
source
stringclasses 1
value | text
stringlengths 152
659k
| filtering_features
stringlengths 402
437
| source_other
stringlengths 440
819k
|
|---|---|---|---|
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Add 'Guitar' to the projects set.
username_0:
<issue_comment>username_0: @guillaumejenkins, need to upload [Guitar action](https://onedrive.live.com/?authkey=%21AApw4m%5FLMKk9o5k&cid=6D448BF1915B0863&id=6D448BF1915B0863%2116215&parId=6D448BF1915B0863%2116197&o=OneUp) to YouTube for the Adafruit Guitar project.
<issue_comment>username_1: Uploaded, will patch the docs. | {'fraction_non_alphanumeric': 0.10864197530864197, 'fraction_numerical': 0.145679012345679, 'mean_word_length': 9.972972972972974, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '21150014', 'n_tokens_mistral': 193, 'n_tokens_neox': 159, 'n_words': 28} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: RPI3: 'unable to create window surface' exception
username_0: I'm trying to get a VideoCore sample working on RPI 3 (Raspbian strech, mono 5.10.0.160)
using latest 0.7.1 release.
When using Fake KMS driver:
getting 'unable to create window surface' exception at this line https://github.com/username_1/OpenGL.Net/blob/354e0bbfd92718c847e27bf8cae3c740fe2f829f/Samples/HelloTriangle.VideoCore/Program.cs#L54
When using Full KMS driver:
getting an exception 'unable to get BCM window size' at https://github.com/username_1/OpenGL.Net/blob/354e0bbfd92718c847e27bf8cae3c740fe2f829f/Samples/HelloTriangle.VideoCore/Program.cs#L49
I'm not sure if this somehow related to my system configuration. Is there some tutorial on getting this working on Raspbian?
<issue_comment>username_1: Can you describe your execution environment? I've run the sample application on RPi2, using VC4+GLES2: note that the application does not require X11, since the VC4 library exposes a basic windowing system without any backend (just like Kodi running without X11).
Are you running under X11? Then your application must be set up just like any X11 application (GLX+GL). Probably you need to disable EGL initialization to get it work (set environment variable OPENGL_NET_EGL_STATIC_INIT to "NO").
<issue_comment>username_0: I've tried from both X11 and not. Also tried OPENGL_NET_EGL_STATIC_INIT. There were always different erros that I mostly described above.
So I just started from scratch, reimaged latest raspbian Stretch, updated/upgraded etc.
The first proplem was Stretch does not have libEGL libs for some reason. I did core upgrade as per this post: https://www.raspberrypi.org/forums/viewtopic.php?t=191638
Second problem I cannot resolve is: * failed to add service - already in use
Some info here: https://www.raspberrypi.org/forums/viewtopic.php?p=1239827#p1239827
and: https://raspberrypi.stackexchange.com/questions/75219/fixing-failed-to-add-service-already-in-use-error-programmatically
<issue_comment>username_2: Same problem here. Fixed it by adding `Bcm.bcm_host_init();` at the top of the VideoCoreWindow's constructor. This call was originally wrapped in an event handler, which is never called with my setup. | {'fraction_non_alphanumeric': 0.06622516556291391, 'fraction_numerical': 0.047240618101545256, 'mean_word_length': 5.157608695652174, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 5, 'lorem ipsum': 0, 'www.': 2, 'xml': 0}, 'pii_count': 1, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '3994741', 'n_tokens_mistral': 753, 'n_tokens_neox': 676, 'n_words': 265} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: [cluster-autoscaler][AWS] Massive scale-out when using composed topologySpreadConstraints
username_0: <!--
Please answer these questions before submitting your bug report. Thanks!
-->
**Which component are you using?**:
<!--
Which autoscaling component hosted in this repository (cluster-autoscaler, vertical-pod-autoscaler, addon-resizer, helm charts) is the bug in?
-->
cluster-autoscaler
**What version of the component are you using?**:
<!--
What version of the relevant component are you using? Either the image tag or helm chart version.
-->
Component version:
1.20.0
**What k8s version are you using (`kubectl version`)?**:
<details><summary><code>kubectl version</code> Output</summary><br><pre>
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"16", GitVersion:"v1.16.2", GitCommit:"c97fe5036ef3df2967d086711e6c0c405941e14b", GitTreeState:"clean", BuildDate:"2019-10-15T23:41:55Z", GoVersion:"go1.12.10", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"19", GitVersion:"v1.19.7", GitCommit:"1dd5338295409edcfff11505e7bb246f0d325d15", GitTreeState:"clean", BuildDate:"2021-01-13T13:15:20Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"linux/amd64"}
</pre></details>
**What environment is this in?**:
<!--
If you're using a cloud provider or hardware configuration as your deployment environment let us know here.
-->
AWS
**What did you expect to happen?**:
<!--
What behaviour did you expect to see?
-->
If I request for 50 pods, at worst-case scenario I expect a maximum 50 new nodes to be provisioned. A small delta/deflection is also acceptable.
**What happened instead?**:
<!--
What behaviour did see instead?
-->
A deployment scaled from 3 pods -> 50 pods and the cluster-autoscaler provisioned 124 new nodes (about 3 times more than needed)
**How to reproduce it (as minimally and precisely as possible)**:
<!--
If possible, provide a recipe for reproducing the error.
A detailed sequence of steps describing what to do to observe the issue is good.
A complete runnable bash shell script is best.
-->
- Have a kubernetes cluster in the AWS environment with the ASGs split-by-az (1 ASG for each availability zone with balance-similar-node-groups flag enabled)
- Have a deployment with composed `topologySpreadConstraints`:
```
topologySpreadConstraints:
- labelSelector:
matchLabels:
app: sample
maxSkew: 1
topologyKey: failure-domain.beta.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
- labelSelector:
matchLabels:
app: sample
maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: ScheduleAnyway
```
- Trigger a scale-out
**Anything else we need to know?**:
<!--
Is there anything else you think we should know? Configuration of the component (be careful what you post here if so)? Relevant logs?
-->
```
I0609 12:23:05.391344 1 scale_up.go:288] Pod sample-deployment-6567d494d-msmqx can't be scheduled on yaldo3-sbx-va6-k8s-compute-1-worker3AutoScalingGroup-SI93SIX7YS99, predicate checking error: node(s) didn't match pod topology spread constraints; predicateName=PodTopologySpread; reasons: node(s) didn't match pod topology spread constraints; debugInfo=
I0609 12:23:05.391358 1 scale_up.go:290] 38 other pods similar to sample-deployment-6567d494d-msmqx can't be scheduled on yaldo3-sbx-va6-k8s-compute-1-worker3AutoScalingGroup-SI93SIX7YS99
doalexan-macOS:~ doalexan$ ks logs cluster-autoscaler-757bc688c7-ctfgw -c cluster-autoscaler | grep Estimated
I0609 12:22:44.484873 1 scale_up.go:460] Estimated 43 nodes needed in yaldo3-sbx-va6-k8s-compute-1-worker1AutoScalingGroup-IEVC83OH6WBI
I0609 12:22:54.780549 1 scale_up.go:460] Estimated 41 nodes needed in yaldo3-sbx-va6-k8s-compute-1-worker3AutoScalingGroup-SI93SIX7YS99
I0609 12:23:05.391416 1 scale_up.go:460] Estimated 38 nodes needed in yaldo3-sbx-va6-k8s-compute-1-worker2AutoScalingGroup-14C4MNCP75I8W
doalexan-macOS:~ doalexan$ ks logs cluster-autoscaler-757bc688c7-ctfgw -c cluster-autoscaler | grep "Best option to resize"
I0609 12:22:44.484866 1 scale_up.go:456] Best option to resize: yaldo3-sbx-va6-k8s-compute-1-worker1AutoScalingGroup-IEVC83OH6WBI
I0609 12:22:54.780542 1 scale_up.go:456] Best option to resize: yaldo3-sbx-va6-k8s-compute-1-worker3AutoScalingGroup-SI93SIX7YS99
I0609 12:23:05.391402 1 scale_up.go:456] Best option to resize: yaldo3-sbx-va6-k8s-compute-1-worker2AutoScalingGroup-14C4MNCP75I8W
doalexan-macOS:~ doalexan$ ks logs cluster-autoscaler-757bc688c7-ctfgw -c cluster-autoscaler | grep "Final"
I0609 12:22:44.484915 1 scale_up.go:574] Final scale-up plan: [{yaldo3-sbx-va6-k8s-compute-1-worker1AutoScalingGroup-IEVC83OH6WBI 9->52 (max: 1000)}]
I0609 12:22:54.780601 1 scale_up.go:574] Final scale-up plan: [{yaldo3-sbx-va6-k8s-compute-1-worker3AutoScalingGroup-SI93SIX7YS99 5->46 (max: 1000)}]
I0609 12:23:05.391476 1 scale_up.go:574] Final scale-up plan: [{yaldo3-sbx-va6-k8s-compute-1-worker2AutoScalingGroup-14C4MNCP75I8W 14->52 (max: 1000)}]
```
<issue_comment>username_1: I can confirm it with a single topologySpreadConstraint:
````
topologySpreadConstraints:
- topologyKey: "topology.kubernetes.io/zone"
maxSkew: 1
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- myApp
````
After scaling up deployment just 2 to 30 replicas (should have fit easily on a few nodes), CA started to scale up all node groups to the maximum within a few seconds.
(CA 1.20.0, EKS 1.20, 1 ASG per AZ)
Might be related to https://github.com/kubernetes/autoscaler/issues/4099 ?
<issue_comment>username_2: Observing the same behaviour after testing with v1.21 ,
- In the AWS environment with the ASGs split-by-az (1 ASG for each availability zone with
balance-similar-node-groups flag enabled)
- for deployment with `failure-domain.beta.kubernetes.io/zone` topologySpreadConstraints.
```
root@a4381d640386:/infrastructure# kubectl get pods cluster-autoscaler-596fd6869f-l2wj8 -n kube-system -o yaml| grep -i "v1.21.0"
...
image: us.gcr.io/k8s-artifacts-prod/autoscaling/cluster-autoscaler:v1.21.0
...
root@a4381d640386:/infrastructure# kubectl logs cluster-autoscaler-596fd6869f-l2wj8 -n kube-system cluster-autoscaler | grep Estimated
I0726 07:40:22.515606 1 scale_up.go:472] Estimated 2 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6
I0726 07:43:43.782579 1 scale_up.go:472] Estimated 44 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A
I0726 07:43:54.011754 1 scale_up.go:472] Estimated 41 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM
```
Taking it a bit further, tried with the changes suggested in #4099 (ie. Adding a predicateChecker.CheckPredicates call after adding a new node in snapshot ([binpacking_estimator.go](https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/estimator/binpacking_estimator.go#L96)) to check whether pod can be scheduled on this new node)
(https://github.com/kubernetes/autoscaler/compare/cluster-autoscaler-release-1.21...username_2:cluster-autoscaler-1.21.0-with-fix)
Testing with the above change has resulted with the following output -
```
root@a4381d640386:/infrastructure# kubectl logs cluster-autoscaler-cc4699b74-wkjmb -n kube-system cluster-autoscaler | grep Estimated
I0726 06:21:23.947747 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6
I0726 06:21:34.222356 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A
I0726 06:21:44.483110 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM
I0726 06:24:05.726519 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6
I0726 06:24:15.871400 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A
I0726 06:24:26.126278 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM
I0726 06:27:27.507255 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6
I0726 06:27:37.780775 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A
I0726 06:27:48.065048 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM
I0726 06:30:29.295872 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6
I0726 06:30:39.459837 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A
I0726 06:30:59.718187 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM
I0726 06:32:50.762266 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6
I0726 06:33:21.291955 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM
I0726 06:33:41.542018 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A
I0726 06:35:32.500733 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6
I0726 06:37:13.391653 1 scale_up.go:472] Estimated 1 nodes needed in nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A
root@a4381d640386:/infrastructure# kubectl logs cluster-autoscaler-cc4699b74-wkjmb -n kube-system cluster-autoscaler | grep Final
I0726 06:21:23.947802 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6 1->2 (max: 10)}]
I0726 06:21:34.222404 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A 2->3 (max: 10)}]
I0726 06:21:44.483167 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM 2->3 (max: 10)}]
I0726 06:24:05.726596 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6 2->3 (max: 10)}]
I0726 06:24:15.871448 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A 3->4 (max: 10)}]
I0726 06:24:26.126330 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM 3->4 (max: 10)}]
I0726 06:27:27.507310 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6 3->4 (max: 10)}]
I0726 06:27:37.780841 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A 4->5 (max: 10)}]
I0726 06:27:48.065102 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM 4->5 (max: 10)}]
I0726 06:30:29.295935 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6 4->5 (max: 10)}]
I0726 06:30:39.459895 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A 5->6 (max: 10)}]
I0726 06:30:59.718238 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM 5->6 (max: 10)}]
I0726 06:32:50.762324 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6 5->6 (max: 10)}]
I0726 06:33:21.292028 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker2AutoScalingGroup-1ORI890DK7IJM 6->7 (max: 10)}]
I0726 06:33:41.542072 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A 6->7 (max: 10)}]
I0726 06:35:32.500807 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker1AutoScalingGroup-1TJLUML3GSRP6 6->7 (max: 10)}]
I0726 06:37:13.391702 1 scale_up.go:586] Final scale-up plan: [{nshkr-sbx-va6-k8s-compute-0-worker3AutoScalingGroup-10MYRA8D9IV6A 7->8 (max: 10)}]
```
Results/Analysis :
With the fix,
- The CA is not scaling massively anymore for scaling of deployment with `failure-domain.beta.kubernetes.io/zone` topologySpreadConstraints defined.
- Scaling node distribution across AZ is balanced.
<issue_comment>username_2: @username_3 Does the changes https://github.com/kubernetes/autoscaler/compare/cluster-autoscaler-release-1.21...username_2:cluster-autoscaler-1.21.0-with-fix looks like something that can be solution for this issue?
Initial testing logs (shared above) suggests that it help with the massive scale out using failure-domain.beta.kubernetes.io/zone topologySpreadConstraints.
Also kindly let us know if there will be any concerns around the same.
Happy to raise a PR if suggested changes looks fine.
<issue_comment>username_3: The changes make a lot of sense and I agree they could help with this issue. One comment:
ExpansionOption also has a list of [pods](https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/core/scale_up.go#L269) that will be helped by scale-up. This fix changes the estimated node number, but it doesn't modify the list of pods. That means that expander (heuristic that selects between available scale-up options) will act as if all those pending pods could be scheduled on a very small number of nodes.
I think the best way to fix would be to keep track of which pods were actually "scheduled" in Estimator and override ExpansionOption.Pods based on it. Since Estimator only has a single implementation now, I don't see any problem with changing the interface so that this information can be returned.
Also, for future reference only: removing node from snapshot is an expensive operation as it drops internal caches. I suspect that with a lot of pending pods using topology spreading one may run into scalability problems with binpacking (which is obviously still a major improvement on current state).
* This could be optimized by not removing the node if CheckPredicates() fail and just remembering it's empty so we don't add empty node for next pod and not count it towards result if it remains empty at the end.
* I think it would be premature and needlessly complex to add this optimization now, just something to keep in mind if we run into scalability issue with this later on.
<issue_comment>username_4: /remove-lifecycle stale | {'fraction_non_alphanumeric': 0.10054701745246158, 'fraction_numerical': 0.11637145089867153, 'mean_word_length': 4.096913375373382, 'pattern_counts': {'":': 0, '<': 24, '<?xml version=': 0, '>': 45, 'https://': 5, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '2644399', 'n_tokens_mistral': 6683, 'n_tokens_neox': 5621, 'n_words': 1390} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: How to install the library / headers in Ubuntu 15.10?
username_0: mkdir build
cd build
cmake ..
make
But then there is no `make install`. Is there a method currently?
<issue_comment>username_1: No, currently there is no way to install the library as it wasn't intended to be installable until now. | {'fraction_non_alphanumeric': 0.05965909090909091, 'fraction_numerical': 0.017045454545454544, 'mean_word_length': 3.5844155844155843, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '6771199', 'n_tokens_mistral': 108, 'n_tokens_neox': 96, 'n_words': 49} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Fix nixos-install when running outside NixOS.
username_0: Due to issues with environmental variables, nixos-install failed to install when
the host operating system wasn't NixOS. This broke bootstrapping from Debian.
<issue_comment>username_1: Already merged https://github.com/NixOS/nixpkgs/commit/71910be9ea225895e36f60ed23a1bdce402b3088 and https://github.com/NixOS/nixpkgs/commit/7b37a5f168706db5efa33599354f5c1967ac4c51 | {'fraction_non_alphanumeric': 0.06971677559912855, 'fraction_numerical': 0.11982570806100218, 'mean_word_length': 7.363636363636363, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '4189670', 'n_tokens_mistral': 187, 'n_tokens_neox': 155, 'n_words': 36} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Allow proc label in datepicker input
username_0: Currently datepicker input doesn't allow to pass label as a proc, this is needed when supporting multiple languages.
<issue_comment>username_0: Is there something else I can do here?
<issue_comment>username_1: Related to #1665?
<issue_comment>username_2: Somewhat, I think this one is about i18n (translating the input label), and that other issue is about l10n (localized month names, week day names, date formats, and so on).
<issue_comment>username_0: Somehow this got lost in my todo list 🙈
Rebased the PR and added the change log entry.
Thank you for the awesome work maintaining ActiveAdmin 💚
<issue_comment>username_3: @username_2 @username_0 I don't want to delay this if you'd like to get this merged in now but with the change I was wondering if we had this documented? I took a quick earlier and I didn't see anything. I bring it up as I've seen more of these type of changes come in which I think is great but wondered perhaps if its valuable to also [include an example in the docs](https://github.com/activeadmin/activeadmin/blob/master/docs/5-forms.md#datepicker)? Sorry I did mean to comment with this earlier today but forgot. 😞
<issue_comment>username_2: I agree we should document this :+1:. Could you add an example to the docs, @username_0?
<issue_comment>username_0: @username_3 Thank you for reminding me about the docs.
I added the follow information to the datepicker section:
```
Datepicker also accepts the `:label` option as a string or proc to display.
If it's a proc, it will be called each time the datepicker is rendered.
``` | {'fraction_non_alphanumeric': 0.058574879227053143, 'fraction_numerical': 0.013285024154589372, 'mean_word_length': 4.814035087719298, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 9, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '10061617', 'n_tokens_mistral': 467, 'n_tokens_neox': 437, 'n_words': 248} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: [BUG] - ir workspace node-list has workspace related flags
username_0: ir workspace node-list is implemented as subparser thus allowing the user to do something like:
`
ir workspace node-list --help
usage: ir workspace node-list [-h] [-n NAME] [-g GROUP]
optional arguments:
-h, --help show this help message and exit
-n NAME, --name NAME Workspace name
-g GROUP, --group GROUP
`
Which prints confusing (non working) flags
<issue_comment>username_1: Hi Tal,
A ticket (#1625) has been opened for this one.
Thanks,
Ariel
<issue_comment>username_1: A [patch](https://review.gerrithub.io/403029) patch has been submitted.
Currently, the patch fixes only the functionality of the 'group' flag for the 'workspace node-list' command.
Fixes for other flags require changes in API, and will have to wait for a newer major version of InfraRed.<issue_closed>
<issue_comment>username_2: I tested that on master and --group now works well now. I'm closing that issue now. @username_0 please reopen or create another issues if problem is still present. thanks! | {'fraction_non_alphanumeric': 0.07850133809099019, 'fraction_numerical': 0.013380909901873328, 'mean_word_length': 3.9210526315789473, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '16088502', 'n_tokens_mistral': 332, 'n_tokens_neox': 309, 'n_words': 151} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Consider inferring allowed CORS origins from redirect URIs?
username_0: If `AllowedCorsOrigin` list is empty and grant type is implicit?
<issue_comment>username_1: Does google do it that way? :P
<issue_comment>username_1: And does AllowAccessTokensInBrowser is true.
<issue_comment>username_1: Assigning to 3.0 since it's enough of a behavior change that I'd call it sort of breaking. I don't want people on 2.x to be surprised by this as a new behavior.
<issue_comment>username_1: Implicit is dead.<issue_closed> | {'fraction_non_alphanumeric': 0.06386861313868614, 'fraction_numerical': 0.014598540145985401, 'mean_word_length': 6.12987012987013, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '15944207', 'n_tokens_mistral': 162, 'n_tokens_neox': 157, 'n_words': 71} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Firebase Error: "Previous value was empty"
username_0: 642/5000
Good morning
I wanted to ask for your help with this problem that has been presenting me several times while generating the apk in the inventor app 2
many times it works without problem but there are days or weeks where the same code generates the error "Previous value was empty" when try use firebase
then it can be solved without me doing anything it just works again,
I summarize my error in a synthetic model where it also occurs, in addition to throwing the error, the app closes me
I already checked that the FirebaseToken and FirebaseURL were fine and they are but even so it throws the problem to me very frequently
I want to know what can I do?
sorry for my english...

 | {'fraction_non_alphanumeric': 0.05454545454545454, 'fraction_numerical': 0.07942583732057416, 'mean_word_length': 4.476439790575916, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '14549278', 'n_tokens_mistral': 357, 'n_tokens_neox': 298, 'n_words': 137} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Training Regime and Backprop
username_0: Love your project and hope very much it's not impolite to ask whether you intend to publish the learning regime as well so that I might try my luck with my own text data (training on the text corpus and the later the classifier on top). Even "dirty" code would do, just to get a starting point.
Would be very happy to hear from you
<issue_comment>username_1: i want train it in chinese
<issue_comment>username_2: Code to train this model 'from scratch' using data-parallelism across multiple GPUs: https://github.com/username_2/openai_reproduction | {'fraction_non_alphanumeric': 0.04784688995215311, 'fraction_numerical': 0.006379585326953748, 'mean_word_length': 5.038461538461538, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '19545607', 'n_tokens_mistral': 165, 'n_tokens_neox': 159, 'n_words': 92} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Added proper initialization for vr_suffix in col_cf_init
username_0: The vr_suffix is now set in col_cf_init.
Fixes #4245
[BFB] for tests in suite but may impact history files for other runs/configurations.
<issue_comment>username_1: @username_2 please start merging this.
<issue_comment>username_2: to 'BFB' as we are only marking PRs non-BFB if any existing tests report non-BFB changes. | {'fraction_non_alphanumeric': 0.057736720554272515, 'fraction_numerical': 0.018475750577367205, 'mean_word_length': 5.2, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '6791822', 'n_tokens_mistral': 141, 'n_tokens_neox': 132, 'n_words': 54} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: The mouse-cursor component is not working on Aframe 0.8.2 on Chrome version 68.
username_0: **Description:**
- A-Frame Version: 0.8.2
- Platform / Device: All
- Reproducible Code Snippet or URL: https://github.com/mayognaise/aframe-mouse-cursor-component
<!-- If you have a support question, please ask at https://stackoverflow.com/questions/ask/?tags=aframe rather than filing an issue. -->
<issue_comment>username_1: Are you talking about the component or the built-in [cursor component](https://aframe.io/docs/0.8.0/components/cursor.html#properties_rayorigin) using the rayOrigin property? Can you provide an example to reproduce and what you get vs. what you expect?
<issue_comment>username_0: Hello it's about the component from https://github.com/mayognaise/aframe-mouse-cursor-component.
Here is the example. https://glitch.com/edit/#!/lapis-girdle?path=index.html:27:7
Click the cube using the mouse and it will turn to blue then click it again to turn it back to pink that was what I expecting but when I changed the version of Aframe to 0.8.2 it will not work anymore. Thanks
<issue_comment>username_0: Hi @username_2 I have tried the demo in android Chrome version 68.0.3440.91 in Huawei GR3 2017 Android version 7 and I can't change the color of the cube by touching or tapping it. I also inspect the Demo in Chrome Version 68.0.3440.106 in my laptop and I saw some warnings and errors.

<issue_comment>username_2: @username_0 I can confirm that I'm experiencing the same issue on Android with that demo, but I only forked your code and updated the cursor entity as an example of how to use `rayOrigin`.
I suspect the issue lies within some of the surrounding code, e.g., code not being properly encapsulated within components or systems, or placed in the wrong part of the document, etc.
I recommend wrapping your code in a component to see if you have better results.
There's also a strange button script at the bottom of the body, which I'm not sure of its purpose.
If I have time, I'll make another demo from scratch to see if I can reproduce the issue.
<issue_comment>username_2: @username_1: I can confirm that this is currently an issue in every Android browser that I've tested using both A-Frame `0.8.2` and the current `master` branch `d611e70`.
I created a simplified demo and tested in the current versions of Samsung Internet, Chrome, Chrome Dev, Canary, Firefox, Edge all with the same results. Touching only works sporadically and is either non-responsive or extremely laggy.
It works perfectly on PC, even on my touch screen, but no good on Android. I just tested with Safari on iOS as well with the same results as Android.
**Code**: https://glitch.com/edit/#!/abrupt-donkey
**Demo**: https://abrupt-donkey.glitch.me
<issue_comment>username_3: Closing issue regarding mouse cursor: https://github.com/aframevr/aframe/issues/3754#issuecomment-417400062
The code above has some bugs (`aycaster`, mouse cursor being child of camera). Don't know how well mouse cursor would work as a child of a camera on a polyfilled device. Can create new issue if there is an example with code without errors.<issue_closed>
<issue_comment>username_2: Thanks, @username_3. I removed the cursor from camera and fixed the typo, and the issue persists. I'll open a new issue with a more accurate title.
<issue_comment>username_2: @username_3 @username_1 Scratch that. It appears the cursor needs to be at the bottom of the scene. Simply removing it from the camera wasn't enough. I'm not sure if that's something that needs to be either addressed or documented.
After moving it to the bottom of the scene, it functions as expected: https://abrupt-donkey.glitch.me/ | {'fraction_non_alphanumeric': 0.07072792978833248, 'fraction_numerical': 0.030459473412493547, 'mean_word_length': 4.337465564738292, 'pattern_counts': {'":': 0, '<': 12, '<?xml version=': 0, '>': 12, 'https://': 10, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '20205006', 'n_tokens_mistral': 1154, 'n_tokens_neox': 1046, 'n_words': 532} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Integrate Ray into MMS for Parallel Inference
username_0: /kind feature
**Describe the solution you'd like**
Recently we've been able to merge https://github.com/kubeflow/kfserving/pull/1637, which adds parallel inference support to kfserving by making use of Rayserve annotations. To build upon this, we should be able support this feature as part of MMS as well. This would allow us to deploy multiple models, with each model running as a separate python worker so the inference can run in parallel.
This issue will be used as a basis for a proof of concept - specifically by integrating Ray into one of the currently supported model types that can be run with MMS enabled (such a SKlearn). RayServe annotations can be added to the SKLearnModel class (model.py).
Note: It may be worth looking into if this could be a toggle-able feature so that users could choose whether or not models run with parallel inference enabled. | {'fraction_non_alphanumeric': 0.03913491246138002, 'fraction_numerical': 0.005149330587023687, 'mean_word_length': 4.4, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '14867642', 'n_tokens_mistral': 249, 'n_tokens_neox': 228, 'n_words': 150} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Broken links
username_0: # Description
Hello,
There are some broken links on a few web pages.
Page | Link
-------|-------
http://pywps.org/docs/ | "official documentation"
http://username_1.github.io/pywps-tutorial/build/html/conclusion/index.html#where-to-continue | "actual PyWPS documentation"
http://geopython.github.io/ | pywps (forwards once)
Is the documentation for the 3.X series available anywhere online?
Regards,
<NAME>
# Environment
Browser
# Steps to Reproduce
Go to url :-)
# Additional Information<issue_closed>
<issue_comment>username_1: should be fixed now, thank you
<issue_comment>username_0: Thanks. The link in the tutorial still seems to be broken for me. It points to http://pywps.wald.intevation.org/documentation/index.html
<issue_comment>username_1: --
<NAME>
e-mail: <EMAIL>
twitter: @username_1c | {'fraction_non_alphanumeric': 0.11692650334075724, 'fraction_numerical': 0.0077951002227171495, 'mean_word_length': 3.8594594594594596, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 9, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '29569584', 'n_tokens_mistral': 305, 'n_tokens_neox': 282, 'n_words': 82} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Integrate GNC into ADCSCommander
username_0: Place GNC functions into ADCSCommander
<issue_comment>username_1: @username_0 could you expand on which GNC functions we are referencing here?
<issue_comment>username_0: I've actually got no idea what the names of them are but,
They are the functions that convert the desired vectors to actual MTR and Wheel commands.
<issue_comment>username_1: Ahhh okay so stuff on top of the controller itself. We can talk about this this weekend and find the companion PSim tickets.
<issue_comment>username_1: Just assigning myself too so I don't forget.
<issue_comment>username_1: @username_0 After talking with @tanishqaggarwal and @stewartaslan I'm just going to take this over for next week to take some stuff off your plate.
