
File size: 15,299 Bytes
4944158 dcc09df 097b0a2 dcc09df 4944158 6c5db7f 4944158 d551155 6c5db7f 4944158 d551155 6c5db7f 4944158 6c5db7f 4944158 0700cd0 4944158 6c5db7f 4944158 0700cd0 4944158 dcc09df |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 |
---
license: apache-2.0
dataset_info:
features:
- name: image
dtype: image
- name: query
dtype: string
- name: product_id
dtype: string
- name: position
dtype: int64
- name: title
dtype: string
- name: pair_id
dtype: string
- name: score_linear
dtype: int64
- name: score_reciprocal
dtype: float64
- name: no_score
dtype: int64
- name: query_id
dtype: string
configs:
- config_name: default
data_files:
- split: in_domain
path: data/in_domain-*
- split: novel_document
path: data/novel_document-*
- split: novel_query
path: data/novel_query-*
- split: zero_shot
path: data/zero_shot-*
language:
- en
tags:
- multimodal
- GCL
- datasets
pretty_name: marqo-GS-10M
size_categories:
- 1M<n<10M
---
<div style="display: flex; align-items: center; gap: 10px;">
<a href="https://www.marqo.ai/blog/generalized-contrastive-learning-for-multi-modal-retrieval-and-ranking">
<img src="https://img.shields.io/badge/Marqo-Blog-blue?logo=font-awesome&logoColor=white&style=flat&logo=pencil-alt" alt="Blog">
</a>
<a href="https://arxiv.org/pdf/2404.08535.pdf">
<img src="https://img.shields.io/badge/arXiv-Paper-red?logo=arxiv" alt="arXiv Paper">
</a>
<a href="https://github.com/marqo-ai/GCL">
<img src="https://img.shields.io/badge/GitHub-Repo-lightgrey?logo=github" alt="GitHub Repo">
</a>
</div>
# Marqo-GS-10M
This dataset is our multimodal, fine-grained, ranking Google Shopping dataset, **Marqo-GS-10M**, followed by our novel training framework: [Generalized Contrastive Learning (GCL)](https://www.marqo.ai/blog/generalized-contrastive-learning-for-multi-modal-retrieval-and-ranking). GCL aims to improve and measure the **ranking** performance of information retrieval models,
especially for retrieving relevant **products** given a search query.
Blog post: https://www.marqo.ai/blog/generalized-contrastive-learning-for-multi-modal-retrieval-and-ranking
Paper: https://arxiv.org/pdf/2404.08535.pdf
GitHub: https://github.com/marqo-ai/GCL
```python
from datasets import load_dataset
ds = load_dataset("Marqo/marqo-GS-10M")
```
## Table of Content
1. Motivation
2. Dataset and Benchmarks
3. Instructions to evaluate with the GCL Benchmarks
4. GCL Training Framwork and Models
5. Example Usage of Models
## 1. Motivation
Contrastive learning has gained widespread adoption for retrieval tasks due to its minimal requirement for manual annotations. However, popular contrastive frameworks typically learn from binary relevance, making them ineffective at incorporating direct fine-grained rankings.
In this paper, we curate a large-scale dataset: Marqo-GS-10M, featuring detailed relevance scores for each query-document pair to facilitate future research and evaluation.
Subsequently, we propose Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking (GCL), which is designed to learn from fine-grained rankings beyond binary relevance score.
Our results show that GCL achieves a **94.5%** increase in NDCG@10 for in-domain and **26.3** to **48.8%** increases for cold-start evaluations, measured **relative** to the CLIP baseline within our curated ranked dataset.
## 2. Dataset and Benchmarks
### Dataset Structure
<img src="https://raw.githubusercontent.com/marqo-ai/GCL/main/assets/ms1.png" alt="multi split visual" width="500"/>
Illustration of multi-dimensional split along both query and document dimensions resulting in 4 splits:
training split with 80\% of queries and 50\% of documents, novel query splitwith the other 20\% of queries and the same documents as the training split,
novel corpus split with the same queries as the training split and unseen documents with the equal size of the training corpus,
and zero-shot split with unseen queries and documents.
### Dataset Structure
In this section, we show the dataset structure.
