
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.1B
| node_id
stringlengths 18
32
| number
int64 1
3.58k
| title
stringlengths 1
276
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
sequence | created_at
int64 1,587B
1,642B
| updated_at
int64 1,587B
1,642B
| closed_at
int64 1,587B
1,642B
⌀ | author_association
stringclasses 3
values | active_lock_reason
null | draft
bool 2
classes | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2771 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2771/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2771/comments | https://api.github.com/repos/huggingface/datasets/issues/2771/events | https://github.com/huggingface/datasets/pull/2771 | 963,257,036 | MDExOlB1bGxSZXF1ZXN0NzA1OTExMDMw | 2,771 | [WIP][Common Voice 7] Add common voice 7.0 | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! I think the name `common_voice_7` is fine :)\r\nMoreover if the dataset_infos.json is missing I'm pretty sure you don't need to specify `ignore_verifications=True`",
"Hi, how about to add a new parameter \"version\" in the function load_dataset, something like: \r\n`load_dataset(\"common_voice\", \"lg\", version=\"7.0\") `\r\nThis is to avoid creating a new common_voice_? dataset (with almost the same code) every time \r\nMozilla updates their Common Voice dataset.\r\n"
] | 1,628,352,070,000 | 1,638,833,042,000 | 1,638,833,042,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2771",
"html_url": "https://github.com/huggingface/datasets/pull/2771",
"diff_url": "https://github.com/huggingface/datasets/pull/2771.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2771.patch",
"merged_at": null
} | This PR allows to load the new common voice dataset manually as explained when doing:
```python
from datasets import load_dataset
ds = load_dataset("./datasets/datasets/common_voice_7", "ab")
```
=>
```
Please follow the manual download instructions:
You need to manually the dataset from `https://commonvoice.mozilla.org/en/datasets`.
Make sure you choose the version `Common Voice Corpus 7.0`.
Choose a language of your choice and find the corresponding language-id, *e.g.*, `Abkhaz` with language-id `ab`. The following language-ids are available:
['ab', 'ar', 'as', 'az', 'ba', 'bas', 'be', 'bg', 'br', 'ca', 'cnh', 'cs', 'cv', 'cy', 'de', 'dv', 'el', 'en', 'eo', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'fy-NL', 'ga-IE', 'gl', 'gn', 'ha', 'hi', 'hsb', 'hu', 'hy-AM', 'ia', 'id', 'it', 'ja', 'ka', 'kab', 'kk', 'kmr', 'ky', 'lg', 'lt', 'lv', 'mn', 'mt', 'nl', 'or', 'pa-IN', 'pl', 'pt', 'rm-sursilv', 'rm-vallader', 'ro', 'ru', 'rw', 'sah', 'sk', 'sl', 'sr', 'sv-SE', 'ta', 'th', 'tr', 'tt', 'ug', 'uk', 'ur', 'uz', 'vi', 'vot', 'zh-CN', 'zh-HK', 'zh-TW']
Next, you will have to enter your email address to download the dataset in the `tar.gz` format. Save the file under <path-to-file>.
The file should then be extracted with: ``tar -xvzf <path-to-file>`` which will extract a folder called ``cv-corpus-7.0-2021-07-21``.
The dataset can then be loaded with `datasets.load_dataset("common_voice", <language-id>, data_dir="<path-to-'cv-corpus-7.0-2021-07-21'-folder>", ignore_verifications=True).
```
Having followed those instructions one can then download the data as follows:
```python
from datasets import load_dataset
ds = load_dataset("./datasets/datasets/common_voice_7", "ab", data_dir="./cv-corpus-7.0-2021-07-21/", ignore_verifications=True)
```
## TODO
- [ ] Discuss naming. Is the name ok here "common_voice_7"? The dataset script differs only really in one point from `common_voice.py` in that all the metadata is different (more hours etc...) and that it has to use manual data dir for now
- [ ] Ideally we should get a bundled download link. For `common_voice.py` there is a bundled download link: `https://voice-prod-bundler-ee1969a6ce8178826482b88e843c335139bd3fb4.s3.amazonaws.com/cv-corpus-6.1-2020-12-11/{}.tar.gz` that allows one to directly download the data. However such a link is missing for Common Voice 7. I guess we should try to contact common voice about it and ask whether we could host the data or help otherwise somehow. See: https://github.com/common-voice/common-voice-bundler/issues/15 cc @yjernite
- [ ] I did not compute the dataset.json and it would mean that I'd have to download 76 datasets totalling around 1TB manually before running the checksum command. This just takes too much time. For now the user will have to add a `ignore_verifications=True` to download the data. This step would also be much easier if we could get a bundled link
- [ ] Add dummy data | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2771/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2771/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2770 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2770/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2770/comments | https://api.github.com/repos/huggingface/datasets/issues/2770/events | https://github.com/huggingface/datasets/pull/2770 | 963,246,512 | MDExOlB1bGxSZXF1ZXN0NzA1OTAzMzIy | 2,770 | Add support for fast tokenizer in BertScore | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,628,348,403,000 | 1,628,512,483,000 | 1,628,507,785,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2770",
"html_url": "https://github.com/huggingface/datasets/pull/2770",
"diff_url": "https://github.com/huggingface/datasets/pull/2770.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2770.patch",
"merged_at": 1628507785000
} | This PR adds support for a fast tokenizer in BertScore, which has been added recently to the lib.
Fixes #2765 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2770/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2770/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2769 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2769/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2769/comments | https://api.github.com/repos/huggingface/datasets/issues/2769/events | https://github.com/huggingface/datasets/pull/2769 | 963,240,802 | MDExOlB1bGxSZXF1ZXN0NzA1ODk5MTYy | 2,769 | Allow PyArrow from source | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,628,346,404,000 | 1,628,523,519,000 | 1,628,523,519,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2769",
"html_url": "https://github.com/huggingface/datasets/pull/2769",
"diff_url": "https://github.com/huggingface/datasets/pull/2769.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2769.patch",
"merged_at": 1628523519000
} | When installing pyarrow from source the version is:
```python
>>> import pyarrow; pyarrow.__version__
'2.1.0.dev612'
```
-> however this breaks the install check at init of `datasets`. This PR makes sure that everything coming after the last `'.'` is removed. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2769/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2769/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2768 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2768/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2768/comments | https://api.github.com/repos/huggingface/datasets/issues/2768/events | https://github.com/huggingface/datasets/issues/2768 | 963,229,173 | MDU6SXNzdWU5NjMyMjkxNzM= | 2,768 | `ArrowInvalid: Added column's length must match table's length.` after using `select` | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nthe `select` method creates an indices mapping and doesn't modify the underlying PyArrow table by default for better performance. To modify the underlying table after the `select` call, call `flatten_indices` on the dataset object as follows:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nds = load_dataset(\"tweets_hate_speech_detection\")['train'].select(range(128))\r\nds = ds.flatten_indices()\r\nds = ds.add_column('ones', [1]*128)\r\n```",
"Thanks for the question @lvwerra. And thanks for the answer @mariosasko. ^^"
] | 1,628,342,249,000 | 1,628,508,403,000 | 1,628,508,403,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
I would like to add a column to a downsampled dataset. However I get an error message saying the length don't match with the length of the unsampled dataset indicated. I suspect that the dataset size is not updated when calling `select`.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("tweets_hate_speech_detection")['train'].select(range(128))
ds = ds.add_column('ones', [1]*128)
```
## Expected results
I would expect a new column named `ones` filled with `1`. When I check the length of `ds` it says `128`. Interestingly, it works when calling `ds = ds.map(lambda x: x)` before adding the column.
## Actual results
Specify the actual results or traceback.
```python
---------------------------------------------------------------------------
ArrowInvalid Traceback (most recent call last)
/var/folders/l4/2905jygx4tx5jv8_kn03vxsw0000gn/T/ipykernel_6301/868709636.py in <module>
1 from datasets import load_dataset
2 ds = load_dataset("tweets_hate_speech_detection")['train'].select(range(128))
----> 3 ds = ds.add_column('ones', [0]*128)
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
183 }
184 # apply actual function
--> 185 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
186 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
187 # re-apply format to the output
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
395 # Call actual function
396
--> 397 out = func(self, *args, **kwargs)
398
399 # Update fingerprint of in-place transforms + update in-place history of transforms
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/arrow_dataset.py in add_column(self, name, column, new_fingerprint)
2965 column_table = InMemoryTable.from_pydict({name: column})
2966 # Concatenate tables horizontally
-> 2967 table = ConcatenationTable.from_tables([self._data, column_table], axis=1)
2968 # Update features
2969 info = self.info.copy()
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/table.py in from_tables(cls, tables, axis)
715 table_blocks = to_blocks(table)
716 blocks = _extend_blocks(blocks, table_blocks, axis=axis)
--> 717 return cls.from_blocks(blocks)
718
719 @property
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/table.py in from_blocks(cls, blocks)
663 return cls(table, blocks)
664 else:
--> 665 table = cls._concat_blocks_horizontally_and_vertically(blocks)
666 return cls(table, blocks)
667
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/table.py in _concat_blocks_horizontally_and_vertically(cls, blocks)
623 if not tables:
624 continue
--> 625 pa_table_horizontally_concatenated = cls._concat_blocks(tables, axis=1)
626 pa_tables_to_concat_vertically.append(pa_table_horizontally_concatenated)
627 return cls._concat_blocks(pa_tables_to_concat_vertically, axis=0)
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/table.py in _concat_blocks(blocks, axis)
612 else:
613 for name, col in zip(table.column_names, table.columns):
--> 614 pa_table = pa_table.append_column(name, col)
615 return pa_table
616 else:
~/git/semantic-clustering/env/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.append_column()
~/git/semantic-clustering/env/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.add_column()
~/git/semantic-clustering/env/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
~/git/semantic-clustering/env/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Added column's length must match table's length. Expected length 31962 but got length 128
```
## Environment info
- `datasets` version: 1.11.0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.5
- PyArrow version: 5.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2768/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2768/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2767 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2767/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2767/comments | https://api.github.com/repos/huggingface/datasets/issues/2767/events | https://github.com/huggingface/datasets/issues/2767 | 963,002,120 | MDU6SXNzdWU5NjMwMDIxMjA= | 2,767 | equal operation to perform unbatch for huggingface datasets | {
"login": "dorooddorood606",
"id": 79288051,
"node_id": "MDQ6VXNlcjc5Mjg4MDUx",
"avatar_url": "https://avatars.githubusercontent.com/u/79288051?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dorooddorood606",
"html_url": "https://github.com/dorooddorood606",
"followers_url": "https://api.github.com/users/dorooddorood606/followers",
"following_url": "https://api.github.com/users/dorooddorood606/following{/other_user}",
"gists_url": "https://api.github.com/users/dorooddorood606/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dorooddorood606/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorooddorood606/subscriptions",
"organizations_url": "https://api.github.com/users/dorooddorood606/orgs",
"repos_url": "https://api.github.com/users/dorooddorood606/repos",
"events_url": "https://api.github.com/users/dorooddorood606/events{/privacy}",
"received_events_url": "https://api.github.com/users/dorooddorood606/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi @lhoestq \r\nMaybe this is clearer to explain like this, currently map function, map one example to \"one\" modified one, lets assume we want to map one example to \"multiple\" examples, in which we do not know in advance how many examples they would be per each entry. I greatly appreciate telling me how I can handle this operation, thanks a lot",
"Hi,\r\nthis is also my question on how to perform similar operation as \"unbatch\" in tensorflow in great huggingface dataset library. \r\nthanks.",
"Hi,\r\n\r\n`Dataset.map` in the batched mode allows you to map a single row to multiple rows. So to perform \"unbatch\", you can do the following:\r\n```python\r\nimport collections\r\n\r\ndef unbatch(batch):\r\n new_batch = collections.defaultdict(list)\r\n keys = batch.keys()\r\n for values in zip(*batch.values()):\r\n ex = {k: v for k, v in zip(keys, values)}\r\n inputs = f\"record query: {ex['query']} entities: {', '.join(ex['entities'])} passage: {ex['passage']}\"\r\n new_batch[\"inputs\"].extend([inputs] * len(ex[\"answers\"]))\r\n new_batch[\"targets\"].extend(ex[\"answers\"])\r\n return new_batch\r\n\r\ndset = dset.map(unbatch, batched=True, remove_columns=dset.column_names)\r\n```",
"Dear @mariosasko \r\nFirst, thank you very much for coming back to me on this, I appreciate it a lot. I tried this solution, I am getting errors, do you mind\r\ngiving me one test example to be able to run your code, to understand better the format of the inputs to your function?\r\nin this function https://github.com/google-research/text-to-text-transfer-transformer/blob/3c58859b8fe72c2dbca6a43bc775aa510ba7e706/t5/data/preprocessors.py#L952 they copy each example to the number of \"answers\", do you mean one should not do the copying part and use directly your function? \r\n\r\n\r\nthank you very much for your help and time.",
"Hi @mariosasko \r\nI think finally I got this, I think you mean to do things in one step, here is the full example for completeness:\r\n\r\n```\r\ndef unbatch(batch):\r\n new_batch = collections.defaultdict(list)\r\n keys = batch.keys()\r\n for values in zip(*batch.values()):\r\n ex = {k: v for k, v in zip(keys, values)}\r\n # updates the passage.\r\n passage = ex['passage']\r\n passage = re.sub(r'(\\.|\\?|\\!|\\\"|\\')\\n@highlight\\n', r'\\1 ', passage)\r\n passage = re.sub(r'\\n@highlight\\n', '. ', passage)\r\n inputs = f\"record query: {ex['query']} entities: {', '.join(ex['entities'])} passage: {passage}\"\r\n # duplicates the samples based on number of answers.\r\n num_answers = len(ex[\"answers\"])\r\n num_duplicates = np.maximum(1, num_answers)\r\n new_batch[\"inputs\"].extend([inputs] * num_duplicates) #len(ex[\"answers\"]))\r\n new_batch[\"targets\"].extend(ex[\"answers\"] if num_answers > 0 else [\"<unk>\"])\r\n return new_batch\r\n\r\ndata = datasets.load_dataset('super_glue', 'record', split=\"train\", script_version=\"master\")\r\ndata = data.map(unbatch, batched=True, remove_columns=data.column_names)\r\n```\r\n\r\nThanks a lot again, this was a super great way to do it."
] | 1,628,279,152,000 | 1,628,366,181,000 | null | NONE | null | null | null | Hi
I need to use "unbatch" operation in tensorflow on a huggingface dataset, I could not find this operation, could you kindly direct me how I can do it, here is the problem I am trying to solve:
I am considering "record" dataset in SuperGlue and I need to replicate each entery of the dataset for each answer, to make it similar to what T5 originally did:
https://github.com/google-research/text-to-text-transfer-transformer/blob/3c58859b8fe72c2dbca6a43bc775aa510ba7e706/t5/data/preprocessors.py#L925
Here please find an example:
For example, a typical example from ReCoRD might look like
{
'passsage': 'This is the passage.',
'query': 'A @placeholder is a bird.',
'entities': ['penguin', 'potato', 'pigeon'],
'answers': ['penguin', 'pigeon'],
}
and I need a prosessor which would turn this example into the following two examples:
{
'inputs': 'record query: A @placeholder is a bird. entities: penguin, '
'potato, pigeon passage: This is the passage.',
'targets': 'penguin',
}
and
{
'inputs': 'record query: A @placeholder is a bird. entities: penguin, '
'potato, pigeon passage: This is the passage.',
'targets': 'pigeon',
}
For doing this, one need unbatch, as each entry can map to multiple samples depending on the number of answers, I am not sure how to perform this operation with huggingface datasets library and greatly appreciate your help
@lhoestq
Thank you very much.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2767/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2767/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2766 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2766/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2766/comments | https://api.github.com/repos/huggingface/datasets/issues/2766/events | https://github.com/huggingface/datasets/pull/2766 | 962,994,198 | MDExOlB1bGxSZXF1ZXN0NzA1NzAyNjM5 | 2,766 | fix typo (ShuffingConfig -> ShufflingConfig) | {
"login": "daleevans",
"id": 4944007,
"node_id": "MDQ6VXNlcjQ5NDQwMDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/4944007?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/daleevans",
"html_url": "https://github.com/daleevans",
"followers_url": "https://api.github.com/users/daleevans/followers",
"following_url": "https://api.github.com/users/daleevans/following{/other_user}",
"gists_url": "https://api.github.com/users/daleevans/gists{/gist_id}",
"starred_url": "https://api.github.com/users/daleevans/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/daleevans/subscriptions",
"organizations_url": "https://api.github.com/users/daleevans/orgs",
"repos_url": "https://api.github.com/users/daleevans/repos",
"events_url": "https://api.github.com/users/daleevans/events{/privacy}",
"received_events_url": "https://api.github.com/users/daleevans/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,628,278,300,000 | 1,628,605,023,000 | 1,628,605,022,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2766",
"html_url": "https://github.com/huggingface/datasets/pull/2766",
"diff_url": "https://github.com/huggingface/datasets/pull/2766.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2766.patch",
"merged_at": 1628605022000
} | pretty straightforward, it should be Shuffling instead of Shuffing | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2766/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2766/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2765 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2765/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2765/comments | https://api.github.com/repos/huggingface/datasets/issues/2765/events | https://github.com/huggingface/datasets/issues/2765 | 962,861,395 | MDU6SXNzdWU5NjI4NjEzOTU= | 2,765 | BERTScore Error | {
"login": "gagan3012",
"id": 49101362,
"node_id": "MDQ6VXNlcjQ5MTAxMzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/49101362?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gagan3012",
"html_url": "https://github.com/gagan3012",
"followers_url": "https://api.github.com/users/gagan3012/followers",
"following_url": "https://api.github.com/users/gagan3012/following{/other_user}",
"gists_url": "https://api.github.com/users/gagan3012/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gagan3012/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gagan3012/subscriptions",
"organizations_url": "https://api.github.com/users/gagan3012/orgs",
"repos_url": "https://api.github.com/users/gagan3012/repos",
"events_url": "https://api.github.com/users/gagan3012/events{/privacy}",
"received_events_url": "https://api.github.com/users/gagan3012/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nThe `use_fast_tokenizer` argument has been recently added to the bert-score lib. I've opened a PR with the fix. In the meantime, you can try to downgrade the version of bert-score with the following command to make the code work:\r\n```\r\npip uninstall bert-score\r\npip install \"bert-score<0.3.10\"\r\n```"
] | 1,628,265,537,000 | 1,628,507,785,000 | 1,628,507,785,000 | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
predictions = ["hello there", "general kenobi"]
references = ["hello there", "general kenobi"]
bert = load_metric('bertscore')
bert.compute(predictions=predictions, references=references,lang='en')
```
# Bug
`TypeError: get_hash() missing 1 required positional argument: 'use_fast_tokenizer'`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Colab
- Python version:
- PyArrow version:
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2765/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2765/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2764 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2764/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2764/comments | https://api.github.com/repos/huggingface/datasets/issues/2764/events | https://github.com/huggingface/datasets/pull/2764 | 962,554,799 | MDExOlB1bGxSZXF1ZXN0NzA1MzI3MDQ5 | 2,764 | Add DER metric for SUPERB speaker diarization task | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,628,241,156,000 | 1,628,244,413,000 | null | MEMBER | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2764",
"html_url": "https://github.com/huggingface/datasets/pull/2764",
"diff_url": "https://github.com/huggingface/datasets/pull/2764.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2764.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2764/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2764/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2763 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2763/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2763/comments | https://api.github.com/repos/huggingface/datasets/issues/2763/events | https://github.com/huggingface/datasets/issues/2763 | 961,895,523 | MDU6SXNzdWU5NjE4OTU1MjM= | 2,763 | English wikipedia datasets is not clean | {
"login": "lucadiliello",
"id": 23355969,
"node_id": "MDQ6VXNlcjIzMzU1OTY5",
"avatar_url": "https://avatars.githubusercontent.com/u/23355969?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucadiliello",
"html_url": "https://github.com/lucadiliello",
"followers_url": "https://api.github.com/users/lucadiliello/followers",
"following_url": "https://api.github.com/users/lucadiliello/following{/other_user}",
"gists_url": "https://api.github.com/users/lucadiliello/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lucadiliello/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucadiliello/subscriptions",
"organizations_url": "https://api.github.com/users/lucadiliello/orgs",
"repos_url": "https://api.github.com/users/lucadiliello/repos",
"events_url": "https://api.github.com/users/lucadiliello/events{/privacy}",
"received_events_url": "https://api.github.com/users/lucadiliello/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi ! Certain users might need these data (for training or simply to explore/index the dataset).\r\n\r\nFeel free to implement a map function that gets rid of these paragraphs and process the wikipedia dataset with it before training"
] | 1,628,174,244,000 | 1,629,738,016,000 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
Wikipedia english dumps contain many wikipedia paragraphs like "References", "Category:" and "See Also" that should not be used for training.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
from datasets import load_dataset
w = load_dataset('wikipedia', '20200501.en')
print(w['train'][0]['text'])
```
> 'Yangliuqing () is a market town in Xiqing District, in the western suburbs of Tianjin, People\'s Republic of China. Despite its relatively small size, it has been named since 2006 in the "famous historical and cultural market towns in China".\n\nIt is best known in China for creating nianhua or Yangliuqing nianhua. For more than 400 years, Yangliuqing has in effect specialised in the creation of these woodcuts for the New Year. wood block prints using vivid colourschemes to portray traditional scenes of children\'s games often interwoven with auspiciouse objects.\n\n, it had 27 residential communities () and 25 villages under its administration.\n\nShi Family Grand Courtyard\n\nShi Family Grand Courtyard (Tiānjīn Shí Jiā Dà Yuàn, 天津石家大院) is situated in Yangliuqing Town of Xiqing District, which is the former residence of wealthy merchant Shi Yuanshi - the 4th son of Shi Wancheng, one of the eight great masters in Tianjin. First built in 1875, it covers over 6,000 square meters, including large and small yards and over 200 folk houses, a theater and over 275 rooms that served as apartments and places of business and worship for this powerful family. Shifu Garden, which finished its expansion in October 2003, covers 1,200 square meters, incorporates the elegance of imperial garden and delicacy of south garden. Now the courtyard of Shi family covers about 10,000 square meters, which is called the first mansion in North China. Now it serves as the folk custom museum in Yangliuqing, which has a large collection of folk custom museum in Yanliuqing, which has a large collection of folk art pieces like Yanliuqing New Year pictures, brick sculpture.\n\nShi\'s ancestor came from Dong\'e County in Shandong Province, engaged in water transport of grain. As the wealth gradually accumulated, the Shi Family moved to Yangliuqing and bought large tracts of land and set up their residence. Shi Yuanshi came from the fourth generation of the family, who was a successful businessman and a good household manager, and the residence was thus enlarged for several times until it acquired the present scale. It is believed to be the first mansion in the west of Tianjin.\n\nThe residence is symmetric based on the axis formed by a passageway in the middle, on which there are four archways. On the east side of the courtyard, there are traditional single-story houses with rows of rooms around the four sides, which was once the living area for the Shi Family. The rooms on north side were the accountants\' office. On the west are the major constructions including the family hall for worshipping Buddha, theater and the south reception room. On both sides of the residence are side yard rooms for maids and servants.\n\nToday, the Shi mansion, located in the township of Yangliuqing to the west of central Tianjin, stands as a surprisingly well-preserved monument to China\'s pre-revolution mercantile spirit. It also serves as an on-location shoot for many of China\'s popular historical dramas. Many of the rooms feature period furniture, paintings and calligraphy, and the extensive Shifu Garden.\n\nPart of the complex has been turned into the Yangliuqing Museum, which includes displays focused on symbolic aspects of the courtyards\' construction, local folk art and customs, and traditional period furnishings and crafts.\n\n**See also \n\nList of township-level divisions of Tianjin\n\nReferences \n\n http://arts.cultural-china.com/en/65Arts4795.html\n\nCategory:Towns in Tianjin'**
## Expected results
I expect no junk in the data.
## Actual results
Specify the actual results or traceback.
## Environment info
- `datasets` version: 1.10.2
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.5
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2763/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2763/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2762 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2762/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2762/comments | https://api.github.com/repos/huggingface/datasets/issues/2762/events | https://github.com/huggingface/datasets/issues/2762 | 961,652,046 | MDU6SXNzdWU5NjE2NTIwNDY= | 2,762 | Add RVL-CDIP dataset | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608941089,
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision",
"name": "vision",
"color": "bfdadc",
"default": false,
"description": "Vision datasets"
}
] | open | false | null | [] | null | [
"cc @nateraw "
] | 1,628,157,425,000 | 1,638,965,146,000 | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** RVL-CDIP
- **Description:** The RVL-CDIP (Ryerson Vision Lab Complex Document Information Processing) dataset consists of 400,000 grayscale images in 16 classes, with 25,000 images per class. There are 320,000 training images, 40,000 validation images, and 40,000 test images. The images are sized so their largest dimension does not exceed 1000 pixels.
