndon",
"B",
".",
"Johnson",
"yönetiminde",
"çalışmış",
"."
] | {
"lemma": [
"1960",
"Brzezinski",
",",
"danışman",
"olarak",
"John",
"\"",
".",
"Kennedy",
"ve",
"ardından",
"da",
"Lyndon",
"b",
".",
"Johnson",
"yönetim",
"çalış",
"."
],
"upos": [
"PROPN",
"PROPN",
"PUNCT",
"NOUN",
"ADP",
"PROPN",
"PROPN",
"PUNCT",
"PROPN",
"CCONJ",
"ADV",
"CCONJ",
"PROPN",
"NOUN",
"PUNCT",
"PROPN",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Loc|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Evident=Nfh|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
""
],
"head": [
"6",
"6",
"2",
"6",
"4",
"0",
"6",
"6",
"6",
"3",
"6",
"3",
"6",
"0",
"6",
"2",
"3",
"0",
"3"
],
"deprel": [
"nmod",
"nsubj",
"punct",
"nmod",
"case",
"root",
"flat",
"punct",
"nsubj",
"cc",
"advmod",
"advmod:emph",
"nsubj",
"root",
"punct",
"nmod:poss",
"obl",
"root",
"punct"
],
"start_char": [
0,
11,
21,
23,
33,
40,
45,
46,
48,
56,
59,
68,
71,
78,
79,
81,
89,
101,
109
],
"end_char": [
10,
21,
22,
32,
39,
44,
46,
47,
55,
58,
67,
70,
77,
79,
80,
88,
100,
109,
110
],
"ner": [
"S-TIME",
"S-ORGANIZATION",
"O",
"O",
"O",
"B-PERSON",
"E-PERSON",
"O",
"S-PERSON",
"O",
"O",
"O",
"B-ORGANIZATION",
"E-ORGANIZATION",
"O",
"S-PERSON",
"O",
"O",
"O"
]
} | [
"1960'larda",
"Brzezinski",
",",
"John",
"F",
".",
"Kennedy'nin",
"danışmanı",
"olarak",
"çalıştı",
"ve",
"ardından",
"Lyndon",
"B",
".",
"Johnson",
"yönetiminde",
"görev",
"aldı",
"."
] | {
"lemma": [
"1960",
"Brzezinski",
",",
"John",
"\"",
".",
"Kenned",
"danışman",
"olarak",
"çalış",
"ve",
"ardından",
"Lyndon",
"b",
".",
"Johnson",
"yönetim",
"görev",
"al",
"."
],
"upos": [
"ADJ",
"PROPN",
"PUNCT",
"PROPN",
"PROPN",
"PUNCT",
"PROPN",
"NOUN",
"ADP",
"VERB",
"CCONJ",
"ADV",
"PROPN",
"NOUN",
"PUNCT",
"PROPN",
"NOUN",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Loc|Number=Plur|Person=3",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Gen|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
""
],
"head": [
"2",
"0",
"2",
"2",
"4",
"4",
"2",
"4",
"2",
"0",
"6",
"4",
"8",
"4",
"4",
"2",
"4",
"4",
"0",
"4"
],
"deprel": [
"amod",
"root",
"punct",
"conj",
"flat",
"punct",
"nmod:poss",
"obl",
"case",
"root",
"cc",
"advmod",
"nsubj",
"obl",
"punct",
"nmod:poss",
"obl",
"obj",
"root",
"punct"
],
"start_char": [
0,
11,
21,
23,
28,
29,
31,
43,
53,
60,
68,
71,
80,
87,
88,
90,
98,
110,
116,
120
],
"end_char": [
10,
21,
22,
27,
29,
30,
42,
52,
59,
67,
70,
79,
86,
88,
89,
97,
109,
115,
120,
121
],
"ner": [
"S-TIME",
"S-PERSON",
"O",
"B-PERSON",
"E-PERSON",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O",
"B-ORGANIZATION",
"E-ORGANIZATION",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"BAD",
"BAD",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] | [
"OK",
"OK",
"OK",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK"
] |
flores101-main-tur-101-pe2-2 | 19 | flores101-main-1012 | tur_t1 | tur | 101 | pe2 | pe | 157 | 192 | 192 | 24 | 24 | 24 | 25.227 | 12 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 25,227 | 1 | 1,643,316,280 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 100 | 25.227 | 0.4204 | 0.007 | 0.1607 | 1.0511 | 0.0764 | 3,424.9019 | 57.0817 | 15 | During the 1976 selections he advised Carter on foreign policy, then served as National Security Advisor (NSA) from 1977 to 1981, succeeding Henry Kissinger. | 1976 seçimlerinde Carter'a dış politika konusunda danışmanlık yaptı, ardından da 1977-1981 yılları arasında Henry Kissinger'in yerini alarak Ulusal Güvenlik Danışmanı (NSA) olarak görev yaptı. | 1976 seçimlerinde Carter'a dış politika konusunda danışmanlık yaptı, ardından da 1977-1981 yılları arasında Henry Kissinger'in yerini alarak Ulusal Güvenlik Danışmanı (NSA) olarak görev yaptı. | REF: 1976 seçimlerinde carter'a dış politika konusunda danışmanlık yaptı , ardından da 1977 - 1981 yılları arasında henry kissinger'in yerini alarak ulusal güvenlik danışmanı ( nsa ) olarak görev yaptı .\nHYP: 1976 seçimlerinde carter'a dış politika konusunda danışmanlık yaptı , ardından da 1977 - 1981 yılları arasında henry kissinger'in yerini alarak ulusal güvenlik danışmanı ( nsa ) olarak görev yaptı .\nEVAL: | [
"During",
"the",
"1976",
"selections",
"he",
"advised",
"Carter",
"on",
"foreign",
"policy",
",",
"then",
"served",
"as",
"National",
"Security",
"Advisor",
"(",
"NSA",
")",
"from",
"1977",
"to",
"1981",
",",
"succeeding",
"Henry",
"Kissinger",
"."
] | {
"lemma": [
"during",
"the",
"1976",
"selection",
"he",
"advise",
"Carter",
"on",
"foreign",
"policy",
",",
"then",
"serve",
"as",
"National",
"Security",
"Advisor",
"(",
"NSA",
")",
"from",
"1977",
"to",
"1981",
",",
"succeed",
"Henry",
"Kissinger",
"."
],
"upos": [
"ADP",
"DET",
"NUM",
"NOUN",
"PRON",
"VERB",
"PROPN",
"ADP",
"ADJ",
"NOUN",
"PUNCT",
"ADV",
"VERB",
"ADP",
"ADJ",
"PROPN",
"PROPN",
"PUNCT",
"PROPN",
"PUNCT",
"ADP",
"NUM",
"ADP",
"NUM",
"PUNCT",
"VERB",
"PROPN",
"PROPN",
"PUNCT"
],
"feats": [
"",
"Definite=Def|PronType=Art",
"NumForm=Digit|NumType=Card",
"Number=Plur",
"Case=Nom|Gender=Masc|Number=Sing|Person=3|PronType=Prs",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"Number=Sing",
"",
"Degree=Pos",
"Number=Sing",
"",
"PronType=Dem",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"",
"Degree=Pos",
"Number=Sing",
"Number=Sing",
"",
"Number=Sing",
"",
"",
"NumForm=Digit|NumType=Card",
"",
"NumForm=Digit|NumType=Card",
"",
"VerbForm=Ger",
"Number=Sing",
"Number=Sing",
""
],
"head": [
"4",
"4",
"4",
"6",
"6",
"0",
"6",
"10",
"10",
"6",
"13",
"13",
"6",
"17",
"17",
"17",
"13",
"19",
"17",
"19",
"22",
"13",
"24",
"22",
"26",
"13",
"26",
"27",
"6"
],
"deprel": [
"case",
"det",
"compound",
"obl",
"nsubj",
"root",
"obj",
"case",
"amod",
"obl",
"punct",
"advmod",
"conj",
"case",
"amod",
"compound",
"obl",
"punct",
"appos",
"punct",
"case",
"obl",
"case",
"nmod",
"punct",
"advcl",
"obj",
"flat",
"punct"
],
"start_char": [
0,
7,
11,
16,
27,
30,
38,
45,
48,
56,
62,
64,
69,
76,
79,
88,
97,
105,
106,
109,
111,
116,
121,
124,
128,
130,
141,
147,
156
],
"end_char": [
6,
10,
15,
26,
29,
37,
44,
47,
55,
62,
63,
68,
75,
78,
87,
96,
104,
106,
109,
110,
115,
120,
123,
128,
129,
140,
146,
156,
157
],
"ner": [
"O",
"O",
"S-DATE",
"O",
"O",
"O",
"S-PERSON",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-ORG",
"O",
"O",
"B-DATE",
"I-DATE",
"E-DATE",
"O",
"O",
"B-PERSON",
"E-PERSON",
"O"
]
} | [
"1976",
"seçimlerinde",
"Carter'a",
"dış",
"politika",
"konusunda",
"danışmanlık",
"yaptı",
",",
"ardından",
"da",
"1977",
"-",
"1981",
"yılları",
"arasında",
"Henry",
"Kissinger'in",
"yerini",
"alarak",
"Ulusal",
"Güvenlik",
"Danışmanı",
"(",
"NSA",
")",
"olarak",
"görev",
"yaptı",
"."
] | {
"lemma": [
"1976",
"seçim",
"Carter",
"dış",
"politika",
"konu",
"danışmanlık",
"yap",
",",
"ardından",
"da",
"1977",
"-",
"1981",
"yıl",
"ara",
"Henry",
"Kissinger",
"yer",
"al",
"ulusal",
"güvenlik",
"danışman",
"(",
"NSA",
")",
"olarak",
"görev",
"yap",
"."
],
"upos": [
"NUM",
"NOUN",
"PROPN",
"ADJ",
"NOUN",
"NOUN",
"NOUN",
"VERB",
"PUNCT",
"ADV",
"CCONJ",
"NUM",
"PUNCT",
"NUM",
"NOUN",
"ADJ",
"PROPN",
"PROPN",
"NOUN",
"VERB",
"ADJ",
"NOUN",
"NOUN",
"PUNCT",
"NOUN",
"PUNCT",
"ADP",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|NumType=Card|Number=Sing|Person=3",
"Case=Loc|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Dat|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
"",
"",
"",
"Case=Nom|NumType=Card|Number=Sing|Person=3",
"",
"Case=Nom|NumType=Card|Number=Sing|Person=3",
"Case=Nom|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Sing|Person=3",
"Case=Acc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Conv",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
""
],
"head": [
"2",
"8",
"8",
"6",
"6",
"7",
"8",
"0",
"28",
"28",
"10",
"15",
"14",
"12",
"16",
"20",
"19",
"17",
"20",
"28",
"28",
"21",
"21",
"25",
"21",
"25",
"25",
"8",
"28",
"28"
],
"deprel": [
"nummod",
"obl",
"obl",
"amod",
"nmod:poss",
"nmod",
"obj",
"root",
"punct",
"advmod",
"advmod:emph",
"nmod:poss",
"punct",
"compound",
"nmod:poss",
"amod",
"nmod:poss",
"flat",
"obj",
"nmod",
"amod",
"flat",
"flat",
"punct",
"nmod",
"punct",
"case",
"conj",
"compound:lvc",
"punct"
],
"start_char": [
0,
5,
18,
27,
31,
40,
50,
62,
67,
69,
78,
81,
85,
86,
91,
99,
108,
114,
127,
134,
141,
148,
157,
167,
168,
171,
173,
180,
186,
191
],
"end_char": [
4,
17,
26,
30,
39,
49,
61,
67,
68,
77,
80,
85,
86,
90,
98,
107,
113,
126,
133,
140,
147,
156,
166,
168,
171,
172,
179,
185,
191,
192
],
"ner": [
"S-TIME",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-TIME",
"O",
"B-TIME",
"E-TIME",
"O",
"B-PERSON",
"E-PERSON",
"O",
"O",
"B-ORGANIZATION",
"I-ORGANIZATION",
"E-ORGANIZATION",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O"
]
} | [
"1976",
"seçimlerinde",
"Carter'a",
"dış",
"politika",
"konusunda",
"danışmanlık",
"yaptı",
",",
"ardından",
"da",
"1977",
"-",
"1981",
"yılları",
"arasında",
"Henry",
"Kissinger'in",
"yerini",
"alarak",
"Ulusal",
"Güvenlik",
"Danışmanı",
"(",
"NSA",
")",
"olarak",
"görev",
"yaptı",
"."
] | {
"lemma": [
"1976",
"seçim",
"Carter",
"dış",
"politika",
"konu",
"danışmanlık",
"yap",
",",
"ardından",
"da",
"1977",
"-",
"1981",
"yıl",
"ara",
"Henry",
"Kissinger",
"yer",
"al",
"ulusal",
"güvenlik",
"danışman",
"(",
"NSA",
")",
"olarak",
"görev",
"yap",
"."
],
"upos": [
"NUM",
"NOUN",
"PROPN",
"ADJ",
"NOUN",
"NOUN",
"NOUN",
"VERB",
"PUNCT",
"ADV",
"CCONJ",
"NUM",
"PUNCT",
"NUM",
"NOUN",
"ADJ",
"PROPN",
"PROPN",
"NOUN",
"VERB",
"ADJ",
"NOUN",
"NOUN",
"PUNCT",
"NOUN",
"PUNCT",
"ADP",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|NumType=Card|Number=Sing|Person=3",
"Case=Loc|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Dat|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
"",
"",
"",
"Case=Nom|NumType=Card|Number=Sing|Person=3",
"",
"Case=Nom|NumType=Card|Number=Sing|Person=3",
"Case=Nom|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Sing|Person=3",
"Case=Acc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Conv",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
""
],
"head": [
"2",
"8",
"8",
"6",
"6",
"7",
"8",
"0",
"28",
"28",
"10",
"15",
"14",
"12",
"16",
"20",
"19",
"17",
"20",
"28",
"28",
"21",
"21",
"25",
"21",
"25",
"25",
"8",
"28",
"28"
],
"deprel": [
"nummod",
"obl",
"obl",
"amod",
"nmod:poss",
"nmod",
"obj",
"root",
"punct",
"advmod",
"advmod:emph",
"nmod:poss",
"punct",
"compound",
"nmod:poss",
"amod",
"nmod:poss",
"flat",
"obj",
"nmod",
"amod",
"flat",
"flat",
"punct",
"nmod",
"punct",
"case",
"conj",
"compound:lvc",
"punct"
],
"start_char": [
0,
5,
18,
27,
31,
40,
50,
62,
67,
69,
78,
81,
85,
86,
91,
99,
108,
114,
127,
134,
141,
148,
157,
167,
168,
171,
173,
180,
186,
191
],
"end_char": [
4,
17,
26,
30,
39,
49,
61,
67,
68,
77,
80,
85,
86,
90,
98,
107,
113,
126,
133,
140,
147,
156,
166,
168,
171,
172,
179,
185,
191,
192
],
"ner": [
"S-TIME",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-TIME",
"O",
"B-TIME",
"E-TIME",
"O",
"B-PERSON",
"E-PERSON",
"O",
"O",
"B-ORGANIZATION",
"I-ORGANIZATION",
"E-ORGANIZATION",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] |
flores101-main-tur-101-pe2-3 | 20 | flores101-main-1013 | tur_t1 | tur | 101 | pe2 | pe | 275 | 272 | 285 | 42 | 34 | 35 | 102.685 | 96 | 21 | 4 | 2 | 1 | 66 | 2 | 0 | 0 | 0 | 0 | 7 | 98,893 | 4 | 96,966 | 102,685 | 2 | 1,643,316,280 | 2 | 1 | 3 | 0 | 0 | 6 | 15.385 | 0.0963 | 68.52 | 88.15 | 102.685 | 1.7114 | 0.0285 | 0.3734 | 2.4449 | 0.3491 | 1,472.4643 | 24.5411 | 16 | As NSA, he assisted Carter in diplomatically handling world affairs, such as the Camp David Accords, 1978; normalizing US–China relations thought the late 1970s; the Iranian Revolution, which led to the Iran hostage crisis, 1979; and the Soviet invasion in Afghanistan, 1979. | NSA olarak Carter'a Camp David Anlaşmaları 1978, 1970'lerin sonlarında ABD-Çin ilişkilerinin normale döndürülmesi, 1979'da İran'da rehin krizine yol açan İran Devrimi ve 1979'da Afganistan'a Sovyet işgali gibi dünya meselelerini diplomatik olarak yönetmede yardım etmişti. | NSA olarak Carter'a 1978'deki Camp David Anlaşmaları, 1970'lerin sonlarında ABD-Çin ilişkilerinin normale döndürülmesi, 1979'da İran'da rehin krizine yol açan İran Devrimi ve 1979'da Afganistan'daki Sovyet işgali gibi dünya meselelerini diplomatik olarak yönetme konusunda yardım etti. | REF: nsa olarak carter'a ********* camp david anlaşmaları 1978 , 1970'lerin sonlarında abd - çin ilişkilerinin normale döndürülmesi , 1979'da i̇ran'da rehin krizine yol açan i̇ran devrimi ve 1979'da afganistan'a sovyet işgali gibi dünya meselelerini diplomatik olarak ******* yönetmede yardım etmişti .\nHYP: nsa olarak carter'a 1978'deki camp david anlaşmaları **** , 1970'lerin sonlarında abd - çin ilişkilerinin normale döndürülmesi , 1979'da i̇ran'da rehin krizine yol açan i̇ran devrimi ve 1979'da afganistan'daki sovyet işgali gibi dünya meselelerini diplomatik olarak yönetme konusunda yardım etti .\nEVAL: I D S I S S | [
"As",
"NSA",
",",
"he",
"assisted",
"Carter",
"in",
"diplomatically",
"handling",
"world",
"affairs",
",",
"such",
"as",
"the",
"Camp",
"David",
"Accords",
",",
"1978",
";",
"normalizing",
"US–China",
"relations",
"thought",
"the",
"late",
"1970s",
";",
"the",
"Iranian",
"Revolution",
",",
"which",
"led",
"to",
"the",
"Iran",
"hostage",
"crisis",
",",
"1979",
";",
"and",
"the",
"Soviet",
"invasion",
"in",
"Afghanistan",
",",
"1979",
"."
