

license: apache-2.0
language:
- en
pretty_name: STEM
size_categories:
- 1M<n<10M
tags:
- stem
- benchmark
STEM Dataset
📃 [Paper] • 💻 [Github] • 🤗 [Dataset] • 🏆 [Leaderboard] • 📽 [Slides] • 📋 [Poster]
This dataset is proposed in the ICLR 2024 paper: Measuring Vision-Language STEM Skills of Neural Models. The problems in the real world often require solutions, combining knowledge from STEM (science, technology, engineering, and math). Unlike existing datasets, our dataset requires the understanding of multimodal vision-language information of STEM. Our dataset features one of the largest and most comprehensive datasets for the challenge. It includes 448 skills and 1,073,146 questions spanning all STEM subjects. Compared to existing datasets that often focus on examining expert-level ability, our dataset includes fundamental skills and questions designed based on the K-12 curriculum. We also add state-of-the-art foundation models such as CLIP and GPT-3.5-Turbo to our benchmark. Results show that the recent model advances only help master a very limited number of lower grade-level skills (2.5% in the third grade) in our dataset. In fact, these models are still well below (averaging 54.7%) the performance of elementary students, not to mention near expert-level performance. To understand and increase the performance on our dataset, we teach the models on a training split of our dataset. Even though we observe improved performance, the model performance remains relatively low compared to average elementary students. To solve STEM problems, we will need novel algorithmic innovations from the community.
Authors
Jianhao Shen*, Ye Yuan*, Srbuhi Mirzoyan, Ming Zhang, Chenguang Wang
Resources
- Code: https://github.com/stemdataset/STEM
- Paper: https://arxiv.org/abs/2402.17205
- Leaderboard: https://huggingface.co/spaces/stemdataset/stem-leaderboard
Dataset
The dataset consists of multimodal multichoice questions. The dataset is spllited in to train, valid and test sets. The groundtruth answers of the test set are not released and everyone can submit the test predictions to the leaderboard. The basic statistics of the dataset are as follows:
| Subject | #Skills | #Questions | Avg. #A | #Train | #Valid | #Test |
|---|---|---|---|---|---|---|
| Science | 82 | 186,740 | 2.8 | 112,120 | 37,343 | 37,277 |
| Technology | 9 | 8,566 | 4.0 | 5,140 | 1,713 | 1,713 |
| Engineering | 6 | 18,981 | 2.5 | 12,055 | 3,440 | 3,486 |
| Math | 351 | 858,859 | 2.8 | 515,482 | 171,776 | 171,601 |
| Total | 448 | 1,073,146 | 2.8 | 644,797 | 214,272 | 214,077 |
The dataset is in the following format:
DatasetDict({
train: Dataset({
features: ['subject', 'grade', 'skill', 'pic_choice', 'pic_prob', 'problem', 'problem_pic', 'choices', 'choices_pic', 'answer_idx'],
num_rows: 644797
})
valid: Dataset({
features: ['subject', 'grade', 'skill', 'pic_choice', 'pic_prob', 'problem', 'problem_pic', 'choices', 'choices_pic', 'answer_idx'],
num_rows: 214272
})
test: Dataset({
features: ['subject', 'grade', 'skill', 'pic_choice', 'pic_prob', 'problem', 'problem_pic', 'choices', 'choices_pic', 'answer_idx'],
num_rows: 214077
})
})
And the detailed descriptions are as follows:
subject:str- The subject of the question, one of
science,technology,engineer,math.
- The subject of the question, one of
grade:str- The grade level information of the question, e.g.,
grade-1.
- The grade level information of the question, e.g.,
skill:str- The skill level information of the question.
pic_choice:bool- Whether the choices are images.
pic_prob:bool- Whether the question has an image.
problem:str- The question description.
problem_pic:bytes- The image of the question.
choices:Optional[List[str]]- The choices of the question. If
pic_choiceisTrue, the choices are images and will be saved intochoices_pic, and thechoiceswith be set toNone.