- **Paper:** https://www.cs.cmu.edu/~aharley/icdar15/
- **Data:** https://www.cs.cmu.edu/~aharley/rvl-cdip/
- **Motivation:** I'm currently adding LayoutLMv2 and LayoutXLM to HuggingFace Transformers. LayoutLM (v1) already exists in the library. This dataset has a large value for document image classification (i.e. classifying scanned documents). LayoutLM models obtain SOTA on this dataset, so would be great to directly use it in notebooks.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2762/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2762/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2761 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2761/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2761/comments | https://api.github.com/repos/huggingface/datasets/issues/2761/events | https://github.com/huggingface/datasets/issues/2761 | 961,568,287 | MDU6SXNzdWU5NjE1NjgyODc= | 2,761 | Error loading C4 realnewslike dataset | {
"login": "danshirron",
"id": 32061512,
"node_id": "MDQ6VXNlcjMyMDYxNTEy",
"avatar_url": "https://avatars.githubusercontent.com/u/32061512?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danshirron",
"html_url": "https://github.com/danshirron",
"followers_url": "https://api.github.com/users/danshirron/followers",
"following_url": "https://api.github.com/users/danshirron/following{/other_user}",
"gists_url": "https://api.github.com/users/danshirron/gists{/gist_id}",
"starred_url": "https://api.github.com/users/danshirron/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danshirron/subscriptions",
"organizations_url": "https://api.github.com/users/danshirron/orgs",
"repos_url": "https://api.github.com/users/danshirron/repos",
"events_url": "https://api.github.com/users/danshirron/events{/privacy}",
"received_events_url": "https://api.github.com/users/danshirron/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @danshirron, \r\n`c4` was updated few days back by @lhoestq. The new configs are `['en', 'en.noclean', 'en.realnewslike', 'en.webtextlike'].` You'll need to remove any older version of this dataset you previously downloaded and then run `load_dataset` again with new configuration.",
"@bhavitvyamalik @lhoestq , just tried the above and got:\r\n>>> a=datasets.load_dataset('c4','en.realnewslike')\r\nDownloading: 3.29kB [00:00, 1.66MB/s] \r\nDownloading: 2.40MB [00:00, 12.6MB/s] \r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/dshirron/.local/lib/python3.8/site-packages/datasets/load.py\", line 819, in load_dataset\r\n builder_instance = load_dataset_builder(\r\n File \"/home/dshirron/.local/lib/python3.8/site-packages/datasets/load.py\", line 701, in load_dataset_builder\r\n builder_instance: DatasetBuilder = builder_cls(\r\n File \"/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py\", line 1049, in __init__\r\n super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)\r\n File \"/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py\", line 268, in __init__\r\n self.config, self.config_id = self._create_builder_config(\r\n File \"/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py\", line 360, in _create_builder_config\r\n raise ValueError(\r\nValueError: BuilderConfig en.realnewslike not found. Available: ['en', 'realnewslike', 'en.noblocklist', 'en.noclean']\r\n>>> \r\n\r\ndatasets version is 1.11.0\r\n",
"I think I had an older version of datasets installed and that's why I commented the old configurations in my last comment, my bad! I re-checked and updated it to latest version (`datasets==1.11.0`) and it's showing `available configs: ['en', 'realnewslike', 'en.noblocklist', 'en.noclean']`. \r\n\r\nI tried `raw_datasets = load_dataset('c4', 'realnewslike')` and the download started. Make sure you don't have any old copy of this dataset and you download it fresh using the latest version of datasets. Sorry for the mix up!",
"It works. I probably had some issue with the cache. after cleaning it im able to download the dataset. Thanks"
] | 1,628,151,418,000 | 1,628,451,874,000 | 1,628,451,874,000 | NONE | null | null | null | ## Describe the bug
Error loading C4 realnewslike dataset. Validation part mismatch
## Steps to reproduce the bug
```python
raw_datasets = load_dataset('c4', 'realnewslike', cache_dir=model_args.cache_dir)
## Expected results
success on data loading
## Actual results
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 15.3M/15.3M [00:00<00:00, 28.1MB/s]Traceback (most recent call last):
File "run_mlm_tf.py", line 794, in <module>
main()
File "run_mlm_tf.py", line 425, in main
raw_datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir) File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/load.py", line 843, in load_dataset
builder_instance.download_and_prepare(
File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py", line 608, in download_and_prepare
self._download_and_prepare(
File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py", line 698, in _download_and_prepare verify_splits(self.info.splits, split_dict) File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 74, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='validation', num_bytes=38165657946, num_examples=13799838, dataset_name='c4'), 'recorded': SplitInfo(name='validation', num_bytes=37875873, num_examples=13863, dataset_name='c4')}]
## Environment info
- `datasets` version: 1.10.2
- Platform: Linux-5.4.0-58-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 4.0.1 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2761/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2761/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2760 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2760/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2760/comments | https://api.github.com/repos/huggingface/datasets/issues/2760/events | https://github.com/huggingface/datasets/issues/2760 | 961,372,667 | MDU6SXNzdWU5NjEzNzI2Njc= | 2,760 | Add Nuswide dataset | {
"login": "shivangibithel",
"id": 19774925,
"node_id": "MDQ6VXNlcjE5Nzc0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/19774925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shivangibithel",
"html_url": "https://github.com/shivangibithel",
"followers_url": "https://api.github.com/users/shivangibithel/followers",
"following_url": "https://api.github.com/users/shivangibithel/following{/other_user}",
"gists_url": "https://api.github.com/users/shivangibithel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shivangibithel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shivangibithel/subscriptions",
"organizations_url": "https://api.github.com/users/shivangibithel/orgs",
"repos_url": "https://api.github.com/users/shivangibithel/repos",
"events_url": "https://api.github.com/users/shivangibithel/events{/privacy}",
"received_events_url": "https://api.github.com/users/shivangibithel/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608941089,
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision",
"name": "vision",
"color": "bfdadc",
"default": false,
"description": "Vision datasets"
}
] | open | false | null | [] | null | [] | 1,628,132,441,000 | 1,638,965,183,000 | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** *NUSWIDE*
- **Description:** *[A Real-World Web Image Dataset from National University of Singapore](https://lms.comp.nus.edu.sg/wp-content/uploads/2019/research/nuswide/NUS-WIDE.html)*
- **Paper:** *[here](https://lms.comp.nus.edu.sg/wp-content/uploads/2019/research/nuswide/nuswide-civr2009.pdf)*
- **Data:** *[here](https://github.com/wenting-zhao/nuswide)*
- **Motivation:** *This dataset is a benchmark in the Text Retrieval task.*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2760/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2760/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2759 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2759/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2759/comments | https://api.github.com/repos/huggingface/datasets/issues/2759/events | https://github.com/huggingface/datasets/issues/2759 | 960,636,572 | MDU6SXNzdWU5NjA2MzY1NzI= | 2,759 | the meteor metric seems not consist with the official version | {
"login": "jianguda",
"id": 9079360,
"node_id": "MDQ6VXNlcjkwNzkzNjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/9079360?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jianguda",
"html_url": "https://github.com/jianguda",
"followers_url": "https://api.github.com/users/jianguda/followers",
"following_url": "https://api.github.com/users/jianguda/following{/other_user}",
"gists_url": "https://api.github.com/users/jianguda/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jianguda/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jianguda/subscriptions",
"organizations_url": "https://api.github.com/users/jianguda/orgs",
"repos_url": "https://api.github.com/users/jianguda/repos",
"events_url": "https://api.github.com/users/jianguda/events{/privacy}",
"received_events_url": "https://api.github.com/users/jianguda/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"the issue is caused by the differences between varied meteor versions:\r\nmeteor1.0 is for https://aclanthology.org/W07-0734.pdf\r\nmeteor1.5 is for https://aclanthology.org/W14-3348.pdf\r\n\r\nhere is a very similar issue in NLTK\r\nhttps://github.com/nltk/nltk/issues/2655",
"Hi @jianguda, thanks for reporting.\r\n\r\nCurrently, at 🤗 `datasets` we are using METEOR 1.0 (indeed using NLTK: `from nltk.translate import meteor_score`): See the [citation here](https://github.com/huggingface/datasets/blob/master/metrics/meteor/meteor.py#L23-L35).\r\n\r\nIf there is some open source implementation of METEOR 1.5, that could be an interesting contribution! 😉 "
] | 1,628,091,197,000 | 1,628,097,534,000 | null | NONE | null | null | null | ## Describe the bug
The computed meteor score seems strange because the value is very different from the scores computed by other tools. For example, I use the meteor score computed by [NLGeval](https://github.com/Maluuba/nlg-eval) as the reference (which reuses the official jar file for the computation)
## Steps to reproduce the bug
```python
from datasets import load_metric
from nlgeval import NLGEval, compute_individual_metrics
meteor = load_metric('meteor')
predictions = ["It is a guide to action which ensures that the military always obeys the commands of the party"]
references = ["It is a guide to action that ensures that the military will forever heed Party commands"]
results = meteor.compute(predictions=predictions, references=references)
# print the actual result
print(round(results["meteor"], 4))
metrics_dict = compute_individual_metrics(references, predictions[0])
# print the expected result
print(round(metrics_dict["METEOR"], 4))
```
By the way, you need to install the `nlg-eval` library first. Please check the installation guide [here](https://github.com/Maluuba/nlg-eval#setup), thanks!
## Expected results
`0.4474`
## Actual results
`0.7398`
## Environment info
- `datasets` version: 1.10.2
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.5
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2759/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2759/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2758 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2758/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2758/comments | https://api.github.com/repos/huggingface/datasets/issues/2758/events | https://github.com/huggingface/datasets/pull/2758 | 960,206,575 | MDExOlB1bGxSZXF1ZXN0NzAzMjQ5Nzky | 2,758 | Raise ManualDownloadError when loading a dataset that requires previous manual download | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,628,072,395,000 | 1,628,076,990,000 | 1,628,076,990,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2758",
"html_url": "https://github.com/huggingface/datasets/pull/2758",
"diff_url": "https://github.com/huggingface/datasets/pull/2758.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2758.patch",
"merged_at": 1628076990000
} | This PR implements the raising of a `ManualDownloadError` when loading a dataset that requires previous manual download, and this is missing.
The `ManualDownloadError` is raised whether the dataset is loaded in normal or streaming mode.
Close #2749.
cc: @severo | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2758/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2758/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2757 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2757/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2757/comments | https://api.github.com/repos/huggingface/datasets/issues/2757/events | https://github.com/huggingface/datasets/issues/2757 | 959,984,081 | MDU6SXNzdWU5NTk5ODQwODE= | 2,757 | Unexpected type after `concatenate_datasets` | {
"login": "JulesBelveze",
"id": 32683010,
"node_id": "MDQ6VXNlcjMyNjgzMDEw",
"avatar_url": "https://avatars.githubusercontent.com/u/32683010?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JulesBelveze",
"html_url": "https://github.com/JulesBelveze",
"followers_url": "https://api.github.com/users/JulesBelveze/followers",
"following_url": "https://api.github.com/users/JulesBelveze/following{/other_user}",
"gists_url": "https://api.github.com/users/JulesBelveze/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JulesBelveze/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JulesBelveze/subscriptions",
"organizations_url": "https://api.github.com/users/JulesBelveze/orgs",
"repos_url": "https://api.github.com/users/JulesBelveze/repos",
"events_url": "https://api.github.com/users/JulesBelveze/events{/privacy}",
"received_events_url": "https://api.github.com/users/JulesBelveze/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @JulesBelveze, thanks for your question.\r\n\r\nNote that 🤗 `datasets` internally store their data in Apache Arrow format.\r\n\r\nHowever, when accessing dataset columns, by default they are returned as native Python objects (lists in this case).\r\n\r\nIf you would like their columns to be returned in a more suitable format for your use case (torch arrays), you can use the method `set_format()`:\r\n```python\r\nconcat_dataset.set_format(type=\"torch\")\r\n```\r\n\r\nYou have detailed information in our docs:\r\n- [Using a Dataset with PyTorch/Tensorflow](https://huggingface.co/docs/datasets/torch_tensorflow.html)\r\n- [Dataset.set_format()](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.set_format)",
"Thanks @albertvillanova it indeed did the job 😃 \r\nThanks for your answer!"
] | 1,628,061,039,000 | 1,628,092,884,000 | 1,628,092,883,000 | NONE | null | null | null | ## Describe the bug
I am trying to concatenate two `Dataset` using `concatenate_datasets` but it turns out that after concatenation the features are casted from `torch.Tensor` to `list`.
It then leads to a weird tensors when trying to convert it to a `DataLoader`. However, if I use each `Dataset` separately everything behave as expected.
## Steps to reproduce the bug
```python
>>> featurized_teacher
Dataset({
features: ['t_labels', 't_input_ids', 't_token_type_ids', 't_attention_mask'],
num_rows: 502
})
>>> for f in featurized_teacher.features:
print(featurized_teacher[f].shape)
torch.Size([502])
torch.Size([502, 300])
torch.Size([502, 300])
torch.Size([502, 300])
>>> featurized_student
Dataset({
features: ['s_features', 's_labels'],
num_rows: 502
})
>>> for f in featurized_student.features:
print(featurized_student[f].shape)
torch.Size([502, 64])
torch.Size([502])
```
The shapes seem alright to me. Then the results after concatenation are as follow:
```python
>>> concat_dataset = datasets.concatenate_datasets([featurized_student, featurized_teacher], axis=1)
>>> type(concat_dataset["t_labels"])
<class 'list'>
```
One would expect to obtain the same type as the one before concatenation.
Am I doing something wrong here? Any idea on how to fix this unexpected behavior?
## Environment info
- `datasets` version: 1.9.0
- Platform: macOS-10.14.6-x86_64-i386-64bit
- Python version: 3.9.5
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2757/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2757/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2756 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2756/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2756/comments | https://api.github.com/repos/huggingface/datasets/issues/2756/events | https://github.com/huggingface/datasets/pull/2756 | 959,255,646 | MDExOlB1bGxSZXF1ZXN0NzAyMzk4Mjk1 | 2,756 | Fix metadata JSON for ubuntu_dialogs_corpus dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,628,005,739,000 | 1,628,070,205,000 | 1,628,070,205,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2756",
"html_url": "https://github.com/huggingface/datasets/pull/2756",
"diff_url": "https://github.com/huggingface/datasets/pull/2756.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2756.patch",
"merged_at": 1628070205000
} | Related to #2743. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2756/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2756/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2755 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2755/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2755/comments | https://api.github.com/repos/huggingface/datasets/issues/2755/events | https://github.com/huggingface/datasets/pull/2755 | 959,115,888 | MDExOlB1bGxSZXF1ZXN0NzAyMjgwMjI4 | 2,755 | Fix metadata JSON for turkish_movie_sentiment dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,997,144,000 | 1,628,068,014,000 | 1,628,068,013,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2755",
"html_url": "https://github.com/huggingface/datasets/pull/2755",
"diff_url": "https://github.com/huggingface/datasets/pull/2755.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2755.patch",
"merged_at": 1628068013000
} | Related to #2743. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2755/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2755/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2754 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2754/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2754/comments | https://api.github.com/repos/huggingface/datasets/issues/2754/events | https://github.com/huggingface/datasets/pull/2754 | 959,105,577 | MDExOlB1bGxSZXF1ZXN0NzAyMjcxMjM4 | 2,754 | Generate metadata JSON for telugu_books dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,996,492,000 | 1,628,066,942,000 | 1,628,066,942,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2754",
"html_url": "https://github.com/huggingface/datasets/pull/2754",
"diff_url": "https://github.com/huggingface/datasets/pull/2754.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2754.patch",
"merged_at": 1628066941000
} | Related to #2743. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2754/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2754/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2753 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2753/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2753/comments | https://api.github.com/repos/huggingface/datasets/issues/2753/events | https://github.com/huggingface/datasets/pull/2753 | 959,036,995 | MDExOlB1bGxSZXF1ZXN0NzAyMjEyMjMz | 2,753 | Generate metadata JSON for reclor dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,991,549,000 | 1,628,064,435,000 | 1,628,064,435,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2753",
"html_url": "https://github.com/huggingface/datasets/pull/2753",
"diff_url": "https://github.com/huggingface/datasets/pull/2753.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2753.patch",
"merged_at": 1628064435000
} | Related to #2743. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2753/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2753/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2752 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2752/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2752/comments | https://api.github.com/repos/huggingface/datasets/issues/2752/events | https://github.com/huggingface/datasets/pull/2752 | 959,023,608 | MDExOlB1bGxSZXF1ZXN0NzAyMjAxMjAy | 2,752 | Generate metadata JSON for lm1b dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,990,496,000 | 1,628,059,240,000 | 1,628,059,239,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2752",
"html_url": "https://github.com/huggingface/datasets/pull/2752",
"diff_url": "https://github.com/huggingface/datasets/pull/2752.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2752.patch",
"merged_at": 1628059239000
} | Related to #2743. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2752/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2752/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2751 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2751/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2751/comments | https://api.github.com/repos/huggingface/datasets/issues/2751/events | https://github.com/huggingface/datasets/pull/2751 | 959,021,262 | MDExOlB1bGxSZXF1ZXN0NzAyMTk5MjA5 | 2,751 | Update metadata for wikihow dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,990,317,000 | 1,628,005,929,000 | 1,628,005,929,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2751",
"html_url": "https://github.com/huggingface/datasets/pull/2751",
"diff_url": "https://github.com/huggingface/datasets/pull/2751.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2751.patch",
"merged_at": 1628005929000
} | Update metadata for wikihow dataset:
- Remove leading new line character in description and citation
- Update metadata JSON
- Remove no longer necessary `urls_checksums/checksums.txt` file
Related to #2748. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2751/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2751/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2750 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2750/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2750/comments | https://api.github.com/repos/huggingface/datasets/issues/2750/events | https://github.com/huggingface/datasets/issues/2750 | 958,984,730 | MDU6SXNzdWU5NTg5ODQ3MzA= | 2,750 | Second concatenation of datasets produces errors | {
"login": "Aktsvigun",
"id": 36672861,
"node_id": "MDQ6VXNlcjM2NjcyODYx",
"avatar_url": "https://avatars.githubusercontent.com/u/36672861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Aktsvigun",
"html_url": "https://github.com/Aktsvigun",
"followers_url": "https://api.github.com/users/Aktsvigun/followers",
"following_url": "https://api.github.com/users/Aktsvigun/following{/other_user}",
"gists_url": "https://api.github.com/users/Aktsvigun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Aktsvigun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aktsvigun/subscriptions",
"organizations_url": "https://api.github.com/users/Aktsvigun/orgs",
"repos_url": "https://api.github.com/users/Aktsvigun/repos",
"events_url": "https://api.github.com/users/Aktsvigun/events{/privacy}",
"received_events_url": "https://api.github.com/users/Aktsvigun/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"@albertvillanova ",
"Hi @Aktsvigun, thanks for reporting.\r\n\r\nI'm investigating this.",
"Hi @albertvillanova ,\r\nany update on this? Can I probably help in some way?",
"Hi @Aktsvigun! We are planning to address this issue before our next release, in a couple of weeks at most. 😅 \r\n\r\nIn the meantime, if you would like to contribute, feel free to open a Pull Request. You are welcome. Here you can find more information: [How to contribute to Datasets?](CONTRIBUTING.md)"
] | 1,627,987,624,000 | 1,628,595,727,000 | null | NONE | null | null | null | Hi,
I am need to concatenate my dataset with others several times, and after I concatenate it for the second time, the features of features (e.g. tags names) are collapsed. This hinders, for instance, the usage of tokenize function with `data.map`.
```
from datasets import load_dataset, concatenate_datasets
data = load_dataset('trec')['train']
concatenated = concatenate_datasets([data, data])
concatenated_2 = concatenate_datasets([concatenated, concatenated])
print('True features of features:', concatenated.features)
print('\nProduced features of features:', concatenated_2.features)
```
outputs
```
True features of features: {'label-coarse': ClassLabel(num_classes=6, names=['DESC', 'ENTY', 'ABBR', 'HUM', 'NUM', 'LOC'], names_file=None, id=None), 'label-fine': ClassLabel(num_classes=47, names=['manner', 'cremat', 'animal', 'exp', 'ind', 'gr', 'title', 'def', 'date', 'reason', 'event', 'state', 'desc', 'count', 'other', 'letter', 'religion', 'food', 'country', 'color', 'termeq', 'city', 'body', 'dismed', 'mount', 'money', 'product', 'period', 'substance', 'sport', 'plant', 'techmeth', 'volsize', 'instru', 'abb', 'speed', 'word', 'lang', 'perc', 'code', 'dist', 'temp', 'symbol', 'ord', 'veh', 'weight', 'currency'], names_file=None, id=None), 'text': Value(dtype='string', id=None)}
Produced features of features: {'label-coarse': Value(dtype='int64', id=None), 'label-fine': Value(dtype='int64', id=None), 'text': Value(dtype='string', id=None)}
```
I am using `datasets` v.1.11.0 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2750/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2750/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2749 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2749/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2749/comments | https://api.github.com/repos/huggingface/datasets/issues/2749/events | https://github.com/huggingface/datasets/issues/2749 | 958,968,748 | MDU6SXNzdWU5NTg5Njg3NDg= | 2,749 | Raise a proper exception when trying to stream a dataset that requires to manually download files | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @severo, thanks for reporting.\r\n\r\nAs discussed, datasets requiring manual download should be:\r\n- programmatically identifiable\r\n- properly handled with more clear error message when trying to load them with streaming\r\n\r\nIn relation with programmatically identifiability, note that for datasets requiring manual download, their builder have a property `manual_download_instructions` which is not None:\r\n```python\r\n# Dataset requiring manual download:\r\nbuilder.manual_download_instructions is not None\r\n```",
"Thanks @albertvillanova "
] | 1,627,986,387,000 | 1,628,499,215,000 | 1,628,076,990,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
At least for 'reclor', 'telugu_books', 'turkish_movie_sentiment', 'ubuntu_dialogs_corpus', 'wikihow', trying to `load_dataset` in streaming mode raises a `TypeError` without any detail about why it fails.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("reclor", streaming=True)
```
## Expected results
Ideally: raise a specific exception, something like `ManualDownloadError`.
Or at least give the reason in the message, as when we load in normal mode:
```python
from datasets import load_dataset
dataset = load_dataset("reclor")
```
```
AssertionError: The dataset reclor with config default requires manual data.
Please follow the manual download instructions: to use ReClor you need to download it manually. Please go to its homepage (http://whyu.me/reclor/) fill the google
form and you will receive a download link and a password to extract it.Please extract all files in one folder and use the path folder in datasets.load_dataset('reclor', data_dir='path/to/folder/folder_name')
.
Manual data can be loaded with `datasets.load_dataset(reclor, data_dir='<path/to/manual/data>')
```
## Actual results
```
TypeError: expected str, bytes or os.PathLike object, not NoneType
```
## Environment info
- `datasets` version: 1.11.0
- Platform: macOS-11.5-x86_64-i386-64bit
- Python version: 3.8.11
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2749/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2749/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2748/comments | https://api.github.com/repos/huggingface/datasets/issues/2748/events | https://github.com/huggingface/datasets/pull/2748 | 958,889,041 | MDExOlB1bGxSZXF1ZXN0NzAyMDg4NTk4 | 2,748 | Generate metadata JSON for wikihow dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,980,940,000 | 1,627,985,871,000 | 1,627,985,871,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2748",
"html_url": "https://github.com/huggingface/datasets/pull/2748",
"diff_url": "https://github.com/huggingface/datasets/pull/2748.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2748.patch",
"merged_at": 1627985871000
} | Related to #2743. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2748/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2748/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2747 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2747/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2747/comments | https://api.github.com/repos/huggingface/datasets/issues/2747/events | https://github.com/huggingface/datasets/pull/2747 | 958,867,627 | MDExOlB1bGxSZXF1ZXN0NzAyMDcwOTgy | 2,747 | add multi-proc in `to_json` | {
"login": "bhavitvyamalik",
"id": 19718818,
"node_id": "MDQ6VXNlcjE5NzE4ODE4",
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhavitvyamalik",
"html_url": "https://github.com/bhavitvyamalik",
"followers_url": "https://api.github.com/users/bhavitvyamalik/followers",
"following_url": "https://api.github.com/users/bhavitvyamalik/following{/other_user}",
"gists_url": "https://api.github.com/users/bhavitvyamalik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhavitvyamalik/subscriptions",
"organizations_url": "https://api.github.com/users/bhavitvyamalik/orgs",
"repos_url": "https://api.github.com/users/bhavitvyamalik/repos",
"events_url": "https://api.github.com/users/bhavitvyamalik/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhavitvyamalik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thank you for working on this, @bhavitvyamalik \r\n\r\n10% is not solving the issue, we want 5-10x faster on a machine that has lots of resources, but limited processing time.\r\n\r\nSo let's benchmark it on an instance with many more cores, I can test with 12 on my dev box and 40 on JZ. \r\n\r\nCould you please share the test I could run with both versions?\r\n\r\nShould we also test the sharded version I shared in https://github.com/huggingface/datasets/issues/2663#issue-946552273 so optionally 3 versions to test.",
"Since I was facing `OSError: [Errno 12] Cannot allocate memory` in CircleCI tests, I've added `num_proc` option instead of always using full `cpu_count`. You can test both v1 and v2 through this branch (some redundancy needs to be removed). \r\n\r\nUpdate: I was able to convert into json which took 50% less time as compared to v1 on `ascent_kb` dataset. Will post the benchmarking script with results here.",
"Here are the benchmarks with the current branch for both v1 and v2 (dataset: `ascent_kb`, 8.9M samples):\r\n| batch_size | time (in sec) | time (in sec) |\r\n|------------|---------------|---------------|\r\n| | num_proc = 1 | num_proc = 4 |\r\n| 10k | 185.56 | 170.11 |\r\n| 50k | 175.79 | 86.84 |\r\n| **100k** | 191.09 | **78.35** |\r\n| 125k | 198.28 | 90.89 |\r\n\r\nIncreasing the batch size on my machine helped in making v2 around 50% faster as compared to v1. Timings may vary depending on the machine. I'm including the benchmarking script as well. CircleCI errors are unrelated (something related to `bertscore`)\r\n```\r\nimport time\r\nfrom datasets import load_dataset\r\nimport pathlib\r\nimport os\r\nfrom pathlib import Path\r\nimport shutil\r\nimport gc\r\n\r\nbatch_sizes = [10_000, 50_000, 100_000, 125_000]\r\nnum_procs = [1, 4] # change this according to your machine\r\n\r\nSAVE_LOC = \"./new_dataset.json\"\r\n\r\nfor batch in batch_sizes:\r\n for num in num_procs:\r\n dataset = load_dataset(\"ascent_kb\")\r\n\r\n local_start = time.time()\r\n ans = dataset['train'].to_json(SAVE_LOC, batch_size=batch, num_proc=num)\r\n local_end = time.time() - local_start\r\n\r\n print(f\"Time taken on {num} num_proc and {batch} batch_size: \", local_end)\r\n\r\n # remove that dataset and its contents from cache and newly generated json\r\n new_json = pathlib.Path(SAVE_LOC)\r\n new_json.unlink()\r\n\r\n try:\r\n shutil.rmtree(os.path.join(str(Path.home()), \".cache\", \"huggingface\"))\r\n except OSError as e:\r\n print(\"Error: %s - %s.\" % (e.filename, e.strerror))\r\n\r\n gc.collect()\r\n```\r\nThis will download the dataset in every iteration and run `to_json`. I didn't do multiple iterations here for `to_json` (for a specific batch_size and num_proc) and took average time as I found that v1 got faster after 1st iteration (maybe it's caching somewhere). Since you'll be doing this operation only once, I thought it'll be better to report how both v1 and v2 performed in single iteration only. \r\n\r\nImportant: Benchmarking script will delete the newly generated json and `~/.cache/huggingface/` after every iteration so that it doesn't end up using any cached data (just to be on a safe side)",
