
arnosimons/astro-hep-bert
Fill-Mask
•
Updated
•
11
•
4
image
image |
|---|
Astro-HEP Corpus consists of approximately 21.8 million paragraphs extracted from more than 600,000 scholarly articles related to astrophysics or high energy physics or both. All articles were published between 1986 and 2022 (inclusive) on the open-access archive arXiv.org. Note: Due to copyright uncertainties, I am unable to make the actual data available here.
This table details the main columns of the dataset:
| Column | Description |
|---|---|
| Text | Full text of the paragraph |
| Characters | Number of unicode characters in the paragraph |
| Subwords | Number of BERT subwords in the paragraph |
| arXiv ID | Identifier of the parent article provided by arXiv |
| Year | Year of the first publication of the parent article |
| Month | Month of the first publication of the parent article |
| Day | Day of the first publication of the parent article |
| Position | Position in the sequence of paragraphs in the article |
The primary purpose of the Astro-HEP Corpus, beyond its role as a training set for the for the Astro-HEP-BERT model, lies in its use for analyzing the meaning of concepts in astrophysics and high energy physics. For further insights into the corpus, the model, and the underlying research project (Network Epistemology in Practice) please refer to this paper [link coming soon].
This figure shows the temporal distribution of articles in terms of initial publication year, category (ASTRO or HEP), and subcategory (six subcategories for ASTRO and four subcategories for HEP), all of which is metadata directly imported from arXiv.org:
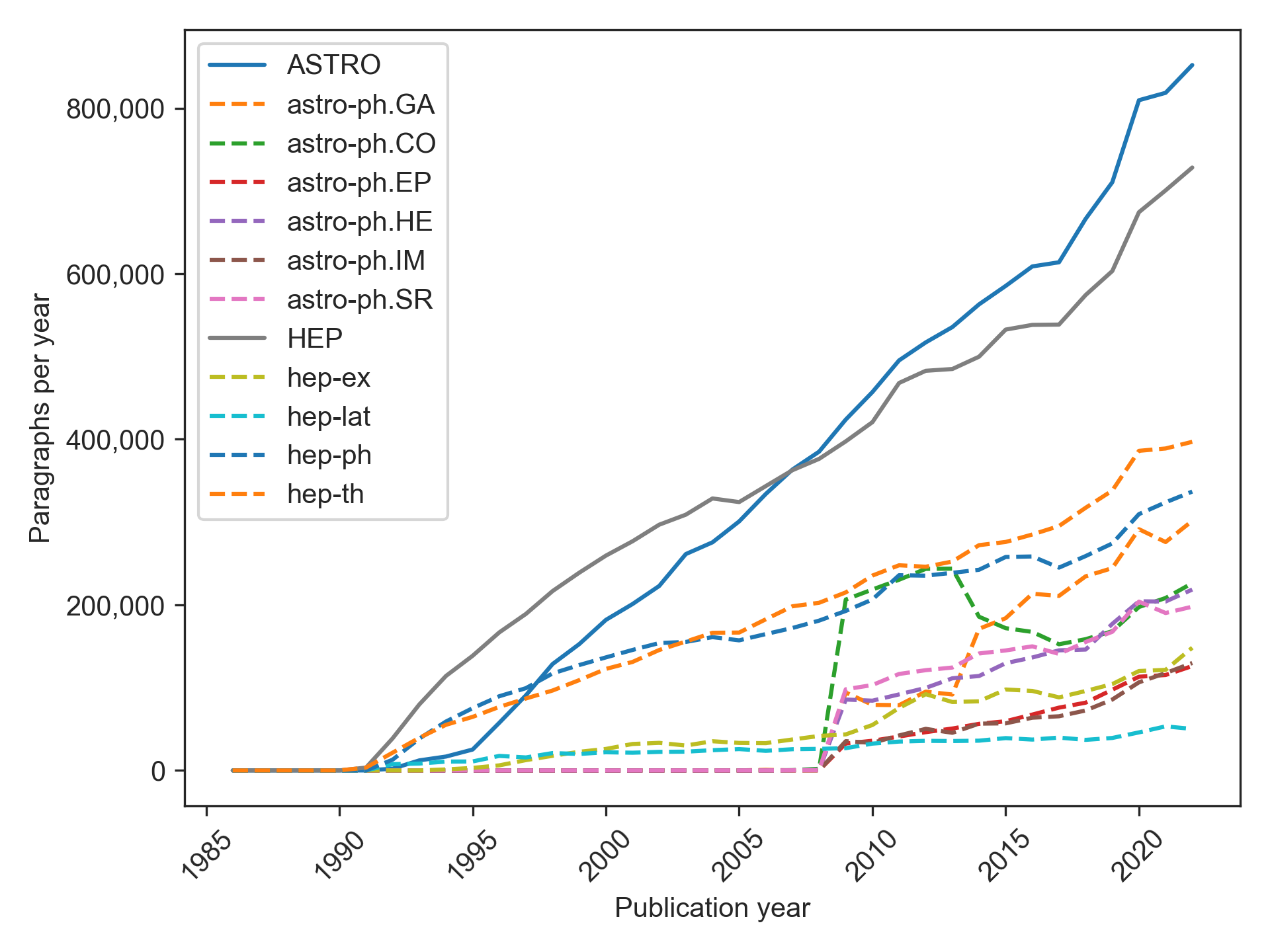
The articles were selected using the original arXiv metadata file and taxonomy, which includes four primary categories for high energy physics (hep-ex, hep-lat, hep-ph, hep-th) and one primary category for astrophysics (astro-ph), the latter of which encompasses six subcategories (astro-ph.CO, astro-ph.EP, astro-ph.GA, astro-ph.HE, astro-ph.IM, and astro-ph.SR). Pandoc was employed to extract plain text from the original LaTeX files sourced from arXiv.org. Furthermore, all in-text citations were replaced with the marker "[CIT]", and all multiline mathematical expressions were replaced with "FORMULA". Inline mathematical expressions (e.g., "$...$") were left unchanged. Parsing the plain text versions of the articles into paragraphs did not require a specialized parser. Due to the LaTeX markup language requirements and the parsing performed by Pandoc, all paragraphs could be parsed by simple newline splitting. Additional cleaning was conducted to remove authorship and funding information as well as noisy paragraphs (see here [link coming soon]).