
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.5B
| node_id
stringlengths 18
32
| number
int64 1
5.38k
| title
stringlengths 1
276
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
sequence | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | author_association
stringclasses 3
values | active_lock_reason
null | draft
bool 2
classes | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | is_pull_request
bool 1
class |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5379 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5379/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5379/comments | https://api.github.com/repos/huggingface/datasets/issues/5379/events | https://github.com/huggingface/datasets/pull/5379 | 1,504,010,639 | PR_kwDODunzps5F1r2k | 5,379 | feat: depth estimation dataset guide. | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
}
] | null | [] | 2022-12-20T05:32:11Z | 2022-12-20T05:42:02Z | null | CONTRIBUTOR | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5379.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5379",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5379.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5379"
} | This PR adds a guide for prepping datasets for depth estimation.
PR to add documentation images is up here: https://huggingface.co/datasets/huggingface/documentation-images/discussions/22 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5379/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5379/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5378/comments | https://api.github.com/repos/huggingface/datasets/issues/5378/events | https://github.com/huggingface/datasets/issues/5378 | 1,503,887,508 | I_kwDODunzps5Zo4CU | 5,378 | The dataset "the_pile", subset "enron_emails" , load_dataset() failure | {
"avatar_url": "https://avatars.githubusercontent.com/u/52023469?v=4",
"events_url": "https://api.github.com/users/shaoyuta/events{/privacy}",
"followers_url": "https://api.github.com/users/shaoyuta/followers",
"following_url": "https://api.github.com/users/shaoyuta/following{/other_user}",
"gists_url": "https://api.github.com/users/shaoyuta/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shaoyuta",
"id": 52023469,
"login": "shaoyuta",
"node_id": "MDQ6VXNlcjUyMDIzNDY5",
"organizations_url": "https://api.github.com/users/shaoyuta/orgs",
"received_events_url": "https://api.github.com/users/shaoyuta/received_events",
"repos_url": "https://api.github.com/users/shaoyuta/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shaoyuta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shaoyuta/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shaoyuta"
} | [] | closed | false | null | [] | null | [] | 2022-12-20T02:19:13Z | 2022-12-20T07:52:54Z | 2022-12-20T07:52:54Z | NONE | null | null | null | ### Describe the bug
When run
"datasets.load_dataset("the_pile","enron_emails")" failure

### Steps to reproduce the bug
Run below code in python cli:
>>> import datasets
>>> datasets.load_dataset("the_pile","enron_emails")
### Expected behavior
Load dataset "the_pile", "enron_emails" successfully.
### Environment info
Copy-and-paste the text below in your GitHub issue.
- `datasets` version: 2.7.1
- Platform: Linux-5.15.0-53-generic-x86_64-with-glibc2.35
- Python version: 3.10.6
- PyArrow version: 10.0.0
- Pandas version: 1.4.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5378/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5378/timeline | null | completed | true |
https://api.github.com/repos/huggingface/datasets/issues/5377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5377/comments | https://api.github.com/repos/huggingface/datasets/issues/5377/events | https://github.com/huggingface/datasets/pull/5377 | 1,503,477,833 | PR_kwDODunzps5Fz5lw | 5,377 | Add a parallel implementation of to_tf_dataset() | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1"
} | [] | open | false | null | [] | null | [] | 2022-12-19T19:40:27Z | 2022-12-19T19:45:06Z | null | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5377.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5377",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5377.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5377"
} | Hey all! Here's a first draft of the PR to add a multiprocessing implementation for `to_tf_dataset()`. It worked in some quick testing for me, but obviously I need to do some much more rigorous testing/benchmarking, and add some proper library tests.
The core idea is that we do everything using `multiprocessing` and `numpy`, and just wrap a `tf.data.Dataset` around the output. We could also rewrite the existing single-threaded implementation based on this code, which might simplify it a bit.
Checklist:
- [X] Add initial draft
- [x] Check that it works regardless of whether the `collate_fn` or dataset returns `tf` or `np` arrays
- [ ] Check that it works with `tf.string` return data
- [ ] Check indices are correctly reshuffled each epoch
- [ ] Check `fit()` with multiple epochs works fine and that the progress bar is correct
- [ ] Check there are no memory leaks or zombie processes
- [ ] Benchmark performance
- [ ] Tweak params for dataset inference - can we speed things up there a bit?
- [ ] Add tests to the library
- [ ] Add a PR to `transformers` to expose the `num_workers` argument via `prepare_tf_dataset` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5377/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5376/comments | https://api.github.com/repos/huggingface/datasets/issues/5376/events | https://github.com/huggingface/datasets/pull/5376 | 1,502,730,559 | PR_kwDODunzps5FxWkM | 5,376 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | 2022-12-19T10:56:56Z | 2022-12-19T11:01:55Z | 2022-12-19T10:57:16Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5376.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5376",
"merged_at": "2022-12-19T10:57:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5376.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5376"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5376/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5376/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5375/comments | https://api.github.com/repos/huggingface/datasets/issues/5375/events | https://github.com/huggingface/datasets/pull/5375 | 1,502,720,404 | PR_kwDODunzps5FxUbG | 5,375 | Release: 2.8.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | 2022-12-19T10:48:26Z | 2022-12-19T10:55:43Z | 2022-12-19T10:53:15Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5375",
"merged_at": "2022-12-19T10:53:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5375"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5375/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5374/comments | https://api.github.com/repos/huggingface/datasets/issues/5374/events | https://github.com/huggingface/datasets/issues/5374 | 1,501,872,945 | I_kwDODunzps5ZhMMx | 5,374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | {
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_url": "https://api.github.com/users/Muennighoff/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Muennighoff",
"id": 62820084,
"login": "Muennighoff",
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"organizations_url": "https://api.github.com/users/Muennighoff/orgs",
"received_events_url": "https://api.github.com/users/Muennighoff/received_events",
"repos_url": "https://api.github.com/users/Muennighoff/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Muennighoff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Muennighoff/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Muennighoff"
} | [] | open | false | null | [] | null | [] | 2022-12-18T11:38:58Z | 2022-12-19T16:33:31Z | null | CONTRIBUTOR | null | null | null | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/huggingface/datasets/pull/3050
### Steps to reproduce the bug
Running
```python
c4 = datasets.load_dataset("c4", "en", split="train", streaming=True).skip(args.start).take(args.end-args.start)
df = pd.DataFrame(c4, index=None)
```
with different start & end arguments on 200 CPUs in parallel yields:
```
WARNING:datasets.load:Using the latest cached version of the module from /users/muennighoff/.cache/huggingface/modules/datasets_modules/datasets/c4/df532b158939272d032cc63ef19cd5b83e9b4d00c922b833e4cb18b2e9869b01 (last modified on Mon Dec 12 10:45:02 2022) since it couldn't be found locally at c4.
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [1/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [2/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [3/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [4/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [5/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [6/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [7/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [8/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [9/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [10/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [11/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [12/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [13/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [14/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [15/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [16/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [17/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [18/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [19/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [20/20]
╭───────────────────── Traceback (most recent call last) ──────────────────────╮
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/dec-2022-tasky/inference │
│ _c4.py:68 in <module> │
│ │
│ 65 │ model.eval() │
│ 66 │ │
│ 67 │ c4 = datasets.load_dataset("c4", "en", split="train", streaming=Tru │
│ ❱ 68 │ df = pd.DataFrame(c4, index=None) │
│ 69 │ texts = df["text"].to_list() │
│ 70 │ preds = batch_inference(texts, batch_size=args.batch_size) │
│ 71 │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/site-packages/pandas/core/frame.p │
│ y:684 in __init__ │
│ │
│ 681 │ │ # For data is list-like, or Iterable (will consume into list │
│ 682 │ │ elif is_list_like(data): │
│ 683 │ │ │ if not isinstance(data, (abc.Sequence, ExtensionArray)): │
│ ❱ 684 │ │ │ │ data = list(data) │
│ 685 │ │ │ if len(data) > 0: │
│ 686 │ │ │ │ if is_dataclass(data[0]): │
│ 687 │ │ │ │ │ data = dataclasses_to_dicts(data) │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:751 in __iter__ │
│ │
│ 748 │ │ yield from ex_iterable.shard_data_sources(shard_idx) │
│ 749 │ │
│ 750 │ def __iter__(self): │
│ ❱ 751 │ │ for key, example in self._iter(): │
│ 752 │ │ │ if self.features: │
│ 753 │ │ │ │ # `IterableDataset` automatically fills missing colum │
│ 754 │ │ │ │ # This is done with `_apply_feature_types`. │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:741 in _iter │
│ │
│ 738 │ │ │ ex_iterable = self._ex_iterable.shuffle_data_sources(self │
│ 739 │ │ else: │
│ 740 │ │ │ ex_iterable = self._ex_iterable │
│ ❱ 741 │ │ yield from ex_iterable │
│ 742 │ │
│ 743 │ def _iter_shard(self, shard_idx: int): │
│ 744 │ │ if self._shuffling: │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:617 in __iter__ │
│ │
│ 614 │ │ self.n = n │
│ 615 │ │
│ 616 │ def __iter__(self): │
│ ❱ 617 │ │ yield from islice(self.ex_iterable, self.n) │
│ 618 │ │
│ 619 │ def shuffle_data_sources(self, generator: np.random.Generator) -> │
│ 620 │ │ """Doesn't shuffle the wrapped examples iterable since it wou │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:594 in __iter__ │
│ │
│ 591 │ │
│ 592 │ def __iter__(self): │
│ 593 │ │ #ex_iterator = iter(self.ex_iterable) │
│ ❱ 594 │ │ yield from islice(self.ex_iterable, self.n, None) │
│ 595 │ │ #for _ in range(self.n): │
│ 596 │ │ # next(ex_iterator) │
│ 597 │ │ #yield from islice(ex_iterator, self.n, None) │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:106 in __iter__ │
│ │
│ 103 │ │ self.kwargs = kwargs │
│ 104 │ │
│ 105 │ def __iter__(self): │
│ ❱ 106 │ │ yield from self.generate_examples_fn(**self.kwargs) │
│ 107 │ │
│ 108 │ def shuffle_data_sources(self, generator: np.random.Generator) -> │
│ 109 │ │ return ShardShuffledExamplesIterable(self.generate_examples_f │
│ │
│ /users/muennighoff/.cache/huggingface/modules/datasets_modules/datasets/c4/d │
│ f532b158939272d032cc63ef19cd5b83e9b4d00c922b833e4cb18b2e9869b01/c4.py:89 in │
│ _generate_examples │
│ │
│ 86 │ │ for filepath in filepaths: │
│ 87 │ │ │ logger.info("generating examples from = %s", filepath) │
│ 88 │ │ │ with gzip.open(open(filepath, "rb"), "rt", encoding="utf-8" │
│ ❱ 89 │ │ │ │ for line in f: │
│ 90 │ │ │ │ │ if line: │
│ 91 │ │ │ │ │ │ example = json.loads(line) │
│ 92 │ │ │ │ │ │ yield id_, example │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/gzip.py:313 in read1 │
│ │
│ 310 │ │ │
│ 311 │ │ if size < 0: │
│ 312 │ │ │ size = io.DEFAULT_BUFFER_SIZE │
│ ❱ 313 │ │ return self._buffer.read1(size) │
│ 314 │ │
│ 315 │ def peek(self, n): │
│ 316 │ │ self._check_not_closed() │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/_compression.py:68 in readinto │
│ │
│ 65 │ │
│ 66 │ def readinto(self, b): │
│ 67 │ │ with memoryview(b) as view, view.cast("B") as byte_view: │
│ ❱ 68 │ │ │ data = self.read(len(byte_view)) │
│ 69 │ │ │ byte_view[:len(data)] = data │
│ 70 │ │ return len(data) │
│ 71 │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/gzip.py:493 in read │
│ │
│ 490 │ │ │ │ self._new_member = False │
│ 491 │ │ │ │
│ 492 │ │ │ # Read a chunk of data from the file │
│ ❱ 493 │ │ │ buf = self._fp.read(io.DEFAULT_BUFFER_SIZE) │
│ 494 │ │ │ │
│ 495 │ │ │ uncompress = self._decompressor.decompress(buf, size) │
│ 496 │ │ │ if self._decompressor.unconsumed_tail != b"": │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/gzip.py:96 in read │
│ │
│ 93 │ │ │ read = self._read │
│ 94 │ │ │ self._read = None │
│ 95 │ │ │ return self._buffer[read:] + \ │
│ ❱ 96 │ │ │ │ self.file.read(size-self._length+read) │
│ 97 │ │
│ 98 │ def prepend(self, prepend=b''): │
│ 99 │ │ if self._read is None: │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/download/streaming_download_manager.py: │
│ 365 in read_with_retries │
│ │
│ 362 │ │ │ │ ) │
│ 363 │ │ │ │ time.sleep(config.STREAMING_READ_RETRY_INTERVAL) │
│ 364 │ │ else: │
│ ❱ 365 │ │ │ raise ConnectionError("Server Disconnected") │
│ 366 │ │ return out │
│ 367 │ │
│ 368 │ file_obj.read = read_with_retries │
╰──────────────────────────────────────────────────────────────────────────────╯
ConnectionError: Server Disconnected
```
### Expected behavior
There should be no disconnect I think.
