

extra_gated_prompt: >-
You agree to use this dataset exclusively in compliance with the
[license](https://usm3d.github.io/S23DR/data_license.html).
extra_gated_fields:
Affiliation: text
Country: country
I agree to use this dataset for non-commercial use ONLY: checkbox
extra_gated_heading: Acknowledge license to accept the repository
extra_gated_description: Our team may take 2-3 days to process your request
extra_gated_button_content: Acknowledge license
pretty_name: hoho
HoHo 5k Subset
This dataset is being used as the training set for the S23DR Challenge.
This is a living dataset. Today, we provide 4316 samples for training, and 175 for validation and hold back an additional 1072 for computing the private and public leaderboards. Additional, we intend to continue releasing training data throughout the challenge and beyond. The data take the following form:
Features({
"order_id": Value(dtype="string"),
# inputs
"K": Sequence(Array2D(dtype="float32", shape=(3, 3))),
"R": Sequence(Array2D(dtype="float32", shape=(3, 3))),
"t": Sequence(Sequence(Value(dtype="float32"), length=(3))), # in centimeters
"gestalt": Sequence(Image()),
"ade20k": Sequence(Image()),
"depthcm": Sequence(Image()), # in centimeters
# result of Colmap reconstruction loaded in named tuples
# More on format: https://github.com/colmap/colmap/blob/main/scripts/python/read_write_model.py#L47
"images": Dict(namedtuple("Image", ["id", "qvec", "tvec", "camera_id", "name", "xys", "point3D_ids"])),
"points3d": Dict(namedtuple( "Point3D", ["id", "xyz", "rgb", "error", "image_ids", "point2D_idxs"])),
"cameras": Dict(namedtuple("Camera", ["id", "model", "width", "height", "params"])),
# side info during training
"mesh_vertices": Sequence(Sequence(Value(dtype="float32"), length=3)),
"mesh_faces": Sequence(Sequence(Value(dtype="int64"))),
"face_semantics": Sequence(Value(dtype='int64')),
"edge_semantics": Sequence(Value(dtype='int64')),
# targets
"wf_vertices": Sequence(Sequence(Value(dtype="float32"), length=3)), # in centimeters
"wf_edges": Sequence(Sequence(Value(dtype="int64"), length=2)),
})
These data were gathered over the course of several years throughout the United States from a variety of smart phone and camera platforms. Each training sample/scene consists of a set of posed image features (segmentation, depth, etc.) and a sparse point cloud as input, and a sparse wire frame (3D embedded graph) with semantically tagged edges as the target. Additionally a mesh with semantically tagged faces is provided for each scene durning training. In order to preserve privacy, original images are not provided.
Note: the test distribution is not guaranteed to match the training set.
Sample visualizations
Two visualizations of houses below are interactive! Grab one with your mouse and rotate!





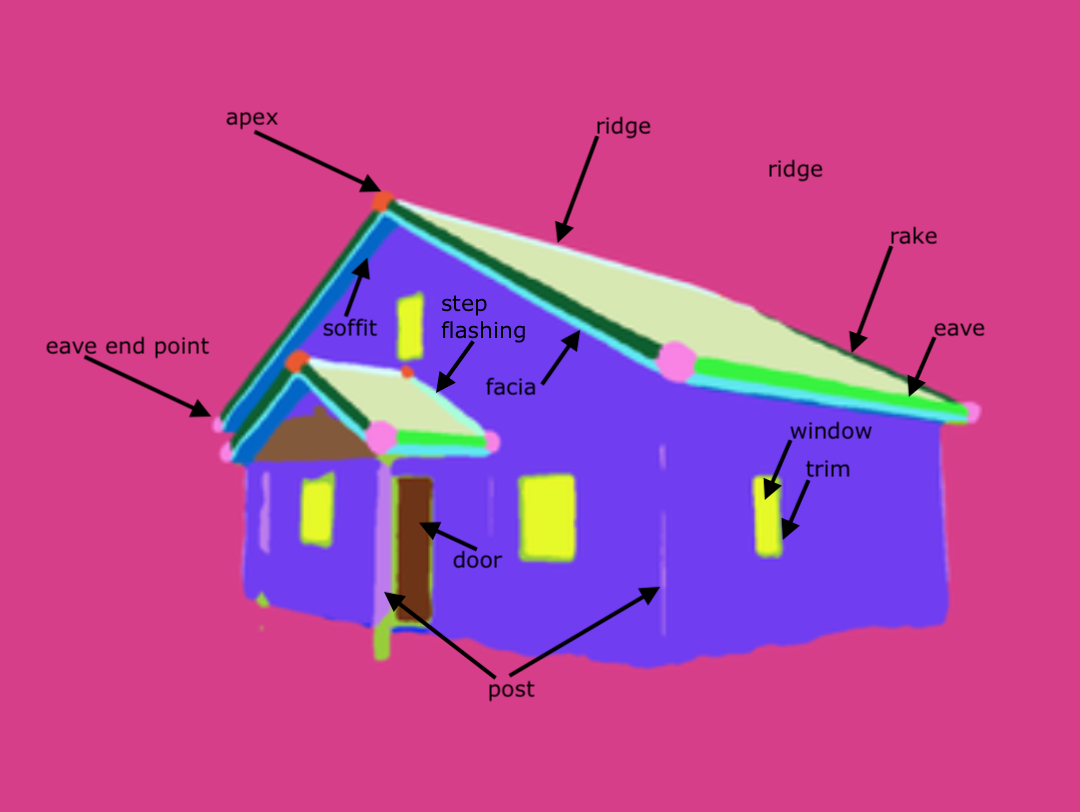
The roofs below are interactive as well!
Additional notes on data
Depth
The depthcm is a result of running monocular depth model, and it is not ground truth by no means. If you need to have a GT depth, you can render the GT mesh in the training set using mesh_faces and mesh_vertices.
The semi-sparse depth from the Colmap reconstructions with dense features, available in points3d is much more accurate, than depthcm.
At the inference time, mesh_faces is not available, so you can use only depthcm and colmap point cloud from points3d
Segmentation
You have two segmentations available. gestalt is domain specific model, which "sees-through-occlusions" and provides a detailed information about house parts. See the list of classes in "Dataset" section in the navigation bar.
ade20k is a standard ADE20K segmentation model (specifically, shi-labs/oneformer_ade20k_swin_large).
Organizers
Jack Langerman (Hover), Dmytro Mishkin (CTU in Prague / Hover), Ilke Demir (Intel), Hanzhi Chen (TUM), Daoyi Gao (TUM), Caner Korkmaz (ICL), Tolga Birdal (ICL)
Sponsors
The organizers would like to thank Hover Inc. for their sponsorship of this challenge and dataset.
Timeline
- Competition Released: March 14, 2024
- Entry Deadline: May 28, 2024
- Team Merging: May 28, 2024
- Final Solution Submission: June 4, 2024
- Writeup Deadline: June 11, 2024
Prizes
- 1st Place: $10,000
- 2nd Place: $7,000
- 3rd Place: $5,000
- Additional Prizes: $3,000
Please see the Competition Rules for additional information.
Cite
@misc{Langerman_Korkmaz_Chen_Gao_Demir_Mishkin_Birdal2024,
title={S23DR Competition at 1st Workshop on Urban Scene Modeling @ CVPR 2024},
url={usm3d.github.io},
howpublished = {\url{https://huggingface.co/usm3d}},
year={2024},
author={Langerman, Jack and Korkmaz, Caner and Chen, Hanzhi and Gao, Daoyi and Demir, Ilke and Mishkin, Dmytro and Birdal, Tolga}
}