

license: odc-by
TxT360: A Top-Quality LLM Pre-training Dataset Requires the Perfect Blend
.png)
We introduce TxT360 (Trillion eXtracted Text) the first dataset to globally deduplicate 99 CommonCrawl snapshots and 14 commonly used non-web data sources (e.g. FreeLaw, PG-19, etc.) providing pretraining teams with a recipe to easily adjust data weighting, obtain the largest high-quality open source dataset, and train the most performant models.
TxT360 Compared to Common Pretraining Datasets
| Data Source | TxT360 | FineWeb | RefinedWeb | PedPajamaV2 | C4 | Dolma | RedPajamaV1 | The Pile |
|---|---|---|---|---|---|---|---|---|
| CommonCrawl Snapshots | 99 | 96 | 90 | 84 | 1 | 24 | 5 | 0.6% of 74 |
| Papers** | 5 Sources | - | - | - | - | 1 Source | 1 Source | 4 Sources |
| Wikipedia | 310+ Languages | - | - | - | - | Included | Included | English Only |
| FreeLaw | Included | - | - | - | - | - | - | Included |
| DM Math | Included | - | - | - | - | - | - | Included |
| USPTO | Included | - | - | - | - | - | - | Included |
| PG-19 | Included | - | - | - | - | Included | Included | Included |
| HackerNews | Included | - | - | - | - | - | - | Included |
| Ubuntu IRC | Included | - | - | - | - | - | - | Included |
| EuroParl | Included | - | - | - | - | - | - | Included |
| StackExchange** | Included | - | - | - | - | - | - | Included |
| Code | * | - | - | - | - | Included | Included | Included |
TxT360 does not include code. This decision was made due to the perceived low duplication code with other sources.
StackExchange and PubMed Central datasets will be uploaded shortly. All other datasets are present and complete.
Complete details on the dataset can be found in our blog post here.
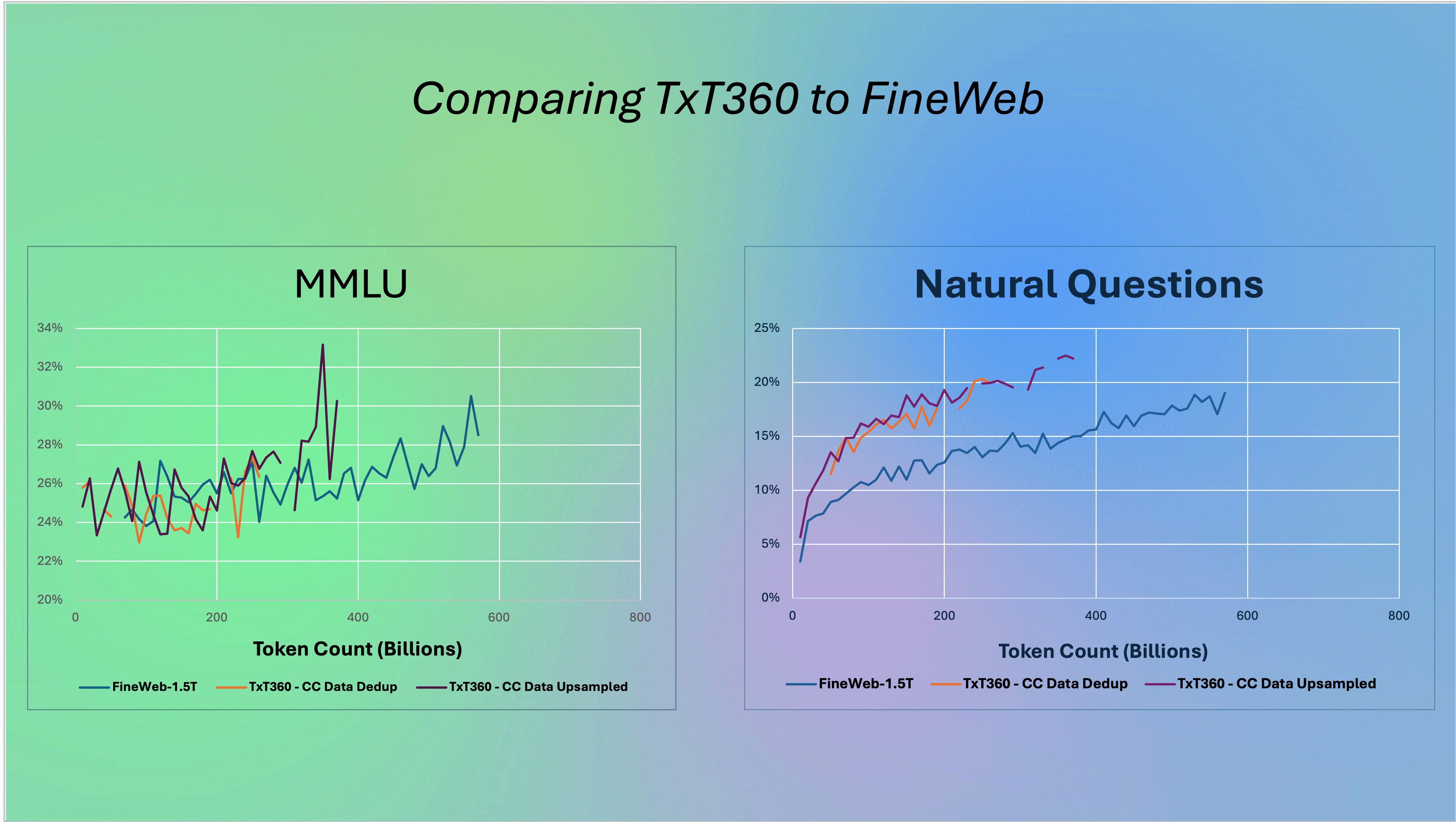
TxT360 Performance
To evaluate the training efficiency of our dataset, we sampled 1.5T tokens from both FineWeb and TxT360 (using the aforementioned weighting) and conducted a training ablation on an 8x8B Mixture-of-Experts architecture, similar to Mixtral. We compared the learning curves by tracking training loss, validation scores, and performance across a wide array of diverse evaluation benchmarks. The validation set was sampled independently from SlimPajama. Note that this experiment is done on a slightly earlier version of the dataset.
Initial Data Representation
To produce TxT360, a comprehensive data processing pipeline was designed to account for the nuances of both web and curated datasets. The pipeline presents a unified framework for processing both data types, making it convenient and easily adaptive for users to revise and fine-tune the pipeline for their own use cases.
