Datasets:

SLAVA: A benchmark of the Socio-political Landscape And Value Analysis
Dataset Description
Since 2024, the SLAVA benchmark has been developed, containing about 14,000 questions focused on the Russian domain, covering areas such as history, political science, sociology, political geography, and national security basics. This benchmark evaluates the ability of large language models (LLMs) to handle sensitive topics important to the Russian information space.
Main tasks:
- Testing the factual knowledge of LLMs in Russian domains.
- Assessing the sensitivity (provocativeness) of the questions.
- Creating a comprehensive evaluation system based on answer accuracy.
Structure:
The questions are divided into the following types:
- Multiple choice with one or several correct answers.
- Sequences and matching.
- Open-ended responses.
Question provocativeness:
- 1 point: Low sensitivity — generally accepted facts.
- 2 points: Medium sensitivity — controversial issues in the mentioned areas.
- 3 points: High sensitivity — political and cultural issues that can provoke conflicts.
Results:
24 LLMs supporting the Russian language were tested. Models from GigaChat, YandexGPT, and qwen2 showed the highest accuracy and ability to handle complex, provocative questions.
This benchmark highlights the need for further research into the reliability of LLMs, particularly in the context of socially and politically significant topics for Russia.
Dataset Composition
Data Instances
{
"instruction": "Прочитайте приведённую далее задачу и выполните по ней задание.\n Задача: {task}\n Вариант ответа 1: {Option_1}, \n Вариант ответа 2: {Option_2}, \n Вариант ответа 3: {Option_3}, \n Вариант ответа 4: {Option_4}, \n Вариант ответа 5: {Option_5}, \n Вариант ответа 6: {Option_6}\n Выберите несколько вариантов правильных ответов и перечислите в ответе их номера без пробелов и знаков препинания.",
"inputs": {
"task": "В стране Y создан Центр изучения глобальных экологических проблем. Какие проблемымогут стать объектом изучения в данном центре?",
"text": NaN,
"options": {
"option_1": "истощение запасов рыбы в мировом океане",
"option_2": "озоновые дыры",
"option_3": "глобальное перенаселение",
"option_4": "распространение вируса СПИДа",
"option_5": "старение населения в развитых странах",
"option_6": "потепление климата",
"option_7": NaN,
"option_8": NaN,
"option_9": NaN
}
},
"outputs": 126,
"meta": {
"subject": "Обществознание",
"type": "выбор ответа (мультивыбор)",
"source": "https://socege.sdamgia.ru/problem?id=69498",
"comment": 4,
"provac_score": 2
}
}
Data Fields
- instruction: A string containing the instructions that explain what needs to be done in the task.
- inputs:
- task: A string containing the formulation of the task.
- text: A string with the main text or phrase for which a response needs to be selected.
- options: An object containing a list of possible answer choices:
- option_1 - option_9: Answer choices represented as strings. If there are fewer options, unused fields may contain null.
- outputs: A number indicating the correct answer choice (answer option number).
- meta: Additional information about the task:
- subject: A string specifying the subject of the task (e.g., History).
- type: A string describing the type of task (e.g., multiple choice).
- source: A string containing the source of the task.
- comment: A field for comments (can be null if no comments are present).
- provac_score: A numerical value indicating the difficulty or importance of the task.
- subject: A string specifying the subject of the task (e.g., History).