### Environment info
```
datasets=2.7.0
Python 3.9.12
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5374/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5374/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5373/comments | https://api.github.com/repos/huggingface/datasets/issues/5373/events | https://github.com/huggingface/datasets/pull/5373 | 1,501,484,197 | PR_kwDODunzps5FtRU4 | 5,373 | Simplify skipping | {
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_url": "https://api.github.com/users/Muennighoff/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Muennighoff",
"id": 62820084,
"login": "Muennighoff",
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"organizations_url": "https://api.github.com/users/Muennighoff/orgs",
"received_events_url": "https://api.github.com/users/Muennighoff/received_events",
"repos_url": "https://api.github.com/users/Muennighoff/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Muennighoff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Muennighoff/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Muennighoff"
} | [] | closed | false | null | [] | null | [] | 2022-12-17T17:23:52Z | 2022-12-18T21:43:31Z | 2022-12-18T21:40:21Z | CONTRIBUTOR | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5373.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5373",
"merged_at": "2022-12-18T21:40:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5373.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5373"
} | Was hoping to find a way to speed up the skipping as I'm running into bottlenecks skipping 100M examples on C4 (it takes 12 hours to skip), but didn't find anything better than this small change :(
Maybe there's a way to directly skip whole shards to speed it up? 🧐 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5373/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5373/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5372 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5372/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5372/comments | https://api.github.com/repos/huggingface/datasets/issues/5372/events | https://github.com/huggingface/datasets/pull/5372 | 1,501,377,802 | PR_kwDODunzps5Fs9w5 | 5,372 | Fix xpandas_read_excel | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | open | false | null | [] | null | [] | 2022-12-17T12:58:52Z | 2022-12-19T09:33:03Z | null | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5372.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5372",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5372.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5372"
} | This PR fixes `xpandas_read_excel`:
- Support passing a path string, besides a file-like object
- Support passing `use_auth_token`
- First assumes the host server supports HTTP range requests; only if a ValueError is thrown (Cannot seek streaming HTTP file), then if preserves previous behavior (see [#3355](https://github.com/huggingface/datasets/pull/3355)).
Fix https://huggingface.co/datasets/bigbio/meqsum/discussions/1
Fix:
- https://github.com/bigscience-workshop/biomedical/issues/801
Related to:
- #3355 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5372/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5372/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5371 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5371/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5371/comments | https://api.github.com/repos/huggingface/datasets/issues/5371/events | https://github.com/huggingface/datasets/issues/5371 | 1,501,369,036 | I_kwDODunzps5ZfRLM | 5,371 | Add a robustness benchmark dataset for vision | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
}
] | null | [] | 2022-12-17T12:35:13Z | 2022-12-20T06:21:41Z | null | CONTRIBUTOR | null | null | null | ### Name
ImageNet-C
### Paper
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
### Data
https://github.com/hendrycks/robustness
### Motivation
It's a known fact that vision models are brittle when they meet with slightly corrupted and perturbed data. This is also correlated to the robustness aspects of vision models.
Researchers use different benchmark datasets to evaluate the robustness aspects of vision models. ImageNet-C is one of them.
Having this dataset in 🤗 Datasets would allow researchers to evaluate and study the robustness aspects of vision models. Since the metric associated with these evaluations is top-1 accuracy, researchers should be able to easily take advantage of the evaluation benchmarks on the Hub and perform comprehensive reporting.
ImageNet-C is a large dataset. Once it's in, it can act as a reference and we can also reach out to the authors of the other robustness benchmark datasets in vision, such as ObjectNet, WILDS, Metashift, etc. These datasets cater to different aspects. For example, ObjectNet is related to assessing how well a model performs under sub-population shifts.
Related thread: https://huggingface.slack.com/archives/C036H4A5U8Z/p1669994598060499 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5371/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5371/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5369/comments | https://api.github.com/repos/huggingface/datasets/issues/5369/events | https://github.com/huggingface/datasets/pull/5369 | 1,500,622,276 | PR_kwDODunzps5Fqaj- | 5,369 | Distributed support | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | open | false | null | [] | null | [] | 2022-12-16T17:43:47Z | 2022-12-16T18:21:30Z | null | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5369.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5369",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5369.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5369"
} | To split your dataset across your training nodes, you can use the new [`datasets.distributed.split_dataset_by_node`]:
```python
import os
from datasets.distributed import split_dataset_by_node
ds = split_dataset_by_node(ds, rank=int(os.environ["RANK"]), world_size=int(os.environ["WORLD_SIZE"]))
```
This works for both map-style datasets and iterable datasets.
The dataset is split for the node at rank `rank` in a pool of nodes of size `world_size`.
For map-style datasets:
Each node is assigned a chunk of data, e.g. rank 0 is given the first chunk of the dataset.
For iterable datasets:
If the dataset has a number of shards that is a factor of `world_size` (i.e. if `dataset.n_shards % world_size == 0`),
then the shards are evenly assigned across the nodes, which is the most optimized.
Otherwise, each node keeps 1 example out of `world_size`, skipping the other examples.
This can also be combined with a `torch.utils.data.DataLoader` if you want each node to use multiple workers to load the data.
This also supports shuffling. At each epoch, the iterable dataset shards are reshuffled across all the nodes - you just have to call `iterable_ds.set_epoch(epoch_number)`.
TODO:
- [x] docs for usage in PyTorch
- [x] unit tests
- [x] integration tests with torch.distributed.launch
Related to https://github.com/huggingface/transformers/issues/20770
Close https://github.com/huggingface/datasets/issues/5360 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5369/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5369/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5368 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5368/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5368/comments | https://api.github.com/repos/huggingface/datasets/issues/5368/events | https://github.com/huggingface/datasets/pull/5368 | 1,500,322,973 | PR_kwDODunzps5FpZyx | 5,368 | Align remove columns behavior and input dict mutation in `map` with previous behavior | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [] | 2022-12-16T14:28:47Z | 2022-12-16T16:28:08Z | 2022-12-16T16:25:12Z | CONTRIBUTOR | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5368.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5368",
"merged_at": "2022-12-16T16:25:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5368.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5368"
} | Align the `remove_columns` behavior and input dict mutation in `map` with the behavior before https://github.com/huggingface/datasets/pull/5252. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5368/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5368/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5367 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5367/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5367/comments | https://api.github.com/repos/huggingface/datasets/issues/5367/events | https://github.com/huggingface/datasets/pull/5367 | 1,499,174,749 | PR_kwDODunzps5FlevK | 5,367 | Fix remove columns from lazy dict | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | 2022-12-15T22:04:12Z | 2022-12-15T22:27:53Z | 2022-12-15T22:24:50Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5367.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5367",
"merged_at": "2022-12-15T22:24:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5367.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5367"
} | This was introduced in https://github.com/huggingface/datasets/pull/5252 and causing the transformers CI to break: https://app.circleci.com/pipelines/github/huggingface/transformers/53886/workflows/522faf2e-a053-454c-94f8-a617fde33393/jobs/648597
Basically this code should return a dataset with only one column:
```python
from datasets import *
ds = Dataset.from_dict({"a": range(5)})
def f(x):
x["b"] = x["a"]
return x
ds = ds.map(f, remove_columns=["a"])
assert ds.column_names == ["b"]
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5367/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5367/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5366/comments | https://api.github.com/repos/huggingface/datasets/issues/5366/events | https://github.com/huggingface/datasets/pull/5366 | 1,498,530,851 | PR_kwDODunzps5FjSFl | 5,366 | ExamplesIterable fixes | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | 2022-12-15T14:23:05Z | 2022-12-15T14:44:47Z | 2022-12-15T14:41:45Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5366.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5366",
"merged_at": "2022-12-15T14:41:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5366.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5366"
} | fix typing and ExamplesIterable.shard_data_sources | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5366/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5366/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5365/comments | https://api.github.com/repos/huggingface/datasets/issues/5365/events | https://github.com/huggingface/datasets/pull/5365 | 1,498,422,466 | PR_kwDODunzps5Fi6ZD | 5,365 | fix: image array should support other formats than uint8 | {
"avatar_url": "https://avatars.githubusercontent.com/u/30353?v=4",
"events_url": "https://api.github.com/users/vigsterkr/events{/privacy}",
"followers_url": "https://api.github.com/users/vigsterkr/followers",
"following_url": "https://api.github.com/users/vigsterkr/following{/other_user}",
"gists_url": "https://api.github.com/users/vigsterkr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vigsterkr",
"id": 30353,
"login": "vigsterkr",
"node_id": "MDQ6VXNlcjMwMzUz",
"organizations_url": "https://api.github.com/users/vigsterkr/orgs",
"received_events_url": "https://api.github.com/users/vigsterkr/received_events",
"repos_url": "https://api.github.com/users/vigsterkr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vigsterkr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vigsterkr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vigsterkr"
} | [] | open | false | null | [] | null | [] | 2022-12-15T13:17:50Z | 2022-12-15T13:22:15Z | null | CONTRIBUTOR | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5365.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5365",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5365.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5365"
} | Currently images that are provided as ndarrays, but not in `uint8` format are going to loose data. Namely, for example in a depth image where the data is in float32 format, the type-casting to uint8 will basically make the whole image blank.