] | {
"lemma": [
"as",
"NSA",
",",
"he",
"assist",
"Carter",
"in",
"diplomatically",
"handle",
"world",
"affair",
",",
"such",
"as",
"the",
"Camp",
"David",
"Accord",
",",
"1978",
";",
"normalize",
"US–China",
"relation",
"think",
"the",
"late",
"1970",
";",
"the",
"Iranian",
"Revolution",
",",
"which",
"lead",
"to",
"the",
"Iran",
"hostage",
"crisis",
",",
"1979",
";",
"and",
"the",
"Soviet",
"invasion",
"in",
"Afghanistan",
",",
"1979",
"."
],
"upos": [
"ADP",
"PROPN",
"PUNCT",
"PRON",
"VERB",
"PROPN",
"SCONJ",
"ADV",
"VERB",
"NOUN",
"NOUN",
"PUNCT",
"ADJ",
"ADP",
"DET",
"PROPN",
"PROPN",
"PROPN",
"PUNCT",
"NUM",
"PUNCT",
"VERB",
"PROPN",
"NOUN",
"VERB",
"DET",
"ADJ",
"NOUN",
"PUNCT",
"DET",
"ADJ",
"PROPN",
"PUNCT",
"PRON",
"VERB",
"ADP",
"DET",
"PROPN",
"NOUN",
"NOUN",
"PUNCT",
"NUM",
"PUNCT",
"CCONJ",
"DET",
"PROPN",
"NOUN",
"ADP",
"PROPN",
"PUNCT",
"NUM",
"PUNCT"
],
"feats": [
"",
"Number=Sing",
"",
"Case=Nom|Gender=Masc|Number=Sing|Person=3|PronType=Prs",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"Number=Sing",
"",
"",
"VerbForm=Ger",
"Number=Sing",
"Number=Plur",
"",
"Degree=Pos|ExtPos=ADP",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"Number=Sing",
"Number=Sing",
"",
"NumForm=Digit|NumType=Card",
"",
"VerbForm=Ger",
"Number=Sing",
"Number=Plur",
"Mood=Ind|Number=Plur|Person=3|Tense=Past|VerbForm=Fin",
"Definite=Def|PronType=Art",
"Degree=Pos",
"Number=Plur",
"",
"Definite=Def|PronType=Art",
"Degree=Pos",
"Number=Sing",
"",
"PronType=Rel",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"Number=Sing",
"Number=Sing",
"",
"NumForm=Digit|NumType=Card",
"",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"Number=Sing",
"",
"Number=Sing",
"",
"NumForm=Digit|NumType=Card",
""
],
"head": [
"2",
"5",
"2",
"5",
"0",
"5",
"9",
"9",
"5",
"11",
"9",
"18",
"18",
"13",
"18",
"18",
"18",
"11",
"20",
"18",
"5",
"25",
"24",
"25",
"5",
"28",
"28",
"25",
"32",
"32",
"32",
"28",
"32",
"35",
"32",
"40",
"40",
"40",
"40",
"35",
"42",
"40",
"47",
"47",
"47",
"47",
"40",
"49",
"47",
"51",
"49",
"5"
],
"deprel": [
"case",
"obl",
"punct",
"nsubj",
"root",
"obj",
"mark",
"advmod",
"advcl",
"compound",
"obj",
"punct",
"case",
"fixed",
"det",
"compound",
"compound",
"nmod",
"punct",
"nmod:tmod",
"punct",
"advcl",
"compound",
"nsubj",
"parataxis",
"det",
"amod",
"obj",
"punct",
"det",
"amod",
"appos",
"punct",
"nsubj",
"acl:relcl",
"case",
"det",
"compound",
"compound",
"obl",
"punct",
"nmod:tmod",
"punct",
"cc",
"det",
"compound",
"conj",
"case",
"nmod",
"punct",
"nmod:tmod",
"punct"
],
"start_char": [
0,
3,
6,
8,
11,
20,
27,
30,
45,
54,
60,
67,
69,
74,
77,
81,
86,
92,
99,
101,
105,
107,
119,
128,
138,
146,
150,
155,
160,
162,
166,
174,
184,
186,
192,
196,
199,
203,
208,
216,
222,
224,
228,
230,
234,
238,
245,
254,
257,
268,
270,
274
],
"end_char": [
2,
6,
7,
10,
19,
26,
29,
44,
53,
59,
67,
68,
73,
76,
80,
85,
91,
99,
100,
105,
106,
118,
127,
137,
145,
149,
154,
160,
161,
165,
173,
184,
185,
191,
195,
198,
202,
207,
215,
222,
223,
228,
229,
233,
237,
244,
253,
256,
268,
269,
274,
275
],
"ner": [
"O",
"S-ORG",
"O",
"O",
"O",
"S-PERSON",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"B-LAW",
"I-LAW",
"I-LAW",
"E-LAW",
"O",
"S-DATE",
"O",
"O",
"S-NORP",
"O",
"O",
"B-DATE",
"I-DATE",
"E-DATE",
"O",
"B-EVENT",
"I-EVENT",
"E-EVENT",
"O",
"O",
"O",
"O",
"O",
"S-GPE",
"O",
"O",
"O",
"S-DATE",
"O",
"O",
"O",
"S-NORP",
"O",
"O",
"S-GPE",
"O",
"S-DATE",
"O"
]
} | [
"NSA",
"olarak",
"Carter'a",
"Camp",
"David",
"Anlaşmaları",
"1978",
",",
"1970'lerin",
"sonlarında",
"ABD",
"-",
"Çin",
"ilişkilerinin",
"normale",
"döndürülmesi",
",",
"1979'da",
"İran'da",
"rehin",
"krizine",
"yol",
"açan",
"İran",
"Devrimi",
"ve",
"1979'da",
"Afganistan'a",
"Sovyet",
"işgali",
"gibi",
"dünya",
"meselelerini",
"diplomatik",
"olarak",
"yönetmede",
"yardım",
"etmişti",
"."
] | {
"lemma": [
"NSA",
"olarak",
"Carter",
"Camp",
"David",
"anlaşma",
"1978",
",",
"1970",
"son",
"Abd",
"-",
"Çin",
"ilişki",
"normal",
"dön",
",",
"1979",
"İran",
"rehin",
"kriz",
"yol",
"aç",
"İran",
"devrimi",
"ve",
"1979",
"Afganistan",
"Sovyet",
"işgal",
"gibi",
"dünya",
"mesele",
"diplomatik",
"olarak",
"yöne",
"yardım",
"et",
"."
],
"upos": [
"NOUN",
"ADP",
"PROPN",
"PROPN",
"PROPN",
"NOUN",
"NUM",
"PUNCT",
"PROPN",
"NOUN",
"NOUN",
"PUNCT",
"PROPN",
"NOUN",
"NOUN",
"VERB",
"PUNCT",
"NUM",
"PROPN",
"NOUN",
"NOUN",
"NOUN",
"VERB",
"PROPN",
"NOUN",
"CCONJ",
"NUM",
"PROPN",
"PROPN",
"NOUN",
"ADP",
"NOUN",
"NOUN",
"ADJ",
"ADP",
"VERB",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"",
"Case=Dat|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|NumType=Card|Number=Sing|Person=3",
"",
"Case=Gen|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun|Voice=Pass",
"",
"Case=Loc|NumType=Card|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Loc|NumType=Card|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Acc|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"",
"Aspect=Perf|Case=Loc|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Pqp",
""
],
"head": [
"6",
"1",
"6",
"6",
"4",
"7",
"14",
"7",
"7",
"16",
"14",
"13",
"11",
"16",
"16",
"37",
"16",
"22",
"22",
"21",
"22",
"24",
"22",
"37",
"24",
"30",
"36",
"36",
"30",
"36",
"30",
"33",
"36",
"36",
"34",
"37",
"0",
"37",
"37"
],
"deprel": [
"nmod",
"case",
"nmod",
"nmod:poss",
"flat",
"nmod",
"nmod:poss",
"punct",
"conj",
"obl",
"nmod:poss",
"punct",
"conj",
"nmod:poss",
"obl",
"nsubj",
"punct",
"nummod",
"nmod",
"nmod:poss",
"nmod",
"nmod",
"compound",
"nsubj",
"flat",
"cc",
"nummod",
"obl",
"nmod:poss",
"obl",
"case",
"nmod:poss",
"obj",
"amod",
"case",
"nmod",
"root",
"compound:lvc",
"punct"
],
"start_char": [
0,
4,
11,
20,
25,
31,
43,
47,
49,
60,
71,
74,
75,
79,
93,
101,
113,
115,
123,
131,
137,
145,
149,
154,
159,
167,
170,
178,
191,
198,
205,
210,
216,
229,
240,
247,
257,
264,
271
],
"end_char": [
3,
10,
19,
24,
30,
42,
47,
48,
59,
70,
74,
75,
78,
92,
100,
113,
114,
122,
130,
136,
144,
148,
153,
158,
166,
169,
177,
190,
197,
204,
209,
215,
228,
239,
246,
256,
263,
271,
272
],
"ner": [
"S-ORGANIZATION",
"O",
"B-ORGANIZATION",
"I-ORGANIZATION",
"E-ORGANIZATION",
"O",
"S-TIME",
"O",
"S-TIME",
"O",
"S-LOCATION",
"O",
"S-LOCATION",
"O",
"O",
"O",
"O",
"S-TIME",
"S-LOCATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-TIME",
"S-LOCATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"NSA",
"olarak",
"Carter'a",
"1978'deki",
"Camp",
"David",
"Anlaşmaları",
",",
"1970'lerin",
"sonlarında",
"ABD",
"-",
"Çin",
"ilişkilerinin",
"normale",
"döndürülmesi",
",",
"1979'da",
"İran'da",
"rehin",
"krizine",
"yol",
"açan",
"İran",
"Devrimi",
"ve",
"1979'da",
"Afganistan'daki",
"Sovyet",
"işgali",
"gibi",
"dünya",
"meselelerini",
"diplomatik",
"olarak",
"yönetme",
"konusunda",
"yardım",
"etti",
"."
] | {
"lemma": [
"NSA",
"olarak",
"Carter",
"197<UNK>'de+ki",
"Camp",
"David",
"anlaşma",
",",
"1970",
"son",
"Abd",
"-",
"Çin",
"ilişki",
"normal",
"dön",
",",
"1979",
"İran",
"rehin",
"kriz",
"yol",
"aç",
"İran",
"devrimi",
"ve",
"1979",
"Afganistan+ki",
"Sovyet",
"işga+li",
"gibi",
"dünya",
"mesele",
"diplomatik",
"olarak",
"yönet",
"konu",
"yardım",
"et",
"."
],
"upos": [
"NOUN",
"ADP",
"PROPN",
"NUM+ADP",
"PROPN",
"PROPN",
"NOUN",
"PUNCT",
"PROPN",
"NOUN",
"NOUN",
"PUNCT",
"PROPN",
"NOUN",
"NOUN",
"VERB",
"PUNCT",
"NUM",
"PROPN",
"NOUN",
"NOUN",
"NOUN",
"VERB",
"PROPN",
"NOUN",
"CCONJ",
"NUM",
"PROPN+ADP",
"PROPN",
"NOUN+ADP",
"ADP",
"NOUN",
"NOUN",
"ADJ",
"ADP",
"VERB",
"NOUN",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"",
"Case=Dat|Number=Sing|Person=3",
"Case=Loc|NumType=Card|Number=Sing|Person=3+",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Gen|Number=Plur|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun|Voice=Pass",
"",
"Case=Loc|NumType=Card|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Loc|NumType=Card|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Person=3+",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3+",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Acc|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=3",
"",
"",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun|Voice=Cau",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
""
],
"head": [
"8",
"1",
"8",
"8+4",
"8",
"6",
"17",
"8",
"11",
"17",
"15",
"14",
"12",
"17",
"17",
"41",
"17",
"23",
"23",
"22",
"23",
"25",
"23",
"41",
"25",
"25",
"29",
"32+29",
"32",
"36+32",
"32",
"36",
"39",
"39",
"37",
"40",
"41",
"0",
"41",
"41"
],
"deprel": [
"nmod",
"case",
"nmod",
"nummod+case",
"nmod:poss",
"flat",
"nmod:poss",
"punct",
"nmod:poss",
"obl",
"nmod:poss",
"punct",
"conj",
"nmod:poss",
"obl",
"nsubj",
"punct",
"nummod",
"nmod",
"nmod:poss",
"nmod",
"nmod",
"compound",
"nsubj",
"flat",
"cc",
"nummod",
"nmod+case",
"nmod",
"nmod+case",
"case",
"nmod:poss",
"obj",
"amod",
"case",
"nmod:poss",
"nmod",
"root",
"compound:lvc",
"punct"
],
"start_char": [
0,
4,
11,
20,
30,
35,
41,
52,
54,
65,
76,
79,
80,
84,
98,
106,
118,
120,
128,
136,
142,
150,
154,
159,
164,
172,
175,
183,
199,
206,
213,
218,
224,
237,
248,
255,
263,
273,
280,
284
],
"end_char": [
3,
10,
19,
29,
34,
40,
52,
53,
64,
75,
79,
80,
83,
97,
105,
118,
119,
127,
135,
141,
149,
153,
158,
163,
171,
174,
182,
198,
205,
212,
217,
223,
236,
247,
254,
262,
272,
279,
284,
285
],
"ner": [
"S-ORGANIZATION",
"O",
"S-ORGANIZATION",
"S-TIME",
"B-ORGANIZATION",
"E-ORGANIZATION",
"O",
"O",
"S-TIME",
"O",
"S-LOCATION",
"O",
"S-LOCATION",
"O",
"O",
"O",
"O",
"S-TIME",
"S-LOCATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-TIME",
"S-LOCATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK"
] | [
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"BAD",
"OK",
"OK"
] |
flores101-main-tur-102-ht-1 | 923 | flores101-main-1021 | tur_t1 | tur | 102 | ht | ht | 87 | null | 90 | 14 | null | 12 | 91.175 | 139 | 71 | 0 | 11 | 3 | 39 | 13 | 0 | 1 | 1 | 0 | 17 | 78,926 | 9 | 73,760 | 91,175 | 2 | 1,643,316,534 | null | null | null | null | null | null | null | null | null | null | 91.175 | 1.5196 | 0.0253 | 1.048 | 6.5125 | 1.5977 | 552.7831 | 9.2131 | 17 | Most of the distinct Baltic Cruises feature an extended stay in St. Petersburg, Russia. | nan | Önemli Baltik Gemi Gezilerinin çoğu, Rusya'nın St. Petersburg kentinde uzun süre duraklar. | nan | [
"Most",
"of",
"the",
"distinct",
"Baltic",
"Cruises",
"feature",
"an",
"extended",
"stay",
"in",
"St.",
"Petersburg",
",",
"Russia",
"."
] | {
"lemma": [
"most",
"of",
"the",
"distinct",
"Baltic",
"Cruise",
"feature",
"a",
"extend",
"stay",
"in",
"St.",
"Petersburg",
",",
"Russia",
"."
],
"upos": [
"ADJ",
"ADP",
"DET",
"ADJ",
"ADJ",
"PROPN",
"VERB",
"DET",
"VERB",
"NOUN",
"ADP",
"PROPN",
"PROPN",
"PUNCT",
"PROPN",
"PUNCT"
],
"feats": [
"Degree=Sup",
"",
"Definite=Def|PronType=Art",
"Degree=Pos",
"Degree=Pos",
"Number=Plur",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"Definite=Ind|PronType=Art",
"Tense=Past|VerbForm=Part",
"Number=Sing",
"",
"Number=Sing",
"Number=Sing",
"",
"Number=Sing",
""
],
"head": [
"7",
"6",
"6",
"6",
"6",
"1",
"0",
"10",
"10",
"7",
"12",
"10",
"12",
"15",
"12",
"7"
],
"deprel": [
"nsubj",
"case",
"det",
"amod",
"amod",
"nmod",
"root",
"det",
"amod",
"obj",
"case",
"nmod",
"flat",
"punct",
"appos",
"punct"
],
"start_char": [
0,
5,
8,
12,
21,
28,
36,
44,
47,
56,
61,
64,
68,
78,
80,
86
],
"end_char": [
4,
7,
11,
20,
27,
35,
43,
46,
55,
60,
63,
67,
78,
79,
86,
87
],
"ner": [
"O",
"O",
"O",
"O",
"B-ORG",
"E-ORG",
"O",
"O",
"O",
"O",
"O",
"B-GPE",
"E-GPE",
"O",
"S-GPE",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Önemli",
"Baltik",
"Gemi",
"Gezilerinin",
"çoğu",
",",
"Rusya'nın",
"St.",
"Petersburg",
"kentinde",
"uzun",
"süre",
"duraklar",
"."
] | {
"lemma": [
"önem+li",
"Baltik",
"gemi",
"gezi",
"çok",
",",
"Rusya",
"St.",
"Petersburg",
"kent",
"uzun",
"süre",
"dur",
"."
