Datasets:

metadata
license: openrail
task_categories:
- conversational
language:
- aa
tags:
- music
size_categories:
- n<1K
pretty_name: genshin_voice_sovits
效果预览
本仓库用于预览训练出的各种语音模型的效果,点击角色名自动跳转对应训练参数。
正常说话的音色转换较为准确,歌曲包含较广的音域且bgm和声等难以去除干净,效果有所折扣。
有推荐的歌想要转换听听效果,或者其他内容建议,点我发起讨论
下面是预览音频,左右滑动可以看到全部
| 角色名 | 角色原声A | 被转换人声B | A音色替换B | A音色翻唱(点击直接下载) |
|---|---|---|---|---|
| 散兵 | 夢で会えたら | |||
| 胡桃 | ......... | ......... | moonlight shadow, 云烟成雨, 原点, 夢で逢えたら, 贝加尔湖畔 | |
| 神里绫华 | アムリタ, 大鱼, 遊園施設, the day you want away |
关键参数:
audio duration:训练集总时长 epoch: 轮数
其余:
batch_size = 一个step训练的片段数
segments = 音频被切分的片段
step=segments*epoch/batch_size,即模型文件后面数字由来
以散兵为例:
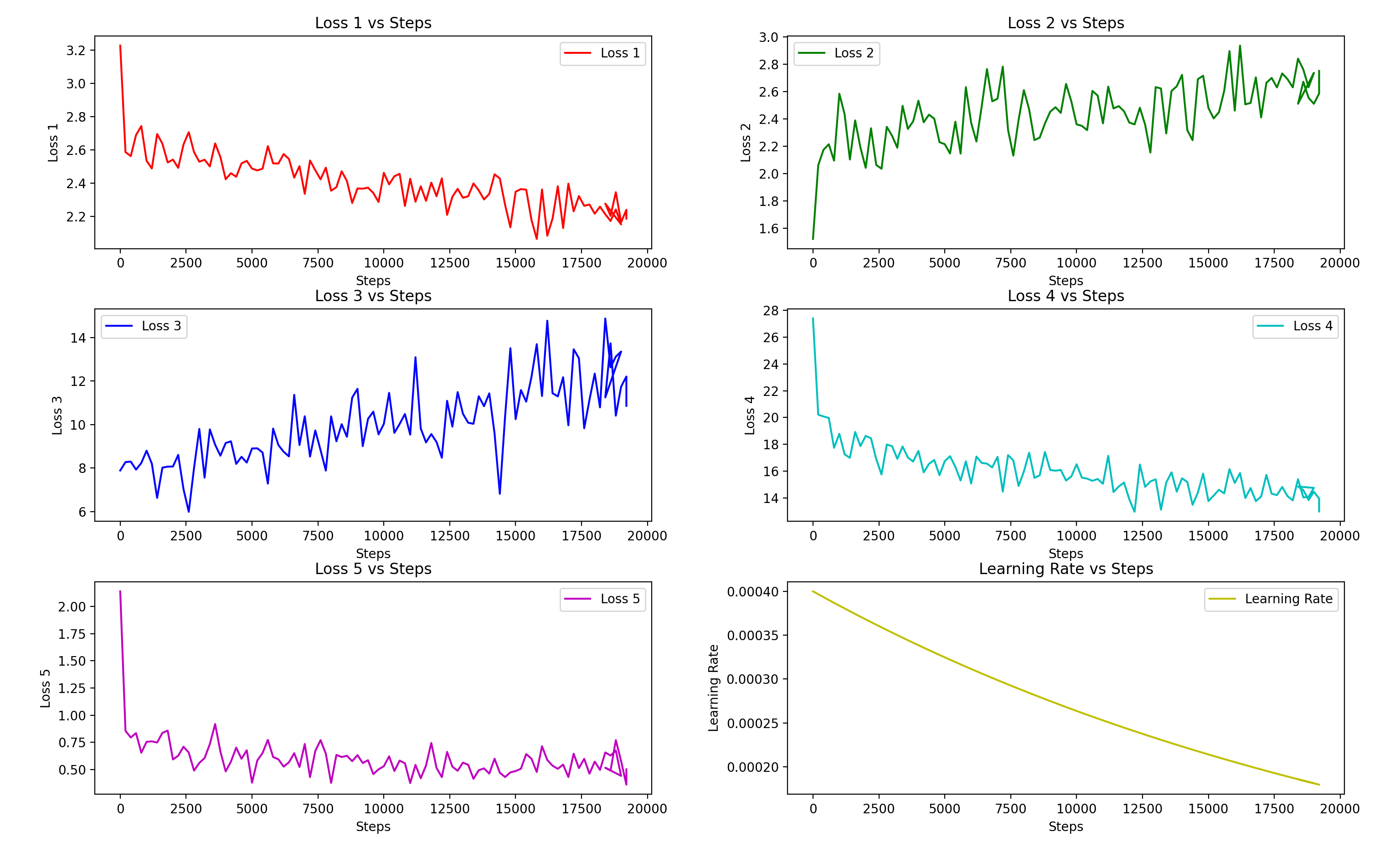
损失函数图像:主要看step 与 loss5,比如:
给一个大致的参考,待转换音频都为高音女生,这是较为刁钻的测试:如图,10min纯净人声,
差不多2800epoch(10000step)就已经出结果了,实际使用的是5571epoch(19500step)的文件,被训练音色和原音色相差几
何,差不多有个概念。当然即使loss也不足以参考,唯一的衡量标准就是当事人的耳朵。当然,正常训练,10min还是有些少的。