"Thank you for sharing the benchmark, @bhavitvyamalik. Your results look promising.\r\n\r\nBut if I remember correctly the sharded version at https://github.com/huggingface/datasets/issues/2663#issue-946552273 was much faster. So we probably should compare to it as well? And if it's faster than at least document that manual sharding version?\r\n\r\n-------\r\n\r\nThat's a dangerous benchmark as it'd wipe out many other HF things. Why not wipe out:\r\n```\r\n~/.cache/huggingface/datasets/ascent_kb/\r\n```\r\n\r\nRunning the benchmark now.",
"Weird, I tried to adapt your benchmark to using shards and the program no longer works. It instead quickly uses up all available RAM and hangs. Has something changed recently in `datasets`? You can try:\r\n\r\n```\r\nimport time\r\nfrom datasets import load_dataset\r\nimport pathlib\r\nimport os\r\nfrom pathlib import Path\r\nimport shutil\r\nimport gc\r\nfrom multiprocessing import cpu_count, Process, Queue\r\n\r\nbatch_sizes = [10_000, 50_000, 100_000, 125_000]\r\nnum_procs = [1, 8] # change this according to your machine\r\n\r\nDATASET_NAME = (\"ascent_kb\")\r\nnum_shards = [1, 8]\r\nfor batch in batch_sizes:\r\n for shards in num_shards:\r\n dataset = load_dataset(DATASET_NAME)[\"train\"]\r\n #print(dataset)\r\n\r\n def process_shard(idx):\r\n print(f\"Sharding {idx}\")\r\n ds_shard = dataset.shard(shards, idx, contiguous=True)\r\n # ds_shard = ds_shard.shuffle() # remove contiguous=True above if shuffling\r\n print(f\"Saving {DATASET_NAME}-{idx}.jsonl\")\r\n ds_shard.to_json(f\"{DATASET_NAME}-{idx}.jsonl\", orient=\"records\", lines=True, force_ascii=False)\r\n\r\n local_start = time.time()\r\n queue = Queue()\r\n processes = [Process(target=process_shard, args=(idx,)) for idx in range(shards)]\r\n for p in processes:\r\n p.start()\r\n\r\n for p in processes:\r\n p.join()\r\n local_end = time.time() - local_start\r\n\r\n print(f\"Time taken on {shards} shards and {batch} batch_size: \", local_end)\r\n```\r\n\r\nJust careful, so that it won't crash your compute environment. As it almost crashed mine.",
"So this part seems to no longer work:\r\n```\r\n dataset = load_dataset(\"ascent_kb\")[\"train\"]\r\n ds_shard = dataset.shard(1, 0, contiguous=True)\r\n ds_shard.to_json(\"ascent_kb-0.jsonl\", orient=\"records\", lines=True, force_ascii=False)\r\n```",
"If you are using `to_json` without any `num_proc`or `num_proc=1` then essentially it'll fall back to v1 only and I've kept it as it is (the tests were passing as well)\r\n\r\n> That's a dangerous benchmark as it'd wipe out many other HF things. Why not wipe out:\r\n\r\nThat's because some dataset related files were still left inside `~/.cache/huggingface/datasets` folder. You can wipe off datasets folder inside your cache maybe\r\n\r\n> dataset = load_dataset(\"ascent_kb\")[\"train\"]\r\n> ds_shard = dataset.shard(1, 0, contiguous=True)\r\n> ds_shard.to_json(\"ascent_kb-0.jsonl\", orient=\"records\", lines=True, force_ascii=False)\r\n\r\nI tried this `lama` dataset (1.3M) and it worked fine. Trying it with `ascent_kb` currently, will update it here.",
"I don't think the issue has anything to do with your work, @bhavitvyamalik. I forgot to mention I tested to see the same problem with the latest datasets release.\r\n\r\nInteresting, I tried your suggestion. This:\r\n```\r\npython -c 'import datasets; ds=\"lama\"; dataset = datasets.load_dataset(ds)[\"train\"]; \\\r\ndataset.shard(1, 0, contiguous=True).to_json(f\"{ds}-0.jsonl\", orient=\"records\", lines=True, force_ascii=False)'\r\n```\r\nworks fine and takes just a few GBs to complete.\r\n\r\nthis on the other hand blows up memory-wise:\r\n```\r\npython -c 'import datasets; ds=\"ascent_kb\"; dataset = datasets.load_dataset(ds)[\"train\"]; \\\r\ndataset.shard(1, 0, contiguous=True).to_json(f\"{ds}-0.jsonl\", orient=\"records\", lines=True, force_ascii=False)'\r\n```\r\nand I have to kill it before it uses up all RAM. (I have 128GB of it, so it should be more than enough)",
"> That's because some dataset related files were still left inside ~/.cache/huggingface/datasets folder. You can wipe off datasets folder inside your cache maybe\r\n\r\nI think recent datasets added a method that will print out the path for all the different components for a given dataset, I can't recall the name though. It was when we were discussing a janitor program to clear up space selectively.",
"> and I have to kill it before it uses up all RAM. (I have 128GB of it, so it should be more than enough)\r\n\r\nSame thing just happened on my machine too. Memory leak somewhere maybe? Even if you were to load this dataset in your memory it shouldn't take more than 4GB. You were earlier doing this for `oscar` dataset. Is it working fine for that?",
"Hmm, looks like `datasets` has changed and won't accept my currently cached oscar-en (crashes), so I'd rather not download 0.5TB again. \r\n\r\nWere you able to reproduce the memory blow up with `ascent_kb`? It's should be a much quicker task to verify.\r\n\r\nBut yes, oscar worked just fine with `.shard()` which is what I used to process it fast.",
"What I tried is:\r\n```\r\nHF_DATASETS_OFFLINE=1 HF_DATASETS_CACHE=cache python -c 'import datasets; ds=\"oscar\"; \\\r\ndataset = datasets.load_dataset(ds, \"unshuffled_deduplicated_en\")[\"train\"]; \\\r\ndataset.shard(1000000, 0, contiguous=True).to_json(f\"{ds}-0.jsonl\", orient=\"records\", lines=True, force_ascii=False)'\r\n```\r\nand got:\r\n```\r\nUsing the latest cached version of the module from /gpfswork/rech/six/commun/modules/datasets_modules/datasets/oscar/e4f06cecc7ae02f7adf85640b4019bf476d44453f251a1d84aebae28b0f8d51d (last modified on Fri Aug 6 01:52:35 2021) since it couldn't be found locally at oscar/oscar.py or remotely (OfflineModeIsEnabled).\r\nReusing dataset oscar (cache/oscar/unshuffled_deduplicated_en/1.0.0/e4f06cecc7ae02f7adf85640b4019bf476d44453f251a1d84aebae28b0f8d51d)\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/load.py\", line 755, in load_dataset\r\n ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/builder.py\", line 737, in as_dataset\r\n datasets = utils.map_nested(\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/utils/py_utils.py\", line 203, in map_nested\r\n mapped = [\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/utils/py_utils.py\", line 204, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True)) for obj in tqdm(iterable, disable=disable_tqdm)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/utils/py_utils.py\", line 142, in _single_map_nested\r\n return function(data_struct)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/builder.py\", line 764, in _build_single_dataset\r\n ds = self._as_dataset(\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/builder.py\", line 834, in _as_dataset\r\n dataset_kwargs = ArrowReader(self._cache_dir, self.info).read(\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/arrow_reader.py\", line 217, in read\r\n return self.read_files(files=files, original_instructions=instructions, in_memory=in_memory)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/arrow_reader.py\", line 238, in read_files\r\n pa_table = self._read_files(files, in_memory=in_memory)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/arrow_reader.py\", line 173, in _read_files\r\n pa_table: Table = self._get_table_from_filename(f_dict, in_memory=in_memory)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/arrow_reader.py\", line 308, in _get_table_from_filename\r\n table = ArrowReader.read_table(filename, in_memory=in_memory)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/arrow_reader.py\", line 327, in read_table\r\n return table_cls.from_file(filename)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/table.py\", line 450, in from_file\r\n table = _memory_mapped_arrow_table_from_file(filename)\r\n File \"/gpfswork/rech/six/commun/conda/stas/lib/python3.8/site-packages/datasets/table.py\", line 43, in _memory_mapped_arrow_table_from_file\r\n memory_mapped_stream = pa.memory_map(filename)\r\n File \"pyarrow/io.pxi\", line 782, in pyarrow.lib.memory_map\r\n File \"pyarrow/io.pxi\", line 743, in pyarrow.lib.MemoryMappedFile._open\r\n File \"pyarrow/error.pxi\", line 122, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 99, in pyarrow.lib.check_status\r\nOSError: Memory mapping file failed: Cannot allocate memory\r\n```",
"> Were you able to reproduce the memory blow up with ascent_kb? It's should be a much quicker task to verify.\r\n\r\nYes, this blows up memory-wise on my machine too. \r\n\r\nI found that a [similar error](https://discuss.huggingface.co/t/saving-memory-with-run-mlm-py-with-wikipedia-datasets/4160) was posted on the forum on 5th March. Since you already knew how much time [#2663 comment](https://github.com/huggingface/datasets/issues/2663#issue-946552273) took, can you try benchmarking v1 and v2 for now maybe until we have a fix for this memory blow up?",
"OK, so I benchmarked using \"lama\" though it's too small for this kind of test, since the sharding is much slower than one thread here.\r\n\r\nResults: https://gist.github.com/stas00/dc1597a1e245c5915cfeefa0eee6902c\r\n\r\nSo sharding does really bad there, and your json over procs is doing great!\r\n\r\nAny suggestions to a somewhat bigger dataset, but not too big? say 10 times of lama?",
"Looks great! I had a few questions/suggestions related to `benchmark-datasets-to_json.py`:\r\n \r\n1. You have used only 10_000 and 100_000 batch size. Including more batch sizes may help you find the perfect batch size for your machine and even give you some extra speed-up. \r\nFor eg, I found `load_dataset(\"cc100\", lang=\"eu\")` with batch size 125_000 took less time as compared to batch size 100_000 (71.16 sec v/s 67.26 sec) since this dataset has 2 fields only `['id', 'text']`, so that's why we can go for higher batch size here. \r\n \r\n2. Why have you used `num_procs` 1 and 4 only? \r\n\r\nYou can use:\r\n1. `dataset = load_dataset(\"cc100\", lang=\"af\")`. Even though it has only 2 fields but there are around 9.9 mil samples. (lama had around 1.3 mil samples)\r\n2. `dataset = load_dataset(\"cc100\", lang=\"eu\")` -> 16 mil samples. (if you want something more than 9.9 mil)\r\n3. `dataset = load_dataset(\"neural_code_search\", 'search_corpus')` -> 4.7 mil samples",
"Thank you, @bhavitvyamalik \r\n\r\nMy apologies, at the moment I have not found time to do more benchmark with the proposed other datasets. I will try to do it later, but I don't want it to hold your PR, it's definitely a great improvement based on the benchmarks I did run! And the comparison to sharded is really just of interest to me to see if it's on par or slower.\r\n\r\nSo if other reviewers are happy, this definitely looks like a great improvement to me and addresses the request I made in the first place.\r\n\r\n> Why have you used num_procs 1 and 4 only?\r\n\r\nOh, no particular reason, I was just comparing to 4 shards on my desktop. Typically it's sufficient to go from 1 to 2-4 to see whether the distributed approach is faster or not. Once hit larger numbers you often run into bottlenecks like IO, and then numbers can be less representative. I hope it makes sense.",
"Tested it with a larger dataset (`srwac`) and memory utilisation remained constant with no swap memory used. @lhoestq should I also add test for the same? Last time I tried this, I got `OSError: [Errno 12] Cannot allocate memory` in CircleCI tests"
] | 1,627,979,413,000 | 1,634,667,861,000 | 1,631,541,397,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2747",
"html_url": "https://github.com/huggingface/datasets/pull/2747",
"diff_url": "https://github.com/huggingface/datasets/pull/2747.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2747.patch",
"merged_at": 1631541397000
} | Closes #2663. I've tried adding multiprocessing in `to_json`. Here's some benchmarking I did to compare the timings of current version (say v1) and multi-proc version (say v2). I did this with `cpu_count` 4 (2015 Macbook Air)
1. Dataset name: `ascent_kb` - 8.9M samples (all samples were used, reporting this for a single run)
v1- ~225 seconds for converting whole dataset to json
v2- ~200 seconds for converting whole dataset to json
2. Dataset name: `lama` - 1.3M samples (all samples were used, reporting this for 2 runs)
v1- ~26 seconds for converting whole dataset to json
v2- ~23.6 seconds for converting whole dataset to json
I think it's safe to say that v2 is 10% faster as compared to v1. Timings may improve further with better configuration.
The only bottleneck I feel is writing to file from the output list. If we can improve that aspect then timings may improve further.
Let me know if any changes/improvements can be done in this @stas00, @lhoestq, @albertvillanova. @lhoestq even suggested to extend this work with other export methods as well like `csv` or `parquet`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2747/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2747/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2746 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2746/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2746/comments | https://api.github.com/repos/huggingface/datasets/issues/2746/events | https://github.com/huggingface/datasets/issues/2746 | 958,551,619 | MDU6SXNzdWU5NTg1NTE2MTk= | 2,746 | Cannot load `few-nerd` dataset | {
"login": "Mehrad0711",
"id": 28717374,
"node_id": "MDQ6VXNlcjI4NzE3Mzc0",
"avatar_url": "https://avatars.githubusercontent.com/u/28717374?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mehrad0711",
"html_url": "https://github.com/Mehrad0711",
"followers_url": "https://api.github.com/users/Mehrad0711/followers",
"following_url": "https://api.github.com/users/Mehrad0711/following{/other_user}",
"gists_url": "https://api.github.com/users/Mehrad0711/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mehrad0711/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mehrad0711/subscriptions",
"organizations_url": "https://api.github.com/users/Mehrad0711/orgs",
"repos_url": "https://api.github.com/users/Mehrad0711/repos",
"events_url": "https://api.github.com/users/Mehrad0711/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mehrad0711/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @Mehrad0711,\r\n\r\nI'm afraid there is no \"canonical\" Hugging Face dataset named \"few-nerd\".\r\n\r\nThere are 2 kinds of datasets hosted at the Hugging Face Hub:\r\n- canonical datasets (their identifier contains no slash \"/\"): we, the Hugging Face team, supervise their implementation and we make sure they work correctly by means of our test suite\r\n- community datasets (their identifier contains a slash \"/\", where before the slash it is the username or the organization name): those datasets are uploaded to the Hub by the community, and we, the Hugging Face team, do not supervise them; it is the responsibility of the user/organization implementing them properly if they want them to be used by other users.\r\n\r\nIn this specific case, there is no \"canonical\" dataset named \"few-nerd\". On the other hand, there are two \"community\" datasets named \"few-nerd\":\r\n- [\"nbroad/few-nerd\"](https://huggingface.co/datasets/nbroad/few-nerd)\r\n- [\"dfki-nlp/few-nerd\"](https://huggingface.co/datasets/dfki-nlp/few-nerd)\r\n\r\nIf they were properly implemented, you should be able to load them this way:\r\n```python\r\n# \"nbroad/few-nerd\" community dataset\r\nds = load_dataset(\"nbroad/few-nerd\", \"supervised\")\r\n\r\n# \"dfki-nlp/few-nerd\" community dataset\r\nds = load_dataset(\"dfki-nlp/few-nerd\", \"supervised\")\r\n```\r\n\r\nHowever, they are not correctly implemented and both of them give errors:\r\n- \"nbroad/few-nerd\":\r\n ```\r\n TypeError: expected str, bytes or os.PathLike object, not dict\r\n ```\r\n- \"dfki-nlp/few-nerd\":\r\n ```\r\n ConnectionError: Couldn't reach https://cloud.tsinghua.edu.cn/f/09265750ae6340429827/?dl=1\r\n ```\r\n\r\nYou could try to contact their users/organizations to inform them about their bugs and ask them if they are planning to fix them. Alternatively you could try to implement your own script for this dataset.",
"Thanks @albertvillanova for your detailed explanation! I will resort to my own scripts for now. ",
"Hello, @Mehrad0711; Hi, @albertvillanova !\r\nI am the maintainer of the `dfki/few-nerd\" dataset script, sorry for the very late reply and hope this message finds you well!\r\nWe should use\r\n```\r\ndataset = load_dataset(\"dfki-nlp/few-nerd\", name=\"supervised\")\r\n```\r\ninstead of not specifying the \"name\" argument, where name is from `[\"supervised\", \"inter\", \"intra\"]`. Otherwise the method just treats \"supervised\" as `split`, which we reserve after specifying the name, since for each name, there are three splits: train, dev and test.\r\n\r\nAlso we use Tsinghua server source to download data files since it is the official source referred in the paper where the dataset is released (even though it is cc-by-sa-4.0 licensed, means we can copy the data anywhere after mentioning the license\r\n). Sometimes the server just runs down due to high pressure, kinda weird (we encountered the same server problem serveral times a month when we conducted experiments on Few-NERD XD). I tried the script just now and it works perfectly!\r\n```\r\n>> dataset\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 131767\r\n })\r\n validation: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 18824\r\n })\r\n test: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 37648\r\n })\r\n})\r\n>>> dataset[\"train\"]\r\nDataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 131767\r\n})\r\n>>> dataset[\"train\"][0]\r\n{'id': '0', 'tokens': ['Paul', 'International', 'airport', '.'], 'ner_tags': [0, 0, 0, 0], 'fine_ner_tags': [0, 0, 0, 0]}\r\n```\r\nAnyways if you cannot stand the pain with the server and its slow download speed, you can also download the `dfki/few-nerd.py` script from HF and change the `_URLs` to your personal drive (after you once successfully download the data and upload to your cloud drive), and then load the .py script locally.\r\n\r\nHope this reply can still be any help. If you still have problems with it, feel free to ask here and I am glad to help!\r\nBest wishes.",
"Hi @chen-yuxuan, thanks for your answer.\r\n\r\nJust a few comments:\r\n\r\n- Please, note that as we use `datasets.load_dataset` implementation, we can pass the configuration name as the second positional argument (no need to pass explicitly `name=`) and it downloads the 3 splits:\r\n```python\r\n In [4]: ds = load_dataset(\"dfki-nlp/few-nerd\", \"supervised\")\r\nDownloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11.5k/11.5k [00:00<00:00, 2.85MB/s]\r\nDownloading and preparing dataset few_nerd/supervised to .cache\\huggingface\\datasets\\dfki-nlp___few_nerd\\supervised\\0.0.0\\e40882b71f037a4a1f232025899170fbe8113cd2f4a26dddd2add7222a077255...\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 14.6M/14.6M [01:16<00:00, 190kB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11.9M/11.9M [01:14<00:00, 160kB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12.0M/12.0M [01:04<00:00, 186kB/s]\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [03:58<00:00, 79.45s/it]\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 3.11it/s]\r\n```\r\n\r\n- On the other hand, please note that your script does not work on Windows machines, because you call `open()` without passing the encoding parameter:\r\n```\r\n~\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\dfki-nlp___few-nerd\\e40882b71f037a4a1f232025899170fbe8113cd2f4a26dddd2add7222a077255\\few-nerd.py in <genexpr>(.0)\r\n 276 assert filepath[-4:] == \".txt\"\r\n 277\r\n--> 278 num_lines = sum(1 for _ in open(filepath))\r\n 279 id = 0\r\n 280\r\n\r\n.venv\\lib\\encodings\\cp1252.py in decode(self, input, final)\r\n 21 class IncrementalDecoder(codecs.IncrementalDecoder):\r\n 22 def decode(self, input, final=False):\r\n---> 23 return codecs.charmap_decode(input,self.errors,decoding_table)[0]\r\n 24\r\n 25 class StreamWriter(Codec,codecs.StreamWriter):\r\n\r\nUnicodeDecodeError: 'charmap' codec can't decode byte 0x8d in position 5238: character maps to <undefined>\r\n```\r\n\r\nIf you would like your script to be usable on Windows machines, you should pass `encoding=\"utf-8\"` to every `open()` function:\r\n- line 278: `num_lines = sum(1 for _ in open(filepath, encoding=\"utf-8\"))`\r\n- line 281: `with open(filepath, \"r\", encoding=\"utf-8\")`",
"Thank you @albertvillanova for your detailed feedback!\r\n\r\n> no need to pass explicitly `name=`\r\n\r\nGood catch! I thought `split` stands before `name` in the argument list... but now it is all clear to me, sounds cool! Thanks for the explanation.\r\n\r\nAnyways in our old code it still looks bit confusing if we only want one split but the function downloads all, so to allow efficient downloading, I optimized the code a bit so that only the specified split data is downloaded. now we get\r\n```\r\n>>> x = load_dataset(\"dfki-nlp/few-nerd\", \"supervised\")\r\nDownloading and preparing dataset few_nerd/supervised to /home/user/.cache/huggingface/datasets/few_nerd/supervised/0.0.0/8e7ab598946cd5b395dcec6ea239123c8dff5b58b8e1c03b0c595b540248a885...\r\nDownloading: 100%|███████████████████████████████████████████████████████████████████| 14.6M/14.6M [01:01<00:00, 238kB/s]\r\n100%|██████████████████████████████████████████████████████████████████████| 3359329/3359329 [00:12<00:00, 275462.84it/s]\r\n100%|████████████████████████████████████████████████████████████████████████| 482037/482037 [00:01<00:00, 278633.64it/s]\r\n100%|████████████████████████████████████████████████████████████████████████| 958765/958765 [00:03<00:00, 267472.83it/s]\r\nDataset few_nerd downloaded and prepared to /home/user/.cache/huggingface/datasets/few_nerd/supervised/0.0.0/8e7ab598946cd5b395dcec6ea239123c8dff5b58b8e1c03b0c595b540248a885. Subsequent calls will reuse this data.\r\n```\r\nwhere only one progress bar indicates downloading, and the three others just indicate pre-processing for the train, dev, test set.\r\n\r\nFor the encoding issue, I have made corresponding changes for the two lines you pointed out. However, I have no windows machine at hand, I would really appreciate it if you could help test on your end.\r\n\r\nAll the updates are uploaded to HF under `dfki-nlp` account where I am working for. \r\nThank you again for your kind help!\r\n",
"Hi @chen-yuxuan,\r\n\r\nI have tested on Windows and now it works perfectly, after the fixing of the encoding issue:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset(\"dfki-nlp/few-nerd\", \"supervised\")\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11.5k/11.5k [00:00<?, ?B/s]\r\nDownloading and preparing dataset few_nerd/supervised to C:\\Users\\username\\.cache\\huggingface\\datasets\\dfki-nlp___few_nerd\\supervised\\0.0.0\\e1ceeaee82073fea12206e4461c7cfcd67e68c8f3ebeca179bddcacee00c4511...\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3359329/3359329 [00:25<00:00, 129427.23it/s]\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 482037/482037 [00:03<00:00, 134513.66it/s]\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 958765/958765 [00:06<00:00, 143152.35it/s]\r\nDataset few_nerd downloaded and prepared to C:\\Users\\username\\.cache\\huggingface\\datasets\\dfki-nlp___few_nerd\\supervised\\0.0.0\\e1ceeaee82073fea12206e4461c7cfcd67e68c8f3ebeca179bddcacee00c4511. Subsequent calls will reuse this data.765 [00:06<00:00, 139045.03it/s]\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 174.71it/s]\r\n\r\nIn [3]: ds\r\nOut[3]:\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 131767\r\n })\r\n validation: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 18824\r\n })\r\n test: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 37648\r\n })\r\n})\r\n```"
] | 1,627,942,737,000 | 1,637,052,694,000 | 1,628,019,943,000 | NONE | null | null | null | ## Describe the bug
Cannot load `few-nerd` dataset.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset('few-nerd', 'supervised')
```
## Actual results
Executing above code will give the following error:
```
Using the latest cached version of the module from /Users/Mehrad/.cache/huggingface/modules/datasets_modules/datasets/few-nerd/62464ace912a40a0f33a11a8310f9041c9dc3590ff2b3c77c14d83ca53cfec53 (last modified on Wed Jun 2 11:34:25 2021) since it couldn't be found locally at /Users/Mehrad/Documents/GitHub/genienlp/few-nerd/few-nerd.py, or remotely (FileNotFoundError).
Downloading and preparing dataset few_nerd/supervised (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /Users/Mehrad/.cache/huggingface/datasets/few_nerd/supervised/0.0.0/62464ace912a40a0f33a11a8310f9041c9dc3590ff2b3c77c14d83ca53cfec53...
Traceback (most recent call last):
File "/Users/Mehrad/opt/anaconda3/lib/python3.7/site-packages/datasets/builder.py", line 693, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/Mehrad/opt/anaconda3/lib/python3.7/site-packages/datasets/builder.py", line 1107, in _prepare_split
disable=bool(logging.get_verbosity() == logging.NOTSET),
File "/Users/Mehrad/opt/anaconda3/lib/python3.7/site-packages/tqdm/std.py", line 1133, in __iter__
for obj in iterable:
File "/Users/Mehrad/.cache/huggingface/modules/datasets_modules/datasets/few-nerd/62464ace912a40a0f33a11a8310f9041c9dc3590ff2b3c77c14d83ca53cfec53/few-nerd.py", line 196, in _generate_examples
with open(filepath, encoding="utf-8") as f:
FileNotFoundError: [Errno 2] No such file or directory: '/Users/Mehrad/.cache/huggingface/datasets/downloads/supervised/train.json'
```
The bug is probably in identifying and downloading the dataset. If I download the json splits directly from [link](https://github.com/nbroad1881/few-nerd/tree/main/uncompressed) and put them under the downloads directory, they will be processed into arrow format correctly.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Python version: 3.8
- PyArrow version: 1.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2746/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2746/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2745 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2745/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2745/comments | https://api.github.com/repos/huggingface/datasets/issues/2745/events | https://github.com/huggingface/datasets/pull/2745 | 958,269,579 | MDExOlB1bGxSZXF1ZXN0NzAxNTc0Mjcz | 2,745 | added semeval18_emotion_classification dataset | {
"login": "maxpel",
"id": 31095360,
"node_id": "MDQ6VXNlcjMxMDk1MzYw",
"avatar_url": "https://avatars.githubusercontent.com/u/31095360?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxpel",
"html_url": "https://github.com/maxpel",
"followers_url": "https://api.github.com/users/maxpel/followers",
"following_url": "https://api.github.com/users/maxpel/following{/other_user}",
"gists_url": "https://api.github.com/users/maxpel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/maxpel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maxpel/subscriptions",
"organizations_url": "https://api.github.com/users/maxpel/orgs",
"repos_url": "https://api.github.com/users/maxpel/repos",
"events_url": "https://api.github.com/users/maxpel/events{/privacy}",
"received_events_url": "https://api.github.com/users/maxpel/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"For training the multilabel classifier, I would combine the labels into a list, for example for the English dataset:\r\n\r\n```\r\ndfpre=pd.read_csv(path+\"2018-E-c-En-train.txt\",sep=\"\\t\")\r\ndfpre['list'] = dfpre[dfpre.columns[2:]].values.tolist()\r\ndf = dfpre[['Tweet', 'list']].copy()\r\ndf.rename(columns={'list': 'labels'}, inplace=True)\r\n```",
"Hi @maxpel , have you had a chance to take my comments into account ?\r\n\r\nLet me know if you have questions or if I can help :)",
"Hi @lhoestq ! I did take your comments into account, changed the naming and tried to add dummy data (manually). I am not sure if the dummy data is correct, maybe you can take a look at that.\r\nThe model card is still missing as I am currently very busy.",
"Thanks ! The dummy data looks all good, good job :)\r\n\r\nThe CI error can be fixed by merging `master` into your branch\r\n```bash\r\ngit fetch upstream\r\ngit merge upstream/master\r\n```",
"Hi! I just added the model card and I did the merge you showed above. Should I then add and commit again? The CI error is still there right now.",
"@lhoestq Unfortunately, I discovered a problem with the test data sets on the competion page (train and dev is fine). They still contain NONE labels for each of the emotions, for example for English: http://saifmohammad.com/WebDocs/AIT-2018/AIT2018-DATA/AIT2018-TEST-DATA/semeval2018englishtestfiles/2018-E-c-En-test.zip\r\nLuckily, a zip file with all data of the competition contains the correct labels also for the test set:\r\nhttp://saifmohammad.com/WebDocs/AIT-2018/AIT2018-DATA/SemEval2018-Task1-all-data.zip\r\nWhat's the best way to correct this?",
"Hi ! I think we can edit the sem_eval_2018_task_1.py file to use this URL instead, and maybe update the `os.path.join` calls to the new paths to the text data in the new ZIP file. Would you like to try to make this work ?"
] | 1,627,918,795,000 | 1,635,499,325,000 | 1,632,217,715,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2745",
"html_url": "https://github.com/huggingface/datasets/pull/2745",
"diff_url": "https://github.com/huggingface/datasets/pull/2745.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2745.patch",
"merged_at": 1632217715000
} | I added the data set of SemEval 2018 Task 1 (Subtask 5) for emotion detection in three languages.
```
datasets-cli test datasets/semeval18_emotion_classification/ --save_infos --all_configs
RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_semeval18_emotion_classification
```
Both commands ran successfully.
I couldn't create the dummy data (the files are tsvs but have .txt ending, maybe that's the problem?) and therefore the test on the dummy data fails, maybe someone can help here.
I also formatted the code:
```
black --line-length 119 --target-version py36 datasets/semeval18_emotion_classification/
isort datasets/semeval18_emotion_classification/
flake8 datasets/semeval18_emotion_classification/
```
That's the publication for reference:
Mohammad, S., Bravo-Marquez, F., Salameh, M., & Kiritchenko, S. (2018). SemEval-2018 task 1: Affect in tweets. Proceedings of the 12th International Workshop on Semantic Evaluation, 1–17. https://doi.org/10.18653/v1/S18-1001 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2745/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2745/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2744 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2744/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2744/comments | https://api.github.com/repos/huggingface/datasets/issues/2744/events | https://github.com/huggingface/datasets/pull/2744 | 958,146,637 | MDExOlB1bGxSZXF1ZXN0NzAxNDY4NDcz | 2,744 | Fix key by recreating metadata JSON for journalists_questions dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,910,873,000 | 1,627,982,734,000 | 1,627,982,733,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2744",
"html_url": "https://github.com/huggingface/datasets/pull/2744",
"diff_url": "https://github.com/huggingface/datasets/pull/2744.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2744.patch",
"merged_at": 1627982733000
} | Close #2743. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2744/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2744/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2743/comments | https://api.github.com/repos/huggingface/datasets/issues/2743/events | https://github.com/huggingface/datasets/issues/2743 | 958,119,251 | MDU6SXNzdWU5NTgxMTkyNTE= | 2,743 | Dataset JSON is incorrect | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"As discussed, the metadata JSON files must be regenerated because the keys were nor properly generated and they will not be read by the builder:\r\n> Indeed there is some problem/bug while reading the datasets_info.json file: there is a mismatch with the config.name keys in the file...\r\nIn the meanwhile, in order to be able to use the datasets_info.json file content, you can create the builder without passing the name :\r\n```\r\nIn [25]: builder = datasets.load_dataset_builder(\"journalists_questions\")\r\nIn [26]: builder.info.splits\r\nOut[26]: {'train': SplitInfo(name='train', num_bytes=342296, num_examples=10077, dataset_name='journalists_questions')}\r\n```\r\n\r\nAfter regenerating the metadata JSON file for this dataset, I get the right key:\r\n```\r\n{\"plain_text\": {\"description\": \"The journalists_questions corpus (\r\n```",
"Thanks!"
] | 1,627,909,286,000 | 1,627,985,217,000 | 1,627,982,733,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
The JSON file generated for https://github.com/huggingface/datasets/blob/573f3d35081cee239d1b962878206e9abe6cde91/datasets/journalists_questions/journalists_questions.py is https://github.com/huggingface/datasets/blob/573f3d35081cee239d1b962878206e9abe6cde91/datasets/journalists_questions/dataset_infos.json.
