
Updating to include DMT evals on dataset
#4
by
Ezi
- opened
- README.md +17 -0
- assets/DMT_eval.png +3 -0
README.md
CHANGED
|
@@ -100,6 +100,23 @@ There is only one split, `train`, that contains 141,047,697 documents.
|
|
| 100 |
|
| 101 |
`OBELICS` with images replaced by their URLs weighs 666.6 GB (😈) in arrow format and 377 GB in the uploaded `parquet` format.
|
| 102 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 103 |
## Opted-out content
|
| 104 |
|
| 105 |
To respect the preferences of content creators, we removed from OBELICS all images for which creators explicitly opted out of AI model training. We used the [Spawning API](https://api.spawning.ai/spawning-api) to verify that the images in the dataset respect the original copyright owners’ choices.
|
|
|
|
| 100 |
|
| 101 |
`OBELICS` with images replaced by their URLs weighs 666.6 GB (😈) in arrow format and 377 GB in the uploaded `parquet` format.
|
| 102 |
|
| 103 |
+
|
| 104 |
+
## Considerations for Using the Data
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
### Discussion of Biases
|
| 108 |
+
|
| 109 |
+
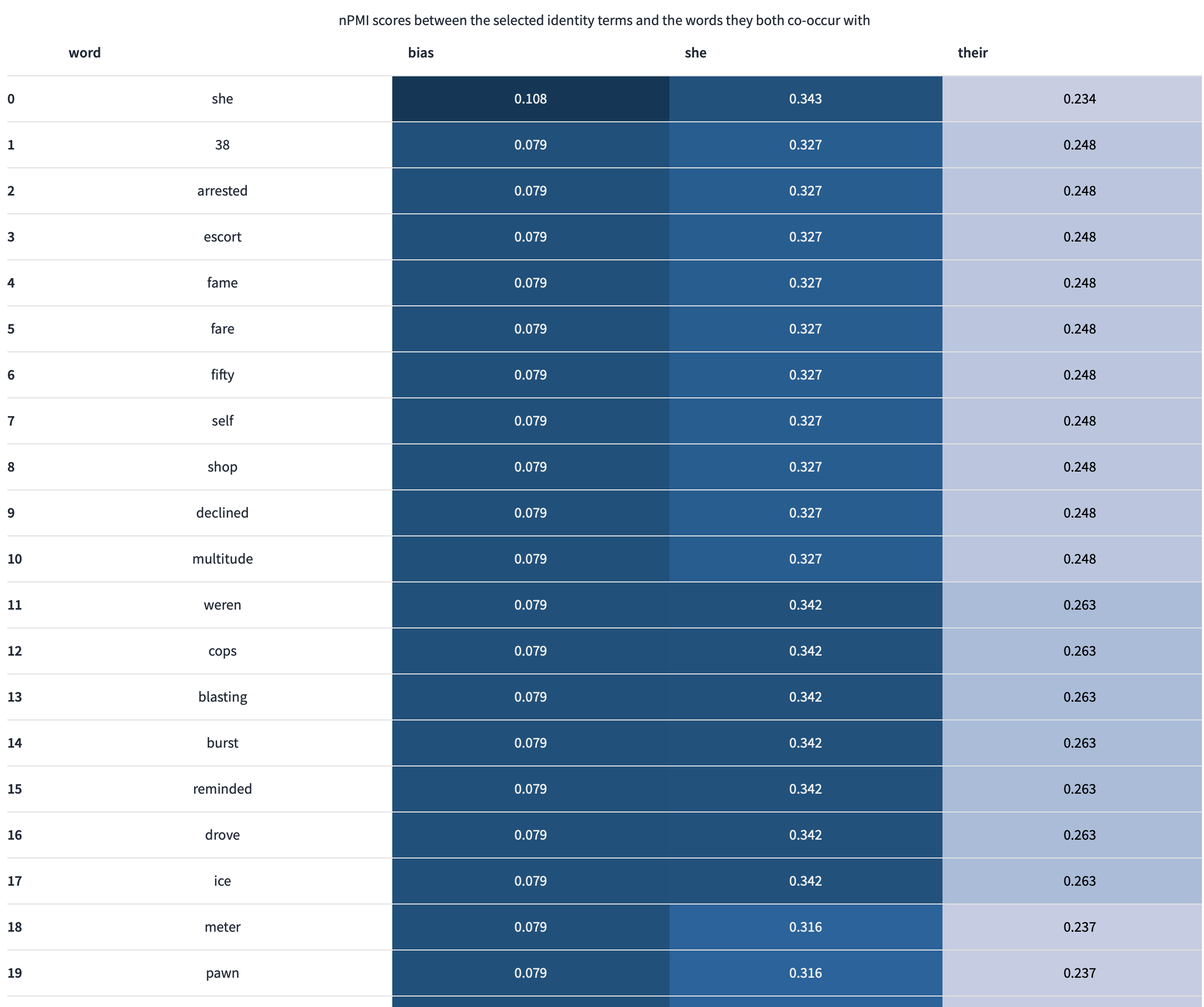
A subset of this dataset `train`, of ~50k was evaluated using the Data Measuremnts Tool, with a particular focus on the nPMI metric
|
| 110 |
+
> nPMI scores for a word help to identify potentially problematic associations, ranked by how close the association is.
|
| 111 |
+
> nPMI bias scores for paired words help to identify how word associations are skewed between the selected selected words (Aka et al., 2021).
|
| 112 |
+
> You can select from gender and sexual orientation identity terms that appear in the dataset at least 10 times.
|
| 113 |
+
> The resulting ranked words are those that co-occur with both identity terms.
|
| 114 |
+
> The more positive the score, the more associated the word is with the first identity term. The more negative the score, the more associated the word is with the second identity term.
|
| 115 |
+
|
| 116 |
+
While there was a positive skew of words relating occupations e.g _`government`_, _`jobs`_ towards she, her, and similar attributions of the masculine and feminine words to they and them, more harmful words attributions such as _`escort`_ and even _`colour`_ presented with greater attributions to she, her and him, his, respectively.
|
| 117 |
+
|
| 118 |
+
We welcome users to explore the [Data Measurements nPMI Visualitons for OBELICS](https://huggingface.co/spaces/HuggingFaceM4/IDEFICS_Data_Measurement_Tool) further and to see the [idefics-9b model card](https://huggingface.co/HuggingFaceM4/idefics-9b) for further Bias considerations.
|
| 119 |
+
|
| 120 |
## Opted-out content
|
| 121 |
|
| 122 |
To respect the preferences of content creators, we removed from OBELICS all images for which creators explicitly opted out of AI model training. We used the [Spawning API](https://api.spawning.ai/spawning-api) to verify that the images in the dataset respect the original copyright owners’ choices.
|
assets/DMT_eval.png
ADDED
|
Git LFS Details
|