],
"upos": [
"NOUN+ADP",
"PROPN",
"NOUN",
"NOUN",
"ADJ",
"PUNCT",
"PROPN",
"PROPN",
"PROPN",
"NOUN",
"ADJ",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|Number=Sing|Person=3+",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Gen|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Hab|Mood=Ind|Number=Plur|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"5+1",
"5",
"5",
"6",
"14",
"6",
"11",
"11",
"9",
"14",
"13",
"14",
"0",
"14"
],
"deprel": [
"nmod+case",
"nmod:poss",
"nmod:poss",
"nmod:poss",
"amod",
"punct",
"nmod:poss",
"nmod:poss",
"flat",
"obl",
"amod",
"obl",
"root",
"punct"
],
"start_char": [
0,
7,
14,
19,
31,
35,
37,
47,
51,
62,
71,
76,
81,
89
],
"end_char": [
6,
13,
18,
30,
35,
36,
46,
50,
61,
70,
75,
80,
89,
90
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"S-LOCATION",
"B-LOCATION",
"I-LOCATION",
"E-LOCATION",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-102-ht-2 | 924 | flores101-main-1022 | tur_t1 | tur | 102 | ht | ht | 119 | null | 85 | 23 | null | 12 | 23.233 | 97 | 76 | 0 | 13 | 1 | 2 | 5 | 0 | 0 | 0 | 0 | 4 | 11,932 | 3 | 11,421 | 23,233 | 2 | 1,643,316,534 | null | null | null | null | null | null | null | null | null | null | 23.233 | 0.3872 | 0.0065 | 0.1952 | 1.0101 | 0.8151 | 3,563.8962 | 59.3983 | 18 | This means you can visit the historic city for a couple of full days while returning and sleeping on the ship at night. | nan | Yani birkaç gün boyunca bu tarihi şehri gezebilir ve geceleri gemide uyuyabilirsiniz. | nan | [
"This",
"means",
"you",
"can",
"visit",
"the",
"historic",
"city",
"for",
"a",
"couple",
"of",
"full",
"days",
"while",
"returning",
"and",
"sleeping",
"on",
"the",
"ship",
"at",
"night",
"."
] | {
"lemma": [
"this",
"mean",
"you",
"can",
"visit",
"the",
"historic",
"city",
"for",
"a",
"couple",
"of",
"full",
"day",
"while",
"return",
"and",
"sleep",
"on",
"the",
"ship",
"at",
"night",
"."
],
"upos": [
"PRON",
"VERB",
"PRON",
"AUX",
"VERB",
"DET",
"ADJ",
"NOUN",
"ADP",
"DET",
"NOUN",
"ADP",
"ADJ",
"NOUN",
"SCONJ",
"VERB",
"CCONJ",
"VERB",
"ADP",
"DET",
"NOUN",
"ADP",
"NOUN",
"PUNCT"
],
"feats": [
"Number=Sing|PronType=Dem",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"Case=Nom|Person=2|PronType=Prs",
"VerbForm=Fin",
"VerbForm=Inf",
"Definite=Def|PronType=Art",
"Degree=Pos",
"Number=Sing",
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"",
"Degree=Pos",
"Number=Plur",
"",
"VerbForm=Ger",
"",
"VerbForm=Ger",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Number=Sing",
""
],
"head": [
"2",
"0",
"5",
"5",
"2",
"8",
"8",
"5",
"11",
"11",
"5",
"14",
"14",
"11",
"16",
"5",
"18",
"16",
"21",
"21",
"18",
"23",
"16",
"2"
],
"deprel": [
"nsubj",
"root",
"nsubj",
"aux",
"ccomp",
"det",
"amod",
"obj",
"case",
"det",
"obl",
"case",
"amod",
"nmod",
"mark",
"advcl",
"cc",
"conj",
"case",
"det",
"obl",
"case",
"obl",
"punct"
],
"start_char": [
0,
5,
11,
15,
19,
25,
29,
38,
43,
47,
49,
56,
59,
64,
69,
75,
85,
89,
98,
101,
105,
110,
113,
118
],
"end_char": [
4,
10,
14,
18,
24,
28,
37,
42,
46,
48,
55,
58,
63,
68,
74,
84,
88,
97,
100,
104,
109,
112,
118,
119
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"B-DATE",
"I-DATE",
"I-DATE",
"I-DATE",
"E-DATE",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-TIME",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Yani",
"birkaç",
"gün",
"boyunca",
"bu",
"tarihi",
"şehri",
"gezebilir",
"ve",
"geceleri",
"gemide",
"uyuyabilirsiniz",
"."
] | {
"lemma": [
"yani",
"birkaç",
"gün",
"boyunca",
"bu",
"tarihi",
"şehir",
"gez",
"ve",
"gece",
"gemi",
"uy",
"."
],
"upos": [
"CCONJ",
"DET",
"NOUN",
"ADP",
"DET",
"ADJ",
"NOUN",
"VERB",
"CCONJ",
"NOUN",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"",
"",
"Case=Acc|Number=Sing|Person=3",
"Aspect=Hab|Mood=Pot|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"Case=Acc|Number=Plur|Person=3",
"Case=Loc|Number=Sing|Person=3",
"Aspect=Hab|Mood=Pot|Number=Plur|Person=2|Polarity=Pos|Tense=Pres",
""
],
"head": [
"8",
"3",
"8",
"3",
"7",
"7",
"8",
"0",
"12",
"12",
"12",
"8",
"12"
],
"deprel": [
"nmod",
"det",
"obl",
"case",
"det",
"amod",
"obj",
"root",
"cc",
"obj",
"obl",
"conj",
"punct"
],
"start_char": [
0,
5,
12,
16,
24,
27,
34,
40,
50,
53,
62,
69,
84
],
"end_char": [
4,
11,
15,
23,
26,
33,
39,
49,
52,
61,
68,
84,
85
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-102-ht-3 | 925 | flores101-main-1023 | tur_t1 | tur | 102 | ht | ht | 96 | null | 101 | 18 | null | 13 | 57.44 | 144 | 107 | 4 | 16 | 3 | 8 | 6 | 0 | 0 | 0 | 0 | 12 | 42,051 | 4 | 37,289 | 57,440 | 1 | 1,643,316,534 | null | null | null | null | null | null | null | null | null | null | 57.44 | 0.9573 | 0.016 | 0.5983 | 3.1911 | 1.5 | 1,128.1337 | 18.8022 | 19 | If you only go ashore using shipboard excursions you will not need a separate visa (as of 2009). | nan | Yalnızca geminin düzenlediği geziler için kıyıya çıkarsanız ayrı bir vize gerekmez (2009 itibarıyla). | nan | [
"If",
"you",
"only",
"go",
"ashore",
"using",
"shipboard",
"excursions",
"you",
"will",
"not",
"need",
"a",
"separate",
"visa",
"(",
"as",
"of",
"2009",
")",
"."
] | {
"lemma": [
"if",
"you",
"only",
"go",
"ashore",
"use",
"shipboard",
"excursion",
"you",
"will",
"not",
"need",
"a",
"separate",
"visa",
"(",
"as",
"of",
"2009",
")",
"."
],
"upos": [
"SCONJ",
"PRON",
"ADV",
"VERB",
"ADV",
"VERB",
"ADJ",
"NOUN",
"PRON",
"AUX",
"PART",
"VERB",
"DET",
"ADJ",
"NOUN",
"PUNCT",
"ADP",
"ADP",
"NUM",
"PUNCT",
"PUNCT"
],
"feats": [
"",
"Case=Nom|Person=2|PronType=Prs",
"",
"Mood=Ind|Number=Sing|Person=2|Tense=Pres|VerbForm=Fin",
"",
"VerbForm=Ger",
"Degree=Pos",
"Number=Plur",
"Case=Nom|Person=2|PronType=Prs",
"VerbForm=Fin",
"",
"VerbForm=Inf",
"Definite=Ind|PronType=Art",
"Degree=Pos",
"Number=Sing",
"",
"",
"",
"NumForm=Digit|NumType=Card",
"",
""
],
"head": [
"4",
"4",
"4",
"12",
"4",
"4",
"8",
"6",
"12",
"12",
"12",
"0",
"15",
"15",
"12",
"19",
"19",
"17",
"12",
"19",
"12"
],
"deprel": [
"mark",
"nsubj",
"advmod",
"advcl",
"advmod",
"advcl",
"amod",
"obj",
"nsubj",
"aux",
"advmod",
"root",
"det",
"amod",
"obj",
"punct",
"case",
"fixed",
"obl",
"punct",
"punct"
],
"start_char": [
0,
3,
7,
12,
15,
22,
28,
38,
49,
53,
58,
62,
67,
69,
78,
83,
84,
87,
90,
94,
95
],
"end_char": [
2,
6,
11,
14,
21,
27,
37,
48,
52,
57,
61,
66,
68,
77,
82,
84,
86,
89,
94,
95,
96
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-DATE",
"O",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Yalnızca",
"geminin",
"düzenlediği",
"geziler",
"için",
"kıyıya",
"çıkarsanız",
"ayrı",
"bir",
"vize",
"gerekmez",
"(",
"2009",
"itibarıyla",
")",
"."
] | {
"lemma": [
"yalnızca",
"gemin",
"düzenle",
"gezi",
"için",
"kıyı",
"çık",
"ayrı",
"bir",
"viz",
"gerek",
"(",
"2009",
"itibar",
")",
"."
],
"upos": [
"ADV",
"NOUN",
"VERB",
"NOUN",
"ADP",
"NOUN",
"VERB",
"ADJ",
"DET",
"NOUN",
"VERB",
"PUNCT",
"NUM",
"NOUN",
"PUNCT",
"PUNCT"
],
"feats": [
"",
"Case=Gen|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"Case=Nom|Number=Plur|Person=3",
"",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Hab|Mood=Cnd|Number=Plur|Person=2|Polarity=Pos|Tense=Pres",
"",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Hab|Mood=Ind|Number=Sing|Person=3|Polarity=Neg|Tense=Pres",
"",
"Case=Nom|NumType=Card|Number=Sing|Person=3",
"Case=Ins|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
""
],
"head": [
"7",
"3",
"4",
"7",
"4",
"7",
"11",
"10",
"10",
"11",
"0",
"13",
"14",
"11",
"13",
"11"
],
"deprel": [
"advmod",
"nmod:poss",
"acl",
"obl",
"case",
"obl",
"nmod",
"amod",
"det",
"obj",
"root",
"punct",
"nmod:poss",
"obl",
"punct",
"punct"
],
"start_char": [
0,
9,
17,
29,
37,
42,
49,
60,
65,
69,
74,
83,
84,
89,
99,
100
],
"end_char": [
8,
16,
28,
36,
41,
48,
59,
64,
68,
73,
82,
84,
88,
99,
100,
101
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-TIME",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-102-ht-4 | 926 | flores101-main-1024 | tur_t1 | tur | 102 | ht | ht | 188 | null | 184 | 38 | null | 24 | 64.176 | 279 | 211 | 0 | 31 | 4 | 18 | 15 | 0 | 0 | 0 | 0 | 29 | 37,101 | 14 | 30,117 | 64,176 | 1 | 1,643,316,534 | null | null | null | null | null | null | null | null | null | null | 64.176 | 1.0696 | 0.0178 | 0.3414 | 1.6888 | 1.484 | 2,131.638 | 35.5273 | 20 | Some cruises feature Berlin, Germany in the brochures. As you can see from the map above Berlin is no where near the sea and a visit to the city is not included in the price of the cruise. | nan | Bazı gemi gezilerinin broşürlerinde Almanya'nın Berlin kenti yer alır. Yukarıdaki haritada görüleceği üzere Berlin denize uzaktır ve şehri ziyaret etmenin ücreti geziye dahil değildir. | nan | [
"Some",
"cruises",
"feature",
"Berlin",
",",
"Germany",
"in",
"the",
"brochures",
".",
"As",
"you",
"can",
"see",
"from",
"the",
"map",
"above",
"Berlin",
"is",
"no",
"where",
"near",
"the",
"sea",
"and",
"a",
"visit",
"to",
"the",
"city",
"is",
"not",
"included",
"in",
"the",
"price",
"of",
"the",
"cruise",
"."
] | {
"lemma": [
"some",
"cruise",
"feature",
"Berlin",
",",
"Germany",
"in",
"the",
"brochure",
".",
"as",
"you",
"can",
"see",
"from",
"the",
"map",
"above",
"Berlin",
"be",
"no",
"where",
"near",
"the",
"sea",
"and",
"a",
"visit",
"to",
"the",
"city",
"be",
"not",
"include",
"in",
"the",
"price",
"of",
"the",
"cruise",
"."
],
"upos": [
"DET",
"NOUN",
"VERB",
"PROPN",
"PUNCT",
"PROPN",
"ADP",
"DET",
"NOUN",
"PUNCT",
"SCONJ",
"PRON",
"AUX",
"VERB",
"ADP",
"DET",
"NOUN",
"ADP",
"PROPN",
"AUX",
"ADV",
"SCONJ",
"ADP",
"DET",
"NOUN",
"CCONJ",
"DET",
"NOUN",
"ADP",
"DET",
"NOUN",
"AUX",
"PART",
"VERB",
"ADP",
"DET",
"NOUN",
"ADP",
"DET",
"NOUN",
"PUNCT"
],
"feats": [
"",
"Number=Plur",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"Number=Sing",
"",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"Number=Plur",
"",
"",
"Case=Nom|Person=2|PronType=Prs",
"VerbForm=Fin",
"VerbForm=Inf",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"",
"PronType=Int",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Tense=Past|VerbForm=Part|Voice=Pass",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
""
],
"head": [
"2",
"3",
"0",
"3",
"6",
"4",
"9",
"9",
"3",
"3",
"4",
"4",
"4",
"15",
"7",
"7",
"4",
"9",
"7",
"15",
"15",
"15",
"15",
"15",
"0",
"24",
"18",
"24",
"21",
"21",
"18",
"24",
"24",
"15",
"27",
"27",
"24",
"30",
"30",
"27",
"15"
],
"deprel": [
"det",
"nsubj",
"root",
"obj",
"punct",
"conj",
"case",
"det",
"obl",
"punct",
"mark",
"nsubj",
"aux",
"advcl",
"case",
"det",
"obl",
"case",
"nmod",
"cop",
"advmod",
"mark",
"case",
"det",
"root",
"cc",
"det",
"nsubj:pass",
"case",
"det",
"nmod",
"aux:pass",
"advmod",
"conj",
"case",
"det",
"obl",
"case",
"det",
"nmod",
"punct"
],
"start_char": [
0,
5,
13,
21,
27,
29,
37,
40,
44,
53,
55,
58,
62,
66,
70,
75,
79,
83,
89,
96,
99,
102,
108,
113,
117,
121,
125,
127,
133,
136,
140,
145,
148,
152,
161,
164,
168,
174,
177,
181,
187
],
"end_char": [
4,
12,
20,
27,
28,
36,
39,
43,
53,
54,
57,
61,
65,
69,
74,
78,
82,
88,
95,
98,
101,
107,
112,
116,
120,
124,
126,
132,
135,
139,
144,
147,
151,
160,
163,
167,
173,
176,
180,
187,
188
],
"ner": [
"O",
"O",
"O",
"S-GPE",
"O",
"S-GPE",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-GPE",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Bazı",
"gemi",
"gezilerinin",
"broşürlerinde",
"Almanya'nın",
"Berlin",
"kenti",
"yer",
"alır",
".",
"Yukarıdaki",
"haritada",
"görüleceği",
"üzere",
"Berlin",
"denize",
"uzaktır",
"ve",
"şehri",
"ziyaret",
"etmenin",
"ücreti",
"geziye",
"dahil",
"değildir",
"."
] | {
"lemma": [
"bazı",
"gemi",
"gezi",
"broşür",
"Almanya",
"Berlin",
"kenti",
"yer",
"al",
".",
"yukarı+ki",
"harita",
"gör",
"üzere",
"Berlin",
"deniz",
"uza",
"ve",
"şehir",
"ziyaret",
"et",
"ücret",
"gezi",
"dahil",
"değil",
"."