<issue_comment>username_1: Per @nhz2 request, we'll also need to update documentation here in accordance with implementation: https://pan-software.readthedocs.io/en/latest/flight_software/components.html
<issue_comment>username_1: The current pointing strategy defined in FSW needs to be reworked have the long edge of the satellite along the orbit normal and point the antenna phase outward at some angle `phi` specified in the hill frame.<issue_closed> | {'fraction_non_alphanumeric': 0.048722044728434506, 'fraction_numerical': 0.00878594249201278, 'mean_word_length': 5.922651933701657, 'pattern_counts': {'":': 0, '<': 10, '<?xml version=': 0, '>': 10, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '23821023', 'n_tokens_mistral': 335, 'n_tokens_neox': 322, 'n_words': 164} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Failed to read artifact descriptor for io.rest-assured:rest-assured:4.4.0
username_0: Hello,
When adding rest assured 4.4.0 in Maven & Eclipse it points out the following error message:
Failed to read artifact descriptor for io.rest-assured:rest-assured:4.4.0
POM:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.10</maven.compiler.source>
<maven.compiler.target>1.10</maven.compiler.target>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/io.rest-assured/rest-assured-common -->
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured-common</artifactId>
<version>4.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.rest-assured/rest-assured -->
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<version>4.4.0</version>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>7.4.0</version>
</dependency>
</dependencies>
Could you please advise... I am not sure if rest-assured-common should be added as well | {'fraction_non_alphanumeric': 0.14354066985645933, 'fraction_numerical': 0.02073365231259968, 'mean_word_length': 3.4661921708185055, 'pattern_counts': {'":': 0, '<': 38, '<?xml version=': 0, '>': 38, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '4916716', 'n_tokens_mistral': 473, 'n_tokens_neox': 399, 'n_words': 72} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Unblocking does not work if the passed value is in a variable
username_0: This is something that I came across in a more complex environment and almost got me thinking that I must be crazy so I tried to reproduce this issue with almost no libraries at all.
As you can see in your demo site, when someone uses window.yett.unblock like this:
`window.yett.unblock('/mypattern/');`
everything works without an issue.
Same goes if you enter an array of previously blacklisted items:
`window.yett.unblock(['/mypattern1/', '/mypattern2/');`
However, when I try to pass the arguments through a variable, it does not work.
I have setup a very basic html page that demonstrates what I'm trying to say. Please check it here:
http://yett.mashup.gr/
Note that inputArr and anotherArr have the exact same initial assignment.
Also, if you execute the unblock function directly from Chrome's console like so: `unblockScript([ /testme\.js/ ]);` it works without issues. The problem is when the input to the unblock function does not come as a literal but as a variable.
<issue_comment>username_1: Actually when I try that on the Chrome console it does not work:
<img width="238" alt="capture d ecran 2019-02-18 a 10 30 17" src="https://user-images.githubusercontent.com/3428394/52941196-82779080-3368-11e9-9c3a-af64f57eefeb.png">
I think your issues comes from the fact that you are trying to pass an array of `Regexp` to the `unblock` function. [But the `unblock` function expects an array of `strings`](https://github.com/snipsco/yett#unblock).
<img width="239" alt="capture d ecran 2019-02-18 a 10 30 28" src="https://user-images.githubusercontent.com/3428394/52941372-e732eb00-3368-11e9-8326-edfe030dd072.png">
<issue_comment>username_0: I have updated the page to use the exact same template with your demo site and the array is now declared as an array of strings, not regexes. Still not working.
<issue_comment>username_1: @username_0 Can you try replacing:
`var unblockArray = [ '/inline\.js$/' ];`
with:
`var unblockArray = [ 'inline.js' ];`
<issue_comment>username_0: That works, thanks a lot!
Question: since I'm using a variable that contains an array of regexes that comes from the backend to block the scripts and I want to selectively enable them based on the user's choice, is there a way to use the same regexes that I'm using for blacklisting in order to do the unblocking?
If the regex that comes from the backend is simple enough, I can maybe create a "somewhat equivalent" text (e.g. in `inline\.js` I can maybe keep the `inline` part) but if we're talking about a regex like: `(?<=[^<]+?)<[^>]+?` it can't be done. What would maybe help if using the regexes is not possible, to have like a method that I could call on window.yett to get a list of the scripts that were blocked so that I can match the regex against them and figure out which one is which.
<issue_comment>username_1: Not right now, but I just added a commit that enables passing regexes to the `unblock` function. It should help with your use case.
With the change, if the `.toString()` representation of both RegExp is equal then it will be removed from the blacklist (or for people using the whitelist - it will be added to the list).
I'm currently waiting for the tests to pass, then I'll release a new version (if everything is fine in a few minutes).
<issue_comment>username_1: @username_0 Just published `0.1.8`, that should solve the issue.
Feel free to reopen if there is any problem with the feature!<issue_closed> | {'fraction_non_alphanumeric': 0.07540345019476906, 'fraction_numerical': 0.033667223149693934, 'mean_word_length': 4.195086705202312, 'pattern_counts': {'":': 0, '<': 14, '<?xml version=': 0, '>': 12, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '5366550', 'n_tokens_mistral': 1124, 'n_tokens_neox': 995, 'n_words': 529} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: some bugs need to fix
username_0: There are some bugs in the script.
such as in Class Data_Loader, _with open(os.path.join(path,"train.pickle"),"r") as f:_ would raise an error. As the pickle file was save in byte mode, but in this line, it was opened in str mode. So the 'r' should be replaced by 'rb'.
In other parts, there are some other bugs. Please fix it if you have time. 3Q.
P.S. I don't yet know how to pull a request, sorry for that.
<issue_comment>username_1: Sorry for the late reply. I've rerun the code but cannot reproduce the error you mentioned. I think it is due to the python version. In python 2.7, it should be fine. But I have to admit that it is better to use "rb" when reading the pickle file as you pointed out.
Please let me know any other issues you found. Thank you again for your time. | {'fraction_non_alphanumeric': 0.06417736289381563, 'fraction_numerical': 0.005834305717619603, 'mean_word_length': 3.7403314917127073, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '13365317', 'n_tokens_mistral': 247, 'n_tokens_neox': 242, 'n_words': 153} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Update Forge
username_0: Would like to be able to stick Tinkers Construct into my dev environment without needing to upgrade my branches temporarily.
Any reason we are not on recommended?
<issue_comment>username_1: Seconded, we were concerned with fluids a while back but now that TE and Tinkers have both updated and they both have tons of fluid handling I think we can too
<issue_comment>username_2: It's -1.7.10 on the end because it's on the 1.7.10 branch of the repo.
<issue_comment>username_3: No.<issue_closed>
<issue_comment>username_1: Why? The version we are using is years old... | {'fraction_non_alphanumeric': 0.057233704292527825, 'fraction_numerical': 0.02066772655007949, 'mean_word_length': 5.0, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '8297718', 'n_tokens_mistral': 179, 'n_tokens_neox': 171, 'n_words': 90} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Mailgun API error with dirty data and cc/bcc
username_0: - Laravel Version: 5.5.4 (but reproduced current 5.7)
- PHP Version: 7.1.20
- Database Driver & Version: [unrelated]
### Description:
In our project, we got some dirty data, and the Mailgun API does not accept all our emails. Turns out this only becomes a problem when adding cc or bcc's to the mail.
I've identified two problems: one with an opening `(` that is not closed, and one with an e-mail in the name field. Once you add one of those names to the 'to' field, and add a cc or bcc, you will get an exception:
```
GuzzleHttp\Exception\ClientException with message 'Client error: `POST https://api.mailgun.net/v3/[DOMAIN]/messages.mime` resulted in a `400 BAD REQUEST` response:
{
"message": "'to' parameter is not a valid address. please check documentation"
}
'
```
I have opened a ticket at Mailgun to ask their opinion, but my guess it that they would suggest adding `""` around the name. (See below)
### Steps To Reproduce:
In a tinker-session with Mailgun setup, one could run the following lines:
```php
$email1 = "<EMAIL>";
$email2 = "<EMAIL>";
// Example with opening an ( and not closing it
Mail::send('welcome', [], function($m) use ($email1, $email2) { $m->to($email1, 'something ( end'); $m->bcc($email2); });
// Example with email inside of name
Mail::send('welcome', [], function($m) use ($email1, $email2) { $m->to($email1, '<EMAIL> Real Name'); $m->bcc($email2); });
```
### Possible Solutions:
I think the issue is located [here](https://github.com/laravel/framework/blob/5.7/src/Illuminate/Mail/Transport/MailgunTransport.php#L112):
```php
// Illuminate/Mail/Transport/MailgunTransport
protected function getTo(Swift_Mime_SimpleMessage $message)
{
return collect($this->allContacts($message))->map(function ($display, $address) {
return $display ? $display." <{$address}>" : $address;
})->values()->implode(',');
}
```
As you can see, this function does not add quotes around the name, but concats all the addresses together. The examples of the steps to reproduce result in the following strings, which are not accepted by the API:
- `something ( end <<EMAIL>>,<EMAIL>`
- `<EMAIL> Real Name <<EMAIL>>,<EMAIL>`
I think it would be best to add quotes:
- `"something ( end" <<EMAIL>>,<EMAIL>`
- `"<EMAIL> Real Name" <<EMAIL>>,<EMAIL>`
Also interesting to note that this issue only seems to arise when adding more recipients to the mail. Just a single user is fine, which makes this kind of an edge case.
<issue_comment>username_0: Hm, I now see that there are no quotes mentioned in this document: https://tools.ietf.org/html/rfc2822#section-3.4 It should be fine without them.
Let's just wait for Mailgun to come back at this.
<issue_comment>username_1: Both examples can be prevented by proper validation in the application itself. Just provide the correct input?<issue_closed>
<issue_comment>username_0: I agree that the data should be cleaner, though, in this particular application, we do not own that data. This is the correct input.
Apart from this particular application, I don't think the above values should result in an API failure. But I'm also asking Mailgun about it, because it's their API that's rejecting it. I'll update when I have a stronger case :)
<issue_comment>username_2: @username_0 Hi, did you get any updates from Mailgun regarding this case?
<issue_comment>username_0: I did, but unfortunately, I switched jobs, so I don't have access to my e-mail history.
Of the top of my head, the solution as presented by Mailgun was to define the `to` field multiple times in the request (instead of relying on commas).
See the example taken from their [API docs](https://documentation.mailgun.com/en/latest/api-sending.html#examples):
```
curl -s --user 'api:YOUR_API_KEY' \
https://api.mailgun.net/v3/YOUR_DOMAIN_NAME/messages \
-F from='Excited User <mailgun@YOUR_DOMAIN_NAME>' \
-F to=YOU@YOUR_DOMAIN_NAME \
-F to=<EMAIL> \
-F subject='Hello' \
-F text='Testing some Mailgun awesomeness!'
```
They showed me output and examples of tests with `something ( end <<EMAIL>>,<EMAIL>` and `<EMAIL> Real Name <<EMAIL>>,<EMAIL>` as input, and it seemed that this was the solution. Unfortunately, I never came around to update here, or to fix our app.
Thanks for the reminder :)
@driesvrints Is this enough info to consider a reopening? I don't feel like it's Laravel's job to catch up with Mailguns API, but since the driver is in the core of the framework, you kind of have to in a way.
<issue_comment>username_2: @username_0 Thanks for sharing the info.
The solution that applied to our problem was putting the name with `""` to handle such an issue, but of course it was more related to the driver of `MailgunTransport`
```
Illuminate/Mail/Transport/MailgunTransport.php // MailgunTransport->getTo()
``` | {'fraction_non_alphanumeric': 0.10782747603833866, 'fraction_numerical': 0.00878594249201278, 'mean_word_length': 4.009, 'pattern_counts': {'":': 1, '<': 36, '<?xml version=': 0, '>': 45, 'https://': 5, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '4359479', 'n_tokens_mistral': 1545, 'n_tokens_neox': 1456, 'n_words': 644} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: WIP: [SPARK-32923][CORE][SHUFFLE] Handle indeterminate stage retries for push-based shuffle
username_0: <!--
Thanks for sending a pull request! Here are some tips for you:
1. If this is your first time, please read our contributor guidelines: https://spark.apache.org/contributing.html
2. Ensure you have added or run the appropriate tests for your PR: https://spark.apache.org/developer-tools.html
3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][SPARK-XXXX] Your PR title ...'.
4. Be sure to keep the PR description updated to reflect all changes.
5. Please write your PR title to summarize what this PR proposes.
6. If possible, provide a concise example to reproduce the issue for a faster review.
7. If you want to add a new configuration, please read the guideline first for naming configurations in
'core/src/main/scala/org/apache/spark/internal/config/ConfigEntry.scala'.
8. If you want to add or modify an error message, please read the guideline first:
https://spark.apache.org/error-message-guidelines.html
-->
### What changes were proposed in this pull request?
[[SPARK-23243](https://issues.apache.org/jira/browse/SPARK-23243)] and [[SPARK-25341](https://issues.apache.org/jira/browse/SPARK-25341)] addressed cases of stage retries for indeterminate stage involving operations like repartition. This PR addresses the same issues in the context of push-based shuffle. Currently there is no way to distinguish the current execution of a stage for a shuffle ID. Therefore the changes explained below are necessary.
Core changes are summarized as follows:
1. Introduce a new variable `shuffleSequenceId` in `ShuffleDependency` which is monotonically increasing value tracking the temporal ordering of execution of <stage-id, stage-attempt-id> for a shuffle ID.
2. Correspondingly make changes in the push-based shuffle protocol layer in `MergedShuffleFileManager`, `BlockStoreClient` passing the `shuffleSequenceId` in order to keep track of the shuffle output in separate files on the shuffle service side.
3. `DAGScheduler` increments the `shuffleSequenceId` tracked in `ShuffleDependency` in the cases of a indeterministic stage execution
4. Deterministic stage will have `shuffleSequenceId` set to -1 as no special handling is needed in this case.
<!--
Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue.
If possible, please consider writing useful notes for better and faster reviews in your PR. See the examples below.
1. If you refactor some codes with changing classes, showing the class hierarchy will help reviewers.
2. If you fix some SQL features, you can provide some references of other DBMSes.
3. If there is design documentation, please add the link.
4. If there is a discussion in the mailing list, please add the link.
-->
### Why are the changes needed?
<!--
Please clarify why the changes are needed. For instance,
1. If you propose a new API, clarify the use case for a new API.
2. If you fix a bug, you can clarify why it is a bug.
-->
New protocol changes are needed due to the reasons explained above.
### Does this PR introduce _any_ user-facing change?
<!--
Note that it means *any* user-facing change including all aspects such as the documentation fix.
If yes, please clarify the previous behavior and the change this PR proposes - provide the console output, description and/or an example to show the behavior difference if possible.
If possible, please also clarify if this is a user-facing change compared to the released Spark versions or within the unreleased branches such as master.
If no, write 'No'.
-->
No
### How was this patch tested?
Unit tests are WIP.
<!--
If tests were added, say they were added here. Please make sure to add some test cases that check the changes thoroughly including negative and positive cases if possible.
If it was tested in a way different from regular unit tests, please clarify how you tested step by step, ideally copy and paste-able, so that other reviewers can test and check, and descendants can verify in the future.
If tests were not added, please describe why they were not added and/or why it was difficult to add.
-->
<issue_comment>username_0: cc @username_1 @Victsm @username_2 @username_4 @username_3 Please take a look. Currently it is in work in progress as tests are being added. Raised this PR now since we are making protocol changes, it would be better if it can be done before branch-3.2 cut that way at least protocol changes can be merged if reviews on implementation details takes more time. Thanks :)
<issue_comment>username_0: @username_1 @username_2 @username_3 Currently I have updated the PR with the changes of [SPARK-35546](https://github.com/apache/spark/pull/33078), will remove it once the PR gets merged. Please review.
<issue_comment>username_0: @username_2 feels this PR is quite big, I agree. I will break this PR in to 2 client and server and keep this for reference purposes.
<issue_comment>username_1: Is this still WIP ?
<issue_comment>username_0: Yeah I am in the process of breaking this into 2 PRs. Will update here once that is done.
<issue_comment>username_0: After having offline discussions with @username_1 , we decided not to break this PR in to 2. Will fix one of the pending change and remove the WIP tag.
<issue_comment>username_2: @username_0 Could you please provide a reason for not breaking this PR in multiple parts. This PR is touching a lot files both on the client and server side. Even on the client, this again touches the driver side, the push side, and the fetch side.
We have broken changes in the past for similar sized changes to make the review easy and reduces the introduction of bugs. So why for this one we are making the exception?
Also cc. @username_1 and @Victsm
<issue_comment>username_0: There are couple of reasons:
1. Splitting the PR into 2 is not easy as well as clean - there are few classes which are dependent on both client and server side for eg: `MergeStatuses, FinalizeShuffleMerge` and if I start adding one of them to either client side changes or server side changes then the dependencies slowly expand and becomes hard to separate them into 2 clean units given now we have implementation also in place.
2. Given the timeline of RC, @username_1 feels if we break this in to 2 and 1 of them gets in but the other don't then that would be a problem. May be we can time it out so that both of them are close to completion and try to merge them both together.
Any suggestions?
<issue_comment>username_0: @username_1 Remove the WIP tag now it is good to review. cc @Victsm @username_2 @username_3
<issue_comment>username_3: I tend to agree with not break because of the RC timeline. Usually, multiple PRs take more time to get all merged in than one PR.
I'll take a look today.
<issue_comment>username_1: I am feeling a bit under the weather, will wait for @username_3's review - and take a pass after.
Thanks for looking into this @username_3 !
<issue_comment>username_0: Addressed all the review comments @username_3 . Gentle ping for additional reviews. cc @username_1
<issue_comment>username_1: Can you fix the build failures and retry ?
<issue_comment>username_1: Jenkins, test this please
<issue_comment>username_1: add to whitelist
<issue_comment>username_1: Jenkins, add to whitelist
<issue_comment>username_1: Can you follow up on the test failures @username_0 ?
<issue_comment>username_0: I rebased to the latest master, not sure why these tests are failing.
```
org.apache.spark.sql.execution.datasources.PruneFileSourcePartitionsSuite.SPARK-35985 push filters for empty read schema |
org.apache.spark.sql.execution.datasources.PruneFileSourcePartitionsSuite.SPARK-36128: spark.sql.hive.metastorePartitionPruning should work for file data sources
```Will try it locally once.
<issue_comment>username_1: There were some changes to those tests/code recently - try locally with a vanilla build as well to validate if it is not master which has issues.
<issue_comment>username_0: Yes it is failing in my local as well.
<issue_comment>username_0: I think I added the comment on the caller side as to what is the blockId format both shuffle blocks and shuffle chunks. I will take a look again.
<issue_comment>username_0: @username_3 @username_1 Addressed all the review comments, please take a look again. Thanks!
<issue_comment>username_3: I'll take another look today.
<issue_comment>username_3: Almost looks good to me.
<issue_comment>username_0: Addressed the remaining review comments. Please take a look. cc @username_1 @username_3 @username_4 @username_2
<issue_comment>username_1: Can you update to latest master @username_0 ? Might help with the test failures (which look unrelated right now).
<issue_comment>username_0: Merged latest master code to this branch.
<issue_comment>username_1: Thanks for updating @username_0.
The tests are passing fine, and the latest changes looks good to me.
Planning to merge it later tonight.
+CC @username_3, @username_2, @username_4 if there are additional comments and I need to hold off !
<issue_comment>username_1: Can you fix the conflict @username_0 ?
<issue_comment>username_0: Fixed the conflict, should be good now.
<issue_comment>username_1: Thanks @username_0, the tests are passing with the update.
The PR has addressed all pending comment, but will wait for @username_3, @username_2 or @username_4 to also take a look before merging.
<issue_comment>username_4: @username_0 Thanks for working on this. LGTM.
<issue_comment>username_1: Merged to master and branch-3.2
There was some conflict cherry picking to branch-3.2 which I manually fixed.
+CC @username_5
Thanks for fixing this @username_0
Thanks for all the reviews @username_3, @username_2, @username_4 and @Victsm !
This was the last patch for push based shuffle SPIP - the only pending task is documentation.
Thanks for all the PR's and reviews everyone !!
<issue_comment>username_5: @username_0 Thanks for the work!
@username_1 Thanks for the ping :)
<issue_comment>username_0: Thanks for the thorough reviews @username_1 @username_3 @username_2 @username_4 . Learned quite a lot :) | {'fraction_non_alphanumeric': 0.05678964651342476, 'fraction_numerical': 0.015742708132122852, 'mean_word_length': 4.467265047518479, 'pattern_counts': {'":': 0, '<': 43, '<?xml version=': 0, '>': 43, 'https://': 6, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '11584762', 'n_tokens_mistral': 2820, 'n_tokens_neox': 2690, 'n_words': 1481} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Custom learning rate scheduler LambdaLR only supports epoch as argument rather than step
username_0: I want to implement the following learning rate
```bash
lrate = d_model ^ 0.5 * min( step_num ^ 0.5, step_num * warmup_steps ^ -1.5)
```
And LambdaLR would be most suitable, but how to extract this step_num using LambdaLR?
Thanks
<issue_comment>username_0: Eventually answering my own question
Have a look at this https://huggingface.co/transformers/main_classes/optimizer_schedules.html#schedules<issue_closed> | {'fraction_non_alphanumeric': 0.07387387387387387, 'fraction_numerical': 0.014414414414414415, 'mean_word_length': 5.465116279069767, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '21910758', 'n_tokens_mistral': 174, 'n_tokens_neox': 164, 'n_words': 60} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: itellij 15.0.1 Mac 10.11.1 Plugin 'com.microsoftopentechnologies.intellij' failed to initialize and will be disabled.
username_0: Plugin 'com.microsoftopentechnologies.intellij' failed to initialize and will be disabled. Please restart IntelliJ IDEA.
java.lang.NoClassDefFoundError: com/intellij/util/PlatformUtilsCore
at com.microsoftopentechnologies.intellij.AzurePlugin.<clinit>(AzurePlugin.java:52)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at com.intellij.openapi.components.impl.ComponentManagerImpl.a(ComponentManagerImpl.java:408)
at com.intellij.openapi.components.impl.ComponentManagerImpl.init(ComponentManagerImpl.java:96)
at com.intellij.openapi.components.impl.ComponentManagerImpl.init(ComponentManagerImpl.java:90)
at com.intellij.openapi.project.impl.ProjectImpl.init(ProjectImpl.java:299)
at com.intellij.openapi.project.impl.ProjectManagerImpl.a(ProjectManagerImpl.java:228)
at com.intellij.openapi.project.impl.ProjectManagerImpl.access$300(ProjectManagerImpl.java:66)
at com.intellij.openapi.project.impl.ProjectManagerImpl$3.run(ProjectManagerImpl.java:308)
at com.intellij.openapi.progress.impl.CoreProgressManager.a(CoreProgressManager.java:446)
at com.intellij.openapi.progress.impl.CoreProgressManager.executeProcessUnderProgress(CoreProgressManager.java:392)
at com.intellij.openapi.progress.impl.ProgressManagerImpl.executeProcessUnderProgress(ProgressManagerImpl.java:54)
at com.intellij.openapi.progress.impl.CoreProgressManager.executeNonCancelableSection(CoreProgressManager.java:170)
at com.intellij.openapi.project.impl.ProjectManagerImpl.getDefaultProject(ProjectManagerImpl.java:303)
at com.intellij.ide.fileTemplates.FileTemplateManager.getDefaultInstance(FileTemplateManager.java:67)
at com.intellij.ide.fileTemplates.FileTemplateManager.getInstance(FileTemplateManager.java:63)
at com.dci.intellij.dbn.DatabaseNavigator.initComponent(DatabaseNavigator.java:60)
at com.intellij.openapi.components.impl.ComponentManagerImpl$ComponentConfigComponentAdapter.getComponentInstance(ComponentManagerImpl.java:518)
at com.intellij.openapi.components.impl.ComponentManagerImpl.createComponents(ComponentManagerImpl.java:123)
at com.intellij.openapi.application.impl.ApplicationImpl.access$801(ApplicationImpl.java:90)
at com.intellij.openapi.application.impl.ApplicationImpl$12.run(ApplicationImpl.java:496)
at com.intellij.openapi.progress.impl.CoreProgressManager$2.run(CoreProgressManager.java:142)
at com.intellij.openapi.progress.impl.CoreProgressManager.a(CoreProgressManager.java:446)
at com.intellij.openapi.progress.impl.CoreProgressManager.executeProcessUnderProgress(CoreProgressManager.java:392)
at com.intellij.openapi.progress.impl.ProgressManagerImpl.executeProcessUnderProgress(ProgressManagerImpl.java:54)
at com.intellij.openapi.progress.impl.CoreProgressManager.runProcess(CoreProgressManager.java:127)
at com.intellij.openapi.application.impl.ApplicationImpl.createComponents(ApplicationImpl.java:505)
at com.intellij.openapi.components.impl.ComponentManagerImpl.init(ComponentManagerImpl.java:107)
at com.intellij.openapi.application.impl.ApplicationImpl.load(ApplicationImpl.java:454)
at com.intellij.openapi.application.impl.ApplicationImpl.load(ApplicationImpl.java:446)
at com.intellij.idea.IdeaApplication.run(IdeaApplication.java:194)
at com.intellij.idea.MainImpl$1$1$1.run(MainImpl.java:63)
at java.awt.event.InvocationEvent.dispatch(InvocationEvent.java:311)
at java.awt.EventQueue.dispatchEventImpl(EventQueue.java:749)
at java.awt.EventQueue.access$500(EventQueue.java:97)
at java.awt.EventQueue$3.run(EventQueue.java:702)
at java.awt.EventQueue$3.run(EventQueue.java:696)
at java.security.AccessController.doPrivileged(Native Method)
at java.security.ProtectionDomain$1.doIntersectionPrivilege(ProtectionDomain.java:75)
at java.awt.EventQueue.dispatchEvent(EventQueue.java:719)
at com.intellij.ide.IdeEventQueue.dispatchEvent(IdeEventQueue.java:360)
at java.awt.EventDispatchThread.pumpOneEventForFilters(EventDispatchThread.java:201)
at java.awt.EventDispatchThread.pumpEventsForFilter(EventDispatchThread.java:116)
at java.awt.EventDispatchThread.pumpEventsForHierarchy(EventDispatchThread.java:105)
at java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:101)
at java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:93)
at java.awt.EventDispatchThread.run(EventDispatchThread.java:82)
Caused by: java.lang.ClassNotFoundException: com.intellij.util.PlatformUtilsCore PluginClassLoader[com.microsoftopentechnologies.intellij, 0.1.255]
at com.intellij.ide.plugins.cl.PluginClassLoader.loadClass(PluginClassLoader.java:68)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 48 more
<issue_comment>username_1: The plugin you are looking at is now being split into 3 separate plugins, one for Java developers on Azure, one for Android developers, and one which is a common dependency of the other two, which includes the Azure services explorer. They all work in IntelliJ 15. The Azure Toolkit for Java plugin and the Azure Services Explorer plugin are already available:
- https://plugins.jetbrains.com/plugin/8053
- https://plugins.jetbrains.com/plugin/8052
We expect the one for Android (if that’s what you’re looking for) to be released over the next few days. It will also support the latest intelliJ 15.
<issue_comment>username_0: so, ms one tech is no longer in use?
<issue_comment>username_1: The 3 new plugins are the new version of this single msopentech plugin. We 've split its functionality among those 3. So the msopentech one will no longer be worked on because the 3 new plugins are taking its place. Besides containing all of the msopentech plugin's functionality, they also have some additional enhancements.
Btw, we've now also released the Android plugin, containing the Android-specific parts of the msopentech plugin's functionality: http://plugins.jetbrains.com/plugin/8077?pr.<issue_closed>
<issue_comment>username_0: Thanks. then, it will be better if ms can remove the obsolete plugin from intelliJ plugin repo | {'fraction_non_alphanumeric': 0.08809263026130495, 'fraction_numerical': 0.029572836801752465, 'mean_word_length': 5.616977225672878, 'pattern_counts': {'":': 0, '<': 8, '<?xml version=': 0, '>': 8, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '7360220', 'n_tokens_mistral': 2005, 'n_tokens_neox': 1875, 'n_words': 334} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Order RSS feeds by most recent pubDate
username_0: Historically, RSS feeds were ordered chronologically. More importantly, a number of RSS reader services are short-sighted (buggy) and don't parse the entire RSS every time, but rather stop when they hit an item they've seen before, assuming they've found everything new. In that scenario, an unchanging top item with a lot of following items that do change don't get picked up by said services until much later when they do a full parse.
I see this a lot more with a personalized RSS feed, which doesn't have nearly as much churn as the main site/RSS.
<issue_comment>username_1: But that would break the ordering for RSS readers that aren't storing everything but just showing the current view and refreshing every so often.<issue_closed>
<issue_comment>username_0: That's a thing?
Okay, closed I guess.
<issue_comment>username_0: FYI- I ended up rolling this myself using hottest.json?token=X, so please
don't take away the use of token there. ;) I've only seen it publicized in
the context of personalized RSS, so I figured I'd mention it.
