Datasets:


task_categories:
- text-classification
language:
- en
task_ids:
- sentiment-classification
- hate-speech-detection
size_categories:
- 10K<n<100K
Tweet Annotation Sensitivity Experiment 2: Annotations in Five Experimental Conditions
Attention: This repository contains cases that might be offensive or upsetting. We do not support the views expressed in these hateful posts.
Description
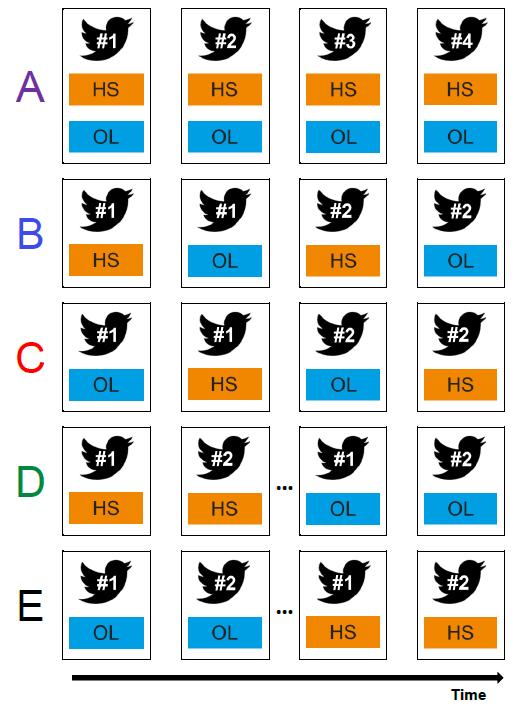
The dataset contains tweet data annotations of hate speech (HS) and offensive language (OL) in five experimental conditions. The tweet data was sampled from the corpus created by Davidson et al. (2017). We selected 3,000 Tweets for our annotation. We developed five experimental conditions that varied the annotation task structure, as shown in the following figure. All tweets were annotated in each condition.
Condition A presented the tweet and three options on a single screen: hate speech, offensive language, or neither. Annotators could select one or both of hate speech, offensive language, or indicate that neither applied.
Conditions B and C split the annotation of a single tweet across two screens.
- For Condition B, the first screen prompted the annotator to indicate whether the tweet contained hate speech. On the following screen, they were shown the tweet again and asked whether it contained offensive language.
- Condition C was similar to Condition B, but flipped the order of hate speech and offensive language for each tweet.
In Conditions D and E, the two tasks are treated independently with annotators being asked to first annotate all tweets for one task, followed by annotating all tweets again for the second task.
- Annotators assigned Condition D were first asked to annotate hate speech for all their assigned tweets, and then asked to annotate offensive language for the same set of tweets.
- Condition E worked the same way, but started with the offensive language annotation task followed by the hate speech annotation task.
We recruited US-based annotators from the crowdsourcing platform Prolific during November and December 2022. Each annotator annotated up to 50 tweets. The dataset also contains demographic information about the annotators. Annotators received a fixed hourly wage in excess of the US federal minimum wage after completing the task.
Codebook
| Column Name | Description | Type |
|---|---|---|
| case_id | case ID | integer |
| duration_seconds | duration of connection to task in seconds | integer |
| last_screen | last question answered | factor |
| device | device type | factor |
| ethn_hispanic | Hispanic race/ethnicity | binary |
| ethn_white | White race/ethnicity | binary |
| ethn_afr_american | African-American race/ethnicity | binary |
| ethn_asian | Asian race/ethnicity | binary |
| ethn_sth_else | race/ethnicity something else | binary |
| ethn_prefer_not | race/ethnicity prefer not to say | binary |
| age | age | integer |
| education | education attainment 1: Less than high school 2: High school 3: Some college 4: College graduate 5: Master's degree or professional degree (law, medicine, MPH, etc.) 6: Doctoral degree (PhD, DPH, EdD, etc.) |
factor |
| english_fl | English as first language | binary |
| twitter_use | Twitter use frequency 1: Most days 2: Most weeks, but not every day 3: A few times a month 4: A few times a year 5: Less often 6: Never |
factor |
| socmedia_use | social media use frequency 1: Most days 2: Most weeks, but not every day 3: A few times a month 4: A few times a year 5: Less often 6: Never |
factor |
| prolific_hours | workload on the platform prolific in hours in the last month | integer |
| task_fun | task perception: fun | binary |
| task_interesting | task perception: interesting | binary |
| task_boring | task perception: boring | binary |
| task_repetitive | task perception: repetitive | binary |
| task_important | task perception: important | binary |
| task_depressing | task perception: depressing | binary |
| task_offensive | task perception: offensive | binary |
| repeat_tweet_coding | likelihood for another tweet task 1: Not at all likely 2: Somewhat likely 3: Very likely |
factor |
| repeat_hs_coding | likelihood for another hate speech task 1: Not at all likely 2: Somewhat likely 3: Very likely |
factor |
| target_online_harassment | targeted by hateful online behavior | binary |
| target_other_harassment | targeted by other hateful behavior | binary |
| party_affiliation | party identification 1: Republican 2: Democrat 3: Independent |
factor |
| societal_relevance_hs | relevance perception of hate speech 1: Not at all likely 2: Somewhat likely 3: Very likely |
factor |
| annotator_id | annotator ID | integer |
| condition | experimental conditions (A-E) | factor |
| tweet_batch | tweet ID in batch | factor |
| hate_speech | hate speech annotation | logical |
| offensive_language | offensive language annotation | logical |
| tweet_id | tweet ID | integer |
| orig_label_hs | number of persons who annotated the tweet as hate speech in the original dataset from Davidson et al. (2017) | integer |
| orig_label_ol | number of persons who annotated the tweet as offensive language in the original dataset from Davidson et al. (2017) | integer |
| orig_label_ne | number of persons who annotated the tweet as neither in the original dataset from Davidson et al. (2017) | integer |
| tweet_hashed | tweet with usernames hashed | character |
Citation
If you find the dataset useful, please cite:
@inproceedings{kern-etal-2023-annotation,
title = "Annotation Sensitivity: Training Data Collection Methods Affect Model Performance",
author = "Kern, Christoph and
Eckman, Stephanie and
Beck, Jacob and
Chew, Rob and
Ma, Bolei and
Kreuter, Frauke",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.992",
pages = "14874--14886",
}
@inproceedings{beck-etal-2024-order,
title = "Order Effects in Annotation Tasks: Further Evidence of Annotation Sensitivity",
author = "Beck, Jacob and
Eckman, Stephanie and
Ma, Bolei and
Chew, Rob and
Kreuter, Frauke",
editor = {V{\'a}zquez, Ra{\'u}l and
Celikkanat, Hande and
Ulmer, Dennis and
Tiedemann, J{\"o}rg and
Swayamdipta, Swabha and
Aziz, Wilker and
Plank, Barbara and
Baan, Joris and
de Marneffe, Marie-Catherine},
booktitle = "Proceedings of the 1st Workshop on Uncertainty-Aware NLP (UncertaiNLP 2024)",
month = mar,
year = "2024",
address = "St Julians, Malta",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.uncertainlp-1.8",
pages = "81--86",
}