],
"upos": [
"DET",
"NOUN",
"NOUN",
"NOUN",
"PROPN",
"PROPN",
"NOUN",
"NOUN",
"VERB",
"PUNCT",
"ADJ+ADP",
"NOUN",
"VERB",
"ADP",
"PROPN",
"NOUN",
"VERB",
"CCONJ",
"NOUN",
"NOUN",
"VERB",
"NOUN",
"NOUN",
"NOUN",
"AUX",
"PUNCT"
],
"feats": [
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Loc|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Gen|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Hab|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"Case=Loc|Number=Sing|Person=3+",
"Case=Loc|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Fut|VerbForm=Part|Voice=Pass",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Hab|Mood=Gen|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"Case=Acc|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Gen|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Dat|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Gen|Number=Sing|Person=3|Polarity=Neg|Tense=Pres",
""
],
"head": [
"3",
"3",
"4",
"9",
"7",
"7",
"9",
"9",
"0",
"9",
"3+1",
"4",
"15",
"4",
"8",
"6",
"15",
"11",
"11",
"13",
"11",
"15",
"15",
"0",
"15",
"15"
],
"deprel": [
"det",
"nmod:poss",
"nmod:poss",
"obl",
"nmod:poss",
"nmod:poss",
"nsubj",
"obj",
"root",
"punct",
"amod+case",
"obl",
"acl",
"case",
"obl",
"compound",
"nmod",
"cc",
"obj",
"nmod",
"compound:lvc",
"nsubj",
"nmod",
"root",
"aux",
"punct"
],
"start_char": [
0,
5,
10,
22,
36,
48,
55,
61,
65,
69,
71,
82,
91,
102,
108,
115,
122,
130,
133,
139,
147,
155,
162,
169,
175,
183
],
"end_char": [
4,
9,
21,
35,
47,
54,
60,
64,
69,
70,
81,
90,
101,
107,
114,
121,
129,
132,
138,
146,
154,
161,
168,
174,
183,
184
],
"ner": [
"O",
"O",
"O",
"O",
"S-LOCATION",
"B-LOCATION",
"E-LOCATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-LOCATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-103-pe1-1 | 669 | flores101-main-1031 | tur_t1 | tur | 103 | pe1 | pe | 195 | 170 | 159 | 28 | 21 | 21 | 154.904 | 207 | 77 | 0 | 16 | 3 | 99 | 10 | 0 | 1 | 1 | 0 | 24 | 125,852 | 14 | 118,817 | 154,904 | 1 | 1,643,316,842 | 2 | 1 | 7 | 1 | 1 | 11 | 47.826 | 0.3198 | 42.69 | 68.27 | 154.904 | 2.5817 | 0.043 | 0.7944 | 5.5323 | 1.0615 | 650.7256 | 10.8454 | 21 | Why would an organization want to go through the time consuming process of establishing a learning organization? One goal for putting organizational learning concepts into practice is innovation. | Bir organizasyon neden öğrenen bir organizasyon kurmanın zaman alıcı sürecinden geçmek istesin ki? Kurumsal öğrenme kavramlarını uygulamaya koymanın bir amacı yeniliktir. | Bir kuruluş, eğitim kurumu kurmak için gereken zaman alıcı süreçten neden geçmek ister? Kurumsal öğrenme kavramlarını uygulamaya koymanın bir amacı yeniliktir. | REF: bir ******* organizasyon neden ****** öğrenen bir organizasyon kurmanın zaman alıcı sürecinden geçmek istesin ki ? kurumsal öğrenme kavramlarını uygulamaya koymanın bir amacı yeniliktir .\nHYP: bir kuruluş , [ neden ] eğitim kurumu kurmak için gereken zaman alıcı süreçten @ geçmek ******* ister ? kurumsal öğrenme kavramlarını uygulamaya koymanın bir amacı yeniliktir .\nEVAL: I S I S S S S S D S | [
"Why",
"would",
"an",
"organization",
"want",
"to",
"go",
"through",
"the",
"time",
"consuming",
"process",
"of",
"establishing",
"a",
"learning",
"organization",
"?",
"One",
"goal",
"for",
"putting",
"organizational",
"learning",
"concepts",
"into",
"practice",
"is",
"innovation",
"."
] | {
"lemma": [
"why",
"would",
"a",
"organization",
"want",
"to",
"go",
"through",
"the",
"time",
"consume",
"process",
"of",
"establish",
"a",
"learning",
"organization",
"?",
"one",
"goal",
"for",
"put",
"organizational",
"learning",
"concept",
"into",
"practice",
"be",
"innovation",
"."
],
"upos": [
"ADV",
"AUX",
"DET",
"NOUN",
"VERB",
"PART",
"VERB",
"ADP",
"DET",
"NOUN",
"VERB",
"NOUN",
"SCONJ",
"VERB",
"DET",
"NOUN",
"NOUN",
"PUNCT",
"NUM",
"NOUN",
"SCONJ",
"VERB",
"ADJ",
"NOUN",
"NOUN",
"ADP",
"NOUN",
"AUX",
"NOUN",
"PUNCT"
],
"feats": [
"PronType=Int",
"VerbForm=Fin",
"Definite=Ind|PronType=Art",
"Number=Sing",
"VerbForm=Inf",
"",
"VerbForm=Inf",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"VerbForm=Ger",
"Number=Sing",
"",
"VerbForm=Ger",
"Definite=Ind|PronType=Art",
"Number=Sing",
"Number=Sing",
"",
"NumForm=Word|NumType=Card",
"Number=Sing",
"",
"VerbForm=Ger",
"Degree=Pos",
"Number=Sing",
"Number=Plur",
"",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"Number=Sing",
""
],
"head": [
"5",
"5",
"4",
"5",
"0",
"7",
"5",
"12",
"12",
"11",
"12",
"7",
"14",
"12",
"17",
"17",
"14",
"5",
"2",
"11",
"4",
"2",
"7",
"7",
"4",
"9",
"4",
"11",
"0",
"11"
],
"deprel": [
"advmod",
"aux",
"det",
"nsubj",
"root",
"mark",
"xcomp",
"case",
"det",
"compound",
"amod",
"obl",
"mark",
"acl",
"det",
"compound",
"obj",
"punct",
"nummod",
"nsubj",
"mark",
"acl",
"amod",
"compound",
"obj",
"case",
"obl",
"cop",
"root",
"punct"
],
"start_char": [
0,
4,
10,
13,
26,
31,
34,
37,
45,
49,
54,
64,
72,
75,
88,
90,
99,
111,
113,
117,
122,
126,
134,
149,
158,
167,
172,
181,
184,
194
],
"end_char": [
3,
9,
12,
25,
30,
33,
36,
44,
48,
53,
63,
71,
74,
87,
89,
98,
111,
112,
116,
121,
125,
133,
148,
157,
166,
171,
180,
183,
194,
195
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-CARDINAL",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Bir",
"organizasyon",
"neden",
"öğrenen",
"bir",
"organizasyon",
"kurmanın",
"zaman",
"alıcı",
"sürecinden",
"geçmek",
"istesin",
"ki",
"?",
"Kurumsal",
"öğrenme",
"kavramlarını",
"uygulamaya",
"koymanın",
"bir",
"amacı",
"yeniliktir",
"."
] | {
"lemma": [
"bir",
"organizasyon",
"neden",
"öğren",
"bir",
"organizasyon",
"kur",
"zaman",
"al",
"süreç",
"geç",
"iste",
"ki",
"?",
"kurumsal",
"öğren",
"kavram",
"uygulama",
"koy",
"bir",
"amaç",
"yenilik+i",
"."
],
"upos": [
"DET",
"NOUN",
"ADV",
"VERB",
"DET",
"NOUN",
"VERB",
"NOUN",
"VERB",
"NOUN",
"VERB",
"VERB",
"CCONJ",
"PUNCT",
"ADJ",
"VERB",
"NOUN",
"VERB",
"VERB",
"DET",
"NOUN",
"NOUN+AUX",
"PUNCT"
],
"feats": [
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Gen|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Abl|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Aspect=Perf|Mood=Imp|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"",
"",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Acc|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Dat|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Aspect=Perf|Case=Gen|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3+Aspect=Perf|Mood=Gen|Number=Sing|Person=3|Tense=Pres",
""
],
"head": [
"2",
"4",
"4",
"6",
"6",
"7",
"11",
"10",
"8",
"11",
"12",
"0",
"12",
"12",
"2",
"3",
"4",
"5",
"7",
"7",
"8",
"0+8",
"8"
],
"deprel": [
"det",
"obj",
"advmod",
"acl",
"det",
"obj",
"nmod:poss",
"nmod",
"compound",
"obl",
"obj",
"root",
"advmod:emph",
"punct",
"amod",
"nmod:poss",
"obj",
"nmod",
"nmod:poss",
"det",
"nsubj",
"root+cop",
"punct"
],
"start_char": [
0,
4,
17,
23,
31,
35,
48,
57,
63,
69,
80,
87,
95,
97,
99,
108,
116,
129,
140,
149,
153,
159,
169
],
"end_char": [
3,
16,
22,
30,
34,
47,
56,
62,
68,
79,
86,
94,
97,
98,
107,
115,
128,
139,
148,
152,
158,
169,
170
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Bir",
"kuruluş",
",",
"eğitim",
"kurumu",
"kurmak",
"için",
"gereken",
"zaman",
"alıcı",
"süreçten",
"neden",
"geçmek",
"ister",
"?",
"Kurumsal",
"öğrenme",
"kavramlarını",
"uygulamaya",
"koymanın",
"bir",
"amacı",
"yeniliktir",
"."
] | {
"lemma": [
"bir",
"kuruluş",
",",
"eğitim",
"kurum",
"kur",
"için",
"gerek",
"zaman",
"al",
"süreç",
"neden",
"geç",
"iste",
"?",
"kurumsal",
"öğren",
"kavram",
"uygulama",
"koy",
"bir",
"amaç",
"yenilik+i",
"."
],
"upos": [
"DET",
"NOUN",
"PUNCT",
"NOUN",
"NOUN",
"VERB",
"ADP",
"VERB",
"NOUN",
"VERB",
"NOUN",
"ADV",
"VERB",
"VERB",
"PUNCT",
"ADJ",
"VERB",
"NOUN",
"VERB",
"VERB",
"DET",
"NOUN",
"NOUN+AUX",
"PUNCT"
],
"feats": [
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Abl|Number=Sing|Person=3",
"",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Aspect=Hab|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
"",
"",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Acc|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Dat|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Aspect=Perf|Case=Gen|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3+Aspect=Perf|Mood=Gen|Number=Sing|Person=3|Tense=Pres",
""
],
"head": [
"2",
"14",
"2",
"5",
"6",
"14",
"6",
"11",
"11",
"9",
"12",
"14",
"12",
"0",
"14",
"2",
"3",
"4",
"5",
"7",
"7",
"8",
"0+8",
"8"
],
"deprel": [
"nummod",
"nsubj",
"punct",
"nmod:poss",
"obj",
"nmod",
"case",
"acl",
"nmod",
"compound",
"obl",
"advmod",
"compound",
"root",
"punct",
"amod",
"nmod:poss",
"obj",
"nmod",
"nmod:poss",
"det",
"nsubj",
"root+cop",
"punct"
],
"start_char": [
0,
4,
11,
13,
20,
27,
34,
39,
47,
53,
59,
68,
74,
81,
86,
88,
97,
105,
118,
129,
138,
142,
148,
158
],
"end_char": [
3,
11,
12,
19,
26,
33,
38,
46,
52,
58,
67,
73,
80,
86,
87,
96,
104,
117,
128,
137,
141,
147,
158,
159
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"BAD",
"OK",
"OK",
"BAD",
"BAD",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"BAD",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] | [
"OK",
"BAD",
"BAD",
"BAD",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"BAD",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] |
flores101-main-tur-103-pe1-2 | 670 | flores101-main-1032 | tur_t1 | tur | 103 | pe1 | pe | 143 | 141 | 136 | 19 | 16 | 16 | 69.953 | 90 | 28 | 0 | 4 | 0 | 57 | 1 | 0 | 0 | 0 | 0 | 4 | 63,208 | 4 | 63,208 | 69,953 | 1 | 1,643,316,842 | 0 | 0 | 4 | 2 | 3 | 6 | 33.333 | 0.2797 | 63.42 | 82.9 | 69.953 | 1.1659 | 0.0194 | 0.4892 | 3.6817 | 0.6294 | 977.7994 | 16.2967 | 22 | When all available resources are effectively used across the functional departments of an organization, creativity and ingenuity can transpire. | Bir organizasyonun işlevsel departmanlarında mevcut tüm kaynaklar etkin bir şekilde kullanıldığında, yaratıcılık ve ustalık ortaya çıkabilir. | Tüm mevcut kaynaklar bir kuruluşun işlevsel departmanlarında etkin bir şekilde kullanıldığında, yaratıcılık ve ustalık ortaya çıkabilir. | REF: bir organizasyonun işlevsel departmanlarında mevcut tüm kaynaklar etkin bir şekilde kullanıldığında , yaratıcılık ve ustalık ortaya çıkabilir .\nHYP: tüm mevcut [ işlevsel departmanlarında ] @ bir kuruluşun [ kaynaklar ] @ etkin bir şekilde kullanıldığında , yaratıcılık ve ustalık ortaya çıkabilir .\nEVAL: S S S S | [
"When",
"all",
"available",
"resources",
"are",
"effectively",
"used",
"across",
"the",
"functional",
"departments",
"of",
"an",
"organization",
",",
"creativity",
"and",
"ingenuity",
"can",
"transpire",
"."
] | {
"lemma": [
"when",
"all",
"available",
"resource",
"be",
"effectively",
"use",
"across",
"the",
"functional",
"department",
"of",
"a",
"organization",
",",
"creativity",
"and",
"ingenuity",
"can",
"transpire",
"."
],
"upos": [
"SCONJ",
"DET",
"ADJ",
"NOUN",
"AUX",
"ADV",
"VERB",
"ADP",
"DET",
"ADJ",
"NOUN",
"ADP",
"DET",
"NOUN",
"PUNCT",
"NOUN",
"CCONJ",
"NOUN",
"AUX",
"VERB",
"PUNCT"
],
"feats": [
"PronType=Int",
"",
"Degree=Pos",
"Number=Plur",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Tense=Past|VerbForm=Part|Voice=Pass",
"",
"Definite=Def|PronType=Art",
"Degree=Pos",
"Number=Plur",
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"",
"Number=Sing",
"",
"Number=Sing",
"VerbForm=Fin",
"VerbForm=Inf",
""
],
"head": [
"7",
"4",
"4",
"7",
"7",
"7",
"20",
"11",
"11",
"11",
"7",
"14",
"14",
"11",
"20",
"20",
"18",
"14",
"20",
"0",
"20"
],
"deprel": [
"mark",
"det",
"amod",
"nsubj:pass",
"aux:pass",
"advmod",
"advcl",
"case",
"det",
"amod",
"obl",
"case",
"det",
"nmod",
"punct",
"nsubj",
"cc",
"conj",
"aux",
"root",
"punct"
],
"start_char": [
0,
5,
9,
19,
29,
33,
45,
50,
57,
61,
72,
84,
87,
90,
102,
104,
115,
119,
129,
133,
142
],
"end_char": [
4,
8,
18,
28,
32,
44,
49,
56,
60,
71,
83,
86,
89,
102,
103,
114,
118,
128,
132,
142,
143
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Bir",
"organizasyonun",
"işlevsel",
"departmanlarında",
"mevcut",
"tüm",
"kaynaklar",
"etkin",
"bir",
"şekilde",
"kullanıldığında",
",",
"yaratıcılık",
"ve",
"ustalık",
"ortaya",
"çıkabilir",
"."
] | {
"lemma": [
"bir",
"organiza",
"işlevsel",
"departman",
"mevcut",
"tüm",
"kaynak",
"etkin",
"bir",
"şekil",
"kullan",
",",
"yaratıcılık",
"ve",
"ustalık",
"orta",
"çık",
"."
],
"upos": [
"DET",
"NOUN",
"ADJ",
"NOUN",
"ADJ",
"DET",
"NOUN",
"ADJ",
"DET",
"NOUN",
"VERB",
"PUNCT",
"NOUN",
"CCONJ",
"NOUN",
"ADJ",
"VERB",
"PUNCT"
],
"feats": [
"Definite=Ind|PronType=Art",
"Case=Gen|Number=Sing|Person=3",
"",
"Case=Loc|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"",
"Case=Nom|Number=Plur|Person=3",
"",
"Definite=Ind|PronType=Art",
"Case=Loc|Number=Sing|Person=3",
"Aspect=Perf|Case=Loc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part|Voice=Pass",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Hab|Mood=Pot|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"2",
"4",
"4",
"5",
"7",
"7",
"11",
"10",
"10",
"11",
"16",
"11",
"16",
"15",
"13",
"0",
"16",
"16"
],
"deprel": [
"det",
"nmod:poss",
"amod",
"obl",
"amod",
"det",
"obj",
"amod",
"det",
"obl",
"acl",
"punct",
"nsubj",
"cc",
"conj",
"root",
"compound",
"punct"
],
"start_char": [
0,
4,
19,
28,
45,
52,
56,
66,
72,
76,
84,
99,
101,
113,
116,
124,
131,
140
],
"end_char": [
3,
18,
27,
44,
51,
55,
65,
71,
75,
83,
99,
100,
112,
115,
123,
130,
140,
141
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Tüm",
"mevcut",
"kaynaklar",
"bir",
"kuruluşun",
"işlevsel",
"departmanlarında",
"etkin",
"bir",
"şekilde",
"kullanıldığında",
",",
"yaratıcılık",
"ve",
"ustalık",
"ortaya",
"çıkabilir",
"."
] | {
"lemma": [
"tüm",
"mevcut",
"kaynak",
"bir",
"kuruluş",
"işlevsel",
"departman",
"etkin",
"bir",
"şekil",
"kullan",
",",
"yaratıcılık",
"ve",
"ustalık",
"orta",
"çık",
"."