<NAME> | {'fraction_non_alphanumeric': 0.04995617879053462, 'fraction_numerical': 0.0035056967572304996, 'mean_word_length': 4.856410256410256, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '30847094', 'n_tokens_mistral': 314, 'n_tokens_neox': 281, 'n_words': 175} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Documentation suggests that /docker/<longid> params exist in docker containers, but it doesn't
username_0: ### Problem description
The documentation (linked below) suggests that a file exists at `/sys/fs/cgroup/memory/docker/<longid>/`, but it doesn't, at least on a container based on vanilla `debian:stretch`.
### Problem location
- I saw a problem on the following URL: https://github.com/docker/docker.github.io/blob/master/config/containers/runmetrics.md#find-the-cgroup-for-a-given-container
### Suggestions for a fix
It would be helpful if the docs could suggest why this file might not exist. | {'fraction_non_alphanumeric': 0.1, 'fraction_numerical': 0.0015384615384615385, 'mean_word_length': 4.470588235294118, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '5404453', 'n_tokens_mistral': 199, 'n_tokens_neox': 178, 'n_words': 69} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Can´t get gatsby to process my scss files
username_0: I started out with the minimal starter project, than added a couple of .scss files into the css folder, but can´t get gatsby to process those files, if I run develop the styles are not loaded same when I run build.
Can´t find on docs any documentation about how to properly set this up, I tried some webpack configs I found on web but no changes.
<issue_comment>username_0: Ok so I figured this out finally lol, I had to import the .scss file into the page jsx.
`import path/to/my/scss/file.scss `
is there a way to load it as a file in the header?
<issue_comment>username_1: You would need to use the ExtractTextPlugin from webpack to create a CSS bundle containing all your CSS rules. Currently, sass-loaders spits out the CSS into the JS bundle, but if you use that Webpack plugin, you can add a <link> to the compiled CSS bundle<issue_closed>
<issue_comment>username_2: If you're still having trouble, checkout the sass example site in the examples folder | {'fraction_non_alphanumeric': 0.04446546830652791, 'fraction_numerical': 0.003784295175023652, 'mean_word_length': 4.425641025641026, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '24854711', 'n_tokens_mistral': 294, 'n_tokens_neox': 284, 'n_words': 173} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Material Values Constantly Changing
username_0: Hey @username_1!
Firstly, thanks for the great plugin, it made designing our in-app catalog a lot easier! It's much appreciated.
I'm just reaching out to find out if you know why the values of a RoundedCorners material might be changing constantly?
It seems like every time we open the prefab that has objects using the material, the width, height and radius values change - it's a bit annoying because it constantly shows up in our source control!
Thanks again!
<issue_comment>username_1: Hi @username_0.
It is changing every time [OnRectTransformDimensionsChange](https://github.com/username_1/Unity-UI-Rounded-Corners/blob/master/UiRoundedCorners/ImageWithRoundedCorners.cs#L12) or [OnValidate](https://github.com/username_1/Unity-UI-Rounded-Corners/blob/master/UiRoundedCorners/ImageWithRoundedCorners.cs#L16) is called. Just Unity stuff, nothing special.
Are you sure everything is ok with your layout?
<issue_comment>username_2: Hi, I'm getting the same problem here. Every time I open a scene the roundness will change, and when I save the scene, it changes again.
Any help is appreciated, thanks!
<issue_comment>username_1: Sorry for the late reply @username_2. I cannot get this thing so can you or @username_0 send me project (as clear as possible) with bug I can reproduce?
<issue_comment>username_0: Hey @username_1, sorry for the very late response, it was a crazy time over the holidays.
From what I can tell, the material changes on Play when the resolution has been changed, which happens quite a bit as we have devs working on Android and iOS versions of our app on both Windows and Mac computers.
I've attached a sample project that seems to show what is happening. If you select FullContentsButton_RoundedCorners.mat and then play around with resolution size, you should see it changing. You may also have to enter and exit Play mode after changing resolutions.
[MaterialTest.zip](https://github.com/username_1/Unity-UI-Rounded-Corners/files/5863985/MaterialTest.zip)
<issue_comment>username_3: I can confirm that this is happening and it's very frustrating if you are working with VCS. Could you find any temporary fix? @username_0
<issue_comment>username_0: @username_3 Unfortunately I haven't been able to. Currently it seems like the values themselves are not changing anymore... for some reason(?), but the material file still gets marked as if it has changed. Within SourceTree if we select the file, it says "No changes in this file have been detected, or it is a binary file."
We actually added .mat files in the specific folder to the gitignore, but this does not stop changes from appearing as the file has already been committed to the project. Just might explain why the values themselves might not be changing anymore.'
At this stage we've just learned to live with it, but your comment has reminded me to try to see if we can figure out how to stop the issue from happening again. If I come up with anything then I'll post again here.
<issue_comment>username_4: I'm also having this same issue. Is it (ironically!) a rounding issue somewhere? Seems like every time it recalculates the values, it gets a slightly different value. Plays havoc with source-control history.<issue_closed>
<issue_comment>username_1: Solved with version 3.0.0 | {'fraction_non_alphanumeric': 0.05288035450516987, 'fraction_numerical': 0.009748892171344165, 'mean_word_length': 4.807890222984563, 'pattern_counts': {'":': 0, '<': 11, '<?xml version=': 0, '>': 11, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '8787167', 'n_tokens_mistral': 900, 'n_tokens_neox': 850, 'n_words': 478} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: disease process vs disease course
username_0: The ontology uses the ICDO class `disease process` as super class of `coronavirus infectious disease (process)`. However, the ontology also includes OGMS' `disease course` class. We isn't `coronavirus infectious disease (process)` a child of `disease course`? In other words, what is the appropriate distinction between `disease process` and `disease course` that is pertinent to classifying`coronavirus infectious disease (process)`.
FWIW, I don't OGMS is clear about its distinction between a `bodily process` and a `disease course` either. But, if we find the distinction here confusing, I think we should not include one of the classes.
cc @username_1 @sivaramarabandi @linikujp
<issue_comment>username_1: OGMS' disease course class definition:
"The totality of all processes through which a given disease instance is realized."
The totality defined in the 'disease course' means that the survival of the pathogen (e.g., some virus, bacterium, or parasite) outside a human body such as in insect, animal host such as bat, or air may also be part of the disease course.
The OGMS term 'bodily process' is in parallel with the OGMS' disease course.
The disease process is a subclass of OGMS's pathological bodily process, which is a subclass of OGMS term 'bodily process'.
<issue_comment>username_1: Yes. I think that disease process is a part of disease course
<issue_comment>username_1: I think this issue is solved. Feel free to reopen if more disscussion is needed. Thanks.<issue_closed> | {'fraction_non_alphanumeric': 0.056568196103079824, 'fraction_numerical': 0.0031426775612822125, 'mean_word_length': 5.053231939163498, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '28030217', 'n_tokens_mistral': 442, 'n_tokens_neox': 404, 'n_words': 230} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Add Pod UID to all "kube_pod_*" metrics
username_0: <!-- This form is for bug reports and feature requests ONLY!
If you're looking for help check [KUBE-STATE-METRICS](https://github.com/kubernetes/kube-state-metrics) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
-->
**Is this a BUG REPORT or FEATURE REQUEST?**:
kind feature
**What happened**:
Currently, only `kube_pod_info` metric exposes pod `UID` value.
It is assumed that `namespace/pod` combination should be always unique at any given point in time.
However, it does not accommodate for cases when pods can be created, deleted, and recreated with the same name over some period of time.
This is typically the case with `StatefulSet` pods and CRD's auxiliary pods (the pods created by custom resource controllers).
In those cases, it is not uncommon to recreate pods with the previously used names.
This results in interesting and at times incorrect metric values, especially when used in "join" multiple metrics: `ON (namespace, pod)` prometheus queries.
**What you expected to happen**:
I propose to add `uid` label to all `kube_pod_.*` metrics as it is done in `kube_pod_info`
**How to reproduce it (as minimally and precisely as possible)**:
The following graph demonstrates the incorrect durations (seconds) value between `kube_pod_created` and `container_start_time_seconds`

The green line represents the duration (seconds) and the lines below represent distinct pods according to `kube_pod_info` (which includes `uid` value).
We can observe that sometime after `12:28` the old pod was deleted and a new pod (w/ new `uid` but with the same name) was created shortly after `12:30`.
However, the query join did not include `uid` value (since it does not exist on `kube_pod_created`) and resulted in incorrect duration computation where
the newer pod's `container_start_time_seconds` was computed against the old pod's `kube_pod_created` value.
This issue would have been avoided if we could use join `ON (namespace,pod,uid)` instead of `ON(namespace,pod`).
**Anything else we need to know?**:
**Environment**:
- Kubernetes version (use `kubectl version`):
- Kube-state-metrics image version
<issue_comment>username_0: If the community/maintainers find this feature request useful, I’d be happy to contribute.
<issue_comment>username_1: @username_0 hey, that sounds like a great idea! Feel free to contribute the changes, if you need any guidence let me know! | {'fraction_non_alphanumeric': 0.0810710301227222, 'fraction_numerical': 0.01822238750464857, 'mean_word_length': 4.772532188841201, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '28422926', 'n_tokens_mistral': 811, 'n_tokens_neox': 736, 'n_words': 344} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: 概率编程语言 Stan
username_0: 官网简介
---
Stan is a state-of-the-art platform for statistical modeling and high-performance statistical computation. Thousands of users rely on Stan for statistical modeling, data analysis, and prediction in the social, biological, and physical sciences, engineering, and business.
Users specify log density functions in Stan’s probabilistic programming language and get:
- full Bayesian statistical inference with MCMC sampling (NUTS, HMC)
- approximate Bayesian inference with variational inference (ADVI)
- penalized maximum likelihood estimation with optimization (L-BFGS)
---
写作动机: Stan 发布 2.19.0 继 [支持 MPI](https://github.com/stan-dev/cmdstan/releases/tag/v2.18.0) 后终于开始 [支持 GPU](https://github.com/stan-dev/cmdstan/releases) 关注其发展一年多了,终于到了该下笔介绍的时候了
Stan 的接口有很多,如 [rstan](https://github.com/stan-dev/rstan)、 [pystan](https://github.com/stan-dev/pystan)、 [cmdstan](https://github.com/stan-dev/cmdstan) 等共计9种,由于对 cmdstan 功能支持最为全面,因此文章会介绍这个接口的使用,而且学完这个, rstan 就比较容易了
作为入门篇,首先介绍单机 CPU 版 ,此时写作环境如下
1. cmdstan 2.19.0 包含 boost 1.69.0 eigen 3.3.3 sundials 4.1.0
1. 虚拟机平台 Fedora 29 Server 64位 GCC/G++ 8.3.1
1. 内存 5G CPU 单核双线程 i7-4710MQ 主频 2.5 GHz
分以下四部分介绍
1. 如何安装使用 stan,默认安装和自定义安装
2. 以简单的二项模型为例,贝叶斯估计之HMC 采样算法与 MLE 估计比较
3. HMC 算法各个参数的解释,一并介绍理论
4. 含有超参数的复杂空间模型之 Stan 实现
<issue_comment>username_0: ## 安装
1. 下载软件压缩包
```bash
curl -fLo ./cmdstan-2.19.tar.gz https://github.com/stan-dev/cmdstan/releases/download/v2.19.0/cmdstan-2.19.0.tar.gz
```
1. 解压
```
tar -xzf cmdstan-2.19.0.tar.gz
cd cmdstan-2.19.0
tree -L 2 .
.
├── bin
│ ├── cmdstan
│ ├── diagnose
│ ├── print
│ ├── stanc
│ └── stansummary
├── examples
│ └── bernoulli
├── Jenkinsfile
├── LICENSE
├── make
│ ├── command
│ ├── program
│ ├── stanc
│ └── tests
├── makefile
├── README.md
├── runCmdStanTests.py
├── src
│ ├── cmdstan
│ ├── docs
│ └── test
├── stan
│ ├── Jenkinsfile
│ ├── lib
│ ├── LICENSE.md
│ ├── licenses
│ ├── make
│ ├── makefile
│ ├── README.md
│ ├── RELEASE-NOTES.txt
│ ├── runTests.py
│ └── src
└── test-all.sh
14 directories, 20 files
```
1. 编译
```bash
cd cmdstan-2.19.0
make build
```
最后显示
```
--- CmdStan v2.19.0 built ---
```
表示编译成功,中间没有任何警告和错误
## 测试
伯努利分布模型: Y 服从 0-1 分布,观测数据共10个,现在需要估计其参数 theta
```
├── bernoulli 编译后生成的可执行文件
├── bernoulli.d
├── bernoulli.data.json 数据文件 JSON 格式
├── bernoulli.data.R 数据文件 R 代码
├── bernoulli.hpp 编译后生成的头文件
[Truncated]
energy__ 7.9 8.4e-02 1.2e+00 6.8 7.5 10 2.0e+02 1.3e+04 1.0e+00
theta 0.25 7.0e-03 1.3e-01 0.063 0.23 0.48 3.3e+02 2.1e+04 1.0e+00
Samples were drawn using hmc with nuts.
For each parameter, N_Eff is a crude measure of effective sample size,
and R_hat is the potential scale reduction factor on split chains (at
convergence, R_hat=1).
```
## 与频率派的最大似然估计的比较
## 参考资料
1. [Getting Started with CmdStan](https://github.com/stan-dev/cmdstan/wiki/Getting-Started-with-CmdStan)<issue_closed> | {'fraction_non_alphanumeric': 0.135258358662614, 'fraction_numerical': 0.045288753799392095, 'mean_word_length': 2.382322713257965, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 7, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 1, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '12512325', 'n_tokens_mistral': 1728, 'n_tokens_neox': 1646, 'n_words': 355} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: [Codelab Issue] Testing Codelab 5.1, Step 8 - What drawing software to use in Codelab
username_0: **Describe the problem**
What drawing software to use in Codelab?
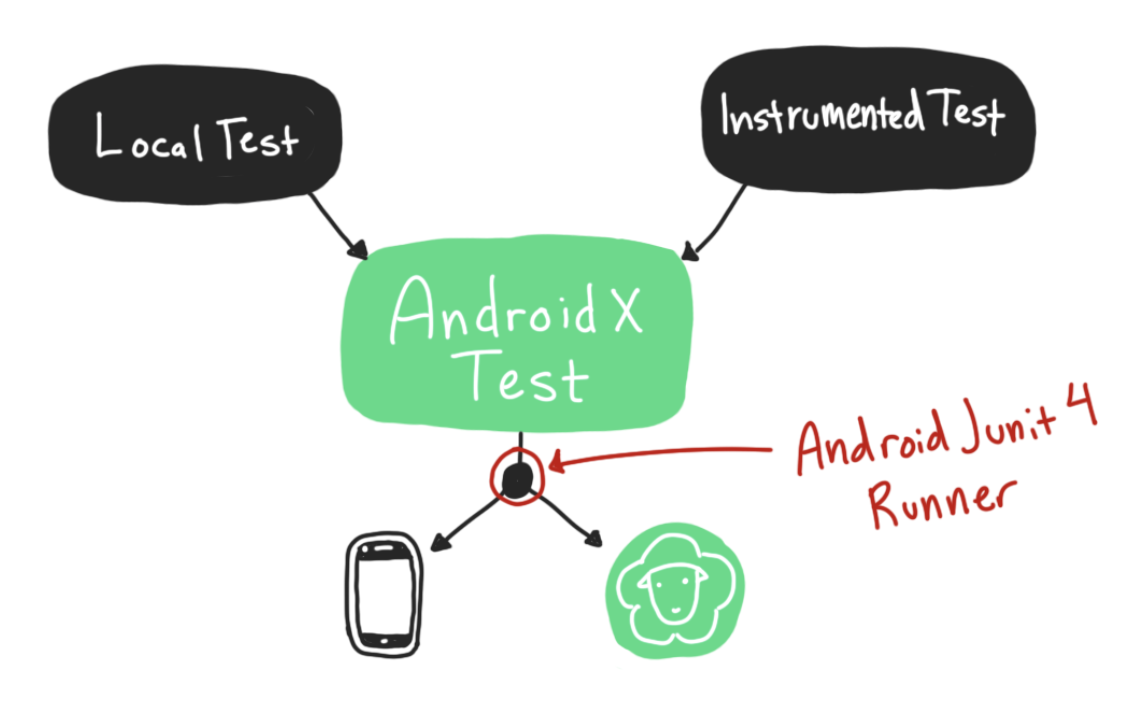
<issue_comment>username_0: 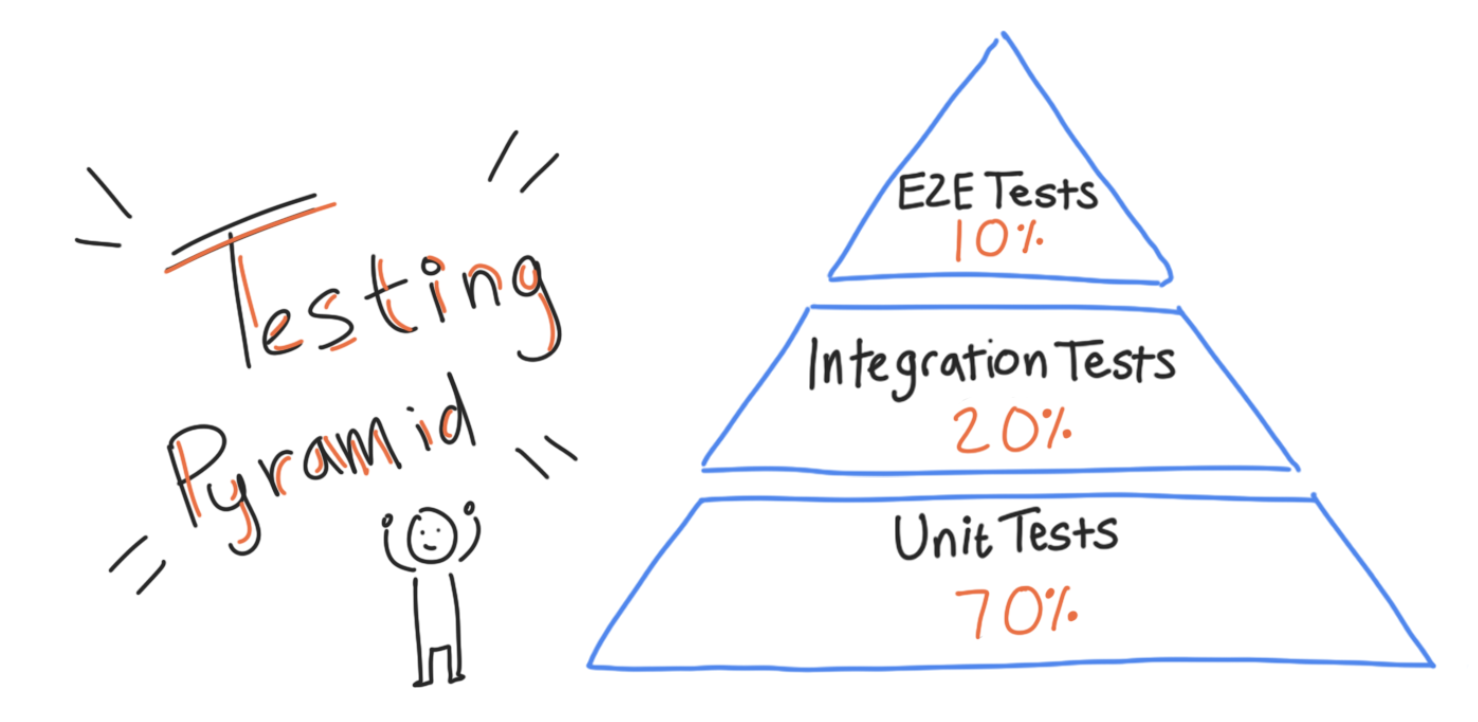
<issue_comment>username_1: Sorry I don't have this information<issue_closed> | {'fraction_non_alphanumeric': 0.12110091743119267, 'fraction_numerical': 0.044036697247706424, 'mean_word_length': 6.583333333333333, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '25638633', 'n_tokens_mistral': 208, 'n_tokens_neox': 180, 'n_words': 36} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Proposal: allow extensions to register web share targets
username_0: Just like PWAs, it can be very beneficial for extensions to register web share targets. We can potentially just go for a 1:1 from the PWA implementation.
See:
https://web.dev/web-share-target/
<issue_comment>username_1: I have an extension which can set local images and videos as wallpapers. It would be nice to share an edited video or photo from an app straight to the extension instead of navigating through windows and menus.
<issue_comment>username_1: This could also be beneficial for fileBrowserHandler extensions which would otherwise have to be selected from the file explorer on Chrome OS. | {'fraction_non_alphanumeric': 0.04096045197740113, 'fraction_numerical': 0.007062146892655367, 'mean_word_length': 5.05982905982906, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '30792665', 'n_tokens_mistral': 171, 'n_tokens_neox': 164, 'n_words': 101} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Add a --show-config cli argument that prints the config.
username_0: See https://github.com/facebook/jest/pull/3156/files#diff-8006e39142c24851115752df17e9c1c0R51
<issue_comment>username_1: Like `--debug` but it shows the config and exits right away?
<issue_comment>username_0: yes, a json-parseable config would be good. Maybe even this:
```
{
version: '…',
config: {…},
}
```
+ adjusting jest-editor-support to use this new command.
<issue_comment>username_1: Perfect, so I guess also `testFramework` right?
<issue_comment>username_0: Nah, nobody needs that. Can we make it so `--debug` also outputs its data as JSON the same way `--show-config` does (except without exiting)? The whole `=` is really weird.
<issue_comment>username_2: Can I take one of these up? Seems like there are 2 issues here, one with the config to JSON, and the other for `--debug`? Maybe a separate issue for the `--debug` flag and I can take that on?
<issue_comment>username_1: @username_2 sure, let me know if you need any help
<issue_comment>username_2: The issue title mentions the argument as `--show-config`, but the convention of other arguments would make it `--showConfig`. Just wanted to throw that out there.<issue_closed> | {'fraction_non_alphanumeric': 0.09872611464968153, 'fraction_numerical': 0.03264331210191083, 'mean_word_length': 4.792626728110599, 'pattern_counts': {'":': 0, '<': 10, '<?xml version=': 0, '>': 10, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '27714218', 'n_tokens_mistral': 397, 'n_tokens_neox': 373, 'n_words': 162} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: test: add FixturesTester and enable js/arrayLiteral alignment tests
username_0: This PR changes way how alignment tests are generated.
`FixturesTester` is helper class which makes all what previously `createFixturePatternConfigFor`, `fixturesRequiringSourceTypeModule`, and those loops was doing before in way cleaner way.
<issue_comment>username_0: github diff don't want to be nice and make diff readable...
<issue_comment>username_1: https://github.com/username_2/typescript-estree/pull/67/files?w=1 might look a little better
<issue_comment>username_0: @username_1 what do you think about this anyway?
<issue_comment>username_2: I personally wouldn't have invested time in this, as it does not appear to add any new capabilities or fix any pain points vs the original code, but there is certainly nothing wrong with the changes you have made.
If you want to fix up the conflicts, I am happy to merge it in
<issue_comment>username_0: i'm going to fix those merge conflicts
<issue_comment>username_2: :tada: This PR is included in version 10.0.1 :tada:
The release is available on:
- [npm package (@latest dist-tag)](https://www.npmjs.com/package/typescript-estree)
- [GitHub release](https://github.com/username_2/typescript-estree/releases/tag/v10.0.1)
Your **[semantic-release](https://github.com/semantic-release/semantic-release)** bot :package::rocket: | {'fraction_non_alphanumeric': 0.08695652173913043, 'fraction_numerical': 0.01496792587312901, 'mean_word_length': 5.591549295774648, 'pattern_counts': {'":': 0, '<': 8, '<?xml version=': 0, '>': 8, 'https://': 4, 'lorem ipsum': 0, 'www.': 1, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '2255376', 'n_tokens_mistral': 410, 'n_tokens_neox': 390, 'n_words': 156} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: How to use the models
username_0: Hi, thanks for the code. This is sort of an absolute beginner question but how do you use the models to test the performance over the datasets once you compile the models. I ran `model_for_cuhk03.py` and got the message:
```
model definition complete
model definition done.
model compile done.
```
together with the network architecture. How do I continue from here?
<issue_comment>username_1: @username_0 Hi, this is a project which I did four months ago. So I cannot remember everything that I did that time. For your question, you could look through the "train" function in the `model_for_cuhk03.py`, which is just in front of the "if __name__ == '__main__': ". You should open a ipython and use a command "run model_for_cuhk03.py" to compile the model, and then, try the command "train(model)". For more details, you could just read the code of function "train".
<issue_comment>username_0: @username_1 Thanks, I could get it working now.<issue_closed> | {'fraction_non_alphanumeric': 0.06504854368932039, 'fraction_numerical': 0.010679611650485437, 'mean_word_length': 4.792134831460674, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '15262575', 'n_tokens_mistral': 285, 'n_tokens_neox': 280, 'n_words': 155} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Tests don't run properly if Jim not built in src dir.
username_0: I'm using this patch.
--- Makefile.in.orig Sun Apr 5 12:22:11 2015
+++ Makefile.in Sun Apr 5 12:24:43 2015
@@ -112,7 +112,7 @@
@endif
test check: $(JIMSH)
- cd @srcdir@/tests; $(DEF_LD_PATH) $(MAKE) jimsh=@builddir@/jimsh
+ cd @srcdir@/tests; $(DEF_LD_PATH) JIMLIB='@top_srcdir@' $(MAKE) jimsh=@builddir@/jimsh
$(OBJS): Makefile $(wildcard *.h)
<issue_comment>username_1: Thanks. I pushed a slightly different fix.<issue_closed> | {'fraction_non_alphanumeric': 0.15818181818181817, 'fraction_numerical': 0.05818181818181818, 'mean_word_length': 4.401960784313726, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '16427878', 'n_tokens_mistral': 250, 'n_tokens_neox': 218, 'n_words': 58} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Backup-related integration tests failing in mysql 5.6
username_0: To reproduce:
```
go run test.go -flavor percona -print-log backup backup_mysqlctld initial_sharding_multi local_example xtrabackup_xbstream xtrabackup_xtra xtrabackup
```
The problem appears to be come from the switch from `UPDATE mysql.user` to `ALTER USER` in https://github.com/vitessio/vitess/pull/4803/files#diff-2ff73b8b1f063f5793a26998202b02eaL86
Those `alter user` statement are not syntactically valid in 5.6<issue_closed> | {'fraction_non_alphanumeric': 0.07339449541284404, 'fraction_numerical': 0.060550458715596334, 'mean_word_length': 5.658536585365853, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '15030621', 'n_tokens_mistral': 210, 'n_tokens_neox': 183, 'n_words': 51} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: DOC: Add RT link to README
username_0: So people can find it.
<issue_comment>username_1: Personally, I would prefer more succinct default badge labels.
<issue_comment>username_0: There is no badge for the RT version, unless @jhunkeler or @rendinam had added one recently?
<issue_comment>username_1: @username_0 Disregard my comment: I got confused. | {'fraction_non_alphanumeric': 0.06788511749347259, 'fraction_numerical': 0.013054830287206266, 'mean_word_length': 6.529411764705882, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '29624756', 'n_tokens_mistral': 116, 'n_tokens_neox': 110, 'n_words': 48} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: dvc pull "counts" incorrectly in the presence of locked stages
username_0: in the presence of locked stages the output from `dvc pull` is slightly wrong (the right files get pulled though):
```
[ec2-user@ip-172-31-3-
Warning: DVC file 'Pro
Warning: DVC file 'Pro
Preparing to download
Preparing to collect s
[#####################
[#####################
(1/28): [#############
(2/28): [#############
(3/28): [#############
(4/28): [#############
(5/28): [#############
(6/28): [#############
(7/28): [#############
(8/28): [#############
(9/28): [#############
(10/28): [############
(11/28): [############
(12/28): [############
(13/28): [############
(14/28): [############
(15/28): [############
(16/28): [############
(17/28): [############
(18/28): [############
(19/28): [############
(20/28): [############
(21/28): [############
(22/28): [############
(23/28): [############
(24/28): [############
(25/28): [############
(26/28): [############
(27/28): [############
(28/28): [############
Warning: DVC file 'Pro
Computing md5 for a la
(29/28): [############
(30/28): [############
Warning: DVC file 'Pro
(30/28): [############
(30/28): [############
```
(clipped for clarity)
As you can see, I have 2 locked stages and they are not included in the total count (thus the /28 part) however, they are still being downloaded, so the count goes up to 30, which is wrong.