The only config should be `plain_text`, but the first key in the JSON is `journalists_questions` (the dataset id) instead.
```json
{
"journalists_questions": {
"description": "The journalists_questions corpus (version 1.0) is a collection of 10K human-written Arabic\ntweets manually labeled for question identification over Arabic tweets posted by journalists.\n",
...
```
## Steps to reproduce the bug
Look at the files.
## Expected results
The first key should be `plain_text`:
```json
{
"plain_text": {
"description": "The journalists_questions corpus (version 1.0) is a collection of 10K human-written Arabic\ntweets manually labeled for question identification over Arabic tweets posted by journalists.\n",
...
```
## Actual results
```json
{
"journalists_questions": {
"description": "The journalists_questions corpus (version 1.0) is a collection of 10K human-written Arabic\ntweets manually labeled for question identification over Arabic tweets posted by journalists.\n",
...
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2743/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2743/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2742 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2742/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2742/comments | https://api.github.com/repos/huggingface/datasets/issues/2742/events | https://github.com/huggingface/datasets/issues/2742 | 958,114,064 | MDU6SXNzdWU5NTgxMTQwNjQ= | 2,742 | Improve detection of streamable file types | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"maybe we should rather attempt to download a `Range` from the server and see if it works?"
] | 1,627,908,909,000 | 1,636,737,490,000 | 1,636,737,490,000 | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
```python
from datasets import load_dataset_builder
from datasets.utils.streaming_download_manager import StreamingDownloadManager
builder = load_dataset_builder("journalists_questions", name="plain_text")
builder._split_generators(StreamingDownloadManager(base_path=builder.base_path))
```
raises
```
NotImplementedError: Extraction protocol for file at https://drive.google.com/uc?export=download&id=1CBrh-9OrSpKmPQBxTK_ji6mq6WTN_U9U is not implemented yet
```
But the file at https://drive.google.com/uc?export=download&id=1CBrh-9OrSpKmPQBxTK_ji6mq6WTN_U9U is a text file and it can be streamed:
```bash
curl --header "Range: bytes=0-100" -L https://drive.google.com/uc\?export\=download\&id\=1CBrh-9OrSpKmPQBxTK_ji6mq6WTN_U9U
506938088174940160 yes 1
302221719412830209 yes 1
289761704907268096 yes 1
513820885032378369 yes %
```
Yet, it's wrongly categorized as a file type that cannot be streamed because the test is currently based on 1. the presence of a file extension at the end of the URL (here: no extension), and 2. the inclusion of this extension in a list of supported formats.
**Describe the solution you'd like**
In the case of an URL (instead of a local path), ask for the MIME type, and decide on that value? Note that it would not work in that case, because the value of `content_type` is `text/html; charset=UTF-8`.
**Describe alternatives you've considered**
Add a variable in the dataset script to set the data format by hand.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2742/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2742/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2741/comments | https://api.github.com/repos/huggingface/datasets/issues/2741/events | https://github.com/huggingface/datasets/issues/2741 | 957,979,559 | MDU6SXNzdWU5NTc5Nzk1NTk= | 2,741 | Add Hypersim dataset | {
"login": "osanseviero",
"id": 7246357,
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/osanseviero",
"html_url": "https://github.com/osanseviero",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608941089,
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision",
"name": "vision",
"color": "bfdadc",
"default": false,
"description": "Vision datasets"
}
] | open | false | null | [] | null | [] | 1,627,898,810,000 | 1,638,965,211,000 | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** Hypersim
- **Description:** photorealistic synthetic dataset for holistic indoor scene understanding
- **Paper:** *link to the dataset paper if available*
- **Data:** https://github.com/apple/ml-hypersim
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2741/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2741/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2740 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2740/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2740/comments | https://api.github.com/repos/huggingface/datasets/issues/2740/events | https://github.com/huggingface/datasets/pull/2740 | 957,911,035 | MDExOlB1bGxSZXF1ZXN0NzAxMjY0NTI3 | 2,740 | Update release instructions | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,893,960,000 | 1,627,915,196,000 | 1,627,915,196,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2740",
"html_url": "https://github.com/huggingface/datasets/pull/2740",
"diff_url": "https://github.com/huggingface/datasets/pull/2740.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2740.patch",
"merged_at": 1627915196000
} | Update release instructions. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2740/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2740/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2739 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2739/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2739/comments | https://api.github.com/repos/huggingface/datasets/issues/2739/events | https://github.com/huggingface/datasets/pull/2739 | 957,751,260 | MDExOlB1bGxSZXF1ZXN0NzAxMTI0ODQ3 | 2,739 | Pass tokenize to sacrebleu only if explicitly passed by user | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,880,945,000 | 1,627,964,617,000 | 1,627,964,617,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2739",
"html_url": "https://github.com/huggingface/datasets/pull/2739",
"diff_url": "https://github.com/huggingface/datasets/pull/2739.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2739.patch",
"merged_at": 1627964617000
} | Next `sacrebleu` release (v2.0.0) will remove `sacrebleu.DEFAULT_TOKENIZER`: https://github.com/mjpost/sacrebleu/pull/152/files#diff-2553a315bb1f7e68c9c1b00d56eaeb74f5205aeb3a189bc3e527b122c6078795L17-R15
This PR passes `tokenize` to `sacrebleu` only if explicitly passed by the user, otherwise it will not pass it (and `sacrebleu` will use its default, no matter where it is and how it is called).
Close: #2737. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2739/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2739/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2738/comments | https://api.github.com/repos/huggingface/datasets/issues/2738/events | https://github.com/huggingface/datasets/pull/2738 | 957,517,746 | MDExOlB1bGxSZXF1ZXN0NzAwOTI5NzA4 | 2,738 | Sunbird AI Ugandan low resource language dataset | {
"login": "ak3ra",
"id": 12105163,
"node_id": "MDQ6VXNlcjEyMTA1MTYz",
"avatar_url": "https://avatars.githubusercontent.com/u/12105163?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ak3ra",
"html_url": "https://github.com/ak3ra",
"followers_url": "https://api.github.com/users/ak3ra/followers",
"following_url": "https://api.github.com/users/ak3ra/following{/other_user}",
"gists_url": "https://api.github.com/users/ak3ra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ak3ra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ak3ra/subscriptions",
"organizations_url": "https://api.github.com/users/ak3ra/orgs",
"repos_url": "https://api.github.com/users/ak3ra/repos",
"events_url": "https://api.github.com/users/ak3ra/events{/privacy}",
"received_events_url": "https://api.github.com/users/ak3ra/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hi @ak3ra , have you had a chance to take my comments into account ?\r\n\r\nLet me know if you have questions or if I can help :)",
"@lhoestq Working on this, thanks for the detailed review :) ",
"Hi ! Cool thanks :)\r\nFeel free to merge master into your branch to fix the CI issues\r\n\r\nLet me know if you have questions or if I can help"
] | 1,627,831,080,000 | 1,638,350,289,000 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2738",
"html_url": "https://github.com/huggingface/datasets/pull/2738",
"diff_url": "https://github.com/huggingface/datasets/pull/2738.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2738.patch",
"merged_at": null
} | Multi-way parallel text corpus of 5 key Ugandan languages for the task of machine translation. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2738/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2738/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2737 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2737/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2737/comments | https://api.github.com/repos/huggingface/datasets/issues/2737/events | https://github.com/huggingface/datasets/issues/2737 | 957,124,881 | MDU6SXNzdWU5NTcxMjQ4ODE= | 2,737 | SacreBLEU update | {
"login": "devrimcavusoglu",
"id": 46989091,
"node_id": "MDQ6VXNlcjQ2OTg5MDkx",
"avatar_url": "https://avatars.githubusercontent.com/u/46989091?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/devrimcavusoglu",
"html_url": "https://github.com/devrimcavusoglu",
"followers_url": "https://api.github.com/users/devrimcavusoglu/followers",
"following_url": "https://api.github.com/users/devrimcavusoglu/following{/other_user}",
"gists_url": "https://api.github.com/users/devrimcavusoglu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/devrimcavusoglu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/devrimcavusoglu/subscriptions",
"organizations_url": "https://api.github.com/users/devrimcavusoglu/orgs",
"repos_url": "https://api.github.com/users/devrimcavusoglu/repos",
"events_url": "https://api.github.com/users/devrimcavusoglu/events{/privacy}",
"received_events_url": "https://api.github.com/users/devrimcavusoglu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @devrimcavusoglu, \r\nI tried your code with latest version of `datasets`and `sacrebleu==1.5.1` and it's running fine after changing one small thing:\r\n```\r\nsacrebleu = datasets.load_metric('sacrebleu')\r\npredictions = [\"It is a guide to action which ensures that the military always obeys the commands of the party\"]\r\nreferences = [[\"It is a guide to action that ensures that the military will forever heed Party commands\"]] # double brackets here should do the work\r\nresults = sacrebleu.compute(predictions=predictions, references=references)\r\nprint(results)\r\noutput: {'score': 41.180376356915765, 'counts': [11, 8, 6, 4], 'totals': [18, 17, 16, 15], 'precisions': [61.111111111111114, 47.05882352941177, 37.5, 26.666666666666668], 'bp': 1.0, 'sys_len': 18, 'ref_len': 16}\r\n```",
"@bhavitvyamalik hmm. I forgot double brackets, but still didn't work when used it with double brackets. It may be an isseu with platform (using win-10 currently), or versions. What is your platform and your version info for datasets, python, and sacrebleu ?",
"You can check that here, I've reproduced your code in [Google colab](https://colab.research.google.com/drive/1X90fHRgMLKczOVgVk7NDEw_ciZFDjaCM?usp=sharing). Looks like there was some issue in `sacrebleu` which was fixed later from what I've found [here](https://github.com/pytorch/fairseq/issues/2049#issuecomment-622367967). Upgrading `sacrebleu` to latest version should work.",
"It seems that next release of `sacrebleu` (v2.0.0) will break our `datasets` implementation to compute it. See my Google Colab: https://colab.research.google.com/drive/1SKmvvjQi6k_3OHsX5NPkZdiaJIfXyv9X?usp=sharing\r\n\r\nI'm reopening this Issue and making a Pull Request to fix it.",
"> It seems that next release of `sacrebleu` (v2.0.0) will break our `datasets` implementation to compute it. See my Google Colab: https://colab.research.google.com/drive/1SKmvvjQi6k_3OHsX5NPkZdiaJIfXyv9X?usp=sharing\r\n> \r\n> I'm reopening this Issue and making a Pull Request to fix it.\r\n\r\nHow did you solve him"
] | 1,627,689,188,000 | 1,632,307,661,000 | 1,627,964,617,000 | NONE | null | null | null | With the latest release of [sacrebleu](https://github.com/mjpost/sacrebleu), `datasets.metrics.sacrebleu` is broken, and getting error.
AttributeError: module 'sacrebleu' has no attribute 'DEFAULT_TOKENIZER'
this happens since in new version of sacrebleu there is no `DEFAULT_TOKENIZER`, but sacrebleu.py tries to import it anyways. This can be fixed currently with fixing `sacrebleu==1.5.0`
## Steps to reproduce the bug
```python
sacrebleu= datasets.load_metric('sacrebleu')
predictions = ["It is a guide to action which ensures that the military always obeys the commands of the party"]
references = ["It is a guide to action that ensures that the military will forever heed Party commands"]
results = sacrebleu.compute(predictions=predictions, references=references)
print(results)
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: Python 3.8.0
- PyArrow version: 5.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2737/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2737/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2736/comments | https://api.github.com/repos/huggingface/datasets/issues/2736/events | https://github.com/huggingface/datasets/issues/2736 | 956,895,199 | MDU6SXNzdWU5NTY4OTUxOTk= | 2,736 | Add Microsoft Building Footprints dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608941089,
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision",
"name": "vision",
"color": "bfdadc",
"default": false,
"description": "Vision datasets"
}
] | open | false | null | [] | null | [
"Motivation: this can be a useful dataset for researchers working on climate change adaptation, urban studies, geography, etc. I'll see if I can figure out how to add it!"
] | 1,627,661,828,000 | 1,638,965,343,000 | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** Microsoft Building Footprints
- **Description:** With the goal to increase the coverage of building footprint data available as open data for OpenStreetMap and humanitarian efforts, we have released millions of building footprints as open data available to download free of charge.
- **Paper:** *link to the dataset paper if available*
- **Data:** https://www.microsoft.com/en-us/maps/building-footprints
- **Motivation:** this can be a useful dataset for researchers working on climate change adaptation, urban studies, geography, etc.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
Reported by: @sashavor | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2736/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2736/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2735 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2735/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2735/comments | https://api.github.com/repos/huggingface/datasets/issues/2735/events | https://github.com/huggingface/datasets/issues/2735 | 956,889,365 | MDU6SXNzdWU5NTY4ODkzNjU= | 2,735 | Add Open Buildings dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 1,627,661,319,000 | 1,627,707,685,000 | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** Open Buildings
- **Description:** A dataset of building footprints to support social good applications.
Building footprints are useful for a range of important applications, from population estimation, urban planning and humanitarian response, to environmental and climate science. This large-scale open dataset contains the outlines of buildings derived from high-resolution satellite imagery in order to support these types of uses. The project being based in Ghana, the current focus is on the continent of Africa.
See: "Mapping Africa's Buildings with Satellite Imagery" https://ai.googleblog.com/2021/07/mapping-africas-buildings-with.html
- **Paper:** https://arxiv.org/abs/2107.12283
- **Data:** https://sites.research.google/open-buildings/
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
Reported by: @osanseviero | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2735/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2735/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2734 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2734/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2734/comments | https://api.github.com/repos/huggingface/datasets/issues/2734/events | https://github.com/huggingface/datasets/pull/2734 | 956,844,874 | MDExOlB1bGxSZXF1ZXN0NzAwMzc4NjI4 | 2,734 | Update BibTeX entry | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,658,571,000 | 1,627,660,078,000 | 1,627,660,078,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2734",
"html_url": "https://github.com/huggingface/datasets/pull/2734",
"diff_url": "https://github.com/huggingface/datasets/pull/2734.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2734.patch",
"merged_at": 1627660078000
} | Update BibTeX entry. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2734/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2734/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2733 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2733/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2733/comments | https://api.github.com/repos/huggingface/datasets/issues/2733/events | https://github.com/huggingface/datasets/pull/2733 | 956,725,476 | MDExOlB1bGxSZXF1ZXN0NzAwMjc1NDMy | 2,733 | Add missing parquet known extension | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,650,080,000 | 1,627,651,471,000 | 1,627,651,470,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2733",
"html_url": "https://github.com/huggingface/datasets/pull/2733",
"diff_url": "https://github.com/huggingface/datasets/pull/2733.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2733.patch",
"merged_at": 1627651470000
} | This code was failing because the parquet extension wasn't recognized:
```python
from datasets import load_dataset
base_url = "https://storage.googleapis.com/huggingface-nlp/cache/datasets/wikipedia/20200501.en/1.0.0/"
data_files = {"train": base_url + "wikipedia-train.parquet"}
wiki = load_dataset("parquet", data_files=data_files, split="train", streaming=True)
```
It raises
```python
NotImplementedError: Extraction protocol for file at https://storage.googleapis.com/huggingface-nlp/cache/datasets/wikipedia/20200501.en/1.0.0/wikipedia-train.parquet is not implemented yet
```
I added `parquet` to the list of known extensions
EDIT: added pickle, conllu, xml extensions as well | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2733/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2733/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2732 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2732/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2732/comments | https://api.github.com/repos/huggingface/datasets/issues/2732/events | https://github.com/huggingface/datasets/pull/2732 | 956,676,360 | MDExOlB1bGxSZXF1ZXN0NzAwMjMzMzQy | 2,732 | Updated TTC4900 Dataset | {
"login": "yavuzKomecoglu",
"id": 5150963,
"node_id": "MDQ6VXNlcjUxNTA5NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/5150963?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yavuzKomecoglu",
"html_url": "https://github.com/yavuzKomecoglu",
"followers_url": "https://api.github.com/users/yavuzKomecoglu/followers",
"following_url": "https://api.github.com/users/yavuzKomecoglu/following{/other_user}",
"gists_url": "https://api.github.com/users/yavuzKomecoglu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yavuzKomecoglu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yavuzKomecoglu/subscriptions",
"organizations_url": "https://api.github.com/users/yavuzKomecoglu/orgs",
"repos_url": "https://api.github.com/users/yavuzKomecoglu/repos",
"events_url": "https://api.github.com/users/yavuzKomecoglu/events{/privacy}",
"received_events_url": "https://api.github.com/users/yavuzKomecoglu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq, lütfen bu PR'ı gözden geçirebilir misiniz?",
"> Thanks ! This looks all good now :)\r\n\r\nThanks"
] | 1,627,645,934,000 | 1,627,660,851,000 | 1,627,660,694,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2732",
"html_url": "https://github.com/huggingface/datasets/pull/2732",
"diff_url": "https://github.com/huggingface/datasets/pull/2732.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2732.patch",
"merged_at": 1627660694000
} | - The source address of the TTC4900 dataset of [@savasy](https://github.com/savasy) has been updated for direct download.
- Updated readme. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2732/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2732/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2731 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2731/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2731/comments | https://api.github.com/repos/huggingface/datasets/issues/2731/events | https://github.com/huggingface/datasets/pull/2731 | 956,087,452 | MDExOlB1bGxSZXF1ZXN0Njk5NzQwMjg5 | 2,731 | Adding to_tf_dataset method | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This seems to be working reasonably well in testing, and performance is way better. `tf.py_function` has been dropped for an input generator, but I moved as much of the code as possible outside the generator to allow TF to compile it correctly. I also avoid `tf.RaggedTensor` at all costs, and do the shuffle in the dataset followed by accessing sequential chunks, instead of shuffling an index tensor. The combination of all of these gives us a more flexible data loader as well as a ~20X boost in performance compared to the first solution.",
"I made a change to the `TFFormatter` in this PR that will need some changes to the tests, so I wanted to ping @lhoestq and anyone else before I made those changes.\r\n\r\nThe key problem is that up until now the `TFFormatter` always returns `RaggedTensor`, created using the very slow `tf.ragged.constant` function. This is a big performance penalty, but it's also (imo) surprising for users - `RaggedTensor` handles tensors where one dimension has variable length. This is a good choice for tokenized datasets with variable sequence length, but it's an odd choice when the non-batch dimensions are constant, such as in image datasets, or in datasets where all samples are padded to the same length (e.g. for TPU training).\r\n\r\nThe change I made was to try to return standard `Tensor` objects instead of `RaggedTensor` when all the samples in the batch had the same shape, and if that was not the case to fall back to fast `RaggedTensor` creation with `tf.ragged.stack`, and only falling back to the very slow `tf.ragged.constant` function as a last resort. I think this will match user expectations in most cases and greatly improve performance, but it's a (very slightly) breaking change, so any feedback is welcome!",
"Also I really can't emphasize enough how slow `tf.ragged.constant` is, it's bad enough to create a data pipeline bottleneck in more or less any training setup:\r\n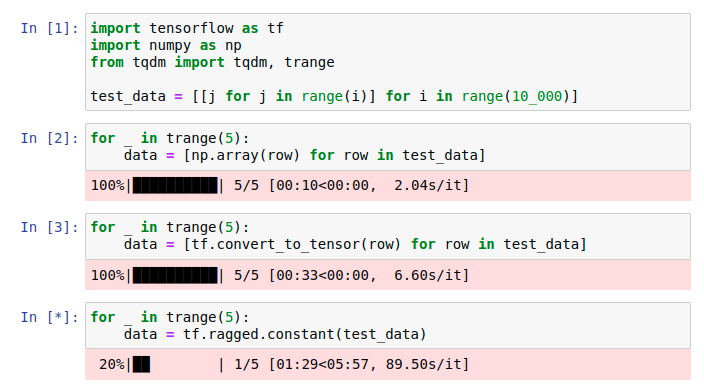\r\n",
"Hi @lhoestq, the tests have been modified and everything is passing. The Windows tests look to be failing for an unrelated reason, but other than that I'm ready to merge if you are!",
"Hi @Rocketknight1 ! Feel free to merge `master` into this branch to fix and run the full CI :)",
"@lhoestq rebased onto master and it looks good! I'm doing some testing with new notebook examples, but are you happy to merge if that looks good?",
"@lhoestq No, I'm happy to merge it as-is and add documentation afterwards!"
] | 1,627,582,225,000 | 1,631,800,254,000 | 1,631,800,254,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2731",
"html_url": "https://github.com/huggingface/datasets/pull/2731",
"diff_url": "https://github.com/huggingface/datasets/pull/2731.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2731.patch",
"merged_at": 1631800253000
} | Oh my **god** do not merge this yet, it's just a draft.
I've added a method (via a mixin) to the `arrow_dataset.Dataset` class that automatically converts our Dataset classes to TF Dataset classes ready for training. It hopefully has most of the features we want, including streaming from disk (no need to load the whole dataset in memory!), correct shuffling, variable-length batches to reduce compute, and correct support for unusual padding. It achieves that by calling the tokenizer `pad` method in the middle of a TF compute graph via a very hacky call to `tf.py_function`, which is heretical but seems to work.
A number of issues need to be resolved before it's ready to merge, though:
1) Is a MixIn the right way to do this? Do other classes besides `arrow_dataset.Dataset` need this method too?
2) Needs an argument to support constant-length batches for TPU training - this is easy to add and I'll do it soon.
3) Needs the user to supply the list of columns to drop from the arrow `Dataset`. Is there some automatic way to get the columns we want, or see which columns were added by the tokenizer?
4) Assumes the label column is always present and always called "label" - this is probably not great, but I'm not sure what the 'correct' thing to do here is. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2731/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2731/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2730/comments | https://api.github.com/repos/huggingface/datasets/issues/2730/events | https://github.com/huggingface/datasets/issues/2730 | 955,987,834 | MDU6SXNzdWU5NTU5ODc4MzQ= | 2,730 | Update CommonVoice with new release | {
"login": "yjernite",
"id": 10469459,
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yjernite",
"html_url": "https://github.com/yjernite",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"repos_url": "https://api.github.com/users/yjernite/repos",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"cc @patrickvonplaten?",
"Does anybody know if there is a bundled link, which would allow direct data download instead of manual? \r\nSomething similar to: `https://voice-prod-bundler-ee1969a6ce8178826482b88e843c335139bd3fb4.s3.amazonaws.com/cv-corpus-6.1-2020-12-11/ab.tar.gz` ? cc @patil-suraj \r\n",
"Also see: https://github.com/common-voice/common-voice-bundler/issues/15"
] | 1,627,574,399,000 | 1,628,353,159,000 | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** CommonVoice mid-2021 release
- **Description:** more data in CommonVoice: Languages that have increased the most by percentage are Thai (almost 20x growth, from 12 hours to 250 hours), Luganda (almost 9x growth, from 8 to 80), Esperanto (7x growth, from 100 to 840), and Tamil (almost 8x, from 24 to 220).
- **Paper:** https://discourse.mozilla.org/t/common-voice-2021-mid-year-dataset-release/83812
- **Data:** https://commonvoice.mozilla.org/en/datasets
- **Motivation:** More data and more varied. I think we just need to add configs in the existing dataset script.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2730/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2730/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2729 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2729/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2729/comments | https://api.github.com/repos/huggingface/datasets/issues/2729/events | https://github.com/huggingface/datasets/pull/2729 | 955,920,489 | MDExOlB1bGxSZXF1ZXN0Njk5NTk5MjA4 | 2,729 | Fix IndexError while loading Arabic Billion Words dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [] | 1,627,570,022,000 | 1,627,650,235,000 | 1,627,650,235,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2729",
"html_url": "https://github.com/huggingface/datasets/pull/2729",
"diff_url": "https://github.com/huggingface/datasets/pull/2729.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2729.patch",
"merged_at": 1627650235000
} | Catch `IndexError` and ignore that record.
Close #2727. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2729/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2729/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2728 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2728/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2728/comments | https://api.github.com/repos/huggingface/datasets/issues/2728/events | https://github.com/huggingface/datasets/issues/2728 | 955,892,970 | MDU6SXNzdWU5NTU4OTI5NzA= | 2,728 | Concurrent use of same dataset (already downloaded) | {
"login": "PierreColombo",
"id": 22492839,
"node_id": "MDQ6VXNlcjIyNDkyODM5",
"avatar_url": "https://avatars.githubusercontent.com/u/22492839?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PierreColombo",
"html_url": "https://github.com/PierreColombo",
"followers_url": "https://api.github.com/users/PierreColombo/followers",
"following_url": "https://api.github.com/users/PierreColombo/following{/other_user}",
"gists_url": "https://api.github.com/users/PierreColombo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PierreColombo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PierreColombo/subscriptions",
"organizations_url": "https://api.github.com/users/PierreColombo/orgs",
"repos_url": "https://api.github.com/users/PierreColombo/repos",
"events_url": "https://api.github.com/users/PierreColombo/events{/privacy}",
"received_events_url": "https://api.github.com/users/PierreColombo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Launching simultaneous job relying on the same datasets try some writing issue. I guess it is unexpected since I only need to load some already downloaded file.",
"If i have two jobs that use the same dataset. I got :\r\n\r\n\r\n File \"compute_measures.py\", line 181, in <module>\r\n train_loader, val_loader, test_loader = get_dataloader(args)\r\n File \"/gpfsdswork/projects/rech/toto/intRAOcular/dataset_utils.py\", line 69, in get_dataloader\r\n dataset_train = load_dataset('paws', \"labeled_final\", split='train', download_mode=\"reuse_cache_if_exists\")\r\n File \"/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.0/lib/python3.7/site-packages/datasets/load.py\", line 748, in load_dataset\r\n use_auth_token=use_auth_token,\r\n File \"/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.0/lib/python3.7/site-packages/datasets/builder.py\", line 582, in download_and_prepare\r\n self._save_info()\r\n File \"/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.0/lib/python3.7/site-packages/datasets/builder.py\", line 690, in _save_info\r\n self.info.write_to_directory(self._cache_dir)\r\n File \"/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.0/lib/python3.7/site-packages/datasets/info.py\", line 195, in write_to_directory\r\n with open(os.path.join(dataset_info_dir, config.LICENSE_FILENAME), \"wb\") as f:\r\nFileNotFoundError: [Errno 2] No such file or directory: '/gpfswork/rech/toto/datasets/paws/labeled_final/1.1.0/09d8fae989bb569009a8f5b879ccf2924d3e5cd55bfe2e89e6dab1c0b50ecd34.incomplete/LICENSE'",
"You can probably have a solution much faster than me (first time I use the library). But I suspect some write function are used when loading the dataset from cache.",
"I have the same issue:\r\n```\r\nTraceback (most recent call last):\r\n File \"/dccstor/tslm/envs/anaconda3/envs/trf-a100/lib/python3.9/site-packages/datasets/builder.py\", line 652, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/dccstor/tslm/envs/anaconda3/envs/trf-a100/lib/python3.9/site-packages/datasets/builder.py\", line 1040, in _prepare_split\r\n with ArrowWriter(features=self.info.features, path=fpath) as writer:\r\n File \"/dccstor/tslm/envs/anaconda3/envs/trf-a100/lib/python3.9/site-packages/datasets/arrow_writer.py\", line 192, in __init__\r\n self.stream = pa.OSFile(self._path, \"wb\")\r\n File \"pyarrow/io.pxi\", line 829, in pyarrow.lib.OSFile.__cinit__\r\n File \"pyarrow/io.pxi\", line 844, in pyarrow.lib.OSFile._open_writable\r\n File \"pyarrow/error.pxi\", line 122, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 97, in pyarrow.lib.check_status\r\nFileNotFoundError: [Errno 2] Failed to open local file '/dccstor/tslm-gen/.cache/csv/default-387f1f95c084d4df/0.0.0/2dc6629a9ff6b5697d82c25b73731dd440507a69cbce8b425db50b751e8fcfd0.incomplete/csv-validation.arrow'. Detail: [errno 2] No such file or directory\r\nDuring handling of the above exception, another exception occurred:\r\nTraceback (most recent call last):\r\n File \"/dccstor/tslm/elron/tslm-gen/train.py\", line 510, in <module>\r\n main()\r\n File \"/dccstor/tslm/elron/tslm-gen/train.py\", line 246, in main\r\n datasets = prepare_dataset(dataset_args, logger)\r\n File \"/dccstor/tslm/elron/tslm-gen/data.py\", line 157, in prepare_dataset\r\n datasets = load_dataset(extension, data_files=data_files, split=dataset_split, cache_dir=dataset_args.dataset_cache_dir, na_filter=False, download_mode=dataset_args.dataset_generate_mode)\r\n File \"/dccstor/tslm/envs/anaconda3/envs/trf-a100/lib/python3.9/site-packages/datasets/load.py\", line 742, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/dccstor/tslm/envs/anaconda3/envs/trf-a100/lib/python3.9/site-packages/datasets/builder.py\", line 574, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/dccstor/tslm/envs/anaconda3/envs/trf-a100/lib/python3.9/site-packages/datasets/builder.py\", line 654, in _download_and_prepare\r\n raise OSError(\r\nOSError: Cannot find data file. \r\nOriginal error:\r\n[Errno 2] Failed to open local file '/dccstor/tslm-gen/.cache/csv/default-387f1f95c084d4df/0.0.0/2dc6629a9ff6b5697d82c25b73731dd440507a69cbce8b425db50b751e8fcfd0.incomplete/csv-validation.arrow'. Detail: [errno 2] No such file or directory\r\n```"
] | 1,627,568,318,000 | 1,627,889,157,000 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
When launching several jobs at the same time loading the same dataset trigger some errors see (last comments).