],
"upos": [
"DET",
"ADJ",
"NOUN",
"DET",
"NOUN",
"ADJ",
"NOUN",
"ADJ",
"DET",
"NOUN",
"VERB",
"PUNCT",
"NOUN",
"CCONJ",
"NOUN",
"ADJ",
"VERB",
"PUNCT"
],
"feats": [
"",
"",
"Case=Nom|Number=Plur|Person=3",
"Definite=Ind|PronType=Art",
"Case=Gen|Number=Sing|Person=3",
"",
"Case=Loc|Number=Plur|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Definite=Ind|PronType=Art",
"Case=Loc|Number=Sing|Person=3",
"Aspect=Perf|Case=Loc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part|Voice=Pass",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Hab|Mood=Pot|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"3",
"3",
"16",
"5",
"7",
"7",
"11",
"10",
"10",
"11",
"16",
"11",
"16",
"15",
"13",
"0",
"16",
"16"
],
"deprel": [
"det",
"amod",
"nsubj",
"det",
"nmod:poss",
"amod",
"obl",
"amod",
"det",
"obl",
"acl",
"punct",
"nsubj",
"cc",
"conj",
"root",
"compound",
"punct"
],
"start_char": [
0,
4,
11,
21,
25,
35,
44,
61,
67,
71,
79,
94,
96,
108,
111,
119,
126,
135
],
"end_char": [
3,
10,
20,
24,
34,
43,
60,
66,
70,
78,
94,
95,
107,
110,
118,
125,
135,
136
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"BAD",
"BAD",
"BAD",
"BAD",
"OK",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] | [
"BAD",
"BAD",
"BAD",
"BAD",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] |
flores101-main-tur-103-pe1-3 | 671 | flores101-main-1033 | tur_t1 | tur | 103 | pe1 | pe | 151 | 159 | 154 | 26 | 22 | 22 | 11.036 | 31 | 9 | 0 | 1 | 0 | 21 | 0 | 0 | 0 | 0 | 0 | 1 | 2,896 | 1 | 2,896 | 11,036 | 1 | 1,643,316,842 | 0 | 0 | 1 | 0 | 0 | 1 | 4 | 0.0741 | 88.95 | 92.12 | 11.036 | 0.1839 | 0.0031 | 0.0731 | 0.4245 | 0.2053 | 8,481.3338 | 141.3556 | 23 | As a result, the process of an organization working together to overcome an obstacle can lead to a new innovative process to serve the customer's need. | Sonuç olarak, bir organizasyonun bir engeli aşmak için birlikte çalışma süreci, müşterinin ihtiyacına hizmet etmek için yeni bir yenilikçi sürece yol açabilir. | Sonuç olarak, bir kuruluşun bir engeli aşmak için birlikte çalışma süreci, müşterinin ihtiyacına hizmet etmek için yeni bir yenilikçi sürece yol açabilir. | REF: sonuç olarak , bir organizasyonun bir engeli aşmak için birlikte çalışma süreci , müşterinin ihtiyacına hizmet etmek için yeni bir yenilikçi sürece yol açabilir .\nHYP: sonuç olarak , bir kuruluşun bir engeli aşmak için birlikte çalışma süreci , müşterinin ihtiyacına hizmet etmek için yeni bir yenilikçi sürece yol açabilir .\nEVAL: S | [
"As",
"a",
"result",
",",
"the",
"process",
"of",
"an",
"organization",
"working",
"together",
"to",
"overcome",
"an",
"obstacle",
"can",
"lead",
"to",
"a",
"new",
"innovative",
"process",
"to",
"serve",
"the",
"customer",
"'s",
"need",
"."
] | {
"lemma": [
"as",
"a",
"result",
",",
"the",
"process",
"of",
"a",
"organization",
"work",
"together",
"to",
"overcome",
"a",
"obstacle",
"can",
"lead",
"to",
"a",
"new",
"innovative",
"process",
"to",
"serve",
"the",
"customer",
"'s",
"need",
"."
],
"upos": [
"ADP",
"DET",
"NOUN",
"PUNCT",
"DET",
"NOUN",
"ADP",
"DET",
"NOUN",
"VERB",
"ADV",
"PART",
"VERB",
"DET",
"NOUN",
"AUX",
"VERB",
"ADP",
"DET",
"ADJ",
"ADJ",
"NOUN",
"PART",
"VERB",
"DET",
"NOUN",
"PART",
"NOUN",
"PUNCT"
],
"feats": [
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"VerbForm=Ger",
"",
"",
"VerbForm=Inf",
"Definite=Ind|PronType=Art",
"Number=Sing",
"VerbForm=Fin",
"VerbForm=Inf",
"",
"Definite=Ind|PronType=Art",
"Degree=Pos",
"Degree=Pos",
"Number=Sing",
"",
"VerbForm=Inf",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Number=Sing",
""
],
"head": [
"3",
"3",
"17",
"17",
"6",
"17",
"9",
"9",
"6",
"9",
"10",
"13",
"10",
"15",
"13",
"17",
"0",
"22",
"22",
"22",
"22",
"17",
"24",
"17",
"26",
"28",
"26",
"24",
"17"
],
"deprel": [
"case",
"det",
"obl",
"punct",
"det",
"nsubj",
"case",
"det",
"nmod",
"acl",
"advmod",
"mark",
"advcl",
"det",
"obj",
"aux",
"root",
"case",
"det",
"amod",
"amod",
"obl",
"mark",
"advcl",
"det",
"nmod:poss",
"case",
"obj",
"punct"
],
"start_char": [
0,
3,
5,
11,
13,
17,
25,
28,
31,
44,
52,
61,
64,
73,
76,
85,
89,
94,
97,
99,
103,
114,
122,
125,
131,
135,
143,
146,
150
],
"end_char": [
2,
4,
11,
12,
16,
24,
27,
30,
43,
51,
60,
63,
72,
75,
84,
88,
93,
96,
98,
102,
113,
121,
124,
130,
134,
143,
145,
150,
151
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Sonuç",
"olarak",
",",
"bir",
"organizasyonun",
"bir",
"engeli",
"aşmak",
"için",
"birlikte",
"çalışma",
"süreci",
",",
"müşterinin",
"ihtiyacına",
"hizmet",
"etmek",
"için",
"yeni",
"bir",
"yenilikçi",
"sürece",
"yol",
"açabilir",
"."
] | {
"lemma": [
"sonuç",
"olarak",
",",
"bir",
"organiza",
"bir",
"enge+li",
"aş",
"için",
"birlikte",
"çalış",
"süreç",
",",
"müşteri",
"ihtiyaç",
"hizmet",
"et",
"için",
"yeni",
"bir",
"yenilikçi",
"süre",
"yol",
"aç",
"."
],
"upos": [
"NOUN",
"ADP",
"PUNCT",
"DET",
"NOUN",
"DET",
"NOUN+ADP",
"VERB",
"ADP",
"ADP",
"VERB",
"NOUN",
"PUNCT",
"NOUN",
"NOUN",
"NOUN",
"VERB",
"ADP",
"ADJ",
"DET",
"ADJ",
"NOUN",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|Number=Sing|Person=3",
"",
"",
"Definite=Ind|PronType=Art",
"Case=Gen|Number=Sing|Person=3",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3+",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Gen|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"",
"Definite=Ind|PronType=Art",
"",
"Case=Dat|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Hab|Mood=Pot|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"24",
"1",
"1",
"5",
"9",
"7",
"9+7",
"24",
"9",
"9",
"13",
"24",
"13",
"16",
"17",
"23",
"17",
"17",
"23",
"23",
"23",
"24",
"0",
"24",
"24"
],
"deprel": [
"nmod",
"case",
"punct",
"det",
"nsubj",
"det",
"obl+case",
"nmod",
"case",
"case",
"nmod:poss",
"nsubj",
"punct",
"nmod:poss",
"nmod",
"nmod",
"compound:lvc",
"case",
"amod",
"det",
"amod",
"nmod",
"root",
"compound",
"punct"
],
"start_char": [
0,
6,
12,
14,
18,
33,
37,
44,
50,
55,
64,
72,
78,
80,
91,
102,
109,
115,
120,
125,
129,
139,
146,
150,
158
],
"end_char": [
5,
12,
13,
17,
32,
36,
43,
49,
54,
63,
71,
78,
79,
90,
101,
108,
114,
119,
124,
128,
138,
145,
149,
158,
159
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Sonuç",
"olarak",
",",
"bir",
"kuruluşun",
"bir",
"engeli",
"aşmak",
"için",
"birlikte",
"çalışma",
"süreci",
",",
"müşterinin",
"ihtiyacına",
"hizmet",
"etmek",
"için",
"yeni",
"bir",
"yenilikçi",
"sürece",
"yol",
"açabilir",
"."
] | {
"lemma": [
"sonuç",
"olarak",
",",
"bir",
"kuruluş",
"bir",
"enge+li",
"aş",
"için",
"birlikte",
"çalış",
"süreç",
",",
"müşteri",
"ihtiyaç",
"hizmet",
"et",
"için",
"yeni",
"bir",
"yenilikçi",
"süre",
"yol",
"aç",
"."
],
"upos": [
"NOUN",
"ADP",
"PUNCT",
"DET",
"NOUN",
"DET",
"NOUN+ADP",
"VERB",
"ADP",
"ADP",
"VERB",
"NOUN",
"PUNCT",
"NOUN",
"NOUN",
"NOUN",
"VERB",
"ADP",
"ADJ",
"DET",
"ADJ",
"NOUN",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|Number=Sing|Person=3",
"",
"",
"Definite=Ind|PronType=Art",
"Case=Gen|Number=Sing|Person=3",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3+",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Gen|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"",
"Definite=Ind|PronType=Art",
"",
"Case=Dat|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Hab|Mood=Pot|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"24",
"1",
"1",
"5",
"9",
"7",
"9+7",
"24",
"9",
"9",
"13",
"24",
"13",
"16",
"17",
"23",
"17",
"17",
"23",
"23",
"23",
"24",
"0",
"24",
"24"
],
"deprel": [
"nmod",
"case",
"punct",
"det",
"nsubj",
"det",
"obl+case",
"nmod",
"case",
"case",
"nmod:poss",
"nsubj",
"punct",
"nmod:poss",
"nmod",
"nmod",
"compound:lvc",
"case",
"amod",
"det",
"amod",
"nmod",
"root",
"compound",
"punct"
],
"start_char": [
0,
6,
12,
14,
18,
28,
32,
39,
45,
50,
59,
67,
73,
75,
86,
97,
104,
110,
115,
120,
124,
134,
141,
145,
153
],
"end_char": [
5,
12,
13,
17,
27,
31,
38,
44,
49,
58,
66,
73,
74,
85,
96,
103,
109,
114,
119,
123,
133,
140,
144,
153,
154
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] | [
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] |
flores101-main-tur-103-pe1-4 | 672 | flores101-main-1034 | tur_t1 | tur | 103 | pe1 | pe | 145 | 141 | 133 | 21 | 17 | 17 | 27.347 | 64 | 21 | 0 | 3 | 0 | 37 | 3 | 0 | 0 | 0 | 0 | 6 | 24,666 | 5 | 24,233 | 27,347 | 1 | 1,643,316,842 | 0 | 1 | 3 | 0 | 0 | 4 | 20 | 0.1736 | 54.64 | 77.99 | 27.347 | 0.4558 | 0.0076 | 0.1886 | 1.3022 | 0.4414 | 2,764.4714 | 46.0745 | 24 | Before an organization can be innovative, leadership must create a culture of innovation as well as shared knowledge and organizational learning. | Bir organizasyonun yenilikçi olabilmesi için, liderlik, paylaşılan bilgi ve örgütsel öğrenmenin yanı sıra bir inovasyon kültürü yaratmalıdır. | Bir kuruluşun yenilikçi olabilmesi için liderler, paylaşılan bilgi ve örgütsel öğrenmenin yanı sıra bir yenilik kültürü yaratmalıdır. | REF: bir organizasyonun yenilikçi olabilmesi için , liderlik , paylaşılan bilgi ve örgütsel öğrenmenin yanı sıra bir inovasyon kültürü yaratmalıdır .\nHYP: bir kuruluşun yenilikçi olabilmesi için * liderler , paylaşılan bilgi ve örgütsel öğrenmenin yanı sıra bir yenilik kültürü yaratmalıdır .\nEVAL: S D S S | [
"Before",
"an",
"organization",
"can",
"be",
"innovative",
",",
"leadership",
"must",
"create",
"a",
"culture",
"of",
"innovation",
"as",
"well",
"as",
"shared",
"knowledge",
"and",
"organizational",
"learning",
"."
] | {
"lemma": [
"before",
"a",
"organization",
"can",
"be",
"innovative",
",",
"leadership",
"must",
"create",
"a",
"culture",
"of",
"innovation",
"as",
"well",
"as",
"share",
"knowledge",
"and",
"organizational",
"learning",
"."
],
"upos": [
"SCONJ",
"DET",
"NOUN",
"AUX",
"AUX",
"ADJ",
"PUNCT",
"NOUN",
"AUX",
"VERB",
"DET",
"NOUN",
"ADP",
"NOUN",
"ADV",
"ADV",
"ADP",
"VERB",
"NOUN",
"CCONJ",
"ADJ",
"NOUN",
"PUNCT"
],
"feats": [
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"VerbForm=Fin",
"VerbForm=Inf",
"Degree=Pos",
"",
"Number=Sing",
"VerbForm=Fin",
"VerbForm=Inf",
"Definite=Ind|PronType=Art",
"Number=Sing",
"",
"Number=Sing",
"ExtPos=CCONJ",
"Degree=Pos",
"",
"Tense=Past|VerbForm=Part",
"Number=Sing",
"",
"Degree=Pos",
"Number=Sing",
""
],
"head": [
"6",
"3",
"6",
"6",
"6",
"10",
"6",
"10",
"10",
"0",
"12",
"10",
"14",
"12",
"19",
"15",
"15",
"19",
"12",
"22",
"22",
"19",
"10"
],
"deprel": [
"mark",
"det",
"nsubj",
"aux",
"cop",
"advcl",
"punct",
"nsubj",
"aux",
"root",
"det",
"obj",
"case",
"nmod",
"cc",
"fixed",
"fixed",
"amod",
"conj",
"cc",
"amod",
"conj",
"punct"
],
"start_char": [
0,
7,
10,
23,
27,
30,
40,
42,
53,
58,
65,
67,
75,
78,
89,
92,
97,
100,
107,
117,
121,
136,
144
],
"end_char": [
6,
9,
22,
26,
29,
40,
41,
52,
57,
64,
66,
74,
77,
88,
91,
96,
99,
106,
116,
120,
135,
144,
145
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Bir",
"organizasyonun",
"yenilikçi",
"olabilmesi",
"için",
",",
"liderlik",
",",
"paylaşılan",
"bilgi",
"ve",
"örgütsel",
"öğrenmenin",
"yanı",
"sıra",
"bir",
"inovasyon",
"kültürü",
"yaratmalıdır",
"."
] | {
"lemma": [
"bir",
"organiza",
"yenilikçi",
"ol",
"için",
",",
"liderlik",
",",
"paylaş",
"bilgi",
"ve",
"örgütsel",
"öğren",
"yan",
"sıra",
"bir",
"inovasyon",
"kültür",
"yarat+i",
"."
],
"upos": [
"DET",
"NOUN",
"ADJ",
"VERB",
"ADP",
"PUNCT",
"NOUN",
"PUNCT",
"VERB",
"NOUN",
"CCONJ",
"ADJ",
"VERB",
"ADJ",
"NOUN",
"DET",
"NOUN",
"NOUN",
"VERB+AUX",
"PUNCT"
],
"feats": [
"Definite=Ind|PronType=Art",
"Case=Gen|Number=Sing|Person=3",
"",
"Aspect=Perf|Case=Nom|Mood=Pot|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part|Voice=Pass",
"Case=Nom|Number=Sing|Person=3",
"",
"",
"Aspect=Perf|Case=Gen|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"Case=Acc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun+Aspect=Perf|Mood=Gen|Number=Sing|Person=3|Tense=Pres",
""
],
"head": [
"2",
"4",
"4",
"15",
"4",
"4",
"14",
"7",
"10",
"7",
"13",
"13",
"7",
"15",
"0",
"18",
"18",
"19",
"15+19",
"19"
],
"deprel": [
"det",
"nmod:poss",
"obj",
"nmod",
"case",
"punct",
"nsubj",
"punct",
"acl",
"conj",
"cc",
"amod",
"conj",
"amod",
"root",
"det",
"nmod:poss",
"obj",
"conj+cop",
"punct"
],
"start_char": [
0,
4,
19,
29,
40,
44,
46,
54,
56,
67,
73,
76,
85,
96,
101,
106,
110,
120,
128,
140
],
"end_char": [
3,
18,
28,
39,
44,
45,
54,
55,
66,
72,
75,
84,
95,
100,
105,
109,
119,
127,
140,
141
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Bir",
"kuruluşun",
"yenilikçi",
"olabilmesi",
"için",
"liderler",
",",
"paylaşılan",
"bilgi",
"ve",
"örgütsel",
"öğrenmenin",
"yanı",
"sıra",
"bir",
"yenilik",
"kültürü",
"yaratmalıdır",
"."
] | {
"lemma": [
"bir",
"kuruluş",
"yenilikçi",
"ol",
"için",
"lider",
",",
"paylaş",
"bilgi",
"ve",
"örgütsel",
"öğren",
"yan",
"sıra",
"bir",
"yenilik",
"kültür",
"yarat+i",
"."