<issue_comment>username_1: @username_0 could you check if that issue is present for current master? I am not sure, but #1817 might have solve it<issue_closed>
<issue_comment>username_2: in the presence of locked stages the output from `dvc pull` is slightly wrong (the right files get pulled though):
```
[ec2-user@ip-172-31-3-
Warning: DVC file 'Pro
Warning: DVC file 'Pro
Preparing to download
Preparing to collect s
[#####################
[#####################
(1/28): [#############
(2/28): [#############
(3/28): [#############
(4/28): [#############
(5/28): [#############
(6/28): [#############
(7/28): [#############
(8/28): [#############
(9/28): [#############
(10/28): [############
(11/28): [############
(12/28): [############
(13/28): [############
(14/28): [############
(15/28): [############
(16/28): [############
(17/28): [############
(18/28): [############
(19/28): [############
(20/28): [############
(21/28): [############
(22/28): [############
(23/28): [############
(24/28): [############
(25/28): [############
(26/28): [############
(27/28): [############
(28/28): [############
Warning: DVC file 'Pro
Computing md5 for a la
(29/28): [############
(30/28): [############
Warning: DVC file 'Pro
(30/28): [############
(30/28): [############
```
(clipped for clarity)
As you can see, I have 2 locked stages and they are not included in the total count (thus the /28 part) however, they are still being downloaded, so the count goes up to 30, which is wrong.<issue_closed> | {'fraction_non_alphanumeric': 0.42762284196547146, 'fraction_numerical': 0.0903054448871182, 'mean_word_length': 4.652908067542214, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 4, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '14736192', 'n_tokens_mistral': 1237, 'n_tokens_neox': 1071, 'n_words': 280} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: add text classification analyzer
username_0: The initial draft for text classifier which will resolve #77
<issue_comment>username_0: @username_1 PR is complete from my side, one possible improvement that can be added. is mapping of labels, transformers map labels as {"LABEL_0", "LABEL_1",....,"LABEL_N"}, what we can do is use the labels parameter and map values from labels to transformers labels, however, if the user passes the wrong sequence of labels, they'd get altogether wrong predictions. So there must be some mechanism for enforcing the right sequence in my knowledge it won't be possible to enforce such a check. what do you think?
<issue_comment>username_1: @username_0 I have refactored you changes a little. Also added functionality to support user provided label map. Check test and let me know if you have any concern. Post that I will merge this.
Also it would be great if we plan a demo/article/colab showing capabilities of https://huggingface.co/obsei-ai/sell-buy-intent-classifier-bert-mini
Or we can show demo of newly added classifier to detect hate speech via https://huggingface.co/Hate-speech-CNERG/dehatebert-mono-english
So workflow would be Twitter or Reddit -> Analyzer -> Elastic Search or Slack
<issue_comment>username_0: @username_1 I can write a small colab tutorial and the post it on LinkedIn about buy-sell intent model.
<issue_comment>username_1: @username_0 We can add tutorial here https://github.com/obsei/obsei#tutorials and article here https://github.com/obsei/obsei#articles | {'fraction_non_alphanumeric': 0.06278026905829596, 'fraction_numerical': 0.008327994875080076, 'mean_word_length': 4.984674329501916, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 8, 'https://': 4, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '3197463', 'n_tokens_mistral': 427, 'n_tokens_neox': 409, 'n_words': 207} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: publish an npm package
username_0: hi , the plain-draggable is a very useful project for our work.
but there is a problem that we expect to install your code with npm.
so is there any plan to publish your work to npm?
<issue_comment>username_1: Hi @username_0, thank you for your comment.
So, could you close this issue if it was solved?
<issue_comment>username_1: No reply came, then I close this abandoned issue.<issue_closed> | {'fraction_non_alphanumeric': 0.05555555555555555, 'fraction_numerical': 0.008547008547008548, 'mean_word_length': 4.790123456790123, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '11687957', 'n_tokens_mistral': 132, 'n_tokens_neox': 129, 'n_words': 70} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Fix docs.
username_0: Many of the code references in markdown were broken when these files
started being generated by protocol buffers.
It would be better to have the code generation print the comments
necessary to render the code block by name (e.g. "DefKey") --
that's left as an issue.
<issue_comment>username_0: @username_1 , so I can deploy this.
<issue_comment>username_0: also, if you know how to force gogoprotobuf to force a comment in certain positions...we can make this better, but I couldn't figure out how to do that in a timebox
<issue_comment>username_1: @username_2 or @username_3 would know better than I about how to get gogoproto to do stuff. Would this be easy, guys?
<issue_comment>username_2: I'm not sure what's going on here. Can you elaborate on what command is being run, and what generates what? Also what it should generate instead.
<issue_comment>username_0: @username_2 sorry for the missing context.
We have a markdown file with an embedded reference to code living in a protobuf generated file, e.g. https://github.com/sourcegraph/srclib/blob/master/graph/def.pb.go#L42
We would like to reference the code in the markdown file as `[[.code "graph/def.pb.go" "DefKey"]]` but this syntax requires a `// START DefKey OMIT` and `// END DefKey OMIT` comment wrapped around the `DefKey` function in the pb-generated file.
That file is generated from https://github.com/sourcegraph/srclib/blob/master/graph/def.proto via `go generate ./...` -- do you know how to get the comments above in the generated output?
<issue_comment>username_3: I don't think you are likely to find an easy way to have gogoproto generate wrapping `// START DefKey OMIT` and `// END DefKey OMIT` comments in the output Go file.. You could have them placed in the type definition documentation (i.e. right above `type DefKey struct {`, but not at the end of the type definition (after the closing `}`).
What reads/needs those odd `START` and `END` omit blocks? It sounds like the correct fix may be making that program aware of Go types or something.
<issue_comment>username_0: @username_3 : https://github.com/sourcegraph/srclib/tree/master/docs#embedding-code-segments
<issue_comment>username_3: @username_0 It sounds like the best quick solution is to use the line number format in the doc you linked:
```
[[.code "grapher/grapher.go" 23 30]]
```
<issue_comment>username_0: @username_3 that's brittle since the file is generated and the line numbers can change, but the person building / deploying the docs might not realize this
<issue_comment>username_0: My strategy is to link to lines from a specific revision, e.g. [[.code "https://raw.githubusercontent.com/sourcegraph/srclib/bf4ec15991ed05161dad3694f8729d48c5124844/graph/ref.pb.go" 14 44]]
<issue_comment>username_3: To conclude my thoughts here, I see these three options:
1. Keep your approach. The docs won't be broken but may become outdated quickly.
2. Fork gogoprotobuf to emit `// START TheTypeName OMIT` `// END TheTypeName OMIT` segments around each data type. We would have ot maintain this fork in the future.
3. Add a preprocessing step that uses `go/parser` to parse the generated protobuf file, insert the `OMIT` comment segments, and write the files back out. This is probably the most robust solution.
<issue_comment>username_1: Option #3 seems like the best option. We can punt on that for now, though, and just file it as an issue. | {'fraction_non_alphanumeric': 0.07457529513389001, 'fraction_numerical': 0.01785200115174201, 'mean_word_length': 4.445141065830721, 'pattern_counts': {'":': 0, '<': 14, '<?xml version=': 0, '>': 14, 'https://': 4, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '18122045', 'n_tokens_mistral': 1021, 'n_tokens_neox': 966, 'n_words': 483} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: pull redis is error
username_0: ### Expected behavior
### Actual behavior
### Information about the Issue
### Steps to reproduce the behavior
1. ...
2. ...
<issue_comment>username_1: Please provide some actual details - none of what you provided help debug this<issue_closed> | {'fraction_non_alphanumeric': 0.0972644376899696, 'fraction_numerical': 0.0121580547112462, 'mean_word_length': 3.7142857142857144, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '1278102', 'n_tokens_mistral': 146, 'n_tokens_neox': 117, 'n_words': 35} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: issue-141 Adding possibility to add customheaders to a single cypher …
username_0: issue-141 Adding possiblity to add customheaders to a single cypher query.
issue-71 Adding max-execution-time to a single cypher query.
<issue_comment>username_1: Awesome work! (and thanks for clearing up the MaxExecutionTime bit as well) | {'fraction_non_alphanumeric': 0.055710306406685235, 'fraction_numerical': 0.027855153203342618, 'mean_word_length': 5.545454545454546, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '24422979', 'n_tokens_mistral': 110, 'n_tokens_neox': 95, 'n_words': 45} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: FDR specification
username_0: We tested two similar runs with different FDR specification, and it turns out the "--fdr" parameter ranges from 0-100 instead of 0-1.
**[log.txt file from run1]:**
NOTICE: eddlib.algorithm.max_segments: got 72 peaks with qvalue below 1.00. From 215 possible.
**[log.txt file from run2]:**
NOTICE: eddlib.algorithm.max_segments: got 215 peaks with qvalue below 100.00. From 215 possible.
Maybe it's because we were using python package "statsmodels" version 0.6.1 instead of the most most recent version. We haven't tried that yet.<issue_closed>
<issue_comment>username_0: Hmm...that might not be the case since we tried fdr==1.01 and got all 215 peaks. So it must be that the FDR cutoff does not include the specified value itself, that's fine. | {'fraction_non_alphanumeric': 0.08190709046454768, 'fraction_numerical': 0.04645476772616137, 'mean_word_length': 4.46, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '30726824', 'n_tokens_mistral': 268, 'n_tokens_neox': 230, 'n_words': 114} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Your contact information.
username_0: Good afternoon Filoe (Florian). Is there a way I can contact you personally? I don't want to mention my e-mail address on this space. If I mention my e-mail address on this space, then my e-mail address will be flooded with junk mail. I have send 2 messages to you via the web site, https://naudio.codeplex.com or https://www.codeplex.com , because this is the only way I can contact you at this moment. Your company is still listed on the web site of https://www.codeplex.com . Please, let me know. Thank you for your help. Regards. Mr. <NAME>.
<issue_comment>username_1: I've replied to your e-mail.<issue_closed> | {'fraction_non_alphanumeric': 0.07703488372093023, 'fraction_numerical': 0.00436046511627907, 'mean_word_length': 4.141791044776119, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 3, 'lorem ipsum': 0, 'www.': 2, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '20081885', 'n_tokens_mistral': 191, 'n_tokens_neox': 189, 'n_words': 104} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Code cleanup and started documentation in GitHubRepository and GitHubFile
username_0: This PR continues the code cleanup that has begun previously and also adds some bits of documentation in the two specified files. While this is not comprehensive, this lays the first stone towards extensive documentation of this API.
<issue_comment>username_0: I don't understand why the diff is so large in this PR, whereas it's only a few lines on my side. Hiding the whitespaces shows the actual diff.
<issue_comment>username_1: Probably because of different line endings. | {'fraction_non_alphanumeric': 0.03523489932885906, 'fraction_numerical': 0.0050335570469798654, 'mean_word_length': 5.633333333333334, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '26973650', 'n_tokens_mistral': 137, 'n_tokens_neox': 130, 'n_words': 85} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: edited sidebar sass file
username_0: Co-authored-by: kurto8 <<EMAIL>>
Co-authored-by: gigifeeds <<EMAIL>>
Co-authored-by: username_1 <<EMAIL>>
Co-authored-by: samhpyo <<EMAIL>>
Co-authored-by: username_0 <<EMAIL>>
<issue_comment>username_1: mistake, will retry | {'fraction_non_alphanumeric': 0.1505016722408027, 'fraction_numerical': 0.016722408026755852, 'mean_word_length': 6.6923076923076925, 'pattern_counts': {'":': 0, '<': 13, '<?xml version=': 0, '>': 13, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '5468554', 'n_tokens_mistral': 116, 'n_tokens_neox': 114, 'n_words': 25} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Mark remote-control connection with flag
username_0: In case of automatic tools, such as testing environment with up/down scripts, it's convenient to understand, that connection is under remote control or under box.cfg{listen} .
```
git diff 16:56:51
diff --git a/cartridge/remote-control.lua b/cartridge/remote-control.lua
old mode 100644
new mode 100755
index 9a2aacf..dde6502
--- a/cartridge/remote-control.lua
+++ b/cartridge/remote-control.lua
@@ -271,6 +271,9 @@ local function communicate(s)
end
local function rc_handle(s)
+ local fiber = require('fiber')
+ fiber.self().storage['remote-control'] = true
+
local version = string.match(_TARANTOOL, "^([%d%.]+)") or '???'
local salt = digest.urandom(32)
```
<issue_comment>username_0: It can be solve with box.replica.uuid == '0000... '<issue_closed> | {'fraction_non_alphanumeric': 0.1202020202020202, 'fraction_numerical': 0.04040404040404041, 'mean_word_length': 2.48943661971831, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 5, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '2476093', 'n_tokens_mistral': 323, 'n_tokens_neox': 285, 'n_words': 80} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Change React global on dist
username_0: Usually `React` global is exposed capitalized
<issue_comment>username_1: When I am trying to run `npm run example`, it couldn't be built correctly. So I revert it first.
Maybe there have issue in "nested bundle" (`webpack.example.config.js`)?
Could you help to solve it? Thank you! | {'fraction_non_alphanumeric': 0.08055555555555556, 'fraction_numerical': 0.005555555555555556, 'mean_word_length': 5.224137931034483, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '15481546', 'n_tokens_mistral': 103, 'n_tokens_neox': 98, 'n_words': 49} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Ng serve fails with the Yarn and ng4 combinationng serve
username_0: ### OS?
Lubuntu 16.10
### Versions.
@angular/cli: 1.0.0-beta.32.3
node: 7.5.0
os: linux x64
### Repro steps. (On a clean VM)
`sudo yarn global add @angular/cli`
`ng set --global packageManager=yarn`
`ng new MyYarnApp -ng4`
`cd MyYarnApp`
`ng serve` or `ng build`
### The log given by the failure.
```
** NG Live Development Server is running on http://localhost:4200. **
Hash: 431dce9b2028dcad96e7
Time: 7586ms
chunk {0} polyfills.bundle.js, polyfills.bundle.js.map (polyfills) 155 kB {4} [initial] [rendered]
chunk {1} main.bundle.js, main.bundle.js.map (main) 3.72 kB {3} [initial] [rendered]
chunk {2} styles.bundle.js, styles.bundle.js.map (styles) 10.1 kB {4} [initial] [rendered]
chunk {3} vendor.bundle.js, vendor.bundle.js.map (vendor) 2.76 MB [initial] [rendered]
chunk {4} inline.bundle.js, inline.bundle.js.map (inline) 0 bytes [entry] [rendered]
ERROR in Could not resolve module @angular/core/src/di/opaque_token
webpack: Failed to compile.
```
### Mention any other details that might be useful.
This seems to be a combination of installing packages with Yarn, and using Angular 4
<issue_comment>username_1: This is a duplicate of https://github.com/angular/angular-cli/issues/4611
Look at https://github.com/angular/angular-cli/issues/4611#issuecomment-279125728 or https://github.com/angular/angular-cli/pull/4781 for a workaround.
<issue_comment>username_0: I can confirm that changing the Angular versions in the package.json works.<issue_closed>
<issue_comment>username_1: Run `ng version` to be sure again.
It turned out it actually installed ng2 not ng4 :(
<issue_comment>username_1: But then again maybe following https://github.com/angular/angular-cli/issues/4611#issuecomment-279125728 literally works. I'll be trying this later.
<issue_comment>username_2: @username_0 Brilliant! This worked for me. Thanks so much!
<issue_comment>username_2: Well I spoke to soon. Meh. @username_1 you are correct. The above change to package.json results in a NG2 install.
<issue_comment>username_0: @username_1 you are correct, it does use Angular 2 with that change. My bad.

<issue_comment>username_0: ### OS?
Lubuntu 16.10
### Versions.
@angular/cli: 1.0.0-beta.32.3
node: 7.5.0
os: linux x64
### Repro steps. (On a clean VM)
`sudo yarn global add @angular/cli`
`ng set --global packageManager=yarn`
`ng new MyYarnApp -ng4`
`cd MyYarnApp`
`ng serve` or `ng build`
or
`sudo yarn global add @angular/cli`
`ng new MyYarnApp -ng4 --skip-install`
`cd MyYarnApp`
`yarn`
`ng serve` or `ng build`
### The log given by the failure.
```
** NG Live Development Server is running on http://localhost:4200. **
Hash: 431dce9b2028dcad96e7
Time: 7586ms
chunk {0} polyfills.bundle.js, polyfills.bundle.js.map (polyfills) 155 kB {4} [initial] [rendered]
chunk {1} main.bundle.js, main.bundle.js.map (main) 3.72 kB {3} [initial] [rendered]
chunk {2} styles.bundle.js, styles.bundle.js.map (styles) 10.1 kB {4} [initial] [rendered]
chunk {3} vendor.bundle.js, vendor.bundle.js.map (vendor) 2.76 MB [initial] [rendered]
chunk {4} inline.bundle.js, inline.bundle.js.map (inline) 0 bytes [entry] [rendered]
ERROR in Could not resolve module @angular/core/src/di/opaque_token
webpack: Failed to compile.
```
### Mention any other details that might be useful.
This seems to be a combination of installing packages with Yarn, and using Angular 4
<issue_comment>username_3: For those interested, I posted a clean workaround for this problem in https://github.com/angular/angular-cli/issues/4611#issuecomment-279125728.<issue_closed>
<issue_comment>username_4: Dupe of https://github.com/angular/angular-cli/issues/4611 | {'fraction_non_alphanumeric': 0.11720884032778743, 'fraction_numerical': 0.05165135336478768, 'mean_word_length': 3.5824800910125143, 'pattern_counts': {'":': 0, '<': 14, '<?xml version=': 0, '>': 14, 'https://': 6, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 6, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '8495125', 'n_tokens_mistral': 1488, 'n_tokens_neox': 1333, 'n_words': 430} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Refactor parse for blocks
username_0: This is a pull request for the refactoring of parsing that Ben suggested.
The idea that `src/js/trove/parse-pyret.js` mixed two things together:
1. Cleaning out all the cruft in the jglr parse tree.
2. Constructing a Pyret AST data structure.
The `codemirror-blocks` block editor wants (1), but not (2), however: it wants to construct its own, blocky, AST. Therefore, this commit separates (1) out into a separate file, `src/js/base/translate-parse-tree.js`. This file provides a function called `translate` that takes a jglr parse-tree and a set of node constructors (as well as some other constructors, like `makeSrcloc`), and produces an AST using those constructors. Pyret passes in the typical constructors from ast.arr, and the block editor will pass in its own constructors.
The tests from `make test` all pass.
I'm happy to tweak the interface if something else would be preferable. (See the top of `translate-parse-tree.js`.) As is, I kept things very close to how they were before, leading to different constructors being used in different ways. For example:
- makeNode('s-num', srcloc, 3)
- opLookup["+"]
- opLookup["is"]\(srcloc)
The hackiest things here are the arguments "getRecordFields", which is used to get the record fields out of a provide (which re-uses record syntax), and "detectAndComplainAboutOperatorWhitespace", which is a heuristic for better parse errors that I don't see how to separate out.
<issue_comment>username_1: @username_0 ping -- please rebase on the latest changes to horizon, and please also revise as we talked about.
<issue_comment>username_0: SO says that rebasing in this case [is questionable](https://stackoverflow.com/questions/19016698/git-branch-diverged-after-rebase). I tried it, and it resulted in a "refactor-parse-for-blocks and origin/refactor-parse-for-blocks branches have diverged" message, from which I would have had to force push. Instead, I merged horizon into the branch.
<issue_comment>username_1: Merging horizon onto this instead of rebasing is fine.
<issue_comment>username_0: Think this is ready to merge? The one nasty case is my check for whether a value is a singleton or not:
const astValues = RUNTIME.getField(astLib, "defined-values");
for (let i in astValues) {
let value = astValues[i];
if (value["$constructor"] !== undefined && value["$name"] === i) {
// it's a singleton
}
I looked through the fields of `defined-values` and `defined-types`, and didn't see any other hint as to whether something was a singleton or not.
<issue_comment>username_1: Well, the lack of an `.app` field is another good clue, rather than checking the `$name` field. Any $-field only ever comes from compilation, so that `$constructor` field is a safe thing to use as a proxy for "is this a `data` variant or not".
This is probably ready to merge; I'll look it over tomorrow in more detail.
<issue_comment>username_0: So, I just noticed this open PR I've had :-). Could we either merge or close this?
<issue_comment>username_2: I would seriously love it if this became a reality | {'fraction_non_alphanumeric': 0.07803650094398994, 'fraction_numerical': 0.00723725613593455, 'mean_word_length': 4.263245033112582, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 9, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '30932414', 'n_tokens_mistral': 898, 'n_tokens_neox': 855, 'n_words': 444} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Frequency should be got from circuit relations and not from lines
username_0: Following #67 and this Talk topic on undergoing power routing proposal:
https://wiki.openstreetmap.org/wiki/Talk:Proposed_features/Power_routing_proposal#Splitting_logical_from_physical_infrastructure
frequency, especially frequency=0 should be got from circuit relations and not from lines or cable.
A given cable could independently support HVDC or HVAC, depending to which substation it is connected to. It's all about logical circuit put on top of it.
Example with INELFE HVDC line between Spain and France :
Physical line with no frequency : https://www.openstreetmap.org/way/242127520
Two relations are then available with frequency=0 : https://www.openstreetmap.org/relation/9934066 and https://www.openstreetmap.org/relation/9934065
This framework may enable to distinguish design voltage, on lines (seen by any mapper and measurable on ground by looking at insulators length) and operational voltage (got from open data and operator data), on relations.
Operational voltage <= design voltage, always true.
All the best
<issue_comment>username_1: Why are there two routes for a single HVDC link like that? Its only one circuit right?
That level of mapping here in Norway would probably be breaking the law actually, so for some its not possible to do this.
I'm already on the edge of what is legal with my mapping so far.
Power route relations are also very easy to break by people not understanding how they work.
It doesn't help that some editors are bad at dealing with relations in general.
<issue_comment>username_0: That's similar to editors which are bad at editing ways and make users connect two ways that shouldn't.
We didn't prevent people to use ways over some bad use cases. Think about benefits brought by a given concept. | {'fraction_non_alphanumeric': 0.04354753053637812, 'fraction_numerical': 0.015932023366967606, 'mean_word_length': 4.761467889908257, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 4, 'https://': 4, 'lorem ipsum': 0, 'www.': 3, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '19881126', 'n_tokens_mistral': 492, 'n_tokens_neox': 453, 'n_words': 260} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: issue #75- [F8]: Add connection checker to external recommender settings.
username_0: **What's in the PR**
Instead of implementing a separate button for checking the external connection we have used the existing save button to verify the form validation. We have developed a custom form validator to remote URL which takes URL as an input and establishes a connection and extracts the headers from the opened connection. From the headers, we receive a status code which when equals to HTTP_OK(200), the connection is successful. If the connection is not successfully established, the form won't be saved and returns an error message with the appropriate status code.
The implementation can be seen from the screenshots below:


<issue_comment>username_0: Please Review our pull request @username_1
<issue_comment>username_0: @username_1 This is regarding the second issue in the pull request. [www.example.com](http://example.com) seems to be an existing domain. We have tried a non-existing domain called [www.username_0.com](http://username_0.com) in the first screenshot and since it does not exist it returns an error code 404.


<issue_comment>username_1: Interesting... I get different results here:

But ok, the code regarding the check looks ok.
Your code is still based on another branch, not on the master branch. This is not good practtice. If you have time, please fix it.
<issue_comment>username_1: Overall, good effort! Changes in webanno look ok. | {'fraction_non_alphanumeric': 0.08681214421252371, 'fraction_numerical': 0.10341555977229601, 'mean_word_length': 5.18475073313783, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 5, 'lorem ipsum': 0, 'www.': 2, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '18866848', 'n_tokens_mistral': 762, 'n_tokens_neox': 628, 'n_words': 224} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Random Coffeescript file showing up as Appveyor
username_0: 
The tab icon when you open it is the Coffeescript brown + the Appveyor icon. Switching languages does _not_ help.
[email protected]
<issue_comment>username_1: Right, kick devtools open. Run this:
~~~js
_FileIcons.fs.paths
~~~
Tell me if:
1. Any paths are using backwards delimiters
2. Any entries are keyed with values that *aren't* Directory or File instances
3. If more than one key exists for a path (...somehow)
**Next:**
~~~js
const fubar = _FileIcons.grep("git-repository-spec.coffee");
~~~
Show me the contents of:
- `fubar.icons`
- `fubar.currentIcon`
<issue_comment>username_0: The path for `C:\Users\user\Documents\GitHub\atom\spec\git-repository-spec.coffee` is pointing to uh... `C:/Users/user/Documents/GitHub/atom/appveyor.yml`...
The two properties are undefined.
<issue_comment>username_1: 2017 and Microsoft still insist on using relics of the DOS-era. Christ, I hate those separators...
Right, that's made the catalyst pretty clear. What I can't understand is how it fell through the dozens of `normalisePath` calls I scattered everywhere to make sure no backwards/weird-Windows paths were used as keys. \*sigh*
Thankfully, stuff like this is about to become easier to debug. Almost finished decoupling the filesystem API... -_-
Guess there's nothing insightful in `_FileIcons.log`?
<issue_comment>username_0: Oh, all my keys were Windows-style. Their corresponding File was mapped to a Unix-style path though. Is that worrisome?

<issue_comment>username_1: Quite the opposite. To make my life simpler and less prickly, I force Windows paths to use POSIX path separators. Every path is meant to be normalised this way before lookup. Obviously something slipped through the gaps somewhere, because those keys aren't meant to be delimited like that.
Is your `process.platform` global set to `"win32"`...?
<issue_comment>username_0: ```
process.platform
"win32"
```
<issue_comment>username_1: The separator discrepancies are the reason for this schizophrenic mess. If I can plug that, this issue will likely be resolved. Needless to say, this is probably connected to the original issue you filed.
I should also check the latest beta to see if there's anything broken I need to fix... -_-
<issue_comment>username_1: BTW, improved path-handling will need to wait for another release. I didn't wanna hold off publishing `v2.0.0`, but I didn't want to rush anything either.
Which overlooks the fact I just spent several hours mud-wrestling both NPM and APM to get these versions published, but yeah.
<issue_comment>username_0: Just updated to 2.1.1 and I :heart: the new test icons though :).
<issue_comment>username_1: Glad to hear that, haha. Spent hours designing 'em. :)
It's interesting how difficult icons are to design well... so little room, so many details can get lost so easily...
<issue_comment>username_0: @username_1 is this maybe the same issue that I'm seeing right now?

<issue_comment>username_1: Freshly-cloned? As in, you didn't create new directories or rename files in the `tree-view` after seeing this?
Have you cloned this repo to its current directory before...?
<issue_comment>username_0: Maybe a long time ago. I have not _recently_ cloned this repo.
Here's the full tree: you can see it happening twice.

<issue_comment>username_0: Introducing: I have no idea what is going on. This is from a new Atom window (`atom . -n`).

<issue_comment>username_1: Could you show the output of `apm ls -bi`, please? I'm gonna have a look at this from a virtualised Windows environment, since I've been unable to reproduce this on Darwin.
<issue_comment>username_0: This isn't going to be of much help because the majority of the packages are linked, but here you go.
```
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
```
autocomplete-python, busy-signal, linter, linter-ui-default, MagicPython are disabled.
<issue_comment>username_1: When you run `AtomFS.paths` in the dev-console, and expand the entries list... are the path separators uniform across all entries? Or do some still have backslashes as separators? They should all be forwards-facing...
<issue_comment>username_0: Oh hey, look at this. Want me to file a new issue? Only happened in Window 1 (which is in dev mode).
```
Uncaught (in promise) TypeError: entity.addEditor is not a function
at disposables.add.onOpenFile.editor (C:\Users\user\.atom\packages\file-icons\lib\ui.js:39:12)
at Function.module.exports.Emitter.simpleDispatch (C:\Users\user\Documents\GitHub\atom\node_modules\event-kit\lib\emitter.js:25:14)
at Emitter.module.exports.Emitter.emit (C:\Users\user\Documents\GitHub\atom\node_modules\event-kit\lib\emitter.js:141:28)
at disposables.add.atom.workspace.observeTextEditors.editor (C:\Users\user\.atom\packages\file-icons\lib\ui.js:66:19)
at file:///C:/Users/user/Documents/GitHub/atom/out/app/src/workspace.js:621:54
at Function.module.exports.Emitter.simpleDispatch (C:\Users\user\Documents\GitHub\atom\node_modules\event-kit\lib\emitter.js:25:14)
at Emitter.module.exports.Emitter.emit (C:\Users\user\Documents\GitHub\atom\node_modules\event-kit\lib\emitter.js:141:28)
at file:///C:/Users/user/Documents/GitHub/atom/out/app/src/workspace.js:502:22
at file:///C:/Users/user/Documents/GitHub/atom/out/app/src/workspace.js:502:82
at Function.module.exports.Emitter.simpleDispatch (C:\Users\user\Documents\GitHub\atom\node_modules\event-kit\lib\emitter.js:25:14)
at Emitter.module.exports.Emitter.emit (C:\Users\user\Documents\GitHub\atom\node_modules\event-kit\lib\emitter.js:141:28)
at PaneContainer.didAddPaneItem (C:\Users\user\Documents\GitHub\atom\src\pane-container.js:266:18)
at Pane.addItem (C:\Users\user\Documents\GitHub\atom\src\pane.js:628:42)
at Pane.activateItem (C:\Users\user\Documents\GitHub\atom\src\pane.js:570:12)
at Workspace.<anonymous> (file:///C:/Users/user/Documents/GitHub/atom/out/app/src/workspace.js:1025:12)
at Generator.next (<anonymous>)
at step (file:///C:/Users/user/Documents/GitHub/atom/out/app/src/workspace.js:1:12)
```
Have a field day with this.

