
Litus whisper-small-ita for CTranslate2
La repo contiene la conversione di litus-ai/whisper-small-ita al formato di CTranslate2.
Questo modello può essere usato su CTranslate2 o su progetti affini tipo:faster-whisper.
Descrizione del Modello
Questo modello è una versione di openai/whisper-small ottimizzata per la lingua italiana, addestrata utilizzando una parte dei dati proprietari di Litus AI.
litus-ai/whisper-small-ita rappresenta un ottimo compromesso value/cost ed è ottimale per contesti in cui il budget computazionale è limitato,
ma è comunque necessaria una trascrizione accurata del parlato.
Particolarità del Modello
La peculiarità principale del modello è l'integrazione di token speciali che arricchiscono la trascrizione con meta-informazioni:
- Elementi paralinguistici:
[LAUGH],[MHMH],[SIGH],[UHM] - Qualità audio:
[NOISE],[UNINT](non intelligibile) - Caratteristiche del parlato:
[AUTOCOR](autocorrezioni),[L-EN](code-switching inglese)
Questi token consentono una trascrizione più ricca che cattura non solo il contenuto verbale ma anche elementi contestuali rilevanti.
Evaluation
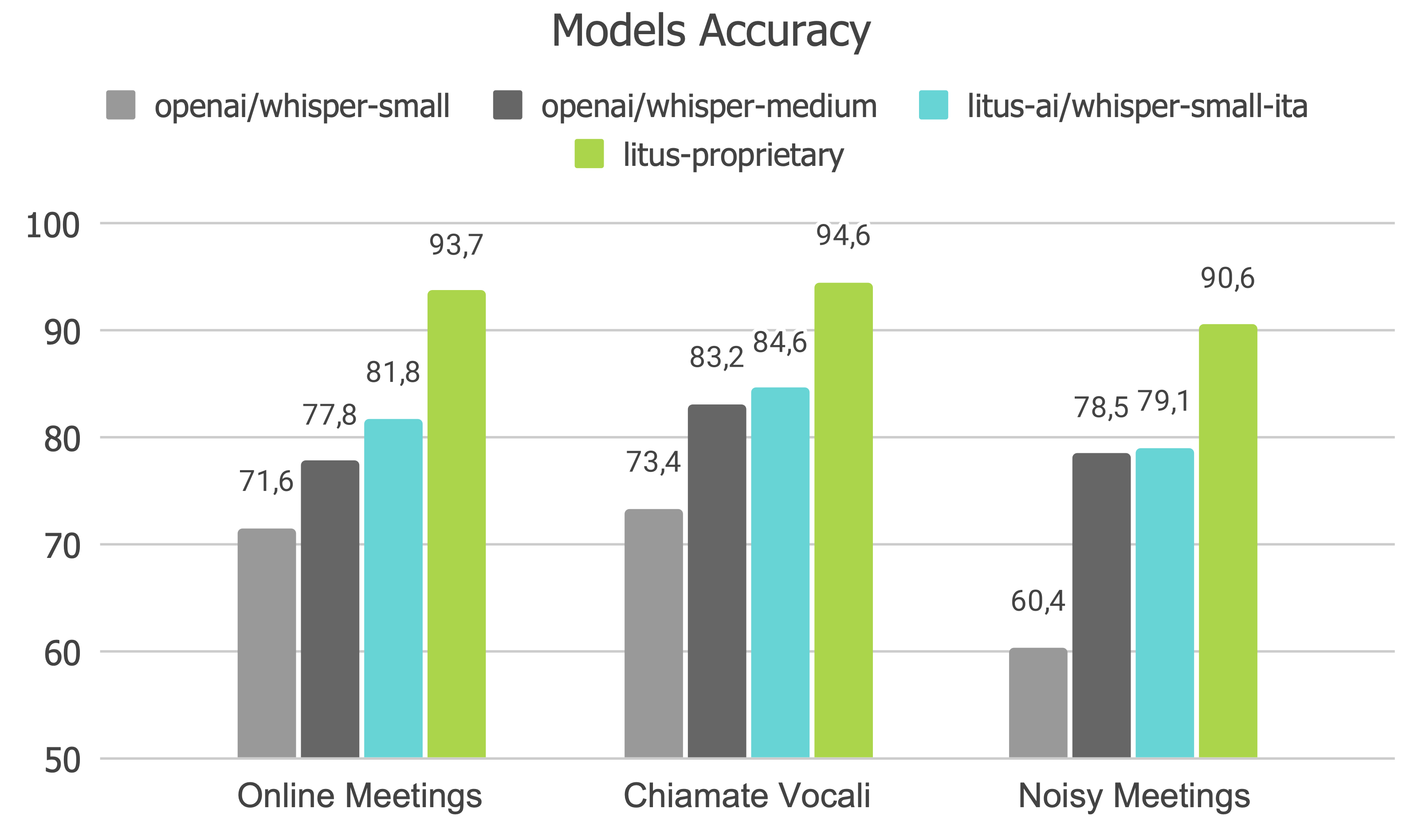
Nel seguente grafico puoi trovare l'Accuracy di openai/whisper-small, openai/whisper-medium, litus-ai/whisper-small-ita e il modello proprietario di Litus AI, litus-proprietary,
su benchmark proprietari per meeting e chiamate vocali in lingua italiana.
Come usare il modello
Puoi utlizzare devilteo911/whisper-small-ita-ct2 tramite faster-whisper:
from faster_whisper import WhisperModel
model = WhisperModel("devilteo911/whisper-small-ita-ct2")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
Dettagli sulla conversione
Il modello originale è stato convertito usando questo comando:
ct2-transformers-converter --model litus-ai/whisper-small-ita --output_dir whisper-small-ita-ct2 \
--copy_files tokenizer_config.json preprocessor_config.json vocab.json normalizer.json merges.txt \
added_tokens.json generation_config.json special_tokens_map.json --quantization float16
Nota che i pesi del modello sono salvati in FP16. Questo tipo può essere cambiato al momento del caricamento del modello usando il parametro compute_type option in CTranslate2.
Conclusions
Per qualsiasi informazione sull'architettura sui dati utilizzati per il pretraining e l'intended use ti preghiamo di rivolgerti al Paper, la Model Card e la Repository originali.
- Downloads last month
- 7