],
"upos": [
"DET",
"NOUN",
"ADJ",
"VERB",
"ADP",
"NOUN",
"PUNCT",
"VERB",
"NOUN",
"CCONJ",
"ADJ",
"VERB",
"ADJ",
"NOUN",
"DET",
"NOUN",
"NOUN",
"VERB+AUX",
"PUNCT"
],
"feats": [
"Definite=Ind|PronType=Art",
"Case=Gen|Number=Sing|Person=3",
"",
"Aspect=Perf|Case=Nom|Mood=Pot|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"Case=Nom|Number=Plur|Person=3",
"",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part|Voice=Pass",
"Case=Nom|Number=Sing|Person=3",
"",
"",
"Aspect=Perf|Case=Gen|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun+Aspect=Perf|Mood=Gen|Number=Sing|Person=3|Tense=Pres",
""
],
"head": [
"2",
"4",
"4",
"14",
"4",
"14",
"6",
"9",
"13",
"12",
"12",
"9",
"14",
"0",
"17",
"17",
"18",
"14+18",
"18"
],
"deprel": [
"det",
"nmod:poss",
"obj",
"nmod",
"case",
"nsubj",
"punct",
"acl",
"nmod:poss",
"cc",
"amod",
"conj",
"amod",
"root",
"det",
"nmod:poss",
"obj",
"conj+cop",
"punct"
],
"start_char": [
0,
4,
14,
24,
35,
40,
48,
50,
61,
67,
70,
79,
90,
95,
100,
104,
112,
120,
132
],
"end_char": [
3,
13,
23,
34,
39,
48,
49,
60,
66,
69,
78,
89,
94,
99,
103,
111,
119,
132,
133
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] | [
"OK",
"BAD",
"OK",
"OK",
"OK",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK"
] |
flores101-main-tur-103-pe1-5 | 673 | flores101-main-1035 | tur_t1 | tur | 103 | pe1 | pe | 127 | 167 | 162 | 20 | 19 | 19 | 19.762 | 36 | 14 | 0 | 1 | 0 | 19 | 2 | 0 | 0 | 0 | 0 | 2 | 15,484 | 1 | 15,140 | 19,762 | 1 | 1,643,316,842 | 0 | 0 | 1 | 0 | 0 | 1 | 4.167 | 0.0698 | 88.44 | 92.73 | 19.762 | 0.3294 | 0.0055 | 0.1556 | 0.9881 | 0.2835 | 3,643.3559 | 60.7226 | 25 | Angel (2006), explains the Continuum approach as a method being used to help organizations reach a higher level of performance. | Angel (2006), Süreklilik yaklaşımını, organizasyonların daha yüksek bir performans düzeyine ulaşmasına yardımcı olmak için kullanılan bir yöntem olarak açıklamaktadır. | Angel (2006), Süreklilik yaklaşımını, kuruluşların daha yüksek bir performans düzeyine ulaşmasına yardımcı olmak için kullanılan bir yöntem olarak açıklamaktadır. | REF: angel ( 2006 ) , süreklilik yaklaşımını , organizasyonların daha yüksek bir performans düzeyine ulaşmasına yardımcı olmak için kullanılan bir yöntem olarak açıklamaktadır .\nHYP: angel ( 2006 ) , süreklilik yaklaşımını , kuruluşların daha yüksek bir performans düzeyine ulaşmasına yardımcı olmak için kullanılan bir yöntem olarak açıklamaktadır .\nEVAL: S | [
"Angel",
"(",
"2006",
")",
",",
"explains",
"the",
"Continuum",
"approach",
"as",
"a",
"method",
"being",
"used",
"to",
"help",
"organizations",
"reach",
"a",
"higher",
"level",
"of",
"performance",
"."
] | {
"lemma": [
"Angel",
"(",
"2006",
")",
",",
"explain",
"the",
"Continuum",
"approach",
"as",
"a",
"method",
"be",
"use",
"to",
"help",
"organization",
"reach",
"a",
"high",
"level",
"of",
"performance",
"."
],
"upos": [
"PROPN",
"PUNCT",
"NUM",
"PUNCT",
"PUNCT",
"VERB",
"DET",
"PROPN",
"NOUN",
"ADP",
"DET",
"NOUN",
"AUX",
"VERB",
"PART",
"VERB",
"NOUN",
"VERB",
"DET",
"ADJ",
"NOUN",
"ADP",
"NOUN",
"PUNCT"
],
"feats": [
"Number=Sing",
"",
"NumForm=Digit|NumType=Card",
"",
"",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"Definite=Def|PronType=Art",
"Number=Sing",
"Number=Sing",
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"VerbForm=Ger",
"Tense=Past|VerbForm=Part|Voice=Pass",
"",
"VerbForm=Inf",
"Number=Plur",
"VerbForm=Inf",
"Definite=Ind|PronType=Art",
"Degree=Cmp",
"Number=Sing",
"",
"Number=Sing",
""
],
"head": [
"6",
"3",
"1",
"3",
"1",
"0",
"9",
"9",
"6",
"12",
"12",
"9",
"14",
"12",
"16",
"14",
"16",
"16",
"21",
"21",
"18",
"23",
"21",
"6"
],
"deprel": [
"nsubj",
"punct",
"nmod:tmod",
"punct",
"punct",
"root",
"det",
"compound",
"obj",
"case",
"det",
"nmod",
"aux:pass",
"acl",
"mark",
"xcomp",
"obj",
"xcomp",
"det",
"amod",
"obj",
"case",
"nmod",
"punct"
],
"start_char": [
0,
6,
7,
11,
12,
14,
23,
27,
37,
46,
49,
51,
58,
64,
69,
72,
77,
91,
97,
99,
106,
112,
115,
126
],
"end_char": [
5,
7,
11,
12,
13,
22,
26,
36,
45,
48,
50,
57,
63,
68,
71,
76,
90,
96,
98,
105,
111,
114,
126,
127
],
"ner": [
"B-ORG",
"I-ORG",
"I-ORG",
"E-ORG",
"O",
"O",
"O",
"S-PRODUCT",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Angel",
"(",
"2006",
")",
",",
"Süreklilik",
"yaklaşımını",
",",
"organizasyonların",
"daha",
"yüksek",
"bir",
"performans",
"düzeyine",
"ulaşmasına",
"yardımcı",
"olmak",
"için",
"kullanılan",
"bir",
"yöntem",
"olarak",
"açıklamaktadır",
"."
] | {
"lemma": [
"Angel",
"(",
"2006",
")",
",",
"süreklilik",
"yaklaşım",
",",
"organizasyon",
"daha",
"yüksek",
"bir",
"performans",
"düzey",
"ulaş",
"yardımcı",
"ol",
"için",
"kullan",
"bir",
"yöntem",
"olarak",
"açıkla",
"."
],
"upos": [
"PROPN",
"PUNCT",
"NOUN",
"PUNCT",
"PUNCT",
"NOUN",
"NOUN",
"PUNCT",
"NOUN",
"ADV",
"ADJ",
"DET",
"NOUN",
"NOUN",
"VERB",
"NOUN",
"VERB",
"ADP",
"VERB",
"DET",
"NOUN",
"ADP",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Acc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Gen|Number=Plur|Person=3",
"",
"",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Dat|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part|Voice=Pass",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"",
"Aspect=Prog|Mood=Gen|Number=Sing|Person=3|Polarity=Pos|Polite=Form|Tense=Pres",
""
],
"head": [
"7",
"3",
"1",
"3",
"3",
"7",
"15",
"7",
"15",
"11",
"13",
"13",
"14",
"15",
"16",
"21",
"16",
"16",
"21",
"21",
"23",
"21",
"0",
"23"
],
"deprel": [
"nmod:poss",
"punct",
"appos",
"punct",
"punct",
"nmod:poss",
"obj",
"punct",
"nmod:poss",
"advmod",
"amod",
"det",
"nmod:poss",
"obl",
"nmod",
"nmod",
"compound:lvc",
"case",
"acl",
"det",
"obl",
"case",
"root",
"punct"
],
"start_char": [
0,
6,
7,
11,
12,
14,
25,
36,
38,
56,
61,
68,
72,
83,
92,
103,
112,
118,
123,
134,
138,
145,
152,
166
],
"end_char": [
5,
7,
11,
12,
13,
24,
36,
37,
55,
60,
67,
71,
82,
91,
102,
111,
117,
122,
133,
137,
144,
151,
166,
167
],
"ner": [
"S-ORGANIZATION",
"O",
"S-TIME",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Angel",
"(",
"2006",
")",
",",
"Süreklilik",
"yaklaşımını",
",",
"kuruluşların",
"daha",
"yüksek",
"bir",
"performans",
"düzeyine",
"ulaşmasına",
"yardımcı",
"olmak",
"için",
"kullanılan",
"bir",
"yöntem",
"olarak",
"açıklamaktadır",
"."
] | {
"lemma": [
"Angel",
"(",
"2006",
")",
",",
"süreklilik",
"yaklaşım",
",",
"kuruluş",
"daha",
"yüksek",
"bir",
"performans",
"düzey",
"ulaş",
"yardımcı",
"ol",
"için",
"kullan",
"bir",
"yöntem",
"olarak",
"açıkla",
"."
],
"upos": [
"PROPN",
"PUNCT",
"NOUN",
"PUNCT",
"PUNCT",
"NOUN",
"NOUN",
"PUNCT",
"NOUN",
"ADV",
"ADJ",
"DET",
"NOUN",
"NOUN",
"VERB",
"NOUN",
"VERB",
"ADP",
"VERB",
"DET",
"NOUN",
"ADP",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Acc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Gen|Number=Plur|Person=3",
"",
"",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"Case=Dat|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Dat|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part|Voice=Pass",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"",
"Aspect=Prog|Mood=Gen|Number=Sing|Person=3|Polarity=Pos|Polite=Form|Tense=Pres",
""
],
"head": [
"7",
"3",
"1",
"3",
"3",
"7",
"15",
"7",
"15",
"11",
"13",
"13",
"14",
"15",
"16",
"21",
"16",
"16",
"21",
"21",
"23",
"21",
"0",
"23"
],
"deprel": [
"nmod:poss",
"punct",
"appos",
"punct",
"punct",
"nmod:poss",
"obj",
"punct",
"nmod:poss",
"advmod",
"amod",
"det",
"nmod:poss",
"obl",
"nmod",
"nmod",
"compound:lvc",
"case",
"acl",
"det",
"obl",
"case",
"root",
"punct"
],
"start_char": [
0,
6,
7,
11,
12,
14,
25,
36,
38,
51,
56,
63,
67,
78,
87,
98,
107,
113,
118,
129,
133,
140,
147,
161
],
"end_char": [
5,
7,
11,
12,
13,
24,
36,
37,
50,
55,
62,
66,
77,
86,
97,
106,
112,
117,
128,
132,
139,
146,
161,
162
],
"ner": [
"S-ORGANIZATION",
"O",
"S-TIME",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK"
] |
flores101-main-tur-104-ht-1 | 608 | flores101-main-1041 | tur_t1 | tur | 104 | ht | ht | 159 | null | 149 | 28 | null | 19 | 81.526 | 235 | 152 | 0 | 20 | 1 | 46 | 14 | 0 | 1 | 1 | 0 | 19 | 61,399 | 11 | 56,381 | 81,526 | 1 | 1,643,317,110 | null | null | null | null | null | null | null | null | null | null | 81.526 | 1.3588 | 0.0226 | 0.5127 | 2.9116 | 1.478 | 1,236.4154 | 20.6069 | 26 | Every morning, people leave small country towns in cars to go their workplace and are passed by others whose work destination is the place they have just left. | nan | Her sabah insanlar küçük kasabalardan arabalarına binip iş yerlerine gidiyor ve yolda, kendilerinin çıktığı yere gitmeye çalışanların yanından geçer. | nan | [
"Every",
"morning",
",",
"people",
"leave",
"small",
"country",
"towns",
"in",
"cars",
"to",
"go",
"their",
"workplace",
"and",
"are",
"passed",
"by",
"others",
"whose",
"work",
"destination",
"is",
"the",
"place",
"they",
"have",
"just",
"left",
"."
] | {
"lemma": [
"every",
"morning",
",",
"people",
"leave",
"small",
"country",
"town",
"in",
"car",
"to",
"go",
"they",
"workplace",
"and",
"be",
"pass",
"by",
"other",
"whose",
"work",
"destination",
"be",
"the",
"place",
"they",
"have",
"just",
"leave",
"."
],
"upos": [
"DET",
"NOUN",
"PUNCT",
"NOUN",
"VERB",
"ADJ",
"NOUN",
"NOUN",
"ADP",
"NOUN",
"PART",
"VERB",
"PRON",
"NOUN",
"CCONJ",
"AUX",
"VERB",
"ADP",
"NOUN",
"PRON",
"NOUN",
"NOUN",
"AUX",
"DET",
"NOUN",
"PRON",
"AUX",
"ADV",
"VERB",
"PUNCT"
],
"feats": [
"",
"Number=Sing",
"",
"Number=Plur",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"Degree=Pos",
"Number=Sing",
"Number=Plur",
"",
"Number=Plur",
"",
"VerbForm=Inf",
"Number=Plur|Person=3|Poss=Yes|PronType=Prs",
"Number=Sing",
"",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"Tense=Past|VerbForm=Part|Voice=Pass",
"",
"Number=Plur",
"Poss=Yes|PronType=Rel",
"Number=Sing",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"Definite=Def|PronType=Art",
"Number=Sing",
"Case=Nom|Number=Plur|Person=3|PronType=Prs",
"Mood=Ind|Number=Plur|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Tense=Past|VerbForm=Part",
""
],
"head": [
"2",
"5",
"2",
"5",
"0",
"8",
"8",
"5",
"10",
"8",
"12",
"5",
"14",
"12",
"17",
"17",
"5",
"19",
"17",
"22",
"22",
"25",
"25",
"25",
"19",
"29",
"29",
"29",
"25",
"5"
],
"deprel": [
"det",
"obl:tmod",
"punct",
"nsubj",
"root",
"amod",
"compound",
"obj",
"case",
"nmod",
"mark",
"advcl",
"nmod:poss",
"obj",
"cc",
"aux:pass",
"conj",
"case",
"obl",
"nmod:poss",
"compound",
"nsubj",
"cop",
"det",
"acl:relcl",
"nsubj",
"aux",
"advmod",
"acl:relcl",
"punct"
],
"start_char": [
0,
6,
13,
15,
22,
28,
34,
42,
48,
51,
56,
59,
62,
68,
78,
82,
86,
93,
96,
103,
109,
114,
126,
129,
133,
139,
144,
149,
154,
158
],
"end_char": [
5,
13,
14,
21,
27,
33,
41,
47,
50,
55,
58,
61,
67,
77,
81,
85,
92,
95,
102,
108,
113,
125,
128,
132,
138,
143,
148,
153,
158,
159
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Her",
"sabah",
"insanlar",
"küçük",
"kasabalardan",
"arabalarına",
"binip",
"iş",
"yerlerine",
"gidiyor",
"ve",
"yolda",
",",
"kendilerinin",
"çıktığı",
"yere",
"gitmeye",
"çalışanların",
"yanından",
"geçer",
"."
] | {
"lemma": [
"her",
"sabah",
"insan",
"küçük",
"kasaba",
"araba",
"bin",
"iş",
"yer",
"git",
"ve",
"yol",
",",
"kendi",
"çık",
"yer",
"git",
"çalış",
"yan",
"geç",
"."
],
"upos": [
"DET",
"NOUN",
"NOUN",
"ADJ",
"NOUN",
"NOUN",
"VERB",
"NOUN",
"NOUN",
"VERB",
"CCONJ",
"NOUN",
"PUNCT",
"PRON",
"VERB",
"NOUN",
"VERB",
"VERB",
"ADJ",
"VERB",
"PUNCT"
],
"feats": [
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Plur|Person=3",
"",
"Case=Abl|Number=Plur|Person=3",
"Case=Dat|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Conv",
"Case=Nom|Number=Sing|Person=3",
"Case=Dat|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=3",
"Aspect=Prog|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Polite=Infm|Tense=Pres",
"",
"Case=Loc|Number=Sing|Person=3",
"",
"Case=Gen|Number=Plur|Number[psor]=Plur|Person=3|Person[psor]=3|Reflex=Yes",
"Aspect=Perf|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"Case=Dat|Number=Sing|Person=3",
"Aspect=Perf|Case=Dat|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Aspect=Perf|Case=Gen|Mood=Ind|Number=Plur|Person=3|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Case=Abl|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Hab|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Pres",
""
],
"head": [
"2",
"7",
"7",
"5",
"6",
"7",
"10",
"9",
"10",
"0",
"20",
"20",
"12",
"15",
"16",
"17",
"20",
"19",
"20",
"10",
"20"
],
"deprel": [
"det",
"obl",
"nsubj",
"amod",
"nmod:poss",
"obl",
"nmod",
"nmod:poss",
"obl",
"root",
"cc",
"obl",
"punct",
"nmod:poss",
"acl",
"obl",
"nmod",
"nmod:poss",
"amod",
"conj",
"punct"
],
"start_char": [
0,
4,
10,
19,
25,
38,
50,
56,
59,
69,
77,
80,
85,
87,
100,
108,
113,
121,
134,
143,
148
],
"end_char": [
3,
9,
18,
24,
37,
49,
55,
58,
68,
76,
79,
85,
86,
99,
107,
112,
120,
133,
142,
148,
149
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-104-ht-2 | 609 | flores101-main-1042 | tur_t1 | tur | 104 | ht | ht | 127 | null | 117 | 19 | null | 16 | 45.705 | 146 | 111 | 0 | 17 | 1 | 10 | 7 | 0 | 0 | 0 | 0 | 17 | 31,725 | 9 | 27,773 | 45,705 | 1 | 1,643,317,110 | null | null | null | null | null | null | null | null | null | null | 45.705 | 0.7617 | 0.0127 | 0.3599 | 2.4055 | 1.1496 | 1,496.554 | 24.9426 | 27 | In this dynamic transport shuttle everyone is somehow connected with, and supporting, a transport system based on private cars. | nan | Bu dinamik ulaşım ortamında herkes, özel araçlara dayalı bir taşıma sistemiyle bağlantılıdır ve bu sistemi destekler. | nan | [
"In",
"this",
"dynamic",
"transport",
"shuttle",
"everyone",
"is",
"somehow",
"connected",
"with",
",",
"and",
"supporting",
",",
"a",
"transport",
"system",
"based",
"on",
"private",
"cars",
"."
