PoolFormer
Overview
The PoolFormer model was proposed in MetaFormer is Actually What You Need for Vision by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
The abstract from the paper is the following:
Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model’s performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of “MetaFormer”, a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.
The figure below illustrates the architecture of PoolFormer. Taken from the original paper.
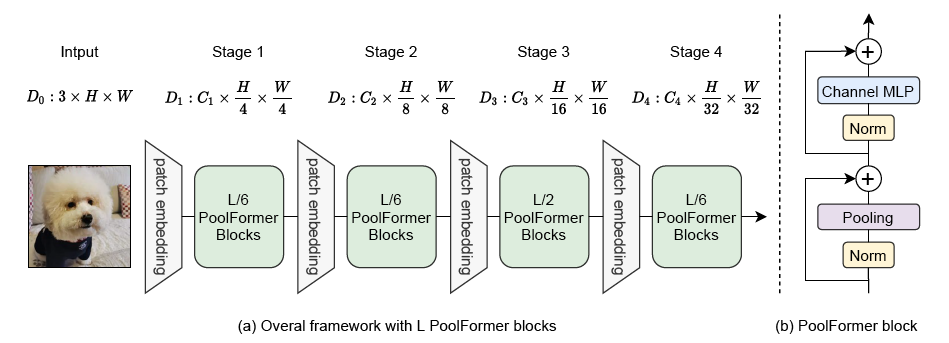
This model was contributed by heytanay. The original code can be found here.
Usage tips
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the hub.
- One can use PoolFormerImageProcessor to prepare images for the model.
- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
| Model variant | Depths | Hidden sizes | Params (M) | ImageNet-1k Top 1 |
|---|---|---|---|---|
| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
- PoolFormerForImageClassification is supported by this example script and notebook.
- See also: Image classification task guide
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
PoolFormerConfig
class transformers.PoolFormerConfig
< source >( num_channels = 3 patch_size = 16 stride = 16 pool_size = 3 mlp_ratio = 4.0 depths = [2, 2, 6, 2] hidden_sizes = [64, 128, 320, 512] patch_sizes = [7, 3, 3, 3] strides = [4, 2, 2, 2] padding = [2, 1, 1, 1] num_encoder_blocks = 4 drop_path_rate = 0.0 hidden_act = 'gelu' use_layer_scale = True layer_scale_init_value = 1e-05 initializer_range = 0.02 **kwargs )
Parameters
- num_channels (
int, optional, defaults to 3) — The number of channels in the input image. - patch_size (
int, optional, defaults to 16) — The size of the input patch. - stride (
int, optional, defaults to 16) — The stride of the input patch. - pool_size (
int, optional, defaults to 3) — The size of the pooling window. - mlp_ratio (
float, optional, defaults to 4.0) — The ratio of the number of channels in the output of the MLP to the number of channels in the input. - depths (
list, optional, defaults to[2, 2, 6, 2]) — The depth of each encoder block. - hidden_sizes (
list, optional, defaults to[64, 128, 320, 512]) — The hidden sizes of each encoder block. - patch_sizes (
list, optional, defaults to[7, 3, 3, 3]) — The size of the input patch for each encoder block. - strides (
list, optional, defaults to[4, 2, 2, 2]) — The stride of the input patch for each encoder block. - padding (
list, optional, defaults to[2, 1, 1, 1]) — The padding of the input patch for each encoder block. - num_encoder_blocks (
int, optional, defaults to 4) — The number of encoder blocks. - drop_path_rate (
float, optional, defaults to 0.0) — The dropout rate for the dropout layers. - hidden_act (
str, optional, defaults to"gelu") — The activation function for the hidden layers. - use_layer_scale (
bool, optional, defaults toTrue) — Whether to use layer scale. - layer_scale_init_value (
float, optional, defaults to 1e-05) — The initial value for the layer scale. - initializer_range (
float, optional, defaults to 0.02) — The initializer range for the weights.
This is the configuration class to store the configuration of PoolFormerModel. It is used to instantiate a PoolFormer model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the PoolFormer sail/poolformer_s12 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import PoolFormerConfig, PoolFormerModel
>>> # Initializing a PoolFormer sail/poolformer_s12 style configuration
>>> configuration = PoolFormerConfig()
>>> # Initializing a model (with random weights) from the sail/poolformer_s12 style configuration
>>> model = PoolFormerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configPoolFormerFeatureExtractor
Preprocess an image or a batch of images.