`PIL.Image.fromarray` [does support mode `F`](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#concept-modes).
although maybe some further metadata could be supplied via the [Image](https://huggingface.co/docs/datasets/v2.7.1/en/package_reference/main_classes#datasets.Image) object. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5365/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5365/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5364 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5364/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5364/comments | https://api.github.com/repos/huggingface/datasets/issues/5364/events | https://github.com/huggingface/datasets/pull/5364 | 1,498,360,628 | PR_kwDODunzps5Fiss1 | 5,364 | Support for writing arrow files directly with BeamWriter | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | open | false | null | [] | null | [] | 2022-12-15T12:38:05Z | 2022-12-19T17:05:00Z | null | CONTRIBUTOR | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5364.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5364",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5364.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5364"
} | Make it possible to write Arrow files directly with `BeamWriter` rather than converting from Parquet to Arrow, which is sub-optimal, especially for big datasets for which Beam is primarily used. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5364/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5364/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5363/comments | https://api.github.com/repos/huggingface/datasets/issues/5363/events | https://github.com/huggingface/datasets/issues/5363 | 1,498,171,317 | I_kwDODunzps5ZTEe1 | 5,363 | Dataset.from_generator() crashes on simple example | {
"avatar_url": "https://avatars.githubusercontent.com/u/2743060?v=4",
"events_url": "https://api.github.com/users/villmow/events{/privacy}",
"followers_url": "https://api.github.com/users/villmow/followers",
"following_url": "https://api.github.com/users/villmow/following{/other_user}",
"gists_url": "https://api.github.com/users/villmow/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/villmow",
"id": 2743060,
"login": "villmow",
"node_id": "MDQ6VXNlcjI3NDMwNjA=",
"organizations_url": "https://api.github.com/users/villmow/orgs",
"received_events_url": "https://api.github.com/users/villmow/received_events",
"repos_url": "https://api.github.com/users/villmow/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/villmow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/villmow/subscriptions",
"type": "User",
"url": "https://api.github.com/users/villmow"
} | [] | closed | false | null | [] | null | [] | 2022-12-15T10:21:28Z | 2022-12-15T11:51:33Z | 2022-12-15T11:51:33Z | NONE | null | null | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5363/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5363/timeline | null | completed | true |
https://api.github.com/repos/huggingface/datasets/issues/5362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5362/comments | https://api.github.com/repos/huggingface/datasets/issues/5362/events | https://github.com/huggingface/datasets/issues/5362 | 1,497,643,744 | I_kwDODunzps5ZRDrg | 5,362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | {
"avatar_url": "https://avatars.githubusercontent.com/u/52023469?v=4",
"events_url": "https://api.github.com/users/shaoyuta/events{/privacy}",
"followers_url": "https://api.github.com/users/shaoyuta/followers",
"following_url": "https://api.github.com/users/shaoyuta/following{/other_user}",
"gists_url": "https://api.github.com/users/shaoyuta/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shaoyuta",
"id": 52023469,
"login": "shaoyuta",
"node_id": "MDQ6VXNlcjUyMDIzNDY5",
"organizations_url": "https://api.github.com/users/shaoyuta/orgs",
"received_events_url": "https://api.github.com/users/shaoyuta/received_events",
"repos_url": "https://api.github.com/users/shaoyuta/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shaoyuta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shaoyuta/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shaoyuta"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | 2022-12-15T01:23:03Z | 2022-12-15T07:45:54Z | 2022-12-15T07:45:53Z | NONE | null | null | null | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
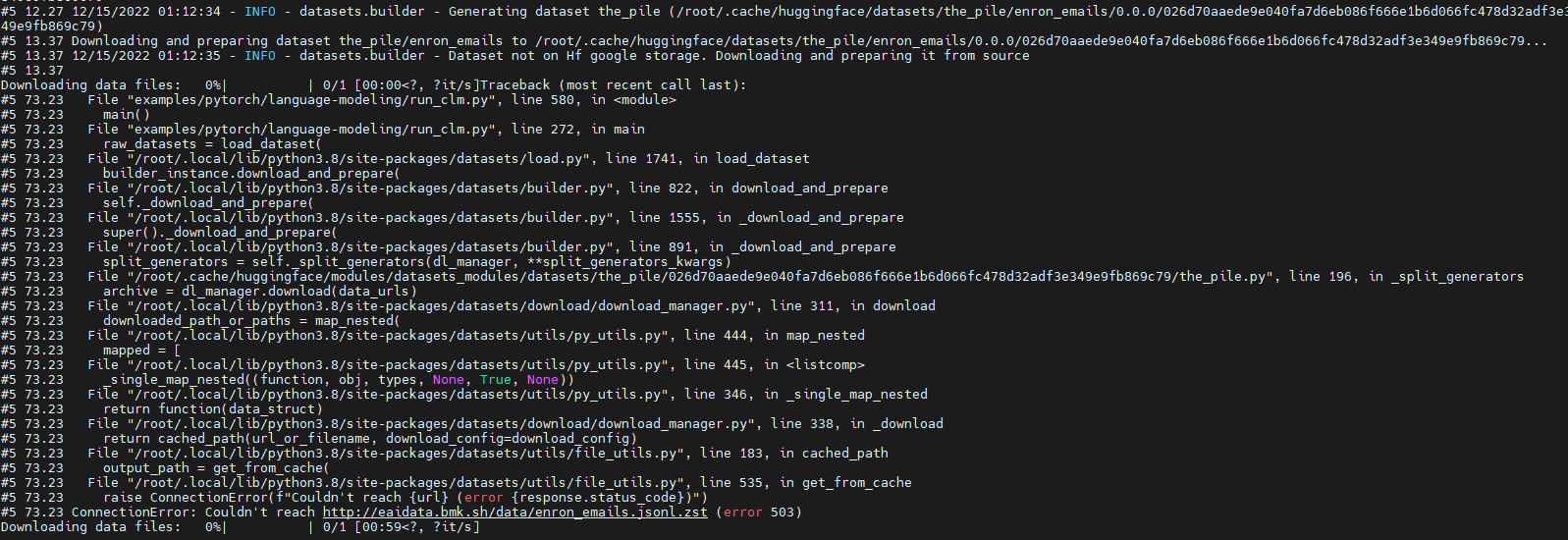
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to reproduce the bug
Steps to reproduce this issue:
git clone https://github.com/huggingface/transformers
cd transformers
python examples/pytorch/language-modeling/run_clm.py --model_name_or_path EleutherAI/gpt-j-6B --dataset_name the_pile --dataset_config_name enron_emails --do_eval --output_dir /tmp/output --overwrite_output_dir
### Expected behavior
This issue looks like due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst " couldn't be reached.
Is there another way to download the dataset "the_pile" ?
Is there another way to cache the dataset "the_pile" but not let the hg to download it when runtime ?
### Environment info
huggingface_hub version: 0.11.1
Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.35
Python version: 3.9.12
Running in iPython ?: No
Running in notebook ?: No
Running in Google Colab ?: No
Token path ?: /home/taosy/.huggingface/token
Has saved token ?: False
Configured git credential helpers:
FastAI: N/A
Tensorflow: N/A
Torch: N/A
Jinja2: N/A
Graphviz: N/A
Pydot: N/A | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5362/timeline | null | completed | true |
https://api.github.com/repos/huggingface/datasets/issues/5361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5361/comments | https://api.github.com/repos/huggingface/datasets/issues/5361/events | https://github.com/huggingface/datasets/issues/5361 | 1,497,153,889 | I_kwDODunzps5ZPMFh | 5,361 | How concatenate `Audio` elements using batch mapping | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"gists_url": "https://api.github.com/users/bayartsogt-ya/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bayartsogt-ya",
"id": 43239645,
"login": "bayartsogt-ya",
"node_id": "MDQ6VXNlcjQzMjM5NjQ1",
"organizations_url": "https://api.github.com/users/bayartsogt-ya/orgs",
"received_events_url": "https://api.github.com/users/bayartsogt-ya/received_events",
"repos_url": "https://api.github.com/users/bayartsogt-ya/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bayartsogt-ya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bayartsogt-ya/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bayartsogt-ya"
} | [] | open | false | null | [] | null | [] | 2022-12-14T18:13:55Z | 2022-12-15T10:53:28Z | null | NONE | null | null | null | ### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batch), 3)
dataset = dataset.map(mapper_function, batch=True, batch_size=24)
print(dataset)
# Expected output:
# Dataset({
# features: ['path', 'audio'],
# num_rows: 8
# })
```
I tried to construct `result={}` dictionary inside the mapper function, I just found it will not work because it needs `byte` also needed :((
I'd appreciate if your share any use cases similar to my problem or any solutions really. Thanks!
cc: @lhoestq
### Steps to reproduce the bug
1. load audio dataset
2. try to merge every k audios and return as one
### Expected behavior
Merged dataset with a fewer rows. If we merge every 3 rows, then `n // 3` number of examples.
### Environment info
- `datasets` version: 2.1.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5361/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5361/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5360 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5360/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5360/comments | https://api.github.com/repos/huggingface/datasets/issues/5360/events | https://github.com/huggingface/datasets/issues/5360 | 1,496,947,177 | I_kwDODunzps5ZOZnp | 5,360 | IterableDataset returns duplicated data using PyTorch DDP | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [] | 2022-12-14T16:06:19Z | 2022-12-16T17:47:20Z | null | MEMBER | null | null | null | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5360/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5360/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5359/comments | https://api.github.com/repos/huggingface/datasets/issues/5359/events | https://github.com/huggingface/datasets/pull/5359 | 1,495,297,857 | PR_kwDODunzps5FYHWm | 5,359 | Raise error if ClassLabel names is not python list | {
"avatar_url": "https://avatars.githubusercontent.com/u/1475568?v=4",
"events_url": "https://api.github.com/users/freddyheppell/events{/privacy}",
"followers_url": "https://api.github.com/users/freddyheppell/followers",
"following_url": "https://api.github.com/users/freddyheppell/following{/other_user}",
"gists_url": "https://api.github.com/users/freddyheppell/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/freddyheppell",
"id": 1475568,
"login": "freddyheppell",
"node_id": "MDQ6VXNlcjE0NzU1Njg=",
"organizations_url": "https://api.github.com/users/freddyheppell/orgs",
"received_events_url": "https://api.github.com/users/freddyheppell/received_events",
"repos_url": "https://api.github.com/users/freddyheppell/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/freddyheppell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/freddyheppell/subscriptions",
"type": "User",
"url": "https://api.github.com/users/freddyheppell"
} | [] | open | false | null | [] | null | [] | 2022-12-13T23:04:06Z | 2022-12-16T14:06:26Z | null | NONE | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5359.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5359",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5359.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5359"
} | Checks type of names provided to ClassLabel to avoid easy and hard to debug errors (closes #5332 - see for discussion) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5359/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5359/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5358/comments | https://api.github.com/repos/huggingface/datasets/issues/5358/events | https://github.com/huggingface/datasets/pull/5358 | 1,495,270,822 | PR_kwDODunzps5FYBcq | 5,358 | Fix `fs.open` resource leaks | {
"avatar_url": "https://avatars.githubusercontent.com/u/297847?v=4",
"events_url": "https://api.github.com/users/tkukurin/events{/privacy}",
"followers_url": "https://api.github.com/users/tkukurin/followers",
"following_url": "https://api.github.com/users/tkukurin/following{/other_user}",
"gists_url": "https://api.github.com/users/tkukurin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tkukurin",
"id": 297847,
"login": "tkukurin",
"node_id": "MDQ6VXNlcjI5Nzg0Nw==",
"organizations_url": "https://api.github.com/users/tkukurin/orgs",
"received_events_url": "https://api.github.com/users/tkukurin/received_events",
"repos_url": "https://api.github.com/users/tkukurin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tkukurin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tkukurin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tkukurin"
} | [] | open | false | null | [] | null | [] | 2022-12-13T22:35:51Z | 2022-12-15T17:09:22Z | null | NONE | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5358.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5358",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5358.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5358"
} | Invoking `{load,save}_from_dict` results in resource leak warnings, this should fix.