- The choices of the question. If
choices_pic:Optional[List[bytes]]- The choices images. If
pic_choiceisFalse, the choices are strings and will be saved intochoices, and thechoices_picwith be set toNone.
- The choices images. If
answer_idx:int- The index of the correct answer in the
choicesorchoices_pic. If the split istest, theanswer_idxis-1.
- The index of the correct answer in the
The bytes can be easily read by the following code:
from PIL import Image
def bytes_to_image(img_bytes: bytes) -> Image:
img = Image.open(io.BytesIO(img_bytes))
return img
Example Questions
Questions containing images
Question: What is the domain of this function?
Image:

Choices: ["{x | x <= -6}", "all real numbers", "{x | x > 3}", "{x | x >= 0}"]
Answer: 1
Metadata:
{
"subject": "math",
"grade": "algebra-1",
"skill": "domain-and-range-of-absolute-value-functions-graphs",
"pic_choice": false,
"pic_prob": true,
"problem": "What is the domain of this function?",
"problem_pic": "b'\\x89PNG\\r\\n\\x1a\\n\\x00\\x00\\x00\\rIHDR\\x00\\x00\\x02\\xd8'...",
"choices": [
"$\\{x \\mid x \\leq -6\\}$",
"all real numbers",
"$\\{x \\mid x > 3\\}$",
"$\\{x \\mid x \\geq 0\\}$"
],
"choices_pic": null,
"answer_idx": 1
}
Choices containing images
Question: The three scatter plots below show the same data set. Choose the scatter plot in which the outlier is highlighted.
Choices:
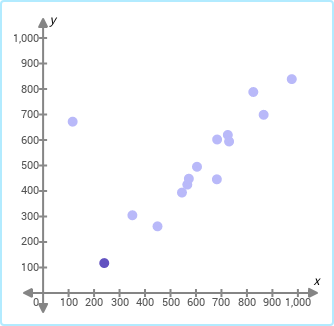
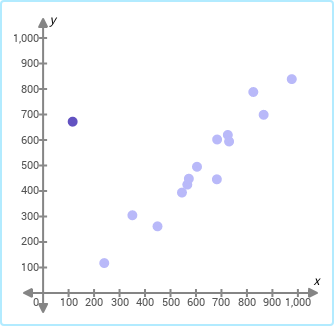
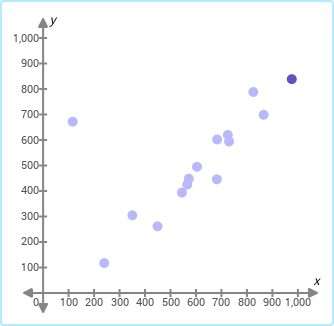
Answer: 1
Metadata:
{
"subject": "math",
"grade": "precalculus",
"skill": "outliers-in-scatter-plots",
"pic_choice": true,
"pic_prob": false,
"problem": "The three scatter plots below show the same data set. Choose the scatter plot in which the outlier is highlighted.",
"problem_pic": null,
"choices": null,
"choices_pic": [
"b'\\x89PNG\\r\\n\\x1a\\n\\x00\\x00\\x00\\rIHDR\\x00\\x00\\x01N'...",
"b'\\x89PNG\\r\\n\\x1a\\n\\x00\\x00\\x00\\rIHDR\\x00\\x00\\x01N'...",
"b'\\x89PNG\\r\\n\\x1a\\n\\x00\\x00\\x00\\rIHDR\\x00\\x00\\x01N'..."
],
"answer_idx": 1
}
How to Use
Please refer to our code for the usage of evaluation on the dataset.
Citation
@inproceedings{shen2024measuring,
title={Measuring Vision-Language STEM Skills of Neural Models},
author={Shen, Jianhao and Yuan, Ye and Mirzoyan, Srbuhi and Zhang, Ming and Wang, Chenguang},
booktitle={ICLR},
year={2024}
}