## Steps to reproduce the bug
export HF_DATASETS_CACHE=/gpfswork/rech/toto/datasets
for MODEL in "bert-base-uncased" "roberta-base" "distilbert-base-cased"; do # "bert-base-uncased" "bert-large-cased" "roberta-large" "albert-base-v1" "albert-large-v1"; do
for TASK_NAME in "mrpc" "rte" 'imdb' "paws" "mnli"; do
export OUTPUT_DIR=${MODEL}_${TASK_NAME}
sbatch --job-name=${OUTPUT_DIR} \
--gres=gpu:1 \
--no-requeue \
--cpus-per-task=10 \
--hint=nomultithread \
--time=1:00:00 \
--output=jobinfo/${OUTPUT_DIR}_%j.out \
--error=jobinfo/${OUTPUT_DIR}_%j.err \
--qos=qos_gpu-t4 \
--wrap="module purge; module load pytorch-gpu/py3/1.7.0 ; export HF_DATASETS_OFFLINE=1; export HF_DATASETS_CACHE=/gpfswork/rech/toto/datasets; python compute_measures.py --seed=$SEED --saving_path=results --batch_size=$BATCH_SIZE --task_name=$TASK_NAME --model_name=/gpfswork/rech/toto/transformers_models/$MODEL"
done
done
```python
# Sample code to reproduce the bug
dataset_train = load_dataset('imdb', split='train', download_mode="reuse_cache_if_exists")
dataset_train = dataset_train.map(lambda e: tokenizer(e['text'], truncation=True, padding='max_length'),
batched=True).select(list(range(args.filter)))
dataset_val = load_dataset('imdb', split='train', download_mode="reuse_cache_if_exists")
dataset_val = dataset_val.map(lambda e: tokenizer(e['text'], truncation=True, padding='max_length'),
batched=True).select(list(range(args.filter, args.filter + 5000)))
dataset_test = load_dataset('imdb', split='test', download_mode="reuse_cache_if_exists")
dataset_test = dataset_test.map(lambda e: tokenizer(e['text'], truncation=True, padding='max_length'),
batched=True)
```
## Expected results
I believe I am doing something wrong with the objects.
## Actual results
Traceback (most recent call last):
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.0/lib/python3.7/site-packages/datasets/builder.py", line 652, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.0/lib/python3.7/site-packages/datasets/builder.py", line 983, in _prepare_split
check_duplicates=True,
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.0/lib/python3.7/site-packages/datasets/arrow_writer.py", line 192, in __init__
self.stream = pa.OSFile(self._path, "wb")
File "pyarrow/io.pxi", line 829, in pyarrow.lib.OSFile.__cinit__
File "pyarrow/io.pxi", line 844, in pyarrow.lib.OSFile._open_writable
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 97, in pyarrow.lib.check_status
FileNotFoundError: [Errno 2] Failed to open local file '/gpfswork/rech/tts/unm25jp/datasets/paws/labeled_final/1.1.0/09d8fae989bb569009a8f5b879ccf2924d3e5cd55bfe2e89e6dab1c0b50ecd34.incomplete/paws-test.arrow'. Detail: [errno 2] No such file or directory
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "compute_measures.py", line 181, in <module>
train_loader, val_loader, test_loader = get_dataloader(args)
File "/gpfsdswork/projects/rech/toto/intRAOcular/dataset_utils.py", line 69, in get_dataloader
dataset_train = load_dataset('paws', "labeled_final", split='train', download_mode="reuse_cache_if_exists")
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.0/lib/python3.7/site-packages/datasets/load.py", line 748, in load_dataset
use_auth_token=use_auth_token,
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.0/lib/python3.7/site-packages/datasets/builder.py", line 575, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.0/lib/python3.7/site-packages/datasets/builder.py", line 658, in _download_and_prepare
+ str(e)
OSError: Cannot find data file.
Original error:
[Errno 2] Failed to open local file '/gpfswork/rech/toto/datasets/paws/labeled_final/1.1.0/09d8fae989bb569009a8f5b879ccf2924d3e5cd55bfe2e89e6dab1c0b50ecd34.incomplete/paws-test.arrow'. Detail: [errno 2] No such file or directory
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: datasets==1.8.0
- Platform: linux (jeanzay)
- Python version: pyarrow==2.0.0
- PyArrow version: 3.7.8
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2728/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2728/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2727/comments | https://api.github.com/repos/huggingface/datasets/issues/2727/events | https://github.com/huggingface/datasets/issues/2727 | 955,812,149 | MDU6SXNzdWU5NTU4MTIxNDk= | 2,727 | Error in loading the Arabic Billion Words Corpus | {
"login": "M-Salti",
"id": 9285264,
"node_id": "MDQ6VXNlcjkyODUyNjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9285264?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/M-Salti",
"html_url": "https://github.com/M-Salti",
"followers_url": "https://api.github.com/users/M-Salti/followers",
"following_url": "https://api.github.com/users/M-Salti/following{/other_user}",
"gists_url": "https://api.github.com/users/M-Salti/gists{/gist_id}",
"starred_url": "https://api.github.com/users/M-Salti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/M-Salti/subscriptions",
"organizations_url": "https://api.github.com/users/M-Salti/orgs",
"repos_url": "https://api.github.com/users/M-Salti/repos",
"events_url": "https://api.github.com/users/M-Salti/events{/privacy}",
"received_events_url": "https://api.github.com/users/M-Salti/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"I modified the dataset loading script to catch the `IndexError` and inspect the records at which the error is happening, and I found this:\r\nFor the `Techreen` config, the error happens in 36 records when trying to find the `Text` or `Dateline` tags. All these 36 records look something like:\r\n```\r\n<Techreen>\r\n <ID>TRN_ARB_0248167</ID>\r\n <URL>http://tishreen.news.sy/tishreen/public/read/248240</URL>\r\n <Headline>Removed, because the original articles was in English</Headline>\r\n</Techreen>\r\n```\r\n\r\nand all the 288 faulty records in the `Almustaqbal` config look like:\r\n```\r\n<Almustaqbal>\r\n <ID>MTL_ARB_0028398</ID>\r\n \r\n <URL>http://www.almustaqbal.com/v4/article.aspx?type=NP&ArticleID=179015</URL>\r\n <Headline> Removed because it is not available in the original site</Headline>\r\n</Almustaqbal>\r\n```\r\n\r\nso the error is happening because the articles were removed and so the associated records lack the `Text` tag.\r\n\r\nIn this case, I think we just need to catch the `IndexError` and ignore (pass) it.\r\n",
"Thanks @M-Salti for reporting this issue and for your investigation.\r\n\r\nIndeed, those `IndexError` should be catched and the corresponding record should be ignored.\r\n\r\nI'm opening a Pull Request to fix it."
] | 1,627,563,189,000 | 1,627,650,235,000 | 1,627,650,235,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
I get `IndexError: list index out of range` when trying to load the `Techreen` and `Almustaqbal` configs of the dataset.
## Steps to reproduce the bug
```python
load_dataset("arabic_billion_words", "Techreen")
load_dataset("arabic_billion_words", "Almustaqbal")
```
## Expected results
The datasets load succefully.
## Actual results
```python
_extract_tags(self, sample, tag)
139 if len(out) > 0:
140 break
--> 141 return out[0]
142
143 def _clean_text(self, text):
IndexError: list index out of range
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.10.2
- Platform: Ubuntu 18.04.5 LTS
- Python version: 3.7.11
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2727/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2727/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2726 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2726/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2726/comments | https://api.github.com/repos/huggingface/datasets/issues/2726/events | https://github.com/huggingface/datasets/pull/2726 | 955,674,388 | MDExOlB1bGxSZXF1ZXN0Njk5Mzg5MDk1 | 2,726 | Typo fix `tokenize_exemple` | {
"login": "shabie",
"id": 30535146,
"node_id": "MDQ6VXNlcjMwNTM1MTQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/30535146?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shabie",
"html_url": "https://github.com/shabie",
"followers_url": "https://api.github.com/users/shabie/followers",
"following_url": "https://api.github.com/users/shabie/following{/other_user}",
"gists_url": "https://api.github.com/users/shabie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shabie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shabie/subscriptions",
"organizations_url": "https://api.github.com/users/shabie/orgs",
"repos_url": "https://api.github.com/users/shabie/repos",
"events_url": "https://api.github.com/users/shabie/events{/privacy}",
"received_events_url": "https://api.github.com/users/shabie/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,553,017,000 | 1,627,560,025,000 | 1,627,560,025,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2726",
"html_url": "https://github.com/huggingface/datasets/pull/2726",
"diff_url": "https://github.com/huggingface/datasets/pull/2726.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2726.patch",
"merged_at": 1627560025000
} | There is a small typo in the main README.md | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2726/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2726/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2725/comments | https://api.github.com/repos/huggingface/datasets/issues/2725/events | https://github.com/huggingface/datasets/pull/2725 | 955,020,776 | MDExOlB1bGxSZXF1ZXN0Njk4ODMwNjYw | 2,725 | Pass use_auth_token to request_etags | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,488,809,000 | 1,627,490,282,000 | 1,627,490,282,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2725",
"html_url": "https://github.com/huggingface/datasets/pull/2725",
"diff_url": "https://github.com/huggingface/datasets/pull/2725.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2725.patch",
"merged_at": 1627490281000
} | Fix #2724. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2725/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2725/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2724/comments | https://api.github.com/repos/huggingface/datasets/issues/2724/events | https://github.com/huggingface/datasets/issues/2724 | 954,919,607 | MDU6SXNzdWU5NTQ5MTk2MDc= | 2,724 | 404 Error when loading remote data files from private repo | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"I guess the issue is when computing the ETags of the remote files. Indeed `use_auth_token` must be passed to `request_etags` here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/35b5e4bc0cb2ed896e40f3eb2a4aa3de1cb1a6c5/src/datasets/builder.py#L160-L160",
"Yes, I remember having properly implemented that: \r\n- https://github.com/huggingface/datasets/commit/7a9c62f7cef9ecc293f629f859d4375a6bd26dc8#diff-f933ce41f71c6c0d1ce658e27de62cbe0b45d777e9e68056dd012ac3eb9324f7R160\r\n- https://github.com/huggingface/datasets/pull/2628/commits/6350a03b4b830339a745f7b1da46ece784ca734c\r\n\r\nBut a subsequent refactoring accidentally removed it...",
"I have opened a PR to fix it @lewtun."
] | 1,627,482,263,000 | 1,627,534,729,000 | 1,627,490,281,000 | MEMBER | null | null | null | ## Describe the bug
When loading remote data files from a private repo, a 404 error is raised.
## Steps to reproduce the bug
```python
url = hf_hub_url("lewtun/asr-preds-test", "preds.jsonl", repo_type="dataset")
dset = load_dataset("json", data_files=url, use_auth_token=True)
# HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/datasets/lewtun/asr-preds-test/resolve/main/preds.jsonl
```
## Expected results
Load dataset.
## Actual results
404 Error.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2724/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2724/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2723 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2723/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2723/comments | https://api.github.com/repos/huggingface/datasets/issues/2723/events | https://github.com/huggingface/datasets/pull/2723 | 954,864,104 | MDExOlB1bGxSZXF1ZXN0Njk4Njk0NDMw | 2,723 | Fix en subset by modifying dataset_info with correct validation infos | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,479,379,000 | 1,627,485,743,000 | 1,627,485,743,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2723",
"html_url": "https://github.com/huggingface/datasets/pull/2723",
"diff_url": "https://github.com/huggingface/datasets/pull/2723.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2723.patch",
"merged_at": 1627485743000
} | - Related to: #2682
We correct the values of `en` subset concerning the expected validation values (both `num_bytes` and `num_examples`.
Instead of having:
`{"name": "validation", "num_bytes": 828589180707, "num_examples": 364868892, "dataset_name": "c4"}`
We replace with correct values:
`{"name": "validation", "num_bytes": 825767266, "num_examples": 364608, "dataset_name": "c4"}`
There are still issues with validation with other subsets, but I can't download all the files, unzip to check for the correct number of bytes. (If you have a fast way to obtain those values for other subsets, I can do this in this PR ... otherwise I can't spend those resources)
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2723/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2723/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2722/comments | https://api.github.com/repos/huggingface/datasets/issues/2722/events | https://github.com/huggingface/datasets/issues/2722 | 954,446,053 | MDU6SXNzdWU5NTQ0NDYwNTM= | 2,722 | Missing cache file | {
"login": "PosoSAgapo",
"id": 33200481,
"node_id": "MDQ6VXNlcjMzMjAwNDgx",
"avatar_url": "https://avatars.githubusercontent.com/u/33200481?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PosoSAgapo",
"html_url": "https://github.com/PosoSAgapo",
"followers_url": "https://api.github.com/users/PosoSAgapo/followers",
"following_url": "https://api.github.com/users/PosoSAgapo/following{/other_user}",
"gists_url": "https://api.github.com/users/PosoSAgapo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PosoSAgapo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PosoSAgapo/subscriptions",
"organizations_url": "https://api.github.com/users/PosoSAgapo/orgs",
"repos_url": "https://api.github.com/users/PosoSAgapo/repos",
"events_url": "https://api.github.com/users/PosoSAgapo/events{/privacy}",
"received_events_url": "https://api.github.com/users/PosoSAgapo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"This could be solved by going to the glue/ directory and delete sst2 directory, then load the dataset again will help you redownload the dataset.",
"Hi ! Not sure why this file was missing, but yes the way to fix this is to delete the sst2 directory and to reload the dataset"
] | 1,627,444,327,000 | 1,627,463,223,000 | null | NONE | null | null | null | Strangely missing cache file after I restart my program again.
`glue_dataset = datasets.load_dataset('glue', 'sst2')`
`FileNotFoundError: [Errno 2] No such file or directory: /Users/chris/.cache/huggingface/datasets/glue/sst2/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96d6053ad/dataset_info.json'`
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2722/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2722/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2721 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2721/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2721/comments | https://api.github.com/repos/huggingface/datasets/issues/2721/events | https://github.com/huggingface/datasets/pull/2721 | 954,238,230 | MDExOlB1bGxSZXF1ZXN0Njk4MTY0Njg3 | 2,721 | Deal with the bad check in test_load.py | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! I did a change for this test already in #2662 :\r\n\r\nhttps://github.com/huggingface/datasets/blob/00686c46b7aaf6bfcd4102cec300a3c031284a5a/tests/test_load.py#L312-L316\r\n\r\n(though I have to change the variable name `m_combined_path` to `m_url` or something)\r\n\r\nI guess it's ok to remove this check for now :)"
] | 1,627,417,403,000 | 1,627,466,314,000 | 1,627,462,398,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2721",
"html_url": "https://github.com/huggingface/datasets/pull/2721",
"diff_url": "https://github.com/huggingface/datasets/pull/2721.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2721.patch",
"merged_at": 1627462398000
} | This PR removes a check that's been added in #2684. My intention with this check was to capture an URL in the error message, but instead, it captures a substring of the previous regex match in the test function. Another option would be to replace this check with:
```python
m_paths = re.findall(r"\S*_dummy/_dummy.py\b", str(exc_info.value)) # on Linux this will match an URL as well as a local_path due to different os.sep, so take the last element (an URL always comes last in the list)
assert len(m_paths) > 0 and is_remote_url(m_paths[-1]) # is_remote_url comes from datasets.utils.file_utils
```
@lhoestq Let me know which one of these two approaches (delete or replace) do you prefer? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2721/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2721/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2720 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2720/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2720/comments | https://api.github.com/repos/huggingface/datasets/issues/2720/events | https://github.com/huggingface/datasets/pull/2720 | 954,024,426 | MDExOlB1bGxSZXF1ZXN0Njk3OTgxNjMx | 2,720 | fix: 🐛 fix two typos | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,401,017,000 | 1,627,411,097,000 | 1,627,411,096,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2720",
"html_url": "https://github.com/huggingface/datasets/pull/2720",
"diff_url": "https://github.com/huggingface/datasets/pull/2720.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2720.patch",
"merged_at": 1627411096000
} | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2720/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2720/timeline | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/2719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2719/comments | https://api.github.com/repos/huggingface/datasets/issues/2719/events | https://github.com/huggingface/datasets/issues/2719 | 953,932,416 | MDU6SXNzdWU5NTM5MzI0MTY= | 2,719 | Use ETag in streaming mode to detect resource updates | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | open | false | null | [] | null | [] | 1,627,395,429,000 | 1,634,895,368,000 | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
I want to cache data I generate from processing a dataset I've loaded in streaming mode, but I've currently no way to know if the remote data has been updated or not, thus I don't know when to invalidate my cache.
**Describe the solution you'd like**
Take the ETag of the data files into account and provide it (directly or through a hash) to give a signal that I can invalidate my cache.
**Describe alternatives you've considered**
None
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2719/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2719/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2718 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2718/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2718/comments | https://api.github.com/repos/huggingface/datasets/issues/2718/events | https://github.com/huggingface/datasets/pull/2718 | 953,360,663 | MDExOlB1bGxSZXF1ZXN0Njk3NDE0NTQy | 2,718 | New documentation structure | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I just did some minor changes + added some content in these sections: share, about arrow, about cache\r\n\r\nFeel free to mark this PR as ready for review ! :)",
"I just separated the `Share` How-to page into three pages: share, dataset_script and dataset_card.\r\n\r\nThis way in the share page we can explain in more details how to share a community or a canonical dataset - focus in their differences and the steps to upload them.\r\n\r\nAlso given that making a dataset script or a dataset card both require several steps, I feel like it's better to have dedicated pages for them.\r\n\r\nLet me know what you think @stevhliu and others. We can still revert this change if you feel like it was better with everything in the same place.",
"I just added some minor changes to match the style, fix typos, etc. Great work on the conceptual guides, I learned a lot from them and I'm sure they will help a lot of other people too!\r\n\r\nI am fine with splitting `Share` into three separate pages. I think this probably makes it easier for users to navigate, instead of having to scroll up and down on a really long single page.",
"Thanks a lot for all the suggestions ! I'm doing the final changes based on the remaining comments, then we can merge and release v1.12 of `datasets` and the new documentation ^^",
"Alright I think I took all the suggestions and comments into account :)\r\nThanks everyone for the help !"
] | 1,627,341,313,000 | 1,631,553,653,000 | 1,631,553,652,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2718",
"html_url": "https://github.com/huggingface/datasets/pull/2718",
"diff_url": "https://github.com/huggingface/datasets/pull/2718.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2718.patch",
"merged_at": 1631553652000
} | Organize Datasets documentation into four documentation types to improve clarity and discoverability of content.
**Content to add in the very short term (feel free to add anything I'm missing):**
- A discussion on why Datasets uses Arrow that includes some context and background about why we use Arrow. Would also be great to talk about Datasets speed and performance here, and if you can share any benchmarking/tests you did, that would be awesome! Finally, a discussion about how memory-mapping frees the user from RAM constraints would be very helpful.
- Explain why you would want to disable or override verifications when loading a dataset.
- If possible, include a code sample of when the number of elements in the field of an output dictionary aren’t the same as the other fields in the output dictionary (taken from the [note](https://huggingface.co/docs/datasets/processing.html#augmenting-the-dataset) here). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2718/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2718/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2717 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2717/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2717/comments | https://api.github.com/repos/huggingface/datasets/issues/2717/events | https://github.com/huggingface/datasets/pull/2717 | 952,979,976 | MDExOlB1bGxSZXF1ZXN0Njk3MDkzNDEx | 2,717 | Fix shuffle on IterableDataset that disables batching in case any functions were mapped | {
"login": "amankhandelia",
"id": 7098967,
"node_id": "MDQ6VXNlcjcwOTg5Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7098967?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amankhandelia",
"html_url": "https://github.com/amankhandelia",
"followers_url": "https://api.github.com/users/amankhandelia/followers",
"following_url": "https://api.github.com/users/amankhandelia/following{/other_user}",
"gists_url": "https://api.github.com/users/amankhandelia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amankhandelia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amankhandelia/subscriptions",
"organizations_url": "https://api.github.com/users/amankhandelia/orgs",
"repos_url": "https://api.github.com/users/amankhandelia/repos",
"events_url": "https://api.github.com/users/amankhandelia/events{/privacy}",
"received_events_url": "https://api.github.com/users/amankhandelia/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,310,542,000 | 1,627,322,654,000 | 1,627,317,006,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2717",
"html_url": "https://github.com/huggingface/datasets/pull/2717",
"diff_url": "https://github.com/huggingface/datasets/pull/2717.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2717.patch",
"merged_at": 1627317005000
} | Made a very minor change to fix the issue#2716. Added the missing argument in the constructor call.
As discussed in the bug report, the change is made to prevent the `shuffle` method call from resetting the value of `batched` attribute in `MappedExamplesIterable`
Fix #2716. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2717/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2717/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2716/comments | https://api.github.com/repos/huggingface/datasets/issues/2716/events | https://github.com/huggingface/datasets/issues/2716 | 952,902,778 | MDU6SXNzdWU5NTI5MDI3Nzg= | 2,716 | Calling shuffle on IterableDataset will disable batching in case any functions were mapped | {
"login": "amankhandelia",
"id": 7098967,
"node_id": "MDQ6VXNlcjcwOTg5Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7098967?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amankhandelia",
"html_url": "https://github.com/amankhandelia",
"followers_url": "https://api.github.com/users/amankhandelia/followers",
"following_url": "https://api.github.com/users/amankhandelia/following{/other_user}",
"gists_url": "https://api.github.com/users/amankhandelia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amankhandelia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amankhandelia/subscriptions",
"organizations_url": "https://api.github.com/users/amankhandelia/orgs",
"repos_url": "https://api.github.com/users/amankhandelia/repos",
"events_url": "https://api.github.com/users/amankhandelia/events{/privacy}",
"received_events_url": "https://api.github.com/users/amankhandelia/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi :) Good catch ! Feel free to open a PR if you want to contribute, this would be very welcome ;)",
"Have raised the PR [here](https://github.com/huggingface/datasets/pull/2717)",
"Fixed by #2717."
] | 1,627,305,899,000 | 1,627,322,683,000 | 1,627,322,683,000 | CONTRIBUTOR | null | null | null | When using dataset in streaming mode, if one applies `shuffle` method on the dataset and `map` method for which `batched=True` than the batching operation will not happen, instead `batched` will be set to `False`
I did RCA on the dataset codebase, the problem is emerging from [this line of code](https://github.com/huggingface/datasets/blob/d25a0bf94d9f9a9aa6cabdf5b450b9c327d19729/src/datasets/iterable_dataset.py#L197) here as it is
`self.ex_iterable.shuffle_data_sources(seed), function=self.function, batch_size=self.batch_size`, as one can see it is missing batched argument, which means that the iterator fallsback to default constructor value, which in this case is `False`.
To remedy the problem we can change this line to
`self.ex_iterable.shuffle_data_sources(seed), function=self.function, batched=self.batched, batch_size=self.batch_size`
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2716/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2716/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2715/comments | https://api.github.com/repos/huggingface/datasets/issues/2715/events | https://github.com/huggingface/datasets/pull/2715 | 952,845,229 | MDExOlB1bGxSZXF1ZXN0Njk2OTc5MjQ1 | 2,715 | Update PAN-X data URL in XTREME dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Merging since the CI is just about missing infos in the dataset card"
] | 1,627,302,077,000 | 1,627,306,079,000 | 1,627,306,079,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2715",
"html_url": "https://github.com/huggingface/datasets/pull/2715",
"diff_url": "https://github.com/huggingface/datasets/pull/2715.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2715.patch",
"merged_at": 1627306079000
} | Related to #2710, #2691. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2715/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2715/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2714 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2714/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2714/comments | https://api.github.com/repos/huggingface/datasets/issues/2714/events | https://github.com/huggingface/datasets/issues/2714 | 952,580,820 | MDU6SXNzdWU5NTI1ODA4MjA= | 2,714 | add more precise information for size | {
"login": "pennyl67",
"id": 1493902,
"node_id": "MDQ6VXNlcjE0OTM5MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1493902?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pennyl67",
"html_url": "https://github.com/pennyl67",
"followers_url": "https://api.github.com/users/pennyl67/followers",
"following_url": "https://api.github.com/users/pennyl67/following{/other_user}",
"gists_url": "https://api.github.com/users/pennyl67/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pennyl67/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pennyl67/subscriptions",
"organizations_url": "https://api.github.com/users/pennyl67/orgs",
"repos_url": "https://api.github.com/users/pennyl67/repos",
"events_url": "https://api.github.com/users/pennyl67/events{/privacy}",
"received_events_url": "https://api.github.com/users/pennyl67/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"We already have this information in the dataset_infos.json files of each dataset.\r\nMaybe we can parse these files in the backend to return their content with the endpoint at huggingface.co/api/datasets\r\n\r\nFor now if you want to access this info you have to load the json for each dataset. For example:\r\n- for a dataset on github like `squad` \r\n- https://raw.githubusercontent.com/huggingface/datasets/master/datasets/squad/dataset_infos.json\r\n- for a community dataset on the hub like `lhoestq/squad`:\r\n https://huggingface.co/datasets/lhoestq/squad/resolve/main/dataset_infos.json"
] | 1,627,283,463,000 | 1,627,290,985,000 | null | NONE | null | null | null | For the import into ELG, we would like a more precise description of the size of the dataset, instead of the current size categories. The size can be expressed in bytes, or any other preferred size unit. As suggested in the slack channel, perhaps this could be computed with a regex for existing datasets. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2714/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2714/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2713/comments | https://api.github.com/repos/huggingface/datasets/issues/2713/events | https://github.com/huggingface/datasets/pull/2713 | 952,515,256 | MDExOlB1bGxSZXF1ZXN0Njk2Njk3MzU0 | 2,713 | Enumerate all ner_tags values in WNUT 17 dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,627,276,936,000 | 1,627,291,855,000 | 1,627,291,855,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2713",
"html_url": "https://github.com/huggingface/datasets/pull/2713",
"diff_url": "https://github.com/huggingface/datasets/pull/2713.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2713.patch",
"merged_at": 1627291854000
} | This PR does:
- Enumerate all ner_tags in dataset card Data Fields section
- Add all metadata tags to dataset card
Close #2709. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2713/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2713/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2710 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2710/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2710/comments | https://api.github.com/repos/huggingface/datasets/issues/2710/events | https://github.com/huggingface/datasets/pull/2710 | 951,723,326 | MDExOlB1bGxSZXF1ZXN0Njk2MDYyNjAy | 2,710 | Update WikiANN data URL | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"We have to update the URL in the XTREME benchmark as well:\r\n\r\nhttps://github.com/huggingface/datasets/blob/0dfc639cec450ed8762a997789a2ed63e63cdcf2/datasets/xtreme/xtreme.py#L411-L411\r\n\r\n"
] | 1,627,057,761,000 | 1,627,292,063,000 | 1,627,292,063,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2710",
"html_url": "https://github.com/huggingface/datasets/pull/2710",
"diff_url": "https://github.com/huggingface/datasets/pull/2710.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2710.patch",
"merged_at": 1627292062000
} | WikiANN data source URL is no longer accessible: 404 error from Dropbox.