Introduces no significant logic changes. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5358/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5358/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5357 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5357/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5357/comments | https://api.github.com/repos/huggingface/datasets/issues/5357/events | https://github.com/huggingface/datasets/pull/5357 | 1,495,029,602 | PR_kwDODunzps5FXNyR | 5,357 | Support torch dataloader without torch formatting | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | 2022-12-13T19:39:24Z | 2022-12-15T19:19:29Z | 2022-12-15T19:15:54Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5357.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5357",
"merged_at": "2022-12-15T19:15:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5357.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5357"
} | In https://github.com/huggingface/datasets/pull/5084 we make the torch formatting consistent with the map-style datasets formatting: a torch formatted iterable dataset will yield torch tensors.
The previous behavior of the torch formatting for iterable dataset was simply to make the iterable dataset inherit from `torch.utils.data.Dataset` to make it work in a torch DataLoader. However ideally an unformatted dataset should also work with a DataLoader. To fix that, `datasets.IterableDataset` should inherit from `torch.utils.data.IterableDataset`.
Since we don't want to import torch on startup, I created this PR to dynamically make the `datasets.IterableDataset` class inherit form the torch one when a `datasets.IterableDataset` is instantiated and if PyTorch is available.
```python
>>> from datasets import load_dataset
>>> ds = load_dataset("c4", "en", streaming=True, split="train")
>>> import torch.utils.data
>>> isinstance(ds, torch.utils.data.IterableDataset)
True
>>> dataloader = torch.utils.data.DataLoader(ds, batch_size=32, num_workers=4)
>>> for example in dataloader:
...: ...
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5357/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5357/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5356/comments | https://api.github.com/repos/huggingface/datasets/issues/5356/events | https://github.com/huggingface/datasets/pull/5356 | 1,494,961,609 | PR_kwDODunzps5FW-c9 | 5,356 | Clean filesystem and logging docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [] | 2022-12-13T18:54:09Z | 2022-12-14T17:25:58Z | 2022-12-14T17:22:16Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5356.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5356",
"merged_at": "2022-12-14T17:22:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5356.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5356"
} | This PR cleans the `Filesystems` and `Logging` docstrings. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5356/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5356/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5355 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5355/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5355/comments | https://api.github.com/repos/huggingface/datasets/issues/5355/events | https://github.com/huggingface/datasets/pull/5355 | 1,493,076,860 | PR_kwDODunzps5FQcYG | 5,355 | Clean up Table class docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [] | 2022-12-13T00:29:47Z | 2022-12-13T18:17:56Z | 2022-12-13T18:14:42Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5355.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5355",
"merged_at": "2022-12-13T18:14:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5355.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5355"
} | This PR cleans up the `Table` class docstrings :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5355/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5355/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5354/comments | https://api.github.com/repos/huggingface/datasets/issues/5354/events | https://github.com/huggingface/datasets/issues/5354 | 1,492,174,125 | I_kwDODunzps5Y8MUt | 5,354 | Consider using "Sequence" instead of "List" | {
"avatar_url": "https://avatars.githubusercontent.com/u/15568078?v=4",
"events_url": "https://api.github.com/users/tranhd95/events{/privacy}",
"followers_url": "https://api.github.com/users/tranhd95/followers",
"following_url": "https://api.github.com/users/tranhd95/following{/other_user}",
"gists_url": "https://api.github.com/users/tranhd95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tranhd95",
"id": 15568078,
"login": "tranhd95",
"node_id": "MDQ6VXNlcjE1NTY4MDc4",
"organizations_url": "https://api.github.com/users/tranhd95/orgs",
"received_events_url": "https://api.github.com/users/tranhd95/received_events",
"repos_url": "https://api.github.com/users/tranhd95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tranhd95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tranhd95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tranhd95"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | open | false | null | [] | null | [] | 2022-12-12T15:39:45Z | 2022-12-16T21:02:44Z | null | NONE | null | null | null | ### Feature request
Hi, please consider using `Sequence` type annotation instead of `List` in function arguments such as in [`Dataset.from_parquet()`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L1088). It leads to type checking errors, see below.
**How to reproduce**
```py
list_of_filenames = ["foo.parquet", "bar.parquet"]
ds = Dataset.from_parquet(list_of_filenames)
```
**Expected mypy output:**
```
Success: no issues found
```
**Actual mypy output:**
```py
test.py:19: error: Argument 1 to "from_parquet" of "Dataset" has incompatible type "List[str]"; expected "Union[Union[str, bytes, PathLike[Any]], List[Union[str, bytes, PathLike[Any]]]]" [arg-type]
test.py:19: note: "List" is invariant -- see https://mypy.readthedocs.io/en/stable/common_issues.html#variance
test.py:19: note: Consider using "Sequence" instead, which is covariant
```
**Env:** mypy 0.991, Python 3.10.0, datasets 2.7.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5354/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5354/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5353/comments | https://api.github.com/repos/huggingface/datasets/issues/5353/events | https://github.com/huggingface/datasets/issues/5353 | 1,491,880,500 | I_kwDODunzps5Y7Eo0 | 5,353 | Support remote file systems for `Audio` | {
"avatar_url": "https://avatars.githubusercontent.com/u/46894149?v=4",
"events_url": "https://api.github.com/users/OllieBroadhurst/events{/privacy}",
"followers_url": "https://api.github.com/users/OllieBroadhurst/followers",
"following_url": "https://api.github.com/users/OllieBroadhurst/following{/other_user}",
"gists_url": "https://api.github.com/users/OllieBroadhurst/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/OllieBroadhurst",
"id": 46894149,
"login": "OllieBroadhurst",
"node_id": "MDQ6VXNlcjQ2ODk0MTQ5",
"organizations_url": "https://api.github.com/users/OllieBroadhurst/orgs",
"received_events_url": "https://api.github.com/users/OllieBroadhurst/received_events",
"repos_url": "https://api.github.com/users/OllieBroadhurst/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/OllieBroadhurst/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/OllieBroadhurst/subscriptions",
"type": "User",
"url": "https://api.github.com/users/OllieBroadhurst"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [] | 2022-12-12T13:22:13Z | 2022-12-12T13:37:14Z | 2022-12-12T13:37:14Z | NONE | null | null | null | ### Feature request
Hi there!
It would be super cool if `Audio()`, and potentially other features, could read files from a remote file system.
### Motivation
Large amounts of data is often stored in buckets. `load_from_disk` is able to retrieve data from cloud storage but to my knowledge actually copies the datasets across first, so if you're working off a system with smaller disk specs (like a VM), you can run out of space very quickly.
### Your contribution
Something like this (for Google Cloud Platform in this instance):
```python
from datasets import Dataset, Audio
import gcsfs
fs = gcsfs.GCSFileSystem()
list_of_audio_fp = {'audio': ['1', '2', '3']}
ds = Dataset.from_dict(list_of_audio_fp)
ds = ds.cast_column("audio", Audio(sampling_rate=16000, fs=fs))
```
Under the hood:
```python
import librosa
from io import BytesIO
def load_audio(fp, sampling_rate=None, fs=None):
if fs is not None:
with fs.open(fp, 'rb') as f:
arr, sr = librosa.load(BytesIO(f), sr=sampling_rate)
else:
# Perform existing io operations
```
Written from memory so some things could be wrong. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5353/timeline | null | completed | true |
https://api.github.com/repos/huggingface/datasets/issues/5352 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5352/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5352/comments | https://api.github.com/repos/huggingface/datasets/issues/5352/events | https://github.com/huggingface/datasets/issues/5352 | 1,490,796,414 | I_kwDODunzps5Y279- | 5,352 | __init__() got an unexpected keyword argument 'input_size' | {
"avatar_url": "https://avatars.githubusercontent.com/u/82662111?v=4",
"events_url": "https://api.github.com/users/J-shel/events{/privacy}",
"followers_url": "https://api.github.com/users/J-shel/followers",
"following_url": "https://api.github.com/users/J-shel/following{/other_user}",
"gists_url": "https://api.github.com/users/J-shel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/J-shel",
"id": 82662111,
"login": "J-shel",
"node_id": "MDQ6VXNlcjgyNjYyMTEx",
"organizations_url": "https://api.github.com/users/J-shel/orgs",
"received_events_url": "https://api.github.com/users/J-shel/received_events",
"repos_url": "https://api.github.com/users/J-shel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/J-shel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/J-shel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/J-shel"
} | [] | open | false | null | [] | null | [] | 2022-12-12T02:52:03Z | 2022-12-19T01:38:48Z | null | NONE | null | null | null | ### Describe the bug
I try to define a custom configuration with a input_size attribute following the instructions by "Specifying several dataset configurations" in https://huggingface.co/docs/datasets/v1.2.1/add_dataset.html
But when I load the dataset, I got an error "__init__() got an unexpected keyword argument 'input_size'"
### Steps to reproduce the bug
Following is the code to define the dataset:
class CsvConfig(datasets.BuilderConfig):
"""BuilderConfig for CSV."""
input_size: int = 2048
class MRF(datasets.ArrowBasedBuilder):
"""Archival MRF data"""
BUILDER_CONFIG_CLASS = CsvConfig
VERSION = datasets.Version("1.0.0")
BUILDER_CONFIGS = [
CsvConfig(name="default", version=VERSION, description="MRF data", input_size=2048),
]
...
def _generate_examples(self):
input_size = self.config.input_size
if input_size > 1000:
numin = 10000
else:
numin = 15000
Below is the code to load the dataset:
reader = load_dataset("default", input_size=1024)
### Expected behavior
I hope to pass the "input_size" parameter to MRF datasets, and change "input_size" to any value when loading the datasets.
