
AraDICE
Collection
# AraDiCE: Benchmarks for Dialectal and Cultural Capabilities in LLMs
•
10 items
•
Updated
•
2
Dataset
stringclasses 8
values | Size
stringclasses 7
values | Link
stringclasses 8
values |
|---|---|---|
ArabicMMLU-egy | 14,459 | https://huggingface.co/datasets/QCRI/AraDICE-ArabicMMLU-egy |
ArabicMMLU-lev | 14,459 | https://huggingface.co/datasets/QCRI/AraDICE-ArabicMMLU-lev |
AraDiCE-Culture | 180 | https://huggingface.co/datasets/QCRI/AraDiCE-Culture |
BoolQ | 892 | https://huggingface.co/datasets/QCRI/AraDiCE-BoolQ |
OpenBookQA (OBQA) | 500 | https://huggingface.co/datasets/QCRI/AraDiCE-OpenBookQA |
PIQA | 1,838 | https://huggingface.co/datasets/QCRI/AraDiCE-PIQA |
TruthfulQA | 780 | https://huggingface.co/datasets/QCRI/AraDiCE-TruthfulQA |
Winogrande | 1,267 | https://huggingface.co/datasets/QCRI/AraDiCE-WinoGrande |
The AraDiCE dataset is designed to evaluate dialectal and cultural capabilities in large language models (LLMs). The dataset consists of post-edited versions of various benchmark datasets, curated for validation in cultural and dialectal contexts relevant to Arabic.
As part of the supplemental materials, we have selected a few datasets (see below) for the reader to review. We will make the full AraDiCE benchmarking suite publicly available to the community.
AraDICE collection can accessed through collection page
Individual dataset can also be accessed by the following link:
The datasets used in this study include: i) four existing Arabic datasets for understanding and generation: Arabic Dialects Dataset (ADD), ADI, QADI, along with a dialectal response generation dataset, and MADAR; ii) seven datasets translated and post-edited into MSA and dialects (Levantine and Egyptian), which include ArabicMMLU, BoolQ, PIQA, OBQA, Winogrande, Belebele, and TruthfulQA; and iii) AraDiCE-Culture, an in-house developed regional Arabic cultural understanding dataset. Please find below the types of dataset and their statistics benchmarked in AraDiCE.
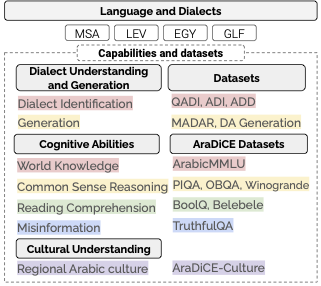

The AraDiCE dataset is intended to be used for benchmarking and evaluating large language models, specifically focusing on:
We have used lm-harness eval framework to for the benchmarking. We will soon release them. Stay tuned!!
We will soon be releasing all our machine translation models. Stay tuned! For early access, feel free to contact us.
The dataset is distributed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). The full license text can be found in the accompanying licenses_by-nc-sa_4.0_legalcode.txt file.
Please find the paper here.If you use all or any specific dataset in this collection, please make sure if also cite original dataset paper. You will find the citations in our paper.
@article{mousi2024aradicebenchmarksdialectalcultural,
title={{AraDiCE}: Benchmarks for Dialectal and Cultural Capabilities in LLMs},
author={Basel Mousi and Nadir Durrani and Fatema Ahmad and Md. Arid Hasan and Maram Hasanain and Tameem Kabbani and Fahim Dalvi and Shammur Absar Chowdhury and Firoj Alam},
year={2024},
publisher={arXiv:2409.11404},
url={https://arxiv.org/abs/2409.11404},
}