We have decided to host it at Hugging Face. This PR updates the data source URL, the metadata JSON file and the dataset card.
Close #2691. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2710/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2710/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2709/comments | https://api.github.com/repos/huggingface/datasets/issues/2709/events | https://github.com/huggingface/datasets/issues/2709 | 951,534,757 | MDU6SXNzdWU5NTE1MzQ3NTc= | 2,709 | Missing documentation for wnut_17 (ner_tags) | {
"login": "maxpel",
"id": 31095360,
"node_id": "MDQ6VXNlcjMxMDk1MzYw",
"avatar_url": "https://avatars.githubusercontent.com/u/31095360?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxpel",
"html_url": "https://github.com/maxpel",
"followers_url": "https://api.github.com/users/maxpel/followers",
"following_url": "https://api.github.com/users/maxpel/following{/other_user}",
"gists_url": "https://api.github.com/users/maxpel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/maxpel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maxpel/subscriptions",
"organizations_url": "https://api.github.com/users/maxpel/orgs",
"repos_url": "https://api.github.com/users/maxpel/repos",
"events_url": "https://api.github.com/users/maxpel/events{/privacy}",
"received_events_url": "https://api.github.com/users/maxpel/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @maxpel, thanks for reporting this issue.\r\n\r\nIndeed, the documentation in the dataset card is not complete. I’m opening a Pull Request to fix it.\r\n\r\nAs the paper explains, there are 6 entity types and we have ordered them alphabetically: `corporation`, `creative-work`, `group`, `location`, `person` and `product`. \r\n\r\nEach of these entity types has 2 possible IOB2 format tags: \r\n- `B-`: to indicate that the token is the beginning of an entity name, and the \r\n- `I-`: to indicate that the token is inside an entity name. \r\n\r\nAdditionally, there is the standalone IOB2 tag \r\n- `O`: that indicates that the token belongs to no named entity. \r\n\r\nIn total there are 13 possible tags, which correspond to the following integer numbers:\r\n\r\n0. `O`\r\n1. `B-corporation`\r\n2. `I-corporation`\r\n3. `B-creative-work`\r\n4. `I-creative-work`\r\n5. `B-group`\r\n6. `I-group`\r\n7. `B-location`\r\n8. `I-location`\r\n9. `B-person`\r\n10. `I-person`\r\n11. `B-product`\r\n12. `I-product`"
] | 1,627,043,132,000 | 1,627,291,855,000 | 1,627,291,855,000 | CONTRIBUTOR | null | null | null | On the info page of the wnut_17 data set (https://huggingface.co/datasets/wnut_17), the model output of ner-tags is only documented for these 5 cases:
`ner_tags: a list of classification labels, with possible values including O (0), B-corporation (1), I-corporation (2), B-creative-work (3), I-creative-work (4).`
I trained a model with the data and it gives me 13 classes:
```
"id2label": {
"0": 0,
"1": 1,
"2": 2,
"3": 3,
"4": 4,
"5": 5,
"6": 6,
"7": 7,
"8": 8,
"9": 9,
"10": 10,
"11": 11,
"12": 12
}
"label2id": {
"0": 0,
"1": 1,
"10": 10,
"11": 11,
"12": 12,
"2": 2,
"3": 3,
"4": 4,
"5": 5,
"6": 6,
"7": 7,
"8": 8,
"9": 9
}
```
The paper (https://www.aclweb.org/anthology/W17-4418.pdf) explains those 6 categories, but the ordering does not match:
```
1. person
2. location (including GPE, facility)
3. corporation
4. product (tangible goods, or well-defined
services)
5. creative-work (song, movie, book and
so on)
6. group (subsuming music band, sports team,
and non-corporate organisations)
```
I would be very helpful for me, if somebody could clarify the model ouputs and explain the "B-" and "I-" prefixes to me.
Really great work with that and the other packages, I couldn't believe that training the model with that data was basically a one-liner! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2709/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2709/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2708/comments | https://api.github.com/repos/huggingface/datasets/issues/2708/events | https://github.com/huggingface/datasets/issues/2708 | 951,092,660 | MDU6SXNzdWU5NTEwOTI2NjA= | 2,708 | QASC: incomplete training set | {
"login": "danyaljj",
"id": 2441454,
"node_id": "MDQ6VXNlcjI0NDE0NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2441454?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danyaljj",
"html_url": "https://github.com/danyaljj",
"followers_url": "https://api.github.com/users/danyaljj/followers",
"following_url": "https://api.github.com/users/danyaljj/following{/other_user}",
"gists_url": "https://api.github.com/users/danyaljj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/danyaljj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danyaljj/subscriptions",
"organizations_url": "https://api.github.com/users/danyaljj/orgs",
"repos_url": "https://api.github.com/users/danyaljj/repos",
"events_url": "https://api.github.com/users/danyaljj/events{/privacy}",
"received_events_url": "https://api.github.com/users/danyaljj/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @danyaljj, thanks for reporting.\r\n\r\nUnfortunately, I have not been able to reproduce your problem. My train split has 8134 examples:\r\n```ipython\r\nIn [10]: ds[\"train\"]\r\nOut[10]:\r\nDataset({\r\n features: ['id', 'question', 'choices', 'answerKey', 'fact1', 'fact2', 'combinedfact', 'formatted_question'],\r\n num_rows: 8134\r\n})\r\n\r\nIn [11]: ds[\"train\"].shape\r\nOut[11]: (8134, 8)\r\n```\r\nand the content of the last 5 examples is:\r\n```ipython\r\nIn [12]: for i in range(8129, 8134):\r\n ...: print(json.dumps(ds[\"train\"][i]))\r\n ...:\r\n{\"id\": \"3KAKFY4PGU1LGXM77JAK2700NGCI3X\", \"question\": \"Chitin can be used for protection by whom?\", \"choices\": {\"text\": [\"Fungi\", \"People\", \"Man\", \"Fish\", \"trees\", \"Dogs\", \"animal\", \"Birds\"], \"label\": [\"A\", \"B\",\r\n \"C\", \"D\", \"E\", \"F\", \"G\", \"H\"]}, \"answerKey\": \"D\", \"fact1\": \"scales are used for protection by scaled animals\", \"fact2\": \"Fish scales are also composed of chitin.\", \"combinedfact\": \"Chitin can be used for prote\r\nction by fish.\", \"formatted_question\": \"Chitin can be used for protection by whom? (A) Fungi (B) People (C) Man (D) Fish (E) trees (F) Dogs (G) animal (H) Birds\"}\r\n{\"id\": \"336YQZE83VDAQVZ26HW59X51JZ9M5M\", \"question\": \"Which type of animal uses plates for protection?\", \"choices\": {\"text\": [\"squids\", \"reptiles\", \"sea urchins\", \"fish\", \"amphibians\", \"Frogs\", \"mammals\", \"salm\r\non\"], \"label\": [\"A\", \"B\", \"C\", \"D\", \"E\", \"F\", \"G\", \"H\"]}, \"answerKey\": \"B\", \"fact1\": \"scales are used for protection by scaled animals\", \"fact2\": \"Reptiles have scales or plates.\", \"combinedfact\": \"Reptiles use\r\n their plates for protection.\", \"formatted_question\": \"Which type of animal uses plates for protection? (A) squids (B) reptiles (C) sea urchins (D) fish (E) amphibians (F) Frogs (G) mammals (H) salmon\"}\r\n{\"id\": \"3WZ36BJEV3FGS66VGOOUYX0LN8GTBU\", \"question\": \"What are used for protection by fish?\", \"choices\": {\"text\": [\"scales\", \"fins\", \"streams.\", \"coral\", \"gills\", \"Collagen\", \"mussels\", \"whiskers\"], \"label\": [\"\r\nA\", \"B\", \"C\", \"D\", \"E\", \"F\", \"G\", \"H\"]}, \"answerKey\": \"A\", \"fact1\": \"scales are used for protection by scaled animals\", \"fact2\": \"Fish are backboned aquatic animals.\", \"combinedfact\": \"scales are used for prote\r\nction by fish \", \"formatted_question\": \"What are used for protection by fish? (A) scales (B) fins (C) streams. (D) coral (E) gills (F) Collagen (G) mussels (H) whiskers\"}\r\n{\"id\": \"3Z2R0DQ0JHDKFAO2706OYIXGNA4E28\", \"question\": \"What are pangolins covered in?\", \"choices\": {\"text\": [\"tunicates\", \"Echinoids\", \"shells\", \"exoskeleton\", \"blastoids\", \"barrel-shaped\", \"protection\", \"white\"\r\n], \"label\": [\"A\", \"B\", \"C\", \"D\", \"E\", \"F\", \"G\", \"H\"]}, \"answerKey\": \"G\", \"fact1\": \"scales are used for protection by scaled animals\", \"fact2\": \"Pangolins have an elongate and tapering body covered above with ov\r\nerlapping scales.\", \"combinedfact\": \"Pangolins are covered in overlapping protection.\", \"formatted_question\": \"What are pangolins covered in? (A) tunicates (B) Echinoids (C) shells (D) exoskeleton (E) blastoids\r\n (F) barrel-shaped (G) protection (H) white\"}\r\n{\"id\": \"3PMBY0YE272GIWPNWIF8IH5RBHVC9S\", \"question\": \"What are covered with protection?\", \"choices\": {\"text\": [\"apples\", \"trees\", \"coral\", \"clams\", \"roses\", \"wings\", \"hats\", \"fish\"], \"label\": [\"A\", \"B\", \"C\", \"D\r\n\", \"E\", \"F\", \"G\", \"H\"]}, \"answerKey\": \"H\", \"fact1\": \"scales are used for protection by scaled animals\", \"fact2\": \"Fish are covered with scales.\", \"combinedfact\": \"Fish are covered with protection\", \"formatted_q\r\nuestion\": \"What are covered with protection? (A) apples (B) trees (C) coral (D) clams (E) roses (F) wings (G) hats (H) fish\"}\r\n```\r\n\r\nCould you please load again your dataset and print its shape, like this:\r\n```python\r\nds = load_dataset(\"qasc\", split=\"train)\r\nprint(ds.shape)\r\n```\r\nand confirm which is your output?",
"Hmm .... it must have been a mistake on my side. Sorry for the hassle! "
] | 1,626,991,184,000 | 1,627,047,007,000 | 1,627,047,007,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
The training instances are not loaded properly.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("qasc", script_version='1.10.2')
def load_instances(split):
instances = dataset[split]
print(f"split: {split} - size: {len(instances)}")
for x in instances:
print(json.dumps(x))
load_instances('test')
load_instances('validation')
load_instances('train')
```
## results
For test and validation, we can see the examples in the output (which is good!):
```
split: test - size: 920
{"answerKey": "", "choices": {"label": ["A", "B", "C", "D", "E", "F", "G", "H"], "text": ["Anthax", "under water", "uterus", "wombs", "two", "moles", "live", "embryo"]}, "combinedfact": "", "fact1": "", "fact2": "", "formatted_question": "What type of birth do therian mammals have? (A) Anthax (B) under water (C) uterus (D) wombs (E) two (F) moles (G) live (H) embryo", "id": "3C44YUNSI1OBFBB8D36GODNOZN9DPA", "question": "What type of birth do therian mammals have?"}
{"answerKey": "", "choices": {"label": ["A", "B", "C", "D", "E", "F", "G", "H"], "text": ["Corvidae", "arthropods", "birds", "backbones", "keratin", "Jurassic", "front paws", "Parakeets."]}, "combinedfact": "", "fact1": "", "fact2": "", "formatted_question": "By what time had mouse-sized viviparous mammals evolved? (A) Corvidae (B) arthropods (C) birds (D) backbones (E) keratin (F) Jurassic (G) front paws (H) Parakeets.", "id": "3B1NLC6UGZVERVLZFT7OUYQLD1SGPZ", "question": "By what time had mouse-sized viviparous mammals evolved?"}
{"answerKey": "", "choices": {"label": ["A", "B", "C", "D", "E", "F", "G", "H"], "text": ["Reduced friction", "causes infection", "vital to a good life", "prevents water loss", "camouflage from consumers", "Protection against predators", "spur the growth of the plant", "a smooth surface"]}, "combinedfact": "", "fact1": "", "fact2": "", "formatted_question": "What does a plant's skin do? (A) Reduced friction (B) causes infection (C) vital to a good life (D) prevents water loss (E) camouflage from consumers (F) Protection against predators (G) spur the growth of the plant (H) a smooth surface", "id": "3QRYMNZ7FYGITFVSJET3PS0F4S0NT9", "question": "What does a plant's skin do?"}
...
```
However, only a few instances are loaded for the training split, which is not correct.
## Environment info
- `datasets` version: '1.10.2'
- Platform: MaxOS
- Python version:3.7
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2708/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2708/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2707/comments | https://api.github.com/repos/huggingface/datasets/issues/2707/events | https://github.com/huggingface/datasets/issues/2707 | 950,812,945 | MDU6SXNzdWU5NTA4MTI5NDU= | 2,707 | 404 Not Found Error when loading LAMA dataset | {
"login": "dwil2444",
"id": 26467159,
"node_id": "MDQ6VXNlcjI2NDY3MTU5",
"avatar_url": "https://avatars.githubusercontent.com/u/26467159?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dwil2444",
"html_url": "https://github.com/dwil2444",
"followers_url": "https://api.github.com/users/dwil2444/followers",
"following_url": "https://api.github.com/users/dwil2444/following{/other_user}",
"gists_url": "https://api.github.com/users/dwil2444/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dwil2444/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dwil2444/subscriptions",
"organizations_url": "https://api.github.com/users/dwil2444/orgs",
"repos_url": "https://api.github.com/users/dwil2444/repos",
"events_url": "https://api.github.com/users/dwil2444/events{/privacy}",
"received_events_url": "https://api.github.com/users/dwil2444/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi @dwil2444! I was able to reproduce your error when I downgraded to v1.1.2. Updating to the latest version of Datasets fixed the error for me :)",
"Hi @dwil2444, thanks for reporting.\r\n\r\nCould you please confirm which `datasets` version you were using and if the problem persists after you update it to the latest version: `pip install -U datasets`?\r\n\r\nThanks @stevhliu for the hint to fix this! ;)",
"@stevhliu @albertvillanova updating to the latest version of datasets did in fact fix this issue. Thanks a lot for your help!"
] | 1,626,969,153,000 | 1,627,309,747,000 | 1,627,309,747,000 | NONE | null | null | null | The [LAMA](https://huggingface.co/datasets/viewer/?dataset=lama) probing dataset is not available for download:
Steps to Reproduce:
1. `from datasets import load_dataset`
2. `dataset = load_dataset('lama', 'trex')`.
Results:
`FileNotFoundError: Couldn't find file locally at lama/lama.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.2/datasets/lama/lama.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/lama/lama.py` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2707/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2707/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2706 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2706/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2706/comments | https://api.github.com/repos/huggingface/datasets/issues/2706/events | https://github.com/huggingface/datasets/pull/2706 | 950,606,561 | MDExOlB1bGxSZXF1ZXN0Njk1MTI3ODgz | 2,706 | Update BibTeX entry | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,956,969,000 | 1,626,957,780,000 | 1,626,957,780,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2706",
"html_url": "https://github.com/huggingface/datasets/pull/2706",
"diff_url": "https://github.com/huggingface/datasets/pull/2706.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2706.patch",
"merged_at": 1626957780000
} | Update BibTeX entry. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2706/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2706/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2705/comments | https://api.github.com/repos/huggingface/datasets/issues/2705/events | https://github.com/huggingface/datasets/issues/2705 | 950,488,583 | MDU6SXNzdWU5NTA0ODg1ODM= | 2,705 | 404 not found error on loading WIKIANN dataset | {
"login": "ronbutan",
"id": 39296659,
"node_id": "MDQ6VXNlcjM5Mjk2NjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/39296659?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ronbutan",
"html_url": "https://github.com/ronbutan",
"followers_url": "https://api.github.com/users/ronbutan/followers",
"following_url": "https://api.github.com/users/ronbutan/following{/other_user}",
"gists_url": "https://api.github.com/users/ronbutan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ronbutan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ronbutan/subscriptions",
"organizations_url": "https://api.github.com/users/ronbutan/orgs",
"repos_url": "https://api.github.com/users/ronbutan/repos",
"events_url": "https://api.github.com/users/ronbutan/events{/privacy}",
"received_events_url": "https://api.github.com/users/ronbutan/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @ronbutan, thanks for reporting.\r\n\r\nYou are right: we have recently found that the link to the original PAN-X dataset (also called WikiANN), hosted at Dropbox, is no longer working.\r\n\r\nWe have opened an issue in the GitHub repository of the original dataset (afshinrahimi/mmner#4) and we have also contacted the author by email to ask if they are planning to fix this issue. See the details here: https://github.com/huggingface/datasets/issues/2691#issuecomment-885463027\r\n\r\nI close this issue because it is the same as in #2691. Feel free to subscribe to that other issue to be informed about any updates."
] | 1,626,947,750,000 | 1,627,027,652,000 | 1,627,027,652,000 | NONE | null | null | null | ## Describe the bug
Unable to retreive wikiann English dataset
## Steps to reproduce the bug
```python
from datasets import list_datasets, load_dataset, list_metrics, load_metric
WIKIANN = load_dataset("wikiann","en")
```
## Expected results
Colab notebook should display successful download status
## Actual results
FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/12h3qqog6q4bjve/panx_dataset.tar?dl=1
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.10.1
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2705/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2705/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2704 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2704/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2704/comments | https://api.github.com/repos/huggingface/datasets/issues/2704/events | https://github.com/huggingface/datasets/pull/2704 | 950,483,980 | MDExOlB1bGxSZXF1ZXN0Njk1MDIzMTEz | 2,704 | Fix pick default config name message | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,947,383,000 | 1,626,948,161,000 | 1,626,948,160,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2704",
"html_url": "https://github.com/huggingface/datasets/pull/2704",
"diff_url": "https://github.com/huggingface/datasets/pull/2704.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2704.patch",
"merged_at": 1626948160000
} | The error message to tell which config name to load is not displayed.
This is because in the code it was considering the config kwargs to be non-empty, which is a special case for custom configs created on the fly. It appears after this change: https://github.com/huggingface/datasets/pull/2659
I fixed that by making the config kwargs empty by default, even if default parameters are passed
Fix https://github.com/huggingface/datasets/issues/2703 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2704/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2704/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2703/comments | https://api.github.com/repos/huggingface/datasets/issues/2703/events | https://github.com/huggingface/datasets/issues/2703 | 950,482,284 | MDU6SXNzdWU5NTA0ODIyODQ= | 2,703 | Bad message when config name is missing | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,626,947,243,000 | 1,626,948,160,000 | 1,626,948,160,000 | MEMBER | null | null | null | When loading a dataset that have several configurations, we expect to see an error message if the user doesn't specify a config name.
However in `datasets` 1.10.0 and 1.10.1 it doesn't show the right message:
```python
import datasets
datasets.load_dataset("glue")
```
raises
```python
AttributeError: 'BuilderConfig' object has no attribute 'text_features'
```
instead of
```python
ValueError: Config name is missing.
Please pick one among the available configs: ['cola', 'sst2', 'mrpc', 'qqp', 'stsb', 'mnli', 'mnli_mismatched', 'mnli_matched', 'qnli', 'rte', 'wnli', 'ax']
Example of usage:
`load_dataset('glue', 'cola')`
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2703/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2703/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2702 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2702/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2702/comments | https://api.github.com/repos/huggingface/datasets/issues/2702/events | https://github.com/huggingface/datasets/pull/2702 | 950,448,159 | MDExOlB1bGxSZXF1ZXN0Njk0OTkyOTc1 | 2,702 | Update BibTeX entry | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,944,679,000 | 1,626,945,459,000 | 1,626,945,458,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2702",
"html_url": "https://github.com/huggingface/datasets/pull/2702",
"diff_url": "https://github.com/huggingface/datasets/pull/2702.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2702.patch",
"merged_at": 1626945458000
} | Update BibTeX entry. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2702/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2702/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2701 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2701/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2701/comments | https://api.github.com/repos/huggingface/datasets/issues/2701/events | https://github.com/huggingface/datasets/pull/2701 | 950,422,403 | MDExOlB1bGxSZXF1ZXN0Njk0OTcxMzM3 | 2,701 | Fix download_mode docstrings | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | closed | false | null | [] | null | [] | 1,626,942,625,000 | 1,626,946,411,000 | 1,626,946,411,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2701",
"html_url": "https://github.com/huggingface/datasets/pull/2701",
"diff_url": "https://github.com/huggingface/datasets/pull/2701.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2701.patch",
"merged_at": 1626946411000
} | Fix `download_mode` docstrings. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2701/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2701/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2700 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2700/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2700/comments | https://api.github.com/repos/huggingface/datasets/issues/2700/events | https://github.com/huggingface/datasets/issues/2700 | 950,276,325 | MDU6SXNzdWU5NTAyNzYzMjU= | 2,700 | from datasets import Dataset is failing | {
"login": "kswamy15",
"id": 5582286,
"node_id": "MDQ6VXNlcjU1ODIyODY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5582286?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kswamy15",
"html_url": "https://github.com/kswamy15",
"followers_url": "https://api.github.com/users/kswamy15/followers",
"following_url": "https://api.github.com/users/kswamy15/following{/other_user}",
"gists_url": "https://api.github.com/users/kswamy15/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kswamy15/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kswamy15/subscriptions",
"organizations_url": "https://api.github.com/users/kswamy15/orgs",
"repos_url": "https://api.github.com/users/kswamy15/repos",
"events_url": "https://api.github.com/users/kswamy15/events{/privacy}",
"received_events_url": "https://api.github.com/users/kswamy15/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @kswamy15, thanks for reporting.\r\n\r\nWe are fixing this critical issue and making an urgent patch release of the `datasets` library today.\r\n\r\nIn the meantime, you can circumvent this issue by updating the `tqdm` library: `!pip install -U tqdm`"
] | 1,626,925,883,000 | 1,626,938,625,000 | 1,626,937,747,000 | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
from datasets import Dataset
```
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py in <module>()
25 import posixpath
26 import requests
---> 27 from tqdm.contrib.concurrent import thread_map
28
29 from .. import __version__, config, utils
ModuleNotFoundError: No module named 'tqdm.contrib.concurrent'
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
---------------------------------------------------------------------------
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: latest version as of 07/21/2021
- Platform: Google Colab
- Python version: 3.7
- PyArrow version:
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2700/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2700/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2699 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2699/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2699/comments | https://api.github.com/repos/huggingface/datasets/issues/2699/events | https://github.com/huggingface/datasets/issues/2699 | 950,221,226 | MDU6SXNzdWU5NTAyMjEyMjY= | 2,699 | cannot combine splits merging and streaming? | {
"login": "eyaler",
"id": 4436747,
"node_id": "MDQ6VXNlcjQ0MzY3NDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/4436747?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eyaler",
"html_url": "https://github.com/eyaler",
"followers_url": "https://api.github.com/users/eyaler/followers",
"following_url": "https://api.github.com/users/eyaler/following{/other_user}",
"gists_url": "https://api.github.com/users/eyaler/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eyaler/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eyaler/subscriptions",
"organizations_url": "https://api.github.com/users/eyaler/orgs",
"repos_url": "https://api.github.com/users/eyaler/repos",
"events_url": "https://api.github.com/users/eyaler/events{/privacy}",
"received_events_url": "https://api.github.com/users/eyaler/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi ! That's missing indeed. We'll try to implement this for the next version :)\r\n\r\nI guess we just need to implement #2564 first, and then we should be able to add support for splits combinations"
] | 1,626,916,405,000 | 1,626,942,467,000 | null | NONE | null | null | null | this does not work:
`dataset = datasets.load_dataset('mc4','iw',split='train+validation',streaming=True)`
with error:
`ValueError: Bad split: train+validation. Available splits: ['train', 'validation']`
these work:
`dataset = datasets.load_dataset('mc4','iw',split='train+validation')`
`dataset = datasets.load_dataset('mc4','iw',split='train',streaming=True)`
`dataset = datasets.load_dataset('mc4','iw',split='validation',streaming=True)`
i could not find a reference to this in the documentation and the error message is confusing. also would be nice to allow streaming for the merged splits | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2699/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2699/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2698 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2698/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2698/comments | https://api.github.com/repos/huggingface/datasets/issues/2698/events | https://github.com/huggingface/datasets/pull/2698 | 950,159,867 | MDExOlB1bGxSZXF1ZXN0Njk0NzUxMzMw | 2,698 | Ignore empty batch when writing | {
"login": "pcuenca",
"id": 1177582,
"node_id": "MDQ6VXNlcjExNzc1ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1177582?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pcuenca",
"html_url": "https://github.com/pcuenca",
"followers_url": "https://api.github.com/users/pcuenca/followers",
"following_url": "https://api.github.com/users/pcuenca/following{/other_user}",
"gists_url": "https://api.github.com/users/pcuenca/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pcuenca/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pcuenca/subscriptions",
"organizations_url": "https://api.github.com/users/pcuenca/orgs",
"repos_url": "https://api.github.com/users/pcuenca/repos",
"events_url": "https://api.github.com/users/pcuenca/events{/privacy}",
"received_events_url": "https://api.github.com/users/pcuenca/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,906,930,000 | 1,627,311,363,000 | 1,627,305,926,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2698",
"html_url": "https://github.com/huggingface/datasets/pull/2698",
"diff_url": "https://github.com/huggingface/datasets/pull/2698.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2698.patch",
"merged_at": 1627305926000
} | This prevents an schema update with unknown column types, as reported in #2644.
This is my first attempt at fixing the issue. I tested the following:
- First batch returned by a batched map operation is empty.
- An intermediate batch is empty.
- `python -m unittest tests.test_arrow_writer` passes.
However, `arrow_writer` looks like a pretty generic interface, I'm not sure if there are other uses I may have overlooked. Let me know if that's the case, or if a better approach would be preferable. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2698/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2698/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2697 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2697/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2697/comments | https://api.github.com/repos/huggingface/datasets/issues/2697/events | https://github.com/huggingface/datasets/pull/2697 | 950,021,623 | MDExOlB1bGxSZXF1ZXN0Njk0NjMyODg0 | 2,697 | Fix import on Colab | {
"login": "nateraw",
"id": 32437151,
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nateraw",
"html_url": "https://github.com/nateraw",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"repos_url": "https://api.github.com/users/nateraw/repos",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq @albertvillanova - It might be a good idea to have a patch release after this gets merged (presumably tomorrow morning when you're around). The Colab issue linked to this PR is a pretty big blocker. "
] | 1,626,894,218,000 | 1,626,937,748,000 | 1,626,937,747,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2697",
"html_url": "https://github.com/huggingface/datasets/pull/2697",
"diff_url": "https://github.com/huggingface/datasets/pull/2697.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2697.patch",
"merged_at": 1626937746000
} | Fix #2695, fix #2700. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2697/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2697/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2696 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2696/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2696/comments | https://api.github.com/repos/huggingface/datasets/issues/2696/events | https://github.com/huggingface/datasets/pull/2696 | 949,901,726 | MDExOlB1bGxSZXF1ZXN0Njk0NTMwODg3 | 2,696 | Add support for disable_progress_bar on Windows | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The CI failure seems unrelated to this PR (probably has something to do with Transformers)."