### Environment info
- `datasets` version: 2.5.1
- Platform: Linux-4.18.0-305.3.1.el8.x86_64-x86_64-with-glibc2.31
- Python version: 3.9.12
- PyArrow version: 9.0.0
- Pandas version: 1.5.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5352/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5352/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5351 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5351/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5351/comments | https://api.github.com/repos/huggingface/datasets/issues/5351/events | https://github.com/huggingface/datasets/issues/5351 | 1,490,659,504 | I_kwDODunzps5Y2aiw | 5,351 | Do we need to implement `_prepare_split`? | {
"avatar_url": "https://avatars.githubusercontent.com/u/7530947?v=4",
"events_url": "https://api.github.com/users/jmwoloso/events{/privacy}",
"followers_url": "https://api.github.com/users/jmwoloso/followers",
"following_url": "https://api.github.com/users/jmwoloso/following{/other_user}",
"gists_url": "https://api.github.com/users/jmwoloso/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jmwoloso",
"id": 7530947,
"login": "jmwoloso",
"node_id": "MDQ6VXNlcjc1MzA5NDc=",
"organizations_url": "https://api.github.com/users/jmwoloso/orgs",
"received_events_url": "https://api.github.com/users/jmwoloso/received_events",
"repos_url": "https://api.github.com/users/jmwoloso/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jmwoloso/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jmwoloso/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jmwoloso"
} | [] | closed | false | null | [] | null | [] | 2022-12-12T01:38:54Z | 2022-12-16T20:07:56Z | 2022-12-12T16:48:56Z | NONE | null | null | null | ### Describe the bug
I'm not sure this is a bug or if it's just missing in the documentation, or i'm not doing something correctly, but I'm subclassing `DatasetBuilder` and getting the following error because on the `DatasetBuilder` class the `_prepare_split` method is abstract (as are the others we are required to implement, hence the genesis of my question):
```
Traceback (most recent call last):
File "/home/jason/source/python/prism_machine_learning/examples/create_hf_datasets.py", line 28, in <module>
dataset_builder.download_and_prepare()
File "/home/jason/.virtualenvs/pml/lib/python3.8/site-packages/datasets/builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "/home/jason/.virtualenvs/pml/lib/python3.8/site-packages/datasets/builder.py", line 793, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/jason/.virtualenvs/pml/lib/python3.8/site-packages/datasets/builder.py", line 1124, in _prepare_split
raise NotImplementedError()
NotImplementedError
```
### Steps to reproduce the bug
I will share implementation if it turns out that everything should be working (i.e. we only need to implement those 3 methods the docs mention), but I don't want to distract from the original question.
### Expected behavior
I just need to know if there are additional methods we need to implement when subclassing `DatasetBuilder` besides what the documentation specifies -> `_info`, `_split_generators` and `_generate_examples`
### Environment info
- `datasets` version: 2.4.0
- Platform: Linux-5.4.0-135-generic-x86_64-with-glibc2.2.5
- Python version: 3.8.12
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5351/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5351/timeline | null | completed | true |
https://api.github.com/repos/huggingface/datasets/issues/5350 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5350/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5350/comments | https://api.github.com/repos/huggingface/datasets/issues/5350/events | https://github.com/huggingface/datasets/pull/5350 | 1,487,559,904 | PR_kwDODunzps5E8y2E | 5,350 | Clean up Loading methods docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [] | 2022-12-09T22:25:30Z | 2022-12-12T17:27:20Z | 2022-12-12T17:24:01Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5350.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5350",
"merged_at": "2022-12-12T17:24:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5350.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5350"
} | Clean up for the docstrings in Loading methods! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5350/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5350/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5349 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5349/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5349/comments | https://api.github.com/repos/huggingface/datasets/issues/5349/events | https://github.com/huggingface/datasets/pull/5349 | 1,487,396,780 | PR_kwDODunzps5E8N6G | 5,349 | Clean up remaining Main Classes docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [] | 2022-12-09T20:17:15Z | 2022-12-12T17:27:17Z | 2022-12-12T17:24:13Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5349.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5349",
"merged_at": "2022-12-12T17:24:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5349.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5349"
} | This PR cleans up the remaining docstrings in Main Classes (`IterableDataset`, `IterableDatasetDict`, and `Features`). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5349/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5349/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5348 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5348/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5348/comments | https://api.github.com/repos/huggingface/datasets/issues/5348/events | https://github.com/huggingface/datasets/issues/5348 | 1,486,975,626 | I_kwDODunzps5YoXKK | 5,348 | The data downloaded in the download folder of the cache does not respect `umask` | {
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"events_url": "https://api.github.com/users/SaulLu/events{/privacy}",
"followers_url": "https://api.github.com/users/SaulLu/followers",
"following_url": "https://api.github.com/users/SaulLu/following{/other_user}",
"gists_url": "https://api.github.com/users/SaulLu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SaulLu",
"id": 55560583,
"login": "SaulLu",
"node_id": "MDQ6VXNlcjU1NTYwNTgz",
"organizations_url": "https://api.github.com/users/SaulLu/orgs",
"received_events_url": "https://api.github.com/users/SaulLu/received_events",
"repos_url": "https://api.github.com/users/SaulLu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SaulLu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SaulLu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SaulLu"
} | [] | open | false | null | [] | null | [] | 2022-12-09T15:46:27Z | 2022-12-09T17:21:26Z | null | NONE | null | null | null | ### Describe the bug
For a project on a cluster we are several users to share the same cache for the datasets library. And we have a problem with the permissions on the data downloaded in the cache.
Indeed, it seems that the data is downloaded by giving read and write permissions only to the user launching the command (and no permissions to the group). In our case, those permissions don't respect the `umask` of this user, which was `0007`.
Traceback:
```
Using custom data configuration default
Downloading and preparing dataset text_caps/default to /gpfswork/rech/cnw/commun/datasets/HuggingFaceM4___text_caps/default/1.0.0/2b9ad220cd90fcf2bfb454645bc54364711b83d6d39401ffdaf8cc40882e9141...
Downloading data files: 100%|████████████████████| 3/3 [00:00<00:00, 921.62it/s]
---------------------------------------------------------------------------
PermissionError Traceback (most recent call last)
Cell In [3], line 1
----> 1 ds = load_dataset(dataset_name)
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/load.py:1746, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1743 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
1745 # Download and prepare data
-> 1746 builder_instance.download_and_prepare(
1747 download_config=download_config,
1748 download_mode=download_mode,
1749 ignore_verifications=ignore_verifications,
1750 try_from_hf_gcs=try_from_hf_gcs,
1751 use_auth_token=use_auth_token,
1752 )
1754 # Build dataset for splits
1755 keep_in_memory = (
1756 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
1757 )
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/builder.py:704, in DatasetBuilder.download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
702 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
703 if not downloaded_from_gcs:
--> 704 self._download_and_prepare(
705 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
706 )
707 # Sync info
708 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/builder.py:1227, in GeneratorBasedBuilder._download_and_prepare(self, dl_manager, verify_infos)
1226 def _download_and_prepare(self, dl_manager, verify_infos):
-> 1227 super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/builder.py:771, in DatasetBuilder._download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
769 split_dict = SplitDict(dataset_name=self.name)
770 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 771 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
773 # Checksums verification
774 if verify_infos and dl_manager.record_checksums:
File /gpfswork/rech/cnw/commun/modules/datasets_modules/datasets/HuggingFaceM4--TextCaps/2b9ad220cd90fcf2bfb454645bc54364711b83d6d39401ffdaf8cc40882e9141/TextCaps.py:125, in TextCapsDataset._split_generators(self, dl_manager)
123 def _split_generators(self, dl_manager):
124 # urls = _URLS[self.config.name] # TODO later
--> 125 data_dir = dl_manager.download_and_extract(_URLS)
126 gen_kwargs = {
127 split_name: {
128 f"{dir_name}_path": Path(data_dir[dir_name][split_name])
(...)
133 for split_name in ["train", "val", "test"]
134 }
136 for split_name in ["train", "val", "test"]:
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/download/download_manager.py:431, in DownloadManager.download_and_extract(self, url_or_urls)
415 def download_and_extract(self, url_or_urls):
416 """Download and extract given url_or_urls.
417
418 Is roughly equivalent to:
(...)
429 extracted_path(s): `str`, extracted paths of given URL(s).
430 """
--> 431 return self.extract(self.download(url_or_urls))
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/download/download_manager.py:324, in DownloadManager.download(self, url_or_urls)
321 self.downloaded_paths.update(dict(zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten())))
323 start_time = datetime.now()
--> 324 self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
325 duration = datetime.now() - start_time
326 logger.info(f"Checksum Computation took {duration.total_seconds() // 60} min")
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/download/download_manager.py:229, in DownloadManager._record_sizes_checksums(self, url_or_urls, downloaded_path_or_paths)
226 """Record size/checksum of downloaded files."""
227 for url, path in zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten()):
228 # call str to support PathLike objects
--> 229 self._recorded_sizes_checksums[str(url)] = get_size_checksum_dict(
230 path, record_checksum=self.record_checksums
231 )
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/utils/info_utils.py:82, in get_size_checksum_dict(path, record_checksum)
80 if record_checksum:
81 m = sha256()
---> 82 with open(path, "rb") as f:
83 for chunk in iter(lambda: f.read(1 << 20), b""):
84 m.update(chunk)
PermissionError: [Errno 13] Permission denied: '/gpfswork/rech/cnw/commun/datasets/downloads/1e6aa6d23190c30885194fabb193dce3874d902d7636b66315ee8aaa584e80d6'
```
### Steps to reproduce the bug
I think the following will reproduce the bug.
Given 2 users belonging to the same group with `umask` set to `0007`
- first run with User 1:
```python
from datasets import load_dataset
ds_name = "HuggingFaceM4/VQAv2"
ds = load_dataset(ds_name)
```
- then run with User 2:
```python
from datasets import load_dataset
ds_name = "HuggingFaceM4/TextCaps"
ds = load_dataset(ds_name)
```
### Expected behavior
No `PermissionError`
### Environment info
- `datasets` version: 2.4.0
- Platform: Linux-4.18.0-305.65.1.el8_4.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.13
- PyArrow version: 7.0.0
- Pandas version: 1.4.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5348/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5348/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5347 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5347/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5347/comments | https://api.github.com/repos/huggingface/datasets/issues/5347/events | https://github.com/huggingface/datasets/pull/5347 | 1,486,920,261 | PR_kwDODunzps5E6jb1 | 5,347 | Force soundfile to return float32 instead of the default float64 | {
"avatar_url": "https://avatars.githubusercontent.com/u/25608944?v=4",
"events_url": "https://api.github.com/users/qmeeus/events{/privacy}",
"followers_url": "https://api.github.com/users/qmeeus/followers",
"following_url": "https://api.github.com/users/qmeeus/following{/other_user}",
"gists_url": "https://api.github.com/users/qmeeus/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/qmeeus",
"id": 25608944,
"login": "qmeeus",
"node_id": "MDQ6VXNlcjI1NjA4OTQ0",
"organizations_url": "https://api.github.com/users/qmeeus/orgs",
"received_events_url": "https://api.github.com/users/qmeeus/received_events",
"repos_url": "https://api.github.com/users/qmeeus/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/qmeeus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qmeeus/subscriptions",
"type": "User",
"url": "https://api.github.com/users/qmeeus"
} | [] | open | false | null | [] | null | [] | 2022-12-09T15:10:24Z | 2022-12-19T10:07:20Z | null | NONE | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5347.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5347",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5347.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5347"
} | (Fixes issue #5345) | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5347/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5347/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5346 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5346/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5346/comments | https://api.github.com/repos/huggingface/datasets/issues/5346/events | https://github.com/huggingface/datasets/issues/5346 | 1,486,884,983 | I_kwDODunzps5YoBB3 | 5,346 | [Quick poll] Give your opinion on the future of the Hugging Face Open Source ecosystem! | {
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LysandreJik",
"id": 30755778,
"login": "LysandreJik",
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LysandreJik"
} | [] | open | false | null | [] | null | [] | 2022-12-09T14:48:02Z | 2022-12-09T14:48:02Z | null | MEMBER | null | null | null | Thanks to all of you, Datasets is just about to pass 15k stars!