<issue_comment>username_0: I'm also getting errors from the github package, so maybe it's not just file-icons.
<issue_comment>username_1: Are you running a beta version of Atom, or has it been built from master directly?
<issue_comment>username_0: I'm running Atom 1.22.0-dev-f762bf954. Should have included that, sorry.
<issue_comment>username_1: Can you test this in a stable environment, please?
<issue_comment>username_0: Will try to.
<issue_comment>username_0: Ok, as this is happening with literally every new repo I'm cloning, I suspect it may be due to my tree-view Map changes. I will attempt to report back soon.
<issue_comment>username_1: @username_0 Don't forget to leverage the filesystem API's index (`global.AtomFS.paths`) in case it helps you with debugging. :)
I appreciate the time you're putting towards investigating this.
<issue_comment>username_0: I tried checking out some new repos while on Atom 1.22.0 stable with only file-icons and my syntax theme installed. While I can't reproduce the incorrect icons right now, I can still confirm that `AtomFS.paths` is reporting a mix of Unix and Windows-style path delimiters. Directories use Unix-style while Files use Windows-style.
language-csharp is still broken and some entries in the Map map to `undefined`.

<issue_comment>username_1: Right, this *should* be solved with the latest release. Could you confirm?
If not the incorrect icons, then certainly the inconsistent path separators. I've [added a speciality class](https://github.com/username_1/Atom-FS/blob/0183b79/lib/path-map.js) to help deal with that.
<issue_comment>username_0: Whoops, missed this. I'll get back to you when I have time.
<issue_comment>username_0: 
There is no `language-csharp/grammars` entry in `AtomFS.paths`.
I also see this:

The file does exist in `AtomFS.paths` and points to the correct `File`. Changing languages does nothing.
Atom 1.25.0-dev-3039ac1f4, [email protected]. | {'fraction_non_alphanumeric': 0.11432610744580585, 'fraction_numerical': 0.06588124410933081, 'mean_word_length': 4.369939271255061, 'pattern_counts': {'":': 0, '<': 33, '<?xml version=': 0, '>': 33, 'https://': 10, 'lorem ipsum': 0, 'www.': 0, 'xml': 1}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '6235113', 'n_tokens_mistral': 4109, 'n_tokens_neox': 3674, 'n_words': 986} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Use the Lumenize.TimeSeriesCalculator library to represent stories for calculations
username_0: I recently learned of this tool http://commondatastorage.googleapis.com/versions.lumenize.com/docs/lumenize-docs/index.html#!/api/Lumenize.TimeSeriesCalculator
that looks like it could be very powerful in generating results for how much time issues spend in a target status. I should investigate using it in this tool. | {'fraction_non_alphanumeric': 0.059734513274336286, 'fraction_numerical': 0.0022123893805309734, 'mean_word_length': 5.661764705882353, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '5819346', 'n_tokens_mistral': 121, 'n_tokens_neox': 114, 'n_words': 47} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Define maintainer
username_0: #### Summary
Add a `CODEOWNERS` files and mentioning the maintainer in `README.md`.
#### Ticket Link
https://community.mattermost.com/core/pl/rx8j7auye7ns8qu39brpd59c3e
<issue_comment>username_1: Thanks for being co-owner @mickmister! | {'fraction_non_alphanumeric': 0.1118421052631579, 'fraction_numerical': 0.03618421052631579, 'mean_word_length': 6.439024390243903, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '22891733', 'n_tokens_mistral': 112, 'n_tokens_neox': 104, 'n_words': 24} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: control.pade has possible numerical issues
username_0: There is an incorrect "optimization" in control.pade (see [delay.py line 80-84](https://github.com/python-control/python-control/blob/master/control/delay.py#L80)):
c = 1.
for k in range(1, n+1):
c = T * c * (n - k + 1)/(2 * n - k + 1)/k
num[n - k] = c * (-1)**k
den[n - k] = c
The problem is the inclusion of the term T in the recursion. I pulled out my copy of Golub + Van Loan p. 574 and they keep the coefficient `c` separate from powers of T (in Golub + Van Loan it is based on matrices, but it's the same math) until point of use. I would change to
c = 1.
Tpow = 1.
sgn = 1
for k in range(1, n+1):
c *= (n - k + 1)/(2 * n - k + 1)/k
Tpow *= T
sgn = -sgn
num[n - k] = sgn * c * Tpow
den[n - k] = c * Tpow
<issue_comment>username_1: Do you have values of T and n demonstrating a problem?
The code at the end of this comment runs without raising an assertion;
that suggests whether c and T are kept separate or not results in only
1 ulp of difference, i.e., not much.
I've tried to test whether scaling (normalizing?) at the end by den[0]
makes a difference; I did this by finding the exact Pade approximant
coefficients with fractions.Fraction(), and comparing against the
floating-point results. I didn't do this terribly scientifically, but
for a variety of T and n the ulp difference is 1 up to order 11.
The *absolute* error is not terribly good; for instance, for T=1e-3
and n=5, the maximum absolute error over all coefficients is 2.7;
increasing n to 6 results in an error of 31e3; and for n=7 it's 2.3e9
(!). In the latter case the constant coefficient is around 2e28, so
the large absolute error is reasonable.
(The code for all these claims is not terribly polished, but if anyone
wants it let me know.)
In short, I don't think keeping c and T separate will change much;
and, assuming one requires that the coefficient of the highest power
of s is 1, I don't think changing the normalization will change much
either. We seem to be getting pretty close to the best floating-point
answer we can.
I'm not even close to being a numerical analyst, but my perception is
that addition is where one particularly accumulates error; the
operations involving c and T are all multiplication. Golub and <NAME>
are dealing with matrix multiplication, which results in addition;
perhaps that's why they separated c and T?
```python
import numpy as np
def orig(T,n):
num = [0.]*(n+1)
den = [0.]*(n+1)
num[-1] = 1.
den[-1] = 1.
c = 1.
for k in range(1, n+1):
c = T * c * (n - k + 1)/(2 * n - k + 1)/k
num[n - k] = c * (-1)**k
den[n - k] = c
return num, den
def changed(T,n):
num = [0.]*(n+1)
den = [0.]*(n+1)
num[-1] = 1.
den[-1] = 1.
c = 1.
Tpow = 1.
for k in range(1, n+1):
c = c * (n - k + 1)/(2 * n - k + 1)/k
Tpow *= T
num[n - k] = c * Tpow * (-1)**k
den[n - k] = c * Tpow
return num, den
T = np.sqrt(2)
no,do = orig(T,5)
nc,dc = changed(T,5)
npa = np.array
Ts = [1, np.sqrt(2), np.sqrt(0.5), 1e-2, 1e-6, 1e6]
for T in Ts:
np.testing.assert_array_almost_equal_nulp(npa(no),npa(nc),nulp=1)
np.testing.assert_array_almost_equal_nulp(npa(do),npa(dc),nulp=1)
```
<issue_comment>username_0: OK, I think I understand your point (as long as you have only multiplications and no additions, there's no problem in roundoff error with very large or small floating-point exponents) and it sounds reasonable to me.
<issue_comment>username_1: I think we can probably close this?
<issue_comment>username_0: I guess so. I have no time to investigate this again in the near future (next 12 months) unless, of course, it becomes an urgent requirement for my day-to-day work.
<issue_comment>username_1: Oh, I thought you agreed (see https://github.com/python-control/python-control/issues/74#issuecomment-168775831 ) that there probably wasn't a numerical issue---besides the limits inherent in using a TF representation.
I think the approach you proposed in #75 for state-space representation would be more accurate, or even as accurate as is possible, but it's not applicable to TF representation.<issue_closed> | {'fraction_non_alphanumeric': 0.09865771812080537, 'fraction_numerical': 0.025279642058165547, 'mean_word_length': 2.679835390946502, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 9, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '26327933', 'n_tokens_mistral': 1524, 'n_tokens_neox': 1395, 'n_words': 635} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: I want to disable interaction with front view when left or right views are revealed.
username_0:
<issue_comment>username_1: Use the delegate methods:
```
- (void)revealController:(PBRevealViewController *)revealController willShowLeftViewController:(UIViewController *)controller
{
revealController.mainViewController.view.userInteractionEnabled = NO;
}
- (void)revealController:(PBRevealViewController *)revealController willHideLeftViewController:(UIViewController *)controller
{
revealController.mainViewController.view.userInteractionEnabled = YES;
}
```
<issue_comment>username_0: where i paste it in appdelegete in swrevealview controller or main view controller
<issue_comment>username_1: Where you want. You have to know what is a protocol and a delegate first! Your controller have to adopt the SWRevealViewController protocol and have to set the SWRevealViewController delegate to self for these methods be called. You could also subclass SWRevealViewController and set the delegate to this subclass.
<issue_comment>username_0: I am uploading my sample project kindly implement the disable interaction with front view when left are revealed and in picture only open gesture is working for open menu but when click it close i want to close with gesture

[sampleproject.zip](https://github.com/username_1/PBRevealViewController/files/590634/sampleproject.zip)
<issue_comment>username_1: 1) I modified DashBordViewController.m for adopting PBRevealViewControllerDelegate protocol and add the two methods called when left is about to show or hide to set userInteractionEnabled to NO or YES on the main view.
2) PBRevealViewController do not provide a pan gesture for close left or right view. Only tap.
[Health-Appoinment1.zip](https://github.com/username_1/PBRevealViewController/files/591209/Health-Appoinment1.zip)
<issue_comment>username_0: what changes you have implemet can you define it i am add @interface DashBordViewController ()<PBRevealViewControllerDelegate> and - (void)revealController:(PBRevealViewController *)revealController willShowLeftViewController:(UIViewController *)controller {
revealController.mainViewController.view.userInteractionEnabled = NO;
}
- (void)revealController:(PBRevealViewController *)revealController willHideLeftViewController:(UIViewController *)controller {
revealController.mainViewController.view.userInteractionEnabled = YES;
}
in my main project but interaction demo project woking fine 1st i am adding protocol and then add these 2 functions in dashboard view controller what i other changes made to enable it<issue_closed>
<issue_comment>username_0: Thanks Very Much<issue_closed> | {'fraction_non_alphanumeric': 0.06223922114047288, 'fraction_numerical': 0.02851182197496523, 'mean_word_length': 6.103703703703704, 'pattern_counts': {'":': 0, '<': 12, '<?xml version=': 0, '>': 12, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '20157797', 'n_tokens_mistral': 838, 'n_tokens_neox': 740, 'n_words': 265} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Wiki permissions opened to everyone ?
username_0: Hey,
I'm not really sure about this, but I don't think this Java REST GUI is really related to your PHP library.
I looked at your wiki and it seems that everyone is able to write pages to this Wiki. Maybe should you remove those permissions :)
<issue_comment>username_1: Thabks for the heads-up. I’ve delete the irrelevant page and adjusted permissions.<issue_closed> | {'fraction_non_alphanumeric': 0.05263157894736842, 'fraction_numerical': 0.0043859649122807015, 'mean_word_length': 4.935064935064935, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '18161644', 'n_tokens_mistral': 121, 'n_tokens_neox': 113, 'n_words': 66} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Add option to access upstream connection
username_0: We have upstream filters now, and thus need a way to access upstream connection by downstream filters to access filterstate/streaminfo on upstream connection.
For an explanation of how to fill out the fields, please see the relevant section
in [PULL_REQUESTS.md](https://github.com/envoyproxy/envoy/blob/master/PULL_REQUESTS.md)
Description:Add option to access upstream connection
Risk Level:Low
Testing:Added unite test for TCP
Docs Changes:
Release Notes:
[Optional Fixes #Issue]
[Optional Deprecated:]
<issue_comment>username_0: /cc @username_1 , @PiotrSikora , @mandarjog
<issue_comment>username_1: I think the idea is carry over filter state from upstream filter to downstream filter. We probably need to use shared pointer for the filter state and just copy that to the downstream stream info.
<issue_comment>username_0: @username_2 : Thanks for the quick response. As @username_1 pointed it out, we need access of upstream filter state in downstream filter. I tried by sharing the filter state between upstream and downstream connections but because of thread local stuff I think, it didn't work. Have more details on this in https://github.com/envoyproxy/envoy-wasm/issues/291 here.
The only approach that seemed less invasive was making ClusterInfo mutable. I also, tried adding upstream connection accessor to HostDescription too but it involved making HostDescription and Host mutable at places.
Please let me know if you have any other ideas..
<issue_comment>username_2: I think you will need to look at the `onPoolReady` callback (for HTTP) and somehow send back the info you need at that point. Unfortunately this is super hacky as there is no connection at that level of abstraction. It's all streams, but potentially sending back some type of const stream info, filter data, etc. might work.
<issue_comment>username_0: @username_2 : Thanks for the pointer... taking a look...
<issue_comment>username_2: I'm going to close this PR. @username_0 can you open an issue once you have a design proposal and we can discuss before we do any implementation? Thank you. | {'fraction_non_alphanumeric': 0.05094079853143644, 'fraction_numerical': 0.006883891693437357, 'mean_word_length': 4.989010989010989, 'pattern_counts': {'":': 0, '<': 8, '<?xml version=': 0, '>': 8, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '22725150', 'n_tokens_mistral': 561, 'n_tokens_neox': 536, 'n_words': 302} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Fix display of posts with a super long name
username_0: As seen in [this unfortunate incident](https://chat.indieweb.org/2017-12-31/1514714003146400) in IRC this morning, IndieNews does not handle posts with a long name very well. In this case, the long name happened because of the implied p-name parsing rules. At the very least, IndieNews should set a maximum length and truncate.<issue_closed> | {'fraction_non_alphanumeric': 0.06481481481481481, 'fraction_numerical': 0.05787037037037037, 'mean_word_length': 5.185714285714286, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '17141082', 'n_tokens_mistral': 132, 'n_tokens_neox': 115, 'n_words': 58} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Error after update for NextJs 12
username_0: I'm getting this error after the update for NEXT 12.
```
antd/lib/config-provider/style/index.less:2
@import '../../style/themes/index';
^
SyntaxError: Invalid or unexpected token
at Object.compileFunction (node:vm:355:18)
at wrapSafe (node:internal/modules/cjs/loader:1022:15)
at Module._compile (node:internal/modules/cjs/loader:1056:27)
at Object.Module._extensions..js (node:internal/modules/cjs/loader:1121:10)
at Module.load (node:internal/modules/cjs/loader:972:32)
at Function.Module._load (node:internal/modules/cjs/loader:813:14)
at Module.require (node:internal/modules/cjs/loader:996:19)
at require (node:internal/modules/cjs/helpers:92:18)
at Object.<anonymous> (../src/node_modules/antd/lib/config-provider/style/index.js:3:1)
at Module._compile (node:internal/modules/cjs/loader:1092:14) {
type: 'SyntaxError'
}
```
config is:
```
withAntdLess({
lessVarsFilePath: '/src/styles/antd-custom.less',
lessVarsFilePathAppendToEndOfContent: false,
cssLoaderOptions: {},
webpack(config) {
return config;
},
})
```
The same code works fine in Next 11. Any clue? Is there something that can I do?
<issue_comment>username_1: +1
<issue_comment>username_2: +1
<issue_comment>username_3: I just updated 1.5.1 to be compatible with Next.js 12. more see [CHANGELOG](https://github.com/username_3/next-plugin-antd-less/blob/master/CHANGELOG.md#150-2021-11-01).<issue_closed> | {'fraction_non_alphanumeric': 0.1357234314980794, 'fraction_numerical': 0.05121638924455826, 'mean_word_length': 3.9936102236421727, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '13824301', 'n_tokens_mistral': 579, 'n_tokens_neox': 533, 'n_words': 104} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Browse Everything Speed up submit with many files
username_0: Is there a way to speed up the submit with many files?
Ask for multiple URLs at the same time?
Send the requests in parallel?
<issue_comment>username_0: Need to be careful that is is not seen as a denial of service attach if we go in parallel. | {'fraction_non_alphanumeric': 0.0377906976744186, 'fraction_numerical': 0.005813953488372093, 'mean_word_length': 4.655737704918033, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '23342109', 'n_tokens_mistral': 94, 'n_tokens_neox': 88, 'n_words': 56} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Cassandra hangs when a custom cassandra.yaml file is specified
username_0: ### Name and Version
bitnami/cassandra:4.0
### What steps will reproduce the bug?
1. Download an example cassandra.yaml from the [cassandra repository](https://github.com/apache/cassandra/find/cassandra-4.0).
2. Run the docker container.
I run the container with this command:
```
docker run --rm -v `pwd`/cassandra.yaml:/bitnami/cassandra/conf/cassandra.yaml \
-v cassandra-play-data:/bitnami --name cassandra-play \
-e BITNAMI_DEBUG=1 -p 9042:9042 \
bitnami/cassandra:4.0
```
### What is the expected behavior?
It is expected for Cassandra to start up and start accepting connections on port 9042
### What do you see instead?
Cassandra hangs, connections on port 9042 are not accepted.
### Additional information
Here are the logs:
```
Digest: sha256:232eae98cce49ab3bdd9e8cd1d6ba420c6c21bea2de4e0f268b8f15796806d88
Status: Downloaded newer image for bitnami/cassandra:4.0
cassandra 08:50:40.20
cassandra 08:50:40.20 Welcome to the Bitnami cassandra container
cassandra 08:50:40.21 Subscribe to project updates by watching https://github.com/bitnami/bitnami-docker-cassandra
cassandra 08:50:40.21 Submit issues and feature requests at https://github.com/bitnami/bitnami-docker-cassandra/issues
cassandra 08:50:40.21
cassandra 08:50:40.22 INFO ==> ** Starting Cassandra setup **
cassandra 08:50:40.26 WARN ==> CASSANDRA_HOST not set, defaulting to system hostname
cassandra 08:50:40.26 INFO ==> Validating settings in CASSANDRA_* env vars..
cassandra 08:50:40.27 WARN ==> You've not provided a password. Default password "cassandra" will be used. For safety reasons, please provide a secure password in a production environment.
cassandra 08:50:40.27 WARN ==> You set the environment variable CASSANDRA_PASSWORD=cassandra. This is the default value when bootstrapping Cassandra and should not be used in production environments.
cassandra 08:50:40.32 INFO ==> Initializing Cassandra database...
cassandra 08:50:40.38 DEBUG ==> No injected jvm-server.options file found. Creating default jvm-server.options file
cassandra 08:50:40.39 DEBUG ==> No injected jvm-clients.options file found. Creating default jvm-clients.options file
cassandra 08:50:40.40 DEBUG ==> No injected jvm11-server.options file found. Creating default jvm11-server.options file
cassandra 08:50:40.41 DEBUG ==> No injected commitlog_archiving.properties file found. Creating default commitlog_archiving.properties file
cassandra 08:50:40.42 DEBUG ==> No injected jvm11-clients.options file found. Creating default jvm11-clients.options file
cassandra 08:50:40.43 DEBUG ==> No injected logback-tools.xml file found. Creating default logback-tools.xml file
cassandra 08:50:40.44 DEBUG ==> No injected cqlshrc.sample file found. Creating default cqlshrc.sample file
cassandra 08:50:40.45 DEBUG ==> No injected triggers/README.txt file found. Creating default triggers/README.txt file
cassandra 08:50:40.46 DEBUG ==> No injected cassandra-rackdc.properties file found. Creating default cassandra-rackdc.properties file
cassandra 08:50:40.48 DEBUG ==> No injected metrics-reporter-config-sample.yaml file found. Creating default metrics-reporter-config-sample.yaml file
cassandra 08:50:40.49 DEBUG ==> No injected cassandra-jaas.config file found. Creating default cassandra-jaas.config file
cassandra 08:50:40.50 DEBUG ==> No injected jvm8-server.options file found. Creating default jvm8-server.options file
cassandra 08:50:40.50 DEBUG ==> No injected jvm8-clients.options file found. Creating default jvm8-clients.options file
cassandra 08:50:40.51 DEBUG ==> Found cassandra.yaml. Skipping default
cassandra 08:50:40.51 DEBUG ==> No injected logback.xml file found. Creating default logback.xml file
cassandra 08:50:40.52 DEBUG ==> No injected README.txt file found. Creating default README.txt file
cassandra 08:50:40.53 DEBUG ==> No injected cassandra-env.sh file found. Creating default cassandra-env.sh file
cassandra 08:50:40.54 DEBUG ==> No injected cassandra-topology.properties file found. Creating default cassandra-topology.properties file
cassandra 08:50:40.55 DEBUG ==> No injected hotspot_compiler file found. Creating default hotspot_compiler file
cassandra 08:50:40.56 DEBUG ==> cassandra.yaml mounted. Skipping authentication method configuration
cassandra 08:50:40.59 DEBUG ==> cassandra.yaml mounted. Skipping native and storage ports configuration
cassandra 08:50:40.60 DEBUG ==> cassandra.yaml mounted. Skipping data directory configuration
cassandra 08:50:40.60 DEBUG ==> cassandra.yaml mounted. Skipping cluster configuration
cassandra 08:50:40.61 DEBUG ==> Ensuring expected directories/files exist...
cassandra 08:50:40.63 INFO ==> Deploying Cassandra from scratch
cassandra 08:50:40.64 INFO ==> Starting Cassandra
cassandra 08:50:40.64 INFO ==> Checking that it started up correctly
cassandra 08:50:40.64 DEBUG ==> Checking that log /opt/bitnami/cassandra/logs/cassandra_first_boot.log contains entry "Starting listening for CQL clients"
```
I have attached the (gzipped) cassandra.yaml: [cassandra.yaml.gz](https://github.com/bitnami/bitnami-docker-cassandra/files/8148376/cassandra.yaml.gz)
I have not changed anything in the downloaded cassandra.yaml except the cluster name.
<issue_comment>username_1: Hi,
Could you do the following?
Override the default command in the docker run.
```
docker run --rm -v `pwd`/cassandra.yaml:/bitnami/cassandra/conf/cassandra.yaml \
-v cassandra-play-data:/bitnami --name cassandra-play \
-e BITNAMI_DEBUG=1 -p 9042:9042 \
bitnami/cassandra:4.0 /bin/bash
```
Then, inside the container, execute
```
/opt/bitnami/scripts/cassandra/entrypoint.sh /opt/bitnami/scripts/cassandra/run.sh
```
The container would fail, but you can check the contents of `/opt/bitnami/cassandra/logs/cassandra_first_boot.log`. Could you check the error that the logs show?
<issue_comment>username_0: Sorry for taking so long, here's the log file: [cassandra_first_boot.log](https://github.com/bitnami/bitnami-docker-cassandra/files/8181474/cassandra_first_boot.log)
<issue_comment>username_2: Hi @username_0 to sort it out temporary that problem you can add `--ulimit memlock=-1` to your docker command but after that other problems are appearing. Any clue or any finding is welcome | {'fraction_non_alphanumeric': 0.09078446306169079, 'fraction_numerical': 0.06397562833206398, 'mean_word_length': 4.2528, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 39, 'https://': 5, 'lorem ipsum': 0, 'www.': 0, 'xml': 4}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 9, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '18242757', 'n_tokens_mistral': 2350, 'n_tokens_neox': 2027, 'n_words': 640} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Use POM DSL for customizations
username_0: - This DSL was first introduced in Gradle 4.8 (released 2018-06-04)
- When multiple plugins attempt to customize the POM with the DSL,
the final result is still valid. When some use the DSL and others
append node, we end up with multiple elements in the POM that makes
it fail publication | {'fraction_non_alphanumeric': 0.0425531914893617, 'fraction_numerical': 0.02925531914893617, 'mean_word_length': 4.026666666666666, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '18276472', 'n_tokens_mistral': 112, 'n_tokens_neox': 97, 'n_words': 57} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Speed up GFF3 -> DB script
username_0: By grouping multiple database `insert` calls into an `executemany` style statement (that can wrap many inserts into a single transaction, and thus save per-transaction costs in the inner loop).
<issue_comment>username_1: Fixed in #1085<issue_closed> | {'fraction_non_alphanumeric': 0.07120743034055728, 'fraction_numerical': 0.021671826625386997, 'mean_word_length': 6.363636363636363, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 5, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '2132053', 'n_tokens_mistral': 90, 'n_tokens_neox': 85, 'n_words': 40} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: il: Lift LDXR instructions
username_0: LDXR is just LDR with exclusive memory access and limitations on source operands, so this is a rather simple PR. I added some tests just in case.
<issue_comment>username_1: To provide a bit more context, these haven't been lifted before due to uncertainty around how to handle atomics in the IL. Take a look at the corresponding v7 PR for example: https://github.com/Vector35/arch-armv7/pull/46/files. I don't really have strong feelings about how they should be lifted, but there are probably benefits to keeping v7 and v8 consistent.
<issue_comment>username_0: @username_1: that makes sense, thanks. I’ll close this for now, and will consider lifting with intrinsics for any future implementation of this instruction, if needed. | {'fraction_non_alphanumeric': 0.05223880597014925, 'fraction_numerical': 0.014925373134328358, 'mean_word_length': 5.098484848484849, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '18066996', 'n_tokens_mistral': 208, 'n_tokens_neox': 200, 'n_words': 116} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Create some anonymous analytics about a script before encrypting it
username_0: It would be good for universities/academic institutions to be able to do bulk analysis on the kinds of scripts people are creating with PXT.
At the point at which someone publishes a script, it might be possible for us to create some anonymous metrics that can be stored before the script is encrypted and stored.
<issue_comment>username_1: Good idea, but won't fix for now.<issue_closed> | {'fraction_non_alphanumeric': 0.03557312252964427, 'fraction_numerical': 0.003952569169960474, 'mean_word_length': 5.182926829268292, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '19923060', 'n_tokens_mistral': 123, 'n_tokens_neox': 117, 'n_words': 75} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Replace pull_request events by push
username_0: **What does this PR do / why we need it**:
* Since a push event is created for every PR, we can replace the pull_request hooks by push. This causes the pipelines to be triggered for every push event.
* This starts a new build when the PR is merged to the default branch.
* github-pr-binding is removed and github-push-binding is renamed to github-binding.
* Added CEL expression to extract the branch name from body.ref field of webhook payload.
* Update the existing unit tests
**Which issue(s) this PR fixes**:
Fixes https://issues.redhat.com/browse/GITOPS-200
<issue_comment>username_0: I'll reopen this PR once we know how to support inheritance for triggers | {'fraction_non_alphanumeric': 0.06349206349206349, 'fraction_numerical': 0.006613756613756613, 'mean_word_length': 4.293706293706293, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '14602098', 'n_tokens_mistral': 215, 'n_tokens_neox': 199, 'n_words': 107} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: How to replace the node icon
username_0: I found that the icons were defined in the css, so is there any api to access the icons to replace them?
<issue_comment>username_1: You should fork the project for this.
The template is located at the at [src/html](https://github.com/10quality/vue-tree-view/blob/v1.0/src/html/template.html), you can play with it to add your own icons.
Once changed, simply minify the template and paste it in the component.
The project comes with grunt tasks that will minify the js for you.