] | 1,626,885,293,000 | 1,627,306,274,000 | 1,627,292,317,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2696",
"html_url": "https://github.com/huggingface/datasets/pull/2696",
"diff_url": "https://github.com/huggingface/datasets/pull/2696.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2696.patch",
"merged_at": 1627292317000
} | This PR is a continuation of #2667 and adds support for `utils.disable_progress_bar()` on Windows when using multiprocessing. This [answer](https://stackoverflow.com/a/6596695/14095927) on SO explains it nicely why the current approach (with calling `utils.is_progress_bar_enabled()` inside `Dataset._map_single`) would not work on Windows. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2696/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2696/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2695/comments | https://api.github.com/repos/huggingface/datasets/issues/2695/events | https://github.com/huggingface/datasets/issues/2695 | 949,864,823 | MDU6SXNzdWU5NDk4NjQ4MjM= | 2,695 | Cannot import load_dataset on Colab | {
"login": "bayartsogt-ya",
"id": 43239645,
"node_id": "MDQ6VXNlcjQzMjM5NjQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bayartsogt-ya",
"html_url": "https://github.com/bayartsogt-ya",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"gists_url": "https://api.github.com/users/bayartsogt-ya/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bayartsogt-ya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bayartsogt-ya/subscriptions",
"organizations_url": "https://api.github.com/users/bayartsogt-ya/orgs",
"repos_url": "https://api.github.com/users/bayartsogt-ya/repos",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"received_events_url": "https://api.github.com/users/bayartsogt-ya/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"I'm facing the same issue on Colab today too.\r\n\r\n```\r\nModuleNotFoundError Traceback (most recent call last)\r\n<ipython-input-4-5833ac0f5437> in <module>()\r\n 3 \r\n 4 from ray import tune\r\n----> 5 from datasets import DatasetDict, Dataset\r\n 6 from datasets import load_dataset, load_metric\r\n 7 from dataclasses import dataclass\r\n\r\n7 frames\r\n/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py in <module>()\r\n 25 import posixpath\r\n 26 import requests\r\n---> 27 from tqdm.contrib.concurrent import thread_map\r\n 28 \r\n 29 from .. import __version__, config, utils\r\n\r\nModuleNotFoundError: No module named 'tqdm.contrib.concurrent'\r\n\r\n---------------------------------------------------------------------------\r\nNOTE: If your import is failing due to a missing package, you can\r\nmanually install dependencies using either !pip or !apt.\r\n\r\nTo view examples of installing some common dependencies, click the\r\n\"Open Examples\" button below.\r\n---------------------------------------------------------------------------\r\n```",
"@phosseini \r\nI think it is related to [1.10.0](https://github.com/huggingface/datasets/actions/runs/1052653701) release done 3 hours ago. (cc: @lhoestq )\r\nFor now I just downgraded to 1.9.0 and it is working fine.",
"> @phosseini\r\n> I think it is related to [1.10.0](https://github.com/huggingface/datasets/actions/runs/1052653701) release done 3 hours ago. (cc: @lhoestq )\r\n> For now I just downgraded to 1.9.0 and it is working fine.\r\n\r\nSame here, downgraded to 1.9.0 for now and works fine.",
"Hi, \r\n\r\nupdating tqdm to the newest version resolves the issue for me. You can do this as follows in Colab:\r\n```\r\n!pip install tqdm --upgrade\r\n```",
"Hi @bayartsogt-ya and @phosseini, thanks for reporting.\r\n\r\nWe are fixing this critical issue and making an urgent patch release of the `datasets` library today.\r\n\r\nIn the meantime, as pointed out by @mariosasko, you can circumvent this issue by updating the `tqdm` library: \r\n```\r\n!pip install -U tqdm\r\n```"
] | 1,626,882,771,000 | 1,626,938,785,000 | 1,626,937,747,000 | NONE | null | null | null | ## Describe the bug
Got tqdm concurrent module not found error during importing load_dataset from datasets.
## Steps to reproduce the bug
Here [colab notebook](https://colab.research.google.com/drive/1pErWWnVP4P4mVHjSFUtkePd8Na_Qirg4?usp=sharing) to reproduce the error
On colab:
```python
!pip install datasets
from datasets import load_dataset
```
## Expected results
Works without error
## Actual results
Specify the actual results or traceback.
```
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-2-8cc7de4c69eb> in <module>()
----> 1 from datasets import load_dataset, load_metric, Metric, MetricInfo, Features, Value
2 from sklearn.metrics import mean_squared_error
/usr/local/lib/python3.7/dist-packages/datasets/__init__.py in <module>()
31 )
32
---> 33 from .arrow_dataset import Dataset, concatenate_datasets
34 from .arrow_reader import ArrowReader, ReadInstruction
35 from .arrow_writer import ArrowWriter
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in <module>()
40 from tqdm.auto import tqdm
41
---> 42 from datasets.tasks.text_classification import TextClassification
43
44 from . import config, utils
/usr/local/lib/python3.7/dist-packages/datasets/tasks/__init__.py in <module>()
1 from typing import Optional
2
----> 3 from ..utils.logging import get_logger
4 from .automatic_speech_recognition import AutomaticSpeechRecognition
5 from .base import TaskTemplate
/usr/local/lib/python3.7/dist-packages/datasets/utils/__init__.py in <module>()
19
20 from . import logging
---> 21 from .download_manager import DownloadManager, GenerateMode
22 from .file_utils import DownloadConfig, cached_path, hf_bucket_url, is_remote_url, temp_seed
23 from .mock_download_manager import MockDownloadManager
/usr/local/lib/python3.7/dist-packages/datasets/utils/download_manager.py in <module>()
24
25 from .. import config
---> 26 from .file_utils import (
27 DownloadConfig,
28 cached_path,
/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py in <module>()
25 import posixpath
26 import requests
---> 27 from tqdm.contrib.concurrent import thread_map
28
29 from .. import __version__, config, utils
ModuleNotFoundError: No module named 'tqdm.contrib.concurrent'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.10.0
- Platform: Colab
- Python version: 3.7.11
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2695/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2695/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2694 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2694/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2694/comments | https://api.github.com/repos/huggingface/datasets/issues/2694/events | https://github.com/huggingface/datasets/pull/2694 | 949,844,722 | MDExOlB1bGxSZXF1ZXN0Njk0NDg0NTcy | 2,694 | fix: 🐛 change string format to allow copy/paste to work in bash | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,881,440,000 | 1,626,950,507,000 | 1,626,950,507,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2694",
"html_url": "https://github.com/huggingface/datasets/pull/2694",
"diff_url": "https://github.com/huggingface/datasets/pull/2694.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2694.patch",
"merged_at": 1626950507000
} | Before: copy/paste resulted in an error because the square bracket
characters `[]` are special characters in bash | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2694/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2694/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2693 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2693/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2693/comments | https://api.github.com/repos/huggingface/datasets/issues/2693/events | https://github.com/huggingface/datasets/pull/2693 | 949,797,014 | MDExOlB1bGxSZXF1ZXN0Njk0NDQ1ODAz | 2,693 | Fix OSCAR Esperanto | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,878,630,000 | 1,626,879,232,000 | 1,626,879,231,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2693",
"html_url": "https://github.com/huggingface/datasets/pull/2693",
"diff_url": "https://github.com/huggingface/datasets/pull/2693.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2693.patch",
"merged_at": 1626879231000
} | The Esperanto part (original) of OSCAR has the wrong number of examples:
```python
from datasets import load_dataset
raw_datasets = load_dataset("oscar", "unshuffled_original_eo")
```
raises
```python
NonMatchingSplitsSizesError:
[{'expected': SplitInfo(name='train', num_bytes=314188336, num_examples=121171, dataset_name='oscar'),
'recorded': SplitInfo(name='train', num_bytes=314064514, num_examples=121168, dataset_name='oscar')}]
```
I updated the number of expected examples in dataset_infos.json
cc @sgugger | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2693/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2693/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2692 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2692/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2692/comments | https://api.github.com/repos/huggingface/datasets/issues/2692/events | https://github.com/huggingface/datasets/pull/2692 | 949,765,484 | MDExOlB1bGxSZXF1ZXN0Njk0NDE4MDg1 | 2,692 | Update BibTeX entry | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,877,415,000 | 1,626,881,501,000 | 1,626,881,500,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2692",
"html_url": "https://github.com/huggingface/datasets/pull/2692",
"diff_url": "https://github.com/huggingface/datasets/pull/2692.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2692.patch",
"merged_at": 1626881500000
} | Update BibTeX entry | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2692/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2692/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2691/comments | https://api.github.com/repos/huggingface/datasets/issues/2691/events | https://github.com/huggingface/datasets/issues/2691 | 949,758,379 | MDU6SXNzdWU5NDk3NTgzNzk= | 2,691 | xtreme / pan-x cannot be downloaded | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @severo, thanks for reporting.\r\n\r\nHowever I have not been able to reproduce this issue. Could you please confirm if the problem persists for you?\r\n\r\nMaybe Dropbox (where the data source is hosted) was temporarily unavailable when you tried.",
"Hmmm, the file (https://www.dropbox.com/s/dl/12h3qqog6q4bjve/panx_dataset.tar) really seems to be unavailable... I tried from various connexions and machines and got the same 404 error. Maybe the dataset has been loaded from the cache in your case?",
"Yes @severo, weird... I could access the file when I answered to you, but now I cannot longer access it either... Maybe it was from the cache as you point out.\r\n\r\nAnyway, I have opened an issue in the GitHub repository responsible for the original dataset: https://github.com/afshinrahimi/mmner/issues/4\r\nI have also contacted the maintainer by email.\r\n\r\nI'll keep you informed with their answer.",
"Reply from the author/maintainer: \r\n> Will fix the issue and let you know during the weekend.",
"The author told that apparently Dropbox has changed their policy and no longer allow downloading the file without having signed in first. The author asked Hugging Face to host their dataset."
] | 1,626,877,085,000 | 1,627,292,062,000 | 1,627,292,062,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
Dataset xtreme / pan-x cannot be loaded
Seems related to https://github.com/huggingface/datasets/pull/2326
## Steps to reproduce the bug
```python
dataset = load_dataset("xtreme", "PAN-X.fr")
```
## Expected results
Load the dataset
## Actual results
```
FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/12h3qqog6q4bjve/panx_dataset.tar?dl=1
```
## Environment info
- `datasets` version: 1.9.0
- Platform: macOS-11.4-x86_64-i386-64bit
- Python version: 3.8.11
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2691/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2691/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2690 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2690/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2690/comments | https://api.github.com/repos/huggingface/datasets/issues/2690/events | https://github.com/huggingface/datasets/pull/2690 | 949,574,500 | MDExOlB1bGxSZXF1ZXN0Njk0MjU5MDc1 | 2,690 | Docs details | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for all the comments and for the corrections in the docs !\r\n\r\nAbout all the points you mentioned:\r\n\r\n> * the code samples assume the expected libraries have already been installed. Maybe add a section at start, or add it to every code sample. Something like `pip install datasets transformers torch 'datasets[streaming]'` (maybe just link to https://huggingface.co/docs/datasets/installation.html + a one-liner that installs all the requirements / alternatively a requirements.txt file)\r\n\r\nYes good idea\r\n\r\n> * \"If you’d like to play with the examples, you must install it from source.\" in https://huggingface.co/docs/datasets/installation.html: it's not clear to me what this means (what are these \"examples\"?)\r\n\r\nIt refers to examples scripts inside the git repository of the library, see the `examples` folder in the `transformers` repo.\r\nWe don't have examples yet in the git repo of `datasets` as in transformers. So currently there are no examples. Maybe we can just remove this sentence from the docs for now\r\n\r\n> * in https://huggingface.co/docs/datasets/loading_datasets.html: \"or AWS bucket if it’s not already stored in the library\". It's the only place in the doc (aside from the docstring https://huggingface.co/docs/datasets/package_reference/loading_methods.html?highlight=aws bucket#datasets.list_datasets) where the \"AWS bucket\" is mentioned. It's not easy to understand what this means. Maybe explain more, and link to https://s3.amazonaws.com/datasets.huggingface.co and/or https://huggingface.co/docs/datasets/filesystems.html.\r\n\r\nThis is outdated and must be replaced by\r\n```\r\nor from the Hugging Face Hub if it’s not already stored in the library\r\n```\r\n\r\n> * example in https://huggingface.co/docs/datasets/loading_datasets.html#manually-downloading-files is obsoleted by [Enable auto-download for PAN-X / Wikiann domain in XTREME #2326](https://github.com/huggingface/datasets/pull/2326). Also: see [xtreme / pan-x cannot be downloaded #2691](https://github.com/huggingface/datasets/issues/2691) for a bug on this specific dataset.\r\n\r\nWe can replace the `XTREME` `PANX` dataste by `matinf` instead for example\r\n\r\n> * in https://huggingface.co/docs/datasets/loading_datasets.html#manually-downloading-files the doc says \"After you’ve downloaded the files, you can point to the folder hosting them locally with the data_dir argument as follows:\", but the following example does not show how to use `data_dir`\r\n\r\nLet's add `data_dir=\"path/to/your/downloaded/data\"` for example\r\n\r\n> * in https://huggingface.co/docs/datasets/loading_datasets.html#csv-files, it would be nice to have an URL to the csv loader reference (but I'm not sure there is one in the API reference). This comment applies in many places in the doc: I would want the API reference to contain doc for all the code/functions/classes... and I would want a lot more links inside the doc pointing to the API entries.\r\n\r\nCurrently there's no documentation for the CSV loader config. Maybe we can add the docstrings to the `CsvConfig` class to explain the parameters and how it works, and then redirect to the doc of this class in this section of the documentation.\r\n\r\n> * in the API reference (docstrings) I would prefer \"SOURCE\" to link to github instead of a copy of the code inside the docs site (eg. https://github.com/huggingface/datasets/blob/master/src/datasets/load.py#L711 instead of https://huggingface.co/docs/datasets/_modules/datasets/load.html#load_dataset)\r\n\r\nThis is the same as in `transformers`, not sure if this is a big issue\r\n\r\n> * it seems like not all the API is exposed in the doc. For example, there is no doc for [`disable_progress_bar`](https://github.com/huggingface/datasets/search?q=disable_progress_bar), see https://huggingface.co/docs/datasets/search.html?q=disable_progress_bar, even if the code contains docstrings. Does it mean that the function is not officially supported? (otherwise, maybe it also deserves a mention in https://huggingface.co/docs/datasets/package_reference/logging_methods.html)\r\n\r\nThe function `disable_progress_bar` should definitely be in the docs, thanks. We can add it to the logging methods\r\n\r\n> * in https://huggingface.co/docs/datasets/loading_datasets.html?highlight=most%20efficient%20format%20have%20json%20files%20consisting%20multiple%20json%20objects#json-files, \"The most efficient format is to have JSON files consisting of multiple JSON objects, one per line, representing individual data rows:\", maybe link to https://en.wikipedia.org/wiki/JSON_streaming#Line-delimited_JSON and give it a name (\"line-delimited JSON\"? \"JSON Lines\" as in https://huggingface.co/docs/datasets/processing.html#exporting-a-dataset-to-csv-json-parquet-or-to-python-objects ?)\r\n\r\nYes good idea !\r\n\r\n> * in https://huggingface.co/docs/datasets/loading_datasets.html, for the local files sections, it would be nice to provide sample csv / json / text files to download, so that it's easier for the reader to try to load them (instead: they won't try)\r\n\r\nSure why not. Moreover the csv loader now supports remote files so you could just run the code pass an an URL to the sample csv file.\r\n\r\n> * the doc explains how to shard a dataset, but does not explain why and when a dataset should be sharded (I have no idea... for [parallelizing](https://huggingface.co/docs/datasets/processing.html#multiprocessing)?). It does neither give an idea of the number of shards a dataset typically should have and why.\r\n\r\nThis can be used for distributed processing or just to use a percentage of the data. We can definitely give example of use cases\r\n\r\n> * the code example in https://huggingface.co/docs/datasets/processing.html#mapping-in-a-distributed-setting does not work, because `training_args` has not been defined before in the doc.\r\n\r\n`training_args` comes from `transformers`, it's a practical way to define all your arguments to train a model. Maybe we can just import it from `transformers` and use it with the default values\r\n\r\n"
] | 1,626,864,194,000 | 1,627,411,254,000 | 1,627,411,254,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2690",
"html_url": "https://github.com/huggingface/datasets/pull/2690",
"diff_url": "https://github.com/huggingface/datasets/pull/2690.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2690.patch",
"merged_at": 1627411253000
} | Some comments here:
- the code samples assume the expected libraries have already been installed. Maybe add a section at start, or add it to every code sample. Something like `pip install datasets transformers torch 'datasets[streaming]'` (maybe just link to https://huggingface.co/docs/datasets/installation.html + a one-liner that installs all the requirements / alternatively a requirements.txt file)
- "If you’d like to play with the examples, you must install it from source." in https://huggingface.co/docs/datasets/installation.html: it's not clear to me what this means (what are these "examples"?)
- in https://huggingface.co/docs/datasets/loading_datasets.html: "or AWS bucket if it’s not already stored in the library". It's the only place in the doc (aside from the docstring https://huggingface.co/docs/datasets/package_reference/loading_methods.html?highlight=aws bucket#datasets.list_datasets) where the "AWS bucket" is mentioned. It's not easy to understand what this means. Maybe explain more, and link to https://s3.amazonaws.com/datasets.huggingface.co and/or https://huggingface.co/docs/datasets/filesystems.html.
- example in https://huggingface.co/docs/datasets/loading_datasets.html#manually-downloading-files is obsoleted by https://github.com/huggingface/datasets/pull/2326. Also: see https://github.com/huggingface/datasets/issues/2691 for a bug on this specific dataset.
- in https://huggingface.co/docs/datasets/loading_datasets.html#manually-downloading-files the doc says "After you’ve downloaded the files, you can point to the folder hosting them locally with the data_dir argument as follows:", but the following example does not show how to use `data_dir`
- in https://huggingface.co/docs/datasets/loading_datasets.html#csv-files, it would be nice to have an URL to the csv loader reference (but I'm not sure there is one in the API reference). This comment applies in many places in the doc: I would want the API reference to contain doc for all the code/functions/classes... and I would want a lot more links inside the doc pointing to the API entries.
- in the API reference (docstrings) I would prefer "SOURCE" to link to github instead of a copy of the code inside the docs site (eg. https://github.com/huggingface/datasets/blob/master/src/datasets/load.py#L711 instead of https://huggingface.co/docs/datasets/_modules/datasets/load.html#load_dataset)
- it seems like not all the API is exposed in the doc. For example, there is no doc for [`disable_progress_bar`](https://github.com/huggingface/datasets/search?q=disable_progress_bar), see https://huggingface.co/docs/datasets/search.html?q=disable_progress_bar, even if the code contains docstrings. Does it mean that the function is not officially supported? (otherwise, maybe it also deserves a mention in https://huggingface.co/docs/datasets/package_reference/logging_methods.html)
- in https://huggingface.co/docs/datasets/loading_datasets.html?highlight=most%20efficient%20format%20have%20json%20files%20consisting%20multiple%20json%20objects#json-files, "The most efficient format is to have JSON files consisting of multiple JSON objects, one per line, representing individual data rows:", maybe link to https://en.wikipedia.org/wiki/JSON_streaming#Line-delimited_JSON and give it a name ("line-delimited JSON"? "JSON Lines" as in https://huggingface.co/docs/datasets/processing.html#exporting-a-dataset-to-csv-json-parquet-or-to-python-objects ?)
- in https://huggingface.co/docs/datasets/loading_datasets.html, for the local files sections, it would be nice to provide sample csv / json / text files to download, so that it's easier for the reader to try to load them (instead: they won't try)
- the doc explains how to shard a dataset, but does not explain why and when a dataset should be sharded (I have no idea... for [parallelizing](https://huggingface.co/docs/datasets/processing.html#multiprocessing)?). It does neither give an idea of the number of shards a dataset typically should have and why.
- the code example in https://huggingface.co/docs/datasets/processing.html#mapping-in-a-distributed-setting does not work, because `training_args` has not been defined before in the doc. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2690/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2690/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2689/comments | https://api.github.com/repos/huggingface/datasets/issues/2689/events | https://github.com/huggingface/datasets/issues/2689 | 949,447,104 | MDU6SXNzdWU5NDk0NDcxMDQ= | 2,689 | cannot save the dataset to disk after rename_column | {
"login": "PaulLerner",
"id": 25532159,
"node_id": "MDQ6VXNlcjI1NTMyMTU5",
"avatar_url": "https://avatars.githubusercontent.com/u/25532159?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PaulLerner",
"html_url": "https://github.com/PaulLerner",
"followers_url": "https://api.github.com/users/PaulLerner/followers",
"following_url": "https://api.github.com/users/PaulLerner/following{/other_user}",
"gists_url": "https://api.github.com/users/PaulLerner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PaulLerner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PaulLerner/subscriptions",
"organizations_url": "https://api.github.com/users/PaulLerner/orgs",
"repos_url": "https://api.github.com/users/PaulLerner/repos",
"events_url": "https://api.github.com/users/PaulLerner/events{/privacy}",
"received_events_url": "https://api.github.com/users/PaulLerner/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! That's because you are trying to overwrite a file that is already open and being used.\r\nIndeed `foo/dataset.arrow` is open and used by your `dataset` object.\r\n\r\nWhen you do `rename_column`, the resulting dataset reads the data from the same arrow file.\r\nIn other cases like when using `map` on the other hand, the resulting dataset reads the data from another arrow file that is the result of the map transform.\r\n\r\nTherefore overwriting a dataset after `rename_column` is not possible, but it is possible after `map`, since `rename_column` doesn't switch to using another arrow file (the actual data stay the same).",
"Ok, thanks for clearing it up :)"
] | 1,626,855,220,000 | 1,626,873,064,000 | 1,626,873,064,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
If you use `rename_column` and do no other modification, you will be unable to save the dataset using `save_to_disk`
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
In [1]: from datasets import Dataset, load_from_disk
In [5]: dataset=Dataset.from_dict({'foo': [0]})
In [7]: dataset.save_to_disk('foo')
In [8]: dataset=load_from_disk('foo')
In [10]: dataset=dataset.rename_column('foo', 'bar')
In [11]: dataset.save_to_disk('foo')
---------------------------------------------------------------------------
PermissionError Traceback (most recent call last)
<ipython-input-11-a3bc0d4fc339> in <module>
----> 1 dataset.save_to_disk('foo')
/mnt/beegfs/projects/meerqat/anaconda3/envs/meerqat/lib/python3.7/site-packages/datasets/arrow_dataset.py in save_to_disk(self, dataset_path
, fs)
597 if Path(dataset_path, config.DATASET_ARROW_FILENAME) in cache_files_paths:
598 raise PermissionError(
--> 599 f"Tried to overwrite {Path(dataset_path, config.DATASET_ARROW_FILENAME)} but a dataset can't overwrite itself."
600 )
601 if Path(dataset_path, config.DATASET_INDICES_FILENAME) in cache_files_paths:
PermissionError: Tried to overwrite foo/dataset.arrow but a dataset can't overwrite itself.
```
N. B. I created the dataset from dict to enable easy reproduction but the same happens if you load an existing dataset (e.g. starting from `In [8]`)
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.0
- Platform: Linux-3.10.0-1160.11.1.el7.x86_64-x86_64-with-centos-7.9.2009-Core
- Python version: 3.7.10
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2689/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2689/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2688 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2688/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2688/comments | https://api.github.com/repos/huggingface/datasets/issues/2688/events | https://github.com/huggingface/datasets/issues/2688 | 949,182,074 | MDU6SXNzdWU5NDkxODIwNzQ= | 2,688 | hebrew language codes he and iw should be treated as aliases | {
"login": "eyaler",
"id": 4436747,
"node_id": "MDQ6VXNlcjQ0MzY3NDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/4436747?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eyaler",
"html_url": "https://github.com/eyaler",
"followers_url": "https://api.github.com/users/eyaler/followers",
"following_url": "https://api.github.com/users/eyaler/following{/other_user}",
"gists_url": "https://api.github.com/users/eyaler/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eyaler/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eyaler/subscriptions",
"organizations_url": "https://api.github.com/users/eyaler/orgs",
"repos_url": "https://api.github.com/users/eyaler/repos",
"events_url": "https://api.github.com/users/eyaler/events{/privacy}",
"received_events_url": "https://api.github.com/users/eyaler/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @eyaler, thanks for reporting.\r\n\r\nWhile you are true with respect the Hebrew language tag (\"iw\" is deprecated and \"he\" is the preferred value), in the \"mc4\" dataset (which is a derived dataset) we have kept the language tags present in the original dataset: [Google C4](https://www.tensorflow.org/datasets/catalog/c4).",
"For discoverability on the website I updated the YAML tags at the top of the mC4 dataset card https://github.com/huggingface/datasets/commit/38288087b1b02f97586e0346e8f28f4960f1fd37\r\n\r\nOnce the website is updated, mC4 will be listed in https://huggingface.co/datasets?filter=languages:he\r\n\r\n"
] | 1,626,822,832,000 | 1,626,885,293,000 | 1,626,885,293,000 | NONE | null | null | null | https://huggingface.co/datasets/mc4 not listed when searching for hebrew datasets (he) as it uses the older language code iw, preventing discoverability. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2688/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2688/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2687 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2687/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2687/comments | https://api.github.com/repos/huggingface/datasets/issues/2687/events | https://github.com/huggingface/datasets/pull/2687 | 948,890,481 | MDExOlB1bGxSZXF1ZXN0NjkzNjY1NDI2 | 2,687 | Minor documentation fix | {
"login": "slowwavesleep",
"id": 44175589,
"node_id": "MDQ6VXNlcjQ0MTc1NTg5",
"avatar_url": "https://avatars.githubusercontent.com/u/44175589?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/slowwavesleep",
"html_url": "https://github.com/slowwavesleep",
"followers_url": "https://api.github.com/users/slowwavesleep/followers",
"following_url": "https://api.github.com/users/slowwavesleep/following{/other_user}",
"gists_url": "https://api.github.com/users/slowwavesleep/gists{/gist_id}",
"starred_url": "https://api.github.com/users/slowwavesleep/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/slowwavesleep/subscriptions",
"organizations_url": "https://api.github.com/users/slowwavesleep/orgs",
"repos_url": "https://api.github.com/users/slowwavesleep/repos",
"events_url": "https://api.github.com/users/slowwavesleep/events{/privacy}",
"received_events_url": "https://api.github.com/users/slowwavesleep/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,803,003,000 | 1,626,872,695,000 | 1,626,872,695,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2687",
"html_url": "https://github.com/huggingface/datasets/pull/2687",
"diff_url": "https://github.com/huggingface/datasets/pull/2687.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2687.patch",
"merged_at": 1626872695000
} | Currently, [Writing a dataset loading script](https://huggingface.co/docs/datasets/add_dataset.html) page has a small error. A link to `matinf` dataset in [_Dataset scripts of reference_](https://huggingface.co/docs/datasets/add_dataset.html#dataset-scripts-of-reference) section actually leads to `xsquad`, instead. This PR fixes that. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2687/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2687/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2686/comments | https://api.github.com/repos/huggingface/datasets/issues/2686/events | https://github.com/huggingface/datasets/pull/2686 | 948,811,669 | MDExOlB1bGxSZXF1ZXN0NjkzNTk4OTE3 | 2,686 | Fix bad config ids that name cache directories | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,796,845,000 | 1,626,798,435,000 | 1,626,798,435,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2686",
"html_url": "https://github.com/huggingface/datasets/pull/2686",
"diff_url": "https://github.com/huggingface/datasets/pull/2686.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2686.patch",
"merged_at": 1626798434000
} | `data_dir=None` was considered a dataset config parameter, hence creating a special config_id for all dataset being loaded.
Since the config_id is used to name the cache directories, this leaded to datasets being regenerated for users.
I fixed this by ignoring the value of `data_dir` when it's `None` when computing the config_id.
I also added a test to make sure the cache directories are not unexpectedly renamed in the future.
Fix https://github.com/huggingface/datasets/issues/2683 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2686/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2686/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2685 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2685/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2685/comments | https://api.github.com/repos/huggingface/datasets/issues/2685/events | https://github.com/huggingface/datasets/pull/2685 | 948,791,572 | MDExOlB1bGxSZXF1ZXN0NjkzNTgxNTk2 | 2,685 | Fix Blog Authorship Corpus dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Normally, I'm expecting errors from the validation of the README file... 😅 ",
"That is:\r\n```\r\n=========================== short test summary info ============================\r\nFAILED tests/test_dataset_cards.py::test_changed_dataset_card[blog_authorship_corpus]\r\n==== 1 failed, 3182 passed, 2763 skipped, 16 warnings in 201.23s (0:03:21) =====\r\n```",
"@lhoestq, apart from the dataset card, everything is OK with this PR: I tested it locally."