Since the last survey, a lot has happened: the [diffusers](https://github.com/huggingface/diffusers), [evaluate](https://github.com/huggingface/evaluate) and [skops](https://github.com/skops-dev/skops) libraries were born. `timm` joined the Hugging Face ecosystem. There were 25 new releases of `transformers`, 21 new releases of `datasets`, 13 new releases of `accelerate`.
If you have a couple of minutes and want to participate in shaping the future of the ecosystem, please share your thoughts:
[**hf.co/oss-survey**](https://docs.google.com/forms/d/e/1FAIpQLSf4xFQKtpjr6I_l7OfNofqiR8s-WG6tcNbkchDJJf5gYD72zQ/viewform?usp=sf_link)
(please reply in the above feedback form rather than to this thread)
Thank you all on behalf of the HuggingFace team! 🤗 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 3,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5346/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5346/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5345 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5345/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5345/comments | https://api.github.com/repos/huggingface/datasets/issues/5345/events | https://github.com/huggingface/datasets/issues/5345 | 1,486,555,384 | I_kwDODunzps5Ymwj4 | 5,345 | Wrong dtype for array in audio features | {
"avatar_url": "https://avatars.githubusercontent.com/u/25608944?v=4",
"events_url": "https://api.github.com/users/qmeeus/events{/privacy}",
"followers_url": "https://api.github.com/users/qmeeus/followers",
"following_url": "https://api.github.com/users/qmeeus/following{/other_user}",
"gists_url": "https://api.github.com/users/qmeeus/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/qmeeus",
"id": 25608944,
"login": "qmeeus",
"node_id": "MDQ6VXNlcjI1NjA4OTQ0",
"organizations_url": "https://api.github.com/users/qmeeus/orgs",
"received_events_url": "https://api.github.com/users/qmeeus/received_events",
"repos_url": "https://api.github.com/users/qmeeus/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/qmeeus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qmeeus/subscriptions",
"type": "User",
"url": "https://api.github.com/users/qmeeus"
} | [] | open | false | null | [] | null | [] | 2022-12-09T11:05:11Z | 2022-12-16T13:44:46Z | null | NONE | null | null | null | ### Describe the bug
When concatenating/interleaving different datasets, I stumble into an error because the features can't be aligned. After some investigation, I understood that the audio arrays had different dtypes, namely `float32` and `float64`. Consequently, the datasets cannot be merged.
### Steps to reproduce the bug
For example, for `facebook/voxpopuli` and `mozilla-foundation/common_voice_11_0`:
```
from datasets import load_dataset, interleave_datasets
covost = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="train", streaming=True)
voxpopuli = datasets.load_dataset("facebook/voxpopuli", "nl", split="train", streaming=True)
sample_cv, = covost.take(1)
sample_vp, = voxpopuli.take(1)
assert sample_cv["audio"]["array"].dtype == sample_vp["audio"]["array"].dtype
# Fails
dataset = interleave_datasets([covost, voxpopuli])
# ValueError: The features can't be aligned because the key audio of features {'audio_id': Value(dtype='string', id=None), 'language': Value(dtype='int64', id=None), 'audio': {'array': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None), 'path': Value(dtype='string', id=None), 'sampling_rate': Value(dtype='int64', id=None)}, 'normalized_text': Value(dtype='string', id=None), 'gender': Value(dtype='string', id=None), 'speaker_id': Value(dtype='string', id=None), 'is_gold_transcript': Value(dtype='bool', id=None), 'accent': Value(dtype='string', id=None), 'sentence': Value(dtype='string', id=None)} has unexpected type - {'array': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None), 'path': Value(dtype='string', id=None), 'sampling_rate': Value(dtype='int64', id=None)} (expected either Audio(sampling_rate=16000, mono=True, decode=True, id=None) or Value("null").
```
### Expected behavior
The audio should be loaded to arrays with a unique dtype (I guess `float32`)
### Environment info
```
- `datasets` version: 2.7.1.dev0
- Platform: Linux-4.18.0-425.3.1.el8.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.15
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5345/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5345/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5344 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5344/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5344/comments | https://api.github.com/repos/huggingface/datasets/issues/5344/events | https://github.com/huggingface/datasets/pull/5344 | 1,485,628,319 | PR_kwDODunzps5E2BPN | 5,344 | Clean up Dataset and DatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [] | 2022-12-09T00:02:08Z | 2022-12-13T00:56:07Z | 2022-12-13T00:53:02Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5344.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5344",
"merged_at": "2022-12-13T00:53:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5344.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5344"
} | This PR cleans up the docstrings for the other half of the methods in `Dataset` and finishes `DatasetDict`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5344/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5344/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5343 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5343/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5343/comments | https://api.github.com/repos/huggingface/datasets/issues/5343/events | https://github.com/huggingface/datasets/issues/5343 | 1,485,297,823 | I_kwDODunzps5Yh9if | 5,343 | T5 for Q&A produces truncated sentence | {
"avatar_url": "https://avatars.githubusercontent.com/u/13484072?v=4",
"events_url": "https://api.github.com/users/junyongyou/events{/privacy}",
"followers_url": "https://api.github.com/users/junyongyou/followers",
"following_url": "https://api.github.com/users/junyongyou/following{/other_user}",
"gists_url": "https://api.github.com/users/junyongyou/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/junyongyou",
"id": 13484072,
"login": "junyongyou",
"node_id": "MDQ6VXNlcjEzNDg0MDcy",
"organizations_url": "https://api.github.com/users/junyongyou/orgs",
"received_events_url": "https://api.github.com/users/junyongyou/received_events",
"repos_url": "https://api.github.com/users/junyongyou/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/junyongyou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/junyongyou/subscriptions",
"type": "User",
"url": "https://api.github.com/users/junyongyou"
} | [] | closed | false | null | [] | null | [] | 2022-12-08T19:48:46Z | 2022-12-08T19:57:17Z | 2022-12-08T19:57:17Z | NONE | null | null | null | Dear all, I am fine-tuning T5 for Q&A task using the MedQuAD ([GitHub - abachaa/MedQuAD: Medical Question Answering Dataset of 47,457 QA pairs created from 12 NIH websites](https://github.com/abachaa/MedQuAD)) dataset. In the dataset, there are many long answers with thousands of words. I have used pytorch_lightning to train the T5-large model. I have two questions.
For example, I set both the max_length, max_input_length, max_output_length to 128.
How to deal with those long answers? I just left them as is and the T5Tokenizer can automatically handle. I would assume the tokenizer just truncates an answer at the position of 128th word (or 127th). Is it possible that I manually split an answer into different parts, each part has 128 words; and then all these sub-answers serve as a separate answer to the same question?
Another question is that I get incomplete (truncated) answers when using the fine-tuned model in inference, even though the predicted answer is shorter than 128 words. I found a message posted 2 years ago saying that one should add at the end of texts when fine-tuning T5. I followed that but then got a warning message that duplicated were found. I am assuming that this is because the tokenizer truncates an answer text, thus is missing in the truncated answer, such that the end token is not produced in predicted answer. However, I am not sure. Can anybody point out how to address this issue?
Any suggestions are highly appreciated.
Below is some code snippet.