```
marqo-gs-dataset/
├── marqo_gs_full_10m/
│ ├── corpus_1.json
│ ├── corpus_2.json
│ ├── query_0_product_id_0.csv
│ ├── query_0_product_id_0_gt_dev.json
│ ├── query_0_product_id_0_gt_test.json
│ ├── query_0_product_id_0_queries.json
│ ├── query_0_product_id_1.csv
│ ├── query_0_product_id_1_gt_dev.json
│ ├── query_0_product_id_1_gt_test.json
│ ├── query_0_product_id_1_queries.json
│ ├── query_1_product_id_0.csv
│ ├── query_1_product_id_0_gt_dev.json
│ ├── query_1_product_id_0_gt_test.json
│ ├── query_1_product_id_0_queries.json
│ ├── query_1_product_id_1.csv
│ ├── query_1_product_id_1_gt_dev.json
│ ├── query_1_product_id_1_gt_test.json
│ └── query_1_product_id_1_queries.json
├── marqo_gs_fashion_5m/
├── marqo_gs_wfash_1m/
```
For each dataset such as marqo_gs_full_10m, there are 4 splits as discussed before.
- `query_0_product_id_0` represents in-domain set,
- `query_1_product_id_0` represents novel query set,
- `query_0_product_id_1` represents novel document set,
- `query_1_product_id_1` represents zero shot set,
For each split, there is a ground truth csv containing triplet information,
a set of validation ground truth and a set of test ground truth.
### Dataset Downloads
The Marqo-GS-10M dataset is available for direct download. This dataset is pivotal for training and benchmarking in Generalized Contrastive Learning (GCL) frameworks and other multi-modal fine-grained ranking tasks.
You can use the dataset with Hugging Face's `datasets`:
```python
from datasets import load_dataset
ds = load_dataset("Marqo/marqo-GS-10M")
```
Alternatively:
- **Full Dataset**: [Download](https://marqo-gcl-public.s3.amazonaws.com/v1/marqo-gs-dataset.tar) - Link contains the entire Marqo-GS-10M dataset except for the images.
- **Full Images**: [Download](https://marqo-gcl-public.s3.amazonaws.com/v1/images_archive.tar) - Link contains the images of the entire Marqo-GS-10M dataset.
- **Sample Images**: [Download](https://marqo-gcl-public.s3.amazonaws.com/v1/images_wfash.tar) - Link contains the images for woman fashion category, it corresponds to the woman fashion sub-dataset.
### Dataset Visualization
Visualization of the collected triplet dataset containing search queries (top row),
documents and scores, showcasing thumbnails of returned products with scores that decrease linearly according to their positions.
## 3. Instructions to use the GCL Benchmarks
### Install environment
```bash
conda create -n gcl python=3.8
conda activate gcl
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install jupyterlab pandas matplotlib beir pytrec_eval braceexpand webdataset wandb notebook open_clip_torch