Web datasets are inherently noisy and varied. The TxT360 pipeline implements sophisticated filtering and deduplication techniques to clean and remove redundancies while preserving data integrity.
Curated datasets are typically structured and consistently formatted, but also can cause troubles with their own special formatting preferences. TxT360 filters these sources with selective steps to maintain their integrity while providing seamless integration into the larger dataset. Both data source types are globally deduplicated together resulting in ~5T tokens of high-quality data. The table below shows the source distribution of TxT360 tokens.
We further highlight the importance of mixing the datasets together with the right blend. The raw distribution of the deduplicated dataset is actually suboptimal, a simple working recipe is provided in the studies section. This recipe will create a dataset of 15T+ tokens, the largest high quality open source pre-training dataset.
| Data Source | Raw Data Size | Token Count | Information Cut-Off Date |
|---|---|---|---|
| CommonCrawl | 9.2 TB | 4.83T | 2024-30 |
| Papers | 712 GB | 154.96B | Q4 2023 |
| Wikipedia | 199 GB | 35.975B | - |
| Freelaw | 71 GB | 16.7B | Q1 2024 |
| DM Math | 22 GB | 5.23B | - |
| USPTO | 45 GB | 4.95B | Q3 2024 |
| PG-19 | 11 GB | 2.63B | - |
| HackerNews | 4.1 GB | 1.08B | Q4 2023 |
| Ubuntu IRC | 4.7 GB | 1.54B | Q3 2024 |
| Europarl | 6.1 GB | 1.96B | - |
| StackExchange | 79 GB | 27.0B | Q4 2023 |
The TxT360 blog post provides all the details behind how we approached and implemented the following features:
CommonCrawl Data Filtering
Complete discussion on how 99 Common Crawl snapshots were filtered and comparison to previous filtering techinques (e.g. Dolma, DataTrove, RedPajamaV2).
Curated Source Filtering
Each data source was filtered individually with respect to the underlying data. Full details and discussion on how each source was filter are covered.
Global Deduplication
After the web and curated sources were filtered, all sources globally deduplicated to create TxT360. The tips and tricks behind the deduplication process are included.
Citation
BibTeX:
@misc{txt360data2024,
title={TxT360: A Top-Quality LLM Pre-training Dataset Requires the Perfect Blend},
author={Liping Tang, Nikhil Ranjan, Omkar Pangarkar, Xuezhi Liang, Zhen Wang, Li An, Bhaskar Rao, Zhoujun Cheng, Suqi Sun, Cun Mu, Victor Miller, Yue Peng, Eric P. Xing, Zhengzhong Liu},
year={2024}
}