] | {
"lemma": [
"in",
"this",
"dynamic",
"transport",
"shuttle",
"everyone",
"be",
"somehow",
"connect",
"with",
",",
"and",
"support",
",",
"a",
"transport",
"system",
"base",
"on",
"private",
"car",
"."
],
"upos": [
"ADP",
"DET",
"ADJ",
"NOUN",
"NOUN",
"PRON",
"AUX",
"ADV",
"VERB",
"ADP",
"PUNCT",
"CCONJ",
"VERB",
"PUNCT",
"DET",
"NOUN",
"NOUN",
"VERB",
"ADP",
"ADJ",
"NOUN",
"PUNCT"
],
"feats": [
"",
"Number=Sing|PronType=Dem",
"Degree=Pos",
"Number=Sing",
"Number=Sing",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Tense=Past|VerbForm=Part|Voice=Pass",
"",
"",
"",
"VerbForm=Ger",
"",
"Definite=Ind|PronType=Art",
"Number=Sing",
"Number=Sing",
"Tense=Past|VerbForm=Part",
"",
"Degree=Pos",
"Number=Plur",
""
],
"head": [
"5",
"5",
"5",
"5",
"9",
"9",
"9",
"9",
"0",
"9",
"13",
"13",
"9",
"17",
"17",
"17",
"13",
"17",
"21",
"21",
"18",
"9"
],
"deprel": [
"case",
"det",
"amod",
"compound",
"obl",
"nsubj:pass",
"aux:pass",
"advmod",
"root",
"obl",
"punct",
"cc",
"conj",
"punct",
"det",
"compound",
"obj",
"acl",
"case",
"amod",
"obl",
"punct"
],
"start_char": [
0,
3,
8,
16,
26,
34,
43,
46,
54,
64,
68,
70,
74,
84,
86,
88,
98,
105,
111,
114,
122,
126
],
"end_char": [
2,
7,
15,
25,
33,
42,
45,
53,
63,
68,
69,
73,
84,
85,
87,
97,
104,
110,
113,
121,
126,
127
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Bu",
"dinamik",
"ulaşım",
"ortamında",
"herkes",
",",
"özel",
"araçlara",
"dayalı",
"bir",
"taşıma",
"sistemiyle",
"bağlantılıdır",
"ve",
"bu",
"sistemi",
"destekler",
"."
] | {
"lemma": [
"bu",
"dinamik",
"ulaşım",
"ortam",
"herkes",
",",
"özel",
"araç",
"dayalı",
"bir",
"taşım",
"sistem",
"bağlantı+i",
"ve",
"bu",
"sistem",
"destek",
"."
],
"upos": [
"DET",
"ADJ",
"NOUN",
"NOUN",
"NOUN",
"PUNCT",
"ADJ",
"NOUN",
"ADJ",
"DET",
"NOUN",
"NOUN",
"NOUN+AUX",
"CCONJ",
"DET",
"NOUN",
"VERB",
"PUNCT"
],
"feats": [
"",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Loc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3",
"",
"",
"Case=Dat|Number=Plur|Person=3",
"",
"Definite=Ind|PronType=Art",
"Case=Nom|Number=Sing|Person=3",
"Case=Ins|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Case=Nom|Number=Sing|Person=3+Aspect=Perf|Mood=Gen|Number=Sing|Person=3|Tense=Pres",
"",
"",
"Case=Acc|Number=Sing|Person=3",
"Aspect=Hab|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Pres|Voice=Cau",
""
],
"head": [
"4",
"4",
"4",
"13",
"13",
"5",
"8",
"13",
"12",
"12",
"12",
"13",
"0+13",
"18",
"17",
"18",
"13",
"18"
],
"deprel": [
"det",
"amod",
"nmod:poss",
"nmod",
"nsubj",
"punct",
"amod",
"nmod",
"amod",
"det",
"nmod:poss",
"nmod",
"root+cop",
"cc",
"det",
"obj",
"conj",
"punct"
],
"start_char": [
0,
3,
11,
18,
28,
34,
36,
41,
50,
57,
61,
68,
79,
93,
96,
99,
107,
116
],
"end_char": [
2,
10,
17,
27,
34,
35,
40,
49,
56,
60,
67,
78,
92,
95,
98,
106,
116,
117
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-104-ht-3 | 610 | flores101-main-1043 | tur_t1 | tur | 104 | ht | ht | 179 | null | 175 | 29 | null | 21 | 132.587 | 317 | 171 | 0 | 27 | 4 | 100 | 12 | 1 | 1 | 1 | 0 | 33 | 112,188 | 17 | 104,517 | 132,587 | 1 | 1,643,317,110 | null | null | null | null | null | null | null | null | null | null | 132.587 | 2.2098 | 0.0368 | 0.7407 | 4.572 | 1.7709 | 787.4075 | 13.1235 | 28 | Science now indicates that this massive carbon economy has dislodged the biosphere from one of its stable states that has supported human evolution for the past two million years. | nan | Bilimsel çalışmalar, bu devasa karbon ekonomisinin, biyosferin iki milyon yıldan uzun zamandır insan evrimini destekleyen kararlı durumundan çıkmasına yol açtığını gösteriyor. | nan | [
"Science",
"now",
"indicates",
"that",
"this",
"massive",
"carbon",
"economy",
"has",
"dislodged",
"the",
"biosphere",
"from",
"one",
"of",
"its",
"stable",
"states",
"that",
"has",
"supported",
"human",
"evolution",
"for",
"the",
"past",
"two",
"million",
"years",
"."
] | {
"lemma": [
"science",
"now",
"indicate",
"that",
"this",
"massive",
"carbon",
"economy",
"have",
"dislodge",
"the",
"biosphere",
"from",
"one",
"of",
"its",
"stable",
"state",
"that",
"have",
"support",
"human",
"evolution",
"for",
"the",
"past",
"two",
"million",
"year",
"."
],
"upos": [
"NOUN",
"ADV",
"VERB",
"SCONJ",
"DET",
"ADJ",
"NOUN",
"NOUN",
"AUX",
"VERB",
"DET",
"NOUN",
"ADP",
"NUM",
"ADP",
"PRON",
"ADJ",
"NOUN",
"PRON",
"AUX",
"VERB",
"ADJ",
"NOUN",
"ADP",
"DET",
"ADJ",
"NUM",
"NUM",
"NOUN",
"PUNCT"
],
"feats": [
"Number=Sing",
"",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"",
"Number=Sing|PronType=Dem",
"Degree=Pos",
"Number=Sing",
"Number=Sing",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"Tense=Past|VerbForm=Part",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"NumForm=Word|NumType=Card",
"",
"Gender=Neut|Number=Sing|Person=3|Poss=Yes|PronType=Prs",
"Degree=Pos",
"Number=Plur",
"PronType=Rel",
"Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",
"Tense=Past|VerbForm=Part",
"Degree=Pos",
"Number=Sing",
"",
"Definite=Def|PronType=Art",
"Degree=Pos",
"NumForm=Word|NumType=Card",
"NumForm=Word|NumType=Card",
"Number=Plur",
""
],
"head": [
"3",
"3",
"0",
"10",
"8",
"8",
"8",
"10",
"10",
"3",
"12",
"10",
"14",
"10",
"18",
"18",
"18",
"14",
"21",
"21",
"18",
"23",
"21",
"29",
"29",
"29",
"28",
"29",
"21",
"3"
],
"deprel": [
"nsubj",
"advmod",
"root",
"mark",
"det",
"amod",
"compound",
"nsubj",
"aux",
"ccomp",
"det",
"obj",
"case",
"obl",
"case",
"nmod:poss",
"amod",
"nmod",
"nsubj",
"aux",
"acl:relcl",
"amod",
"obj",
"case",
"det",
"amod",
"compound",
"nummod",
"obl",
"punct"
],
"start_char": [
0,
8,
12,
22,
27,
32,
40,
47,
55,
59,
69,
73,
83,
88,
92,
95,
99,
106,
113,
118,
122,
132,
138,
148,
152,
156,
161,
165,
173,
178
],
"end_char": [
7,
11,
21,
26,
31,
39,
46,
54,
58,
68,
72,
82,
87,
91,
94,
98,
105,
112,
117,
121,
131,
137,
147,
151,
155,
160,
164,
172,
178,
179
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"S-CARDINAL",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"B-DATE",
"I-DATE",
"I-DATE",
"I-DATE",
"E-DATE",
"O"
]
} | [] | {
"lemma": [],
"upos": [],
"feats": [],
"head": [],
"deprel": [],
"start_char": [],
"end_char": [],
"ner": []
} | [
"Bilimsel",
"çalışmalar",
",",
"bu",
"devasa",
"karbon",
"ekonomisinin",
",",
"biyosferin",
"iki",
"milyon",
"yıldan",
"uzun",
"zamandır",
"insan",
"evrimini",
"destekleyen",
"kararlı",
"durumundan",
"çıkmasına",
"yol",
"açtığını",
"gösteriyor",
"."
] | {
"lemma": [
"bilimsel",
"çalış",
",",
"bu",
"devasa",
"karbon",
"ekonomi",
",",
"biyosferin",
"iki",
"milyon",
"yıl",
"uzun",
"zaman+dir",
"insan",
"evrim",
"destekle",
"kararlı",
"durum",
"çık",
"yol",
"aç",
"göster",
"."
],
"upos": [
"ADJ",
"VERB",
"PUNCT",
"DET",
"NOUN",
"NOUN",
"NOUN",
"PUNCT",
"NOUN",
"NUM",
"NUM",
"NOUN",
"ADJ",
"NOUN+ADP",
"NOUN",
"NOUN",
"VERB",
"ADJ",
"NOUN",
"VERB",
"NOUN",
"VERB",
"VERB",
"PUNCT"
],
"feats": [
"",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Gen|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"",
"Case=Gen|Number=Sing|Person=3",
"NumType=Card",
"NumType=Card",
"Case=Abl|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3+",
"Case=Nom|Number=Sing|Person=3",
"Case=Acc|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part|Voice=Cau",
"",
"Case=Abl|Number=Sing|Number[psor]=Sing|Person=3|Person[psor]=3",
"Aspect=Perf|Case=Dat|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Case=Nom|Number=Sing|Person=3",
"Aspect=Perf|Case=Acc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part",
"Aspect=Prog|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Polite=Infm|Tense=Pres",
""
],
"head": [
"2",
"24",
"2",
"5",
"7",
"7",
"22",
"7",
"7",
"12",
"10",
"14",
"14",
"18+14",
"17",
"18",
"20",
"20",
"21",
"22",
"24",
"22",
"0",
"24"
],
"deprel": [
"amod",
"nsubj",
"punct",
"det",
"nmod:poss",
"nmod:poss",
"nmod",
"punct",
"conj",
"nummod",
"flat",
"nmod",
"amod",
"obl+case",
"nmod:poss",
"obj",
"acl",
"amod",
"obl",
"nmod",
"obj",
"compound",
"root",
"punct"
],
"start_char": [
0,
9,
19,
21,
24,
31,
38,
50,
52,
63,
67,
74,
81,
86,
95,
101,
110,
122,
130,
141,
151,
155,
164,
174
],
"end_char": [
8,
19,
20,
23,
30,
37,
50,
51,
62,
66,
73,
80,
85,
94,
100,
109,
121,
129,
140,
150,
154,
163,
174,
175
],
"ner": [
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [] | [] |
flores101-main-tur-105-pe2-1 | 267 | flores101-main-1051 | tur_t1 | tur | 105 | pe2 | pe | 135 | 121 | 118 | 21 | 17 | 17 | 20.462 | 36 | 11 | 0 | 3 | 0 | 21 | 1 | 0 | 0 | 0 | 0 | 4 | 18,884 | 3 | 18,314 | 20,462 | 1 | 1,643,317,392 | 0 | 0 | 2 | 1 | 2 | 3 | 15.789 | 0.0952 | 54.42 | 87.45 | 20.462 | 0.341 | 0.0057 | 0.1516 | 0.9744 | 0.2667 | 3,694.6535 | 61.5776 | 29 | The Director of Public Prosecutions, Kier Starmer QC, gave a statement this morning announcing the prosecution of both Huhne and Pryce. | Başsavcılık Direktörü Kier Starmer QC, hem Huhne hem de Pryce'nin kovuşturulduğunu duyurarak bu sabah bir açıklama yaptı. | Başsavcılık Direktörü Kier Starmer QC, bu sabah hem Huhne hem de Pryce'ın kovuşturulduğunu duyuran bir açıklama yaptı. | REF: başsavcılık direktörü kier starmer qc , hem huhne hem de pryce'nin kovuşturulduğunu duyurarak bu sabah bir açıklama yaptı .\nHYP: başsavcılık direktörü kier starmer qc , @ hem huhne hem de pryce'ın kovuşturulduğunu duyuran [ bu sabah ] bir açıklama yaptı .\nEVAL: S S | [
"The",
"Director",
"of",
"Public",
"Prosecutions",
",",
"Kier",
"Starmer",
"QC",
",",
"gave",
"a",
"statement",
"this",
"morning",
"announcing",
"the",
"prosecution",
"of",
"both",
"Huhne",
"and",
"Pryce",
"."
] | {
"lemma": [
"the",
"Director",
"of",
"Public",
"Prosecution",
",",
"Kier",
"Starmer",
"QC",
",",
"give",
"a",
"statement",
"this",
"morning",
"announce",
"the",
"prosecution",
"of",
"both",
"Huhne",
"and",
"Pryce",
"."
],
"upos": [
"DET",
"PROPN",
"ADP",
"ADJ",
"PROPN",
"PUNCT",
"PROPN",
"PROPN",
"PROPN",
"PUNCT",
"VERB",
"DET",
"NOUN",
"DET",
"NOUN",
"VERB",
"DET",
"NOUN",
"ADP",
"CCONJ",
"PROPN",
"CCONJ",
"PROPN",
"PUNCT"
],
"feats": [
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"Degree=Pos",
"Number=Plur",
"",
"Number=Sing",
"Number=Sing",
"Number=Sing",
"",
"Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin",
"Definite=Ind|PronType=Art",
"Number=Sing",
"Number=Sing|PronType=Dem",
"Number=Sing",
"VerbForm=Ger",
"Definite=Def|PronType=Art",
"Number=Sing",
"",
"",
"Number=Sing",
"",
"Number=Sing",
""
],
"head": [
"2",
"11",
"5",
"5",
"2",
"7",
"2",
"7",
"7",
"2",
"0",
"13",
"11",
"15",
"11",
"11",
"18",
"16",
"21",
"21",
"18",
"23",
"21",
"11"
],
"deprel": [
"det",
"nsubj",
"case",
"amod",
"nmod",
"punct",
"appos",
"flat",
"flat",
"punct",
"root",
"det",
"obj",
"det",
"obl:tmod",
"advcl",
"det",
"obj",
"case",
"cc:preconj",
"nmod",
"cc",
"conj",
"punct"
],
"start_char": [
0,
4,
13,
16,
23,
35,
37,
42,
50,
52,
54,
59,
61,
71,
76,
84,
95,
99,
111,
114,
119,
125,
129,
134
],
"end_char": [
3,
12,
15,
22,
35,
36,
41,
49,
52,
53,
58,
60,
70,
75,
83,
94,
98,
110,
113,
118,
124,
128,
134,
135
],
"ner": [
"O",
"O",
"O",
"B-ORG",
"E-ORG",
"O",
"B-PERSON",
"I-PERSON",
"E-PERSON",
"O",
"O",
"O",
"O",
"B-TIME",
"E-TIME",
"O",
"O",
"O",
"O",
"O",
"S-PERSON",
"O",
"S-PERSON",
"O"
]
} | [
"Başsavcılık",
"Direktörü",
"Kier",
"Starmer",
"QC",
",",
"hem",
"Huhne",
"hem",
"de",
"Pryce'nin",
"kovuşturulduğunu",
"duyurarak",
"bu",
"sabah",
"bir",
"açıklama",
"yaptı",
"."
] | {
"lemma": [
"başsavcılık",
"direktör",
"Kier",
"Starmer",
"QC",
",",
"hem",
"Huhne",
"hem",
"de",
"Pryce",
"kovuş",
"duyur",
"bu",
"sabah",
"bir",
"açıkla",
"yap",
"."
],
"upos": [
"NOUN",
"NOUN",
"PROPN",
"PROPN",
"NOUN",
"PUNCT",
"CCONJ",
"PROPN",
"CCONJ",
"CCONJ",
"PROPN",
"VERB",
"VERB",
"DET",
"NOUN",
"DET",
"VERB",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|Number=Sing|Person=3",
"Case=Acc|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"",
"Case=Gen|Number=Sing|Person=3",
"Aspect=Perf|Case=Acc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part|Voice=Pass",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Conv",
"",
"Case=Nom|Number=Sing|Person=3",
"Definite=Ind|PronType=Art",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
""
],
"head": [
"2",
"3",
"5",
"3",
"13",
"5",
"12",
"5",
"11",
"8",
"8",
"13",
"18",
"15",
"17",
"17",
"18",
"0",
"18"
],
"deprel": [
"compound",
"nmod",
"nmod",
"flat",
"nsubj",
"punct",
"cc",
"conj",
"cc",
"advmod:emph",
"conj",
"obj",
"nmod",
"det",
"obl",
"det",
"obj",
"root",
"punct"
],
"start_char": [
0,
12,
22,
27,
35,
37,
39,
43,
49,
53,
56,
66,
83,
93,
96,
102,
106,
115,
120
],
"end_char": [
11,
21,
26,
34,
37,
38,
42,
48,
52,
55,
65,
82,
92,
95,
101,
105,
114,
120,
121
],
"ner": [
"O",
"O",
"B-ORGANIZATION",
"I-ORGANIZATION",
"E-ORGANIZATION",
"O",
"O",
"S-ORGANIZATION",
"O",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"Başsavcılık",
"Direktörü",
"Kier",
"Starmer",
"QC",
",",
"bu",
"sabah",
"hem",
"Huhne",
"hem",
"de",
"Pryce'ın",
"kovuşturulduğunu",
"duyuran",
"bir",
"açıklama",
"yaptı",
"."