pip install --force-reinstall numpy==1.23.2
```
### Evaluate using GCL benchmarks
1. Download the Dataset, links above. We recommend try out the Sample set first.
2. Either prepare your own model or download our finetuned model down below.
3. Modify [eval-vitb32-ckpt.sh](./scripts/eval-vitb32-ckpt.sh) to add image dir, eval dir and model path.
4. Use [change_image_paths.py](./evals/change_image_paths.py) to modify image paths in the csv.
```bash
python change_image_paths.py /dataset/csv/dir/path /image/root/path
# Example:
python change_image_paths.py /data/marqo-gs-dataset/marqo_gs_wfash_1m /data/marqo-gs-dataset/images_wfash
```
5. Run the eval script:
```bash
bash ./scripts/eval-vitb32-ckpt.sh
```
## 4. GCL Training Framework and Models
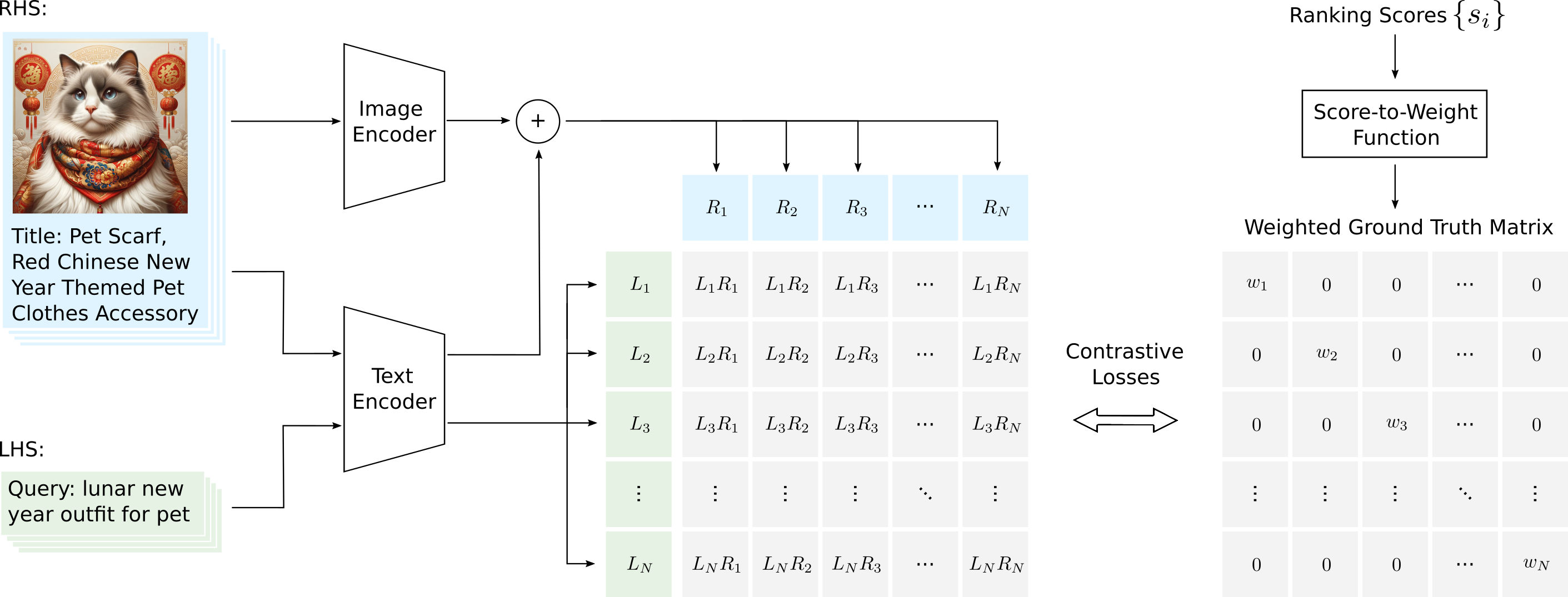
Overview of our Generalized Contrastive Learning (GCL) approach.
GCL integrates ranking information alongside multiple input fields for each sample (e.g., title and image)
across both left-hand-side (LHS) and right-hand-side (RHS).
Ground-truth ranking scores are transformed into weights,
which are used for computing contrastive losses, ensuring that pairs with higher weights incur greater penalties.
Please refer to the paper for full explanation.
### Results and Model Downloads
Retrieval and ranking performance comparison of GCL versus publicly available contrastive learning methods assessed by NDCG@10, ERR, and RBP metrics on the GSFull-10M dataset for the **In-Domain** category. The methods are based on multi-modal approaches:
### Multi-Field/Text-Image
| Methods | Models | Size | nDCG | ERR | RBP | Downloads |
|---------------|----------|-------|------------|-----------|-----------|--------------------------------------------------------------------------------------------------------|
| CLIP | ViT-L-14 | 1.6G | 0.310 | 0.093 | 0.252 | [model](https://marqo-gcl-public.s3.us-west-2.amazonaws.com/v1/clip-vitl14-110-gs-full-states.pt) |
| GCL (ours) | ViT-B-32 | 577M | 0.577 | 0.554 | 0.446 | [model](https://marqo-gcl-public.s3.us-west-2.amazonaws.com/v1/gcl-vitb32-117-gs-full-states.pt) |
| GCL (ours) | ViT-L-14 | 1.6G | 0.603 | 0.562 | 0.467 | [model](https://marqo-gcl-public.s3.us-west-2.amazonaws.com/v1/gcl-vitl14-120-gs-full-states.pt) |
| GCL (ours) | ViT-B-32 | 577M | 0.683 | 0.689 | 0.515 | [model](https://marqo-gcl-public.s3.us-west-2.amazonaws.com/v1/marqo-gcl-vitb32-127-gs-full_states.pt) |
| GCL (ours) | ViT-L-14 | 1.6G | **0.690** | **0.630** | **0.535** | [model](https://marqo-gcl-public.s3.us-west-2.amazonaws.com/v1/marqo-gcl-vitl14-124-gs-full_states.pt) |
### Text-only
| Methods | Models | nDCG | ERR | RBP | Downloads |
|---------------|----------------------------|-----------|------------|-----------|---------------------------------------------------------------------------------------------------|
| BM25 | - | 0.071 | 0.028 | 0.052 | |
| E5 | e5-large-v2 | 0.335 | 0.095 | 0.289 | |
| Cross Entropy | xlm-roberta-base-ViT-B-32 | 0.332 | 0.099 | 0.288 | |
| GCL (ours) | e5-large-v2 | 0.431 | 0.400 | 0.347 | [model](https://marqo-gcl-public.s3.us-west-2.amazonaws.com/v1/gcl-e5l-113-gs-full-states.pt) |