PoolFormerImageProcessor
class transformers.PoolFormerImageProcessor
< source >( do_resize: bool = True size: Dict = None crop_pct: int = 0.9 resample: Resampling = <Resampling.BICUBIC: 3> do_center_crop: bool = True crop_size: Dict = None rescale_factor: Union = 0.00392156862745098 do_rescale: bool = True do_normalize: bool = True image_mean: Union = None image_std: Union = None **kwargs )
Parameters
- do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s (height, width) dimensions to the specifiedsize. Can be overridden bydo_resizein thepreprocessmethod. - size (
Dict[str, int]optional, defaults to{"shortest_edge" -- 224}): Size of the image after resizing. Can be overridden bysizein thepreprocessmethod. If crop_pct is unset:- size is
{"height": h, "width": w}: the image is resized to(h, w). - size is
{"shortest_edge": s}: the shortest edge of the image is resized to s whilst maintaining the aspect ratio.
If crop_pct is set:
- size is
{"height": h, "width": w}: the image is resized to(int(floor(h/crop_pct)), int(floor(w/crop_pct))) - size is
{"height": c, "width": c}: the shortest edge of the image is resized toint(floor(c/crop_pct)whilst maintaining the aspect ratio. - size is
{"shortest_edge": c}: the shortest edge of the image is resized toint(floor(c/crop_pct)whilst maintaining the aspect ratio.
- size is
- crop_pct (
float, optional, defaults to 0.9) — Percentage of the image to crop from the center. Can be overridden bycrop_pctin thepreprocessmethod. - resample (
PILImageResampling, optional, defaults toResampling.BICUBIC) — Resampling filter to use if resizing the image. Can be overridden byresamplein thepreprocessmethod. - do_center_crop (
bool, optional, defaults toTrue) — Whether to center crop the image. If the input size is smaller thancrop_sizealong any edge, the image is padded with 0’s and then center cropped. Can be overridden bydo_center_cropin thepreprocessmethod. - crop_size (
Dict[str, int], optional, defaults to{"height" -- 224, "width": 224}): Size of the image after applying center crop. Only has an effect ifdo_center_cropis set toTrue. Can be overridden by thecrop_sizeparameter in thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Can be overridden by therescale_factorparameter in thepreprocessmethod. - do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overridden by thedo_rescaleparameter in thepreprocessmethod. - do_normalize (
bool, optional, defaults toTrue) — Controls whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults toIMAGENET_STANDARD_MEAN) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults toIMAGENET_STANDARD_STD) — Standard deviation to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_stdparameter in thepreprocessmethod.
Constructs a PoolFormer image processor.
preprocess
< source >( images: Union do_resize: bool = None size: Dict = None crop_pct: int = None resample: Resampling = None do_center_crop: bool = None crop_size: Dict = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Size of the image after applying resize. - crop_pct (
float, optional, defaults toself.crop_pct) — Percentage of the image to crop. Only has an effect ifdo_resizeis set toTrue. - resample (
int, optional, defaults toself.resample) — Resampling filter to use if resizing the image. This can be one of the enumPILImageResampling, Only has an effect ifdo_resizeis set toTrue. - do_center_crop (
bool, optional, defaults toself.do_center_crop) — Whether to center crop the image. - crop_size (
Dict[str, int], optional, defaults toself.crop_size) — Size of the image after applying center crop. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image values between [0 - 1]. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorList[float], optional, defaults toself.image_mean) — Image mean. - image_std (
floatorList[float], optional, defaults toself.image_std) — Image standard deviation. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:ChannelDimension.FIRST: image in (num_channels, height, width) format.ChannelDimension.LAST: image in (height, width, num_channels) format.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Preprocess an image or batch of images.
PoolFormerModel
class transformers.PoolFormerModel
< source >( config )
Parameters
- config (PoolFormerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare PoolFormer Model transformer outputting raw hidden-states without any specific head on top. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.BaseModelOutputWithNoAttention or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See PoolFormerImageProcessor.call() for details.
Returns
transformers.modeling_outputs.BaseModelOutputWithNoAttention or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithNoAttention or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PoolFormerConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, num_channels, height, width).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
The PoolFormerModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoImageProcessor, PoolFormerModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image", trust_remote_code=True)
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("sail/poolformer_s12")
>>> model = PoolFormerModel.from_pretrained("sail/poolformer_s12")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 512, 7, 7]PoolFormerForImageClassification
class transformers.PoolFormerForImageClassification
< source >( config )
Parameters
- config (PoolFormerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
PoolFormer Model transformer with an image classification head on top
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: Optional = None labels: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See PoolFormerImageProcessor.call() for details. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or tuple(torch.FloatTensor)
A transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PoolFormerConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each stage) of shape(batch_size, num_channels, height, width). Hidden-states (also called feature maps) of the model at the output of each stage.
The PoolFormerForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoImageProcessor, PoolFormerForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image", trust_remote_code=True)
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("sail/poolformer_s12")
>>> model = PoolFormerForImageClassification.from_pretrained("sail/poolformer_s12")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby cat