<issue_comment>username_0: Thx!, but I strongly suggest that there should be somewhere or api method to replace icon to diy
<issue_comment>username_1: Will brainstorm an idea, thanks for your valid suggestion. | {'fraction_non_alphanumeric': 0.0609597924773022, 'fraction_numerical': 0.010376134889753566, 'mean_word_length': 4.553956834532374, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '4796899', 'n_tokens_mistral': 216, 'n_tokens_neox': 207, 'n_words': 110} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: `GameGem On iOS 11.3.1` not working on iOS 11.3.1
username_0: ```
{
"packageId": "org.cydia.kiimo.memsearch11.3",
"action": "notworking",
"userInfo": {
"arch32": false,
"packageId": "org.cydia.kiimo.memsearch11.3",
"deviceId": "iPhone9,2",
"url": "http://cydia.saurik.com/package/org.cydia.kiimo.memsearch11.3/",
"iOSVersion": "11.3.1",
"packageVersionIndexed": false,
"packageName": "GameGem On iOS 11.3.1",
"category": "Utilities",
"repository": "A kiiimo Respositoty ",
"name": "GameGem On iOS 11.3.1",
"installed": "1.4b",
"packageIndexed": false,
"packageStatusExplaination": "This tweak has not been reviewed. Please submit a review if you choose to install.",
"id": "org.cydia.kiimo.memsearch11.3",
"commercial": false,
"packageInstalled": true,
"tweakCompatVersion": "0.1.0",
"shortDescription": "Memory debug tool for iOS. Support iPhone and iPad above iOS 8.x (include 8.x) . Support mode: accurate . Support data type: Word, DWord, Float. Support data locking and batch modify. Tutorials: , AD include .",
"latest": "1.4b",
"author": "Aidoo.TK",
"packageStatus": "Unknown"
},
"base64": "eyJhcmNoMzIiOmZhbHNlLCJwYWNrYWdlSWQiOiJvcmcuY3lkaWEua2lpbW8ubWVtc2VhcmNoMTEuMyIsImRldmljZUlkIjoiaVBob25lOSwyIiwidXJsIjoiaHR0cDpcL1wvY3lkaWEuc2F1cmlrLmNvbVwvcGFja2FnZVwvb3JnLmN5ZGlhLmtpaW1vLm1lbXNlYXJjaDExLjNcLyIsImlPU1ZlcnNpb24iOiIxMS4zLjEiLCJwYWNrYWdlVmVyc2lvbkluZGV4ZWQiOmZhbHNlLCJwYWNrYWdlTmFtZSI6IkdhbWVHZW0gT24gaU9TIDExLjMuMSIsImNhdGVnb3J5IjoiVXRpbGl0aWVzIiwicmVwb3NpdG9yeSI6IkEga2lpaW1vIFJlc3Bvc2l0b3R5IO+jvyIsIm5hbWUiOiJHYW1lR2VtIE9uIGlPUyAxMS4zLjEiLCJpbnN0YWxsZWQiOiIxLjRiIiwicGFja2FnZUluZGV4ZWQiOmZhbHNlLCJwYWNrYWdlU3RhdHVzRXhwbGFpbmF0aW9uIjoiVGhpcyB0d2VhayBoYXMgbm90IGJlZW4gcmV2aWV3ZWQuIFBsZWFzZSBzdWJtaXQgYSByZXZpZXcgaWYgeW91IGNob29zZSB0byBpbnN0YWxsLiIsImlkIjoib3JnLmN5ZGlhLmtpaW1vLm1lbXNlYXJjaDExLjMiLCJjb21tZXJjaWFsIjpmYWxzZSwicGFja2FnZUluc3RhbGxlZCI6dHJ1ZSwidHdlYWtDb21wYXRWZXJzaW9uIjoiMC4xLjAiLCJzaG9ydERlc2NyaXB0aW9uIjoiTWVtb3J5IGRlYnVnIHRvb2wgZm9yIGlPUy4gU3VwcG9ydCBpUGhvbmUgYW5kIGlQYWQgYWJvdmUgaU9TIDgueCAoaW5jbHVkZSA4LngpIC4gU3VwcG9ydCBtb2RlOiBhY2N1cmF0ZSAuIFN1cHBvcnQgZGF0YSB0eXBlOiBXb3JkLCBEV29yZCwgRmxvYXQuIFN1cHBvcnQgZGF0YSBsb2NraW5nIGFuZCBiYXRjaCBtb2RpZnkuIFR1dG9yaWFsczogLCBBRCBpbmNsdWRlIC4iLCJsYXRlc3QiOiIxLjRiIiwiYXV0aG9yIjoiQWlkb28uVEsiLCJwYWNrYWdlU3RhdHVzIjoiVW5rbm93biJ9",
"chosenStatus": "not working",
"notes": "0 match error"
}
``` | {'fraction_non_alphanumeric': 0.08975879794385132, 'fraction_numerical': 0.06840648477659154, 'mean_word_length': 7.214285714285714, 'pattern_counts': {'":': 27, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '29321196', 'n_tokens_mistral': 1435, 'n_tokens_neox': 1334, 'n_words': 121} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Sorting on jon properties
username_0: Given the following schema
```
CREATE TABLE table_dummy
(
id bigint NOT NULL,
date_created timestamp with time zone NOT NULL,
name character varying(16),
stats jsonb,
CONSTRAINT table_dummy_pkey PRIMARY KEY (id)
)
```
and the content of the stats field that can look like:
```
{
"granularity": 78,
"intensity" : 50,
"spacing" : 48
}
```
How would you do the following through GORM (HQL/Criterias/dynamic_finders) with the grails-postgresql-extensions plugin?
```
SELECT * FROM table_dummy order by (stats->'intensity') desc
```
Thanks,
Dominique.
<issue_comment>username_1: I've found this post: http://blog.tremend.ro/2008/06/10/how-to-order-by-a-custom-sql-formulaexpression-when-using-hibernate-criteria-api/ and I've made a very quick test with that class and this code:
```
// Service method
List<TestMapJsonb> orderByJson() {
TestMapJsonb.withCriteria {
order sqlFormula("(data->'name') desc")
}
}
```
and this test:
```
void 'Order by a json property'() {
setup:
new TestMapJsonb(data: [name: 'Iván', lastName: 'López']).save(flush: true)
new TestMapJsonb(data: [name: 'Alonso', lastName: 'Torres']).save(flush: true)
new TestMapJsonb(data: [name: 'Ernesto', lastName: 'Pérez']).save(flush: true)
when:
def result = pgJsonTestSearchService.orderByJson()
then:
result != null
result.data.name == ['Iván', 'Ernesto', 'Alonso']
}
```
And it works :smile:
It's a little bit hacky because you need to write the correct order expression and it's just appended to the criteria. Does it sounds good to you?
<issue_comment>username_1: BTW @username_0 you can see all the changes here: https://github.com/kaleidos/grails-postgresql-extensions/compare/master...order_by
<issue_comment>username_0: Hey @username_1,
Hacky or not, this is exactly what I needed :-) . Works like a charm.
Thanks for your assistance and very quick response.
<issue_comment>username_1: Great. I'm going to try to fix another issue and then I'll release a new version with this new sorting and another "sort byRandom".
<issue_comment>username_1: Included in version `4.6.0`<issue_closed>
<issue_comment>username_0: Thanks @username_1
<issue_comment>username_1: :+1: | {'fraction_non_alphanumeric': 0.1132713440405748, 'fraction_numerical': 0.013102282333051564, 'mean_word_length': 3.8703703703703702, 'pattern_counts': {'":': 1, '<': 11, '<?xml version=': 0, '>': 13, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '5809537', 'n_tokens_mistral': 806, 'n_tokens_neox': 761, 'n_words': 243} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: MBS-8726: Replicated updates don't invalidate cache entries on slave servers
username_0: This is based on https://github.com/metabrainz/musicbrainz-server/pull/212 to avoid conflicts (and to also simplify the implementation). For just the relevant changes, see https://github.com/metabrainz/musicbrainz-server/commit/b115b490565436382c9c4b28813fc8a39b54a35e
This adds two complementary solutions:
First, suggested by <NAME> in MBS-8732, is a new DBDefs setting called `ENTITY_CACHE_TTL` which defaults to 1 hour on slave servers. It ensures that if all else fails, entities will only remain cached for an hour at most.
Secondly, I added a script that can clear everything in memcached, and changed the sample replication post-process file to call it. In order to have this run after each packet, you can just do:
```bash
mv admin/replication/hooks/post-process.sample admin/replication/hooks/post-process
```
<issue_comment>username_0: I don't think we store anything else in memcached that needs a setting like this? I see most of the things using `Data::Role::SelectAll` are stored in the in-memory cache, which already has a TTL, but some things aren't. This seems broken, in fact: https://github.com/metabrainz/musicbrainz-server/blob/2d64080751192bb234ee1327ebc41df6db3530d2/lib/MusicBrainz/Server/Data/Role/SelectAll.pm#L25
<issue_comment>username_1: Seems broken indeed. I actually think it has happened in the past that changes via the admin interface weren’t visible at first, and the cache had to be cleared manually first. This looks like it could have been the reason.
There is one other use of `$c->cache` without argument in `MB::S::Data::Role::MediaWikiAPI::_get_cache_and_key`. Shouldn’t matter in that case, but still a latent bug. Perhaps we should throw an exception when `MB::S::CacheManager::cache` receives an undefined prefix parameter?
<issue_comment>username_0: @username_1 Maybe it's time we got rid of the in-memory cache, since we don't even have a way to invalidate it across servers. But I agree it would be a good idea to have `$c->cache` throw an error for an undef parameter—I don't see any reason to allow something error-prone like that.
<issue_comment>username_0: https://github.com/username_0/musicbrainz-server/commit/1cc98c5c72ae31f54701802501caba66c6a5cb6f#diff-40c11f28200f921e0df9eaefde5c8cbaR46 and below was problematic for the AliasType models, so I actually ended up generating them from a template in https://github.com/username_0/musicbrainz-server/commit/fe2c06326a1664b332c7dc4b0c5ceb058f48526d
I tried generating them using `eval` instead (so, as multiple packages defined in the existing file), but `Module::Pluggable::Object` wasn't finding them. I do think we discussed using templates for our sql before.
<issue_comment>username_1: Can’t say that I like the TT-generated code files particularly, but it should work for now. However, now the master file says “auto-generated, do not edit”, too; I think we should have a TT comment before it saying that actually _this_ is where changes are to be made.
<issue_comment>username_0: Comment added. | {'fraction_non_alphanumeric': 0.06723755153821757, 'fraction_numerical': 0.046622264509990484, 'mean_word_length': 5.320641282565131, 'pattern_counts': {'":': 0, '<': 9, '<?xml version=': 0, '>': 11, 'https://': 5, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '15958287', 'n_tokens_mistral': 1004, 'n_tokens_neox': 901, 'n_words': 393} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: JsonSerializer.SerializeToElement has wrong XML documentation
username_0: The SerializeToElement XML documentation states that it returns a `JsonDocument` when it actually returns a `JsonElement`.
I can try creating a PR for improving the documentation.
<issue_comment>username_1: marking as 7.0 because it's already in PR and likely gets merged soon<issue_closed> | {'fraction_non_alphanumeric': 0.04975124378109453, 'fraction_numerical': 0.009950248756218905, 'mean_word_length': 6.462962962962963, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '332824', 'n_tokens_mistral': 101, 'n_tokens_neox': 96, 'n_words': 47} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: misc dkim_sign updates
username_0: Fixes #1705
closes #1706
Changes proposed in this pull request:
- use path.* instead of / delimited string (cross-platform compat)
- set haraka_dir to empty string when process.env.HARAKA is unset (for testing)
- switch from fs.exists (deprecated) to fs.stat for directory detection
- switch from async.filter to async.detectSeries (b/c results order matters)
- improved test coverage for get_key_dir
Checklist:
- [ ] docs updated
- [ ] tests updated | {'fraction_non_alphanumeric': 0.07462686567164178, 'fraction_numerical': 0.016791044776119403, 'mean_word_length': 4.018691588785047, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '9221621', 'n_tokens_mistral': 164, 'n_tokens_neox': 160, 'n_words': 62} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: ADA: Calendar - Additional information is read and name for different day is read same
username_0: #### This is a bug.
#### Additional information is not read and name of the days is not read precise.
#### Angular 10
#### Steps:
<h2 style="margin: 0px; padding: 0px; color: rgb(0, 73, 148); font-weight: 500; text-transform: none; font-size: 20px; line-height: 1.5; letter-spacing: -0.008em; font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; orphans: 2; text-align: start; text-indent: 0px; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;">1.1 Internal Message Details</h2><div class="table-wrap" style="margin: 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;">
Internal Message: |
-- | --
Test Plan: | - **
Message Priority: | High
Affected UI | Calendar
Affected Check Point: | ACC-264
Short text: | ACC-264.1: Calendar: Additional information is read and name for different day is read same
</div><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"> </p><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"> ** </p><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"> </p><h2 style="margin: 30px 0px 0px; padding: 0px; color: rgb(0, 73, 148); font-weight: 500; text-transform: none; font-size: 20px; line-height: 1.5; letter-spacing: -0.008em; font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; orphans: 2; text-align: start; text-indent: 0px; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"><a name="ScreenFlow" title="Follow link" style="color: rgb(0, 73, 148); text-decoration: none; cursor: pointer;"></a>Screen Flow</h2><ul style="margin: 10px 0px 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"><li>Launch the application with the URL provided.</li><li>Login using the credentials provided.</li><li>Navigate to Create menu and activate it.</li><li>Select Guided Sourcing Project.</li><li>In Create Guided Sourcing Project screen, press tab to navigate to Project type radio button.</li><li>Within project type radio button, select full project radio button</li><li>Fill in the data in the mandatory marked fields.</li><li>Press tab to navigate to predecessor project and select other.</li><li>Press tab to navigate to the list of cards available and select any card.</li><li>Back in the create screen navigate to template name combo box and select template for ADA testing from the list.</li><li>Once all the mandatory fields are filled, activate Create button.</li><li>In the ADA_Demo2_ACC (created project) screen, navigate to more menu and press tab to navigate.</li><li>Within tasks section, activate create menu and activate create task button. In the screen, navigate to name input field</li><li>Within date tab navigate to calendar toggle button and activate it navigate within the date fields</li></ul><h2 style="margin: 30px 0px 0px; padding: 0px; color: rgb(0, 73, 148); font-weight: 500; text-transform: none; font-size: 20px; line-height: 1.5; letter-spacing: -0.008em; font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; orphans: 2; text-align: start; text-indent: 0px; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"><a name="%C2%A0" title="Follow link" style="color: rgb(0, 73, 148); text-decoration: none; cursor: pointer;"></a> </h2><h2 style="margin: 30px 0px 0px; padding: 0px; color: rgb(0, 73, 148); font-weight: 500; text-transform: none; font-size: 20px; line-height: 1.5; letter-spacing: -0.008em; font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; orphans: 2; text-align: start; text-indent: 0px; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"><a name="Issue" title="Follow link" style="color: rgb(0, 73, 148); text-decoration: none; cursor: pointer;"></a>Issue</h2><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"><b>Synopsis: Additional information is not read and name of the days is not read precise</b></p><h3 style="margin: 30px 0px 0px; padding: 0px; color: rgb(0, 73, 148); font-size: 16px; font-weight: 500; line-height: 1.25; letter-spacing: -0.006em; text-transform: none; font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; orphans: 2; text-align: start; text-indent: 0px; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"><a name="ObservedBehavior%3A" title="Follow link" style="color: rgb(0, 73, 148); text-decoration: none; cursor: pointer;"></a>Observed Behavior:</h3><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;">On navigating within the date in the calendar, an additional information ‘has controls’ is read.</p><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;">Also, the name of the days for e.g. Sunday, Monday etc. is read as ‘S,M etc.’ which is not meaningful and can be confusing for a screen reader user as for both Sunday and Saturday it reads as ‘S’ and for both ‘Tuesday and Thursday’ it is read as ‘T’.</p><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;">The speech output is:</p><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;">26<br>S<br>column 1 row 5<br>June 27, 2021 Contains Controls‑<br>M<br>June 28, 2021 Contains Controls‑<br>T<br>June 29, 2021 Contains Controls‑</p><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"> </p><h3 style="margin: 30px 0px 0px; padding: 0px; color: rgb(0, 73, 148); font-size: 16px; font-weight: 500; line-height: 1.25; letter-spacing: -0.006em; text-transform: none; font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; orphans: 2; text-align: start; text-indent: 0px; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"><a name="ExpectedBehavior%3A%C2%A0%C2%A0%C2%A0" title="Follow link" style="color: rgb(0, 73, 148); text-decoration: none; cursor: pointer;"></a>Expected Behavior: </h3><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;">Ideally, no additional information should be read on navigating to the date fields within a calendar.</p><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;">Also, the name of each days read should be distinct and clear to a screen reader user. For e.g. for Sunday instead of ‘S’ it can read ‘Sun’, for Saturday ‘Sat’ etc.</p><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"> </p><p style="margin: 10px 0px 0px; padding: 0px; color: rgb(23, 43, 77); font-family: -apple-system, system-ui, "Segoe UI", Roboto, Oxygen, Ubuntu, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;">Note: The issue persists throughout the application for similar occurrences.</p>
#### Attachment for more details.
[45. ACC-264.1_Calendar_Additional information is read and name for different day is read same (1).docx](https://github.com/SAP/fundamental-ngx/files/6727783/45.ACC-264.1_Calendar_Additional.information.is.read.and.name.for.different.day.is.read.same.1.docx)
#### Reported by ADA team. Linked to https://product-jira.ariba.com/browse/SS-27447
<issue_comment>username_1: @username_0 can you please verify this is still an issue? I can see the days pronounced correctly
 | {'fraction_non_alphanumeric': 0.15657174151150055, 'fraction_numerical': 0.045290251916757944, 'mean_word_length': 5.930170777988614, 'pattern_counts': {'":': 0, '<': 92, '<?xml version=': 0, '>': 92, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '7019261', 'n_tokens_mistral': 7091, 'n_tokens_neox': 5930, 'n_words': 1809} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Added typings definition to package.json
username_0: This fixes issue #4 TS7016: Could not find a declaration file for module 'redux-yjs-bindings' when using with Typescript projects
<issue_comment>username_1: Sorry for the delayed response. I merged your changes (thank you!) and also added an example for usage with create-react-app. | {'fraction_non_alphanumeric': 0.062162162162162166, 'fraction_numerical': 0.01891891891891892, 'mean_word_length': 5.87037037037037, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '1867077', 'n_tokens_mistral': 102, 'n_tokens_neox': 95, 'n_words': 47} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: alerts: remove auroElement.js from local package
username_0: - [ ] README doc completed with all relative information
- [ ] API documentation created
- [ ] Bundled version tested and documented
- [ ] Examples and use case info created
- [ ] Pages added to the Auro Doc Site<issue_closed> | {'fraction_non_alphanumeric': 0.07668711656441718, 'fraction_numerical': 0.003067484662576687, 'mean_word_length': 4.360655737704918, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '3899296', 'n_tokens_mistral': 89, 'n_tokens_neox': 86, 'n_words': 36} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Seeking remote file with HTTP Range header
username_0: Hi there,
Awesome project, was nerd-sniped when my disc didn't have enough space to download the ChromeOS.
I was wondering if we could work around the necessity of downloading the ChromeOS image to disk or to memory and rather only download the parts we need in each "read".
**Technical feasability**
As I see it, the main mechanism that is used in inputstreamhelper, is feeding a file-like object into ZipFile:
https://github.com/emilsvennesson/script.module.inputstreamhelper/blob/b21b228c22309ea62ec90627c983fa42ce7c7d4d/lib/inputstreamhelper/widevine/arm_chromeos.py#L322
ZipFile will only read some metadata, such as the end of central directory by using seek/tell/read:
https://github.com/python/cpython/blob/ffa505b580464d9d90c29e69bd4db8c52275280a/Lib/zipfile.py#L1343
You then call the open() function on the ZipFile object which returns an object of type ZipExtFile. Again, ZipExtFile does only read some metadata from the file at this point.
On the ZipExtFile object your code calls seek/read/close etc. and the ZipExtFile does zip-specific things, but it only calls seek/tell/read on the originally given file-like object as well when asked.
Summarised: Any file-like object should work with the current ZipFile approach.
**Proposal**
Create a file-like HttpFile class that implements seek/tell/read etc. and uses the HTTP Range feature to only fetch certain parts of the zip file from the Google servers. I guess the class will need to be clever about the chunks it caches (e.g. it always keeps a 100MB chunk in memory), so that not every read() call will result in an HTTP request to the Google servers. Instead of downloading the ChromeOS image to disk, pass the HttpFile object into ZipFile.
I just checked and the Google servers where the ChromeOS images are downloaded do support HTTP Range.
Obviously this would need some testing (e.g. with a proxy to see how many HTTP request go out and what a good cache chunk size is).
** Pro/Cons **
Pro:
* More flexibility regarding disk space
* Inputstreamhelper could decide on it's own (in the HttpFile class) if chunks are stored in memory or on disk and how large the chunks should be
* Less data (number of bytes) might be downloaded from Google servers
Con:
* More HTTP requests to Google servers (number of requests) are sent (but this is configurable in the HttpFile class).
Alternatively, it would also be possible to only use this approach if less than the necessary disk space is available.
Was something like this approached before? What do you think?
<issue_comment>username_0: So I just went ahead and tried it. The below script extracts libwidevinecdm.so directly in-memory with HTTP range requests.
It allows to trade-off the metrics "number of HTTP requests to Google" and "memory consumption". With minor modifications it would also allow caching on disc instead of in-memory.
Running the code with different cache sizes means (all with a 0MB free disc space requirement except of course for the final libwidevinecdm.so):
Memory (cache size) 3MB: 365 HTTP Range requests to Google in 26 seconds
Memory (cache size) 50MB: 45 HTTP Range requests to Google in 20 seconds
Memory (cache size) 100MB: 22 HTTP Range requests to Google in 19 seconds
Memory (cache size) 200MB: 11 HTTP Range requests to Google in 19 seconds
Memory (cache size) 300MB: 8 HTTP Range requests to Google in 19 seconds
I have very fast Internet though.
I'm not entirely sure if making "more HTTP request" to Google is really an issue, because the TCP response size is also large when requesting one big file. The overhead of the HTTP requests is negligible compared to the download size. Additionally, with TLS session resumption (which I hope is used) there are enough Optimizations that make it efficient.
I would say this is at least worth a try for users that don't have 1GB of disc space left. But you could also consider it for all users.
Note that the main point of the script is the HTTPFile class, the rest is more or less glue code I borrowed from your project to demonstrate how it works (and I changed a couple of things so this works standalone, because I don't have a proper InputStreamHelper dev environment):
```
from __future__ import absolute_import, division, unicode_literals
import os
from struct import calcsize, unpack
from zipfile import ZipFile
from io import UnsupportedOperation
import ssl
#ctx = ssl.create_default_context()
#ctx.check_hostname = False
#ctx.verify_mode = ssl.CERT_NONE
try: # Python 3
from urllib.error import HTTPError, URLError
from urllib.request import Request, urlopen
except ImportError: # Python 2
from urllib2 import HTTPError, Request, URLError, urlopen
def http_file_size(url):
req = Request(url)
req.get_method = lambda: 'HEAD'
#req.set_proxy("localhost:8080", 'https')
try:
resp = urlopen(req)#, context=ctx)
return int(resp.info().get('Content-Length'))
except HTTPError as exc:
raise HTTPError("Could not determine Content-Length of " + url)
def http_range(url, from_range, to_range, time_out=40):
headers = {'Range': 'bytes={}-{}'.format(from_range, to_range)}
try:
request = Request(url, headers=headers)
#request.set_proxy("localhost:8080", 'https')
req = urlopen(request, timeout=time_out)#, context=ctx)
if 400 <= req.getcode() < 600:
raise HTTPError('HTTP %s Error for url: %s' % (req.getcode(), url), response=req)
except (HTTPError, URLError) as err:
print("Error occured:")
print(err)
chunk = req.read()
req.close()
return chunk
class HTTPFile:
def __init__(self, url, cache_size):
self.url = url
self.position = 0
self.filesize = http_file_size(url)
self.cache_size = cache_size
self.cache_start = 0
self.cache_end = 0
self.cache = b''
self.debug_number_of_requests = 0
print("New HTTPFile created with filesize {} and URL {}".format(self.filesize, url))
def seekable(self):
return True
def seek(self, pos, from_what=0):
if from_what == 0:
[Truncated]
return False
@staticmethod
def get_bstream(url, cache_size):
"""Get a bytestream of the image"""
if url.endswith('.zip'):
bstream = ZipFile(HTTPFile(url, cache_size), 'r').open(os.path.basename(url).strip('.zip'), 'r') # pylint: disable=consider-using-with
else:
bstream = open(imgpath, 'rb') # pylint: disable=consider-using-with
return [bstream, 0]
if __name__ == "__main__":
link = "https://dl.google.com/dl/edgedl/chromeos/recovery/chromeos_14324.62.0_bob_recovery_stable-channel_mp.bin.zip"
cache_size = 1024*1024*3
os_image = ChromeOSImage(link, cache_size)
extracted = os_image.extract_file(filename="libwidevinecdm.so", extract_path=".")
```
<issue_comment>username_1: Thanks for coming up with this interesting proof of concept!
However I see some problems to make this the main approach in our add-on for getting the Widevine CDM on ARM devices:
- Our users worldwide don't always have very fast internet connections, so we should keep bandwidth usage to a minimum for ordinary users.
- This approach seems much slower than downloading a single 1 GB image? Not sure.
- I fear that the chance to a get a ConnectionRefusedError from Google is very likely when opening dozens of connections. We sometimes see this in our CI testing on Github.
Feel free to come up with a PR implementing this as an option for "expert users". After some more testing, I guess this can be merged.
When I find some time, I'll take another look at this.
<issue_comment>username_0: Thanks for considering.
It is currently only slower than downloading a single 1GB image because I haven't implemented caching on disk and I haven't implemented multi-chunk caching (currently only caches one chunk). Therefore it downloads large parts of the zip file twice, which is of course not optimal.
I have a different view on it: As the implementation allows to decided what happens (use memory, disc or more connections), we can just make the default behave just the same as now. How about:
1. If more than 1.5GB memory is free and available: Use 1 HTTP request, store chunks in-memory
2. If more than 1.5GB disc is available: 1 HTTP request, store on disc
3. Use 50% of available memory as the chunk size and only cache 1 chunk, do as many HTTP requests as necessary
That would probably make thinks faster compared to now for people who have enough memory (e.g. Raspberry Pi 4 with 4 or 8 GB RAM). I guess it should be no issue to "resort to the next strategy" as a fallback if something goes wrong in the approach chosen.
I have a couple of questions:
* Can we determine how much memory is free/available to us? I saw that we know how much disc space is available at https://github.com/emilsvennesson/script.module.inputstreamhelper/blob/c97af2116594a8b372920d614122f9acb4b1bbd9/lib/inputstreamhelper/utils.py#L231
* What is the easiest way to setup a development environment with inputstreamhelper? I guess I have to use a RasperryPi or something to test the ARM setup? Or do you have a nice virtualized environment (ARM VM?) I could download?
* Any IDE you are using?
I'm currenlty still thinking about how I could visualize which chunks are necessary from the zip file at all.
<issue_comment>username_1: No, I use a text editor and a symlink from a local git repo to a real Kodi installation
```
ln -s ~/script.module.inputstreamhelper/ ~/.kodi/addons/
```
And I enabled debug logging in advancedsettings.xml in ~/.kodi/userdata/
```
<advancedsettings>
<loglevel>1</loglevel>
</advancedsettings>
```
To speed up testing on a real Kodi installation you can automatically execute add-on functions on startup.
https://kodi.wiki/view/Autoexec_Service
You can auto execute the scripts from the `api.py`
- Automatically remove Widevine with autoexec
```
import xbmc
xbmc.executebuiltin('RunScript(script.module.inputstreamhelper, widevine_remove)')
```
Automatically install Widevine with autoexec
```
import xbmc
xbmc.executebuiltin('RunScript(script.module.inputstreamhelper, widevine_install)')
``` | {'fraction_non_alphanumeric': 0.06503137478608101, 'fraction_numerical': 0.01806427077391139, 'mean_word_length': 3.738288288288288, 'pattern_counts': {'":': 1, '<': 12, '<?xml version=': 0, '>': 10, 'https://': 5, 'lorem ipsum': 0, 'www.': 0, 'xml': 1}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 11, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '13143706', 'n_tokens_mistral': 3135, 'n_tokens_neox': 2851, 'n_words': 1373} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: iOS 12.2 real device changing to webview context failing
username_0: ## The problem
The test is crashing when it tries to change from native context to webview context on ios 12.2 real device. The webview context is found but it fails on set context.
## Environment
* Appium version: appium 1.13.0 beta 3
* OS: macOS 10.14.4
* Node.js vesion: 11.14.0
* Npm or Yarn package manager:
* Mobile platform/version under test: iPhone X with iOS 12.2
* Real device
## Appium logs
[HTTP] --> POST /wd/hub/session/d6e528f6-fb7e-4f79-9c70-4d55143bfae5/context
[HTTP] {"name":"WEBVIEW_1"}
[debug] [W3C (d6e528f6)] Calling AppiumDriver.setContext() with args: ["WEBVIEW_1","d6e528f6-fb7e-4f79-9c70-4d55143bfae5"]
[debug] [XCUITest] Executing command 'setContext'
[debug] [iOS] Attempting to set context to 'WEBVIEW_1'
[debug] [RemoteDebugger] Using full Web Inspector protocol communication
[debug] [RemoteDebugger] Connecting to WebKit socket: 'ws://localhost:27753/devtools/page/1'
[debug] [RemoteDebugger] WebKit debugger web socket connected to url: ws://localhost:27753/devtools/page/1
[debug] [RemoteDebugger] Starting to listen for JavaScript console
[debug] [RemoteDebugger] Sending WebKit data: {"method":"Console.enable","params":{"objectGroup":"console","includeCommandLineAPI":true,"doNotPauseOnExceptionsAndMuteConsole":true}}
[debug] [RemoteDebugger] Webkit response timeout: 5000
[debug] [RemoteDebugger] Received WebKit data: '{"method":"Target.targetCreated","params":{"targetInfo":{"targetId":"page-1","type":"page"}}}'
[debug] [RemoteDebugger] Found method 'Target.targetCreated'
[debug] [RemoteDebugger] Target created: {"targetId":"page-1","type":"page"}
[debug] [RemoteDebugger] Received WebKit data: '{"error":{"code":-32601,"message":"'Console' domain was not found","data":[{"code":-32601,"message":"'Console' domain was not found"}]},"id":0}'
[debug] [RemoteDebugger] Found method 'Console.enable'
[debug] [W3C (d6e528f6)] Encountered internal error running command: 'Console' domain was not found
<issue_comment>username_1: Please try to use the latest Appium beta (`npm uninstall -g appium && npm install -g appium@beta`).
<issue_comment>username_0: HI @username_1 , thanks for your reply. I already did it, The error I got is with appium v1.13.0-beta.3
<issue_comment>username_1: Did you fully uninstall appium before installing the beta? This problem should be fixed.