| GCL (ours) | xlm-roberta-base-ViT-B-32 | 0.441 | 0.404 | 0.355 | [model](https://marqo-gcl-public.s3.us-west-2.amazonaws.com/v1/gcl-robbxlm-105-gs-full-states.pt) |
| E5 | e5-large-v2 | **0.470** | **0.457** | **0.374** | Marqo/marqo-gcl-e5-large-v2-130 |
## 5. Example Usage of Models
### Quick Demo with OpenCLIP
Here is a quick example to use our model if you have installed open_clip_torch.
```bash
python demos/openclip_demo.py
```
or
```python
import torch
from PIL import Image
import open_clip
import wget
model_url = "https://marqo-gcl-public.s3.us-west-2.amazonaws.com/v1/gcl-vitb32-117-gs-full-states.pt"
wget.download(model_url, "gcl-vitb32-117-gs-full-states.pt")
model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32', pretrained='gcl-vitb32-117-gs-full-states.pt')
tokenizer = open_clip.get_tokenizer('ViT-B-32')
image = preprocess(Image.open('https://raw.githubusercontent.com/marqo-ai/GCL/main/assets/oxford_shoe.png')).unsqueeze(0)
text = tokenizer(["a dog", "Vintage Style Women's Oxfords", "a cat"])
logit_scale = 10
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (logit_scale * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs)
```
### Quick Demo with Hugging Face for E5 models.
Here is a quick example to load our finetuned e5 text models from Hugging Face directly.
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ".
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: Espresso Pitcher with Handle',
'query: Women’s designer handbag sale',
"passage: Dianoo Espresso Steaming Pitcher, Espresso Milk Frothing Pitcher Stainless Steel",
"passage: Coach Outlet Eliza Shoulder Bag - Black - One Size"]
tokenizer = AutoTokenizer.from_pretrained('Marqo/marqo-gcl-e5-large-v2-130')
model_new = AutoModel.from_pretrained('Marqo/marqo-gcl-e5-large-v2-130')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=77, padding=True, truncation=True, return_tensors='pt')
outputs = model_new(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
<!---
### Using VITB32/VITL14/E5 with **marqo** vector search.
Using model download url for VIT models
```python
import marqo
# create an index with your custom model
mq = marqo.Client(url='http://localhost:8882')
settings = {
"treatUrlsAndPointersAsImages": True,
"model": "generic-clip-test-model-1",
"modelProperties": {
"name": "ViT-B-32",
"dimensions": 512,
"url": "https://marqo-gcl-public.s3.us-west-2.amazonaws.com/v1/marqo-gcl-vitb32-127-gs-full_states.pt",
"type": "open_clip",
},
"normalizeEmbeddings": True,
}
response = mq.create_index("my-own-clip", settings_dict=settings)
```
Using Hugging Face for our finetuned E5 models
```python
import marqo
# create an index with your custom model
mq = marqo.Client(url='http://localhost:8882')
model_properties = {
"name": "Marqo/marqo-gcl-e5-large-v2-130",
"dimensions": 1024,
"type": "hf"
}
mq.create_index("test_e5", model="my_custom_e5", model_properties=model_properties)
```
-->
## Citation
```
@misc{zhu2024generalized,
title={Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking},
author={Tianyu Zhu and Myong Chol Jung and Jesse Clark},
year={2024},
eprint={2404.08535},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
``` |