] | {
"lemma": [
"başsavcılık",
"direktör",
"Kier",
"Starmer",
"QC",
",",
"bu",
"sabah",
"hem",
"Huhne",
"hem",
"de",
"Pryce",
"kovuş",
"duyur",
"bir",
"açıkla",
"yap",
"."
],
"upos": [
"NOUN",
"NOUN",
"PROPN",
"PROPN",
"NOUN",
"PUNCT",
"DET",
"NOUN",
"CCONJ",
"PROPN",
"CCONJ",
"CCONJ",
"PROPN",
"VERB",
"VERB",
"DET",
"VERB",
"VERB",
"PUNCT"
],
"feats": [
"Case=Nom|Number=Sing|Person=3",
"Case=Acc|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Case=Nom|Number=Sing|Person=3",
"Abbr=Yes|Case=Nom|Number=Sing|Person=3",
"",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"Case=Nom|Number=Sing|Person=3",
"",
"",
"Case=Gen|Number=Sing|Person=3",
"Aspect=Perf|Case=Acc|Mood=Ind|Number[psor]=Sing|Person[psor]=3|Polarity=Pos|Tense=Past|VerbForm=Part|Voice=Pass",
"Aspect=Perf|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Part",
"Definite=Ind|PronType=Art",
"Aspect=Perf|Case=Nom|Mood=Ind|Polarity=Pos|Tense=Pres|VerbForm=Vnoun",
"Aspect=Perf|Mood=Ind|Number=Sing|Person=3|Polarity=Pos|Tense=Past",
""
],
"head": [
"17",
"1",
"5",
"3",
"17",
"5",
"8",
"14",
"10",
"8",
"13",
"10",
"10",
"15",
"17",
"17",
"0",
"17",
"17"
],
"deprel": [
"nsubj",
"compound",
"nmod",
"flat",
"nsubj",
"punct",
"det",
"obl",
"cc",
"conj",
"cc",
"advmod:emph",
"conj",
"obj",
"acl",
"det",
"root",
"compound:lvc",
"punct"
],
"start_char": [
0,
12,
22,
27,
35,
37,
39,
42,
48,
52,
58,
62,
65,
74,
91,
99,
103,
112,
117
],
"end_char": [
11,
21,
26,
34,
37,
38,
41,
47,
51,
57,
61,
64,
73,
90,
98,
102,
111,
117,
118
],
"ner": [
"O",
"O",
"B-ORGANIZATION",
"I-ORGANIZATION",
"E-ORGANIZATION",
"O",
"O",
"O",
"O",
"S-ORGANIZATION",
"O",
"O",
"S-ORGANIZATION",
"O",
"O",
"O",
"O",
"O",
"O"
]
} | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"BAD",
"OK"
] | [
"OK",
"OK",
"OK",
"OK",
"OK",
"OK",
"BAD",
"OK",
"OK",
"OK",
"BAD",
"OK",
"BAD",
"BAD",
"BAD",
"OK",
"OK",
"OK",
"OK",
"OK"
] |
Dataset Card for DivEMT
For more details on DivEMT, see our EMNLP 2022 Paper and our Github repository
Gabriele Sarti • Arianna Bisazza • Ana Guerberof Arenas • Antonio Toral
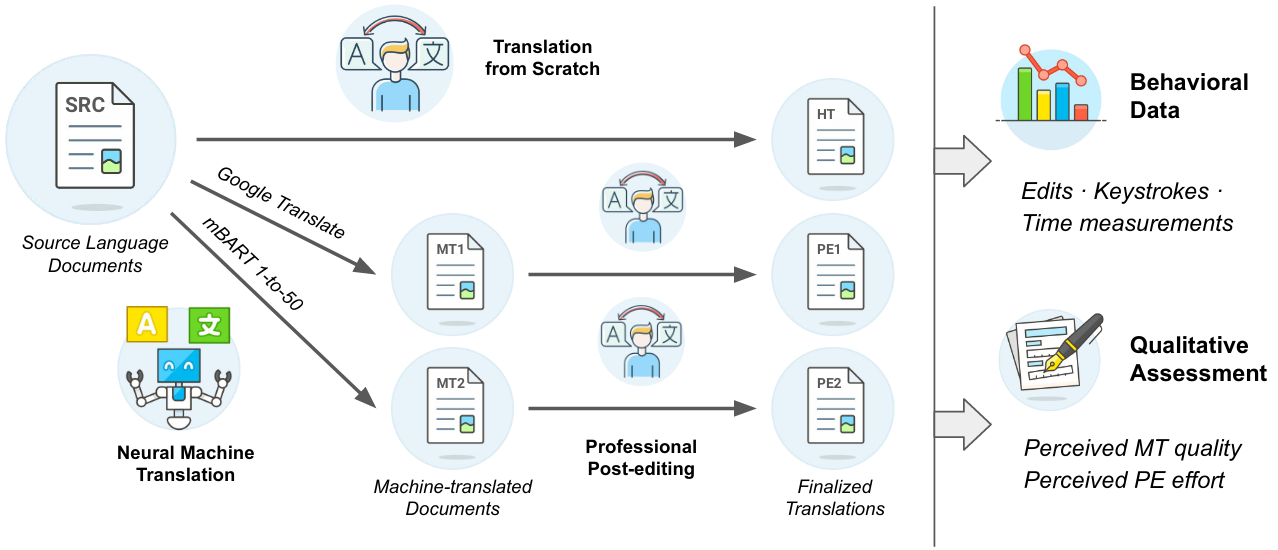
We introduce DivEMT, the first publicly available post-editing study of Neural Machine Translation (NMT) over a typologically diverse set of target languages. Using a strictly controlled setup, 18 professional translators were instructed to translate or post-edit the same set of English documents into Arabic, Dutch, Italian, Turkish, Ukrainian, and Vietnamese. During the process, their edits, keystrokes, editing times and pauses were recorded, enabling an in-depth, cross-lingual evaluation of NMT quality and post-editing effectiveness. Using this new dataset, we assess the impact of two state-of-the-art NMT systems, Google Translate and the multilingual mBART-50 model, on translation productivity. We find that post-editing is consistently faster than translation from scratch. However, the magnitude of productivity gains varies widely across systems and languages, highlighting major disparities in post-editing effectiveness for languages at different degrees of typological relatedness to English, even when controlling for system architecture and training data size. We publicly release the complete dataset including all collected behavioral data, to foster new research on the translation capabilities of NMT systems for typologically diverse languages.
Dataset Summary
This dataset contains the processed warmup and main splits of the DivEMT dataset. A sample of documents extracted from the Flores-101 corpus were either translated from scratch or post-edited from an existing automatic translation by a total of 18 professional translators across six typologically diverse languages (Arabic, Dutch, Italian, Turkish, Ukrainian, Vietnamese). During the translation, behavioral data (keystrokes, pauses, editing times) were collected using the PET platform.
We publicly release the processed dataset including all collected behavioural data, to foster new research on the ability of state-of-the-art NMT systems to generate text in typologically diverse languages.
News 🎉
February, 2023: The DivEMT dataset now contains linguistic annotations (*_annotations fields) computed with Stanza and word-level quality estimation tags (src_wmt22_qe, mt_wmt22_qe) obtained using the same scripts adopted for the WMT22 QE Task 2.
Languages
The language data of DivEMT is in English (BCP-47 en), Italian (BCP-47 it), Dutch (BCP-47 nl), Arabic (BCP-47 ar), Turkish (BCP-47 tr), Ukrainian (BCP-47 uk) and Vietnamese (BCP-47 vi)
Dataset Structure
Data Instances
The dataset contains two configurations: main and warmup. main contains the full data collected during the main task and analyzed during our experiments. warmup contains the data collected in the verification phase, before the main task begins.
Data Fields
The following fields are contained in the training set:
| Field | Description |
|---|---|
unit_id |
The full entry identifier. Format: flores101-{config}-{lang}-{doc_id}-{modality}-{sent_in_doc_num} |
flores_id |
Index of the sentence in the original Flores-101 dataset |
item_id |
The sentence identifier. The first digits of the number represent the document containing the sentence, while the last digit of the number represents the sentence position inside the document. Documents can contain from 3 to 5 contiguous sentences each. |
subject_id |
The identifier for the translator performing the translation from scratch or post-editing task. Values: t1, t2 or t3. |
lang_id |
Language identifier for the sentence, using Flores-101 three-letter format (e.g. ara, nld) |
doc_id |
Document identifier for the sentence |
task_type |
The modality of the translation task. Values: ht (translation from scratch), pe1 (post-editing Google Translate translations), pe2 (post-editing mBART 1-to-50 translations). |
translation_type |
Either ht for from scratch or pe for post-editing |
src_len_chr |
Length of the English source text in number of characters |
mt_len_chr |
Length of the machine translation in number of characters (NaN for ht) |
tgt_len_chr |
Length of the target text in number of characters |
src_len_wrd |
Length of the English source text in number of words |
mt_len_wrd |
Length of the machine translation in number of words (NaN for ht) |
tgt_len_wrd |
Length of the target text in number of words |
edit_time |
Total editing time for the translation in seconds. |
k_total |
Total number of keystrokes for the translation. |
k_letter |
Total number of letter keystrokes for the translation. |
k_digit |
Total number of digit keystrokes for the translation. |
k_white |
Total number of whitespace keystrokes for the translation. |
k_symbol |
Total number of symbol (punctuation, etc.) keystrokes for the translation. |
k_nav |
Total number of navigation keystrokes (left-right arrows, mouse clicks) for the translation. |
k_erase |
Total number of erase keystrokes (backspace, cancel) for the translation. |
k_copy |
Total number of copy (Ctrl + C) actions during the translation. |
k_cut |
Total number of cut (Ctrl + X) actions during the translation. |
k_paste |
Total number of paste (Ctrl + V) actions during the translation. |
k_do |
Total number of Enter actions during the translation. |
n_pause_geq_300 |
Number of pauses of 300ms or more during the translation. |
len_pause_geq_300 |
Total duration of pauses of 300ms or more, in milliseconds. |
n_pause_geq_1000 |
Number of pauses of 1s or more during the translation. |
len_pause_geq_1000 |
Total duration of pauses of 1000ms or more, in milliseconds. |
event_time |
Total time summed across all translation events, should be comparable to edit_time in most cases. |
num_annotations |
Number of times the translator focused the textbox for performing the translation of the sentence during the translation session. E.g. 1 means the translation was performed once and never revised. |
n_insert |
Number of post-editing insertions (empty for modality ht) computed using the tercom library. |
n_delete |
Number of post-editing deletions (empty for modality ht) computed using the tercom library. |
n_substitute |
Number of post-editing substitutions (empty for modality ht) computed using the tercom library. |
n_shift |
Number of post-editing shifts (empty for modality ht) computed using the tercom library. |
tot_shifted_words |
Total amount of shifted words from all shifts present in the sentence. |
tot_edits |
Total of all edit types for the sentence. |
hter |
Human-mediated Translation Edit Rate score computed between MT and post-edited TGT (empty for modality ht) using the tercom library. |
cer |
Character-level HTER score computed between MT and post-edited TGT (empty for modality ht) using CharacTER. |
bleu |
Sentence-level BLEU score between MT and post-edited TGT (empty for modality ht) computed using the SacreBLEU library with default parameters. |
chrf |
Sentence-level chrF score between MT and post-edited TGT (empty for modality ht) computed using the SacreBLEU library with default parameters. |
time_s |
Edit time expressed in seconds. |
time_m |
Edit time expressed in minutes. |
time_h |
Edit time expressed in hours. |
time_per_char |
Edit time per source character, expressed in seconds. |
time_per_word |
Edit time per source word, expressed in seconds. |
key_per_char |
Proportion of keys per character needed to perform the translation. |
words_per_hour |
Amount of source words translated or post-edited per hour. |
words_per_minute |
Amount of source words translated or post-edited per minute. |
per_subject_visit_order |
Id denoting the order in which the translator accessed documents. 1 correspond to the first accessed document. |
src_text |
The original source sentence extracted from Wikinews, wikibooks or wikivoyage. |
mt_text |
Missing if tasktype is ht. Otherwise, contains the automatically-translated sentence before post-editing. |
tgt_text |
Final sentence produced by the translator (either via translation from scratch of sl_text or post-editing mt_text) |
aligned_edit |
Aligned visual representation of REF (mt_text), HYP (tl_text) and edit operations (I = Insertion, D = Deletion, S = Substitution) performed on the field. Replace \\n with \n to show the three aligned rows. |
src_tokens |
List of tokens obtained tokenizing src_text with Stanza using default params. |
src_annotations |
List of lists (one per src_tokens token) containing dictionaries (one per word, >1 for mwt) with pos, ner and other info parsed by Stanza |
mt_tokens |
List of tokens obtained tokenizing mt_text with Stanza using default params. |
mt_annotations |
List of lists (one per mt_tokens token) containing dictionaries (one per word, >1 for mwt) with pos, ner and other info parsed by Stanza |
tgt_tokens |
List of tokens obtained tokenizing tgt_text with Stanza using default params. |
tgt_annotations |
List of lists (one per tgt_tokens token) containing dictionaries (one per word, >1 for mwt) with pos, ner and other info parsed by Stanza |
Data Splits
| config | train |
|---|---|
main |
7740 (107 docs i.e. 430 sents x 18 translators) |
warmup |
360 (5 docs i.e. 20 sents x 18 translators) |
Train Split
The train split contains the totality of triplets (or pairs, when translation from scratch is performed) annotated with behavioral data produced during the translation.
The following is an example of the subject t1 post-editing a machine translation produced by Google Translate (task_type pe1) taken from the train split for Turkish. The field aligned_edit is showed over three lines to provide a visual understanding of its contents.
{
'unit_id': 'flores101-main-tur-46-pe1-3',
'flores_id': 871,
'item_id': 'flores101-main-463',
'subject_id': 'tur_t1',
'task_type': 'pe1',
'translation_type': 'pe',
'src_len_chr': 109,
'mt_len_chr': 129.0,
'tgt_len_chr': 120,
'src_len_wrd': 17,
'mt_len_wrd': 15.0,
'tgt_len_wrd': 13,
'edit_time': 11.762999534606934,
'k_total': 31,
'k_letter': 9,
'k_digit': 0,
'k_white': 0,
'k_symbol': 0,
'k_nav': 20,
'k_erase': 2,
'k_copy': 0,
'k_cut': 0,
'k_paste': 0,
'k_do': 0,
'n_pause_geq_300': 2,
'len_pause_geq_300': 4986,
'n_pause_geq_1000': 1,
'len_pause_geq_1000': 4490,
'event_time': 11763,
'num_annotations': 2,
'last_modification_time': 1643569484,
'n_insert': 0.0,
'n_delete': 2.0,
'n_substitute': 1.0,
'n_shift': 0.0,
'tot_shifted_words': 0.0,
'tot_edits': 3.0,
'hter': 20.0,
'cer': 0.10,
'bleu': 0.0,
'chrf': 2.569999933242798,
'lang_id': 'tur',
'doc_id': 46,
'time_s': 11.762999534606934,
'time_m': 0.1960500031709671,
'time_h': 0.0032675000838935375,
'time_per_char': 0.1079174280166626,
'time_per_word': 0.6919412016868591,
'key_per_char': 0.2844036817550659,
'words_per_hour': 5202.75439453125,
'words_per_minute': 86.71257019042969,
'per_subject_visit_order': 201,
'src_text': 'As one example, American citizens in the Middle East might face different situations from Europeans or Arabs.',
'mt_text': "Bir örnek olarak, Orta Doğu'daki Amerikan vatandaşları, Avrupalılardan veya Araplardan farklı durumlarla karşı karşıya kalabilir.",
'tgt_text': "Örneğin, Orta Doğu'daki Amerikan vatandaşları, Avrupalılardan veya Araplardan farklı durumlarla karşı karşıya kalabilir.",
'aligned_edit': "REF: bir örnek olarak, orta doğu'daki amerikan vatandaşları, avrupalılardan veya araplardan farklı durumlarla karşı karşıya kalabilir.\\n
HYP: *** ***** örneğin, orta doğu'daki amerikan vatandaşları, avrupalılardan veya araplardan farklı durumlarla karşı karşıya kalabilir.\\n
EVAL: D D S"
}
The text is provided as-is, without further preprocessing or tokenization.
Dataset Creation
The dataset was parsed from PET XML files into CSV format using the scripts available in the DivEMT Github repository.
Those are adapted from the ones by Antonio Toral found at the following link: https://github.com/antot/postediting_novel_frontiers.
Additional Information
Dataset Curators
For problems related to this 🤗 Datasets version, please contact me at [email protected].
Citation Information
@inproceedings{sarti-etal-2022-divemt,
title = "{D}iv{EMT}: Neural Machine Translation Post-Editing Effort Across Typologically Diverse Languages",
author = "Sarti, Gabriele and
Bisazza, Arianna and
Guerberof-Arenas, Ana and
Toral, Antonio",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.532",
pages = "7795--7816",
}
- Downloads last month
- 147