Please uninstall and reinstall the beta, then post the full logs (as a link to a [gist](https://gist.github.com)).
<issue_comment>username_1: It would also be interesting to see the output of running the command `npm ls -g appium-remote-debugger`.
<issue_comment>username_0: The output for command npm ls -g appium-remote-debugger is:
/usr/local/lib
└─┬ [email protected]
├─┬ [email protected]
│ └── [email protected]
├─┬ [email protected]
│ └── [email protected] deduped
└─┬ [email protected]
└─┬ [email protected]
└── [email protected]
<issue_comment>username_0: I uninstalled and reinstalled the beta but the error still there.
Here is the full log: https://gist.github.com/username_0/aa81964653d56767282748c6e7a91ef9
Thanks for your help.
<issue_comment>username_1: @username_0 Those dependencies look good. For some reason our check for the new communication protocol is failing in your case.
I have released a new version of `appium-remote-debugger` (which is what Appium uses to communicate with Safari/webviews on iOS) with verbose logging of the decision process. Hopefully this can help figure out the problem, so we can solve it!
Can you uninstall/reinstall again? It should end up with `[email protected]` (visible using `npm ls -g appium-remote-debugger` again).
Sorry for the complexity of debugging this.
<issue_comment>username_0: Hi @username_1, I installed [email protected] again. Here is the output for command: npm ls -g appium-remote-debugger
/usr/local/lib
└─┬ [email protected]
├─┬ [email protected]
│ └── [email protected]
├─┬ [email protected]
│ └── [email protected] deduped
└─┬ [email protected]
└─┬ [email protected]
└── [email protected]
Also here is the gist link for appium log for appium using [email protected]:
https://gist.github.com/username_0/f1e144fa80555c2dddba39132d0a64c1
Thanks for taking a look on this!
<issue_comment>username_2: For what it's worth, per #12510 (which is now closed in favor of this issue), several folks are experiencing a similar problem with simulators. Suggest this issue's title be changed accordingly.
<issue_comment>username_1: @username_0 (and anyone else willing to try)...
[Once more, with feeling](https://www.youtube.com/watch?v=FmLSjwam26E)
I've added code to automatically switch communication protocols when necessary. Your system behaves differently than mine, so hardcoding it does not work, alas. Could you reinstall, so that you have `[email protected]`? And retry?
<issue_comment>username_0: @username_1, the issue seems fixed with [email protected]. I was able to change to webview context with this fix.
Thanks you all guys for the assistance!
<issue_comment>username_1: 👍
I'll leave this open for a bit for others who are having problems.
<issue_comment>username_3: I got the same issue with below env:
Appium desktop: 1.12.1
OS: macOS 10.14.4
Node.js vesion: 11.4.0
Mobile platform/version under test: iPhone 5S with iOS 12.2
Real device
Can anyone help on this issue?
<issue_comment>username_4: @username_1
i update appium to appium@beta, but still have issue
```
[HTTP] {"name":"WEBVIEW_17033.1"}
[debug] [W3C (7b530b40)] Calling AppiumDriver.setContext() with args: ["WEBVIEW_17033.1","7b530b40-83be-4f4a-8dbd-3375938d33da"]
[debug] [XCUITest] Executing command 'setContext'
[debug] [iOS] Attempting to set context to 'WEBVIEW_17033.1'
[debug] [RemoteDebugger] Selecting page '1' on app 'PID:17033' and forwarding socket setup
[debug] [RemoteDebugger] Sending '_rpc_forwardSocketSetup:' message to remote debugger (id: 3)
[debug] [RemoteDebugger] Sender key set
[debug] [RemoteDebugger] Sending '_rpc_forwardSocketData:' message to remote debugger (id: 4)
[debug] [W3C (7b530b40)] Encountered internal error running command: Error: Remote debugger error with code '-32601': 'Page' domain was not found
[debug] [W3C (7b530b40)] at Object.errorHandler (/Applications/Appium.app/Contents/Resources/app/node_modules/appium/node_modules/appium-xcuitest-driver/node_modules/appium-remote-debugger/lib/remote-debugger-rpc-client.js:241:18)
[debug] [W3C (7b530b40)] at RpcMessageHandler.handleDataMessage (/Applications/Appium.app/Contents/Resources/app/node_modules/appium/node_modules/appium-xcuitest-driver/node_modules/appium-remote-debugger/lib/remote-debugger-message-handler.js:190:9)
[debug] [W3C (7b530b40)] at RpcMessageHandler.handleMessage (/Applications/Appium.app/Contents/Resources/app/node_modules/appium/node_modules/appium-xcuitest-driver/node_modules/appium-remote-debugger/lib/remote-debugger-message-handler.js:73:13)
[debug] [W3C (7b530b40)] at RemoteDebuggerRpcClient.handleMessage [as receive] (/Applications/Appium.app/Contents/Resources/app/node_modules/appium/node_modules/appium-xcuitest-driver/node_modules/appium-remote-debugger/lib/remote-debugger-rpc-client.js:389:35)
[debug] [W3C (7b530b40)] at Socket.emit (events.js:189:13)
[debug] [W3C (7b530b40)] at addChunk (_stream_readable.js:284:12)
[debug] [W3C (7b530b40)] at readableAddChunk (_stream_readable.js:265:11)
[debug] [W3C (7b530b40)] at Socket.Readable.push (_stream_readable.js:220:10)
[debug] [W3C (7b530b40)] at Pipe.onStreamRead [as onread] (internal/stream_base_commons.js:94:17)
[HTTP] <-- POST /wd/hub/session/7b530b40-83be-4f4a-8dbd-3375938d33da/context 500 37 ms - 701
```
<issue_comment>username_5: I have a number of complex UI tests that require the switching from WEBVIEW context to NATIVE and back to WEBVIEW that are now failing with iOS 12.2 even with the latest beta (which does fix the initial issue) is this a known issue / limitation?
<issue_comment>username_1: @username_4 Please post the full logs as a link to a [gist](https://gist.github.com). The snippet you've posted does not provide enough information to say anything.
<issue_comment>username_4: @username_1 Yes, sure
https://gist.github.com/username_4/01be33ffee1e69cee21956b0d3a189a4
<issue_comment>username_0: Hi @username_4,
Are you using Appium-Desktop app or Appium-CLI?
<issue_comment>username_1: @username_4 I'm sorry, but those are not the logs for the latest version. Please try the latest beta (_fully_ uninstall the old version, then install the latest: `npm uninstall -g appium && npm install -g appium@beta`).
<issue_comment>username_4: @username_1 , ok, i'll try
<issue_comment>username_4: @username_1 i just reinstall and still have a problem
https://gist.github.com/username_4/5c678c234634622abcee0b3e2b8b8847
`appium 1.13.0-beta.3`
<issue_comment>username_5: I seem to be getting different behaviour using the same version of Appium against iOS 12.2 and 12.1.
When running against 12.1 the context remains the original context regardless of whether the application changes WEBVIEW (in my application you are navigated to a login portal) meaning I have to manually switch contexts. In 12.2 it seems to follow the context.
Is this intentional?
<issue_comment>username_4: @username_1 sorry, some interesting why it's running appium 1.12.1
<issue_comment>username_1: @username_4 However you are spawning the Appium server, the wrong one is being started. It should be `[email protected]`.
<issue_comment>username_1: @username_5 I'm not entirely sure I understand what you are meaning. But it doesn't sound intentional. Much was changed between 12.1 and 12.2, so things behaving differently might happen, though we would prefer it not to, and if you completely explain the situation (probably in its own issue) we could try to rectify.
<issue_comment>username_4: @username_1 How could i change version of the server that would be started?
<issue_comment>username_0: @username_4, for some reason you are point to the appium desktop app resources (/Applications/Appium.app/Contents/Resources/app/node_modules/appium/node_modules/appium-xcuitest-driver/node_modules/appium-remote-debugger/) instead of the appium-cli server. Please check your capabilities if you are point to correct agentPath or if you have installed appium-desktop, uninstall it and run appium from command line.
<issue_comment>username_5: @username_1 I will try to describe with an example
In iOS 12.1
- Start application (Current context: WEBVIEW_27890.1)
- Redirected to Login (Current context: WEBVIEW_27890.1)
- I would now manually switch contexts to the new (Current context: WEBVIEW_27890.11)
- Perform Login steps (Current context: WEBVIEW_27890.11)
In iOS 12.2
- Start application (Current context: WEBVIEW_27890.1)
- Redirected to Login context has automatically switch over (Current context: WEBVIEW_27890.11)
- I no longer need to manually switch contexts
- Perform Login steps (Current context: WEBVIEW_27890.11)
Hope that helps
<issue_comment>username_4: @username_0 sure, i currently doing this
<issue_comment>username_1: @username_4 I'm confused. It looks like you're using the Java Appium server service, not Appium Desktop? But the logs are from Appium Desktop. Or at least, from the server installed when that is installed.
This is a configuration issue on your end. https://github.com/appium/java-client/blob/master/docs/The-starting-of-an-app-using-Appium-node-server-started-programmatically.md
<issue_comment>username_1: @username_5 Please create a new issue, since it is not the same as this one. Please include the steps you noted here as well as full logs for both situations.
From there we can try to get things in-line.
<issue_comment>username_4: @username_1 thanks, now it's working
<issue_comment>username_1: Excellent! I'm glad to hear it!
<issue_comment>username_4: @username_1 thank for help
<issue_comment>username_6: Failed to create WDA session (An unknown server-side error occurred while processing the command. Original error: +[XCAXClient_iOS sharedClient]: unrecognized selector sent to class 0x1002a8130<issue_closed> | {'fraction_non_alphanumeric': 0.10018316476865494, 'fraction_numerical': 0.05184359321493987, 'mean_word_length': 5.072533849129594, 'pattern_counts': {'":': 21, '<': 39, '<?xml version=': 0, '>': 39, 'https://': 8, 'lorem ipsum': 0, 'www.': 1, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '30448581', 'n_tokens_mistral': 4401, 'n_tokens_neox': 4053, 'n_words': 1341} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Adds new integration [GrumpyMeow/media_source]
username_0: <!--
DO NOT REQUEST REVIEWS, THAT IS JUST RUDE, IF YOU DO THE PULL REQUEST WILL BE CLOSED!
Make sure to check out the guide here: https://hacs.xyz/docs/publish/start
And consider adding a GitHub Action workflow to your repository: https://hacs.xyz/docs/publish/action
-->
<issue_comment>username_0: Hi,
This is a customization of the inbuilt Homeassistant Local-Media-Source-component. As such i don't really know what to do with to resolve the blocking of the merge.
<issue_comment>username_1: There are 2 options;
1) Change the domain so you don't override a core integration
2) Keep it as custom <https://hacs.xyz/docs/faq/custom_repositories> (effectively close this PR)
Custom integrations that override core integrations cause so many issues and confusion for all parties, I don't want any more of that added as default in HACS.
<issue_comment>username_0: I choose the blue-pill... I'll close close this Pull-Request. :-)
Thanks! | {'fraction_non_alphanumeric': 0.07684918347742556, 'fraction_numerical': 0.0067243035542747355, 'mean_word_length': 4.602150537634409, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '6663533', 'n_tokens_mistral': 315, 'n_tokens_neox': 298, 'n_words': 135} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: fix: Dramatiq calls are no http requests
username_0: Fix https://github.com/username_1/sentry-dramatiq/issues/2
<issue_comment>username_1: Thanks @username_0. Seems like the unit tests are failing though.
<issue_comment>username_0: @username_1 should work now?
<issue_comment>username_2: Can we please merge this and create a new release @username_1?
<issue_comment>username_1: Merged and released as 0.3.0 | {'fraction_non_alphanumeric': 0.08390022675736962, 'fraction_numerical': 0.02947845804988662, 'mean_word_length': 6.754385964912281, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '29427860', 'n_tokens_mistral': 140, 'n_tokens_neox': 138, 'n_words': 45} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Take width into account for adaptive sampling
username_0: Currently, adaptive sampling is only based on the control point positions. This leads to not enough samples computed when the control points are aligned but with varying width.
Here is an example where adaptive sampling is "on", but don't generate any new samples while it should, resulting in a noticeable angle:
 | {'fraction_non_alphanumeric': 0.06788990825688074, 'fraction_numerical': 0.06788990825688074, 'mean_word_length': 5.423529411764706, 'pattern_counts': {'":': 0, '<': 2, '<?xml version=': 0, '>': 2, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '24658931', 'n_tokens_mistral': 172, 'n_tokens_neox': 145, 'n_words': 61} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Fails to connect to github when a profile is viewed through the weekly monthly trending repos
username_0: ***Expected Behavior***
It should be able to load profiles conveniently, regardless of where it was clicked from...
***Actual Behavior***
When a user profile is clicked from the weekly/monthly trending repos, it would load for like a second and then display a message saying : Loading the data from Github failed
But when a profile is clicked theory 'Today's' menu, it will work fine
***How to reproduce the bug***
Open the app, login using your github details, open the menu at the top left corner, scroll down and select 'Trending Repos', now move to either the week or the month to see the trending repos. When it opens, select a repository, after loading, now touch the user's profile name located in the repository(before the '/'******
For instance,
*proflink/Gn4qr* Where proflink is the profile link we should click so as to get to the users profile to see more of his/her works and details )
After clicking on the link, it would load and after some couple of sec, it would give a message that loading data from github failed...
***NOTE :*** when a profile is clicked from the 'today' list in the trending repo, it opens neatly
To reproduce the bug might get a little tricky.... Just follow the step above and also endeavor to see the video below....
***TEST TOOLS***
* Operating system : Android 6.0
* Phone : Infinix hot s
* Octodroid V4.3.1
***Recording of the bug is showned below....***
Watch the video below to see how it behaves....
https://youtu.be/1jErrxyQ1N4
<br /><hr/><em>Posted on <a href="https://utopian.io/utopian-io/@username_0/fails-to-connect-to-github-when-a-profile-is-viewed-through-the-weekly-monthly-trending-repos">Utopian.io - Rewarding Open Source Contributors</a></em><hr/>
<issue_comment>username_1: I'm pretty sure this depends on the type of opened user: it's very likely to only occur for organizations and thus has the same root cause as #830. Can you confirm it only happens for organizations? If no, with what non-organization user can you reproduce this with? | {'fraction_non_alphanumeric': 0.08183908045977012, 'fraction_numerical': 0.006896551724137931, 'mean_word_length': 4.12, 'pattern_counts': {'":': 0, '<': 10, '<?xml version=': 0, '>': 10, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '9283304', 'n_tokens_mistral': 622, 'n_tokens_neox': 577, 'n_words': 318} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: TestResponseProgress fails in Go v1.4.3
username_0: ```
--- FAIL: TestResponseProgress (0.74s)
response_test.go:31: Transfer should not have started
response_test.go:35: Transfer should not have started yet but progress is 1
```
<issue_comment>username_0: v1.4.x is no longer supported. This issue has not been replicated in any subsequent version.<issue_closed> | {'fraction_non_alphanumeric': 0.08933002481389578, 'fraction_numerical': 0.03722084367245657, 'mean_word_length': 5.3125, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '2192767', 'n_tokens_mistral': 126, 'n_tokens_neox': 118, 'n_words': 43} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Rust linter doesn't work properly
username_0: ## Information
**VIM version**
NVIM v0.4.3
Build type: Release
Operating System: Manjaro Linux
## What went wrong
Rust's linter isn't working as expected. After I include an external create, module it generates an error and it says that the module was not found even tho if I compile it everything works normally.
## Reproducing the bug
1. Just import any external file, module, library, create etc. and the linter goes crazy even if there's no error.
### :ALEInfo
Current Filetype: rust
Available Linters: ['cargo', 'rls', 'rustc']
Enabled Linters: ['rustc']
Suggested Fixers:
'remove_trailing_lines' - Remove all blank lines at the end of a file.
'rustfmt' - Fix Rust files with Rustfmt.
'trim_whitespace' - Remove all trailing whitespace characters at the end of every line.
Linter Variables:
let g:ale_rust_ignore_error_codes = []
let g:ale_rust_ignore_secondary_spans = 0
let g:ale_rust_rustc_options = ''
Global Variables:
let g:ale_cache_executable_check_failures = v:null
let g:ale_change_sign_column_color = 0
let g:ale_command_wrapper = ''
let g:ale_completion_delay = 100
let g:ale_completion_enabled = 0
let g:ale_completion_max_suggestions = 50
let g:ale_echo_cursor = 1
let g:ale_echo_msg_error_str = 'Error'
let g:ale_echo_msg_format = '%code: %%s'
let g:ale_echo_msg_info_str = 'Info'
let g:ale_echo_msg_warning_str = 'Warning'
let g:ale_enabled = 1
let g:ale_fix_on_save = 0
let g:ale_fixers = {}
let g:ale_history_enabled = 1
let g:ale_history_log_output = 1
let g:ale_keep_list_window_open = 0
let g:ale_lint_delay = 200
let g:ale_lint_on_enter = 1
let g:ale_lint_on_filetype_changed = 1
let g:ale_lint_on_insert_leave = 1
let g:ale_lint_on_save = 1
let g:ale_lint_on_text_changed = 'normal'
let g:ale_linter_aliases = {}
let g:ale_linters = {'rust': ['rustc']}
let g:ale_linters_explicit = 0
let g:ale_list_vertical = 0
let g:ale_list_window_size = 10
let g:ale_loclist_msg_format = '%code: %%s'
let g:ale_lsp_root = {}
let g:ale_max_buffer_history_size = 20
let g:ale_max_signs = -1
let g:ale_maximum_file_size = v:null
let g:ale_open_list = 0
let g:ale_pattern_options = v:null
let g:ale_pattern_options_enabled = v:null
let g:ale_set_balloons = 0
let g:ale_set_highlights = 1
let g:ale_set_loclist = 1
let g:ale_set_quickfix = 0
let g:ale_set_signs = 1
let g:ale_sign_column_always = 0
let g:ale_sign_error = '>>'
let g:ale_sign_info = '--'
let g:ale_sign_offset = 1000000
let g:ale_sign_style_error = '>>'
let g:ale_sign_style_warning = '--'
[Truncated]
(finished - exit code 1) ['/usr/bin/zsh', '-c', 'rustc --error-format=json -L ''/home/godnyx/Projects/Programming/Rust/restaurant/target/debug/deps'' -L ''/home/godnyx/Projects/Programming/Rust/restaurant/target/release/deps'' - < ''/tmp/nvimqY3d5H/972/lib.rs''']
<<<OUTPUT STARTS>>>
{"message":"unresolved import `crate::front_of_house::hosting`","code":{"code":"E0432","explanation":"An import was unresolved.\n\nErroneous code example:\n\n```compile_fail,E0432\nuse something::Foo; // error: unresolved import `something::Foo`.\n```\n\nPaths in `use` statements are relative to the crate root. To import items\nrelative to the current and parent modules, use the `self::` and `super::`\nprefixes, respectively. Also verify that you didn't misspell the import\nname and that the import exists in the module from where you tried to\nimport it. Example:\n\n```\nuse self::something::Foo; // ok!\n\nmod something {\n pub struct Foo;\n}\n# fn main() {}\n```\n\nOr, if you tried to use a module from an external crate, you may have missed\nthe `extern crate` declaration (which is usually placed in the crate root):\n\n```\nextern crate core; // Required to use the `core` crate\n\nuse core::any;\n# fn main() {}\n```\n"},"level":"error","spans":[{"file_name":"<anon>","byte_start":29,"byte_end":59,"line_start":3,"line_end":3,"column_start":9,"column_end":39,"is_primary":true,"text":[{"text":"pub use crate::front_of_house::hosting;","highlight_start":9,"highlight_end":39}],"label":"no `hosting` in `front_of_house`","suggested_replacement":null,"suggestion_applicability":null,"expansion":null}],"children":[],"rendered":"error[E0432]: unresolved import `crate::front_of_house::hosting`\n --> <anon>:3:9\n |\n3 | pub use crate::front_of_house::hosting;\n | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ no `hosting` in `front_of_house`\n\n"}
{"message":"`main` function not found in crate `rust_out`","code":{"code":"E0601","explanation":"No `main` function was found in a binary crate. To fix this error, add a\n`main` function. For example:\n\n```\nfn main() {\n // Your program will start here.\n println!(\"Hello world!\");\n}\n```\n\nIf you don't know the basics of Rust, you can go look to the Rust Book to get\nstarted: https://doc.rust-lang.org/book/\n"},"level":"error","spans":[{"file_name":"<anon>","byte_start":0,"byte_end":188,"line_start":1,"line_end":9,"column_start":1,"column_end":2,"is_primary":true,"text":[{"text":"mod front_of_house;","highlight_start":1,"highlight_end":20},{"text":"","highlight_start":1,"highlight_end":1},{"text":"pub use crate::front_of_house::hosting;","highlight_start":1,"highlight_end":40},{"text":"","highlight_start":1,"highlight_end":1},{"text":"pub fn eat_at_restaurant() {","highlight_start":1,"highlight_end":29},{"text":" hosting::add_to_waitlist();","highlight_start":1,"highlight_end":32},{"text":" hosting::add_to_waitlist();","highlight_start":1,"highlight_end":32},{"text":" hosting::add_to_waitlist();","highlight_start":1,"highlight_end":32},{"text":"}","highlight_start":1,"highlight_end":2}],"label":"consider adding a `main` function at the crate level","suggested_replacement":null,"suggestion_applicability":null,"expansion":null}],"children":[],"rendered":"error[E0601]: `main` function not found in crate `rust_out`\n --> <anon>:1:1\n |\n1 | / mod front_of_house;\n2 | |\n3 | | pub use crate::front_of_house::hosting;\n4 | |\n... |\n8 | | hosting::add_to_waitlist();\n9 | | }\n | |_^ consider adding a `main` function at the crate level\n\n"}
{"message":"aborting due to 2 previous errors","code":null,"level":"error","spans":[],"children":[],"rendered":"error: aborting due to 2 previous errors\n\n"}
{"message":"Some errors have detailed explanations: E0432, E0601.","code":null,"level":"failure-note","spans":[],"children":[],"rendered":"Some errors have detailed explanations: E0432, E0601.\n"}
{"message":"For more information about an error, try `rustc --explain E0432`.","code":null,"level":"failure-note","spans":[],"children":[],"rendered":"For more information about an error, try `rustc --explain E0432`.\n"}
<<<OUTPUT ENDS>>>
(finished - exit code 1) ['/usr/bin/zsh', '-c', 'rustc --error-format=json -L ''/home/godnyx/Projects/Programming/Rust/restaurant/target/debug/deps'' -L ''/home/godnyx/Projects/Programming/Rust/restaurant/target/release/deps'' - < ''/tmp/nvimqY3d5H/973/lib.rs''']
<<<OUTPUT STARTS>>>
{"message":"unresolved import `crate::front_of_house::hosting`","code":{"code":"E0432","explanation":"An import was unresolved.\n\nErroneous code example:\n\n```compile_fail,E0432\nuse something::Foo; // error: unresolved import `something::Foo`.\n```\n\nPaths in `use` statements are relative to the crate root. To import items\nrelative to the current and parent modules, use the `self::` and `super::`\nprefixes, respectively. Also verify that you didn't misspell the import\nname and that the import exists in the module from where you tried to\nimport it. Example:\n\n```\nuse self::something::Foo; // ok!\n\nmod something {\n pub struct Foo;\n}\n# fn main() {}\n```\n\nOr, if you tried to use a module from an external crate, you may have missed\nthe `extern crate` declaration (which is usually placed in the crate root):\n\n```\nextern crate core; // Required to use the `core` crate\n\nuse core::any;\n# fn main() {}\n```\n"},"level":"error","spans":[{"file_name":"<anon>","byte_start":29,"byte_end":59,"line_start":3,"line_end":3,"column_start":9,"column_end":39,"is_primary":true,"text":[{"text":"pub use crate::front_of_house::hosting;","highlight_start":9,"highlight_end":39}],"label":"no `hosting` in `front_of_house`","suggested_replacement":null,"suggestion_applicability":null,"expansion":null}],"children":[],"rendered":"error[E0432]: unresolved import `crate::front_of_house::hosting`\n --> <anon>:3:9\n |\n3 | pub use crate::front_of_house::hosting;\n | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ no `hosting` in `front_of_house`\n\n"}
{"message":"`main` function not found in crate `rust_out`","code":{"code":"E0601","explanation":"No `main` function was found in a binary crate. To fix this error, add a\n`main` function. For example:\n\n```\nfn main() {\n // Your program will start here.\n println!(\"Hello world!\");\n}\n```\n\nIf you don't know the basics of Rust, you can go look to the Rust Book to get\nstarted: https://doc.rust-lang.org/book/\n"},"level":"error","spans":[{"file_name":"<anon>","byte_start":0,"byte_end":188,"line_start":1,"line_end":9,"column_start":1,"column_end":2,"is_primary":true,"text":[{"text":"mod front_of_house;","highlight_start":1,"highlight_end":20},{"text":"","highlight_start":1,"highlight_end":1},{"text":"pub use crate::front_of_house::hosting;","highlight_start":1,"highlight_end":40},{"text":"","highlight_start":1,"highlight_end":1},{"text":"pub fn eat_at_restaurant() {","highlight_start":1,"highlight_end":29},{"text":" hosting::add_to_waitlist();","highlight_start":1,"highlight_end":32},{"text":" hosting::add_to_waitlist();","highlight_start":1,"highlight_end":32},{"text":" hosting::add_to_waitlist();","highlight_start":1,"highlight_end":32},{"text":"}","highlight_start":1,"highlight_end":2}],"label":"consider adding a `main` function at the crate level","suggested_replacement":null,"suggestion_applicability":null,"expansion":null}],"children":[],"rendered":"error[E0601]: `main` function not found in crate `rust_out`\n --> <anon>:1:1\n |\n1 | / mod front_of_house;\n2 | |\n3 | | pub use crate::front_of_house::hosting;\n4 | |\n... |\n8 | | hosting::add_to_waitlist();\n9 | | }\n | |_^ consider adding a `main` function at the crate level\n\n"}
{"message":"aborting due to 2 previous errors","code":null,"level":"error","spans":[],"children":[],"rendered":"error: aborting due to 2 previous errors\n\n"}
{"message":"Some errors have detailed explanations: E0432, E0601.","code":null,"level":"failure-note","spans":[],"children":[],"rendered":"Some errors have detailed explanations: E0432, E0601.\n"}
{"message":"For more information about an error, try `rustc --explain E0432`.","code":null,"level":"failure-note","spans":[],"children":[],"rendered":"For more information about an error, try `rustc --explain E0432`.\n"}
<<<OUTPUT ENDS>>>
<issue_comment>username_0: Thanks for the answer!<issue_closed>
<issue_comment>username_1: Sorry to open this but I have also the same problem and I cant seem to find the solution?
What exactly was it, @username_0 ? | {'fraction_non_alphanumeric': 0.18665949435180204, 'fraction_numerical': 0.023668639053254437, 'mean_word_length': 6.521915037086986, 'pattern_counts': {'":': 180, '<': 27, '<?xml version=': 0, '>': 33, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '13163709', 'n_tokens_mistral': 4050, 'n_tokens_neox': 3767, 'n_words': 865} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Create JSON Document for Metrics
username_0: I would like for a JSON document entailing all the metrics we have discussed to be posted here.
<issue_comment>username_1: ```
{
"event_key":
"match_number":
"match_type":
"match_type_number":
"team_number":
"scout_team":
"scout_initials":
"auto_starting_level":
"auto_crossed_line":
"auto_bottom_rocket_panels":
"auto_middle_rocket_panels":
"auto_top_rocket_panels":
"auto_ship_panels":
"auto_bottom_rocket_cargo":
"auto_middle_rocket_cargo":
"auto_top_rocket_cargo":
"auto_ship_cargo":
"teleop_bottom_rocket_panels":
"teleop_middle_rocket_panels":
"teleop_top_rocket_panels":
"teleop_ship_panels":
"teleop_bottom_rocket_cargo":
"teleop_middle_rocket_cargo":
"teleop_top_rocket_cargo":
"teleop_ship_cargo":
"panel_ground_pickup":
"cargo_ground_pickup":
"endgame_level_climbed":
"endgame_assist_in_climbing":
"comments_not_present":
"comments_disabled":
"comments_robot_failure":
"comments_top_heavy":
"comments_foul":
"comments_card":
}
```
(deep_space_metrics.json)<issue_closed> | {'fraction_non_alphanumeric': 0.10231814548361311, 'fraction_numerical': 0.0015987210231814548, 'mean_word_length': 3.852713178294574, 'pattern_counts': {'":': 35, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '25519', 'n_tokens_mistral': 500, 'n_tokens_neox': 454, 'n_words': 62} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: disable uploading if ANACONDA_TOKEN does not exist
username_0: To avoid issues when testing a fork on the fork's master branch, xref https://github.com/bioconda/bioconda-recipes/pull/3724<issue_closed>
<issue_comment>username_1: Think this is fixed?