`
import pytorch_lightning as pl
from torch.utils.data import DataLoader
import torch
import numpy as np
import time
from pathlib import Path
from transformers import (
Adafactor,
T5ForConditionalGeneration,
T5Tokenizer,
get_linear_schedule_with_warmup
)
from torch.utils.data import RandomSampler
from question_answering.utils import *
class T5FineTuner(pl.LightningModule):
def __init__(self, hyparams):
super(T5FineTuner, self).__init__()
self.hyparams = hyparams
self.model = T5ForConditionalGeneration.from_pretrained(hyparams.model_name_or_path)
self.tokenizer = T5Tokenizer.from_pretrained(hyparams.tokenizer_name_or_path)
if self.hyparams.freeze_embeds:
self.freeze_embeds()
if self.hyparams.freeze_encoder:
self.freeze_params(self.model.get_encoder())
# assert_all_frozen()
self.step_count = 0
self.output_dir = Path(self.hyparams.output_dir)
n_observations_per_split = {
'train': self.hyparams.n_train,
'validation': self.hyparams.n_val,
'test': self.hyparams.n_test
}
self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
self.em_score_list = []
self.subset_score_list = []
data_folder = r'C:\Datasets\MedQuAD-master'
self.train_data, self.val_data, self.test_data = load_medqa_data(data_folder)
def freeze_params(self, model):
for param in model.parameters():
param.requires_grad = False
def freeze_embeds(self):
try:
self.freeze_params(self.model.model.shared)
for d in [self.model.model.encoder, self.model.model.decoder]:
self.freeze_params(d.embed_positions)
self.freeze_params(d.embed_tokens)
except AttributeError:
self.freeze_params(self.model.shared)
for d in [self.model.encoder, self.model.decoder]:
self.freeze_params(d.embed_tokens)
def lmap(self, f, x):
return list(map(f, x))
def is_logger(self):
return self.trainer.proc_rank <= 0
def forward(self, input_ids, attention_mask=None, decoder_input_ids=None, decoder_attention_mask=None, labels=None):
return self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
labels=labels
)
def _step(self, batch):
labels = batch['target_ids']
labels[labels[:, :] == self.tokenizer.pad_token_id] = -100
outputs = self(
input_ids = batch['source_ids'],
attention_mask=batch['source_mask'],
labels=labels,
decoder_attention_mask=batch['target_mask']
)
loss = outputs[0]
return loss
def ids_to_clean_text(self, generated_ids):
gen_text = self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
return self.lmap(str.strip, gen_text)
def _generative_step(self, batch):
t0 = time.time()
generated_ids = self.model.generate(
batch["source_ids"],
attention_mask=batch["source_mask"],
use_cache=True,
decoder_attention_mask=batch['target_mask'],
max_length=128,
num_beams=2,
early_stopping=True
)
preds = self.ids_to_clean_text(generated_ids)
targets = self.ids_to_clean_text(batch["target_ids"])
gen_time = (time.time() - t0) / batch["source_ids"].shape[0]
loss = self._step(batch)
base_metrics = {'val_loss': loss}
summ_len = np.mean(self.lmap(len, generated_ids))
base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=targets)
em_score, subset_match_score = calculate_scores(preds, targets)
self.em_score_list.append(em_score)
self.subset_score_list.append(subset_match_score)
em_score = torch.tensor(em_score, dtype=torch.float32)
subset_match_score = torch.tensor(subset_match_score, dtype=torch.float32)
base_metrics.update(em_score=em_score, subset_match_score=subset_match_score)
# rouge_results = self.rouge_metric.compute()
# rouge_dict = self.parse_score(rouge_results)
return base_metrics
def training_step(self, batch, batch_idx):
loss = self._step(batch)
tensorboard_logs = {'train_loss': loss}
return {'loss': loss, 'log': tensorboard_logs}
def training_epoch_end(self, outputs):
avg_train_loss = torch.stack([x['loss'] for x in outputs]).mean()
tensorboard_logs = {'avg_train_loss': avg_train_loss}
# return {'avg_train_loss': avg_train_loss, 'log': tensorboard_logs, 'progress_bar': tensorboard_logs}
def validation_step(self, batch, batch_idx):
return self._generative_step(batch)
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
tensorboard_logs = {'val_loss': avg_loss}
if len(self.em_score_list) <= 2:
average_em_score = sum(self.em_score_list) / len(self.em_score_list)
average_subset_match_score = sum(self.subset_score_list) / len(self.subset_score_list)
else:
latest_em_score = self.em_score_list[:-2]
latest_subset_score = self.subset_score_list[:-2]
average_em_score = sum(latest_em_score) / len(latest_em_score)
average_subset_match_score = sum(latest_subset_score) / len(latest_subset_score)
average_em_score = torch.tensor(average_em_score, dtype=torch.float32)
average_subset_match_score = torch.tensor(average_subset_match_score, dtype=torch.float32)
tensorboard_logs.update(em_score=average_em_score, subset_match_score=average_subset_match_score)
self.target_gen = []
self.prediction_gen = []
return {
'avg_val_loss': avg_loss,
'em_score': average_em_score,
'subset_match_socre': average_subset_match_score,
'log': tensorboard_logs,
'progress_bar': tensorboard_logs
}
def configure_optimizers(self):
model = self.model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.hyparams.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = Adafactor(optimizer_grouped_parameters, lr=self.hyparams.learning_rate, scale_parameter=False,
relative_step=False)
self.opt = optimizer
return [optimizer]
def optimizer_step(self, epoch, batch_idx, optimizer, optimizer_idx, optimizer_closure=None,
on_tpu=False, using_native_amp=False, using_lbfgs=False):
optimizer.step(closure=optimizer_closure)
optimizer.zero_grad()
self.lr_scheduler.step()
def get_tqdm_dict(self):
tqdm_dict = {"loss": "{:.3f}".format(self.trainer.avg_loss), "lr": self.lr_scheduler.get_last_lr()[-1]}
return tqdm_dict
def train_dataloader(self):
n_samples = self.n_obs['train']
train_dataset = get_dataset(tokenizer=self.tokenizer, data=self.train_data, num_samples=n_samples,
args=self.hyparams)
sampler = RandomSampler(train_dataset)
dataloader = DataLoader(train_dataset, sampler=sampler, batch_size=self.hyparams.train_batch_size,
drop_last=True, num_workers=4)
# t_total = (
# (len(dataloader.dataset) // (self.hyparams.train_batch_size * max(1, self.hyparams.n_gpu)))
# // self.hyparams.gradient_accumulation_steps
# * float(self.hyparams.num_train_epochs)
# )
t_total = 100000
scheduler = get_linear_schedule_with_warmup(
self.opt, num_warmup_steps=self.hyparams.warmup_steps, num_training_steps=t_total
)
self.lr_scheduler = scheduler
return dataloader
def val_dataloader(self):
n_samples = self.n_obs['validation']
validation_dataset = get_dataset(tokenizer=self.tokenizer, data=self.val_data, num_samples=n_samples,
args=self.hyparams)
sampler = RandomSampler(validation_dataset)
return DataLoader(validation_dataset, shuffle=False, batch_size=self.hyparams.eval_batch_size, sampler=sampler, num_workers=4)
def test_dataloader(self):
n_samples = self.n_obs['test']
test_dataset = get_dataset(tokenizer=self.tokenizer, data=self.test_data, num_samples=n_samples, args=self.hyparams)
return DataLoader(test_dataset, batch_size=self.hyparams.eval_batch_size, num_workers=4)
def on_save_checkpoint(self, checkpoint):
save_path = self.output_dir.joinpath("best_tfmr")
self.model.config.save_step = self.step_count
self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
import os
import argparse
import pytorch_lightning as pl
from question_answering.t5_closed_book import T5FineTuner
if __name__ == '__main__':
args_dict = dict(
output_dir="", # path to save the checkpoints
model_name_or_path='t5-large',
tokenizer_name_or_path='t5-large',
max_input_length=128,
max_output_length=128,
freeze_encoder=False,
freeze_embeds=False,
learning_rate=1e-5,
weight_decay=0.0,
adam_epsilon=1e-8,
warmup_steps=0,
train_batch_size=4,
eval_batch_size=4,
num_train_epochs=2,
gradient_accumulation_steps=10,
n_gpu=1,
resume_from_checkpoint=None,
val_check_interval=0.5,
n_val=4000,
n_train=-1,
n_test=-1,
early_stop_callback=False,
fp_16=False,
opt_level='O1',
max_grad_norm=1.0,
seed=101,
)
args_dict.update({'output_dir': 't5_large_MedQuAD_256', 'num_train_epochs': 100,
'train_batch_size': 16, 'eval_batch_size': 16, 'learning_rate': 1e-3})
args = argparse.Namespace(**args_dict)
checkpoint_callback = pl.callbacks.ModelCheckpoint(dirpath=args.output_dir, monitor="em_score", mode="max", save_top_k=1)
## If resuming from checkpoint, add an arg resume_from_checkpoint
train_params = dict(
accumulate_grad_batches=args.gradient_accumulation_steps,
gpus=args.n_gpu,
max_epochs=args.num_train_epochs,
# early_stop_callback=False,
precision=16 if args.fp_16 else 32,
# amp_level=args.opt_level,
# resume_from_checkpoint=args.resume_from_checkpoint,
gradient_clip_val=args.max_grad_norm,
checkpoint_callback=checkpoint_callback,
val_check_interval=args.val_check_interval,
# accelerator='dp'
# logger=wandb_logger,
# callbacks=[LoggingCallback()],
)
model = T5FineTuner(args)
trainer = pl.Trainer(**train_params)
trainer.fit(model)
` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5343/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5343/timeline | null | completed | true |
https://api.github.com/repos/huggingface/datasets/issues/5342 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5342/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5342/comments | https://api.github.com/repos/huggingface/datasets/issues/5342/events | https://github.com/huggingface/datasets/issues/5342 | 1,485,244,178 | I_kwDODunzps5YhwcS | 5,342 | Emotion dataset cannot be downloaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/78887193?v=4",
"events_url": "https://api.github.com/users/cbarond/events{/privacy}",
"followers_url": "https://api.github.com/users/cbarond/followers",
"following_url": "https://api.github.com/users/cbarond/following{/other_user}",
"gists_url": "https://api.github.com/users/cbarond/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cbarond",
"id": 78887193,
"login": "cbarond",
"node_id": "MDQ6VXNlcjc4ODg3MTkz",
"organizations_url": "https://api.github.com/users/cbarond/orgs",
"received_events_url": "https://api.github.com/users/cbarond/received_events",
"repos_url": "https://api.github.com/users/cbarond/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cbarond/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cbarond/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cbarond"
} | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | null | [] | null | [] | 2022-12-08T19:07:09Z | 2022-12-09T19:11:51Z | 2022-12-09T10:46:11Z | NONE | null | null | null | ### Describe the bug
The emotion dataset gives a FileNotFoundError. The full error is: `FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt?dl=1`.
It was working yesterday (December 7, 2022), but stopped working today (December 8, 2022).
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("emotion")
```
### Expected behavior
The dataset should load properly.
### Environment info
- `datasets` version: 2.7.1
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.9.13
- PyArrow version: 10.0.1
- Pandas version: 1.5.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5342/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5342/timeline | null | completed | true |
https://api.github.com/repos/huggingface/datasets/issues/5341 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5341/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5341/comments | https://api.github.com/repos/huggingface/datasets/issues/5341/events | https://github.com/huggingface/datasets/pull/5341 | 1,484,376,644 | PR_kwDODunzps5Exohx | 5,341 | Remove tasks.json | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | 2022-12-08T11:04:35Z | 2022-12-09T12:26:21Z | 2022-12-09T12:23:20Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5341.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5341",
"merged_at": "2022-12-09T12:23:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5341.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5341"
} | After discussions in https://github.com/huggingface/datasets/pull/5335 we should remove this file that is not used anymore. We should update https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts instead. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5341/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5341/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5340 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5340/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5340/comments | https://api.github.com/repos/huggingface/datasets/issues/5340/events | https://github.com/huggingface/datasets/pull/5340 | 1,483,182,158 | PR_kwDODunzps5EtWo3 | 5,340 | Clean up DatasetInfo and Dataset docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [] | 2022-12-08T00:17:53Z | 2022-12-08T19:33:14Z | 2022-12-08T19:30:10Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5340.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5340",
"merged_at": "2022-12-08T19:30:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5340.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5340"
} | This PR cleans up the docstrings for `DatasetInfo` and about half of the methods in `Dataset`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5340/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5340/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5339 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5339/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5339/comments | https://api.github.com/repos/huggingface/datasets/issues/5339/events | https://github.com/huggingface/datasets/pull/5339 | 1,482,817,424 | PR_kwDODunzps5EsC8N | 5,339 | Add Video feature, videofolder, and video-classification task | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nateraw",
"id": 32437151,
"login": "nateraw",
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"repos_url": "https://api.github.com/users/nateraw/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nateraw"
} | [] | open | false | null | [] | null | [] | 2022-12-07T20:48:34Z | 2022-12-07T20:54:06Z | null | CONTRIBUTOR | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/5339.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5339",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5339.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5339"
} | This PR does the following:
- Adds `Video` feature (Resolves #5225 )
- Adds `video-classification` task
- Adds `videofolder` packaged module for easy loading of local video classification datasets
TODO:
- [ ] add tests
- [ ] add docs | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5339/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5339/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5338 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5338/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5338/comments | https://api.github.com/repos/huggingface/datasets/issues/5338/events | https://github.com/huggingface/datasets/issues/5338 | 1,482,646,151 | I_kwDODunzps5YX2KH | 5,338 | `map()` stops every 1000 steps | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"gists_url": "https://api.github.com/users/bayartsogt-ya/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bayartsogt-ya",
"id": 43239645,
"login": "bayartsogt-ya",
"node_id": "MDQ6VXNlcjQzMjM5NjQ1",
"organizations_url": "https://api.github.com/users/bayartsogt-ya/orgs",
"received_events_url": "https://api.github.com/users/bayartsogt-ya/received_events",
"repos_url": "https://api.github.com/users/bayartsogt-ya/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bayartsogt-ya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bayartsogt-ya/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bayartsogt-ya"
} | [] | closed | false | null | [] | null | [] | 2022-12-07T19:09:40Z | 2022-12-10T00:39:29Z | 2022-12-10T00:39:28Z | NONE | null | null | null | ### Describe the bug
I am passing the following `prepare_dataset` function to `Dataset.map` (code is inspired from [here](https://github.com/huggingface/community-events/blob/main/whisper-fine-tuning-event/run_speech_recognition_seq2seq_streaming.py#L454))
```python3
def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch[text_column]).input_ids
return batch
...
train_ds = train_ds.map(prepare_dataset)
```
Here is the exact code I am running https://github.com/bayartsogt-ya/whisper-multiple-hf-datasets/blob/main/train.py#L70-L71
It starts using all the cores (I am not sure why because I did not pass `num_proc`)
then progress bar stops at every 1k steps. (starts using a single core)
then come back to using all the cores again.
link to [screen record](https://youtu.be/jPQpQQGp6Gc)
Can someone explain this process and maybe provide a way to improve this pipeline? cc: @lhoestq
### Steps to reproduce the bug
1. load the dataset
2. create a Whisper processor
3. create a `prepare_dataset` function
4. pass the function to `dataset.map(prepare_dataset)`
### Expected behavior
- Use a single core per a function
- not to stop at some point?