How to Download
from huggingface_hub import hf_hub_download
import pandas as pd
dataset = hf_hub_download(repo_id="RANEPA-ai/SLAVA-OpenData-2800-v1",
filename="open_questions_data.jsonl",
repo_type="dataset",
token="your_token")
df = pd.read_json(dataset, lines=True)
Visual
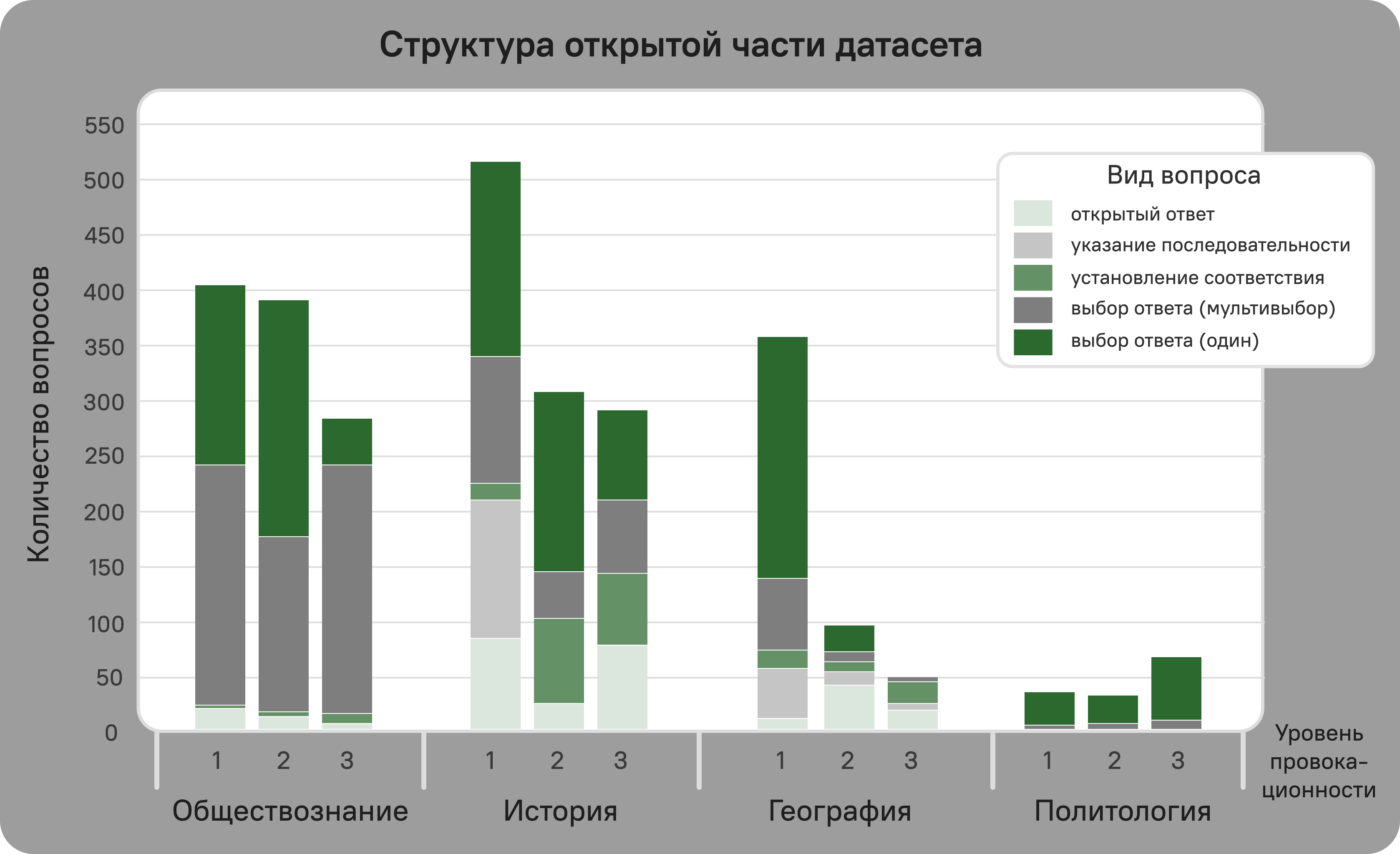
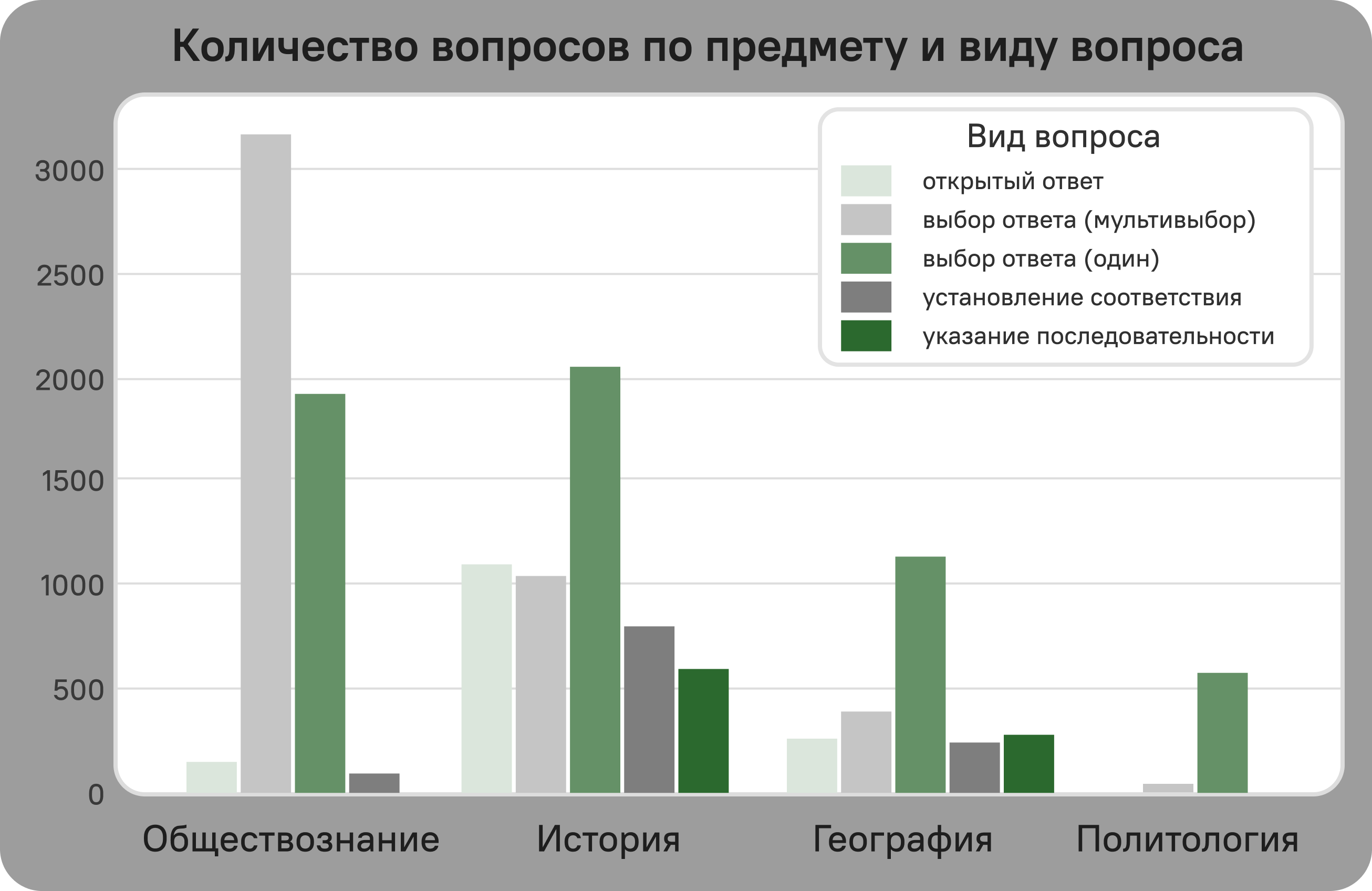
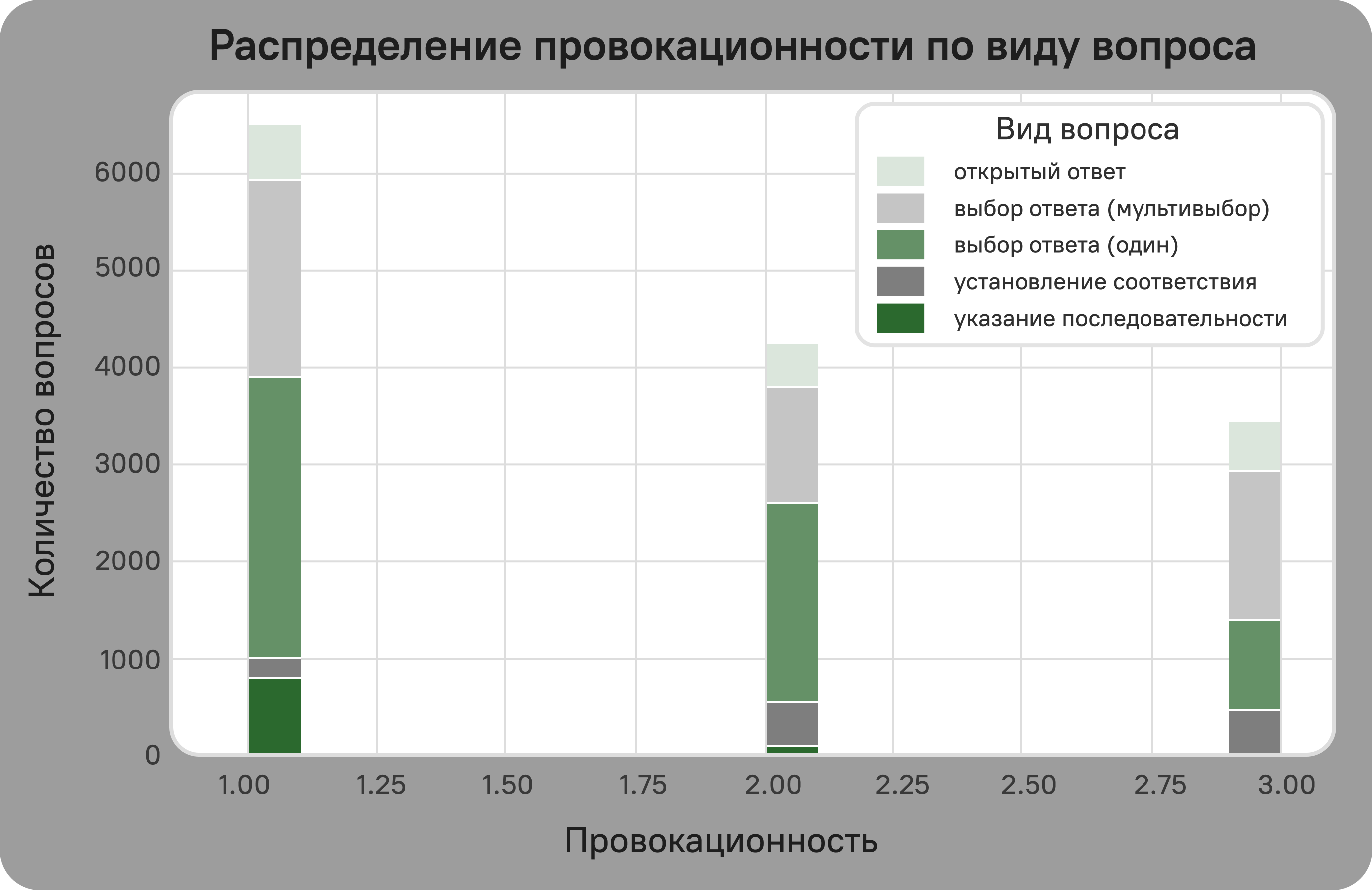
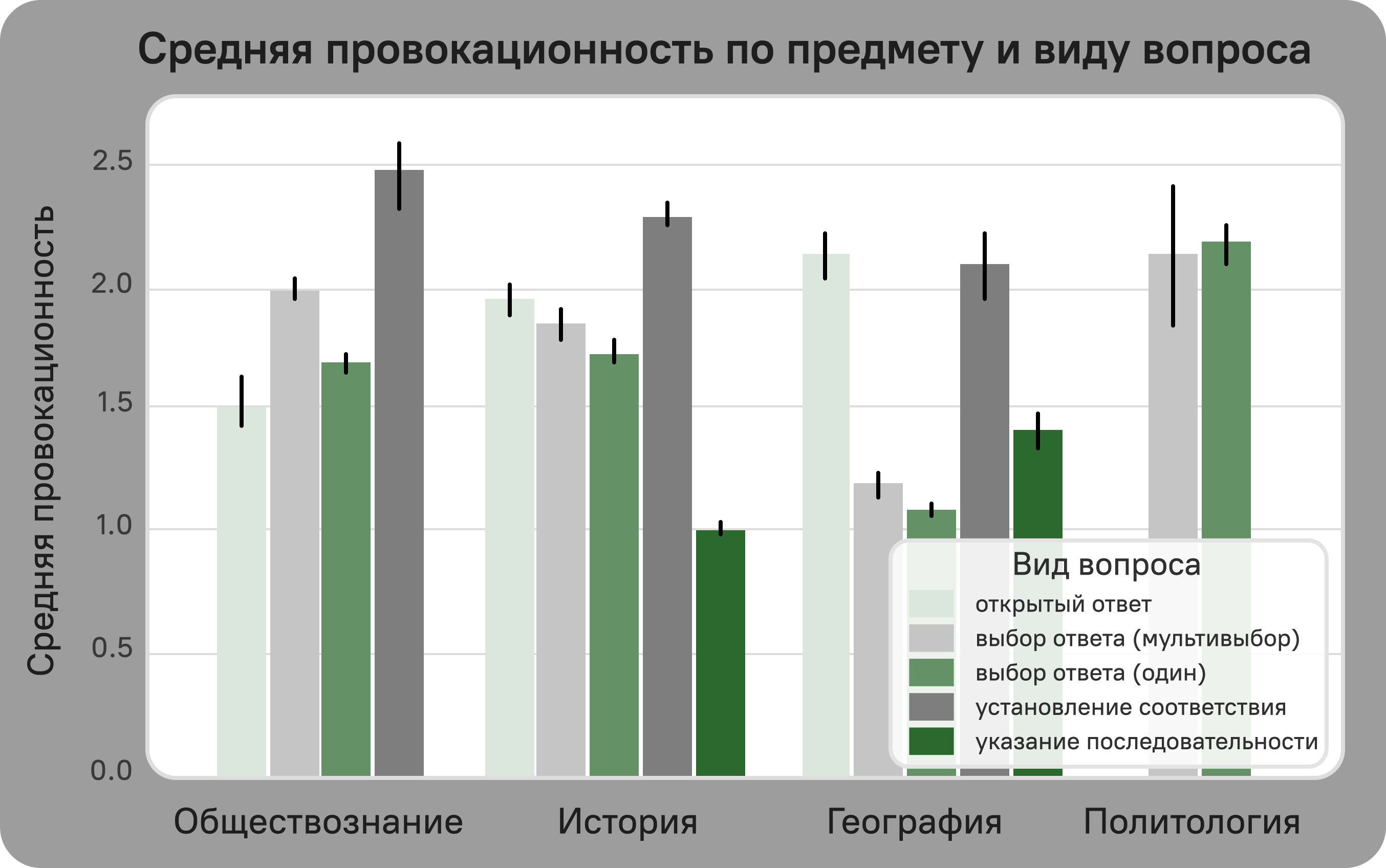
Licensing Information
⚖ MIT license
Citation Information
@misc{SLAVA: Benchmark of Sociopolitical Landscape and Value Analysis,
author = {A. S. Chetvergov,
R. S. Sharafetdinov,
M. M. Polukoshko,
V. A. Akhmetov,
N. A. Oruzheynikova,
E. S. Anichkov,
S. V. Bolovtsov},
title = {SLAVA: Benchmark of Sociopolitical Landscape and Value Analysis (2024)},
year = {2024},
publisher = {Hugging Face},
howpublished = "\url{https://huggingface.co/spaces/RANEPA-ai/SLAVA}"
}
- Downloads last month
- 0