<issue_comment>username_0: Haven't seen this pop up in a while, thanks for closing! | {'fraction_non_alphanumeric': 0.07880434782608696, 'fraction_numerical': 0.019021739130434784, 'mean_word_length': 6.6875, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '9508503', 'n_tokens_mistral': 115, 'n_tokens_neox': 110, 'n_words': 40} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Jdk10 fix: #1223 #1212 #1209 #1665
username_0:
<issue_comment>username_0: @username_1 @ctadlock are there any comments on these commits?
<issue_comment>username_1: @ctadlock This should go into the tornadofx2 repo now, shouldn't it?
<issue_comment>username_0: *up javafx version (13)
<issue_comment>username_0: @username_1 I made a serious mistake last merging with the `main` branch. Please take it and put it on the `bintray`. And then @ctadlock while with the repository `TornadoFX 2` is not in a hurry.
this PR will replace #1219 | {'fraction_non_alphanumeric': 0.078397212543554, 'fraction_numerical': 0.05749128919860627, 'mean_word_length': 5.764705882352941, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '4277795', 'n_tokens_mistral': 201, 'n_tokens_neox': 183, 'n_words': 76} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: ToolbarView AddButton doesn't seem to be adding any buttons
username_0: Hey again,
I was beginning to experiment with things, so I create a new Window/View/Toolbar, following the Custom Toolbar example, but then I noticed that even in the example, I don't see any sort of custom toolbar?
I am assuming it should be up there near Center, Show Processor, etc, etc?
<img src="https://i.imgur.com/IJi6NO4.png" width="650" />
I went to try and add a new one as follows:
```cs
public class WaypointNodeManagerToolbar : ToolbarView
{
public WaypointNodeManagerToolbar(BaseGraphView graphView) : base(graphView)
{
}
protected override void AddButtons()
{
// Add the hello world button on the left of the toolbar
AddButton("Hello !", () => Debug.Log("Hello World"), false);
AddButton("Create new Waypoint", () => Debug.Log("Creating new waypoint"));
// add the default buttons (center, show processor and show in project)
base.AddButtons();
}
}
```
This is what I end up with:
<img src="https://i.imgur.com/SVyg70Y.png" width="650" />
I feel like I might be missing something silly? Perhaps it's related to 2020.1.0b15. I will try the example in a lesser version to compare.
Thanks,
-MH
<issue_comment>username_1: Hello,
There was indeed an issue in the AddButtons() code of the ToolBarView (it was deleting existing buttons from the list before adding new ones).
The issue should be fixed in this commit: 9ccce050ee63d62a87cd544bf10751b7783686dc
Thanks for the detailed bug report!<issue_closed> | {'fraction_non_alphanumeric': 0.08141592920353982, 'fraction_numerical': 0.02654867256637168, 'mean_word_length': 3.038095238095238, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 8, 'https://': 2, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '4133822', 'n_tokens_mistral': 513, 'n_tokens_neox': 463, 'n_words': 200} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Quantity update: Wrong config for icons.
username_0: For both `minus` and `plus` , it should wrap `iconClass` and `iconId` into `icon` property inside of object. Instead of:
```
minusQtyButton: {
tag: 'button',
class: 'button--icon quantity-update__button quantity-update__button--minus quantity-update__button--disabled',
attributes: 'type="button" aria-label="quantity minus button"',
iconClass: 'button__icon quantity-update__icon',
iconId: 'minus'
},
```
it should be:
```
minusQtyButton: {
tag: 'button',
class: 'button--icon quantity-update__button quantity-update__button--minus quantity-update__button--disabled',
attributes: 'type="button" aria-label="quantity minus button"',
icon: {
iconClass: 'button__icon quantity-update__icon',
iconId: 'minus'
}
},
```
<issue_comment>username_1: if it's really necessary to change than imho we should also rename in second example `iconClass` and `iconId` to `class`, `icon` no to have later sth like `icon.iconClass`
<issue_comment>username_2: Fixed https://github.com/SnowdogApps/magento2-alpaca-components/pull/471
<issue_comment>username_3: FIxed and merged to develop #471<issue_closed> | {'fraction_non_alphanumeric': 0.11782945736434108, 'fraction_numerical': 0.008527131782945736, 'mean_word_length': 3.8533834586466167, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '6500209', 'n_tokens_mistral': 397, 'n_tokens_neox': 375, 'n_words': 106} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: [documentation] Database Adapters - TypeORM table names
username_0: ## Question 💬
I'm new to next-auth, so first thing i did i went to the documentation page, [the mysql page](https://next-auth.js.org/adapters/typeorm/mysql) more exactly, to set up the tables. Everything went ok, until the project started and `typeorm-legacy-adapter` created a new set of tables. The difference was that in the documentation the table names are pluralized and in the `typeorm-legacy-adapter` schema the names are not.
Postgres and Microsoft SQL Server pages are also pluralized. Everything works fine, but regarding the pluralized names from the docs, was it meant to be like that or they're just typos ?
<issue_comment>username_1: So it's @iaincollins who created the typeorm adapter, but from the source code, if I think correctly, it always pluralizes:
https://github.com/nextauthjs/adapters/blob/canary/packages/typeorm-legacy/src/lib/naming-strategies.js
https://github.com/nextauthjs/adapters/blob/canary/packages/typeorm-legacy/src/lib/transform.js<issue_closed> | {'fraction_non_alphanumeric': 0.08113035551504102, 'fraction_numerical': 0.0018231540565177757, 'mean_word_length': 5.0, 'pattern_counts': {'":': 0, '<': 4, '<?xml version=': 0, '>': 4, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '3953281', 'n_tokens_mistral': 320, 'n_tokens_neox': 305, 'n_words': 125} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Uncaught Error: code length overflow.
username_0: ```html
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=0">
<title>username_0</title>
</head>
<body>
<div id="qrcode"></div>
<script type="text/javascript" src="qrcode.js"></script>
<script type="text/javascript">
new QRCode(document.getElementById('qrcode'), {
text: 'dianping://web?url=http%3A%2F%2Fusername_0.github.io%2Fqrcode-chrome%2Fservice%2Findex.html%23dianping%253A%252F%252Fweb%253Furl%253Dhttp%25253A%25252F%25252F127.0.0.1%25253A3000%25252Fdest%25252Findex.html',
width: 360,
height: 360,
colorDark: 'rgba(0, 0, 0, 1)',
colorLight: 'rgba(0, 0, 0, 0)'
});
</script>
</body>
</html>
```
throws this error
```
Uncaught Error: code length overflow. (1636>1056)
```
Is there something wrong with my code, or qrcodejs?
<issue_comment>username_0: add
```js
QRCodeModel.prototype = {
// ...
make: function () {
if (this.typeNumber < 1) {
var typeNumber = 1;
for (typeNumber = 1; typeNumber < 40; typeNumber++) {
var rsBlocks = QRRSBlock.getRSBlocks(typeNumber, this.errorCorrectLevel);
var buffer = new QRBitBuffer();
var totalDataCount = 0;
for (var i = 0; i < rsBlocks.length; i++) {
totalDataCount += rsBlocks[i].dataCount;
}
for (var i = 0; i < this.dataList.length; i++) {
var data = this.dataList[i];
buffer.put(data.mode, 4);
buffer.put(data.getLength(), QRUtil.getLengthInBits(data.mode, typeNumber));
data.write(buffer);
}
if (buffer.getLengthInBits() <= totalDataCount * 8)
break;
}
this.typeNumber = typeNumber;
}
this.makeImpl(false, this.getBestMaskPattern());
}
// ...
```
modify
```js
QRCode.prototype.makeCode = function (sText) {
this._oQRCode = new QRCodeModel(-1, this._htOption.correctLevel);
this._oQRCode.addData(sText);
this._oQRCode.make();
//this._el.title = sText;
this._oDrawing.draw(this._oQRCode);
this.makeImage();
};
```
remove `_getTypeNumber` definition and usage.
<issue_comment>username_1: Same error. This seems to happen when URL contains some URLEncoded parts. Can you explain your fix ?
<issue_comment>username_0: @username_1
I didn't really looked into these codes, but it really works.
I found it [here](https://github.com/jeromeetienne/jquery-qrcode/blob/master/src/qrcode.js#L72), which I was using years ago, and it always works.
<issue_comment>username_1: It just seems that qrcode.min.js is not up to date. Getting qrcode.js and minify it yourself is working. | {'fraction_non_alphanumeric': 0.12822124450031427, 'fraction_numerical': 0.034569453174104335, 'mean_word_length': 2.17982017982018, 'pattern_counts': {'":': 0, '<': 28, '<?xml version=': 0, '>': 24, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 1, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '22539902', 'n_tokens_mistral': 1086, 'n_tokens_neox': 973, 'n_words': 218} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: More help
username_0: Sorry but I need some more help. Where are the input button spritesheets located in release 712?
<issue_comment>username_1: eai presente real, precisa de mais ajuda kkkk
<issue_comment>username_0: sim, preciso de mais ajuda, se você puder me dar alguma. (eu tive que traduzir isso)
<issue_comment>username_1: hm, ok. Well, the Input Controls sprites it’s not in the game’s files, it’s just in the source code. so unless you edit by source code, I think it is not possible.
<issue_comment>username_0: I'm just gonna close this for now, as I am making something else since the idea is out the door.<issue_closed> | {'fraction_non_alphanumeric': 0.06146926536731634, 'fraction_numerical': 0.01199400299850075, 'mean_word_length': 5.242990654205608, 'pattern_counts': {'":': 0, '<': 7, '<?xml version=': 0, '>': 7, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '7592554', 'n_tokens_mistral': 208, 'n_tokens_neox': 199, 'n_words': 102} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: RyuJIT: Optimize -X and MathF.Abs(X) for floats
username_0: Contributes to https://github.com/dotnet/runtime/issues/1342
```csharp
public static float XorTest(float x) => -x;
public static float AbsTest(float x) => MathF.Abs(x);
```
#### Current codegen:
```asm
; Method Test:XorTest(float):float
C5F877 vzeroupper
C5FA100D0D000000 vmovss xmm1, dword ptr [reloc @RWD00]
C5F857C1 vxorps xmm0, xmm1
C3 ret
RWD00 dd 80000000h
; Total bytes of code: 16
; Method Test:AbsTest(float):float
C5F877 vzeroupper
C5FA100D0D000000 vmovss xmm1, dword ptr [reloc @RWD00]
C5F854C1 vandps xmm0, xmm1
C3 ret
RWD00 dd 7FFFFFFFh
; Total bytes of code: 16
```
#### New codegen:
```asm
; Method XorTest(float):float
C5F877 vzeroupper
C5F8570505000000 vxorps xmm0, xmm0, dword ptr [reloc @RWD00]
C3 ret
RWD00 dd 80000000h
; Total bytes of code: 12
; Method AbsTest(float):float
C5F877 vzeroupper
C5F8540505000000 vandps xmm0, xmm0, dword ptr [reloc @RWD00]
C3 ret
RWD00 dd 7FFFFFFFh
; Total bytes of code: 12
```
godbolt: https://godbolt.org/z/5K5dGr
#### jit-diff:
```
C:\prj>jit-diff diff --output C:\prj\jitdiffs -f --core_root C:\prj\runtime-1\artifacts\tests\coreclr\Windows_NT.x64.Release\Tests\Core_Root --base C:\prj\runtime-1\artifacts\bin\coreclr\Windows_NT.x64.Checked_base --diff C:\prj\runtime-1\artifacts\bin\coreclr\Windows_NT.x64.Checked --pmi
Beginning PMI CodeSize Diffs for System.Private.CoreLib.dll, framework assemblies
| Finished 267/267 Base 267/267 Diff [379.6 sec]
Completed PMI CodeSize Diffs for System.Private.CoreLib.dll, framework assemblies in 379.72s
Diffs (if any) can be viewed by comparing: C:\prj\jitdiffs\dasmset_9\base C:\prj\jitdiffs\dasmset_9\diff
Analyzing CodeSize diffs...
Found 14 files with textual diffs.
PMI CodeSize Diffs for System.Private.CoreLib.dll, framework assemblies for default jit
Summary of Code Size diffs:
(Lower is better)
Total bytes of diff: -1136 (-0.00% of base)
diff is an improvement.
Top file improvements (bytes):
-523 : System.Private.CoreLib.dasm (-0.01% of base)
-153 : Microsoft.VisualBasic.Core.dasm (-0.03% of base)
-152 : System.Runtime.Numerics.dasm (-0.21% of base)
-92 : Microsoft.Diagnostics.Tracing.TraceEvent.dasm (-0.00% of base)
-84 : System.Drawing.Common.dasm (-0.03% of base)
-36 : Newtonsoft.Json.dasm (-0.00% of base)
-28 : System.Data.Common.dasm (-0.00% of base)
-20 : Microsoft.CodeAnalysis.VisualBasic.dasm (-0.00% of base)
-16 : System.Private.Xml.dasm (-0.00% of base)
-8 : FSharp.Core.dasm (-0.00% of base)
-8 : System.Linq.Expressions.dasm (-0.00% of base)
-8 : System.Private.DataContractSerialization.dasm (-0.00% of base)
-4 : Microsoft.CodeAnalysis.CSharp.dasm (-0.00% of base)
-4 : System.Net.Mail.dasm (-0.00% of base)
14 total files with Code Size differences (14 improved, 0 regressed), 253 unchanged.
Top method improvements (bytes):
-41 (-1.90% of base) : System.Private.CoreLib.dasm - Matrix4x4:<Invert>g__SoftwareFallback|59_1(Matrix4x4,byref):bool
-36 (-5.55% of base) : System.Private.CoreLib.dasm - Matrix4x4:CreateShadow(Vector3,Plane):Matrix4x4
-28 (-1.36% of base) : Microsoft.VisualBasic.Core.dasm - ObjectType:InternalNegObj(Object,IConvertible,int):Object
-25 (-7.84% of base) : System.Private.CoreLib.dasm - MathF:IEEERemainder(float,float):float
-24 (-1.21% of base) : Microsoft.VisualBasic.Core.dasm - Operators:NegateObject(Object):Object
-24 (-5.93% of base) : System.Drawing.Common.dasm - Matrix:RotateAt(float,PointF,int):this
[Truncated]
-8 (-16.33% of base) : System.Runtime.Numerics.dasm - Complex:op_UnaryNegation(Complex):Complex
-8 (-15.38% of base) : Microsoft.VisualBasic.Core.dasm - Conversion:Fix(double):double
-12 (-14.81% of base) : System.Private.CoreLib.dasm - Quaternion:Conjugate(Quaternion):Quaternion
-24 (-14.20% of base) : System.Private.CoreLib.dasm - Matrix3x2:Negate(Matrix3x2):Matrix3x2
-24 (-14.20% of base) : System.Private.CoreLib.dasm - Matrix3x2:op_UnaryNegation(Matrix3x2):Matrix3x2
-16 (-13.68% of base) : System.Private.CoreLib.dasm - Vector4:Abs(Vector4):Vector4
-8 (-12.50% of base) : Microsoft.Diagnostics.Tracing.TraceEvent.dasm - <>c:<ByIDSortedExclusiveMetric>b__15_0(CallTreeNodeBase,CallTreeNodeBase):int:this
-8 (-12.50% of base) : Microsoft.Diagnostics.Tracing.TraceEvent.dasm - <>c:<.ctor>b__0_0(CallTreeNodeBase,CallTreeNodeBase):int:this
-8 (-12.50% of base) : Microsoft.Diagnostics.Tracing.TraceEvent.dasm - <>c:<.ctor>b__0_1(CallTreeNodeBase,CallTreeNodeBase):int:this
-8 (-12.50% of base) : Microsoft.Diagnostics.Tracing.TraceEvent.dasm - <>c:<GetCallees>b__5_0(CallTreeNode,CallTreeNode):int:this
-12 (-12.37% of base) : Newtonsoft.Json.dasm - MathUtils:ApproxEquals(double,double):bool
-12 (-11.88% of base) : System.Private.CoreLib.dasm - Vector3:Abs(Vector3):Vector3
-8 (-11.76% of base) : Microsoft.VisualBasic.Core.dasm - Conversion:Fix(float):float
-4 (-11.76% of base) : Newtonsoft.Json.dasm - JsonValidatingReader:IsZero(double):bool
129 total methods with Code Size differences (129 improved, 0 regressed), 258503 unchanged.
Completed analysis in 28.14s
```
/cc @username_2
Saving 0.0 constant into a temp reg makes sense when it's used more than once but it doesn't work anyway: https://sharplab.io/#v2:EYLgxg9gTgpgtADwGwBYA0AXEBDAzgWwB8ABAJgEYBYAKGIGYACMhgYQYG8aHunGAzADYRsGBgFls2ABSDhohGgayRDAJ4BKBgF4AfA0QMAVPtUBuLjwD0lhgEtRQ7ABNcDAEQAGAHQe3DfHgA1gwYAO62YDCKAJIM2PgMAHYQojAAbjCJ/pkYthCJtokA5voIhnCqDLgAFhAArgJODMAwDBAADrn4tgBeME0YEAxlqjQAvkA===
<issue_comment>username_0: OPTIONAL: Convert `x * -1` to `-x` if it's legal (I am not sure)
<issue_comment>username_1: @username_0, do you know why clang is producing `vxorps`, for double precision (as well as for `float`); while gcc seems to be doing the right thing, producing `vxorpd` with `double` and `vxorps` for `float`?
<issue_comment>username_0: I guess there is no difference for `xor` what to xor - it xors bits https://godbolt.org/z/9TsWq1 🙂
<issue_comment>username_2: For the legacy encoding, the `ps` version is generally 1 byte smaller than the `pd` or integral versions. For VEX they should be the same size.
`movaps`, `movups`, `movntps`, `xorps`, `orps`, `andps`, and `shufps` are all other instructions that can also be substituted due to being a byte smaller but functionally operating on bits rather than on "32-bit floats".
<issue_comment>username_3: @dotnet/jit-contrib
<issue_comment>username_0: some tests fail, a simplified repro:
```csharp
using System;
using System.Runtime.CompilerServices;
class Prog
{
static void Main()
{
Console.WriteLine(
BitConverter.DoubleToInt64Bits(Egor(0, double.NaN)));
}
[MethodImpl(MethodImplOptions.NoInlining)]
static double Egor(double xmm0, double xmm1) => double.IsNegative(xmm1) ? -xmm1 : xmm1;
}
```
happens only when AVX (VEX) is not available (e.g R2R).
Output:
```
Unhandled exception. System.NullReferenceException: Object reference not set to an instance of an object.
at Prog.Egor(Double xmm0, Double xmm1)
at Prog.Main()
```
<issue_comment>username_2: Shouldn't that be `reloc @RWD00`, not `@RWD24`?
<issue_comment>username_0: @username_2 🤔 hm.. shouldn't the constant be `0x8000000000000000` (with sign bit on) but the section looks weird indeed.
<issue_comment>username_2: There is no scalar `xor` operation, just a packed version, so the constant must be 16-bytes with at least element 0 being `-0.0` (although we currently set all elements to be `-0.0` or `-0.0f`).
<issue_comment>username_0: @username_2 I've updated my previous comment - do you see why the second (current) codegen works fine?
<issue_comment>username_2: `movsd xmm0, qword ptr [reloc @RWD08]` reads a `scalar double` (hence `sd`), so it will only read 8-bytes and using `RWD08` when the constant at that address is 8-bytes is fine.
`xorps xmm0, qword ptr [reloc @RWD08]` reads a `packed single` (hence `ps`), so it reads 16-bytes. You are reading from `RWD08` and so it is reading `RWD08-RWD24` (where there is no data at `RWD16`).
The failure, however, isn't due to the overreading (in this case), its because the data isn't aligned. The VEX encoding allows contained memory operands to be unaligned, while the legacy encoding (generally speaking) requires them to be aligned.
Fixing the overreading issue should also fix the alignment issue. You just need to read from `RWD00`.
<issue_comment>username_2: * Assuming you are specifying the constant should be 16-byte aligned when being emitted, there is an option for this (`emitAnyCns` takes a `cnsAlign` parameter that is respected).
<issue_comment>username_0: @username_2 thank you for the explanation!
not sure my fix for it looks good but at least it works now
<issue_comment>username_0: @username_2 here is the current codegen:
Double:
```csharp
static double Test(double xmm0, double xmm1) => -xmm1;
```
```asm
; VEX
C5F877 vzeroupper
C5F0570505000000 vxorps xmm0, xmm1, qword ptr [reloc @RWD00]
C3 ret
RWD00 dq 8000000000000000h
RWD08 dq 8000000000000000h
; legacy
0F28C1 movaps xmm0, xmm1
0F570516000000 xorps xmm0, qword ptr [reloc @RWD16]
C3 ret
RWD00 db 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h
RWD16 dq 8000000000000000h
RWD24 dq 8000000000000000h
```
Float:
```csharp
static float Test(float xmm0, float xmm1) => -xmm1;
```
```asm
; VEX
C5F877 vzeroupper
C5F0570505000000 vxorps xmm0, xmm1, dword ptr [reloc @RWD00]
C3 ret
RWD00 dd 80000000h
RWD04 dd 80000000h
RWD08 dd 80000000h
RWD12 dd 80000000h
; legacy
0F28C1 movaps xmm0, xmm1
0F570516000000 xorps xmm0, dword ptr [reloc @RWD16]
C3 ret
RWD00 db 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 000h
RWD16 dd 80000000h
RWD20 dd 80000000h
RWD24 dd 80000000h
RWD28 dd 80000000h
```
<issue_comment>username_2: 👍, that looks correct now. However, I'm unsure why there are 16-bytes of padding before the constant. It looks like it should just be able to start at `RWD00` (with that being properly aligned).
<issue_comment>username_0: @username_2 Fixed! as a bonus it fixes redundant paddings everywhere, e.g:
```csharp
static double Test(double x) => x * 10 * 10;
```
```asm
C5F877 vzeroupper
C5FB590515000000 vmulsd xmm0, xmm0, qword ptr [reloc @RWD08]
C5FB59051D000000 vmulsd xmm0, xmm0, qword ptr [reloc @RWD24]
C3 ret
RWD00 dq 0000000000000000h
RWD08 dq 4024000000000000h
RWD16 dq 0000000000000000h
RWD24 dq 4024000000000000h
```
to this:
```asm
C5F877 vzeroupper
C5FB59050D000000 vmulsd xmm0, xmm0, qword ptr [reloc @RWD00]
C5FB59050D000000 vmulsd xmm0, xmm0, qword ptr [reloc @RWD08]
C3 ret
RWD00 dq 4024000000000000h
RWD08 dq 4028000000000000h
```
<issue_comment>username_0: @dotnet/jit-contrib @username_2 PTAL, it's ready for final review
Summary:
This PR cleans up `genSSE2BitwiseOp` and it now emits 3-operands versions (VEX) of xorps/andps instead of movsd+xorps
Also, it fixes alignment for `emitter::emitDataGenBeg`, it used to emit paddings even if offset is already aligned or zero.
(my System.Private.Corelib.dll(R2R) is now 4kb less in size, jit-diff doesn't take data section into account)
A sample to cover both problems this PR fixes:
```csharp
double Test(double x, double y) => -x * 10 * 5;
```
Current asm:
```asm
C5F877 vzeroupper
C5FB100525000000 vmovsd xmm0, qword ptr [reloc @RWD08]
C5F857C1 vxorps xmm0, xmm1
C5FB590529000000 vmulsd xmm0, xmm0, qword ptr [reloc @RWD24]
C5FB590531000000 vmulsd xmm0, xmm0, qword ptr [reloc @RWD40]
C3 ret
RWD00 dq 0000000000000000h <-- redundant padding
RWD08 dq 8000000000000000h
RWD16 dq 0000000000000000h <-- redundant padding
RWD24 dq 4024000000000000h
RWD32 dq 0000000000000000h <-- redundant padding
RWD40 dq 4014000000000000h
```
New asm:
```asm
G_M60258_IG01:
C5F877 vzeroupper
G_M60258_IG02:
C5F0570515000000 vxorps xmm0, xmm1, qword ptr [reloc @RWD00]
C5FB59051D000000 vmulsd xmm0, xmm0, qword ptr [reloc @RWD16]
C5FB59051D000000 vmulsd xmm0, xmm0, qword ptr [reloc @RWD24]
G_M60258_IG03:
C3 ret
RWD00 db 000h, 000h, 000h, 000h, 000h, 000h, 000h, 080h, 000h, 000h, 000h, 000h, 000h, 000h, 000h, 080h
RWD16 dq 4024000000000000h
RWD24 dq 4014000000000000h
```
`RWD00` is a 16bytes pack of masks for xor | {'fraction_non_alphanumeric': 0.09657479456039561, 'fraction_numerical': 0.10319249509126609, 'mean_word_length': 2.8531801625105073, 'pattern_counts': {'":': 0, '<': 31, '<?xml version=': 0, '>': 36, 'https://': 4, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 31, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '12589331', 'n_tokens_mistral': 5942, 'n_tokens_neox': 4837, 'n_words': 1378} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Use Null Coalesce Operator
username_0: Following #1420
<issue_comment>username_1: ok LGTM!
<issue_comment>username_2: @username_1 Minor comment: squash / merge or whatever it's called in the future to not have the merge commit in the history: https://github.com/username_2/Elastica/commits/master
<issue_comment>username_1: @username_2 my first merge... my first mistake... it looks like it was already rebased... I will be more careful next time. sorry.
<issue_comment>username_2: @username_1 Nothing wrong happened here, it's only clicking a different button and personal preferences. Default on Github is with the merge commit. I normally use squash merge as I assume 1 PR = 1 commit in the end. | {'fraction_non_alphanumeric': 0.07094133697135062, 'fraction_numerical': 0.020463847203274217, 'mean_word_length': 5.168067226890757, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '28767638', 'n_tokens_mistral': 205, 'n_tokens_neox': 195, 'n_words': 95} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: math: add Tau in constants
username_0: The constant is based on [the corresponding page in the online
encyclopedia of integer sequences](https://oeis.org/A019692), and is also
equal to `math.Pi * 2`.
Usage:
```go
perimeter := math.Tau * radius
```
<issue_comment>username_2: The proposal was rejected (#40663) so I'm closing this PR. | {'fraction_non_alphanumeric': 0.10846560846560846, 'fraction_numerical': 0.037037037037037035, 'mean_word_length': 4.656716417910448, 'pattern_counts': {'":': 0, '<': 3, '<?xml version=': 0, '>': 3, 'https://': 1, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '8445974', 'n_tokens_mistral': 133, 'n_tokens_neox': 116, 'n_words': 45} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: no data.py in scannet module
username_0: hi,
there is no data.py in scannet module. could you help to push that?<issue_closed>
<issue_comment>username_1: Opps, thanks for pointing that out.
<issue_comment>username_0: How to reproduce the result on Scannet dataset? Can you give the parameter details, such as epochs, batch size...? | {'fraction_non_alphanumeric': 0.07629427792915532, 'fraction_numerical': 0.008174386920980926, 'mean_word_length': 5.571428571428571, 'pattern_counts': {'":': 0, '<': 5, '<?xml version=': 0, '>': 5, 'https://': 0, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '13540221', 'n_tokens_mistral': 109, 'n_tokens_neox': 108, 'n_words': 48} |
starcoder-github-issues-filtered-structured | <issue_start><issue_comment>Title: Too generic
username_0: The article is good. However almost the same story is always told. For example, the article does not tell us about a single use-case. Also, the article does not show the difference between Microservices and other web-service approaches. Also,it does not address the learning curve or cost or requirements to adopt this approach.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 9da8bfc3-34f4-4b28-58bc-44db1d5990b9
* Version Independent ID: 8fb2214a-ade9-7cef-4fc8-e6888e5c1fd0
* Content: [Introduction to microservices on Azure](https://docs.microsoft.com/en-us/azure/service-fabric/service-fabric-overview-microservices)
* Content Source: [articles/service-fabric/service-fabric-overview-microservices.md](https://github.com/Microsoft/azure-docs/blob/master/articles/service-fabric/service-fabric-overview-microservices.md)
* Service: **service-fabric**
* GitHub Login: @athinanthny
* Microsoft Alias: **atsenthi**
<issue_comment>username_1: Thanks for the feedback! We are currently investigating and will update you shortly.
<issue_comment>username_1: @username_0 have you looked at any of the other concepts we discuss?

We don't want to make introduction articles too long otherwise they can be hard to read and take in. So some of your questions may be answered in other concept docs.<issue_closed>
<issue_comment>username_0: OK, thanks. | {'fraction_non_alphanumeric': 0.09255784865540963, 'fraction_numerical': 0.04940587867417136, 'mean_word_length': 5.2745098039215685, 'pattern_counts': {'":': 0, '<': 6, '<?xml version=': 0, '>': 6, 'https://': 3, 'lorem ipsum': 0, 'www.': 0, 'xml': 0}, 'pii_count': 0, 'substrings_counts': 0, 'word_list_counts': {'cursed_substrings.json': 0, 'profanity_word_list.json': 0, 'sexual_word_list.json': 0, 'zh_pornsignals.json': 0}} | {'dir': 'github-issues-filtered-structured', 'id': '4299562', 'n_tokens_mistral': 525, 'n_tokens_neox': 468, 'n_words': 159} |