] | 1,626,795,890,000 | 1,626,873,118,000 | 1,626,873,118,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2685",
"html_url": "https://github.com/huggingface/datasets/pull/2685",
"diff_url": "https://github.com/huggingface/datasets/pull/2685.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2685.patch",
"merged_at": 1626873117000
} | This PR:
- Update the JSON metadata file, which previously was raising a `NonMatchingSplitsSizesError`
- Fix the codec of the data files (`latin_1` instead of `utf-8`), which previously was raising ` UnicodeDecodeError` for some files
Close #2679. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2685/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2685/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2684 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2684/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2684/comments | https://api.github.com/repos/huggingface/datasets/issues/2684/events | https://github.com/huggingface/datasets/pull/2684 | 948,771,753 | MDExOlB1bGxSZXF1ZXN0NjkzNTY0MDY4 | 2,684 | Print absolute local paths in load_dataset error messages | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,794,908,000 | 1,626,986,899,000 | 1,626,962,470,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2684",
"html_url": "https://github.com/huggingface/datasets/pull/2684",
"diff_url": "https://github.com/huggingface/datasets/pull/2684.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2684.patch",
"merged_at": 1626962470000
} | Use absolute local paths in the error messages of `load_dataset` as per @stas00's suggestion in https://github.com/huggingface/datasets/pull/2500#issuecomment-874891223 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2684/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2684/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2683 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2683/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2683/comments | https://api.github.com/repos/huggingface/datasets/issues/2683/events | https://github.com/huggingface/datasets/issues/2683 | 948,721,379 | MDU6SXNzdWU5NDg3MjEzNzk= | 2,683 | Cache directories changed due to recent changes in how config kwargs are handled | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,626,791,877,000 | 1,626,798,435,000 | 1,626,798,435,000 | MEMBER | null | null | null | Since #2659 I can see weird cache directory names with hashes in the config id, even though no additional config kwargs are passed. For example:
```python
from datasets import load_dataset_builder
c4_builder = load_dataset_builder("c4", "en")
print(c4_builder.cache_dir)
# /Users/quentinlhoest/.cache/huggingface/datasets/c4/en-174d3b7155eb68db/0.0.0/...
# instead of
# /Users/quentinlhoest/.cache/huggingface/datasets/c4/en/0.0.0/...
```
This issue could be annoying since it would simply ignore old cache directories for users, and regenerate datasets
cc @stas00 this is what you experienced a few days ago
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2683/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2683/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2682/comments | https://api.github.com/repos/huggingface/datasets/issues/2682/events | https://github.com/huggingface/datasets/pull/2682 | 948,713,137 | MDExOlB1bGxSZXF1ZXN0NjkzNTE2NjU2 | 2,682 | Fix c4 expected files | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,791,371,000 | 1,626,791,891,000 | 1,626,791,890,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2682",
"html_url": "https://github.com/huggingface/datasets/pull/2682",
"diff_url": "https://github.com/huggingface/datasets/pull/2682.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2682.patch",
"merged_at": 1626791890000
} | Some files were not registered in the list of expected files to download
Fix https://github.com/huggingface/datasets/issues/2677 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2682/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2682/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2681 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2681/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2681/comments | https://api.github.com/repos/huggingface/datasets/issues/2681/events | https://github.com/huggingface/datasets/issues/2681 | 948,708,645 | MDU6SXNzdWU5NDg3MDg2NDU= | 2,681 | 5 duplicate datasets | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Yes this was documented in the PR that added this hf->paperswithcode mapping (https://github.com/huggingface/datasets/pull/2404) and AFAICT those are slightly distinct datasets so I think it's a wontfix\r\n\r\nFor context on the paperswithcode mapping you can also refer to https://github.com/huggingface/huggingface_hub/pull/43 which contains a lot of background discussion ",
"Thanks for the antecedents. I close."
] | 1,626,791,100,000 | 1,626,795,857,000 | 1,626,795,857,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
In 5 cases, I could find a dataset on Paperswithcode which references two Hugging Face datasets as dataset loaders. They are:
- https://paperswithcode.com/dataset/multinli -> https://huggingface.co/datasets/multi_nli and https://huggingface.co/datasets/multi_nli_mismatch
<img width="838" alt="Capture d’écran 2021-07-20 à 16 33 58" src="https://user-images.githubusercontent.com/1676121/126342757-4625522a-f788-41a3-bd1f-2a8b9817bbf5.png">
- https://paperswithcode.com/dataset/squad -> https://huggingface.co/datasets/squad and https://huggingface.co/datasets/squad_v2
- https://paperswithcode.com/dataset/narrativeqa -> https://huggingface.co/datasets/narrativeqa and https://huggingface.co/datasets/narrativeqa_manual
- https://paperswithcode.com/dataset/hate-speech-and-offensive-language -> https://huggingface.co/datasets/hate_offensive and https://huggingface.co/datasets/hate_speech_offensive
- https://paperswithcode.com/dataset/newsph-nli -> https://huggingface.co/datasets/newsph and https://huggingface.co/datasets/newsph_nli
Possible solutions:
- don't fix (it works)
- for each pair of duplicate datasets, remove one, and create an alias to the other.
## Steps to reproduce the bug
Visit the Paperswithcode links, and look at the "Dataset Loaders" section
## Expected results
There should only be one reference to a Hugging Face dataset loader
## Actual results
Two Hugging Face dataset loaders
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2681/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2681/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2680 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2680/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2680/comments | https://api.github.com/repos/huggingface/datasets/issues/2680/events | https://github.com/huggingface/datasets/pull/2680 | 948,649,716 | MDExOlB1bGxSZXF1ZXN0NjkzNDYyNzY3 | 2,680 | feat: 🎸 add paperswithcode id for qasper dataset | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,787,349,000 | 1,626,789,850,000 | 1,626,789,850,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2680",
"html_url": "https://github.com/huggingface/datasets/pull/2680",
"diff_url": "https://github.com/huggingface/datasets/pull/2680.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2680.patch",
"merged_at": 1626789850000
} | The reverse reference exists on paperswithcode:
https://paperswithcode.com/dataset/qasper | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2680/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2680/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2679 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2679/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2679/comments | https://api.github.com/repos/huggingface/datasets/issues/2679/events | https://github.com/huggingface/datasets/issues/2679 | 948,506,638 | MDU6SXNzdWU5NDg1MDY2Mzg= | 2,679 | Cannot load the blog_authorship_corpus due to codec errors | {
"login": "izaskr",
"id": 38069449,
"node_id": "MDQ6VXNlcjM4MDY5NDQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/38069449?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/izaskr",
"html_url": "https://github.com/izaskr",
"followers_url": "https://api.github.com/users/izaskr/followers",
"following_url": "https://api.github.com/users/izaskr/following{/other_user}",
"gists_url": "https://api.github.com/users/izaskr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/izaskr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/izaskr/subscriptions",
"organizations_url": "https://api.github.com/users/izaskr/orgs",
"repos_url": "https://api.github.com/users/izaskr/repos",
"events_url": "https://api.github.com/users/izaskr/events{/privacy}",
"received_events_url": "https://api.github.com/users/izaskr/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @izaskr, thanks for reporting.\r\n\r\nHowever the traceback you joined does not correspond to the codec error message: it is about other error `NonMatchingSplitsSizesError`. Maybe you missed some important part of your traceback...\r\n\r\nI'm going to have a look at the dataset anyway...",
"Hi @izaskr, thanks again for having reported this issue.\r\n\r\nAfter investigation, I have created a Pull Request (#2685) to fix several issues with this dataset:\r\n- the `NonMatchingSplitsSizesError`\r\n- the `UnicodeDecodeError`\r\n\r\nOnce the Pull Request merged into master, you will be able to load this dataset if you install `datasets` from our GitHub repository master branch. Otherwise, you will be able to use it after our next release, by updating `datasets`: `pip install -U datasets`.",
"@albertvillanova \r\nCan you shed light on how this fix works?\r\n\r\nWe're experiencing a similar issue. \r\n\r\nIf we run several runs (eg in a Wandb sweep) the first run \"works\" but then we get `NonMatchingSplitsSizesError`\r\n\r\n| run num | actual train examples # | expected example # | recorded example # |\r\n| ------- | -------------- | ----------------- | -------- |\r\n| 1 | 100 | 100 | 100 |\r\n| 2 | 102 | 100 | 102 |\r\n| 3 | 100 | 100 | 202 | \r\n| 4 | 40 | 100 | 40 |\r\n| 5 | 40 | 100 | 40 |\r\n| 6 | 40 | 100 | 40 | \r\n\r\n\r\nThe second through the nth all crash with \r\n\r\n```\r\ndatasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=19980970, num_examples=100, dataset_name='cies'), 'recorded': SplitInfo(name='train', num_bytes=40163811, num_examples=202, dataset_name='cies')}]\r\n\r\n```"
] | 1,626,776,000,000 | 1,626,886,941,000 | 1,626,873,118,000 | NONE | null | null | null | ## Describe the bug
A codec error is raised while loading the blog_authorship_corpus.
## Steps to reproduce the bug
```
from datasets import load_dataset
raw_datasets = load_dataset("blog_authorship_corpus")
```
## Expected results
Loading the dataset without errors.
## Actual results
An error similar to the one below was raised for (what seems like) every XML file.
/home/izaskr/.cache/huggingface/datasets/downloads/extracted/7cf52524f6517e168604b41c6719292e8f97abbe8f731e638b13423f4212359a/blogs/788358.male.24.Arts.Libra.xml cannot be loaded. Error message: 'utf-8' codec can't decode byte 0xe7 in position 7551: invalid continuation byte
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/izaskr/anaconda3/envs/local_vae_older/lib/python3.8/site-packages/datasets/load.py", line 856, in load_dataset
builder_instance.download_and_prepare(
File "/home/izaskr/anaconda3/envs/local_vae_older/lib/python3.8/site-packages/datasets/builder.py", line 583, in download_and_prepare
self._download_and_prepare(
File "/home/izaskr/anaconda3/envs/local_vae_older/lib/python3.8/site-packages/datasets/builder.py", line 671, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/home/izaskr/anaconda3/envs/local_vae_older/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 74, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='train', num_bytes=614706451, num_examples=535568, dataset_name='blog_authorship_corpus')}, {'expected': SplitInfo(name='validation', num_bytes=37500394, num_examples=31277, dataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='validation', num_bytes=32553710, num_examples=28521, dataset_name='blog_authorship_corpus')}]
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.0
- Platform: Linux-4.15.0-132-generic-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2679/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2679/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2678/comments | https://api.github.com/repos/huggingface/datasets/issues/2678/events | https://github.com/huggingface/datasets/issues/2678 | 948,471,222 | MDU6SXNzdWU5NDg0NzEyMjI= | 2,678 | Import Error in Kaggle notebook | {
"login": "prikmm",
"id": 47216475,
"node_id": "MDQ6VXNlcjQ3MjE2NDc1",
"avatar_url": "https://avatars.githubusercontent.com/u/47216475?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/prikmm",
"html_url": "https://github.com/prikmm",
"followers_url": "https://api.github.com/users/prikmm/followers",
"following_url": "https://api.github.com/users/prikmm/following{/other_user}",
"gists_url": "https://api.github.com/users/prikmm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/prikmm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/prikmm/subscriptions",
"organizations_url": "https://api.github.com/users/prikmm/orgs",
"repos_url": "https://api.github.com/users/prikmm/repos",
"events_url": "https://api.github.com/users/prikmm/events{/privacy}",
"received_events_url": "https://api.github.com/users/prikmm/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"This looks like an issue with PyArrow. Did you try reinstalling it ?",
"@lhoestq I did, and then let pip handle the installation in `pip import datasets`. I also tried using conda but it gives the same error.\r\n\r\nEdit: pyarrow version on kaggle is 4.0.0, it gets replaced with 4.0.1. So, I don't think uninstalling will change anything.\r\n```\r\nInstall Trace of datasets:\r\n\r\nCollecting datasets\r\n Downloading datasets-1.9.0-py3-none-any.whl (262 kB)\r\n |████████████████████████████████| 262 kB 834 kB/s eta 0:00:01\r\nRequirement already satisfied: dill in /opt/conda/lib/python3.7/site-packages (from datasets) (0.3.4)\r\nCollecting pyarrow!=4.0.0,>=1.0.0\r\n Downloading pyarrow-4.0.1-cp37-cp37m-manylinux2014_x86_64.whl (21.8 MB)\r\n |████████████████████████████████| 21.8 MB 6.2 MB/s eta 0:00:01\r\nRequirement already satisfied: importlib-metadata in /opt/conda/lib/python3.7/site-packages (from datasets) (3.4.0)\r\nRequirement already satisfied: huggingface-hub<0.1.0 in /opt/conda/lib/python3.7/site-packages (from datasets) (0.0.8)\r\nRequirement already satisfied: pandas in /opt/conda/lib/python3.7/site-packages (from datasets) (1.2.4)\r\nRequirement already satisfied: requests>=2.19.0 in /opt/conda/lib/python3.7/site-packages (from datasets) (2.25.1)\r\nRequirement already satisfied: fsspec>=2021.05.0 in /opt/conda/lib/python3.7/site-packages (from datasets) (2021.6.1)\r\nRequirement already satisfied: multiprocess in /opt/conda/lib/python3.7/site-packages (from datasets) (0.70.12.2)\r\nRequirement already satisfied: packaging in /opt/conda/lib/python3.7/site-packages (from datasets) (20.9)\r\nCollecting xxhash\r\n Downloading xxhash-2.0.2-cp37-cp37m-manylinux2010_x86_64.whl (243 kB)\r\n |████████████████████████████████| 243 kB 23.7 MB/s eta 0:00:01\r\nRequirement already satisfied: numpy>=1.17 in /opt/conda/lib/python3.7/site-packages (from datasets) (1.19.5)\r\nRequirement already satisfied: tqdm>=4.27 in /opt/conda/lib/python3.7/site-packages (from datasets) (4.61.1)\r\nRequirement already satisfied: filelock in /opt/conda/lib/python3.7/site-packages (from huggingface-hub<0.1.0->datasets) (3.0.12)\r\nRequirement already satisfied: urllib3<1.27,>=1.21.1 in /opt/conda/lib/python3.7/site-packages (from requests>=2.19.0->datasets) (1.26.5)\r\nRequirement already satisfied: idna<3,>=2.5 in /opt/conda/lib/python3.7/site-packages (from requests>=2.19.0->datasets) (2.10)\r\nRequirement already satisfied: certifi>=2017.4.17 in /opt/conda/lib/python3.7/site-packages (from requests>=2.19.0->datasets) (2021.5.30)\r\nRequirement already satisfied: chardet<5,>=3.0.2 in /opt/conda/lib/python3.7/site-packages (from requests>=2.19.0->datasets) (4.0.0)\r\nRequirement already satisfied: typing-extensions>=3.6.4 in /opt/conda/lib/python3.7/site-packages (from importlib-metadata->datasets) (3.7.4.3)\r\nRequirement already satisfied: zipp>=0.5 in /opt/conda/lib/python3.7/site-packages (from importlib-metadata->datasets) (3.4.1)\r\nRequirement already satisfied: pyparsing>=2.0.2 in /opt/conda/lib/python3.7/site-packages (from packaging->datasets) (2.4.7)\r\nRequirement already satisfied: python-dateutil>=2.7.3 in /opt/conda/lib/python3.7/site-packages (from pandas->datasets) (2.8.1)\r\nRequirement already satisfied: pytz>=2017.3 in /opt/conda/lib/python3.7/site-packages (from pandas->datasets) (2021.1)\r\nRequirement already satisfied: six>=1.5 in /opt/conda/lib/python3.7/site-packages (from python-dateutil>=2.7.3->pandas->datasets) (1.15.0)\r\nInstalling collected packages: xxhash, pyarrow, datasets\r\n Attempting uninstall: pyarrow\r\n Found existing installation: pyarrow 4.0.0\r\n Uninstalling pyarrow-4.0.0:\r\n Successfully uninstalled pyarrow-4.0.0\r\nSuccessfully installed datasets-1.9.0 pyarrow-4.0.1 xxhash-2.0.2\r\nWARNING: Running pip as root will break packages and permissions. You should install packages reliably by using venv: https://pip.pypa.io/warnings/venv\r\n```",
"You may need to restart your kaggle notebook after installing a newer version of `pyarrow`.\r\n\r\nIf it doesn't work we'll probably have to create an issue on [arrow's JIRA](https://issues.apache.org/jira/projects/ARROW/issues/), and maybe ask kaggle why it could fail",
"> You may need to restart your kaggle notebook before after installing a newer version of `pyarrow`.\r\n> \r\n> If it doesn't work we'll probably have to create an issue on [arrow's JIRA](https://issues.apache.org/jira/projects/ARROW/issues/), and maybe ask kaggle why it could fail\r\n\r\nIt works after restarting.\r\nMy bad, I forgot to restart the notebook. Sorry for the trouble!"
] | 1,626,773,318,000 | 1,626,875,966,000 | 1,626,872,582,000 | NONE | null | null | null | ## Describe the bug
Not able to import datasets library in kaggle notebooks
## Steps to reproduce the bug
```python
!pip install datasets
import datasets
```
## Expected results
No such error
## Actual results
```
ImportError Traceback (most recent call last)
<ipython-input-9-652e886d387f> in <module>
----> 1 import datasets
/opt/conda/lib/python3.7/site-packages/datasets/__init__.py in <module>
31 )
32
---> 33 from .arrow_dataset import Dataset, concatenate_datasets
34 from .arrow_reader import ArrowReader, ReadInstruction
35 from .arrow_writer import ArrowWriter
/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py in <module>
36 import pandas as pd
37 import pyarrow as pa
---> 38 import pyarrow.compute as pc
39 from multiprocess import Pool, RLock
40 from tqdm.auto import tqdm
/opt/conda/lib/python3.7/site-packages/pyarrow/compute.py in <module>
16 # under the License.
17
---> 18 from pyarrow._compute import ( # noqa
19 Function,
20 FunctionOptions,
ImportError: /opt/conda/lib/python3.7/site-packages/pyarrow/_compute.cpython-37m-x86_64-linux-gnu.so: undefined symbol: _ZNK5arrow7compute15KernelSignature8ToStringEv
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.0
- Platform: Kaggle
- Python version: 3.7.10
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2678/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2678/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2677/comments | https://api.github.com/repos/huggingface/datasets/issues/2677/events | https://github.com/huggingface/datasets/issues/2677 | 948,429,788 | MDU6SXNzdWU5NDg0Mjk3ODg= | 2,677 | Error when downloading C4 | {
"login": "Aktsvigun",
"id": 36672861,
"node_id": "MDQ6VXNlcjM2NjcyODYx",
"avatar_url": "https://avatars.githubusercontent.com/u/36672861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Aktsvigun",
"html_url": "https://github.com/Aktsvigun",
"followers_url": "https://api.github.com/users/Aktsvigun/followers",
"following_url": "https://api.github.com/users/Aktsvigun/following{/other_user}",
"gists_url": "https://api.github.com/users/Aktsvigun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Aktsvigun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aktsvigun/subscriptions",
"organizations_url": "https://api.github.com/users/Aktsvigun/orgs",
"repos_url": "https://api.github.com/users/Aktsvigun/repos",
"events_url": "https://api.github.com/users/Aktsvigun/events{/privacy}",
"received_events_url": "https://api.github.com/users/Aktsvigun/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi Thanks for reporting !\r\nIt looks like these files are not correctly reported in the list of expected files to download, let me fix that ;)",
"Alright this is fixed now. We'll do a new release soon to make the fix available.\r\n\r\nIn the meantime feel free to simply pass `ignore_verifications=True` to `load_dataset` to skip this error",
"@lhoestq thank you for such a quick feedback!"
] | 1,626,770,250,000 | 1,626,792,091,000 | 1,626,791,890,000 | NONE | null | null | null | Hi,
I am trying to download `en` corpus from C4 dataset. However, I get an error caused by validation files download (see image). My code is very primitive:
`datasets.load_dataset('c4', 'en')`
Is this a bug or do I have some configurations missing on my server?
Thanks!
<img width="1014" alt="Снимок экрана 2021-07-20 в 11 37 17" src="https://user-images.githubusercontent.com/36672861/126289448-6e0db402-5f3f-485a-bf74-eb6e0271fc25.png"> | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2677/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2677/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2676/comments | https://api.github.com/repos/huggingface/datasets/issues/2676/events | https://github.com/huggingface/datasets/pull/2676 | 947,734,909 | MDExOlB1bGxSZXF1ZXN0NjkyNjc2NTg5 | 2,676 | Increase json reader block_size automatically | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,706,274,000 | 1,626,717,099,000 | 1,626,717,098,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2676",
"html_url": "https://github.com/huggingface/datasets/pull/2676",
"diff_url": "https://github.com/huggingface/datasets/pull/2676.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2676.patch",
"merged_at": 1626717098000
} | Currently some files can't be read with the default parameters of the JSON lines reader.
For example this one:
https://huggingface.co/datasets/thomwolf/codeparrot/resolve/main/file-000000000006.json.gz
raises a pyarrow error:
```python
ArrowInvalid: straddling object straddles two block boundaries (try to increase block size?)
```
The block size that is used is the default one by pyarrow (related to this [jira issue](https://issues.apache.org/jira/browse/ARROW-9612)).
To fix this issue I changed the block_size to increase automatically if there is a straddling issue when parsing a batch of json lines.
By default the value is `chunksize // 32` in order to leverage multithreading, and it doubles every time a straddling issue occurs. The block_size is then reset for each file.
cc @thomwolf @albertvillanova | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2676/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2676/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2675/comments | https://api.github.com/repos/huggingface/datasets/issues/2675/events | https://github.com/huggingface/datasets/pull/2675 | 947,657,732 | MDExOlB1bGxSZXF1ZXN0NjkyNjEwNTA1 | 2,675 | Parallelize ETag requests | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,701,442,000 | 1,626,723,205,000 | 1,626,723,205,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2675",
"html_url": "https://github.com/huggingface/datasets/pull/2675",
"diff_url": "https://github.com/huggingface/datasets/pull/2675.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2675.patch",
"merged_at": 1626723205000
} | Since https://github.com/huggingface/datasets/pull/2628 we use the ETag or the remote data files to compute the directory in the cache where a dataset is saved. This is useful in order to reload the dataset from the cache only if the remote files haven't changed.
In this I made the ETag requests parallel using multithreading. There is also a tqdm progress bar that shows up if there are more than 16 data files. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2675/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2675/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2674/comments | https://api.github.com/repos/huggingface/datasets/issues/2674/events | https://github.com/huggingface/datasets/pull/2674 | 947,338,202 | MDExOlB1bGxSZXF1ZXN0NjkyMzMzODU3 | 2,674 | Fix sacrebleu parameter name | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,678,446,000 | 1,626,682,023,000 | 1,626,682,023,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2674",
"html_url": "https://github.com/huggingface/datasets/pull/2674",
"diff_url": "https://github.com/huggingface/datasets/pull/2674.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2674.patch",
"merged_at": 1626682023000
} | DONE:
- Fix parameter name: `smooth` to `smooth_method`.
- Improve kwargs description.
- Align docs on using a metric.
- Add example of passing additional arguments in using metrics.
Related to #2669. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2674/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2674/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2673/comments | https://api.github.com/repos/huggingface/datasets/issues/2673/events | https://github.com/huggingface/datasets/pull/2673 | 947,300,008 | MDExOlB1bGxSZXF1ZXN0NjkyMzAxMTgw | 2,673 | Fix potential DuplicatedKeysError in SQuAD | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,674,880,000 | 1,626,678,483,000 | 1,626,678,483,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2673",
"html_url": "https://github.com/huggingface/datasets/pull/2673",
"diff_url": "https://github.com/huggingface/datasets/pull/2673.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2673.patch",
"merged_at": 1626678483000
} | DONE:
- Fix potential DiplicatedKeysError by ensuring keys are unique.
- Align examples in the docs with SQuAD code.
We should promote as a good practice, that the keys should be programmatically generated as unique, instead of read from data (which might be not unique). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2673/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2673/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2672/comments | https://api.github.com/repos/huggingface/datasets/issues/2672/events | https://github.com/huggingface/datasets/pull/2672 | 947,294,605 | MDExOlB1bGxSZXF1ZXN0NjkyMjk2NDQ4 | 2,672 | Fix potential DuplicatedKeysError in LibriSpeech | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,626,674,449,000 | 1,626,676,137,000 | 1,626,676,136,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2672",
"html_url": "https://github.com/huggingface/datasets/pull/2672",
"diff_url": "https://github.com/huggingface/datasets/pull/2672.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2672.patch",
"merged_at": 1626676136000
} | DONE:
- Fix unnecessary path join.
- Fix potential DiplicatedKeysError by ensuring keys are unique.
We should promote as a good practice, that the keys should be programmatically generated as unique, instead of read from data (which might be not unique). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2672/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2672/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2671/comments | https://api.github.com/repos/huggingface/datasets/issues/2671/events | https://github.com/huggingface/datasets/pull/2671 | 947,273,875 | MDExOlB1bGxSZXF1ZXN0NjkyMjc5MTM0 | 2,671 | Mesinesp development and training data sets have been added. | {
"login": "aslihanuysall",
"id": 32900185,
"node_id": "MDQ6VXNlcjMyOTAwMTg1",
"avatar_url": "https://avatars.githubusercontent.com/u/32900185?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aslihanuysall",
"html_url": "https://github.com/aslihanuysall",
"followers_url": "https://api.github.com/users/aslihanuysall/followers",
"following_url": "https://api.github.com/users/aslihanuysall/following{/other_user}",
"gists_url": "https://api.github.com/users/aslihanuysall/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aslihanuysall/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aslihanuysall/subscriptions",
"organizations_url": "https://api.github.com/users/aslihanuysall/orgs",
"repos_url": "https://api.github.com/users/aslihanuysall/repos",
"events_url": "https://api.github.com/users/aslihanuysall/events{/privacy}",
"received_events_url": "https://api.github.com/users/aslihanuysall/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"It'll be new pull request with new commits."
] | 1,626,671,678,000 | 1,626,679,948,000 | 1,626,677,150,000 | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2671",
"html_url": "https://github.com/huggingface/datasets/pull/2671",
"diff_url": "https://github.com/huggingface/datasets/pull/2671.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2671.patch",
"merged_at": null
} | https://zenodo.org/search?page=1&size=20&q=mesinesp, Mesinesp has Medical Semantic Indexed records in Spanish. Indexing is done using DeCS codes, a sort of Spanish equivalent to MeSH terms.
The Mesinesp (Spanish BioASQ track, see https://temu.bsc.es/mesinesp) development set has a total of 750 records.
The Mesinesp (Spanish BioASQ track, see https://temu.bsc.es/mesinesp) training set has a total of 369,368 records.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2671/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2671/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2670/comments | https://api.github.com/repos/huggingface/datasets/issues/2670/events | https://github.com/huggingface/datasets/issues/2670 | 947,120,709 | MDU6SXNzdWU5NDcxMjA3MDk= | 2,670 | Using sharding to parallelize indexing | {
"login": "ggdupont",
"id": 5583410,
"node_id": "MDQ6VXNlcjU1ODM0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/5583410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ggdupont",
"html_url": "https://github.com/ggdupont",
"followers_url": "https://api.github.com/users/ggdupont/followers",
"following_url": "https://api.github.com/users/ggdupont/following{/other_user}",
"gists_url": "https://api.github.com/users/ggdupont/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ggdupont/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ggdupont/subscriptions",
"organizations_url": "https://api.github.com/users/ggdupont/orgs",
"repos_url": "https://api.github.com/users/ggdupont/repos",
"events_url": "https://api.github.com/users/ggdupont/events{/privacy}",
"received_events_url": "https://api.github.com/users/ggdupont/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,626,643,586,000 | 1,633,613,605,000 | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
Creating an elasticsearch index on large dataset could be quite long and cannot be parallelized on shard (the index creation is colliding)
**Describe the solution you'd like**
When working on dataset shards, if an index already exists, its mapping should be checked and if compatible, the indexing process should continue with the shard data.
Additionally, at the end of the process, the `_indexes` dict should be send back to the original dataset object (from which the shards have been created) to allow to use the index for later filtering on the whole dataset.
**Describe alternatives you've considered**
Each dataset shard could created independent partial indices. then on the whole dataset level, indices should be all referred in `_indexes` dict and be used in querying through `get_nearest_examples()`. The drawback is that the scores will be computed independently on the partial indices leading to inconsistent values for most scoring based on corpus level statistics (tf/idf, BM25).
**Additional context**
The objectives is to parallelize the index creation to speed-up the process (ie surcharging the ES server which is fine to handle large load) while later enabling search on the whole dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/2670/reactions",
"total_count": 3,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/2670/timeline | null | false |