### Environment info
- `datasets` version: 2.7.1.dev0
- Platform: Linux-5.4.0-109-generic-x86_64-with-glibc2.27
- Python version: 3.8.10
- PyArrow version: 10.0.1
- Pandas version: 1.5.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5338/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5338/timeline | null | completed | true |
https://api.github.com/repos/huggingface/datasets/issues/5337 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5337/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5337/comments | https://api.github.com/repos/huggingface/datasets/issues/5337/events | https://github.com/huggingface/datasets/issues/5337 | 1,481,692,156 | I_kwDODunzps5YUNP8 | 5,337 | Support webdataset format | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | open | false | null | [] | null | [] | 2022-12-07T11:32:25Z | 2022-12-12T14:23:44Z | null | MEMBER | null | null | null | Webdataset is an efficient format for iterable datasets. It would be nice to support it in `datasets`, as discussed in https://github.com/rom1504/img2dataset/issues/234.
In particular it would be awesome to be able to load one using `load_dataset` in streaming mode (either from a local directory, or from a dataset on the Hugging Face Hub). Some datasets on the Hub are already in webdataset format.
It terms of implementation, we can have something similar to the Parquet loader.
I also think it's fine to have webdataset as an optional dependency. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5337/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5337/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5336 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5336/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5336/comments | https://api.github.com/repos/huggingface/datasets/issues/5336/events | https://github.com/huggingface/datasets/pull/5336 | 1,479,649,900 | PR_kwDODunzps5Egzed | 5,336 | Set `IterableDataset.map` param `batch_size` typing as optional | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_url": "https://api.github.com/users/alvarobartt/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alvarobartt",
"id": 36760800,
"login": "alvarobartt",
"node_id": "MDQ6VXNlcjM2NzYwODAw",
"organizations_url": "https://api.github.com/users/alvarobartt/orgs",
"received_events_url": "https://api.github.com/users/alvarobartt/received_events",
"repos_url": "https://api.github.com/users/alvarobartt/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alvarobartt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alvarobartt/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alvarobartt"
} | [] | closed | false | null | [] | null | [] | 2022-12-06T17:08:10Z | 2022-12-07T14:14:56Z | 2022-12-07T14:06:27Z | CONTRIBUTOR | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5336.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5336",
"merged_at": "2022-12-07T14:06:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5336.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5336"
} | This PR solves #5325
~Indeed we're using the typing for optional values as `Union[type, None]` as it's similar to how Python 3.10 handles optional values as `type | None`, instead of using `Optional[type]`.~
~Do we want to start using `Union[type, None]` for type-hinting optional values or just keep on using `Optional`?~ -> Keeping `Optional` still for consistency with the rest of the code in `datasets`
Also we now allow `batch_size` to be `None` for `IterableDataset.map` and `IterableDataset.filter`e.g. `MappedExamplesIterable` as `map` is internally instantiating those and propagating the `batch_size` param so if it can be `None` for `map` it should also do so for `MappedExamplesIterable`, as well as for `FilteredExamplesIterable` when calling `IterableDataset.filter`.
## TODOs
- [x] Add integration tests
- [x] Handle scenario where `batched=True` and `batch_size=None` or `batch_size<=0` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5336/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5336/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5335 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5335/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5335/comments | https://api.github.com/repos/huggingface/datasets/issues/5335/events | https://github.com/huggingface/datasets/pull/5335 | 1,478,890,788 | PR_kwDODunzps5EeHdA | 5,335 | Update tasks.json | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [] | closed | false | null | [] | null | [] | 2022-12-06T11:37:57Z | 2022-12-08T11:05:33Z | 2022-12-07T12:46:03Z | CONTRIBUTOR | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5335.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5335",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5335.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5335"
} | Context:
* https://github.com/huggingface/datasets/issues/5255#issuecomment-1339107195
Cc: @osanseviero | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5335/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5335/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5334 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5334/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5334/comments | https://api.github.com/repos/huggingface/datasets/issues/5334/events | https://github.com/huggingface/datasets/pull/5334 | 1,477,421,927 | PR_kwDODunzps5EY9zN | 5,334 | Clean up docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [] | 2022-12-05T20:56:08Z | 2022-12-09T01:44:25Z | 2022-12-09T01:41:44Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5334.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5334",
"merged_at": "2022-12-09T01:41:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5334.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5334"
} | As raised by @polinaeterna in #5324, some of the docstrings are a bit of a mess because it has both Markdown and Sphinx syntax. This PR fixes the docstring for `DatasetBuilder`.
I'll start working on cleaning up the rest of the docstrings and removing the old Sphinx syntax (let me know if you prefer one big PR with all the cleaned changes or multiple smaller ones)! 🧼 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5334/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5334/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5333 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5333/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5333/comments | https://api.github.com/repos/huggingface/datasets/issues/5333/events | https://github.com/huggingface/datasets/pull/5333 | 1,476,890,156 | PR_kwDODunzps5EXGQ2 | 5,333 | fix: 🐛 pass the token to get the list of config names | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [] | closed | false | null | [] | null | [] | 2022-12-05T16:06:09Z | 2022-12-06T08:25:17Z | 2022-12-06T08:22:49Z | CONTRIBUTOR | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5333.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5333",
"merged_at": "2022-12-06T08:22:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5333.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5333"
} | Otherwise, get_dataset_infos doesn't work on gated or private datasets, even with the correct token. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5333/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5333/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5332 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5332/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5332/comments | https://api.github.com/repos/huggingface/datasets/issues/5332/events | https://github.com/huggingface/datasets/issues/5332 | 1,476,513,072 | I_kwDODunzps5YAc0w | 5,332 | Passing numpy array to ClassLabel names causes ValueError | {
"avatar_url": "https://avatars.githubusercontent.com/u/1475568?v=4",
"events_url": "https://api.github.com/users/freddyheppell/events{/privacy}",
"followers_url": "https://api.github.com/users/freddyheppell/followers",
"following_url": "https://api.github.com/users/freddyheppell/following{/other_user}",
"gists_url": "https://api.github.com/users/freddyheppell/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/freddyheppell",
"id": 1475568,
"login": "freddyheppell",
"node_id": "MDQ6VXNlcjE0NzU1Njg=",
"organizations_url": "https://api.github.com/users/freddyheppell/orgs",
"received_events_url": "https://api.github.com/users/freddyheppell/received_events",
"repos_url": "https://api.github.com/users/freddyheppell/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/freddyheppell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/freddyheppell/subscriptions",
"type": "User",
"url": "https://api.github.com/users/freddyheppell"
} | [] | open | false | null | [] | null | [] | 2022-12-05T12:59:03Z | 2022-12-15T16:40:22Z | null | NONE | null | null | null | ### Describe the bug
If a numpy array is passed to the names argument of ClassLabel, creating a dataset with those features causes an error.
### Steps to reproduce the bug
https://colab.research.google.com/drive/1cV_es1PWZiEuus17n-2C-w0KEoEZ68IX
TLDR:
If I define my classes as:
```
my_classes = np.array(['one', 'two', 'three'])
```
Then this errors:
```py
features = Features({'value': Value('string'), 'label': ClassLabel(names=my_classes)})
dataset = Dataset.from_list(my_data, features=features)
```
```
ValueError Traceback (most recent call last)
[<ipython-input-8-a8a9d53ec82f>](https://localhost:8080/#) in <module>
----> 1 dataset = Dataset.from_list(my_data, features=features)
11 frames
[/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py](https://localhost:8080/#) in _asdict_inner(obj)
183 for f in fields(obj):
184 value = _asdict_inner(getattr(obj, f.name))
--> 185 if not f.init or value != f.default or f.metadata.get("include_in_asdict_even_if_is_default", False):
186 result[f.name] = value
187 return result
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
```
But this works:
```
features2 = Features({'value': Value('string'), 'label': ClassLabel(names=list(my_classes))})
dataset2 = Dataset.from_list(my_data, features=features2)
```
### Expected behavior
If I provide a numpy array of class names, I would expect either an error that the names list is the wrong type, or for it to be cast internally.
### Environment info
- `datasets` version: 2.7.1
- Platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.10
- Python version: 3.8.15
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
Additionally:
- Numpy version: 1.23.5
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5332/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5332/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5331 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5331/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5331/comments | https://api.github.com/repos/huggingface/datasets/issues/5331/events | https://github.com/huggingface/datasets/pull/5331 | 1,473,146,738 | PR_kwDODunzps5EKDpr | 5,331 | Support for multiple configs in packaged modules via metadata yaml info | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [] | open | false | null | [] | null | [] | 2022-12-02T16:43:44Z | 2022-12-13T11:54:46Z | null | CONTRIBUTOR | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/5331.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5331",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5331.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5331"
} | will solve https://github.com/huggingface/datasets/issues/5209 and https://github.com/huggingface/datasets/issues/5151 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5331/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5331/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5329 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5329/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5329/comments | https://api.github.com/repos/huggingface/datasets/issues/5329/events | https://github.com/huggingface/datasets/pull/5329 | 1,471,999,125 | PR_kwDODunzps5EGK3y | 5,329 | Clarify imagefolder is for small datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [] | 2022-12-01T21:47:29Z | 2022-12-06T17:20:04Z | 2022-12-06T17:16:53Z | MEMBER | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5329.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5329",
"merged_at": "2022-12-06T17:16:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5329.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5329"
} | Based on feedback from [here](https://github.com/huggingface/datasets/issues/5317#issuecomment-1334108824), this PR adds a note to the `imagefolder` loading and creating docs that `imagefolder` is designed for small scale image datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5329/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5329/timeline | null | null | true |
End of preview. Expand
in Dataset Viewer.
- Downloads last month
- 41